 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semantic Communications in Networked Systems
Mar 09, 2021
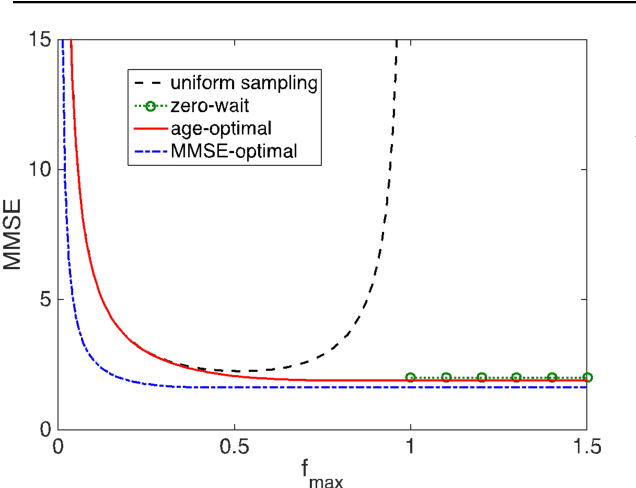
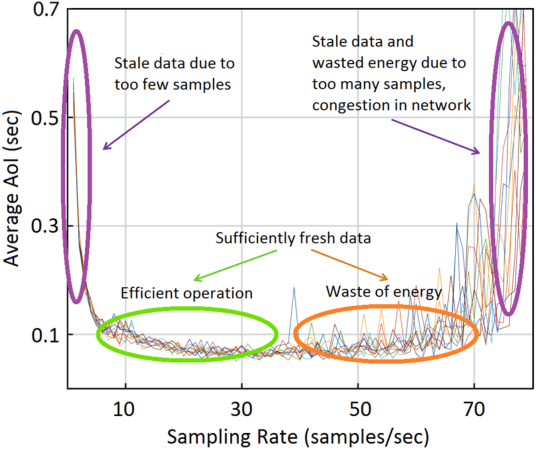
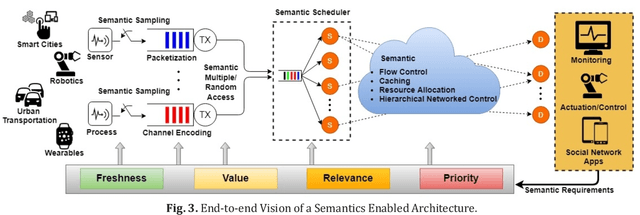
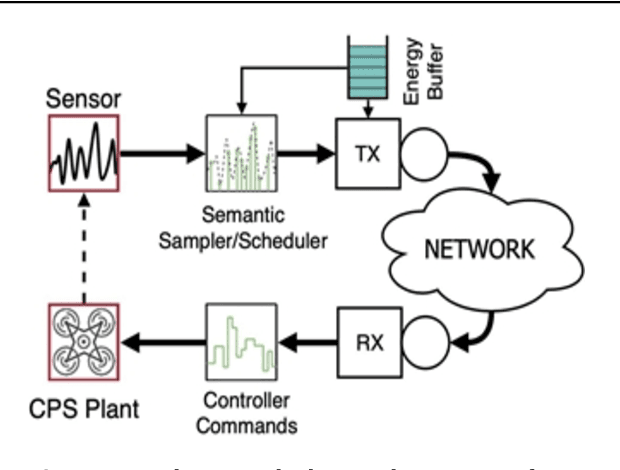
We present our vision for a departure from the established way of architecting and assessing communication networks, by incorporating the semantics of information for communications and control in networked systems. We define semantics of information, not as the meaning of the messages, but as their significance, possibly within a real time constraint, relative to the purpose of the data exchange. We argue that research efforts must focus on laying the theoretical foundations of a redesign of the entire process of information generation, transmission and usage in unison by developing: advanced semantic metrics for communications and control systems; an optimal sampling theory combining signal sparsity and semantics, for real-time prediction, reconstruction and control under communication constraints and delays; semantic compressed sensing techniques for decision making and inference directly in the compressed domain; semantic-aware data generation, channel coding, feedback, multiple and random access schemes that reduce the volume of data and the energy consumption, increasing the number of supportable devices.
