 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Compact pneumatic clutch with integrated stiffness variation and position feedback
Mar 05, 2021
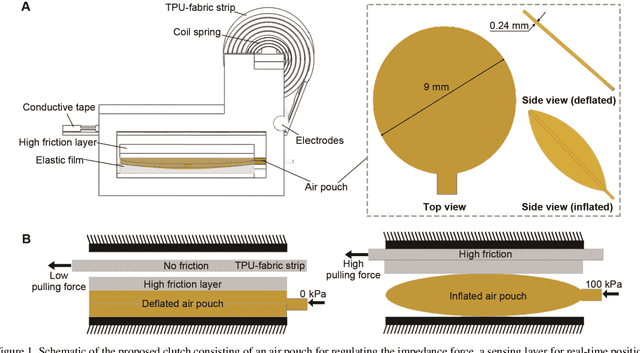
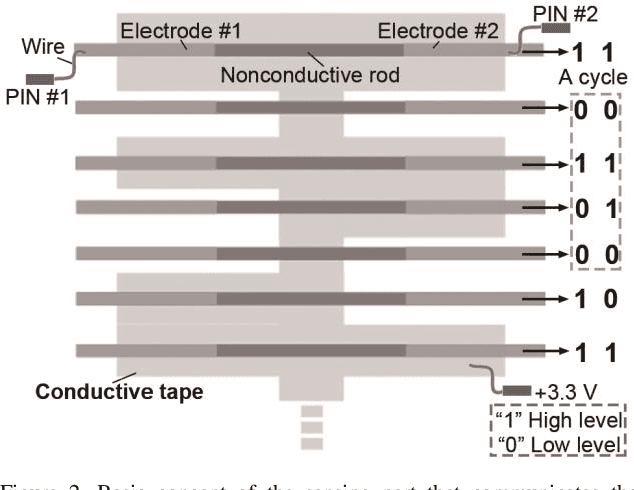
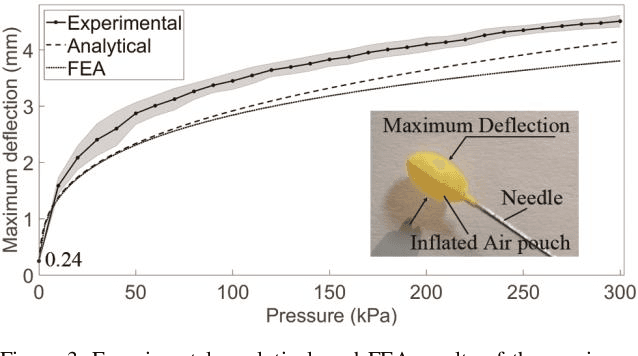
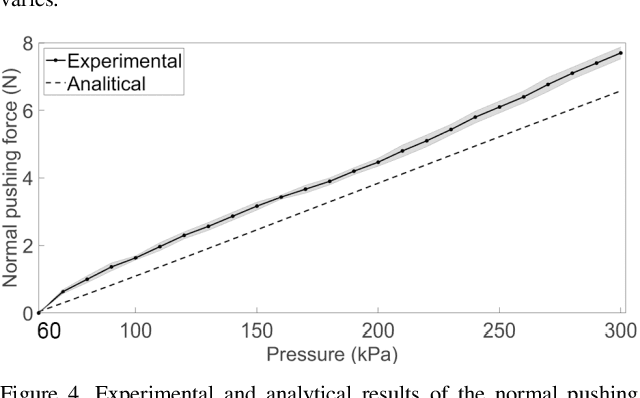
Stiffness variation and real-time position feedback are critical for any robotic system but most importantly for active and wearable devices to interact with the user and environment. Currently, for compact sizes, there is a lack of solutions bringing high-fidelity feedback and maintaining design and functional integrity. In this work, we propose a novel minimal clutch with integrated stiffness variation and real-time position feedback whose performance surpasses conventional jamming solutions. We introduce integrated design, modeling, and verification of the clutch in detail. Preliminary experimental results show the change in impedance force of the clutch is close to 24-fold at the maximum force density of 15.64 N/cm2. We validated the clutch experimentally in (1) enhancing the bending stiffness of a soft actuator to increase a soft manipulator's gripping force by 73%; (2) enabling a soft cylindrical actuator to execute omnidirectional movement; (3) providing real-time position feedback for hand posture detection and impedance force for kinesthetic haptic feedback. This manuscript presents the functional components with a focus on the integrated design methodology, which will have an impact on the development of soft robots and wearable devices.
