 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards a mathematical theory of trajectory inference
Feb 18, 2021
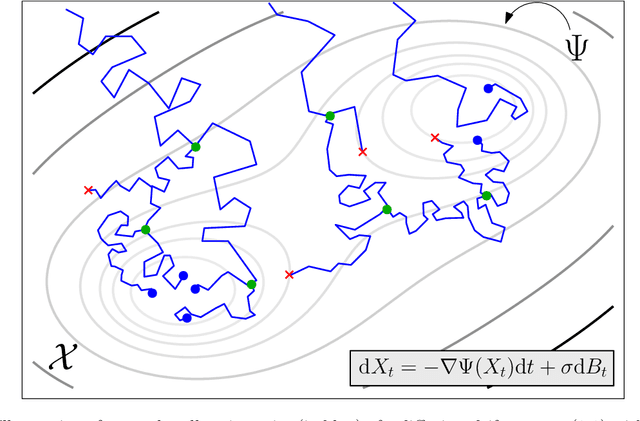

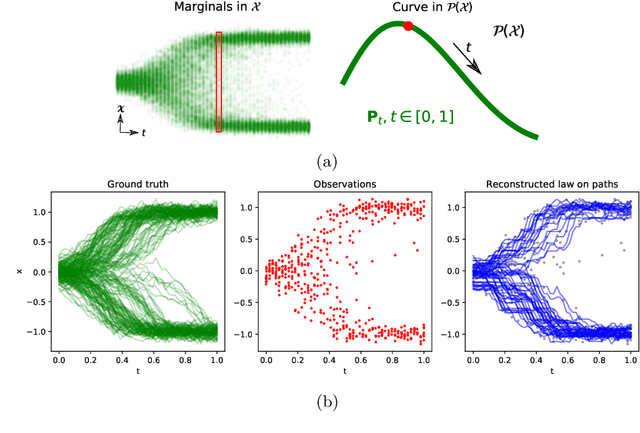
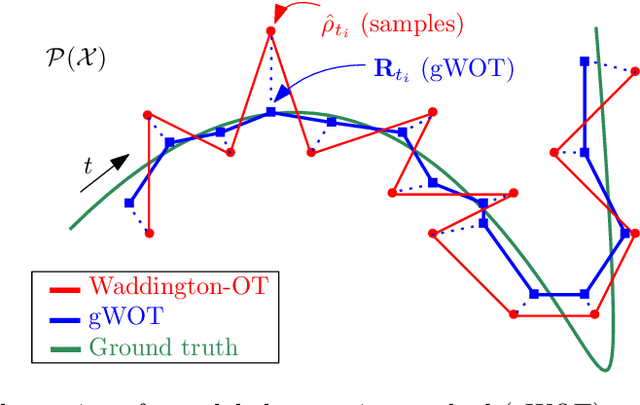
We devise a theoretical framework and a numerical method to infer trajectories of a stochastic process from snapshots of its temporal marginals. This problem arises in the analysis of single cell RNA-sequencing data, which provide high dimensional measurements of cell states but cannot track the trajectories of the cells over time. We prove that for a class of stochastic processes it is possible to recover the ground truth trajectories from limited samples of the temporal marginals at each time-point, and provide an efficient algorithm to do so in practice. The method we develop, Global Waddington-OT (gWOT), boils down to a smooth convex optimization problem posed globally over all time-points involving entropy-regularized optimal transport. We demonstrate that this problem can be solved efficiently in practice and yields good reconstructions, as we show on several synthetic and real datasets.
