 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning from Event Cameras with Sparse Spiking Convolutional Neural Networks
Apr 26, 2021
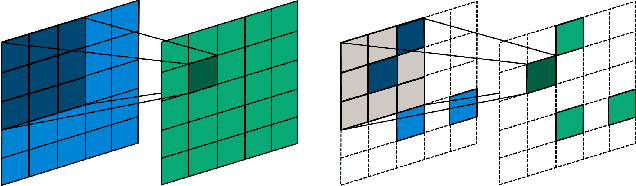
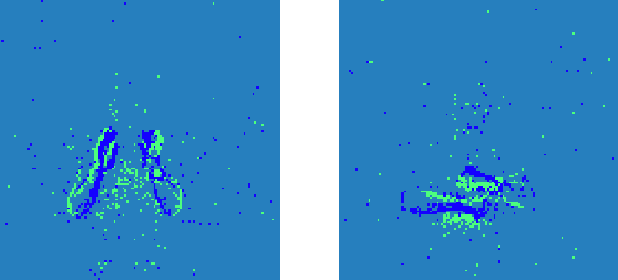
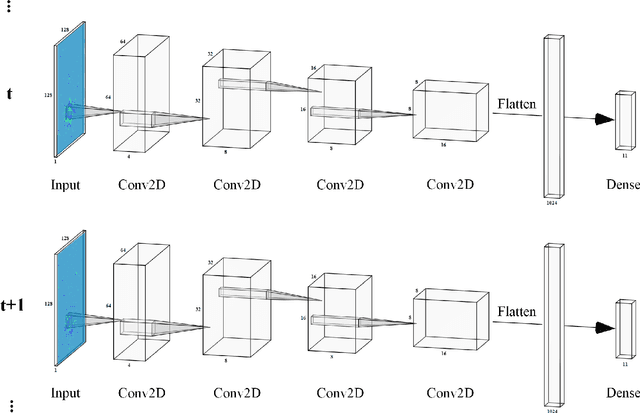
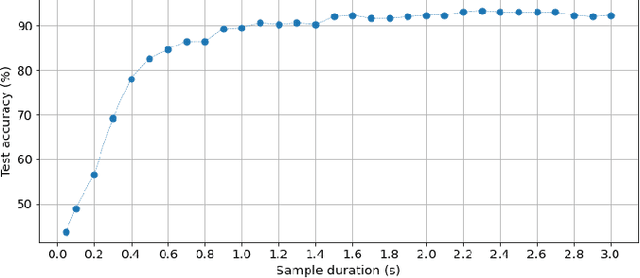
Convolutional neural networks (CNNs) are now the de facto solution for computer vision problems thanks to their impressive results and ease of learning. These networks are composed of layers of connected units called artificial neurons, loosely modeling the neurons in a biological brain. However, their implementation on conventional hardware (CPU/GPU) results in high power consumption, making their integration on embedded systems difficult. In a car for example, embedded algorithms have very high constraints in term of energy, latency and accuracy. To design more efficient computer vision algorithms, we propose to follow an end-to-end biologically inspired approach using event cameras and spiking neural networks (SNNs). Event cameras output asynchronous and sparse events, providing an incredibly efficient data source, but processing these events with synchronous and dense algorithms such as CNNs does not yield any significant benefits. To address this limitation, we use spiking neural networks (SNNs), which are more biologically realistic neural networks where units communicate using discrete spikes. Due to the nature of their operations, they are hardware friendly and energy-efficient, but training them still remains a challenge. Our method enables the training of sparse spiking convolutional neural networks directly on event data, using the popular deep learning framework PyTorch. The performances in terms of accuracy, sparsity and training time on the popular DVS128 Gesture Dataset make it possible to use this bio-inspired approach for the future embedding of real-time applications on low-power neuromorphic hardware.
