 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Stacked Deep Multi-Scale Hierarchical Network for Fast Bokeh Effect Rendering from a Single Image
May 15, 2021
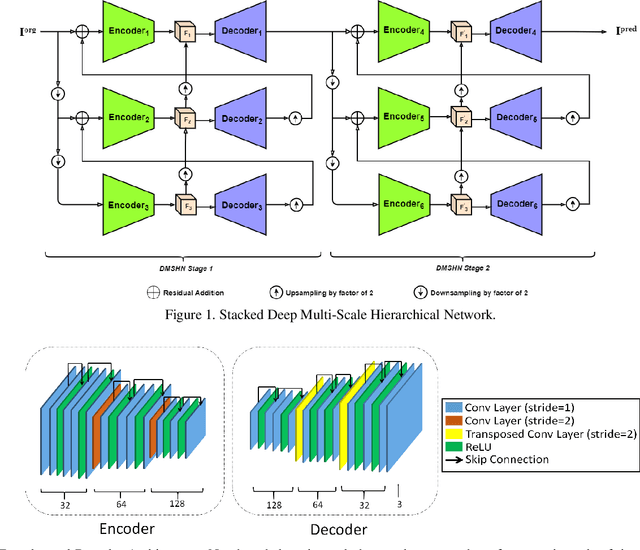
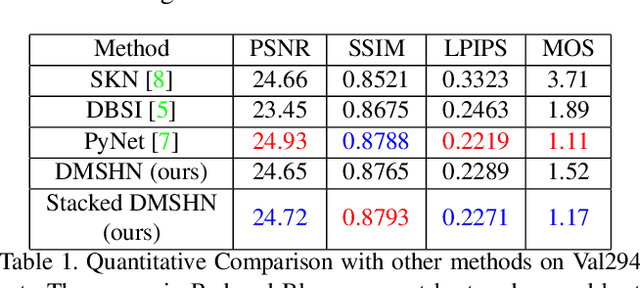
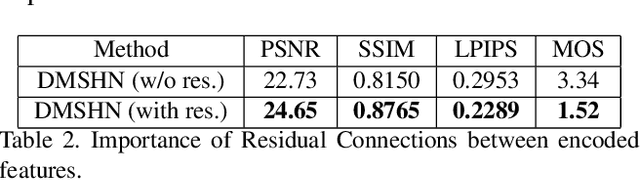

The Bokeh Effect is one of the most desirable effects in photography for rendering artistic and aesthetic photos. Usually, it requires a DSLR camera with different aperture and shutter settings and certain photography skills to generate this effect. In smartphones, computational methods and additional sensors are used to overcome the physical lens and sensor limitations to achieve such effect. Most of the existing methods utilized additional sensor's data or pretrained network for fine depth estimation of the scene and sometimes use portrait segmentation pretrained network module to segment salient objects in the image. Because of these reasons, networks have many parameters, become runtime intensive and unable to run in mid-range devices. In this paper, we used an end-to-end Deep Multi-Scale Hierarchical Network (DMSHN) model for direct Bokeh effect rendering of images captured from the monocular camera. To further improve the perceptual quality of such effect, a stacked model consisting of two DMSHN modules is also proposed. Our model does not rely on any pretrained network module for Monocular Depth Estimation or Saliency Detection, thus significantly reducing the size of model and run time. Stacked DMSHN achieves state-of-the-art results on a large scale EBB! dataset with around 6x less runtime compared to the current state-of-the-art model in processing HD quality images.
