 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
WAX-ML: A Python library for machine learning and feedback loops on streaming data
Jun 11, 2021
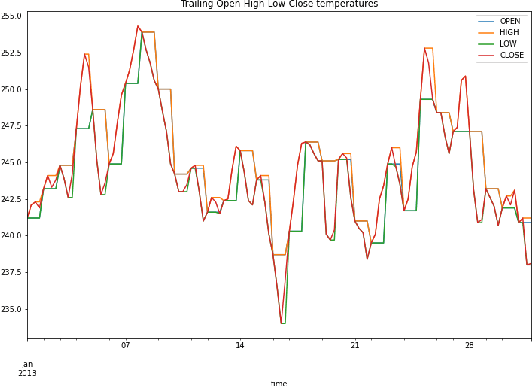
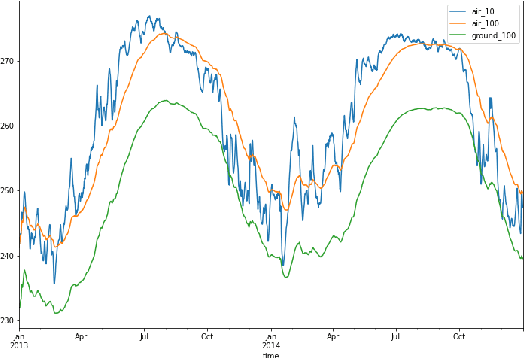
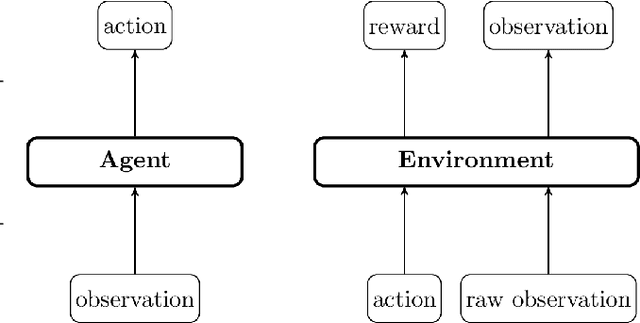
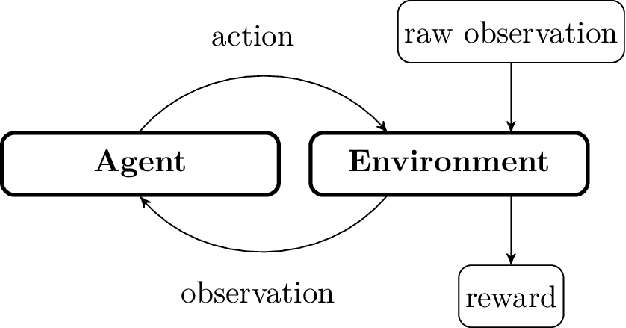
Wax is what you put on a surfboard to avoid slipping. It is an essential tool to go surfing... We introduce WAX-ML a research-oriented Python library providing tools to design powerful machine learning algorithms and feedback loops working on streaming data. It strives to complement JAX with tools dedicated to time series. WAX-ML makes JAX-based programs easy to use for end-users working with pandas and xarray for data manipulation. It provides a simple mechanism for implementing feedback loops, allows the implementation of online learning and reinforcement learning algorithms with functions, and makes them easy to integrate by end-users working with the object-oriented reinforcement learning framework from the Gym library. It is released with an Apache open-source license on GitHub at https://github.com/eserie/wax-ml.
Real-time Deep Video Deinterlacing
Aug 01, 2017
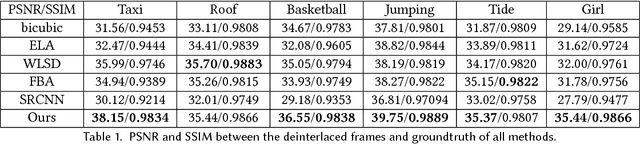


Interlacing is a widely used technique, for television broadcast and video recording, to double the perceived frame rate without increasing the bandwidth. But it presents annoying visual artifacts, such as flickering and silhouette "serration," during the playback. Existing state-of-the-art deinterlacing methods either ignore the temporal information to provide real-time performance but lower visual quality, or estimate the motion for better deinterlacing but with a trade-off of higher computational cost. In this paper, we present the first and novel deep convolutional neural networks (DCNNs) based method to deinterlace with high visual quality and real-time performance. Unlike existing models for super-resolution problems which relies on the translation-invariant assumption, our proposed DCNN model utilizes the temporal information from both the odd and even half frames to reconstruct only the missing scanlines, and retains the given odd and even scanlines for producing the full deinterlaced frames. By further introducing a layer-sharable architecture, our system can achieve real-time performance on a single GPU. Experiments shows that our method outperforms all existing methods, in terms of reconstruction accuracy and computational performance.