Identifying Linked Fraudulent Activities Using GraphConvolution Network
Jun 05, 2021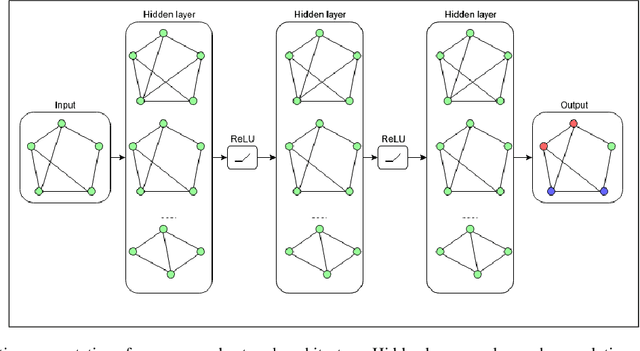


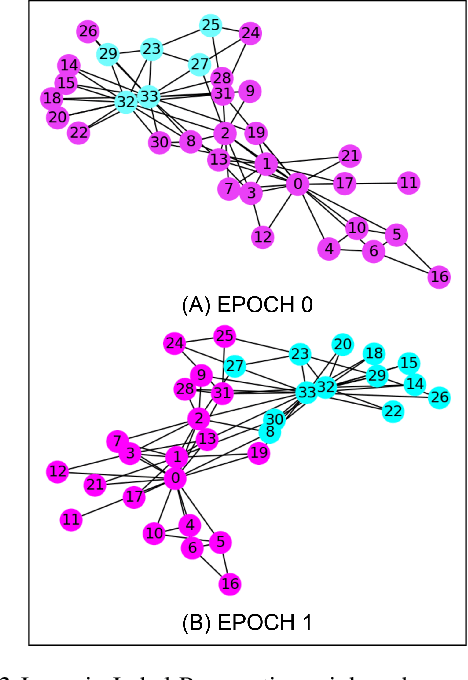
In this paper, we present a novel approach to identify linked fraudulent activities or actors sharing similar attributes, using Graph Convolution Network (GCN). These linked fraudulent activities can be visualized as graphs with abstract concepts like relationships and interactions, which makes GCNs an ideal solution to identify the graph edges which serve as links between fraudulent nodes. Traditional approaches like community detection require strong links between fraudulent attempts like shared attributes to find communities and the supervised solutions require large amount of training data which may not be available in fraud scenarios and work best to provide binary separation between fraudulent and non fraudulent activities. Our approach overcomes the drawbacks of traditional methods as GCNs simply learn similarities between fraudulent nodes to identify clusters of similar attempts and require much smaller dataset to learn. We demonstrate our results on linked accounts with both strong and weak links to identify fraud rings with high confidence. Our results outperform label propagation community detection and supervised GBTs algorithms in terms of solution quality and computation time.
Semantic Journeys: Quantifying Change in Emoji Meaning from 2012-2018
May 04, 2021
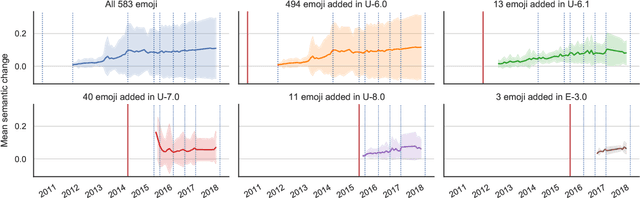
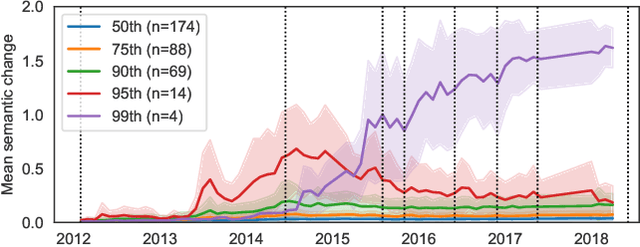

The semantics of emoji has, to date, been considered from a static perspective. We offer the first longitudinal study of how emoji semantics changes over time, applying techniques from computational linguistics to six years of Twitter data. We identify five patterns in emoji semantic development and find evidence that the less abstract an emoji is, the more likely it is to undergo semantic change. In addition, we analyse select emoji in more detail, examining the effect of seasonality and world events on emoji semantics. To aid future work on emoji and semantics, we make our data publicly available along with a web-based interface that anyone can use to explore semantic change in emoji.