Lane Graph Estimation for Scene Understanding in Urban Driving
May 01, 2021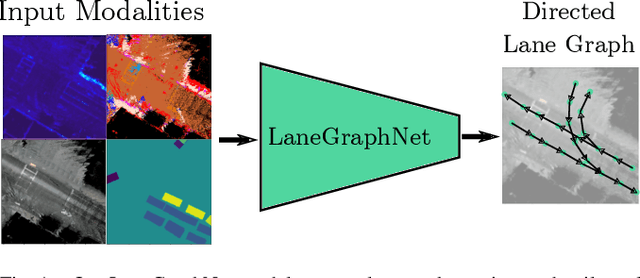
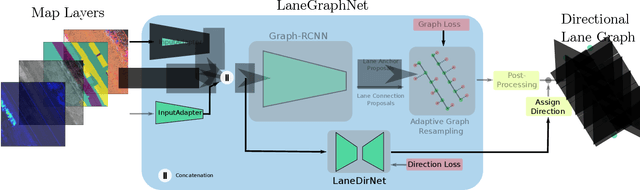


Lane-level scene annotations provide invaluable data in autonomous vehicles for trajectory planning in complex environments such as urban areas and cities. However, obtaining such data is time-consuming and expensive since lane annotations have to be annotated manually by humans and are as such hard to scale to large areas. In this work, we propose a novel approach for lane geometry estimation from bird's-eye-view images. We formulate the problem of lane shape and lane connections estimation as a graph estimation problem where lane anchor points are graph nodes and lane segments are graph edges. We train a graph estimation model on multimodal bird's-eye-view data processed from the popular NuScenes dataset and its map expansion pack. We furthermore estimate the direction of the lane connection for each lane segment with a separate model which results in a directed lane graph. We illustrate the performance of our LaneGraphNet model on the challenging NuScenes dataset and provide extensive qualitative and quantitative evaluation. Our model shows promising performance for most evaluated urban scenes and can serve as a step towards automated generation of HD lane annotations for autonomous driving.
An Update to the Minho Quotation Resource
Apr 14, 2021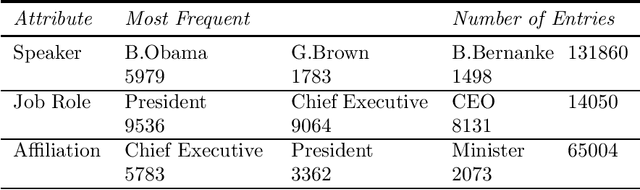
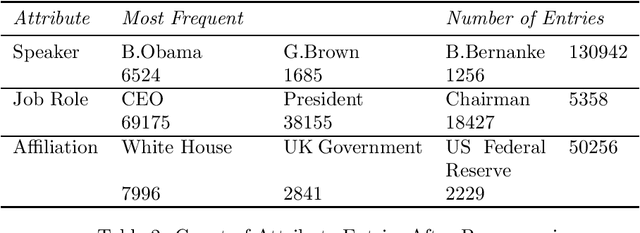

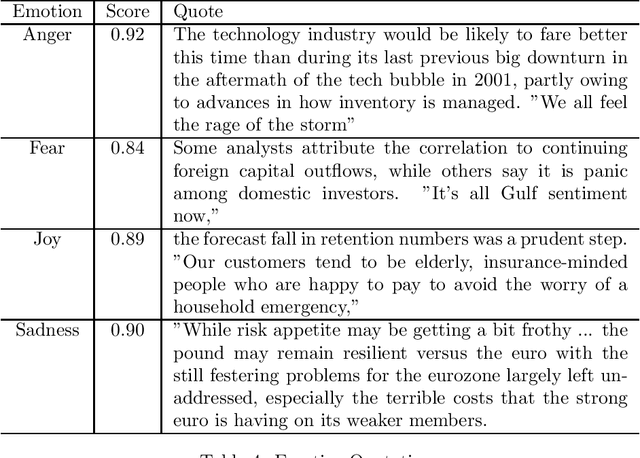
The Minho Quotation Resource was originally released in 2012. It provided approximately 500,000 quotes from business leaders, analysts and politicians that spanned the period from 2008 to 2012. The original resource had several failings which include a large number of missing job titles and affiliations as well as unnormalised job titles which produced a large variation in spellings and formats of the same employment position. Also, there were numerous duplicate posts. This update has standardised the job title text as well as the imputation of missing job titles and affiliations. Duplicate quotes have been deleted. This update also provides some metaphor and simile extraction as well as an emotion distribution of the quotes. This update has also replaced an antiquated version of Lucene index with a JSONL format as well as a rudimentary interface that can query the data supplied with the resource. It is hoped that this update will encourage the study of business communication in a time of a financial crisis.
