 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Biologically inspired alternatives to backpropagation through time for learning in recurrent neural nets
Jan 25, 2019
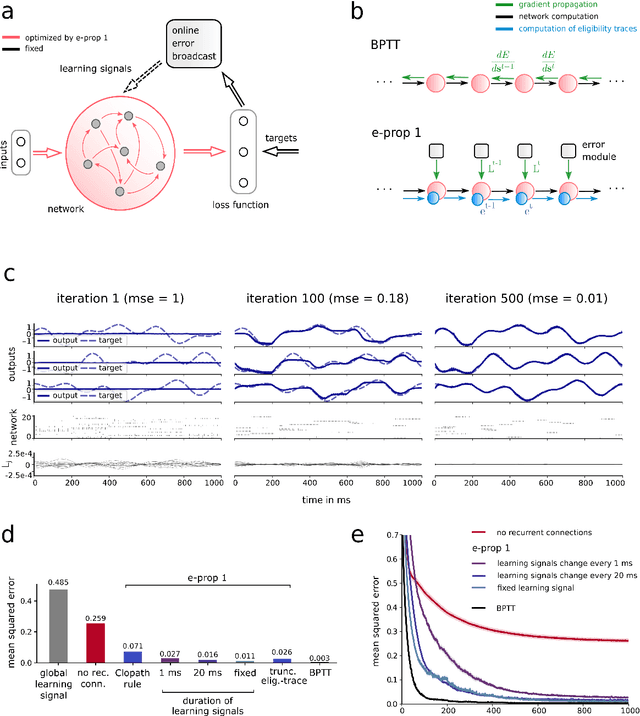
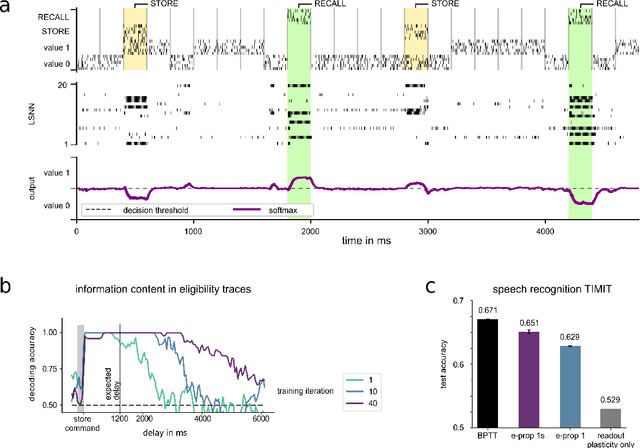
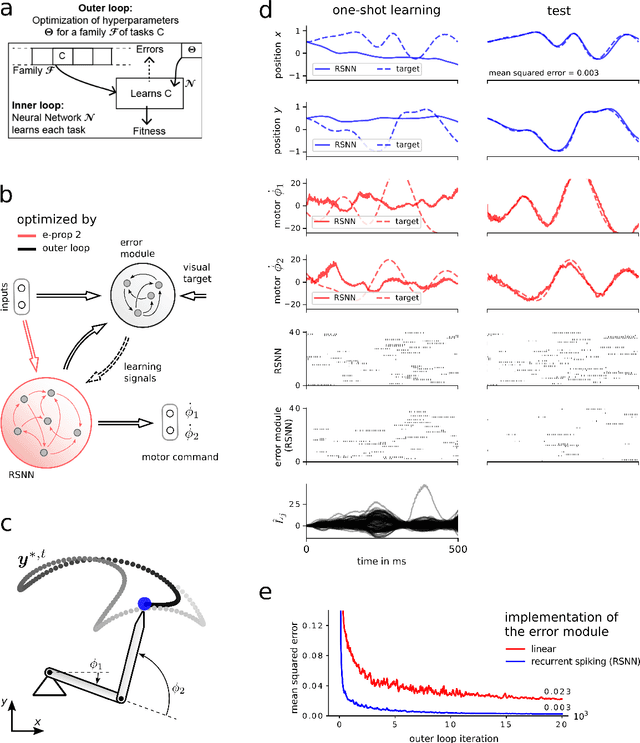
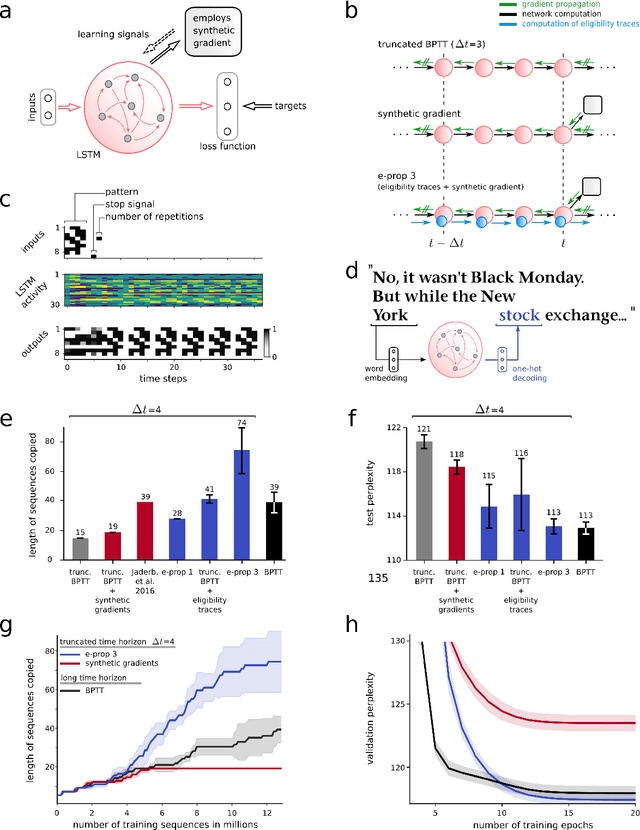
The way how recurrently connected networks of spiking neurons in the brain acquire powerful information processing capabilities through learning has remained a mystery. This lack of understanding is linked to a lack of learning algorithms for recurrent networks of spiking neurons (RSNNs) that are both functionally powerful and can be implemented by known biological mechanisms. Since RSNNs are simultaneously a primary target for implementations of brain-inspired circuits in neuromorphic hardware, this lack of algorithmic insight also hinders technological progress in that area. The gold standard for learning in recurrent neural networks in machine learning is back-propagation through time (BPTT), which implements stochastic gradient descent with regard to a given loss function. But BPTT is unrealistic from a biological perspective, since it requires a transmission of error signals backwards in time and in space, i.e., from post- to presynaptic neurons. We show that an online merging of locally available information during a computation with suitable top-down learning signals in real-time provides highly capable approximations to BPTT. For tasks where information on errors arises only late during a network computation, we enrich locally available information through feedforward eligibility traces of synapses that can easily be computed in an online manner. The resulting new generation of learning algorithms for recurrent neural networks provides a new understanding of network learning in the brain that can be tested experimentally. In addition, these algorithms provide efficient methods for on-chip training of RSNNs in neuromorphic hardware.