RMQFMU: Bridging the Real World with Co-simulation Technical Report
Jul 02, 2021
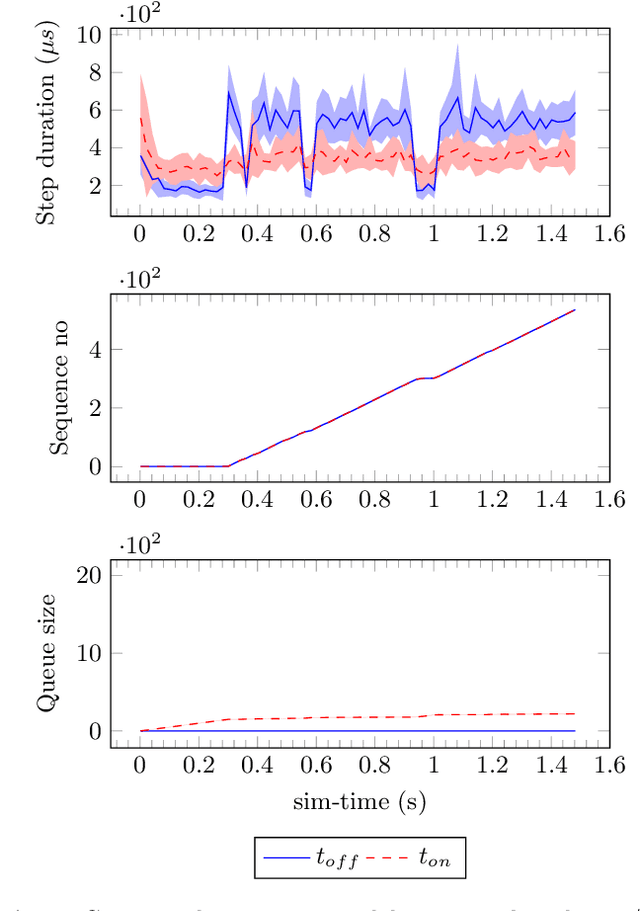
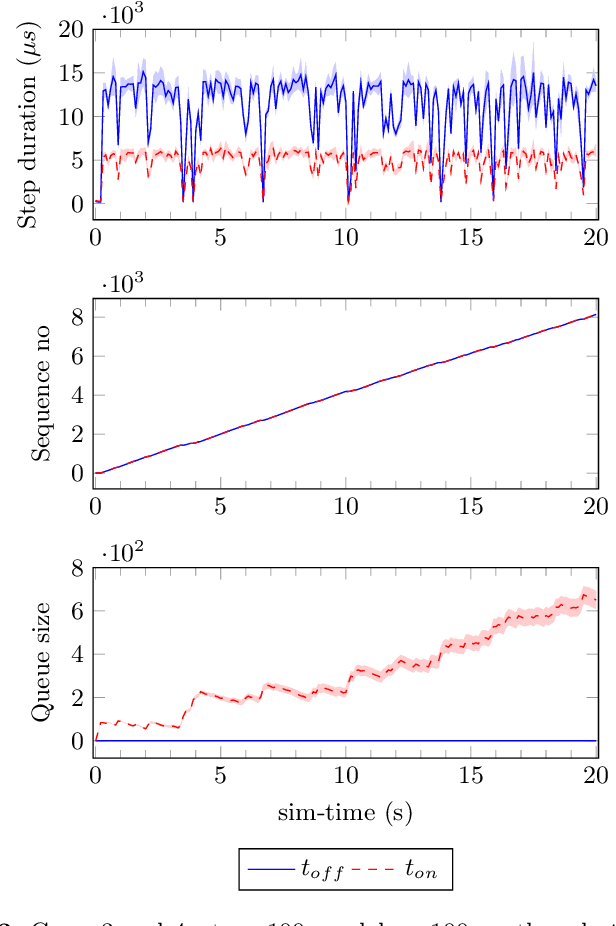
In this paper we present an experience report for the RMQ\-FMU, a plug and play tool, that enables feeding data to/from an FMI2-based co-simulation environment based on the AMQP protocol. Bridging the co-simulation to an external environment allows on one side to feed historical data to the co-simulation, serving different purposes, such as visualisation and/or data analysis. On the other side, such a tool facilitates the realisation of the digital twin concept by coupling co-simulation and hardware/robots close to real-time. In the paper we present limitations of the initial version of the RMQFMU with respect to the capability of bridging co-simulation with the real world. To provide the desired functionality of the tool, we present in a step-by-step fashion how these limitations, and subsequent limitations, are alleviated. We perform various experiments in order to give reason to the modifications carried out. Finally, we report on two case-studies where we have adopted the RMQFMU, and provide guidelines meant to aid practitioners in the use of the tool.