Non-stationary Linear Bandits Revisited
Mar 09, 2021
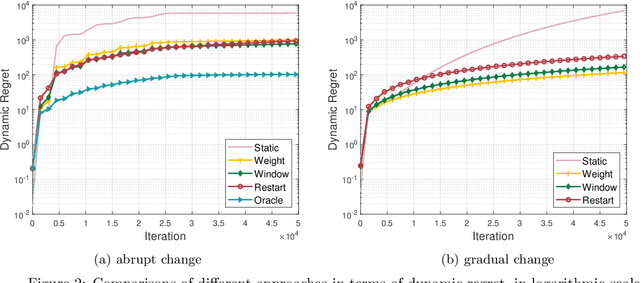
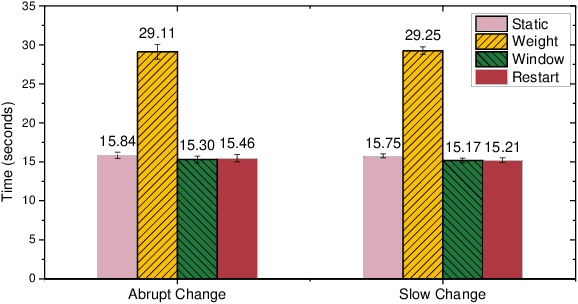
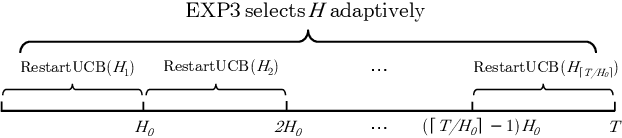
In this note, we revisit non-stationary linear bandits, a variant of stochastic linear bandits with a time-varying underlying regression parameter. Existing studies develop various algorithms and show that they enjoy an $\widetilde{O}(T^{2/3}(1+P_T)^{1/3})$ dynamic regret, where $T$ is the time horizon and $P_T$ is the path-length that measures the fluctuation of the evolving unknown parameter. However, we discover that a serious technical flaw makes the argument ungrounded. We revisit the analysis and present a fix. Without modifying original algorithms, we can prove an $\widetilde{O}(T^{3/4}(1+P_T)^{1/4})$ dynamic regret for these algorithms, slightly worse than the rate as was anticipated. We also show some impossibility results for the key quantity concerned in the regret analysis. Note that the above dynamic regret guarantee requires an oracle knowledge of the path-length $P_T$. Combining the bandit-over-bandit mechanism, we can also achieve the same guarantee in a parameter-free way.
Noise Reduction in X-ray Photon Correlation Spectroscopy with Convolutional Neural Networks Encoder-Decoder Models
Feb 07, 2021



Like other experimental techniques, X-ray Photon Correlation Spectroscopy is a subject to various kinds of noise. Random and correlated fluctuations and heterogeneities can be present in a two-time correlation function and obscure the information about the intrinsic dynamics of a sample. Simultaneously addressing the disparate origins of noise in the experimental data is challenging. We propose a computational approach for improving the signal-to-noise ratio in two-time correlation functions that is based on Convolutional Neural Network Encoder-Decoder (CNN-ED) models. Such models extract features from an image via convolutional layers, project them to a low dimensional space and then reconstruct a clean image from this reduced representation via transposed convolutional layers. Not only are ED models a general tool for random noise removal, but their application to low signal-to-noise data can enhance the data quantitative usage since they are able to learn the functional form of the signal. We demonstrate that the CNN-ED models trained on real-world experimental data help to effectively extract equilibrium dynamics parameters from two-time correlation functions, containing statistical noise and dynamic heterogeneities. Strategies for optimizing the models performance and their applicability limits are discussed.