Anchor-based Plain Net for Mobile Image Super-Resolution
May 20, 2021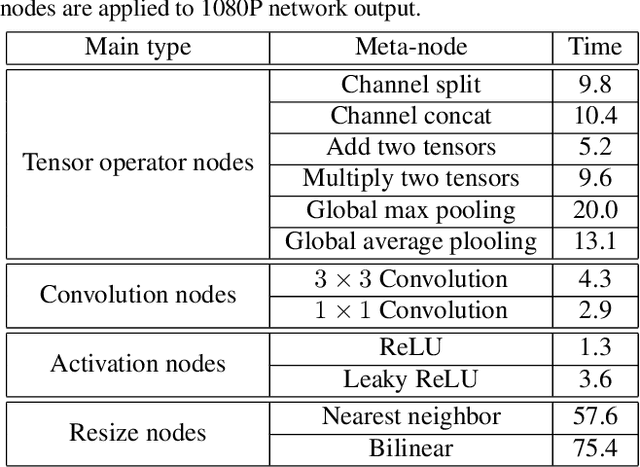
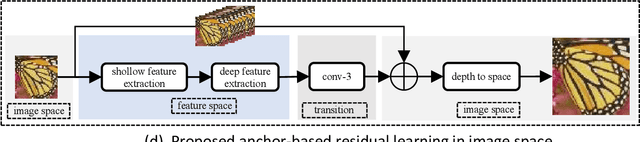
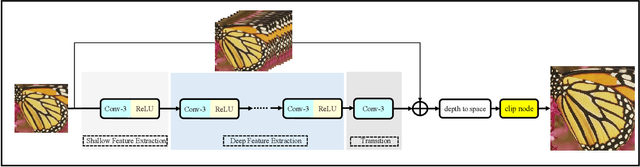
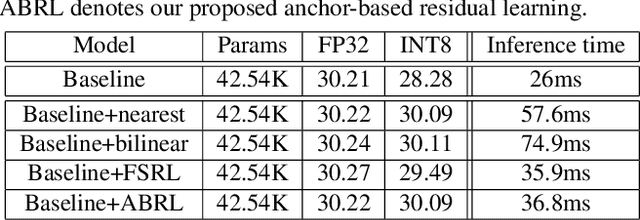
Along with the rapid development of real-world applications, higher requirements on the accuracy and efficiency of image super-resolution (SR) are brought forward. Though existing methods have achieved remarkable success, the majority of them demand plenty of computational resources and large amount of RAM, and thus they can not be well applied to mobile device. In this paper, we aim at designing efficient architecture for 8-bit quantization and deploy it on mobile device. First, we conduct an experiment about meta-node latency by decomposing lightweight SR architectures, which determines the portable operations we can utilize. Then, we dig deeper into what kind of architecture is beneficial to 8-bit quantization and propose anchor-based plain net (ABPN). Finally, we adopt quantization-aware training strategy to further boost the performance. Our model can outperform 8-bit quantized FSRCNN by nearly 2dB in terms of PSNR, while satisfying realistic needs at the same time. Code is avaliable at https://github.com/NJU- Jet/SR_Mobile_Quantization.
Where the Action is: Let's make Reinforcement Learning for Stochastic Dynamic Vehicle Routing Problems work!
Feb 28, 2021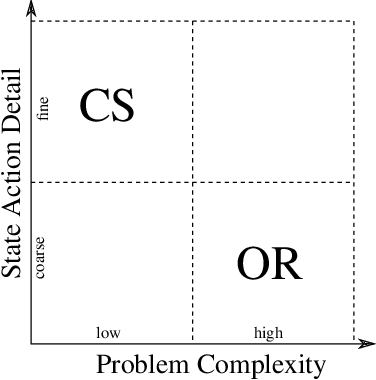
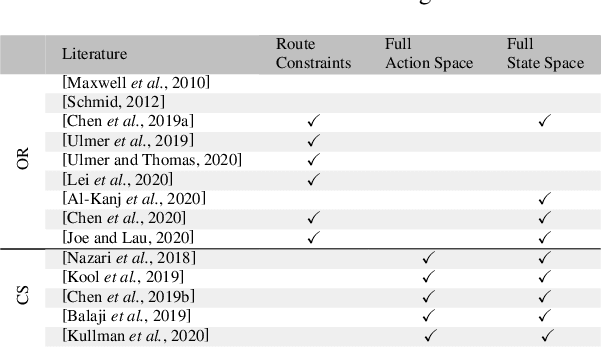
There has been a paradigm-shift in urban logistic services in the last years; demand for real-time, instant mobility and delivery services grows. This poses new challenges to logistic service providers as the underlying stochastic dynamic vehicle routing problems (SDVRPs) require anticipatory real-time routing actions. Searching the combinatorial action space for efficient routing actions is by itself a complex task of mixed-integer programming (MIP) well-known by the operations research community. This complexity is now multiplied by the challenge of evaluating such actions with respect to their effectiveness given future dynamism and uncertainty, a potentially ideal case for reinforcement learning (RL) well-known by the computer science community. For solving SDVRPs, joint work of both communities is needed, but as we show, essentially non-existing. Both communities focus on their individual strengths leaving potential for improvement. Our survey paper highlights this potential in research originating from both communities. We point out current obstacles in SDVRPs and guide towards joint approaches to overcome them.
