 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Achieving 100X faster simulations of complex biological phenomena by coupling ML to HPC ensembles
Apr 26, 2021
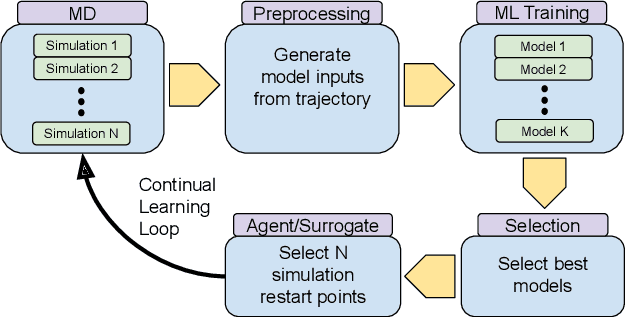
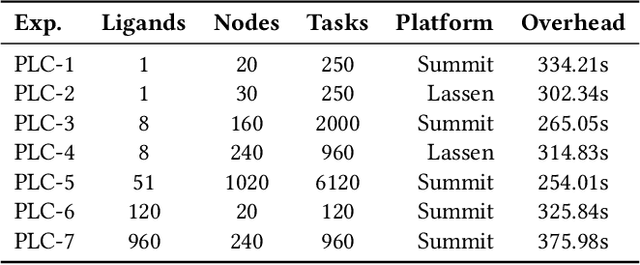
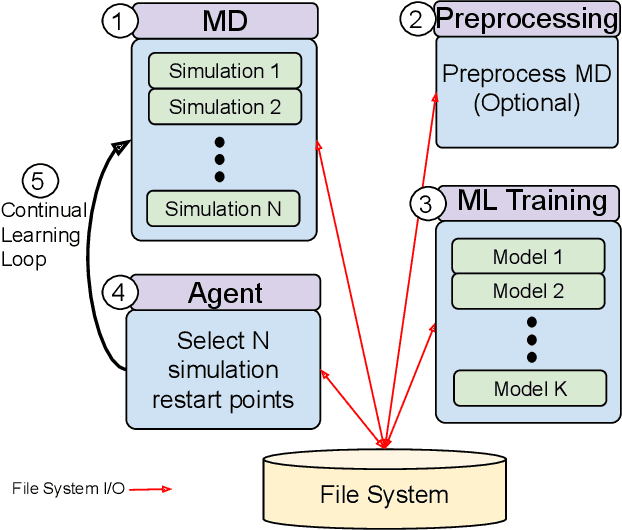
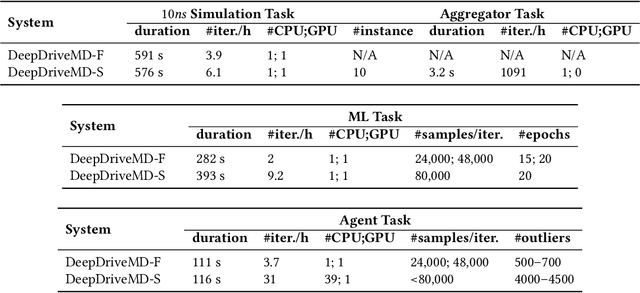
The use of ML methods to dynamically steer ensemble-based simulations promises significant improvements in the performance of scientific applications. We present DeepDriveMD, a tool for a range of prototypical ML-driven HPC simulation scenarios, and use it to quantify improvements in the scientific performance of ML-driven ensemble-based applications. We discuss its design and characterize its performance. Motivated by the potential for further scientific improvements and applicability to more sophisticated physical systems, we extend the design of DeepDriveMD to support stream-based communication between simulations and learning methods. It demonstrates a 100x speedup to fold proteins, and performs 1.6x more simulations per unit time, improving resource utilization compared to the sequential framework. Experiments are performed on leadership-class platforms, at scales of up to O(1000) nodes, and for production workloads. We establish DeepDriveMD as a high-performance framework for ML-driven HPC simulation scenarios, that supports diverse simulation and ML back-ends, and which enables new scientific insights by improving length- and time-scale accessed.