Exploring Transformers in Emotion Recognition: a comparison of BERT, DistillBERT, RoBERTa, XLNet and ELECTRA
Apr 05, 2021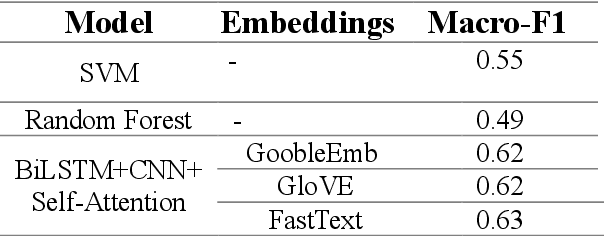

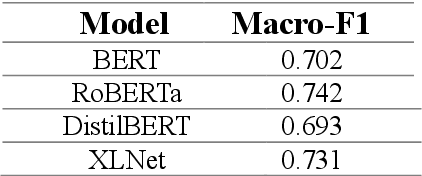
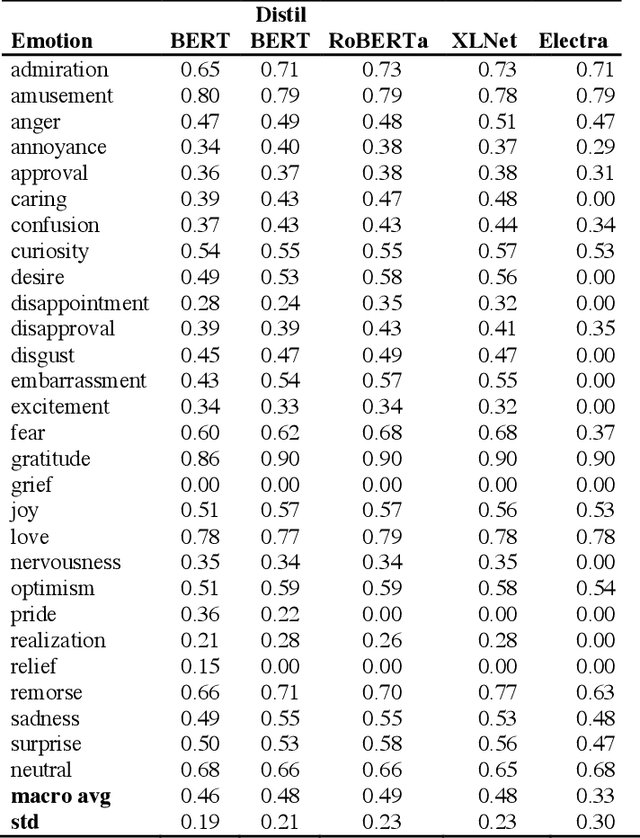
This paper investigates how Natural Language Understanding (NLU) could be applied in Emotion Recognition, a specific task in affective computing. We finetuned different transformers language models (BERT, DistilBERT, RoBERTa, XLNet, and ELECTRA) using a fine-grained emotion dataset and evaluating them in terms of performance (f1-score) and time to complete.
NeuralLog: Natural Language Inference with Joint Neural and Logical Reasoning
Jun 10, 2021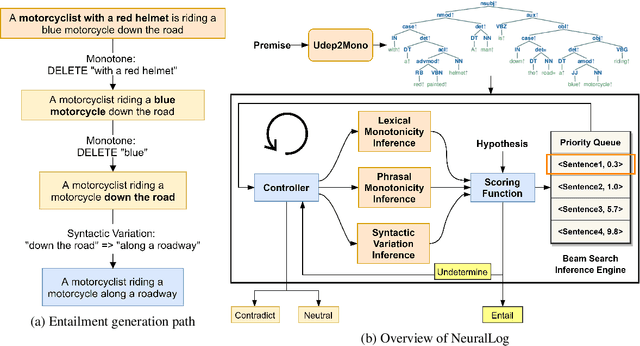
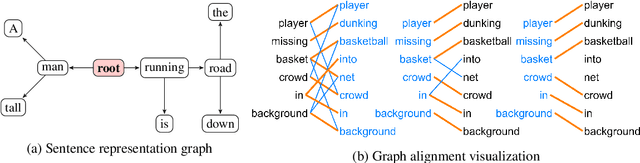

Deep learning (DL) based language models achieve high performance on various benchmarks for Natural Language Inference (NLI). And at this time, symbolic approaches to NLI are receiving less attention. Both approaches (symbolic and DL) have their advantages and weaknesses. However, currently, no method combines them in a system to solve the task of NLI. To merge symbolic and deep learning methods, we propose an inference framework called NeuralLog, which utilizes both a monotonicity-based logical inference engine and a neural network language model for phrase alignment. Our framework models the NLI task as a classic search problem and uses the beam search algorithm to search for optimal inference paths. Experiments show that our joint logic and neural inference system improves accuracy on the NLI task and can achieve state-of-art accuracy on the SICK and MED datasets.