Temporally-Coherent Surface Reconstruction via Metric-Consistent Atlases
Apr 14, 2021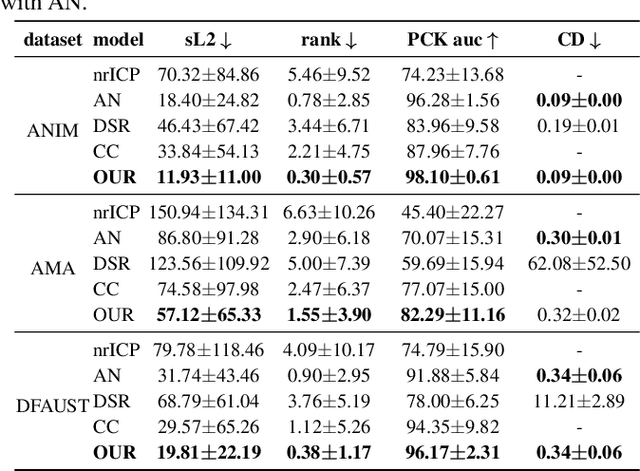
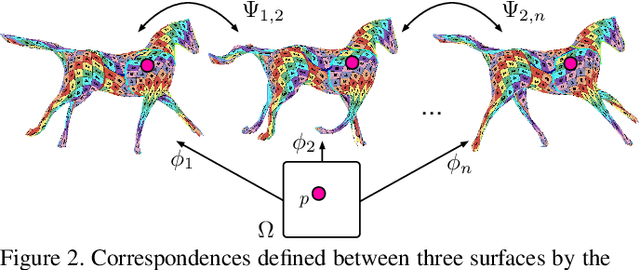

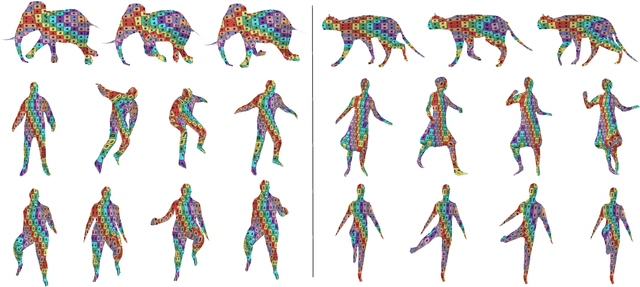
We propose a method for the unsupervised reconstruction of a temporally-coherent sequence of surfaces from a sequence of time-evolving point clouds, yielding dense, semantically meaningful correspondences between all keyframes. We represent the reconstructed surface as an atlas, using a neural network. Using canonical correspondences defined via the atlas, we encourage the reconstruction to be as isometric as possible across frames, leading to semantically-meaningful reconstruction. Through experiments and comparisons, we empirically show that our method achieves results that exceed that state of the art in the accuracy of unsupervised correspondences and accuracy of surface reconstruction.