Continuous Time Dynamic Topic Models
May 16, 2015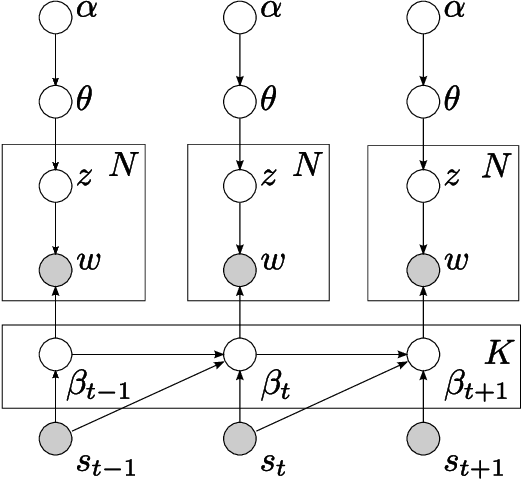

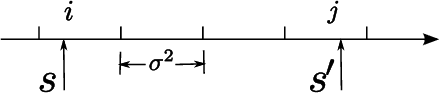
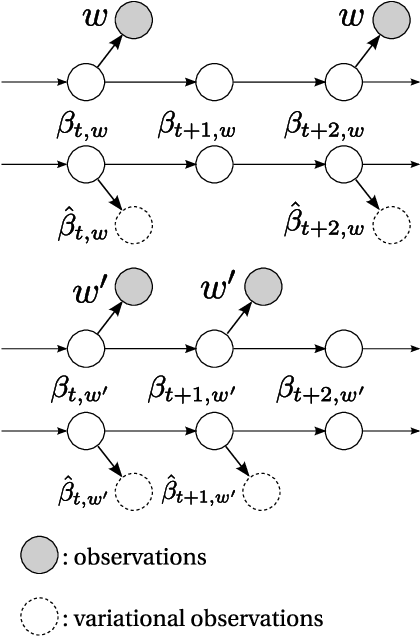
In this paper, we develop the continuous time dynamic topic model (cDTM). The cDTM is a dynamic topic model that uses Brownian motion to model the latent topics through a sequential collection of documents, where a "topic" is a pattern of word use that we expect to evolve over the course of the collection. We derive an efficient variational approximate inference algorithm that takes advantage of the sparsity of observations in text, a property that lets us easily handle many time points. In contrast to the cDTM, the original discrete-time dynamic topic model (dDTM) requires that time be discretized. Moreover, the complexity of variational inference for the dDTM grows quickly as time granularity increases, a drawback which limits fine-grained discretization. We demonstrate the cDTM on two news corpora, reporting both predictive perplexity and the novel task of time stamp prediction.
End-to-End Intersection Handling using Multi-Agent Deep Reinforcement Learning
May 01, 2021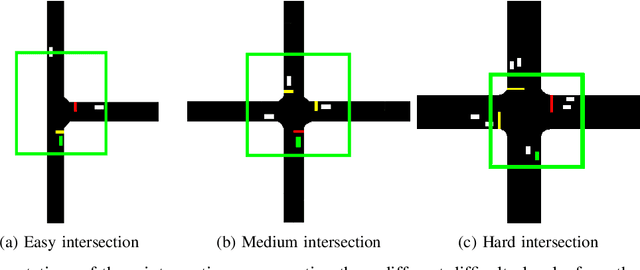
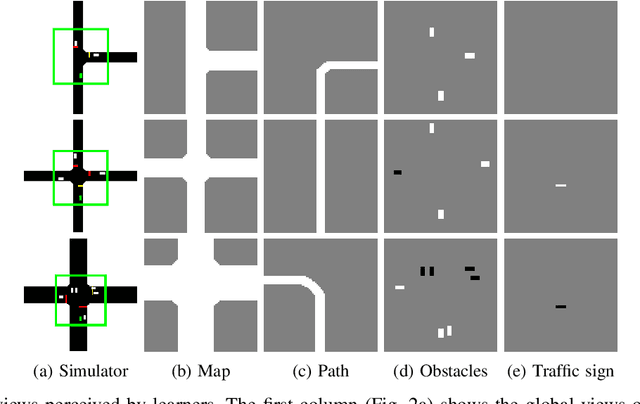
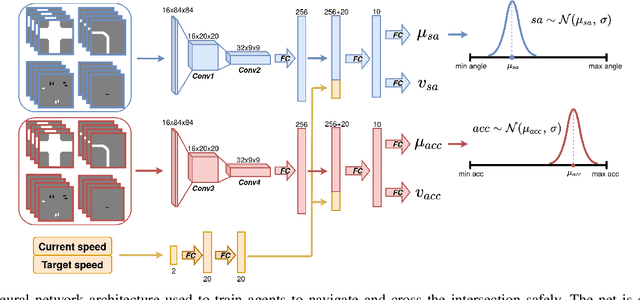
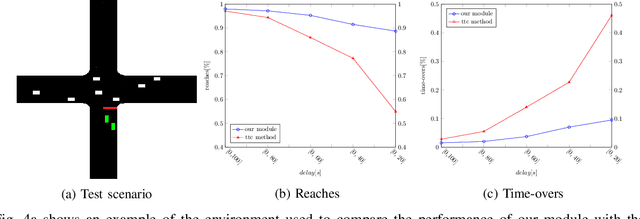
Navigating through intersections is one of the main challenging tasks for an autonomous vehicle. However, for the majority of intersections regulated by traffic lights, the problem could be solved by a simple rule-based method in which the autonomous vehicle behavior is closely related to the traffic light states. In this work, we focus on the implementation of a system able to navigate through intersections where only traffic signs are provided. We propose a multi-agent system using a continuous, model-free Deep Reinforcement Learning algorithm used to train a neural network