 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dual Optimization for Kolmogorov Model Learning Using Enhanced Gradient Descent
Jul 11, 2021

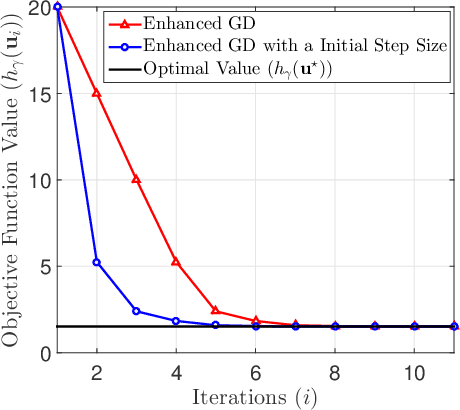
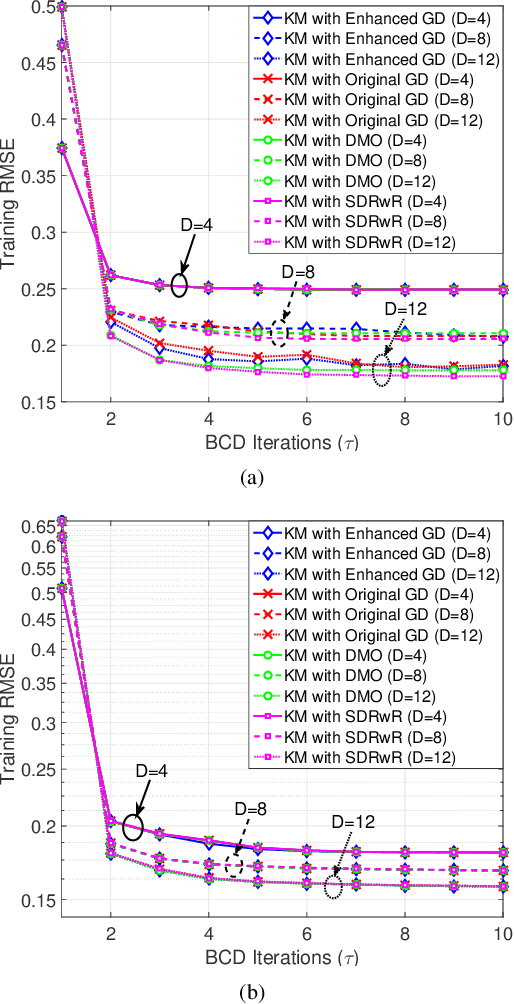
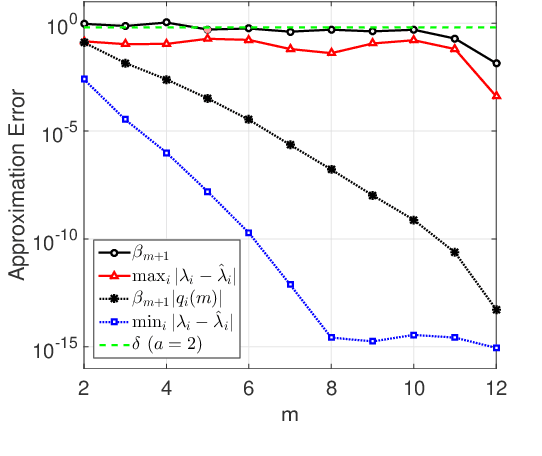
Data representation techniques have made a substantial contribution to advancing data processing and machine learning (ML). Improving predictive power was the focus of previous representation techniques, which unfortunately perform rather poorly on the interpretability in terms of extracting underlying insights of the data. Recently, Kolmogorov model (KM) was studied, which is an interpretable and predictable representation approach to learning the underlying probabilistic structure of a set of random variables. The existing KM learning algorithms using semi-definite relaxation with randomization (SDRwR) or discrete monotonic optimization (DMO) have, however, limited utility to big data applications because they do not scale well computationally. In this paper, we propose a computationally scalable KM learning algorithm, based on the regularized dual optimization combined with enhanced gradient descent (GD) method. To make our method more scalable to large-dimensional problems, we propose two acceleration schemes, namely, eigenvalue decomposition (EVD) elimination strategy and proximal EVD algorithm. Furthermore, a thresholding technique by exploiting the approximation error analysis and leveraging the normalized Minkowski $\ell_1$-norm and its bounds, is provided for the selection of the number of iterations of the proximal EVD algorithm. When applied to big data applications, it is demonstrated that the proposed method can achieve compatible training/prediction performance with significantly reduced computational complexity; roughly two orders of magnitude improvement in terms of the time overhead, compared to the existing KM learning algorithms. Furthermore, it is shown that the accuracy of logical relation mining for interpretability by using the proposed KM learning algorithm exceeds $80\%$.