TEALS: Time-aware Text Embedding Approach to Leverage Subgraphs
Jul 06, 2019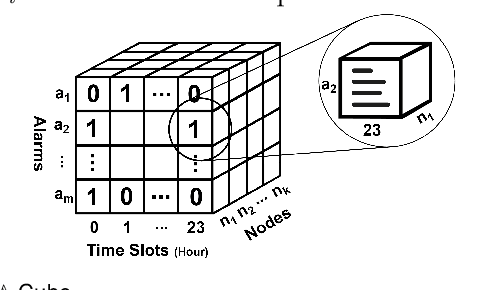
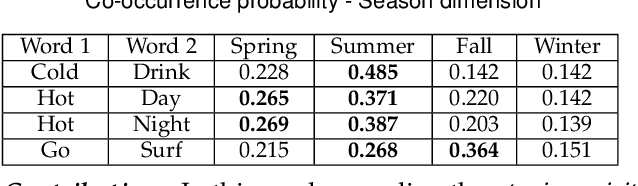
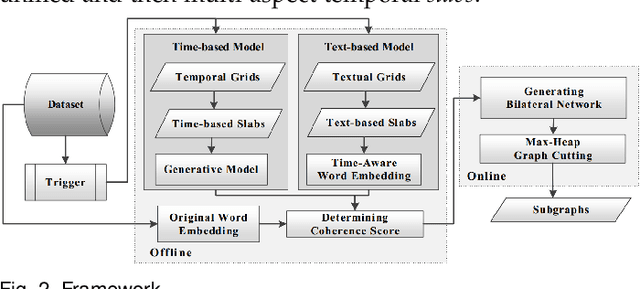
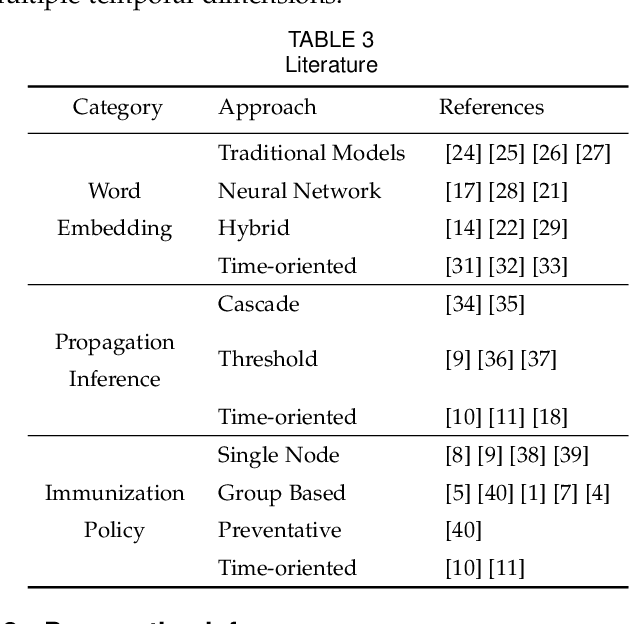
Given a graph over which the contagions (e.g. virus, gossip) propagate, leveraging subgraphs with highly correlated nodes is beneficial to many applications. Yet, challenges abound. First, the propagation pattern between a pair of nodes may change in various temporal dimensions. Second, not always the same contagion is propagated. Hence, state-of-the-art text mining approaches ranging from similarity measures to topic-modeling cannot use the textual contents to compute the weights between the nodes. Third, the word-word co-occurrence patterns may differ in various temporal dimensions, which increases the difficulty to employ current word embedding approaches. We argue that inseparable multi-aspect temporal collaborations are inevitably needed to better calculate the correlation metrics in dynamical processes. In this work, we showcase a sophisticated framework that on the one hand, integrates a neural network based time-aware word embedding component that can collectively construct the word vectors through an assembly of infinite latent temporal facets, and on the other hand, uses an elaborate generative model to compute the edge weights through heterogeneous temporal attributes. After computing the intra-nodes weights, we utilize our Max-Heap Graph cutting algorithm to exploit subgraphs. We then validate our model through comprehensive experiments on real-world propagation data. The results show that the knowledge gained from the versatile temporal dynamics is not only indispensable for word embedding approaches but also plays a significant role in the understanding of the propagation behaviors. Finally, we demonstrate that compared with other rivals, our model can dominantly exploit the subgraphs with highly coordinated nodes.