Learning to Generalize One Sample at a Time with Self-Supervision
Oct 10, 2019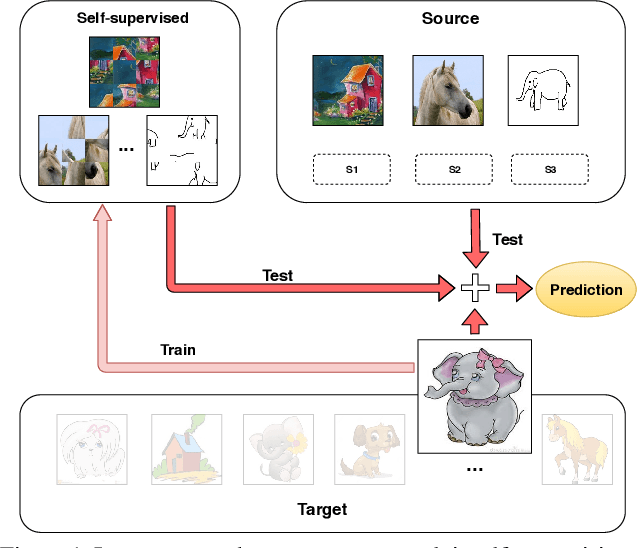
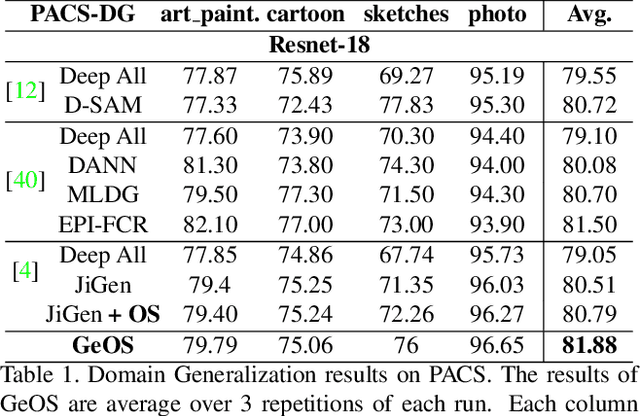
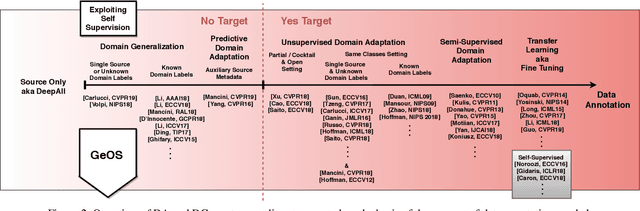
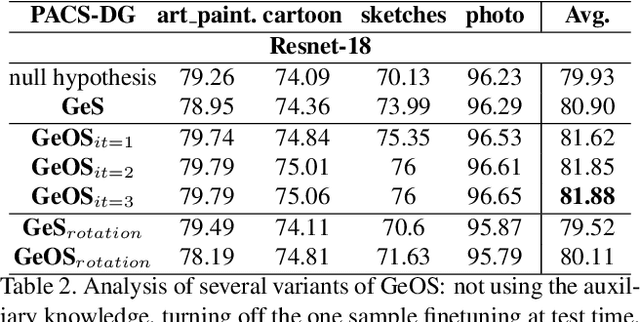
Although deep networks have significantly increased the performance of visual recognition methods, it is still challenging to achieve the robustness across visual domains that is necessary for real-world applications. To tackle this issue, research on domain adaptation and generalization has flourished over the last decade. An important aspect to consider when assessing the work done in the literature so far is the amount of data annotation necessary for training each approach, both at the source and target level. In this paper we argue that the data annotation overload should be minimal, as it is costly. Hence, we propose to use self-supervised learning to achieve domain generalization and adaptation. We consider learning regularities from non annotated data as an auxiliary task, and cast the problem within an Auxiliary Learning principled framework. Moreover, we suggest to further exploit the ability to learn about visual domains from non annotated images by learning from target data while testing, as data are presented to the algorithm one sample at a time. Results on three different scenarios confirm the value of our approach.