Spatial resolution of late reverberation in virtual acoustic environments
Jun 30, 2021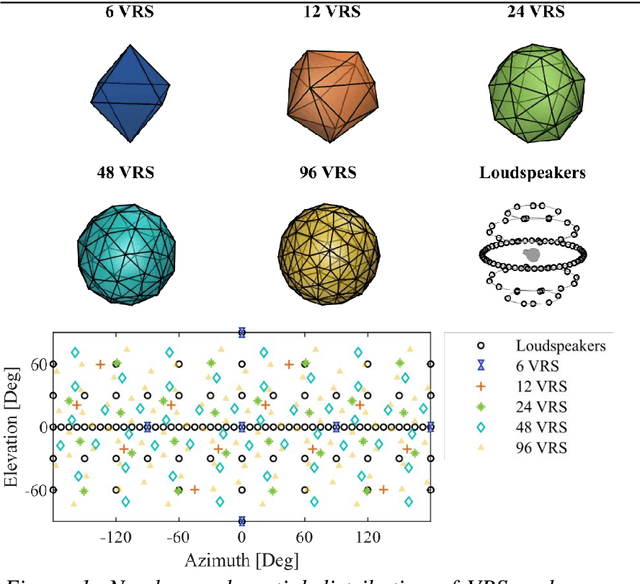
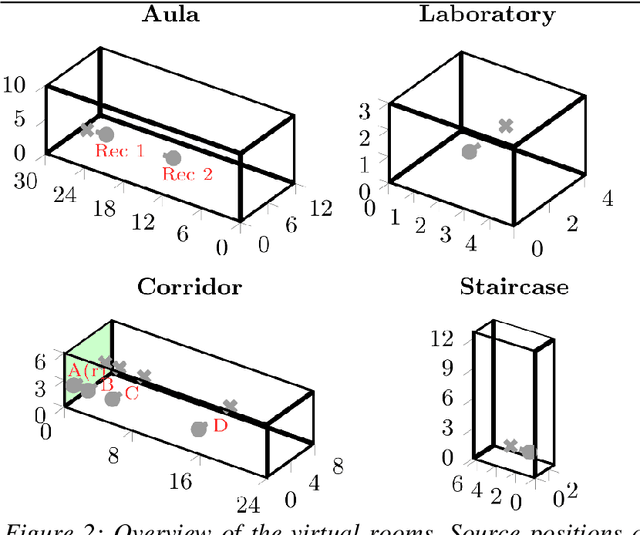
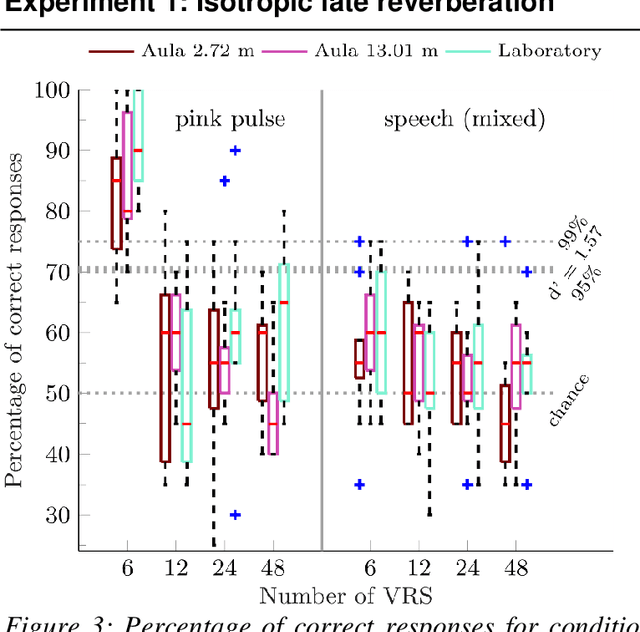
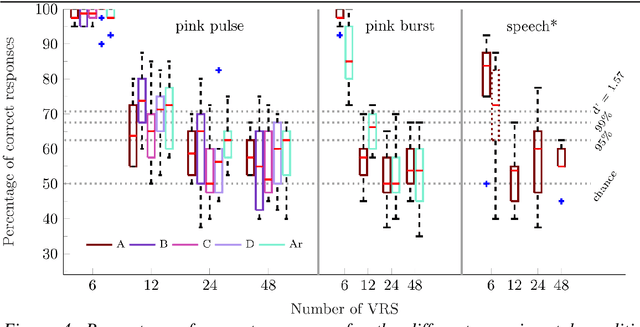
Late reverberation involves the superposition of many sound reflections resulting in a diffuse sound field. Since the spatially resolved perception of individual diffuse reflections is impossible, simplifications can potentially be made for modelling late reverberation in room acoustics simulations with reduced spatial resolution. Such simplifications are desired for interactive, real-time virtual acoustic environments with applications in hearing research and for the evaluation of hearing supportive devices. In this context, the number and spatial arrangement of loudspeakers used for playback additionally affect spatial resolution. The current study assessed the minimum number of spatially evenly distributed virtual late reverberation sources required to perceptually approximate spatially highly resolved isotropic and anisotropic late reverberation and to technically approximate a spherically isotropic diffuse sound field. The spatial resolution of the rendering was systematically reduced by using subsets of the loudspeakers of an 86-channel spherical loudspeaker array in an anechoic chamber. It was tested whether listeners can distinguish lower spatial resolutions for the rendering of late reverberation from the highest achievable spatial resolution in different simulated rooms. Rendering of early reflections was kept fixed. The coherence of the sound field across a pair of microphones at ear and behind-the-ear hearing device distance was assessed to separate the effects of number of virtual sources and loudspeaker array geometry. Results show that between 12 and 24 reverberation sources are required.
Genre determining prediction: Non-standard TAM marking in football language
Jun 30, 2021German and French football language display tense-aspect-mood (TAM) forms which differ from the TAM use in other genres. In German football talk, the present indicative may replace the pluperfect subjunctive. In French reports of football matches, the imperfective past may occur instead of a perfective past tense-aspect form. We argue that the two phenomena share a functional core and are licensed in the same way, which is a direct result of the genre they occur in. More precisely, football match reports adhere to a precise script and specific events are temporally determined in terms of objective time. This allows speakers to exploit a secondary function of TAM forms, namely, they shift the temporal perspective. We argue that it is on the grounds of the genre that comprehenders predict the deviating forms and are also able to decode them. We present various corpus studies where we explore the functioning of these phenomena in order to gain insights into their distribution, grammaticalization and their functioning in discourse. Relevant factors are Aktionsart properties, rhetorical relations and their interaction with other TAM forms. This allows us to discuss coping mechanisms on the part of the comprehender. We broaden our understanding of the phenomena, which have only been partly covered for French and up to now seem to have been ignored in German.