Merging Tasks for Video Panoptic Segmentation
Jul 10, 2021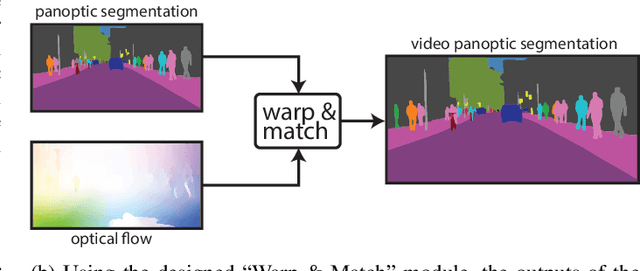
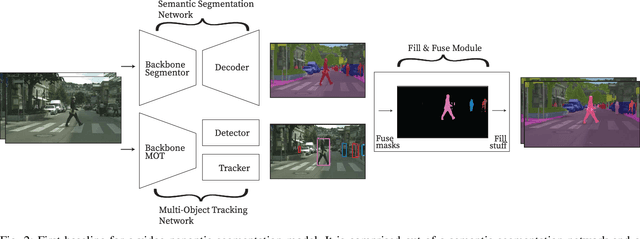
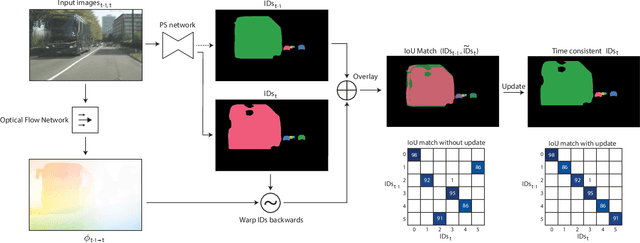

In this paper, the task of video panoptic segmentation is studied and two different methods to solve the task will be proposed. Video panoptic segmentation (VPS) is a recently introduced computer vision task that requires classifying and tracking every pixel in a given video. The nature of this task makes the cost of annotating datasets for it prohibiting. To understand video panoptic segmentation, first, earlier introduced constituent tasks that focus on semantics and tracking separately will be researched. Thereafter, two data-driven approaches which do not require training on a tailored VPS dataset will be selected to solve it. The first approach will show how a model for video panoptic segmentation can be built by heuristically fusing the outputs of a pre-trained semantic segmentation model and a pre-trained multi-object tracking model. This can be desired if one wants to easily extend the capabilities of either model. The second approach will counter some of the shortcomings of the first approach by building on top of a shared neural network backbone with task-specific heads. This network is designed for panoptic segmentation and will be extended by a mask propagation module to link instance masks across time, yielding the video panoptic segmentation format.
Speech is Silver, Silence is Golden: What do ASVspoof-trained Models Really Learn?