Banker Online Mirror Descent
Jun 16, 2021
We propose Banker-OMD, a novel framework generalizing the classical Online Mirror Descent (OMD) technique in online learning algorithm design. Banker-OMD allows algorithms to robustly handle delayed feedback, and offers a general methodology for achieving $\tilde{O}(\sqrt{T} + \sqrt{D})$-style regret bounds in various delayed-feedback online learning tasks, where $T$ is the time horizon length and $D$ is the total feedback delay. We demonstrate the power of Banker-OMD with applications to three important bandit scenarios with delayed feedback, including delayed adversarial Multi-armed bandits (MAB), delayed adversarial linear bandits, and a novel delayed best-of-both-worlds MAB setting. Banker-OMD achieves nearly-optimal performance in all the three settings. In particular, it leads to the first delayed adversarial linear bandit algorithm achieving $\tilde{O}(\text{poly}(n)(\sqrt{T} + \sqrt{D}))$ regret.
A Self-adaptive SAC-PID Control Approach based on Reinforcement Learning for Mobile Robots
Mar 19, 2021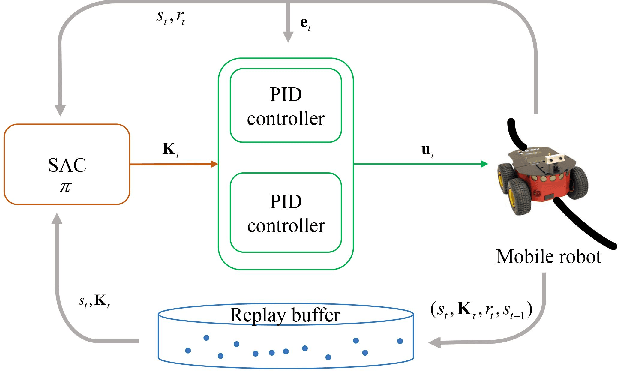
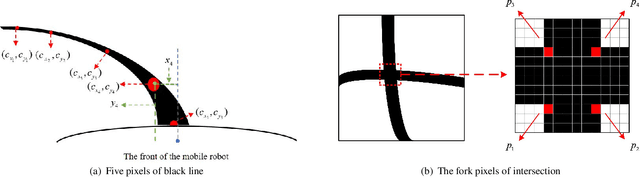

Proportional-integral-derivative (PID) control is the most widely used in industrial control, robot control and other fields. However, traditional PID control is not competent when the system cannot be accurately modeled and the operating environment is variable in real time. To tackle these problems, we propose a self-adaptive model-free SAC-PID control approach based on reinforcement learning for automatic control of mobile robots. A new hierarchical structure is developed, which includes the upper controller based on soft actor-critic (SAC), one of the most competitive continuous control algorithms, and the lower controller based on incremental PID controller. Soft actor-critic receives the dynamic information of the mobile robot as input, and simultaneously outputs the optimal parameters of incremental PID controllers to compensate for the error between the path and the mobile robot in real time. In addition, the combination of 24-neighborhood method and polynomial fitting is developed to improve the adaptability of SAC-PID control method to complex environments. The effectiveness of the SAC-PID control method is verified with several different difficulty paths both on Gazebo and real mecanum mobile robot. Futhermore, compared with fuzzy PID control, the SAC-PID method has merits of strong robustness, generalization and real-time performance.