Scaling Neural Tangent Kernels via Sketching and Random Features
Jun 15, 2021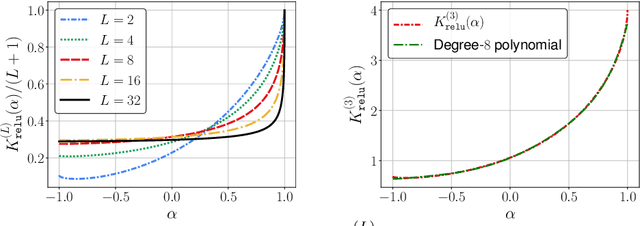

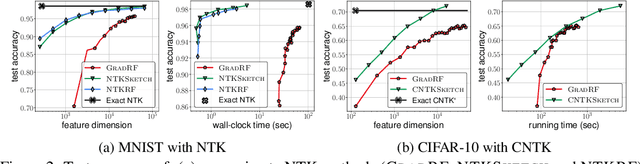
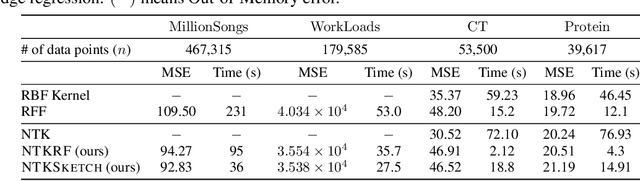
The Neural Tangent Kernel (NTK) characterizes the behavior of infinitely-wide neural networks trained under least squares loss by gradient descent. Recent works also report that NTK regression can outperform finitely-wide neural networks trained on small-scale datasets. However, the computational complexity of kernel methods has limited its use in large-scale learning tasks. To accelerate learning with NTK, we design a near input-sparsity time approximation algorithm for NTK, by sketching the polynomial expansions of arc-cosine kernels: our sketch for the convolutional counterpart of NTK (CNTK) can transform any image using a linear runtime in the number of pixels. Furthermore, we prove a spectral approximation guarantee for the NTK matrix, by combining random features (based on leverage score sampling) of the arc-cosine kernels with a sketching algorithm. We benchmark our methods on various large-scale regression and classification tasks and show that a linear regressor trained on our CNTK features matches the accuracy of exact CNTK on CIFAR-10 dataset while achieving 150x speedup.
Training cascaded networks for speeded decisions using a temporal-difference loss
Feb 19, 2021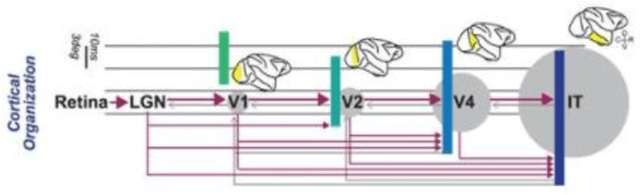
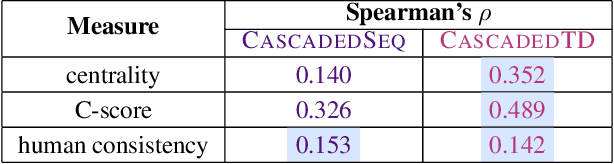
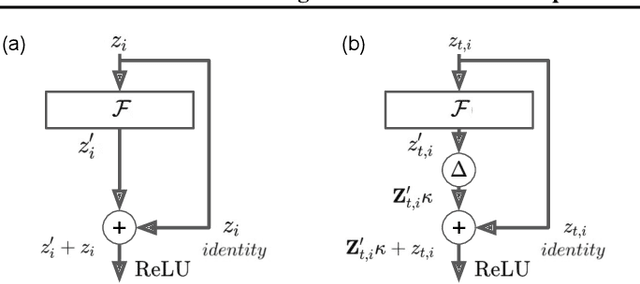

Although deep feedforward neural networks share some characteristics with the primate visual system, a key distinction is their dynamics. Deep nets typically operate in sequential stages wherein each layer fully completes its computation before processing begins in subsequent layers. In contrast, biological systems have cascaded dynamics: information propagates from neurons at all layers in parallel but transmission is gradual over time. In our work, we construct a cascaded ResNet by introducing a propagation delay into each residual block and updating all layers in parallel in a stateful manner. Because information transmitted through skip connections avoids delays, the functional depth of the architecture increases over time and yields a trade off between processing speed and accuracy. We introduce a temporal-difference (TD) training loss that achieves a strictly superior speed accuracy profile over standard losses. The CascadedTD model has intriguing properties, including: typical instances are classified more rapidly than atypical instances; CascadedTD is more robust to both persistent and transient noise than is a conventional ResNet; and the time-varying output trace of CascadedTD provides a signal that can be used by `meta-cognitive' models for OOD detection and to determine when to terminate processing.
