 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Attention-Based Recurrent Neural Network For Automatic Behavior Laying Hen Recognition
Jan 18, 2024
One of the interests of modern poultry farming is the vocalization of laying hens which contain very useful information on health behavior. This information is used as health and well-being indicators that help breeders better monitor laying hens, which involves early detection of problems for rapid and more effective intervention. In this work, we focus on the sound analysis for the recognition of the types of calls of the laying hens in order to propose a robust system of characterization of their behavior for a better monitoring. To do this, we first collected and annotated laying hen call signals, then designed an optimal acoustic characterization based on the combination of time and frequency domain features. We then used these features to build the multi-label classification models based on recurrent neural network to assign a semantic class to the vocalization that characterize the laying hen behavior. The results show an overall performance with our model based on the combination of time and frequency domain features that obtained the highest F1-score (F1=92.75) with a gain of 17% on the models using the frequency domain features and of 8% on the compared approaches from the litterature.
STanHop: Sparse Tandem Hopfield Model for Memory-Enhanced Time Series Prediction
Dec 28, 2023We present STanHop-Net (Sparse Tandem Hopfield Network) for multivariate time series prediction with memory-enhanced capabilities. At the heart of our approach is STanHop, a novel Hopfield-based neural network block, which sparsely learns and stores both temporal and cross-series representations in a data-dependent fashion. In essence, STanHop sequentially learn temporal representation and cross-series representation using two tandem sparse Hopfield layers. In addition, StanHop incorporates two additional external memory modules: a Plug-and-Play module and a Tune-and-Play module for train-less and task-aware memory-enhancements, respectively. They allow StanHop-Net to swiftly respond to certain sudden events. Methodologically, we construct the StanHop-Net by stacking STanHop blocks in a hierarchical fashion, enabling multi-resolution feature extraction with resolution-specific sparsity. Theoretically, we introduce a sparse extension of the modern Hopfield model (Generalized Sparse Modern Hopfield Model) and show that it endows a tighter memory retrieval error compared to the dense counterpart without sacrificing memory capacity. Empirically, we validate the efficacy of our framework on both synthetic and real-world settings.
Segmentation of tibiofemoral joint tissues from knee MRI using MtRA-Unet and incorporating shape information: Data from the Osteoarthritis Initiative
Jan 23, 2024Knee Osteoarthritis (KOA) is the third most prevalent Musculoskeletal Disorder (MSD) after neck and back pain. To monitor such a severe MSD, a segmentation map of the femur, tibia and tibiofemoral cartilage is usually accessed using the automated segmentation algorithm from the Magnetic Resonance Imaging (MRI) of the knee. But, in recent works, such segmentation is conceivable only from the multistage framework thus creating data handling issues and needing continuous manual inference rendering it unable to make a quick and precise clinical diagnosis. In order to solve these issues, in this paper the Multi-Resolution Attentive-Unet (MtRA-Unet) is proposed to segment the femur, tibia and tibiofemoral cartilage automatically. The proposed work has included a novel Multi-Resolution Feature Fusion (MRFF) and Shape Reconstruction (SR) loss that focuses on multi-contextual information and structural anatomical details of the femur, tibia and tibiofemoral cartilage. Unlike previous approaches, the proposed work is a single-stage and end-to-end framework producing a Dice Similarity Coefficient (DSC) of 98.5% for the femur, 98.4% for the tibia, 89.1% for Femoral Cartilage (FC) and 86.1% for Tibial Cartilage (TC) for critical MRI slices that can be helpful to clinicians for KOA grading. The time to segment MRI volume (160 slices) per subject is 22 sec. which is one of the fastest among state-of-the-art. Moreover, comprehensive experimentation on the segmentation of FC and TC which is of utmost importance for morphology-based studies to check KOA progression reveals that the proposed method has produced an excellent result with binary segmentation
The Neglected Tails of Vision-Language Models
Jan 23, 2024Vision-language models (VLMs) excel in zero-shot recognition but exhibit drastically imbalanced performance across visual concepts. For example, CLIP, despite an impressive mean zero-shot accuracy on ImageNet (72.7%), yields $<$10% on ten concepts (e.g., gyromitra and night snake), presumably, because these concepts are under-represented in VLMs' imbalanced pretraining data. Yet, assessing this imbalance is challenging as it is non-trivial to calculate the frequency of specific concepts within VLMs' large-scale pretraining data. Our work makes the first attempt to measure the concept frequency by analyzing pretraining texts. We use off-the-shelf language models to help count relevant texts that contain synonyms of the given concepts and resolve linguistic ambiguity. We confirm that popular VLM datasets like LAION indeed exhibit long-tailed concept distributions, which strongly correlate with per-class accuracies. Further, contemporary multimodal systems, e.g., visual chatbots and text-to-image generators, also struggle with the rare concepts identified by our method. To mitigate VLMs' imbalanced performance in zero-shot recognition, we propose REtrieval-Augmented Learning REAL. First, instead of prompting VLMs using the original class names, REAL uses their most frequent synonyms found in VLMs' pretraining texts. This already outperforms human-engineered and LLM-generated prompts over nine benchmark datasets, likely because VLMs have seen more images associated with the frequently used synonyms. Second, REAL uses all the concept synonyms to retrieve a small, class-balanced set of pretraining data to train a robust classifier. REAL surpasses the recent retrieval-augmented solution REACT, using 400x less storage and 10,000x less training time!