for predicting both the acceleration and the steering angle at each time step. We demonstrate that agents learn both the basic rules needed to handle intersections by understanding the priorities of other learners inside the environment, and to drive safely along their paths. Moreover, a comparison between our system and a rule-based method proves that our model achieves better results especially with dense traffic conditions. Finally, we test our system on real world scenarios using real recorded traffic data, proving that our module is able to generalize both to unseen environments and to different traffic conditions.
A Cognitive Approach to Real-time Rescheduling using SOAR-RL
May 12, 2018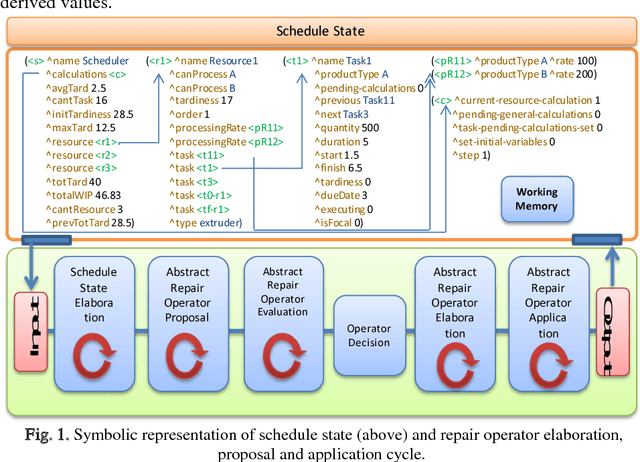
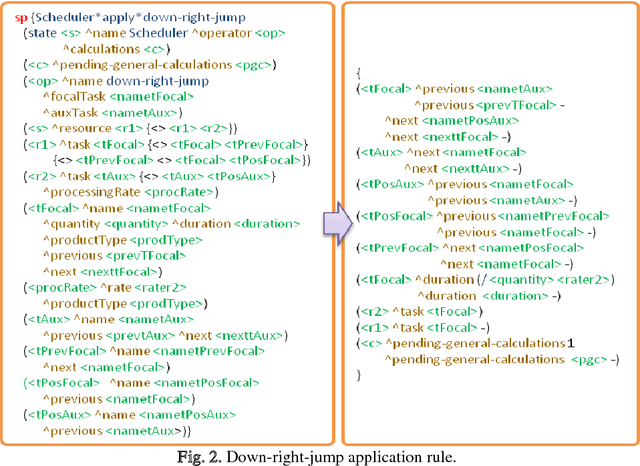
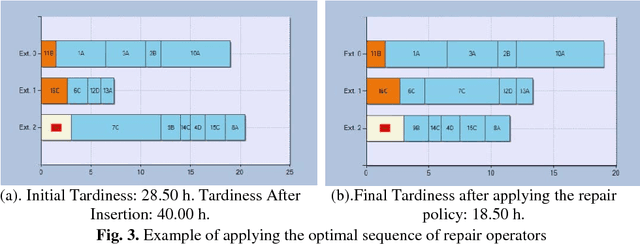
Ensuring flexible and efficient manufacturing of customized products in an increasing dynamic and turbulent environment without sacrificing cost effectiveness, product quality and on-time delivery has become a key issue for most industrial enterprises. A promising approach to cope with this challenge is the integration of cognitive capabilities in systems and processes with the aim of expanding the knowledge base used to perform managerial and operational tasks. In this work, a novel approach to real-time rescheduling is proposed in order to achieve sustainable improvements in flexibility and adaptability of production systems through the integration of artificial cognitive capabilities, involving perception, reasoning/learning and planning skills. Moreover, an industrial example is discussed where the SOAR cognitive architecture capabilities are integrated in a software prototype, showing that the approach enables the rescheduling system to respond to events in an autonomic way, and to acquire experience through intensive simulation while performing repair tasks.