AGGGEN: Ordering and Aggregating while Generating
Jun 10, 2021We present AGGGEN (pronounced 'again'), a data-to-text model which re-introduces two explicit sentence planning stages into neural data-to-text systems: input ordering and input aggregation. In contrast to previous work using sentence planning, our model is still end-to-end: AGGGEN performs sentence planning at the same time as generating text by learning latent alignments (via semantic facts) between input representation and target text. Experiments on the WebNLG and E2E challenge data show that by using fact-based alignments our approach is more interpretable, expressive, robust to noise, and easier to control, while retaining the advantages of end-to-end systems in terms of fluency. Our code is available at https://github.com/XinnuoXu/AggGen.
Consistency issues in Gaussian Mixture Models reduction algorithms
Apr 26, 2021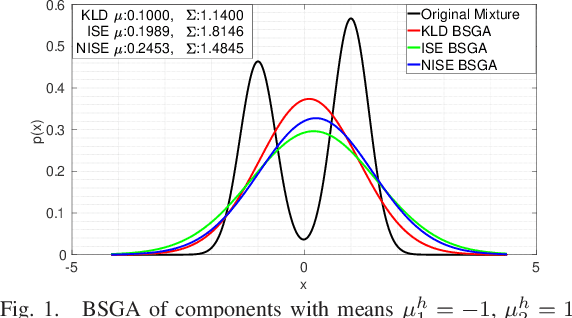
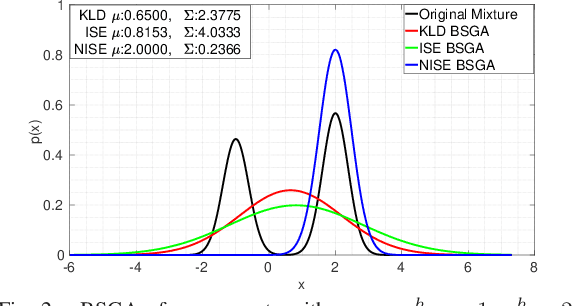
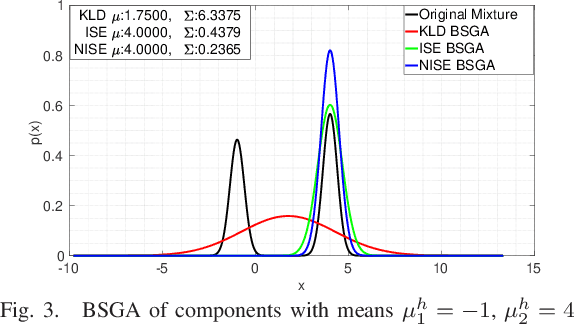
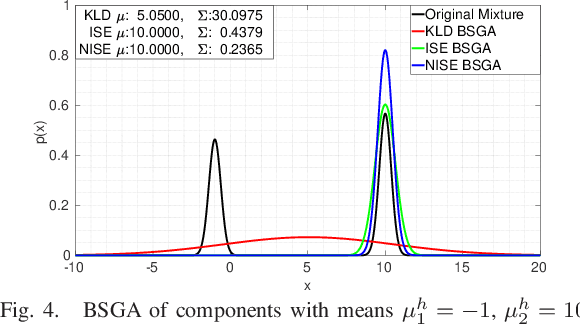
In many contexts Gaussian Mixtures (GM) are used to approximate probability distributions, possibly time-varying. In some applications the number of GM components exponentially increases over time, and reduction procedures are required to keep them reasonably limited. The GM reduction (GMR) problem can be formulated by choosing different measures of the dissimilarity of GMs before and after reduction, like the Kullback-Leibler Divergence (KLD) and the Integral Squared Error (ISE). Since in no case the solution is obtained in closed form, many approximate GMR algorithms have been proposed in the past three decades, although none of them provides optimality guarantees. In this work we discuss the importance of the choice of the dissimilarity measure and the issue of consistency of all steps of a reduction algorithm with the chosen measure. Indeed, most of the existing GMR algorithms are composed by several steps which are not consistent with a unique measure, and for this reason may produce reduced GMs far from optimality. In particular, the use of the KLD, of the ISE and normalized ISE is discussed and compared in this perspective.