Reliable Prediction Errors for Deep Neural Networks Using Test-Time Dropout
Apr 12, 2019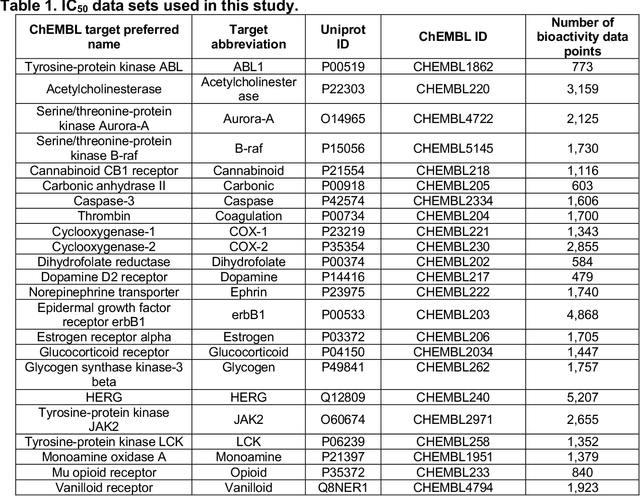
While the use of deep learning in drug discovery is gaining increasing attention, the lack of methods to compute reliable errors in prediction for Neural Networks prevents their application to guide decision making in domains where identifying unreliable predictions is essential, e.g. precision medicine. Here, we present a framework to compute reliable errors in prediction for Neural Networks using Test-Time Dropout and Conformal Prediction. Specifically, the algorithm consists of training a single Neural Network using dropout, and then applying it N times to both the validation and test sets, also employing dropout in this step. Therefore, for each instance in the validation and test sets an ensemble of predictions were generated. The residuals and absolute errors in prediction for the validation set were then used to compute prediction errors for test set instances using Conformal Prediction. We show using 24 bioactivity data sets from ChEMBL 23 that dropout Conformal Predictors are valid (i.e., the fraction of instances whose true value lies within the predicted interval strongly correlates with the confidence level) and efficient, as the predicted confidence intervals span a narrower set of values than those computed with Conformal Predictors generated using Random Forest (RF) models. Lastly, we show in retrospective virtual screening experiments that dropout and RF-based Conformal Predictors lead to comparable retrieval rates of active compounds. Overall, we propose a computationally efficient framework (as only N extra forward passes are required in addition to training a single network) to harness Test-Time Dropout and the Conformal Prediction framework, and to thereby generate reliable prediction errors for deep Neural Networks.
Monocular Depth Estimation through Virtual-world Supervision and Real-world SfM Self-Supervision
Mar 22, 2021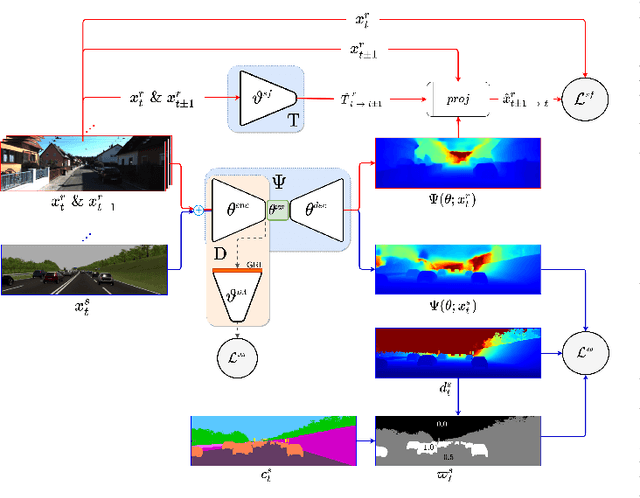
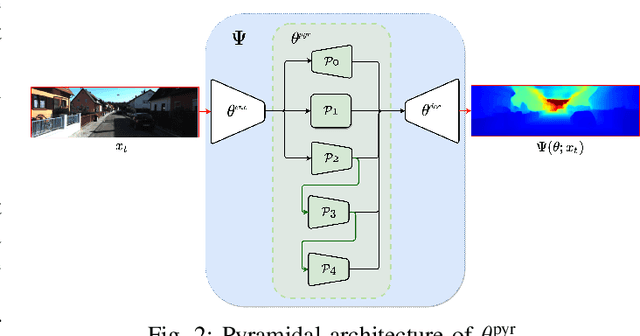
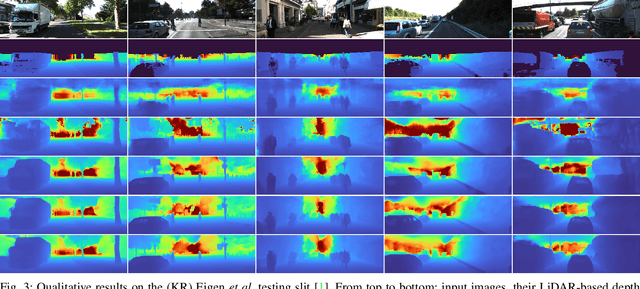
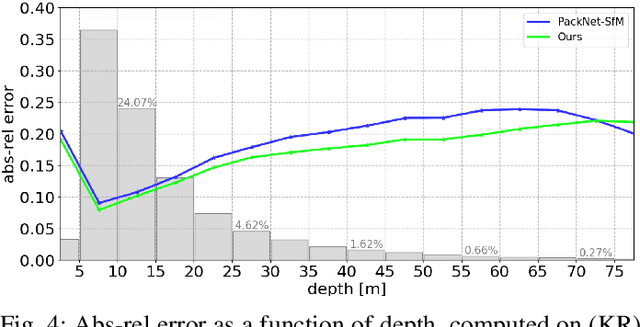