In-field high throughput grapevine phenotyping with a consumer-grade depth camera
Apr 14, 2021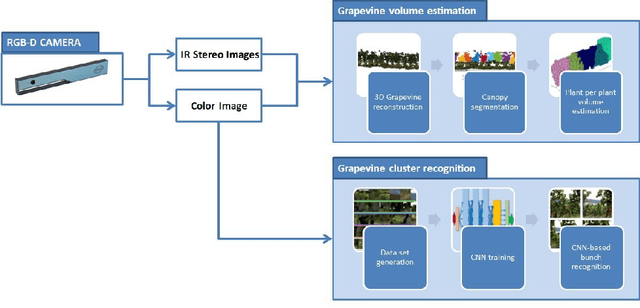


Plant phenotyping, that is, the quantitative assessment of plant traits including growth, morphology, physiology, and yield, is a critical aspect towards efficient and effective crop management. Currently, plant phenotyping is a manually intensive and time consuming process, which involves human operators making measurements in the field, based on visual estimates or using hand-held devices. In this work, methods for automated grapevine phenotyping are developed, aiming to canopy volume estimation and bunch detection and counting. It is demonstrated that both measurements can be effectively performed in the field using a consumer-grade depth camera mounted onboard an agricultural vehicle.
Online Hate: Behavioural Dynamics and Relationship with Misinformation
May 28, 2021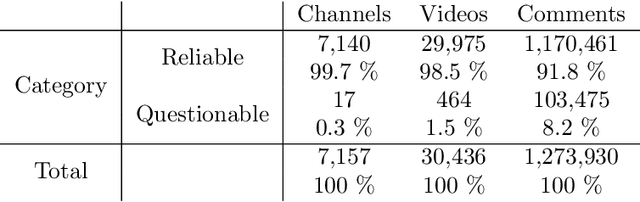
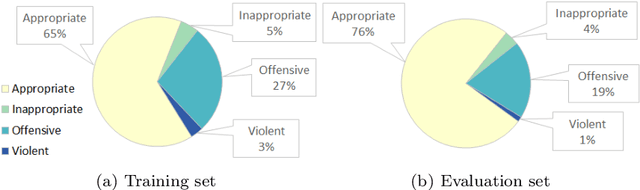

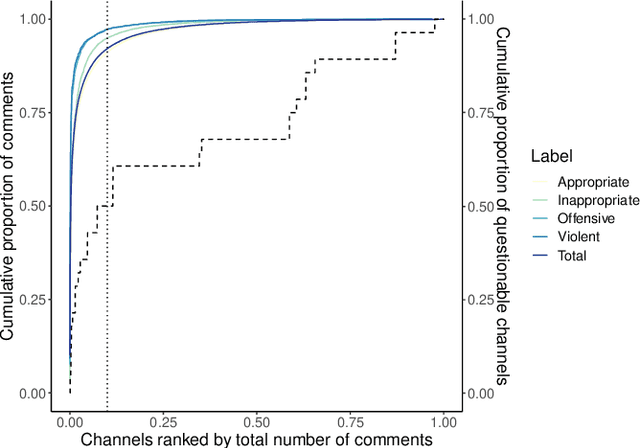
Online debates are often characterised by extreme polarisation and heated discussions among users. The presence of hate speech online is becoming increasingly problematic, making necessary the development of appropriate countermeasures. In this work, we perform hate speech detection on a corpus of more than one million comments on YouTube videos through a machine learning model fine-tuned on a large set of hand-annotated data. Our analysis shows that there is no evidence of the presence of "serial haters", intended as active users posting exclusively hateful comments. Moreover, coherently with the echo chamber hypothesis, we find that users skewed towards one of the two categories of video channels (questionable, reliable) are more prone to use inappropriate, violent, or hateful language within their opponents community. Interestingly, users loyal to reliable sources use on average a more toxic language than their counterpart. Finally, we find that the overall toxicity of the discussion increases with its length, measured both in terms of number of comments and time. Our results show that, coherently with Godwin's law, online debates tend to degenerate towards increasingly toxic exchanges of views.