Fast Online Planning for Bipedal Locomotion via Centroidal Model Predictive Gait Synthesis
Feb 26, 2021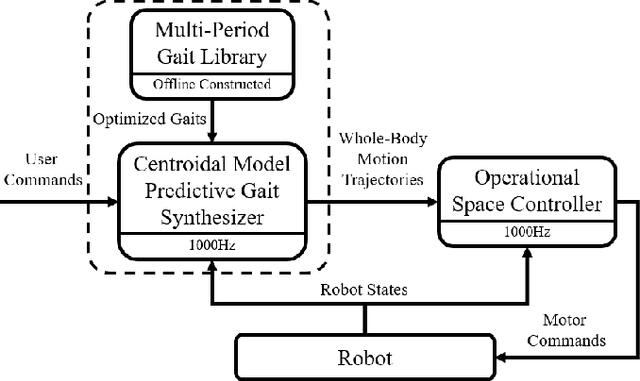
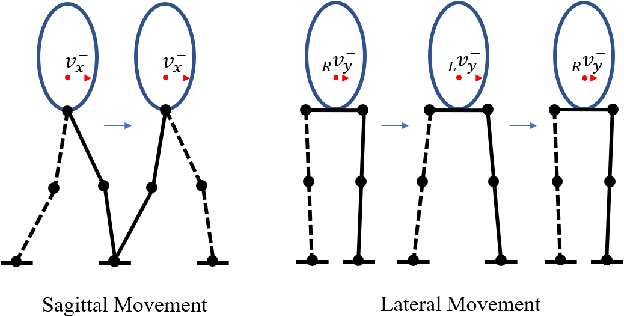
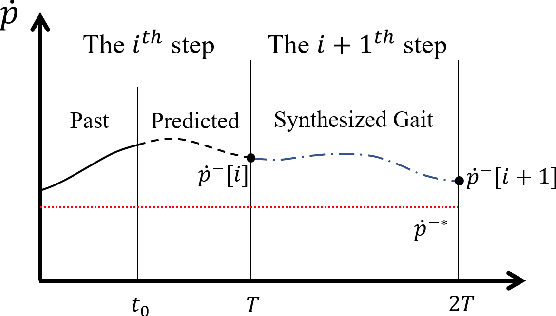
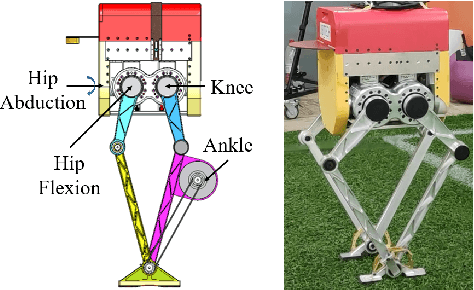
The planning of whole-body motion and step time for bipedal locomotion is constructed as a model predictive control (MPC) problem, in which a sequence of optimization problems need to be solved online. While directly solving these problems is extremely time-consuming, we propose a predictive gait synthesizer to solve them quickly online. Based on the full dimensional model, a library of gaits with different speeds and periods is first constructed offline. Then the proposed gait synthesizer generates real-time gaits by synthesizing the gait library based on the online prediction of centroidal dynamics. We prove that the generated gaits are feasible solutions of the MPC optimization problems. Thus our proposed gait synthesizer works as a fast MPC-style planner to guarantee the feasibility and stability of the full dimensional robot. Simulation and experimental results on an 8 degrees of freedom (DoF) bipedal robot are provided to show the performance and robustness of this approach for walking and standing.
Modeling User Behaviour in Research Paper Recommendation System
Jul 16, 2021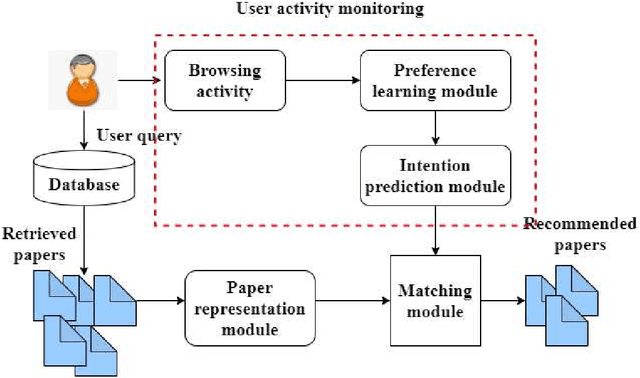
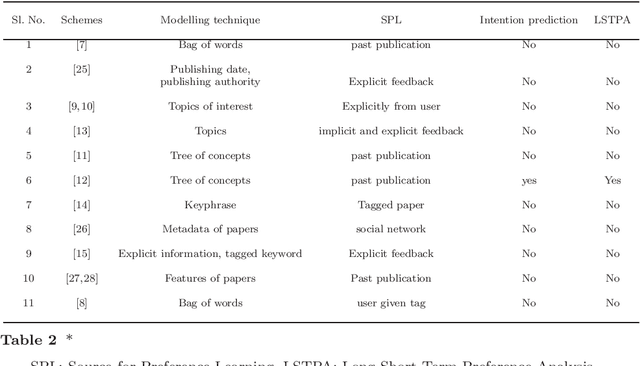
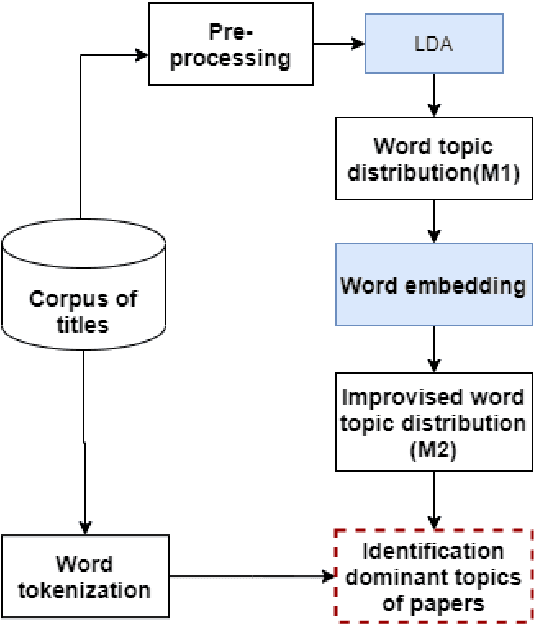
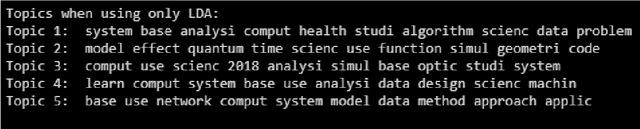
User intention which often changes dynamically is considered to be an important factor for modeling users in the design of recommendation systems. Recent studies are starting to focus on predicting user intention (what users want) beyond user preference (what users like). In this work, a user intention model is proposed based on deep sequential topic analysis. The model predicts a user's intention in terms of the topic of interest. The Hybrid Topic Model (HTM) comprising Latent Dirichlet Allocation (LDA) and Word2Vec is proposed to derive the topic of interest of users and the history of preferences. HTM finds the true topics of papers estimating word-topic distribution