A Microarchitecture Implementation Framework for Online Learning with Temporal Neural Networks
Jun 02, 2021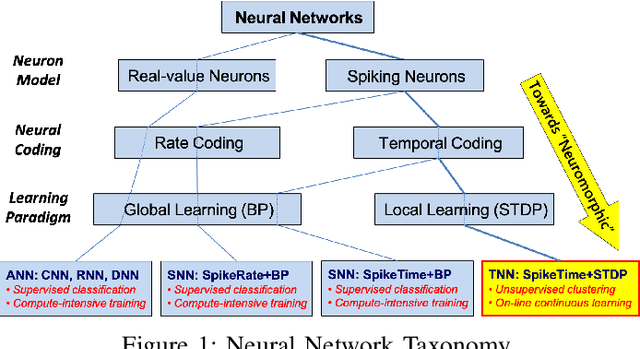

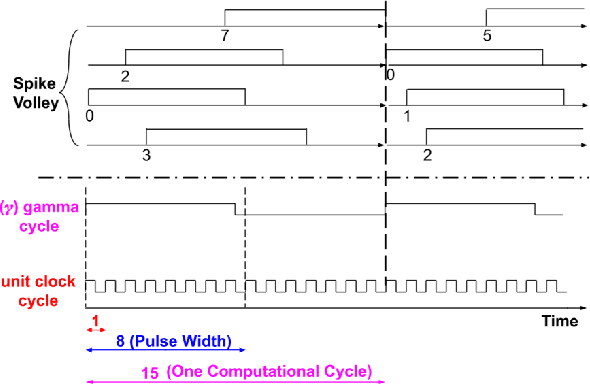
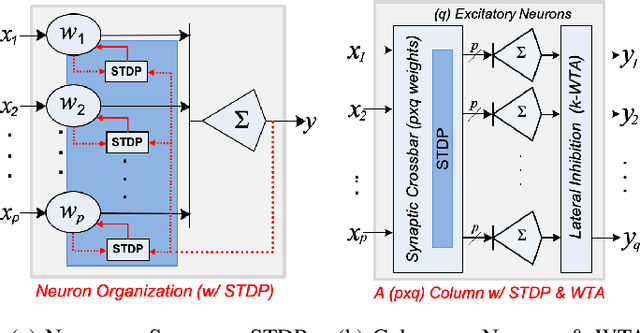
Temporal Neural Networks (TNNs) are spiking neural networks that use time as a resource to represent and process information, similar to the mammalian neocortex. In contrast to compute-intensive deep neural networks that employ separate training and inference phases, TNNs are capable of extremely efficient online incremental/continual learning and are excellent candidates for building edge-native sensory processing units. This work proposes a microarchitecture framework for implementing TNNs using standard CMOS. Gate-level implementations of three key building blocks are presented: 1) multi-synapse neurons, 2) multi-neuron columns, and 3) unsupervised and supervised online learning algorithms based on Spike Timing Dependent Plasticity (STDP). The proposed microarchitecture is embodied in a set of characteristic scaling equations for assessing the gate count, area, delay and power for any TNN design. Post-synthesis results (in 45nm CMOS) for the proposed designs are presented, and their online incremental learning capability is demonstrated.