LaplaceNet: A Hybrid Energy-Neural Model for Deep Semi-Supervised Classification
Jun 12, 2021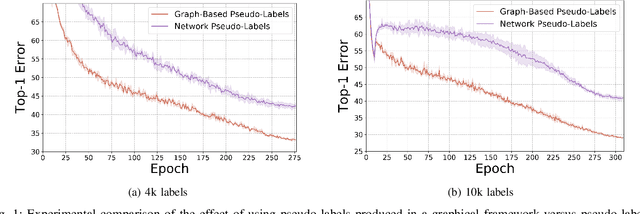
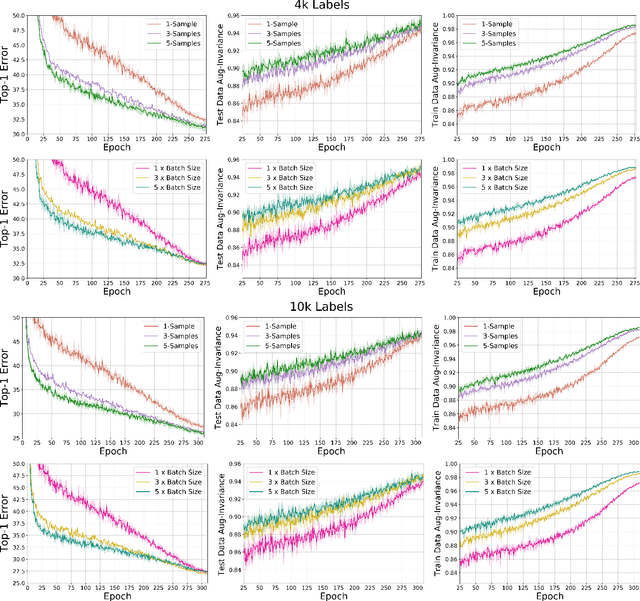

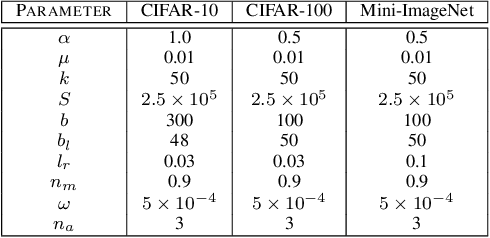
Semi-supervised learning has received a lot of recent attention as it alleviates the need for large amounts of labelled data which can often be expensive, requires expert knowledge and be time consuming to collect. Recent developments in deep semi-supervised classification have reached unprecedented performance and the gap between supervised and semi-supervised learning is ever-decreasing. This improvement in performance has been based on the inclusion of numerous technical tricks, strong augmentation techniques and costly optimisation schemes with multi-term loss functions. We propose a new framework, LaplaceNet, for deep semi-supervised classification that has a greatly reduced model complexity. We utilise a hybrid energy-neural network where graph based pseudo-labels, generated by minimising the graphical Laplacian, are used to iteratively improve a neural-network backbone. Our model outperforms state-of-the-art methods for deep semi-supervised classification, over several benchmark datasets. Furthermore, we consider the application of strong-augmentations to neural networks theoretically and justify the use of a multi-sampling approach for semi-supervised learning. We demonstrate, through rigorous experimentation, that a multi-sampling augmentation approach improves generalisation and reduces the sensitivity of the network to augmentation.
Multi-modal Point-of-Care Diagnostics for COVID-19 Based On Acoustics and Symptoms
Jun 05, 2021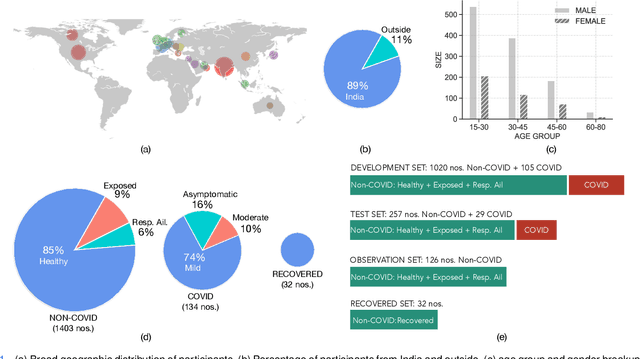
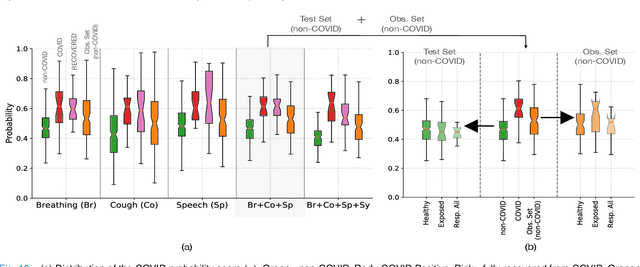
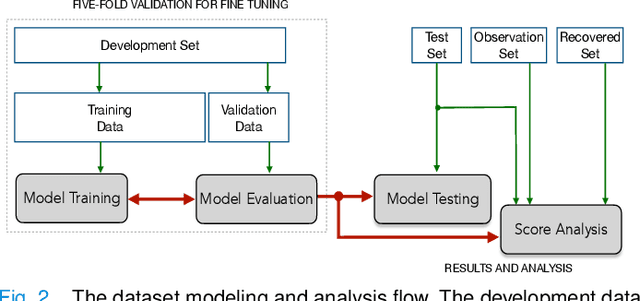
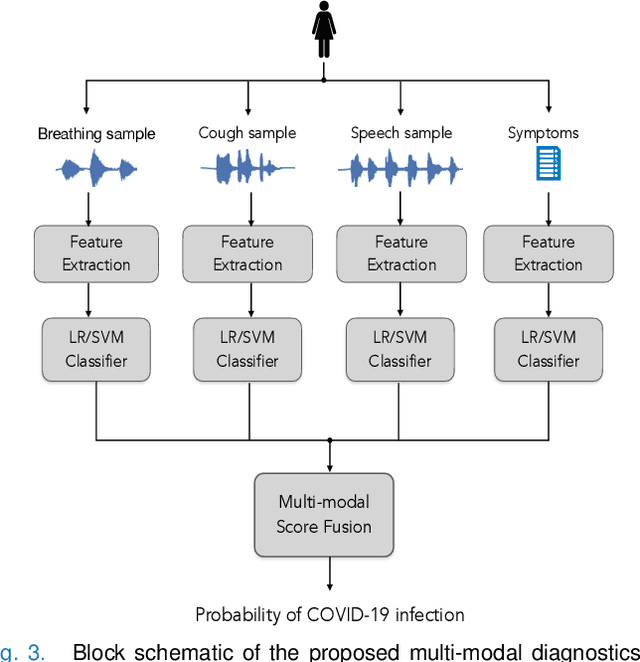
The research direction of identifying acoustic bio-markers of respiratory diseases has received renewed interest following the onset of COVID-19 pandemic. In this paper, we design an approach to COVID-19 diagnostic using crowd-sourced multi-modal data. The data resource, consisting of acoustic signals like cough, breathing, and speech signals, along with the data of symptoms, are recorded using a web-application over a period of ten months. We investigate the use of statistical descriptors of simple time-frequency features for acoustic signals and binary features for the presence of symptoms. Unlike previous works, we primarily focus on the application of simple linear classifiers like logistic regression and support vector machines for acoustic data while decision tree models are employed on the symptoms data. We show that a multi-modal integration of acoustics and symptoms classifiers achieves an area-under-curve (AUC) of 92.40, a significant improvement over any individual modality. Several ablation experiments are also provided which highlight the acoustic and symptom dimensions that are important for the task of COVID-19 diagnostics.