Jul 16, 2021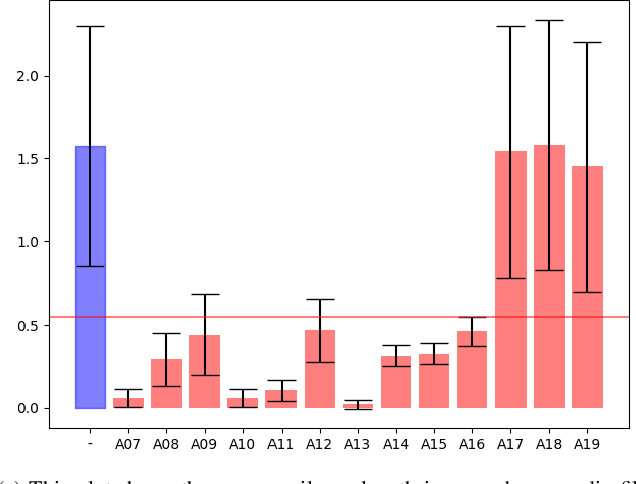
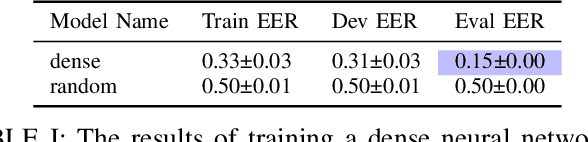
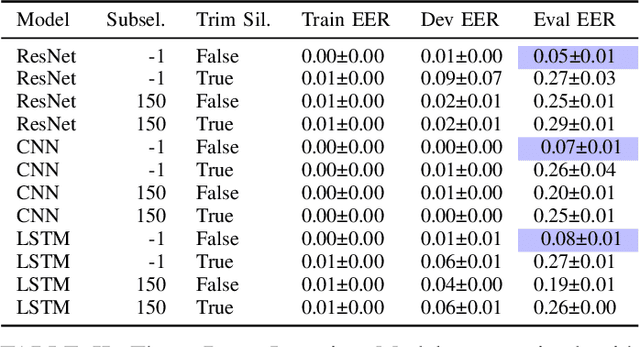
We present our analysis of a significant data artifact in the official 2019/2021 ASVspoof Challenge Dataset. We identify an uneven distribution of silence duration in the training and test splits, which tends to correlate with the target prediction label. Bonafide instances tend to have significantly longer leading and trailing silences than spoofed instances. In this paper, we explore this phenomenon and its impact in depth. We compare several types of models trained on a) only the duration of the leading silence and b) only on the duration of leading and trailing silence. Results show that models trained on only the duration of the leading silence perform particularly well, and achieve up to 85% percent accuracy and an equal error rate (EER) of 0.15 (scale between 0 and 1). At the same time, we observe that trimming silence during pre-processing and then training established antispoofing models using signal-based features leads to comparatively worse performance. In that case, EER increases from 0.03 (with silence) to 0.15 (trimmed silence). Our findings suggest that previous work may, in part, have inadvertently learned thespoof/bonafide distinction by relying on the duration of silence as it appears in the official challenge dataset. We discuss the potential consequences that this has for interpreting system scores in the challenge and discuss how the ASV community may further consider this issue.
Deep-Learned Event Variables for Collider Phenomenology
May 21, 2021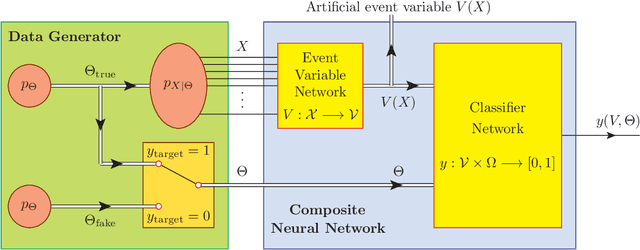
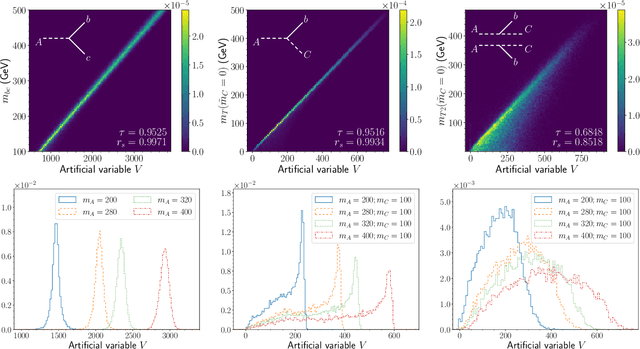
The choice of optimal event variables is crucial for achieving the maximal sensitivity of experimental analyses. Over time, physicists have derived suitable kinematic variables for many typical event topologies in collider physics. Here we introduce a deep learning technique to design good event variables, which are sensitive over a wide range of values for the unknown model parameters. We demonstrate that the neural networks trained with our technique on some simple event topologies are able to reproduce standard event variables like invariant mass, transverse mass, and stransverse mass. The method is automatable, completely general, and can be used to derive sensitive, previously unknown, event variables for other, more complex event topologies.