Sequential convolutional network for behavioral pattern extraction in gait recognition
Apr 23, 2021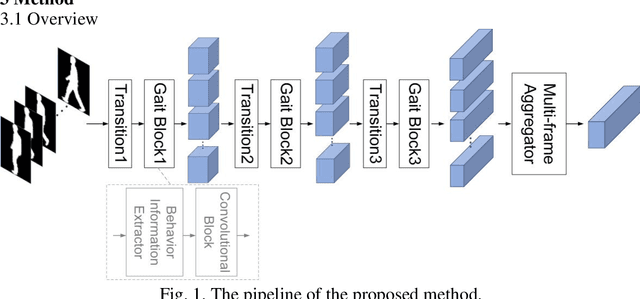
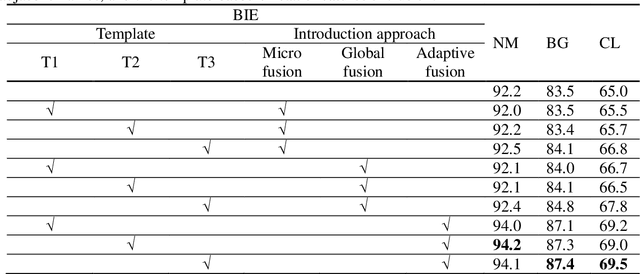
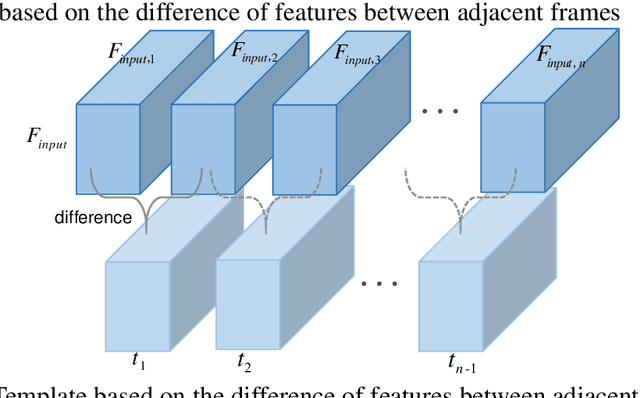
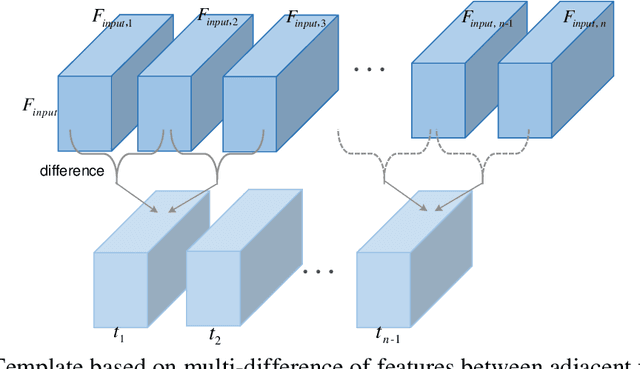
As a unique and promising biometric, video-based gait recognition has broad applications. The key step of this methodology is to learn the walking pattern of individuals, which, however, often suffers challenges to extract the behavioral feature from a sequence directly. Most existing methods just focus on either the appearance or the motion pattern. To overcome these limitations, we propose a sequential convolutional network (SCN) from a novel perspective, where spatiotemporal features can be learned by a basic convolutional backbone. In SCN, behavioral information extractors (BIE) are constructed to comprehend intermediate feature maps in time series through motion templates where the relationship between frames can be analyzed, thereby distilling the information of the walking pattern. Furthermore, a multi-frame aggregator in SCN performs feature integration on a sequence whose length is uncertain, via a mobile 3D convolutional layer. To demonstrate the effectiveness, experiments have been conducted on two popular public benchmarks, CASIA-B and OU-MVLP, and our approach is demonstrated superior performance, comparing with the state-of-art methods.