Depth information is essential for on-board perception in autonomous driving and driver assistance. Monocular depth estimation (MDE) is very appealing since it allows for appearance and depth being on direct pixelwise correspondence without further calibration. Best MDE models are based on Convolutional Neural Networks (CNNs) trained in a supervised manner, i.e., assuming pixelwise ground truth (GT). Usually, this GT is acquired at training time through a calibrated multi-modal suite of sensors. However, also using only a monocular system at training time is cheaper and more scalable. This is possible by relying on structure-from-motion (SfM) principles to generate self-supervision. Nevertheless, problems of camouflaged objects, visibility changes, static-camera intervals, textureless areas, and scale ambiguity, diminish the usefulness of such self-supervision. In this paper, we perform monocular depth estimation by virtual-world supervision (MonoDEVS) and real-world SfM self-supervision. We compensate the SfM self-supervision limitations by leveraging virtual-world images with accurate semantic and depth supervision and addressing the virtual-to-real domain gap. Our MonoDEVSNet outperforms previous MDE CNNs trained on monocular and even stereo sequences.
Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers
Jun 09, 2021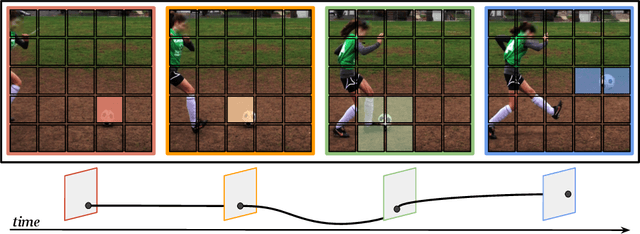

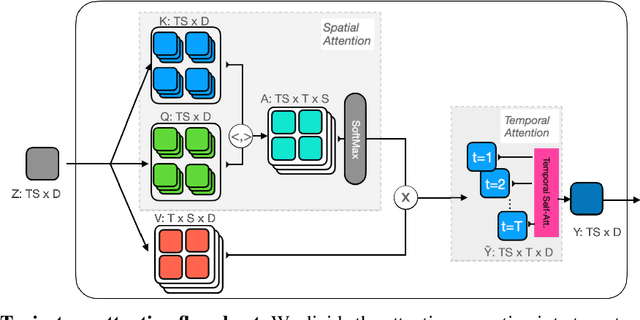
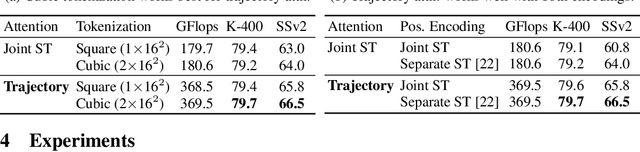
In video transformers, the time dimension is often treated in the same way as the two spatial dimensions. However, in a scene where objects or the camera may move, a physical point imaged at one location in frame $t$ may be entirely unrelated to what is found at that location in frame $t+k$. These temporal correspondences should be modeled to facilitate learning about dynamic scenes. To this end, we propose a new drop-in block for video transformers -- trajectory attention -- that aggregates information along implicitly determined motion paths. We additionally propose a new method to address the quadratic dependence of computation and memory on the input size, which is particularly important for high resolution or long videos. While these ideas are useful in a range of settings, we apply them to the specific task of video action recognition with a transformer model and obtain state-of-the-art results on the Kinetics, Something--Something V2, and Epic-Kitchens datasets. Code and models are available at: https://github.com/facebookresearch/Motionformer
Edge Proposal Sets for Link Prediction
Jun 30, 2021