Towards Multi-Functional 6G Wireless Networks: Integrating Sensing, Communication and Security
Jul 16, 2021
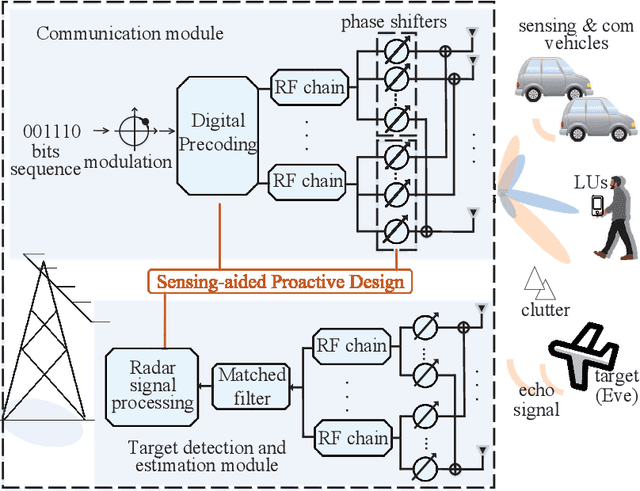
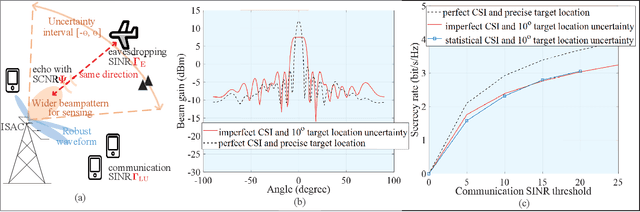
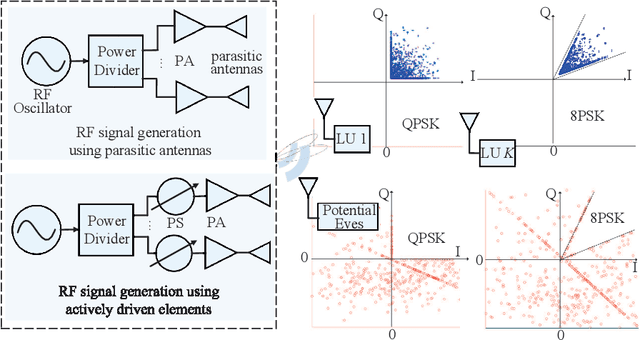
Integrated sensing and communication (ISAC) has recently emerged as a candidate 6G technology, aiming to unify the two key operations of the future network in spectrum/energy/cost efficient way. ISAC involves communicating information to receivers and simultaneously sensing targets, while both operations use the same waveforms, the same transmitter and ultimately the same network infrastructure. Nevertheless, the inclusion of information signalling into the probing waveform for target sensing raises unique and difficult challenges from the perspective of information security. At the same time, the sensing capability incorporated in the ISAC transmission offers unique opportunities to design secure ISAC techniques. This overview paper discusses these unique challenges and opportunities for the next generation of ISAC networks. We first briefly discuss the fundamentals of waveform design for sensing and communication. Then, we detail the challenges and contradictory objectives involved in securing ISAC transmission, along with state-of-the-art approaches to address them. We then identify the new opportunity of using the sensing capability to obtain knowledge of the targets, as an enabling approach against known weaknesses of PHY security. Finally, we illustrate a low-cost secure ISAC architecture, followed by a series of open research topics. This family of sensing-aided secure ISAC techniques brings a new insight on providing information security, with an eye on robust and hardware-constrained designs tailored for low-cost ISAC devices.