Optical Braille Recognition using Circular Hough Transform
Jul 02, 2021
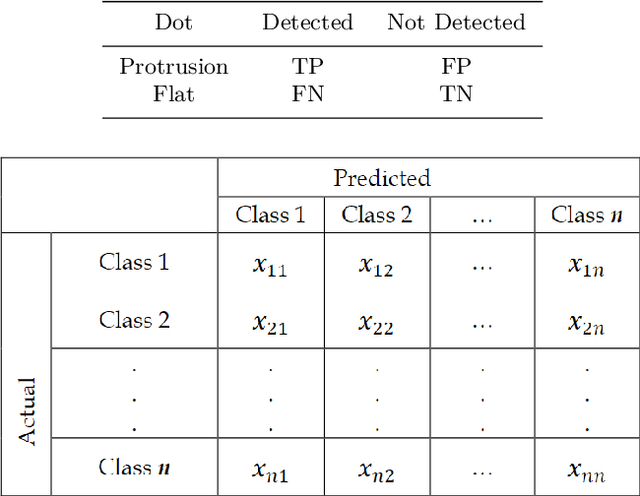


Braille has empowered visually challenged community to read and write. But at the same time, it has created a gap due to widespread inability of non-Braille users to understand Braille scripts. This gap has fuelled researchers to propose Optical Braille Recognition techniques to convert Braille documents to natural language. The main motivation of this work is to cement the communication gap at academic institutions by translating personal documents of blind students. This has been accomplished by proposing an economical and effective technique which digitizes Braille documents using a smartphone camera. For any given Braille image, a dot detection mechanism based on Hough transform is proposed which is invariant to skewness, noise and other deterrents. The detected dots are then clustered into Braille cells using distance-based clustering algorithm. In succession, the standard physical parameters of each Braille cells are estimated for feature extraction and classification as natural language characters. The comprehensive evaluation of this technique on the proposed dataset of 54 Braille scripts has yielded into accuracy of 98.71%.
Model-Based Reinforcement Learning via Latent-Space Collocation
Jun 24, 2021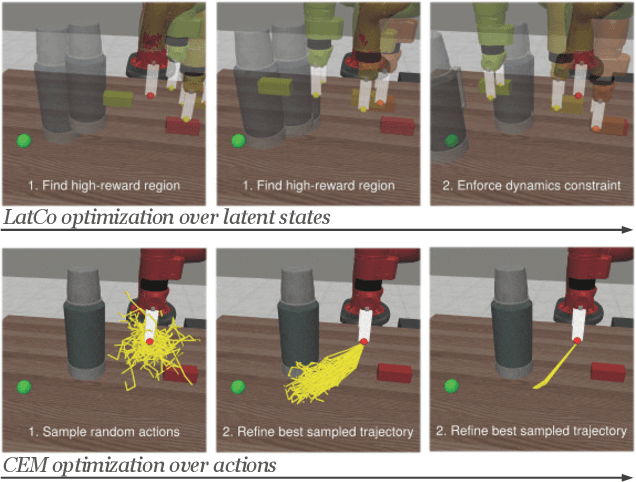
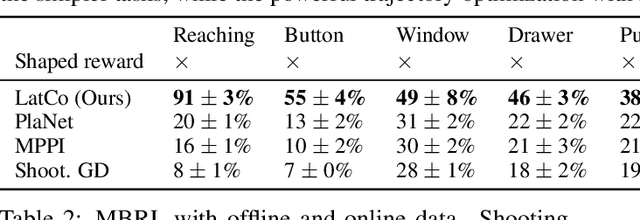
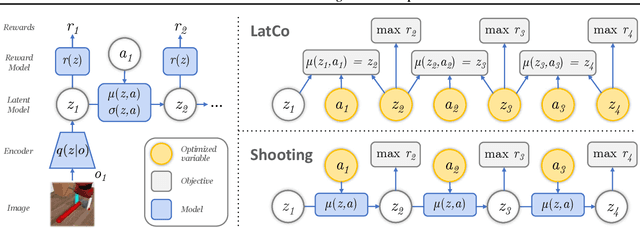

The ability to plan into the future while utilizing only raw high-dimensional observations, such as images, can provide autonomous agents with broad capabilities. Visual model-based reinforcement learning (RL) methods that plan future actions directly have shown impressive results on tasks that require only short-horizon reasoning, however, these methods struggle on temporally extended tasks. We argue that it is easier to solve long-horizon tasks by planning sequences of states rather than just actions, as the effects of actions greatly compound over time and are harder to optimize. To achieve this, we draw on the idea of collocation, which has shown good results on long-horizon tasks in optimal control literature, and adapt it to the image-based setting by utilizing learned latent state space models. The resulting latent collocation method (LatCo) optimizes trajectories of latent states, which improves over previously proposed shooting methods for visual model-based RL on tasks with sparse rewards and long-term goals. Videos and code at https://orybkin.github.io/latco/.