Aligning Latent and Image Spaces to Connect the Unconnectable
Apr 14, 2021
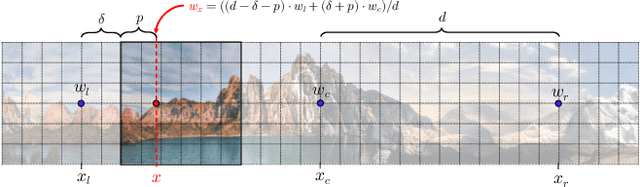

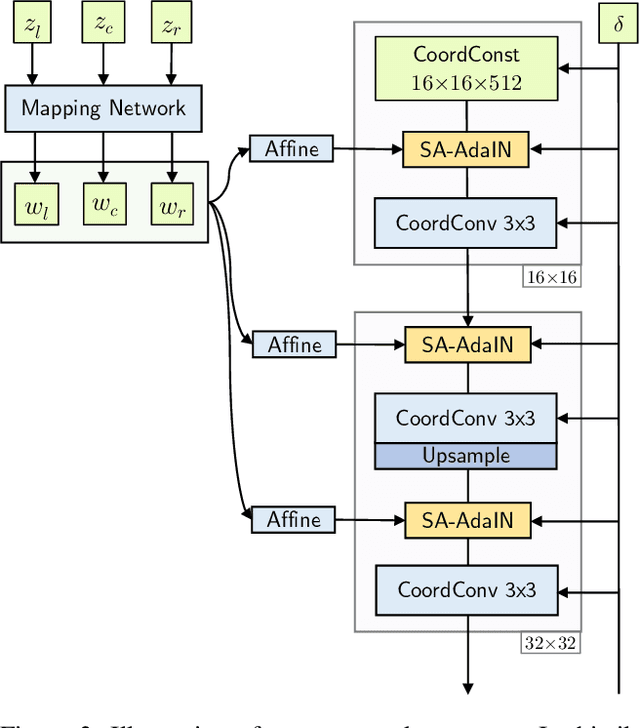
In this work, we develop a method to generate infinite high-resolution images with diverse and complex content. It is based on a perfectly equivariant generator with synchronous interpolations in the image and latent spaces. Latent codes, when sampled, are positioned on the coordinate grid, and each pixel is computed from an interpolation of the nearby style codes. We modify the AdaIN mechanism to work in such a setup and train the generator in an adversarial setting to produce images positioned between any two latent vectors. At test time, this allows for generating complex and diverse infinite images and connecting any two unrelated scenes into a single arbitrarily large panorama. Apart from that, we introduce LHQ: a new dataset of \lhqsize high-resolution nature landscapes. We test the approach on LHQ, LSUN Tower and LSUN Bridge and outperform the baselines by at least 4 times in terms of quality and diversity of the produced infinite images. The project page is located at https://universome.github.io/alis.
An Efficient and Scalable Deep Learning Approach for Road Damage Detection
Dec 17, 2020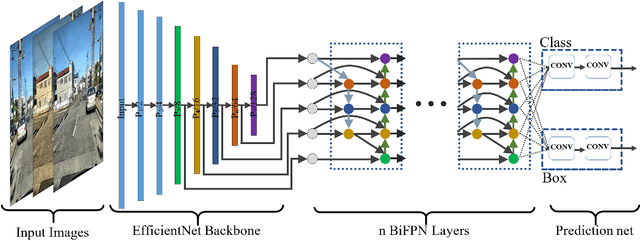

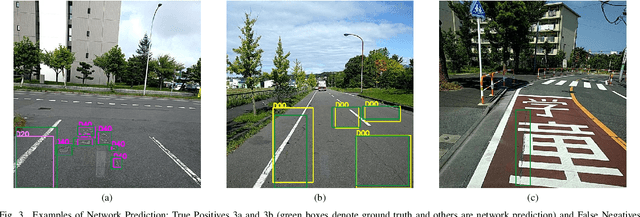

Pavement condition evaluation is essential to time the preventative or rehabilitative actions and control distress propagation. Failing to conduct timely evaluations can lead to severe structural and financial loss of the infrastructure and complete reconstructions. Automated computer-aided surveying measures can provide a database of road damage patterns and their locations. This database can be utilized for timely road repairs to gain the minimum cost of maintenance and the asphalt's maximum durability. This paper introduces a deep learning-based surveying scheme to analyze the image-based distress data in real-time. A database consisting of a diverse population of crack distress types such as longitudinal, transverse, and alligator cracks, photographed using mobile-device is used. Then, a family of efficient and scalable models that are tuned for pavement crack detection is trained, and various augmentation policies are explored. Proposed models, resulted in F1-scores, ranging from 52% to 56%, and average inference time from 178-10 images per second. Finally, the performance of the object detectors are examined, and error analysis is reported against various images. The source code is available at https://github.com/mahdi65/roadDamageDetection2020.