Manipulating SGD with Data Ordering Attacks
Apr 19, 2021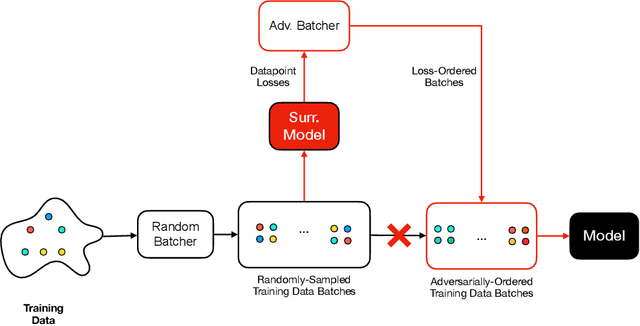
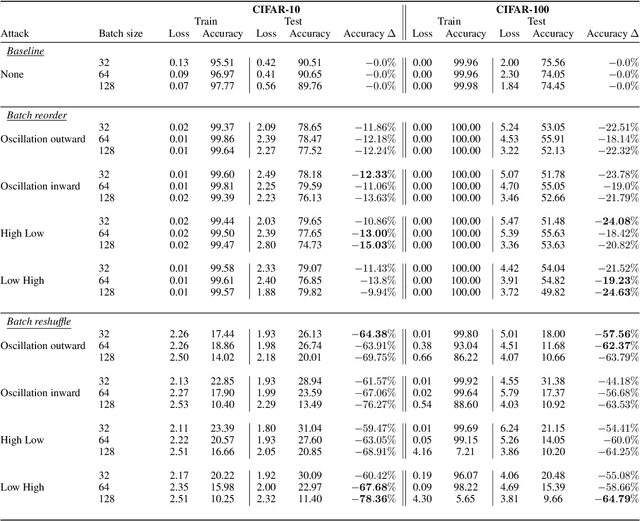
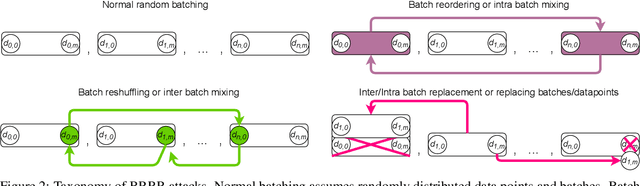
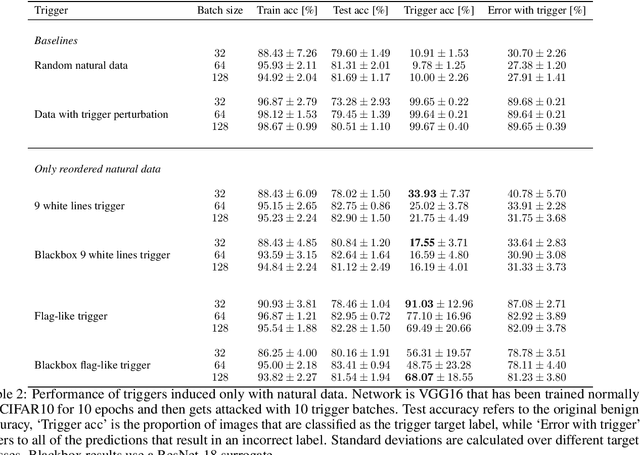
Machine learning is vulnerable to a wide variety of different attacks. It is now well understood that by changing the underlying data distribution, an adversary can poison the model trained with it or introduce backdoors. In this paper we present a novel class of training-time attacks that require no changes to the underlying model dataset or architecture, but instead only change the order in which data are supplied to the model. In particular, an attacker can disrupt the integrity and availability of a model by simply reordering training batches, with no knowledge about either the model or the dataset. Indeed, the attacks presented here are not specific to the model or dataset, but rather target the stochastic nature of modern learning procedures. We extensively evaluate our attacks to find that the adversary can disrupt model training and even introduce backdoors. For integrity we find that the attacker can either stop the model from learning, or poison it to learn behaviours specified by the attacker. For availability we find that a single adversarially-ordered epoch can be enough to slow down model learning, or even to reset all of the learning progress. Such attacks have a long-term impact in that they decrease model performance hundreds of epochs after the attack took place. Reordering is a very powerful adversarial paradigm in that it removes the assumption that an adversary must inject adversarial data points or perturbations to perform training-time attacks. It reminds us that stochastic gradient descent relies on the assumption that data are sampled at random. If this randomness is compromised, then all bets are off.