Fast Approximate Time-Delay Estimation in Ultrasound Elastography Using Principal Component Analysis
Nov 13, 2019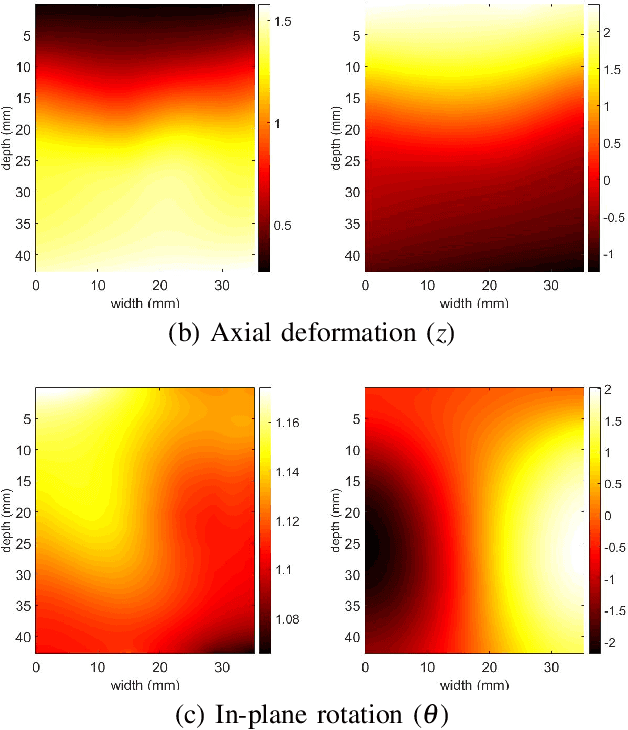
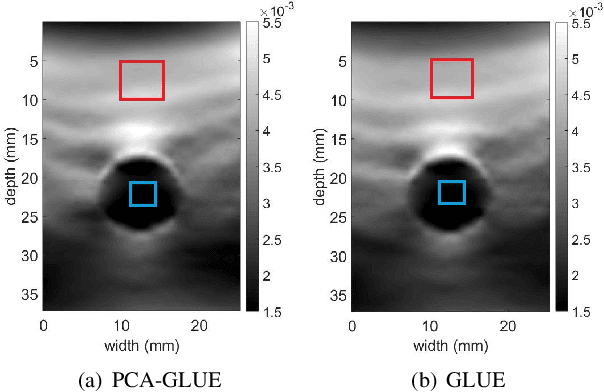
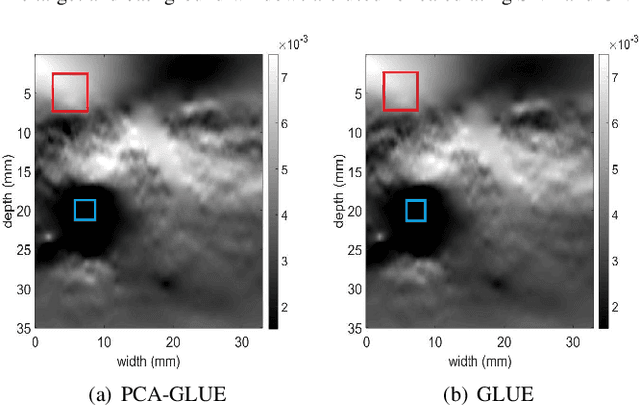

Time delay estimation (TDE) is a critical and challenging step in all ultrasound elastography methods. A growing number of TDE techniques require an approximate but robust and fast method to initialize solving for TDE. Herein, we present a fast method for calculating an approximate TDE between two radio frequency (RF) frames of ultrasound. Although this approximate TDE can be useful for several algorithms, we focus on GLobal Ultrasound Elastography (GLUE), which currently relies on Dynamic Programming (DP) to provide this approximate TDE. We exploit Principal Component Analysis (PCA) to find the general modes of deformation in quasi-static elastography, and therefore call our method PCA-GLUE. PCA-GLUE is a data-driven approach that learns a set of TDE principal components from a training database in real experiments. In the test phase, TDE is approximated as a weighted sum of these principal components. Our algorithm robustly estimates the weights from sparse feature matches, then passes the resulting displacement field to GLUE as initial estimates to perform a more accurate displacement estimation. PCA-GLUE is more than ten times faster than DP in estimation of the initial displacement field and yields similar results.