Graphs are a common model for complex relational data such as social networks and protein interactions, and such data can evolve over time (e.g., new friendships) and be noisy (e.g., unmeasured interactions). Link prediction aims to predict future edges or infer missing edges in the graph, and has diverse applications in recommender systems, experimental design, and complex systems. Even though link prediction algorithms strongly depend on the set of edges in the graph, existing approaches typically do not modify the graph topology to improve performance. Here, we demonstrate how simply adding a set of edges, which we call a \emph{proposal set}, to the graph as a pre-processing step can improve the performance of several link prediction algorithms. The underlying idea is that if the edges in the proposal set generally align with the structure of the graph, link prediction algorithms are further guided towards predicting the right edges; in other words, adding a proposal set of edges is a signal-boosting pre-processing step. We show how to use existing link prediction algorithms to generate effective proposal sets and evaluate this approach on various synthetic and empirical datasets. We find that proposal sets meaningfully improve the accuracy of link prediction algorithms based on both neighborhood heuristics and graph neural networks. Code is available at \url{https://github.com/CUAI/Edge-Proposal-Sets}.
The Wits Intelligent Teaching System: Detecting Student Engagement During Lectures Using Convolutional Neural Networks
May 28, 2021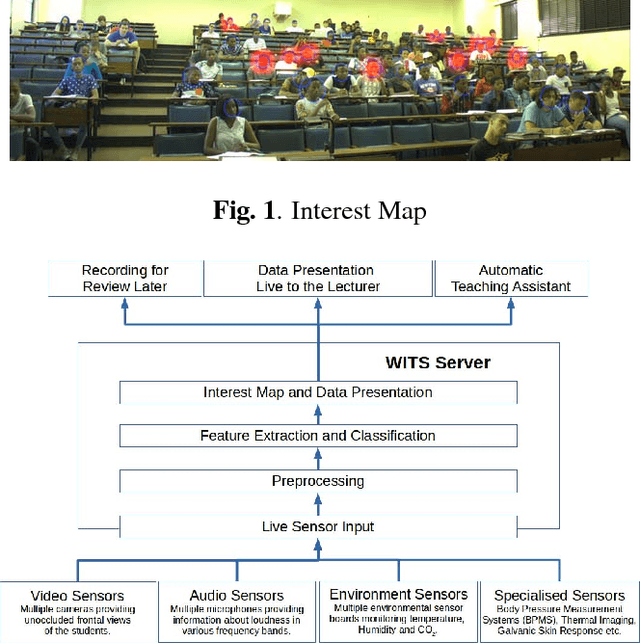
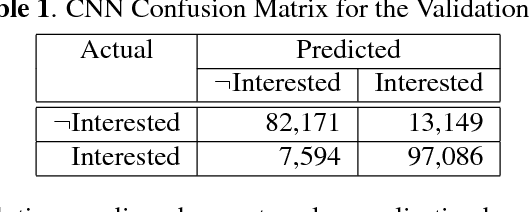
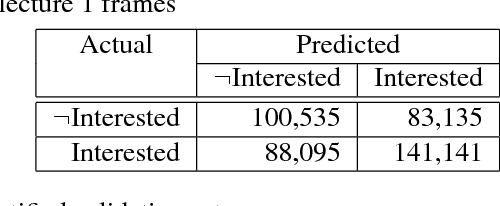

To perform contingent teaching and be responsive to students' needs during class, lecturers must be able to quickly assess the state of their audience. While effective teachers are able to gauge easily the affective state of the students, as class sizes grow this becomes increasingly difficult and less precise. The Wits Intelligent Teaching System (WITS) aims to assist lecturers with real-time feedback regarding student affect. The focus is primarily on recognising engagement or lack thereof. Student engagement is labelled based on behaviour and postures that are common to classroom settings. These proxies are then used in an observational checklist to construct a dataset of engagement upon which a CNN based on AlexNet is successfully trained and which significantly outperforms a Support Vector Machine approach. The deep learning approach provides satisfactory results on a challenging, real-world dataset with significant occlusion, lighting and resolution constraints.