which includes syntactic and semantic correlations among words. Next, to model user intention, a Long Short Term Memory (LSTM) based sequential deep learning model is proposed. This model takes into account temporal context, namely the time difference between clicks of two consecutive papers seen by a user. Extensive experiments with the real-world research paper dataset indicate that the proposed approach significantly outperforms the state-of-the-art methods. Further, the proposed approach introduces a new road map to model a user activity suitable for the design of a research paper recommendation system.
Efficient automated U-Net based tree crown delineation using UAV multi-spectral imagery on embedded devices
Jul 16, 2021



Delineation approaches provide significant benefits to various domains, including agriculture, environmental and natural disasters monitoring. Most of the work in the literature utilize traditional segmentation methods that require a large amount of computational and storage resources. Deep learning has transformed computer vision and dramatically improved machine translation, though it requires massive dataset for training and significant resources for inference. More importantly, energy-efficient embedded vision hardware delivering real-time and robust performance is crucial in the aforementioned application. In this work, we propose a U-Net based tree delineation method, which is effectively trained using multi-spectral imagery but can then delineate single-spectrum images. The deep architecture that also performs localization, i.e., a class label corresponds to each pixel, has been successfully used to allow training with a small set of segmented images. The ground truth data were generated using traditional image denoising and segmentation approaches. To be able to execute the proposed DNN efficiently in embedded platforms designed for deep learning approaches, we employ traditional model compression and acceleration methods. Extensive evaluation studies using data collected from UAVs equipped with multi-spectral cameras demonstrate the effectiveness of the proposed methods in terms of delineation accuracy and execution efficiency.