* Accepted to be Published in 2019, 41th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany
Multi-Metric Optimization using Generative Adversarial Networks for Near-End Speech Intelligibility Enhancement
Apr 17, 2021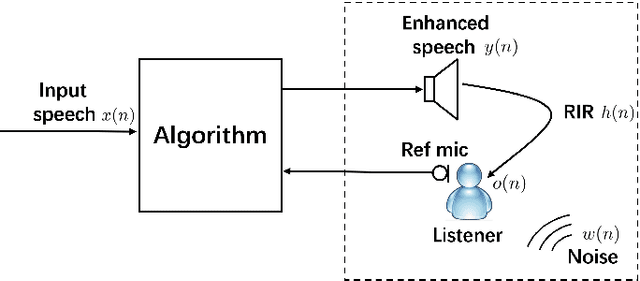
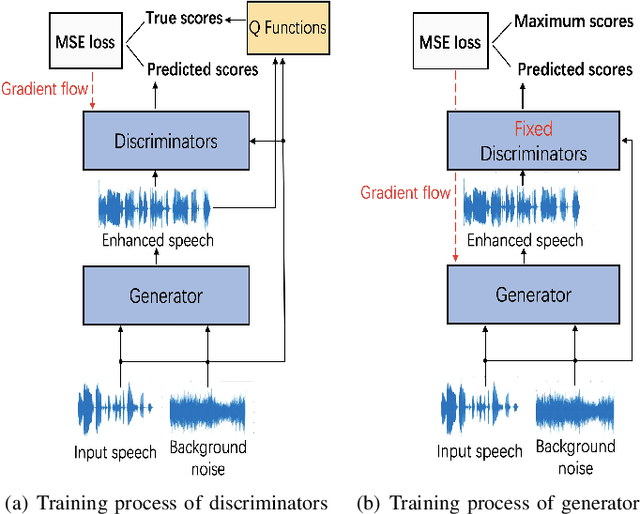
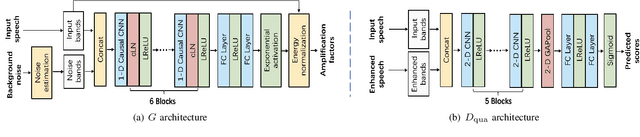
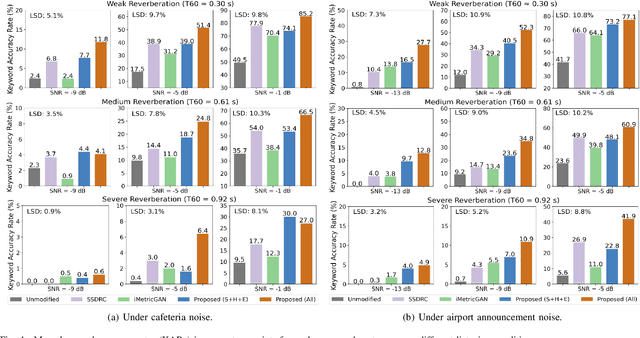
The intelligibility of speech severely degrades in the presence of environmental noise and reverberation. In this paper, we propose a novel deep learning based system for modifying the speech signal to increase its intelligibility under the equal-power constraint, i.e., signal power before and after modification must be the same. To achieve this, we use generative adversarial networks (GANs) to obtain time-frequency dependent amplification factors, which are then applied to the input raw speech to reallocate the speech energy. Instead of optimizing only a single, simple metric, we train a deep neural network (DNN) model to simultaneously optimize multiple advanced speech metrics, including both intelligibility- and quality-related ones, which results in notable improvements in performance and robustness. Our system can not only work in non-realtime mode for offline audio playback but also support practical real-time speech applications. Experimental results using both objective measurements and subjective listening tests indicate that the proposed system significantly outperforms state-ofthe-art baseline systems under various noisy and reverberant listening conditions.