Entropy Causal Graphs for Multivariate Time Series Anomaly Detection
Dec 15, 2023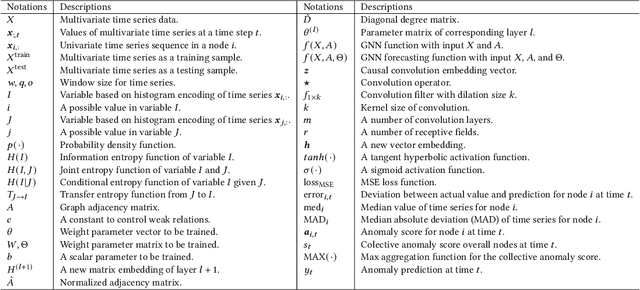
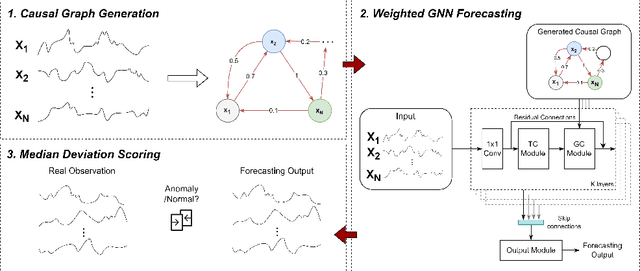
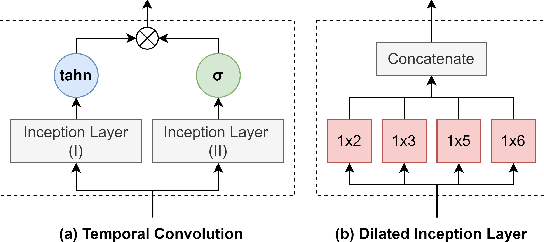
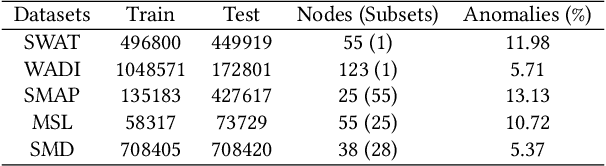
Many multivariate time series anomaly detection frameworks have been proposed and widely applied. However, most of these frameworks do not consider intrinsic relationships between variables in multivariate time series data, thus ignoring the causal relationship among variables and degrading anomaly detection performance. This work proposes a novel framework called CGAD, an entropy Causal Graph for multivariate time series Anomaly Detection. CGAD utilizes transfer entropy to construct graph structures that unveil the underlying causal relationships among time series data. Weighted graph convolutional networks combined with causal convolutions are employed to model both the causal graph structures and the temporal patterns within multivariate time series data. Furthermore, CGAD applies anomaly scoring, leveraging median absolute deviation-based normalization to improve the robustness of the anomaly identification process. Extensive experiments demonstrate that CGAD outperforms state-of-the-art methods on real-world datasets with a 15% average improvement based on three different multivariate time series anomaly detection metrics.
Simulated Autopoiesis in Liquid Automata
Jan 15, 2024We present a novel form of Liquid Automata, using this to simulate autopoiesis, whereby living machines self-organise in the physical realm. This simulation is based on an earlier Cellular Automaton described by Francisco Varela. The basis of Liquid Automata is a particle simulation with additional rules about how particles are transformed on collision with other particles. Unlike cellular automata, there is no fixed grid or time-step, only particles moving about and colliding with each other in a continuous space/time.