Accelerating Kinodynamic RRT* Through Dimensionality Reduction
Jul 02, 2021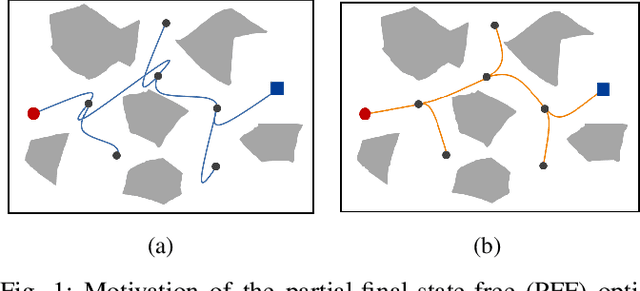
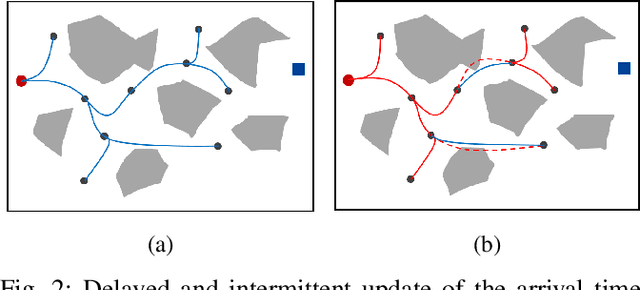


Sampling-based motion planning algorithms such as RRT* are well-known for their ability to quickly find an initial solution and then converge to the optimal solution asymptotically. However, the convergence rate can be slow for highdimensional planning problems, particularly for dynamical systems where the sampling space is not just the configuration space but the full state space. In this paper, we introduce the idea of using a partial-final-state-free (PFF) optimal controller in kinodynamic RRT* [1] to reduce the dimensionality of the sampling space. Instead of sampling the full state space, the proposed accelerated kinodynamic RRT*, called Kino-RRT*, only samples part of the state space, while the rest of the states are selected by the PFF optimal controller. We also propose a delayed and intermittent update of the optimal arrival time of all the edges in the RRT* tree to decrease the computation complexity of the algorithm. We tested the proposed algorithm using 4-D and 10-D state-space linear systems and showed that Kino-RRT* converges much faster than the kinodynamic RRT* algorithm.
Risk Adversarial Learning System for Connected and Autonomous Vehicle Charging
Aug 02, 2021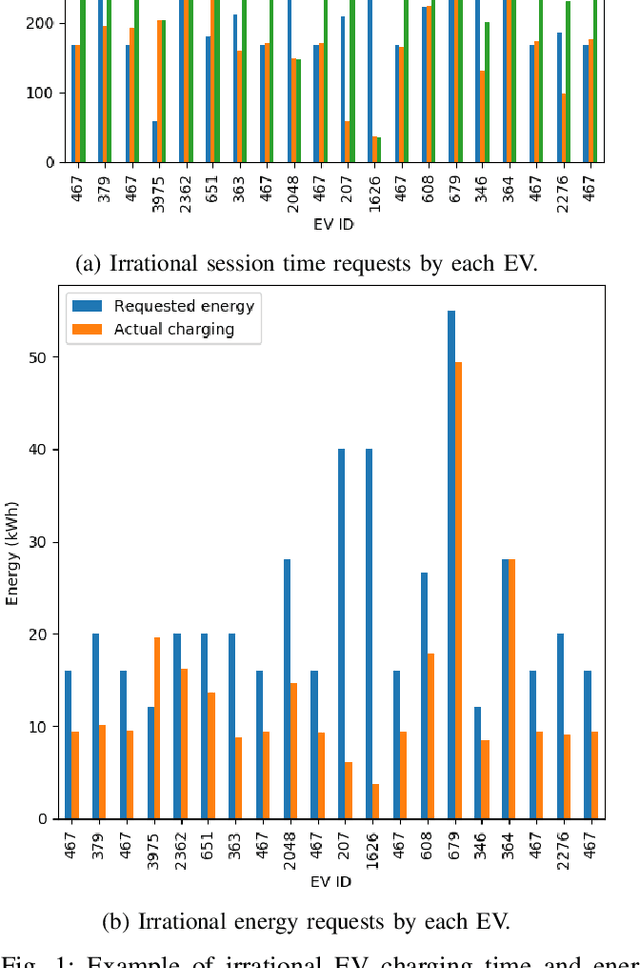
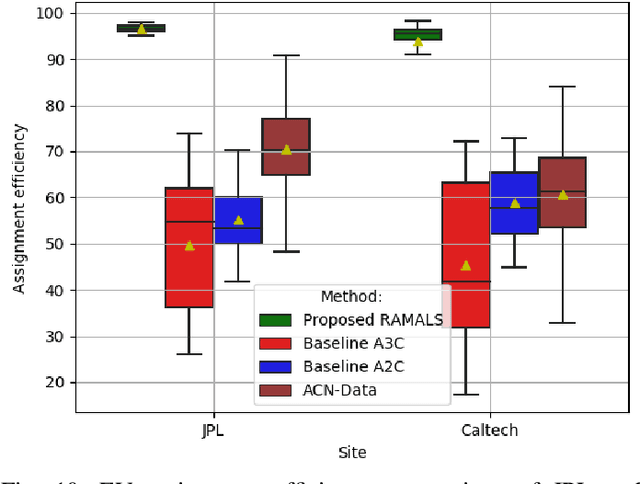
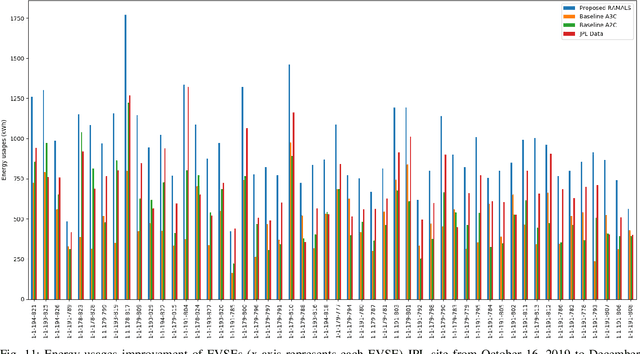
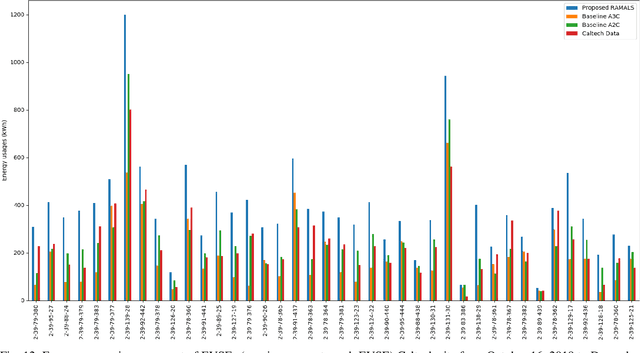