Algorithmic Solution for Non-Square, Dense Systems of Linear Equations, with applications in Feature Selection
Apr 26, 2021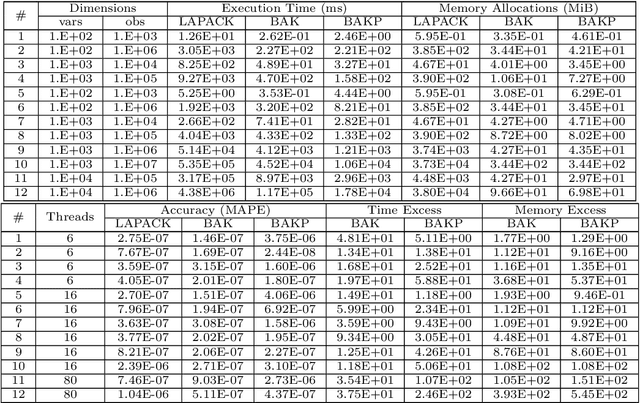
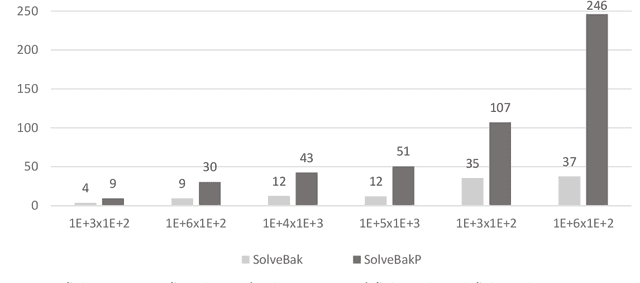
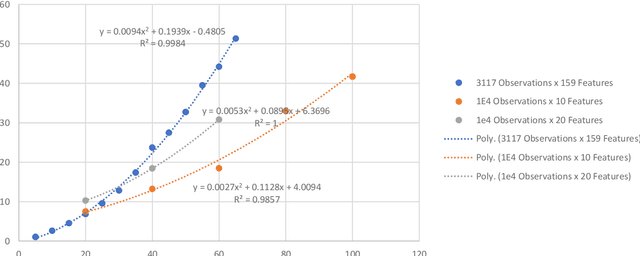
We present a novel algorithm attaining excessively fast, the sought solution of linear systems of equations. The algorithm is short in its basic formulation and by definition vectorised, while the memory allocation demands trivial, because for each iteration only one dimension of the given input matrix $\mathbf x$ is utilized. The execution time is very short compared with state-of-the-art methods, exhibiting up to $\mathcal{O}(10^3)$ speed-up and low memory allocation demands, especially for non-square Systems of Linear Equations, with ratio of equations versus features high (tall systems), or low (wide systems) accordingly. The accuracy is high and straightforwardly controlled, and the numerical results highlight the efficiency of the proposed algorithm, in terms of computation time, solution accuracy and memory allocations demands. The parallelisation of the algorithm is also presented in multi-threaded and GPU accelerators' setting. The paper also comprises a theoretical proof for the algorithmic convergence. Finally, we extend the implementation of the proposed algorithmic rationale to feature selection tasks.