Quantization optimized with respect to the Haar basis
Jan 09, 2021We propose a method of data quantization of finite discrete-time signals which optimizes the error estimate of low frequency Haar coefficients. We also discuss the error/noise bounds of this quantization in the Fourier space. Our result shows one can quantize any discrete-time analog signal with high precision at low frequencies. Our method is deterministic, and it employs no statistical arguments, nor any probabilistic assumptions.
Bird-Area Water-Bodies Dataset (BAWD) and Predictive AI Model for Avian Botulism Outbreak (AVI-BoT)
May 03, 2021

Avian botulism caused by a bacterium, Clostridium botulinum, causes a paralytic disease in birds often leading to high fatality, and is usually diagnosed using molecular techniques. Diagnostic techniques for Avian botulism include: Mouse Bioassay, ELISA, PCR, all of which are time-consuming, laborious and require invasive sample collection from affected sites. In this study, we build a first-ever multi-spectral, remote-sensing imagery based global Bird-Area Water-bodies Dataset (BAWD) (i.e. fused satellite images of water-body sites important for avian fauna) backed by on-ground reporting evidence of outbreaks. In the current version, BAWD covers a total ground area of 904 sq.km from two open source satellite projects (Sentinel and Landsat). BAWD consists of 17 topographically diverse global sites spanning across 4 continents, with locations monitored over a time-span of 3 years (2016-2020). Using BAWD and state-of-the-art deep-learning techniques we propose a first-ever Artificial Intelligence based (AI) model to predict potential outbreak of Avian botulism called AVI-BoT (Aerosol, Visible, Infra-red (NIR/SWIR) and Bands of Thermal). AVI-BoT uses fused multi-spectral satellite images of water-bodies (10-bands) as input to generate a spatial prediction map depicting probability of potential Avian botulism outbreaks. We also train and investigate a simpler (5-band) Causative-Factor model (based on prominent physiological factors reported in literature as conducive for outbreak) to predict Avian botulism. Using AVI-BoT, we achieve a training accuracy of 0.94 and validation accuracy of 0.96 on BAWD, far superior in comparison to our Causative factors model. The proposed technique presents a scale-able, low-cost, non-invasive methodology for continuous monitoring of bird-habitats against botulism outbreaks with the potential of saving valuable fauna lives.