Achieving 100X faster simulations of complex biological phenomena by coupling ML to HPC ensembles
Apr 10, 2021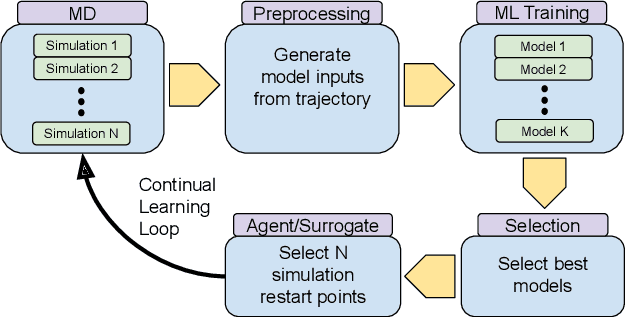
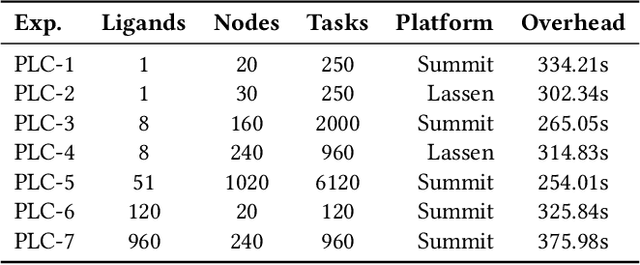
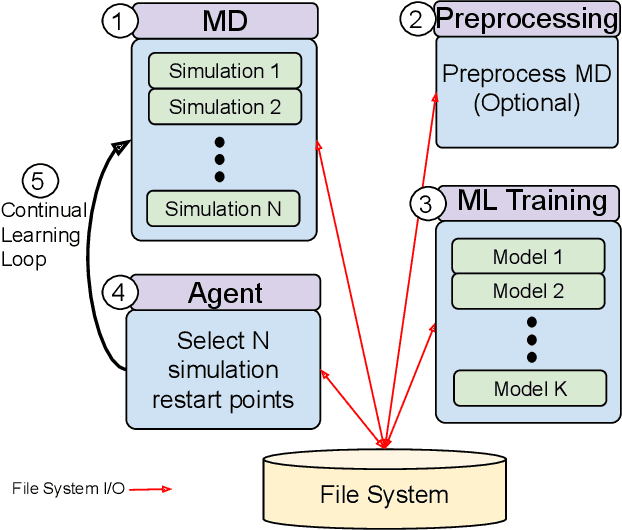
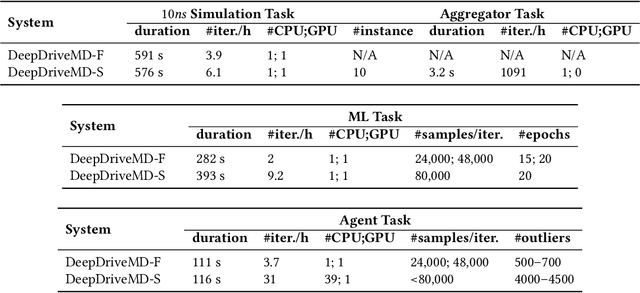
The use of ML methods to dynamically steer ensemble-based simulations promises significant improvements in the performance of scientific applications. We present DeepDriveMD, a tool for a range of prototypical ML-driven HPC simulation scenarios, and use it to quantify improvements in the scientific performance of ML-driven ensemble-based applications. We discuss its design and characterize its performance. Motivated by the potential for further scientific improvements and applicability to more sophisticated physical systems, we extend the design of DeepDriveMD to support stream-based communication between simulations and learning methods. It demonstrates a 100x speedup to fold proteins, and performs 1.6x more simulations per unit time, improving resource utilization compared to the sequential framework. Experiments are performed on leadership-class platforms, at scales of up to O(1000) nodes, and for production workloads. We establish DeepDriveMD as a high-performance framework for ML-driven HPC simulation scenarios, that supports diverse simulation and ML back-ends, and which enables new scientific insights by improving length- and time-scale accessed.
A Training-free and Reference-free Summarization Evaluation Metric via Centrality-weighted Relevance and Self-referenced Redundancy
Jun 26, 2021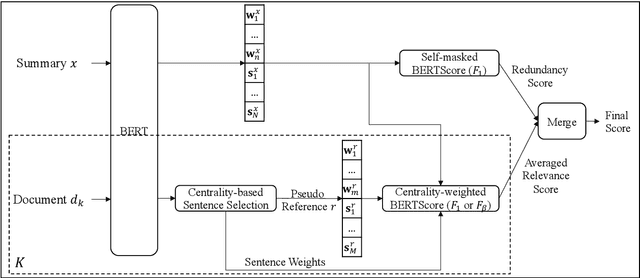
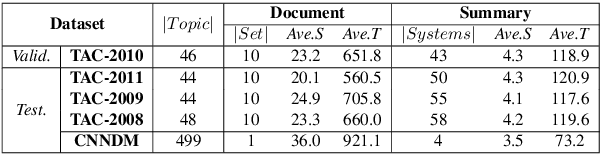
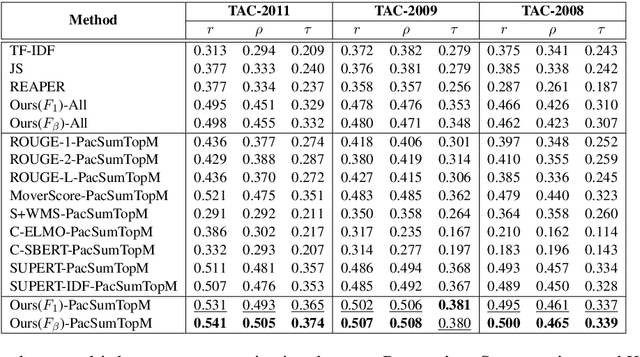
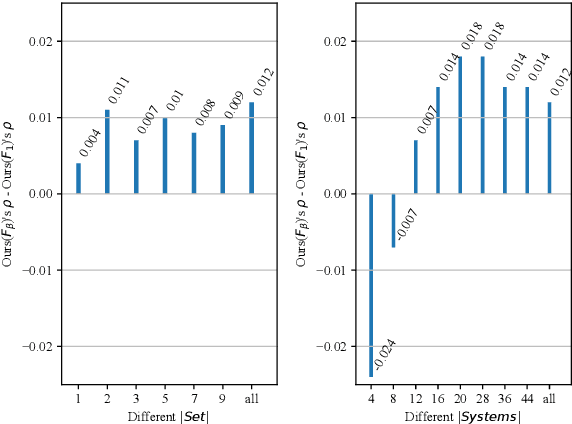
In recent years, reference-based and supervised summarization evaluation metrics have been widely explored. However, collecting human-annotated references and ratings are costly and time-consuming. To avoid these limitations, we propose a training-free and reference-free summarization evaluation metric. Our metric consists of a centrality-weighted relevance score and a self-referenced redundancy score. The relevance score is computed between the pseudo reference built from