Monte Carlo Simulation of SDEs using GANs
Apr 03, 2021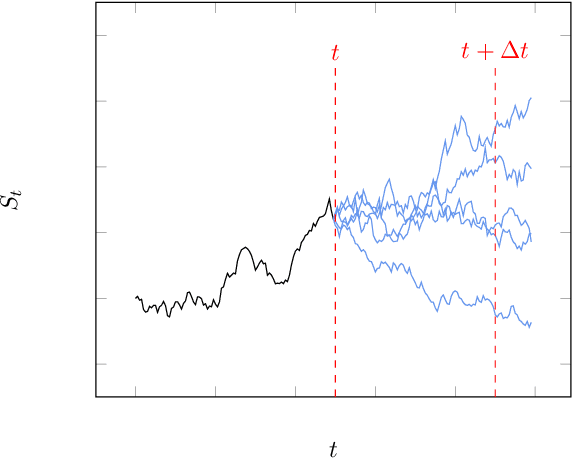

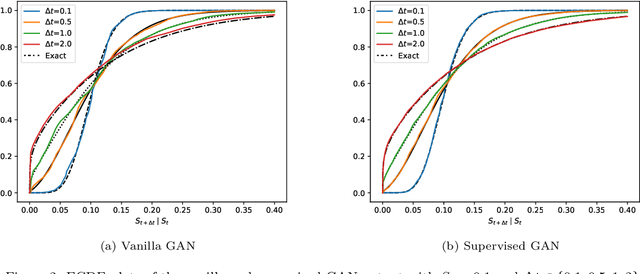
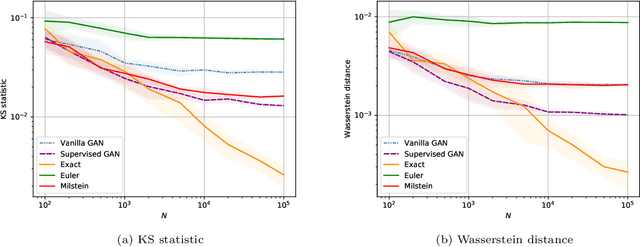
Generative adversarial networks (GANs) have shown promising results when applied on partial differential equations and financial time series generation. We investigate if GANs can also be used to approximate one-dimensional Ito stochastic differential equations (SDEs). We propose a scheme that approximates the path-wise conditional distribution of SDEs for large time steps. Standard GANs are only able to approximate processes in distribution, yielding a weak approximation to the SDE. A conditional GAN architecture is proposed that enables strong approximation. We inform the discriminator of this GAN with the map between the prior input to the generator and the corresponding output samples, i.e. we introduce a `supervised GAN'. We compare the input-output map obtained with the standard GAN and supervised GAN and show experimentally that the standard GAN may fail to provide a path-wise approximation. The GAN is trained on a dataset obtained with exact simulation. The architecture was tested on geometric Brownian motion (GBM) and the Cox-Ingersoll-Ross (CIR) process. The supervised GAN outperformed the Euler and Milstein schemes in strong error on a discretisation with large time steps. It also outperformed the standard conditional GAN when approximating the conditional distribution. We also demonstrate how standard GANs may give rise to non-parsimonious input-output maps that are sensitive to perturbations, which motivates the need for constraints and regularisation on GAN generators.