In this paper, the design of a rational decision support system (RDSS) for a connected and autonomous vehicle charging infrastructure (CAV-CI) is studied. In the considered CAV-CI, the distribution system operator (DSO) deploys electric vehicle supply equipment (EVSE) to provide an EV charging facility for human-driven connected vehicles (CVs) and autonomous vehicles (AVs). The charging request by the human-driven EV becomes irrational when it demands more energy and charging period than its actual need. Therefore, the scheduling policy of each EVSE must be adaptively accumulated the irrational charging request to satisfy the charging demand of both CVs and AVs. To tackle this, we formulate an RDSS problem for the DSO, where the objective is to maximize the charging capacity utilization by satisfying the laxity risk of the DSO. Thus, we devise a rational reward maximization problem to adapt the irrational behavior by CVs in a data-informed manner. We propose a novel risk adversarial multi-agent learning system (RAMALS) for CAV-CI to solve the formulated RDSS problem. In RAMALS, the DSO acts as a centralized risk adversarial agent (RAA) for informing the laxity risk to each EVSE. Subsequently, each EVSE plays the role of a self-learner agent to adaptively schedule its own EV sessions by coping advice from RAA. Experiment results show that the proposed RAMALS affords around 46.6% improvement in charging rate, about 28.6% improvement in the EVSE's active charging time and at least 33.3% more energy utilization, as compared to a currently deployed ACN EVSE system, and other baselines.