the source document and the given summary, where the pseudo reference content is weighted by the sentence centrality to provide importance guidance. Besides an $F_1$-based relevance score, we also design an $F_\beta$-based variant that pays more attention to the recall score. As for the redundancy score of the summary, we compute a self-masked similarity score with the summary itself to evaluate the redundant information in the summary. Finally, we combine the relevance and redundancy scores to produce the final evaluation score of the given summary. Extensive experiments show that our methods can significantly outperform existing methods on both multi-document and single-document summarization evaluation.
Modeling continuous-time stochastic processes using $\mathcal{N}$-Curve mixtures
Aug 12, 2019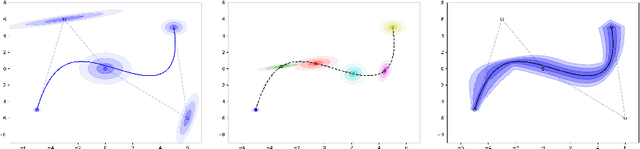

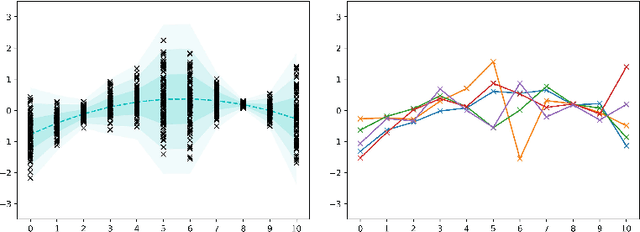
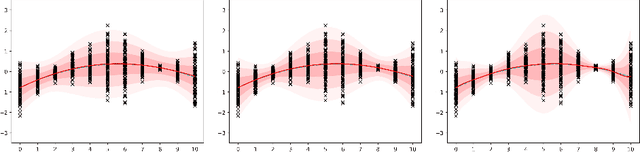
Representations of sequential data are commonly based on the assumption that observed sequences are realizations of an unknown underlying stochastic process, where the learning problem includes determination of the model parameters. In this context the model must be able to capture the multi-modal nature of the data, without blurring between modes. This property is essential for applications like trajectory prediction or human motion modeling. Towards this end, a neural network model for continuous-time stochastic processes usable for sequence prediction is proposed. The model is based on Mixture Density Networks using B\'ezier curves with Gaussian random variables as control points (abbrev.: $\mathcal{N}$-Curves). Key advantages of the model include the ability of generating smooth multi-mode predictions in a single inference step which reduces the need for Monte Carlo simulation, as required in many multi-step prediction models, based on state-of-the-art neural networks. Essential properties of the proposed approach are illustrated by several toy examples and the task of multi-step sequence prediction. Further, the model performance is evaluated on two real world use-cases, i.e. human trajectory prediction and human motion modeling, outperforming different state-of-the-art models.