Probabilistic Attention for Interactive Segmentation
Jul 02, 2021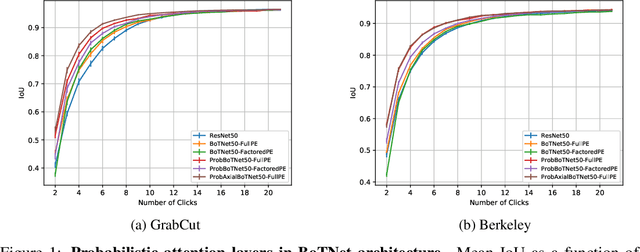
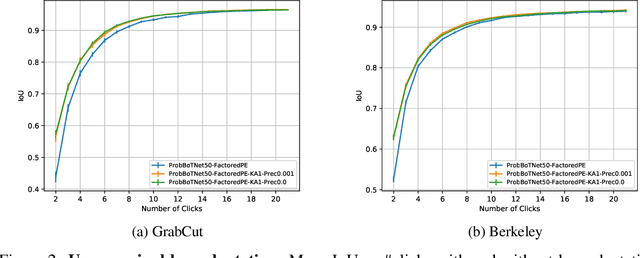
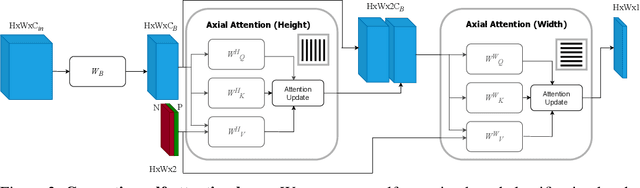
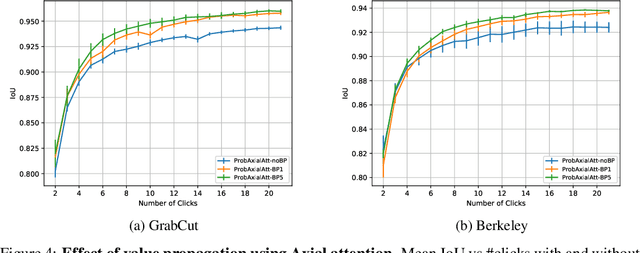
We provide a probabilistic interpretation of attention and show that the standard dot-product attention in transformers is a special case of Maximum A Posteriori (MAP) inference. The proposed approach suggests the use of Expectation Maximization algorithms for online adaptation of key and value model parameters. This approach is useful for cases in which external agents, e.g., annotators, provide inference-time information about the correct values of some tokens, e.g, the semantic category of some pixels, and we need for this new information to propagate to other tokens in a principled manner. We illustrate the approach on an interactive semantic segmentation task in which annotators and models collaborate online to improve annotation efficiency. Using standard benchmarks, we observe that key adaptation boosts model performance ($\sim10\%$ mIoU) in the low feedback regime and value propagation improves model responsiveness in the high feedback regime. A PyTorch layer implementation of our probabilistic attention model will be made publicly available here: https://github.com/apple/ml-probabilistic-attention.
Sparse Feature Factorization for Recommender Systems with Knowledge Graphs
Jul 29, 2021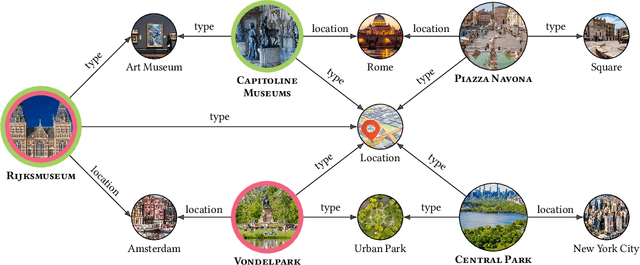
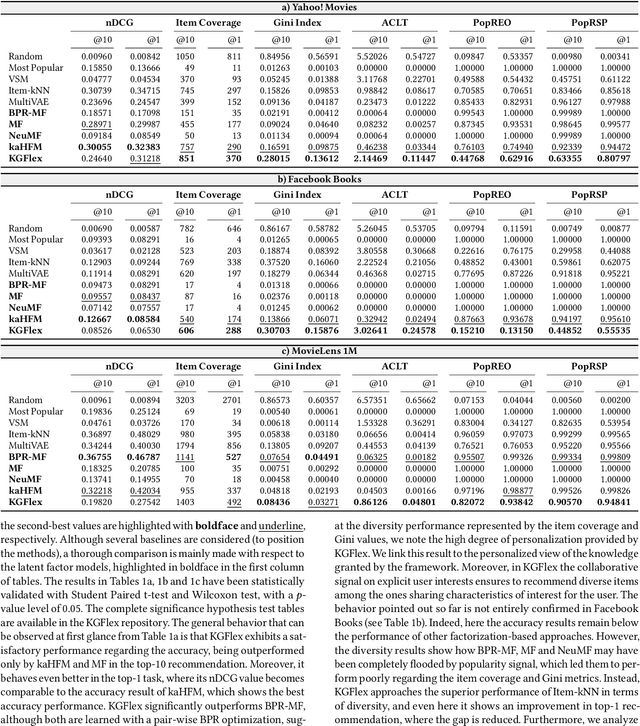
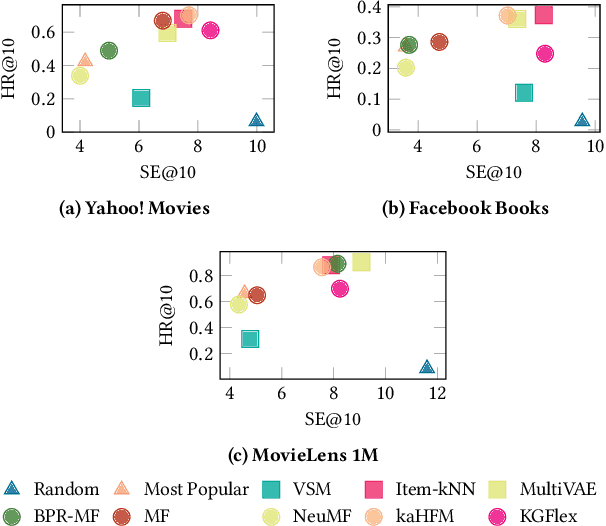
Deep Learning and factorization-based collaborative filtering recommendation models have undoubtedly dominated the scene of recommender systems in recent years. However, despite their outstanding performance, these methods require a training time proportional to the size of the embeddings and it further increases when also side information is considered for the computation of the recommendation list. In fact, in these cases we have that with a large number of high-quality features, the resulting models are more complex and difficult to train. This paper addresses this problem by presenting KGFlex: a sparse factorization approach that grants an even greater degree of expressiveness. To achieve this result, KGFlex analyzes the historical data to understand the dimensions the user decisions depend on (e.g., movie direction, musical genre, nationality of book writer). KGFlex represents each item feature as an embedding and it models user-item interactions as a factorized entropy-driven combination of the item attributes relevant to the user. KGFlex facilitates the training process by letting users update only those relevant features on which they base their decisions. In other words, the user-item prediction is mediated by the user's personal view that considers only relevant features. An extensive experimental evaluation shows the approach's effectiveness, considering the recommendation results' accuracy, diversity, and induced bias. The public implementation of KGFlex is available at https://split.to/kgflex.
Real-time Approximate Bayesian Computation for Scene Understanding
May 22, 2019



Consider scene understanding problems such as predicting where a person is probably reaching, or inferring the pose of 3D objects from depth images, or inferring the probable street crossings of pedestrians at a busy intersection. This paper shows how to solve these problems using Approximate Bayesian Computation. The underlying generative models are built from realistic simulation software, wrapped in a Bayesian error model for the gap between simulation outputs and real data. The simulators are drawn from off-the-shelf computer graphics, video game, and traffic simulation code. The paper introduces two techniques for speeding up inference that can be used separately or in combination. The first is to train neural surrogates of the simulators, using a simple form of domain randomization to make the surrogates more robust to the gap between the simulation and reality. The second is to adaptively discretize the latent variables using a Tree-pyramid approach adapted from computer graphics. This paper also shows performance and accuracy measurements on real-world problems, establishing that it is feasible to solve these problems in real-time.