Angular Path Integration by Projection Filtering with Increment Observations
Feb 18, 2021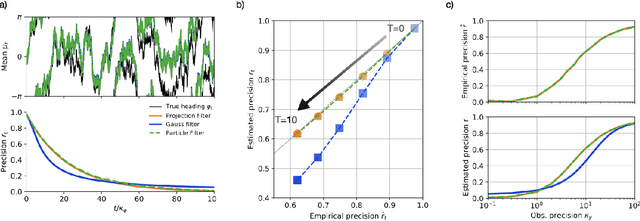
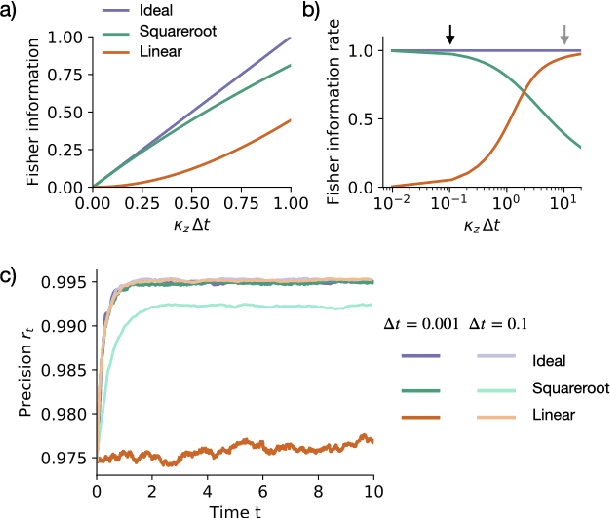
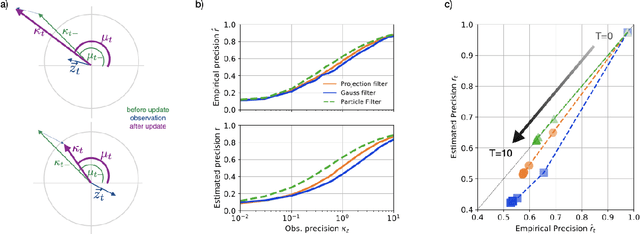
Angular path integration is the ability of a system to estimate its own heading direction from potentially noisy angular velocity (or increment) observations. Despite its importance for robot and animal navigation, current algorithms for angular path integration lack probabilistic descriptions that take into account the reliability of such observations, which is essential for appropriately weighing one's current heading direction estimate against incoming information. In a probabilistic setting, angular path integration can be formulated as a continuous-time nonlinear filtering problem (circular filtering) with increment observations. The circular symmetry of heading direction makes this inference task inherently nonlinear, thereby precluding the use of popular inference algorithms such as Kalman filters and rendering the problem analytically inaccessible. Here, we derive an approximate solution to circular continuous-time filtering, which integrates increment observations while maintaining a fixed representation through both state propagation and observational updates. Specifically, we extend the established projection-filtering method to account for increment observations and apply this framework to the circular filtering problem. We further propose a generative model for continuous-time angular-valued direct observations of the hidden state, which we integrate seamlessly into the projection filter. Applying the resulting scheme to a model of probabilistic angular path integration, we derive an algorithm for circular filtering, which we term the circular Kalman filter. Importantly, this algorithm is analytically accessible, interpretable, and outperforms an alternative filter based on a Gaussian approximation.