Multi Projection Fusion for Real-time Semantic Segmentation of 3D LiDAR Point Clouds
Nov 06, 2020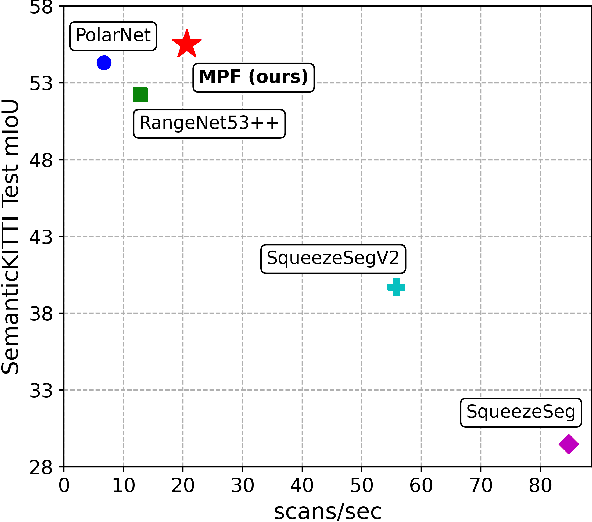
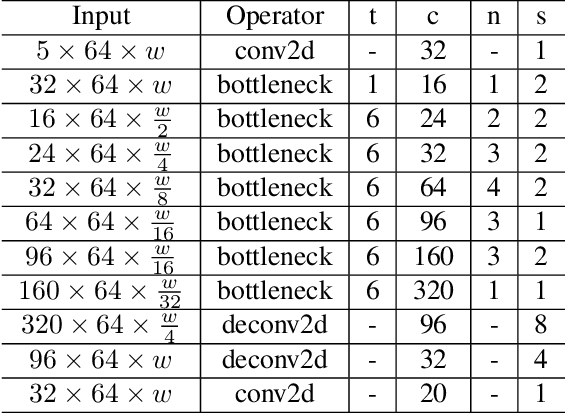
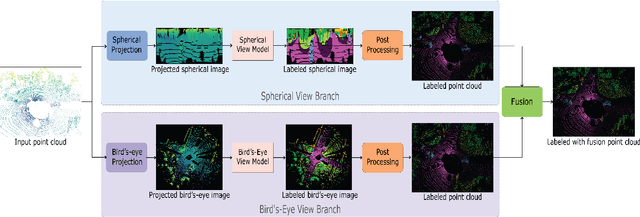
Semantic segmentation of 3D point cloud data is essential for enhanced high-level perception in autonomous platforms. Furthermore, given the increasing deployment of LiDAR sensors onboard of cars and drones, a special emphasis is also placed on non-computationally intensive algorithms that operate on mobile GPUs. Previous efficient state-of-the-art methods relied on 2D spherical projection of point clouds as input for 2D fully convolutional neural networks to balance the accuracy-speed trade-off. This paper introduces a novel approach for 3D point cloud semantic segmentation that exploits multiple projections of the point cloud to mitigate the loss of information inherent in single projection methods. Our Multi-Projection Fusion (MPF) framework analyzes spherical and bird's-eye view projections using two separate highly-efficient 2D fully convolutional models then combines the segmentation results of both views. The proposed framework is validated on the SemanticKITTI dataset where it achieved a mIoU of 55.5 which is higher than state-of-the-art projection-based methods RangeNet++ and PolarNet while being 1.6x faster than the former and 3.1x faster than the latter.