An Empirical Framework for Domain Generalization in Clinical Settings
Mar 20, 2021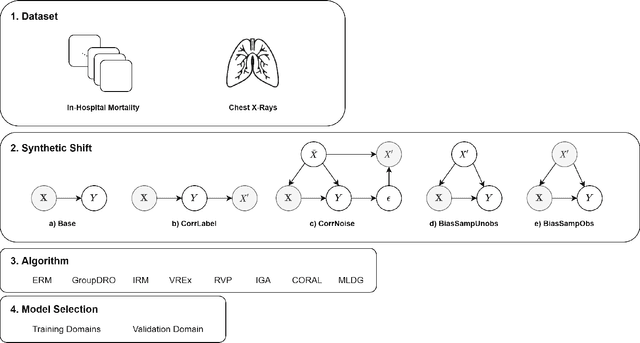

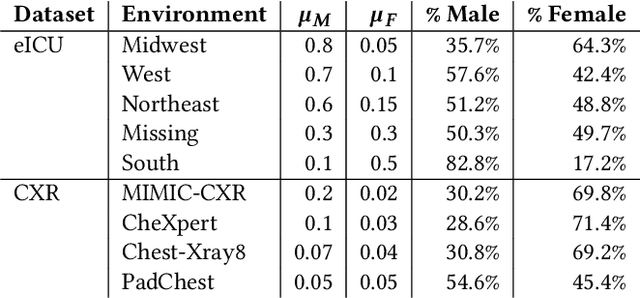
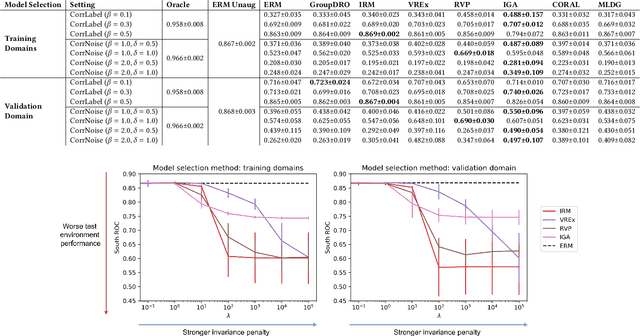
Clinical machine learning models experience significantly degraded performance in datasets not seen during training, e.g., new hospitals or populations. Recent developments in domain generalization offer a promising solution to this problem by creating models that learn invariances across environments. In this work, we benchmark the performance of eight domain generalization methods on multi-site clinical time series and medical imaging data. We introduce a framework to induce synthetic but realistic domain shifts and sampling bias to stress-test these methods over existing non-healthcare benchmarks. We find that current domain generalization methods do not achieve significant gains in out-of-distribution performance over empirical risk minimization on real-world medical imaging data, in line with prior work on general imaging datasets. However, a subset of realistic induced-shift scenarios in clinical time series data exhibit limited performance gains. We characterize these scenarios in detail, and recommend best practices for domain generalization in the clinical setting.