Points2Polygons: Context-Based Segmentation from Weak Labels Using Adversarial Networks
Jun 05, 2021
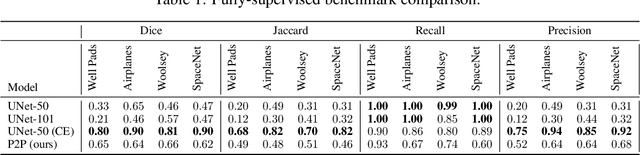
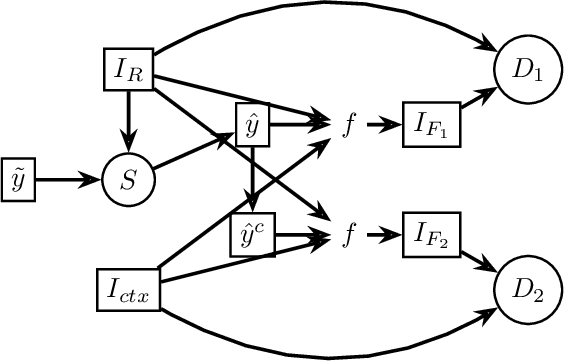
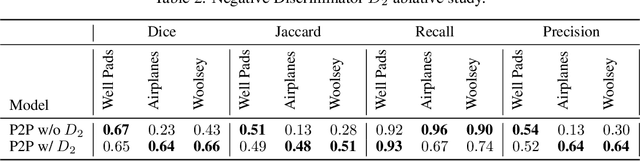
In applied image segmentation tasks, the ability to provide numerous and precise labels for training is paramount to the accuracy of the model at inference time. However, this overhead is often neglected, and recently proposed segmentation architectures rely heavily on the availability and fidelity of ground truth labels to achieve state-of-the-art accuracies. Failure to acknowledge the difficulty in creating adequate ground truths can lead to an over-reliance on pre-trained models or a lack of adoption in real-world applications. We introduce Points2Polygons (P2P), a model which makes use of contextual metric learning techniques that directly addresses this problem. Points2Polygons performs well against existing fully-supervised segmentation baselines with limited training data, despite using lightweight segmentation models (U-Net with a ResNet18 backbone) and having access to only weak labels in the form of object centroids and no pre-training. We demonstrate this on several different small but non-trivial datasets. We show that metric learning using contextual data provides key insights for self-supervised tasks in general, and allow segmentation models to easily generalize across traditionally label-intensive domains in computer vision.
Educational Robotics in Online Distance Learning: An Experience from Primary School
May 20, 2021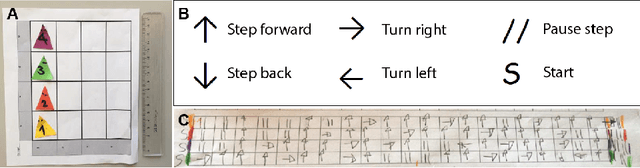
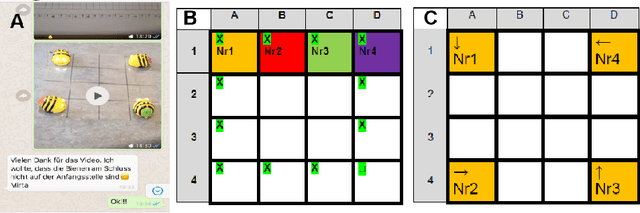
Temporary school closures caused by the Covid-19 pandemic have posed new challenges for many teachers and students worldwide. Especially the abrupt shift to online distance learning posed many obstacles to be overcome and it particularly complicated the implementation of Educational Robotics activities. Such activities usually comprise a variety of different learning artifacts, which were not accessible to many students during the period of school closure. Moreover, online distance learning considerably limits the possibilities for students to interact with their peers and teachers. In an attempt to address these issues, this work presents the development of an Educational Robotics activity particularly conceived for online distance learning in primary school. The devised activities are based on pen and paper approaches that are complemented by commonly used social media to facilitate communication and collaboration. They were proposed to 13 students, as a way to continue ER activities in online distance learning over the time period of four weeks.