Neural Time-Reversed Generalized Riccati Equation
Dec 14, 2023Optimal control deals with optimization problems in which variables steer a dynamical system, and its outcome contributes to the objective function. Two classical approaches to solving these problems are Dynamic Programming and the Pontryagin Maximum Principle. In both approaches, Hamiltonian equations offer an interpretation of optimality through auxiliary variables known as costates. However, Hamiltonian equations are rarely used due to their reliance on forward-backward algorithms across the entire temporal domain. This paper introduces a novel neural-based approach to optimal control, with the aim of working forward-in-time. Neural networks are employed not only for implementing state dynamics but also for estimating costate variables. The parameters of the latter network are determined at each time step using a newly introduced local policy referred to as the time-reversed generalized Riccati equation. This policy is inspired by a result discussed in the Linear Quadratic (LQ) problem, which we conjecture stabilizes state dynamics. We support this conjecture by discussing experimental results from a range of optimal control case studies.
Scaling Face Interaction Graph Networks to Real World Scenes
Jan 22, 2024Accurately simulating real world object dynamics is essential for various applications such as robotics, engineering, graphics, and design. To better capture complex real dynamics such as contact and friction, learned simulators based on graph networks have recently shown great promise. However, applying these learned simulators to real scenes comes with two major challenges: first, scaling learned simulators to handle the complexity of real world scenes which can involve hundreds of objects each with complicated 3D shapes, and second, handling inputs from perception rather than 3D state information. Here we introduce a method which substantially reduces the memory required to run graph-based learned simulators. Based on this memory-efficient simulation model, we then present a perceptual interface in the form of editable NeRFs which can convert real-world scenes into a structured representation that can be processed by graph network simulator. We show that our method uses substantially less memory than previous graph-based simulators while retaining their accuracy, and that the simulators learned in synthetic environments can be applied to real world scenes captured from multiple camera angles. This paves the way for expanding the application of learned simulators to settings where only perceptual information is available at inference time.
Integrating Statistical Significance and Discriminative Power in Pattern Discovery
Jan 22, 2024Pattern discovery plays a central role in both descriptive and predictive tasks across multiple domains. Actionable patterns must meet rigorous statistical significance criteria and, in the presence of target variables, further uphold discriminative power. Our work addresses the underexplored area of guiding pattern discovery by integrating statistical significance and discriminative power criteria into state-of-the-art algorithms while preserving pattern quality. We also address how pattern quality thresholds, imposed by some algorithms, can be rectified to accommodate these additional criteria. To test the proposed methodology, we select the triclustering task as the guiding pattern discovery case and extend well-known greedy and multi-objective optimization triclustering algorithms, $\delta$-Trimax and TriGen, that use various pattern quality criteria, such as Mean Squared Residual (MSR), Least Squared Lines (LSL), and Multi Slope Measure (MSL). Results from three case studies show the role of the proposed methodology in discovering patterns with pronounced improvements of discriminative power and statistical significance without quality deterioration, highlighting its importance in supervisedly guiding the search. Although the proposed methodology is motivated over multivariate time series data, it can be straightforwardly extended to pattern discovery tasks involving multivariate, N-way (N>3), transactional, and sequential data structures. Availability: The code is freely available at https://github.com/JupitersMight/MOF_Triclustering under the MIT license.
Towards Effective and General Graph Unlearning via Mutual Evolution
Jan 22, 2024With the rapid advancement of AI applications, the growing needs for data privacy and model robustness have highlighted the importance of machine unlearning, especially in thriving graph-based scenarios. However, most existing graph unlearning strategies primarily rely on well-designed architectures or manual process, rendering them less user-friendly and posing challenges in terms of deployment efficiency. Furthermore, striking a balance between unlearning performance and framework generalization is also a pivotal concern. To address the above issues, we propose \underline{\textbf{M}}utual \underline{\textbf{E}}volution \underline{\textbf{G}}raph \underline{\textbf{U}}nlearning (MEGU), a new mutual evolution paradigm that simultaneously evolves the predictive and unlearning capacities of graph unlearning. By incorporating aforementioned two components, MEGU ensures complementary optimization in a unified training framework that aligns with the prediction and unlearning requirements. Extensive experiments on 9 graph benchmark datasets demonstrate the superior performance of MEGU in addressing unlearning requirements at the feature, node, and edge levels. Specifically, MEGU achieves average performance improvements of 2.7\%, 2.5\%, and 3.2\% across these three levels of unlearning tasks when compared to state-of-the-art baselines. Furthermore, MEGU exhibits satisfactory training efficiency, reducing time and space overhead by an average of 159.8x and 9.6x, respectively, in comparison to retraining GNN from scratch.