Analysis of EEG data using complex geometric structurization
Feb 17, 2021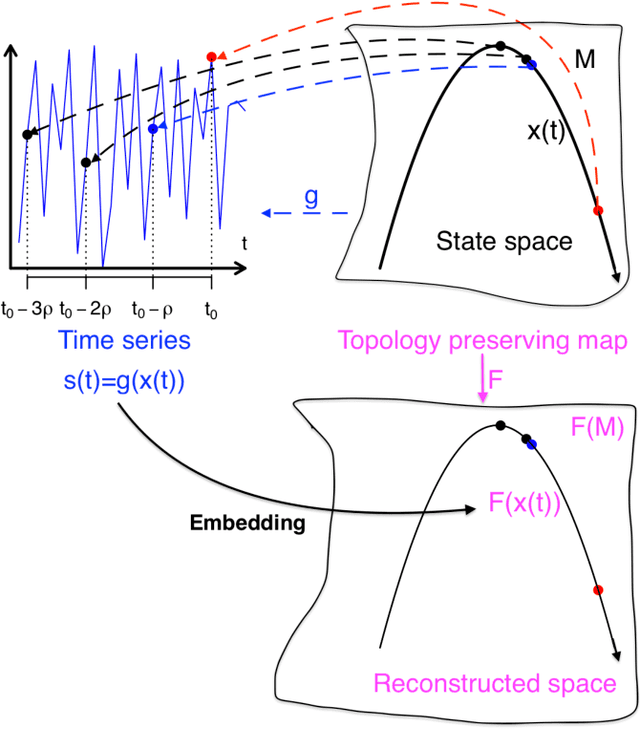
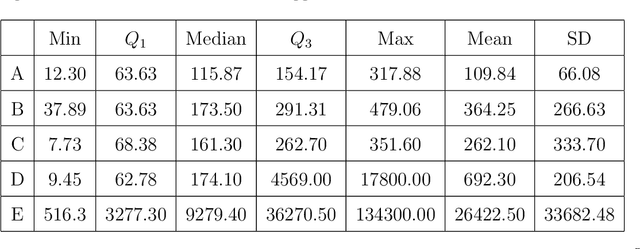
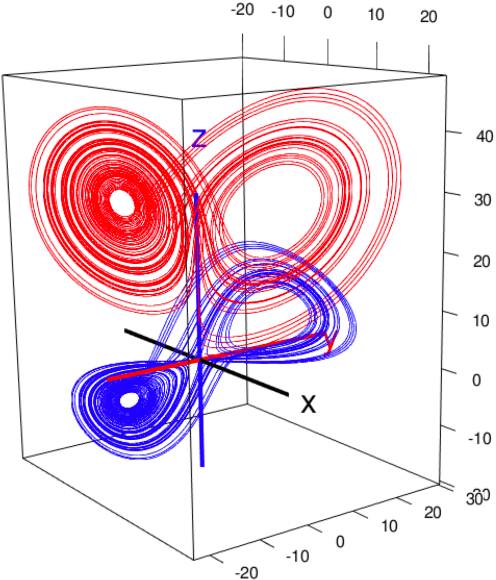

Electroencephalogram (EEG) is a common tool used to understand brain activities. The data are typically obtained by placing electrodes at the surface of the scalp and recording the oscillations of currents passing through the electrodes. These oscillations can sometimes lead to various interpretations, depending on the subject's health condition, the experiment carried out, the sensitivity of the tools used, human manipulations etc. The data obtained over time can be considered a time series. There is evidence in the literature that epilepsy EEG data may be chaotic. Either way, the embedding theory in dynamical systems suggests that time series from a complex system could be used to reconstruct its phase space under proper conditions. In this paper, we propose an analysis of epilepsy electroencephalogram time series data based on a novel approach dubbed complex geometric structurization. Complex geometric structurization stems from the construction of strange attractors using embedding theory from dynamical systems. The complex geometric structures are themselves obtained using a geometry tool, namely the $\alpha$-shapes from shape analysis. Initial analyses show a proof of concept in that these complex structures capture the expected changes brain in lobes under consideration. Further, a deeper analysis suggests that these complex structures can be used as biomarkers for seizure changes.