Design of Real-time Semantic Segmentation Decoder for Automated Driving
Jan 19, 2019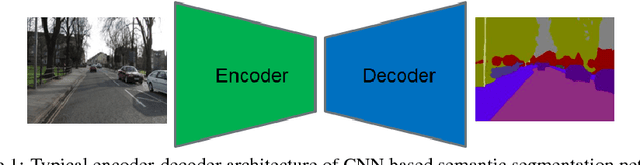
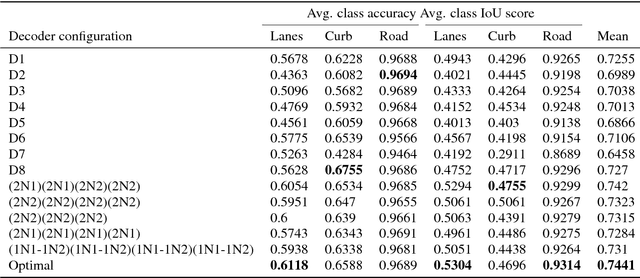
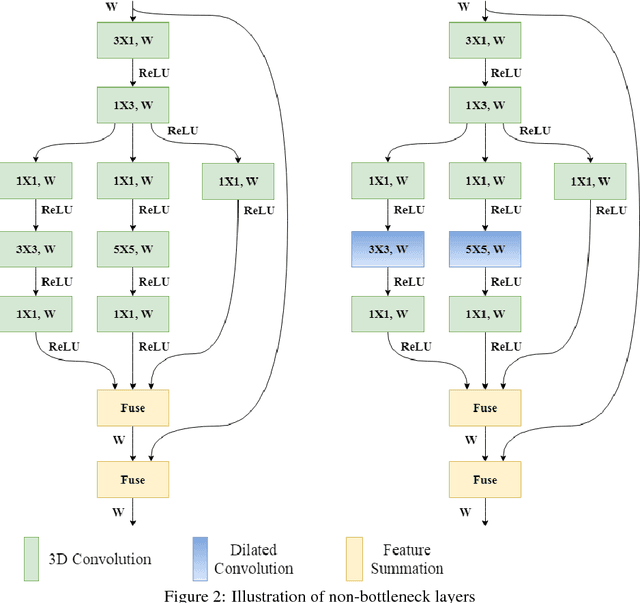
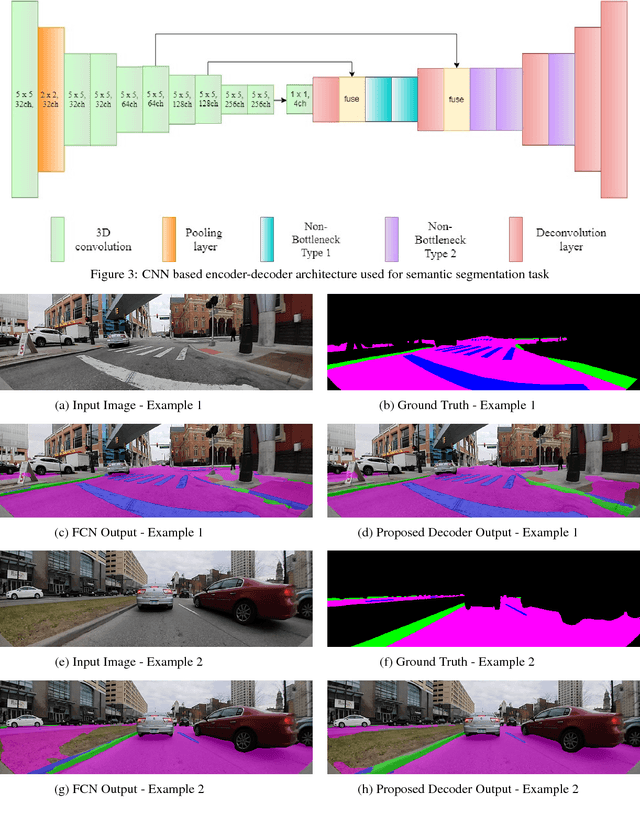
Semantic segmentation remains a computationally intensive algorithm for embedded deployment even with the rapid growth of computation power. Thus efficient network design is a critical aspect especially for applications like automated driving which requires real-time performance. Recently, there has been a lot of research on designing efficient encoders that are mostly task agnostic. Unlike image classification and bounding box object detection tasks, decoders are computationally expensive as well for semantic segmentation task. In this work, we focus on efficient design of the segmentation decoder and assume that an efficient encoder is already designed to provide shared features for a multi-task learning system. We design a novel efficient non-bottleneck layer and a family of decoders which fit into a small run-time budget using VGG10 as efficient encoder. We demonstrate in our dataset that experimentation with various design choices led to an improvement of 10\% from a baseline performance.