M4Depth: A motion-based approach for monocular depth estimation on video sequences
May 21, 2021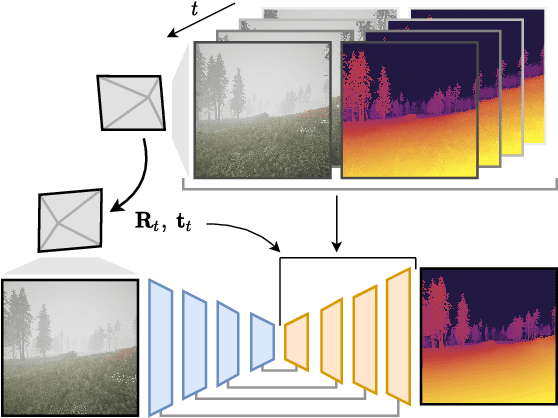
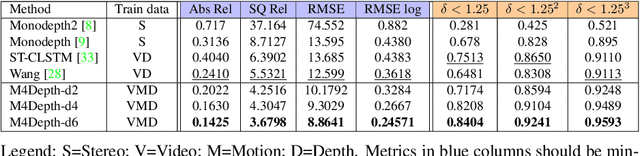
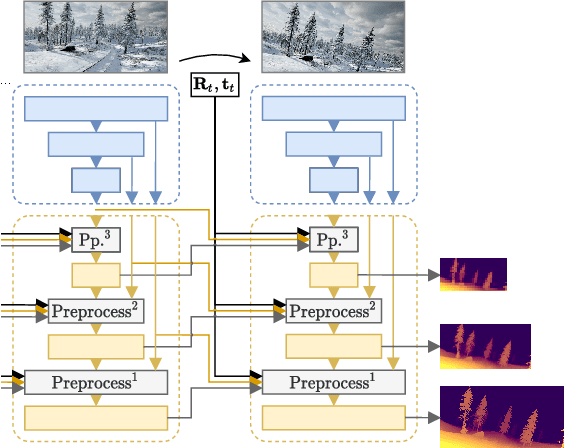
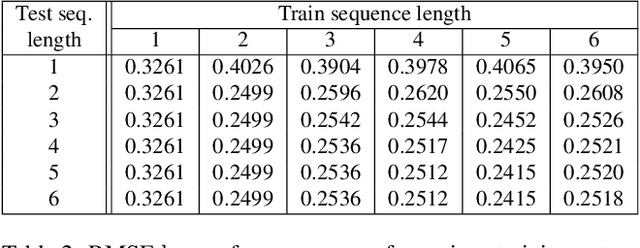
Getting the distance to objects is crucial for autonomous vehicles. In instances where depth sensors cannot be used, this distance has to be estimated from RGB cameras. As opposed to cars, the task of estimating depth from on-board mounted cameras is made complex on drones because of the lack of constrains on motion during flights. In this paper, we present a method to estimate the distance of objects seen by an on-board mounted camera by using its RGB video stream and drone motion information. Our method is built upon a pyramidal convolutional neural network architecture and uses time recurrence in pair with geometric constraints imposed by motion to produce pixel-wise depth maps. In our architecture, each level of the pyramid is designed to produce its own depth estimate based on past observations and information provided by the previous level in the pyramid. We introduce a spatial reprojection layer to maintain the spatio-temporal consistency of the data between the levels. We analyse the performance of our approach on Mid-Air, a public drone dataset featuring synthetic drone trajectories recorded in a wide variety of unstructured outdoor environments. Our experiments show that our network outperforms state-of-the-art depth estimation methods and that the use of motion information is the main contributing factor for this improvement. The code of our method is publicly available on GitHub; see https://github.com/michael-fonder/M4Depth