Physics-Informed Neural Nets-based Control
Apr 06, 2021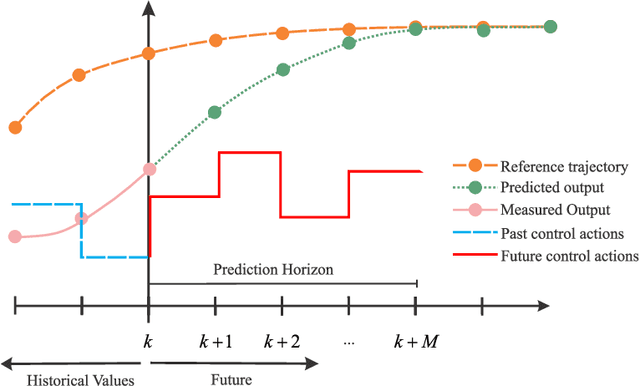
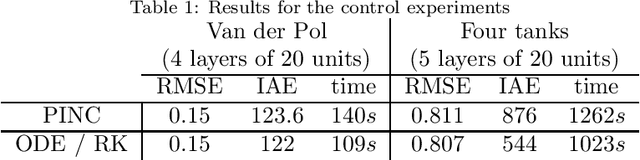
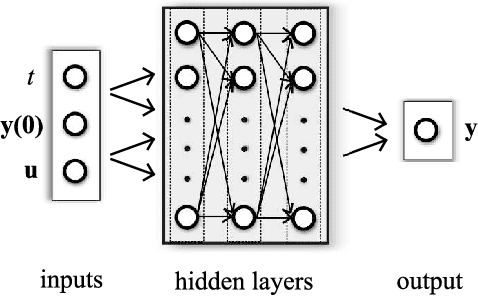
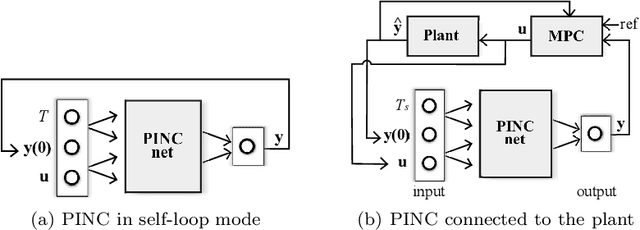
Physics-informed neural networks (PINNs) impose known physical laws into the learning of deep neural networks, making sure they respect the physics of the process while decreasing the demand of labeled data. For systems represented by Ordinary Differential Equations (ODEs), the conventional PINN has a continuous time input variable and outputs the solution of the corresponding ODE. In their original form, PINNs do not allow control inputs neither can they simulate for long-range intervals without serious degradation in their predictions. In this context, this work presents a new framework called Physics-Informed Neural Nets-based Control (PINC), which proposes a novel PINN-based architecture that is amenable to control problems and able to simulate for longer-range time horizons that are not fixed beforehand. First, the network is augmented with new inputs to account for the initial state of the system and the control action. Then, the response over the complete time horizon is split such that each smaller interval constitutes a solution of the ODE conditioned on the fixed values of initial state and control action. The complete response is formed by setting the initial state of the next interval to the terminal state of the previous one. The new methodology enables the optimal control of dynamic systems, making feasible to integrate a priori knowledge from experts and data collected from plants in control applications. We showcase our method in the control of two nonlinear dynamic systems: the Van der Pol oscillator and the four-tank system.