Modeling Magnetic Particle Imaging for Dynamic Tracer Distributions
Jun 24, 2021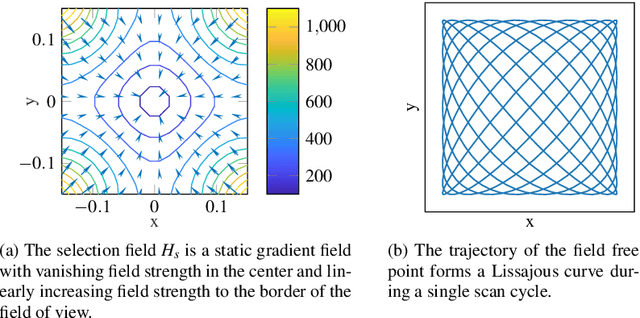
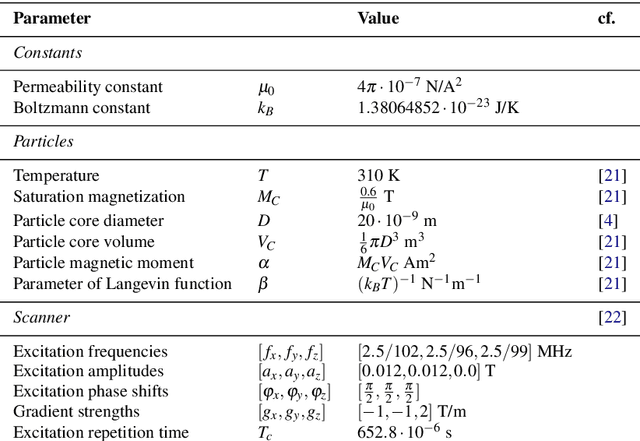
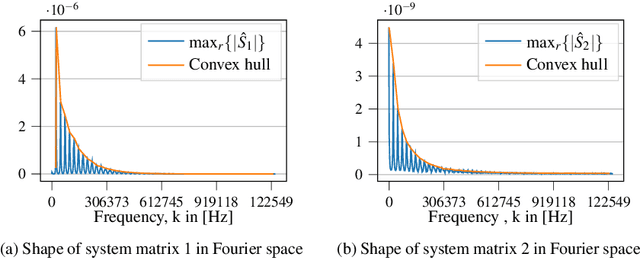
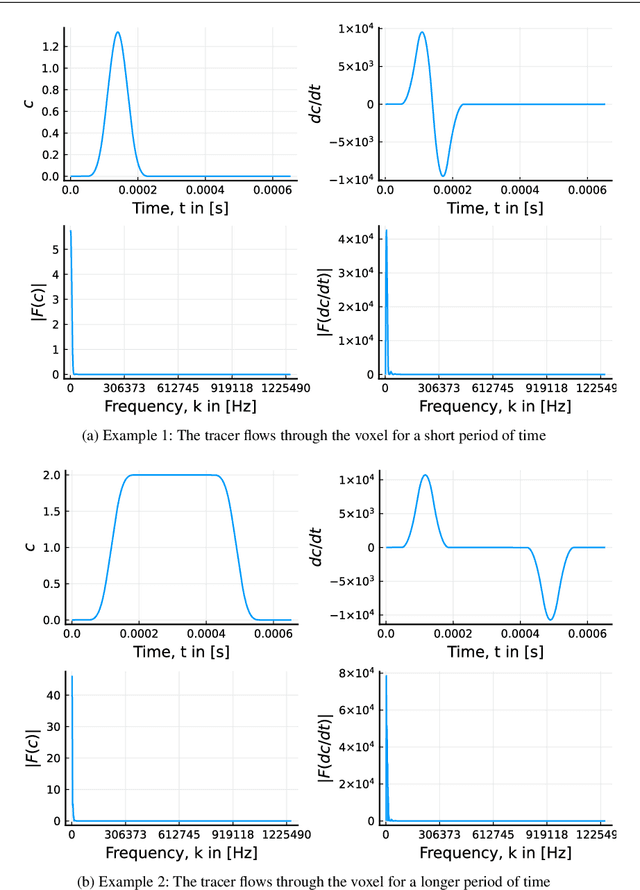
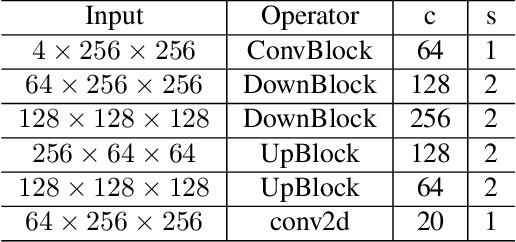
Magnetic Particle Imaging (MPI) is a promising tracer-based, functional medical imaging technique which measures the non-linear response of superparamagnetic iron oxide nanoparticles (SPION) to a dynamic magnetic field. For image reconstruction, system matrices from time-consuming calibration scans are used predominantly. Finding modeled forward operators for magnetic particle imaging, which are able to compete with measured matrices in practice, is an ongoing topic of research. The existing models for magnetic particle imaging are by design not suitable for dynamic tracer concentrations. Neither modeled nor measured system matrices account for changes in the concentration during a single scanning cycle. In this paper we present a new MPI forward model for dynamic concentrations. A standard model will be introduced briefly, followed by the changes due to the dynamic behavior of the tracer concentration. Furthermore, the relevance of this new extended model is examined by investigating the influence of the extension and example reconstructions with the new and the standard model.