Exploring Periodicity and Interactivity in Multi-Interest Framework for Sequential Recommendation
Jun 07, 2021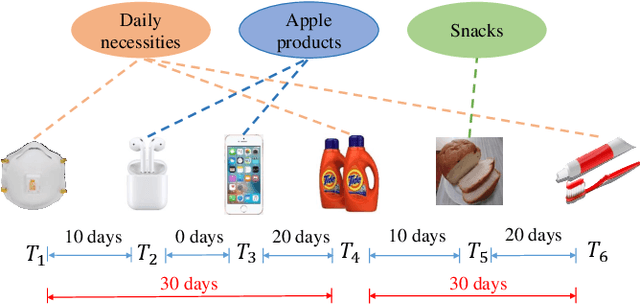

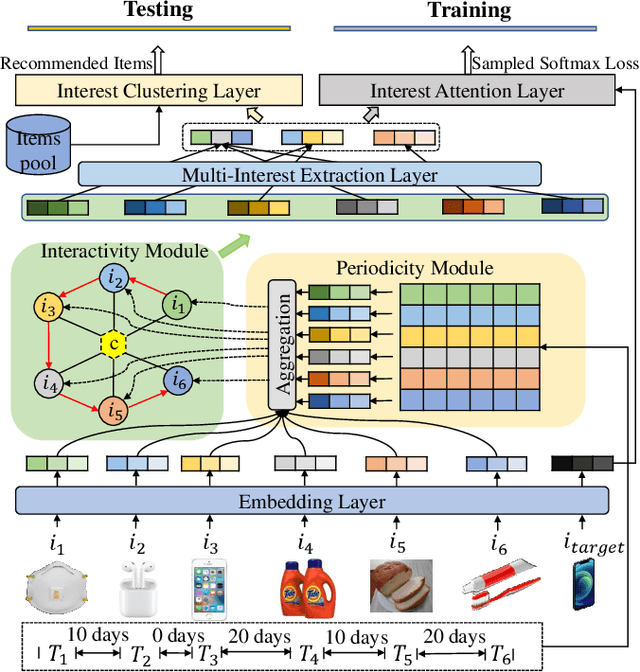

Sequential recommendation systems alleviate the problem of information overload, and have attracted increasing attention in the literature. Most prior works usually obtain an overall representation based on the user's behavior sequence, which can not sufficiently reflect the multiple interests of the user. To this end, we propose a novel method called PIMI to mitigate this issue. PIMI can model the user's multi-interest representation effectively by considering both the periodicity and interactivity in the item sequence. Specifically, we design a periodicity-aware module to utilize the time interval information between user's behaviors. Meanwhile, an ingenious graph is proposed to enhance the interactivity between items in user's behavior sequence, which can capture both global and local item features. Finally, a multi-interest extraction module is applied to describe user's multiple interests based on the obtained item representation. Extensive experiments on two real-world datasets Amazon and Taobao show that PIMI outperforms state-of-the-art methods consistently.
Augmenting Modelers with Semantic Autocompletion of Processes
May 24, 2021

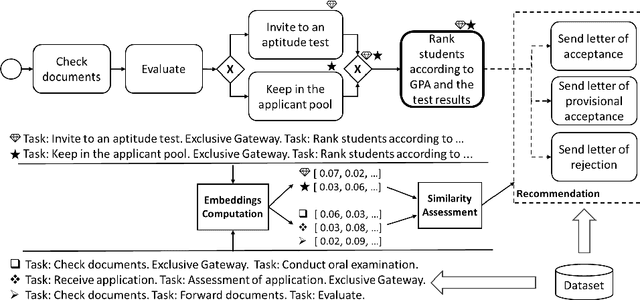

Business process modelers need to have expertise and knowledge of the domain that may not always be available to them. Therefore, they may benefit from tools that mine collections of existing processes and recommend element(s) to be added to a new process that they are constructing. In this paper, we present a method for process autocompletion at design time, that is based on the semantic similarity of sub-processes. By converting sub-processes to textual paragraphs and encoding them as numerical vectors, we can find semantically similar ones, and thereafter recommend the next element. To achieve this, we leverage a state-of-the-art technique for embedding natural language as vectors. We evaluate our approach on open source and proprietary datasets and show that our technique is accurate for processes in various domains.