Best-Case Lower Bounds in Online Learning
Jun 23, 2021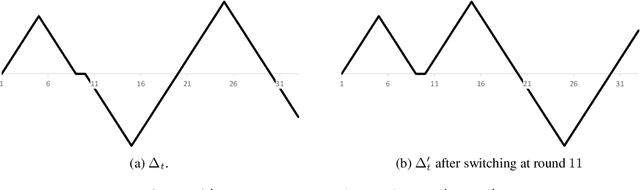
Much of the work in online learning focuses on the study of sublinear upper bounds on the regret. In this work, we initiate the study of best-case lower bounds in online convex optimization, wherein we bound the largest improvement an algorithm can obtain relative to the single best action in hindsight. This problem is motivated by the goal of better understanding the adaptivity of a learning algorithm. Another motivation comes from fairness: it is known that best-case lower bounds are instrumental in obtaining algorithms for decision-theoretic online learning (DTOL) that satisfy a notion of group fairness. Our contributions are a general method to provide best-case lower bounds in Follow The Regularized Leader (FTRL) algorithms with time-varying regularizers, which we use to show that best-case lower bounds are of the same order as existing upper regret bounds: this includes situations with a fixed learning rate, decreasing learning rates, timeless methods, and adaptive gradient methods. In stark contrast, we show that the linearized version of FTRL can attain negative linear regret. Finally, in DTOL with two experts and binary predictions, we fully characterize the best-case sequences, which provides a finer understanding of the best-case lower bounds.
Fast Exploration of Weight Sharing Opportunities for CNN Compression
Feb 02, 2021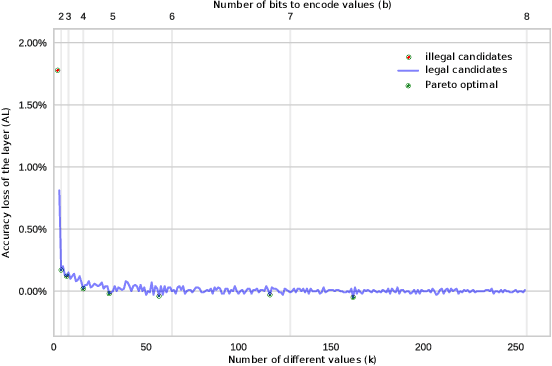
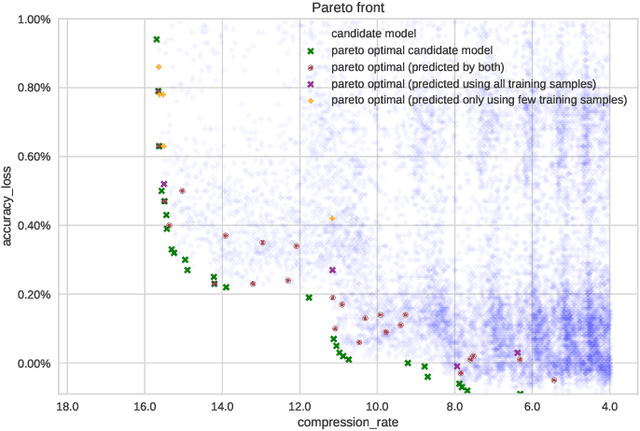
The computational workload involved in Convolutional Neural Networks (CNNs) is typically out of reach for low-power embedded devices. There are a large number of approximation techniques to address this problem. These methods have hyper-parameters that need to be optimized for each CNNs using design space exploration (DSE). The goal of this work is to demonstrate that the DSE phase time can easily explode for state of the art CNN. We thus propose the use of an optimized exploration process to drastically reduce the exploration time without sacrificing the quality of the output.