Optimal Balancing of Time-Dependent Confounders for Marginal Structural Models
Jun 04, 2018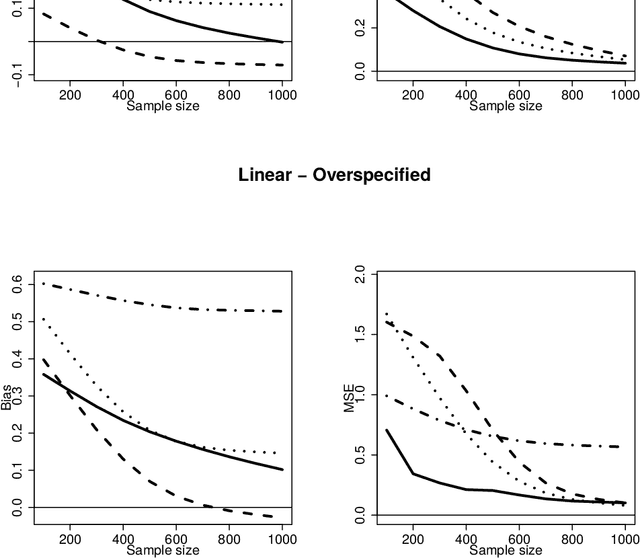

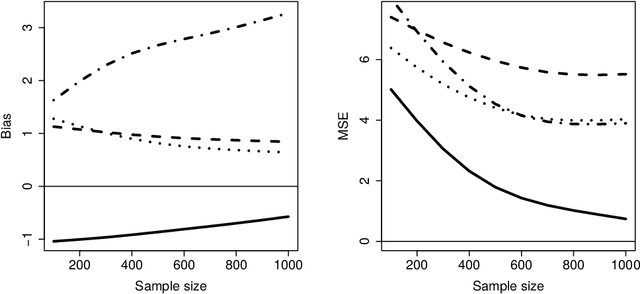
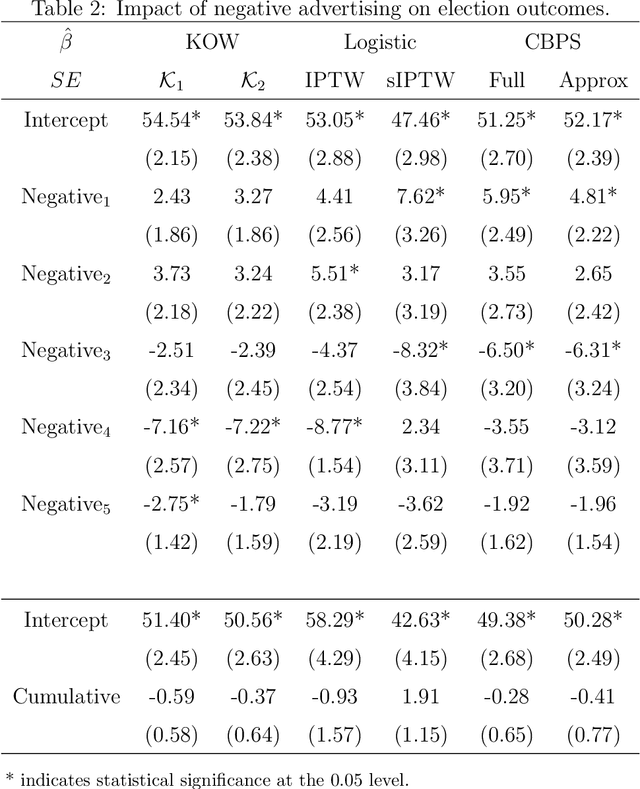
Marginal structural models (MSMs) estimate the causal effect of a time-varying treatment in the presence of time-dependent confounding via weighted regression. The standard approach of using inverse probability of treatment weighting (IPTW) can lead to high-variance estimates due to extreme weights and be sensitive to model misspecification. Various methods have been proposed to partially address this, including truncation and stabilized-IPTW to temper extreme weights and covariate balancing propensity score (CBPS) to address treatment model misspecification. In this paper, we present Kernel Optimal Weighting (KOW), a convex-optimization-based approach that finds weights for fitting the MSM that optimally balance time-dependent confounders while simultaneously controlling for precision, directly addressing the above limitations. KOW directly minimizes the error in estimation due to time-dependent confounding via a new decomposition as a functional. We further extend KOW to control for informative censoring. We evaluate the performance of KOW in a simulation study, comparing it with IPTW, stabilized-IPTW, and CBPS. We demonstrate the use of KOW in studying the effect of treatment initiation on time-to-death among people living with HIV and the effect of negative advertising on elections in the United States.