Towards an Interpretable Latent Space in Structured Models for Video Prediction
Jul 16, 2021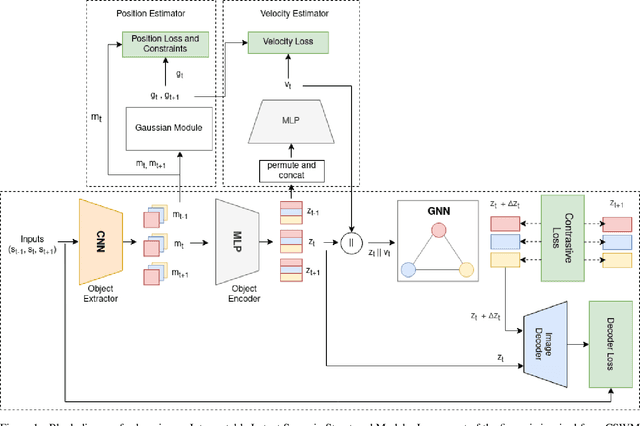
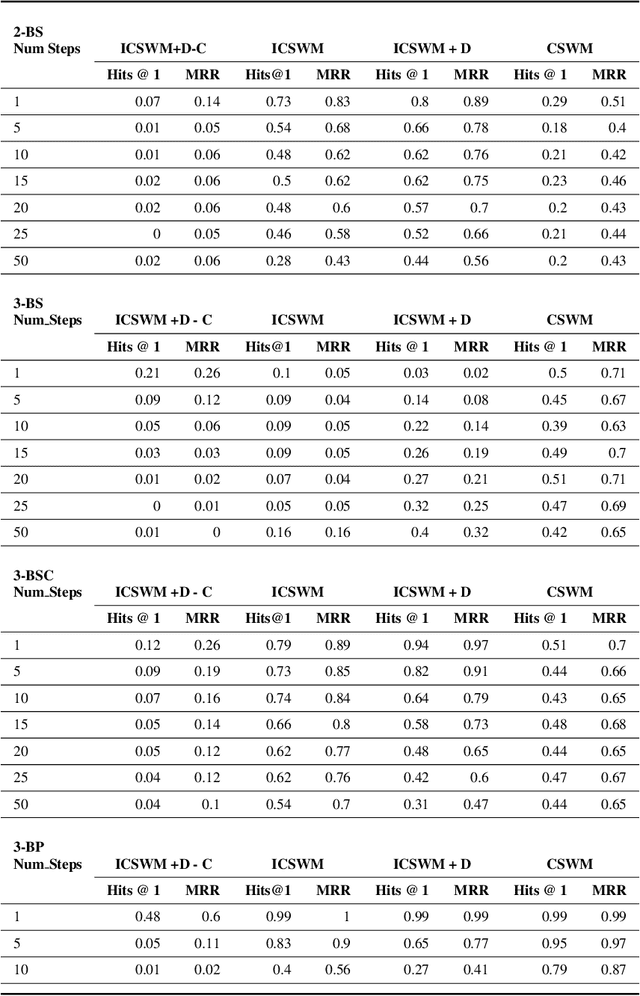
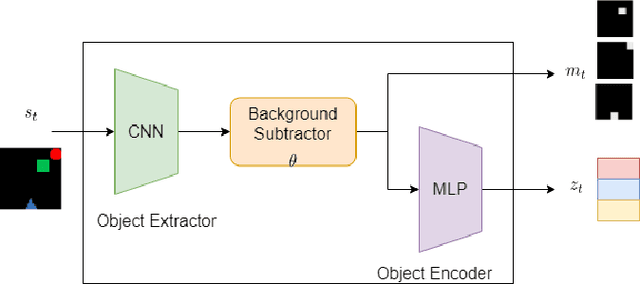
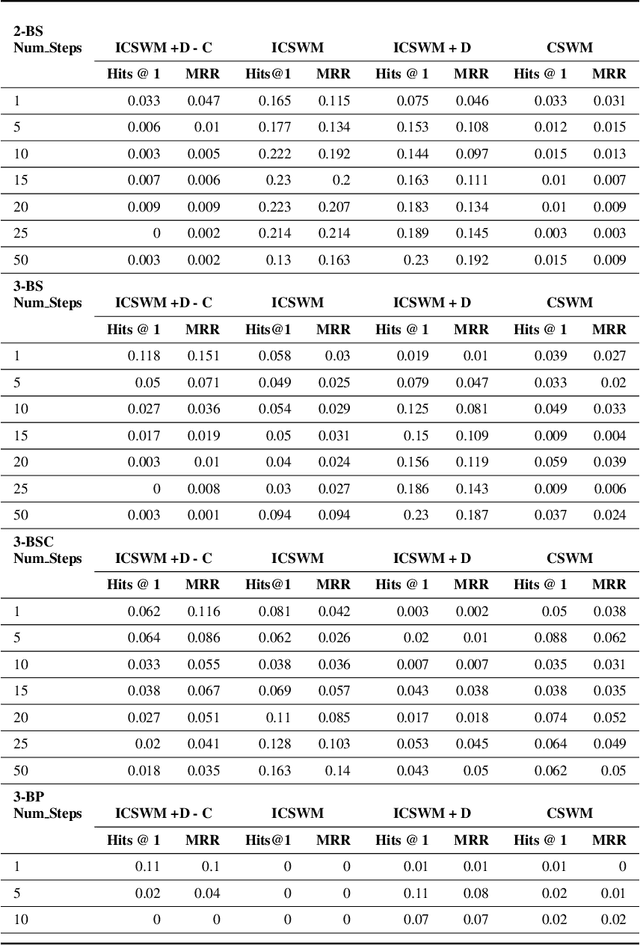
We focus on the task of future frame prediction in video governed by underlying physical dynamics. We work with models which are object-centric, i.e., explicitly work with object representations, and propagate a loss in the latent space. Specifically, our research builds on recent work by Kipf et al. \cite{kipf&al20}, which predicts the next state via contrastive learning of object interactions in a latent space using a Graph Neural Network. We argue that injecting explicit inductive bias in the model, in form of general physical laws, can help not only make the model more interpretable, but also improve the overall prediction of model. As a natural by-product, our model can learn feature maps which closely resemble actual object positions in the image, without having any explicit supervision about the object positions at the training time. In comparison with earlier works \cite{jaques&al20}, which assume a complete knowledge of the dynamics governing the motion in the form of a physics engine, we rely only on the knowledge of general physical laws, such as, world consists of objects, which have position and velocity. We propose an additional decoder based loss in the pixel space, imposed in a curriculum manner, to further refine the latent space predictions. Experiments in multiple different settings demonstrate that while Kipf et al. model is effective at capturing object interactions, our model can be significantly more effective at localising objects, resulting in improved performance in 3 out of 4 domains that we experiment with. Additionally, our model can learn highly intrepretable feature maps, resembling actual object positions.
Efficient PAC Reinforcement Learning in Regular Decision Processes
May 14, 2021



Recently regular decision processes have been proposed as a well-behaved form of non-Markov decision process. Regular decision processes are characterised by a transition function and a reward function that depend on the whole history, though regularly (as in regular languages). In practice both the transition and the reward functions can be seen as finite transducers. We study reinforcement learning in regular decision processes. Our main contribution is to show that a near-optimal policy can be PAC-learned in polynomial time in a set of parameters that describe the underlying decision process. We argue that the identified set of parameters is minimal and it reasonably captures the difficulty of a regular decision process.
Semantic Segmentation with Generative Models: Semi-Supervised Learning and Strong Out-of-Domain Generalization
Apr 12, 2021



Training deep networks with limited labeled data while achieving a strong generalization ability is key in the quest to reduce human annotation efforts. This is the goal of semi-supervised learning, which exploits more widely available unlabeled data to complement small labeled data sets. In this paper, we propose a novel framework for discriminative pixel-level tasks using a generative model of both images and labels. Concretely, we learn a generative adversarial network that captures the joint image-label distribution and is trained efficiently using a large set of unlabeled images supplemented with only few labeled ones. We build our architecture on top of StyleGAN2, augmented with a label synthesis branch. Image labeling at test time is achieved by first embedding the target image into the joint latent space via an encoder network and test-time optimization, and then generating the label from the inferred embedding. We evaluate our approach in two important domains: medical image segmentation and part-based face segmentation. We demonstrate strong in-domain performance compared to several baselines, and are the first to showcase extreme out-of-domain generalization, such as transferring from CT to MRI in medical imaging, and photographs of real faces to paintings, sculptures, and even cartoons and animal faces. Project Page: \url{https://nv-tlabs.github.io/semanticGAN/}