 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Solution for Non-Square, Dense Systems of Linear Equations, with applications in Feature Selection
Apr 26, 2021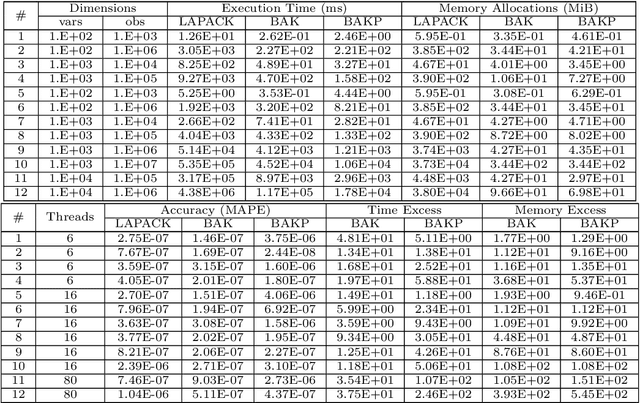
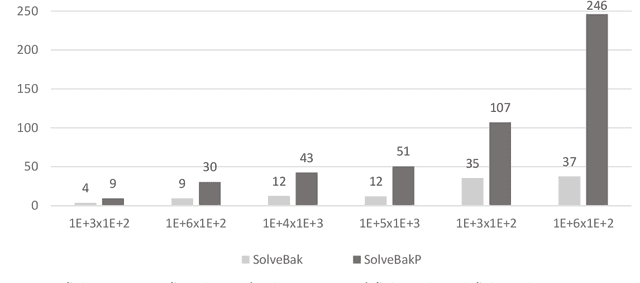
We present a novel algorithm attaining excessively fast, the sought solution of linear systems of equations. The algorithm is short in its basic formulation and by definition vectorised, while the memory allocation demands trivial, because for each iteration only one dimension of the given input matrix $\mathbf x$ is utilized. The execution time is very short compared with state-of-the-art methods, exhibiting up to $\mathcal{O}(10^3)$ speed-up and low memory allocation demands, especially for non-square Systems of Linear Equations, with ratio of equations versus features high (tall systems), or low (wide systems) accordingly. The accuracy is high and straightforwardly controlled, and the numerical results highlight the efficiency of the proposed algorithm, in terms of computation time, solution accuracy and memory allocations demands. The parallelisation of the algorithm is also presented in multi-threaded and GPU accelerators' setting. The paper also comprises a theoretical proof for the algorithmic convergence. Finally, we extend the implementation of the proposed algorithmic rationale to feature selection tasks.
Training-Free Artificial Neural Networks
Nov 05, 2019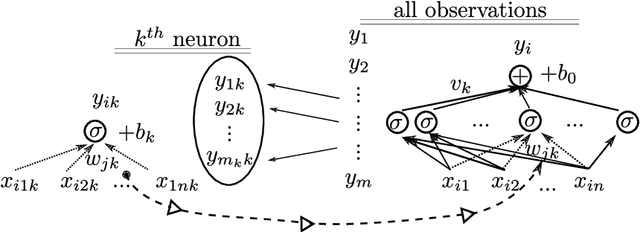

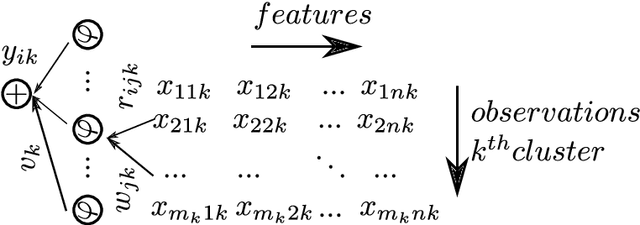
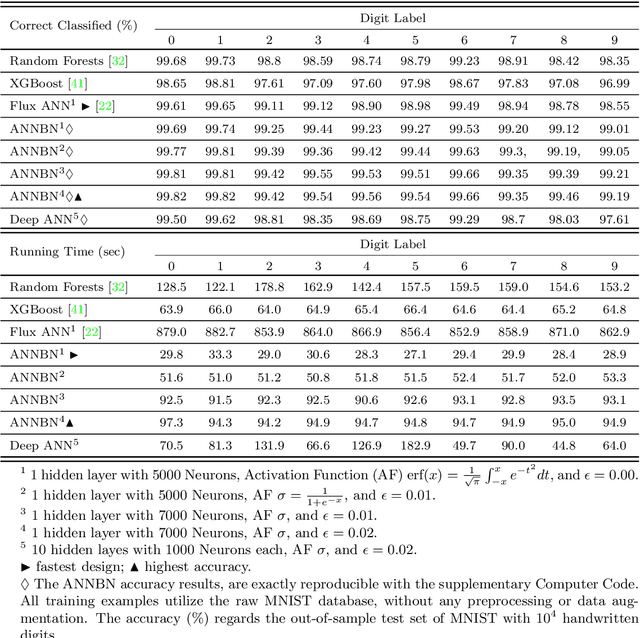
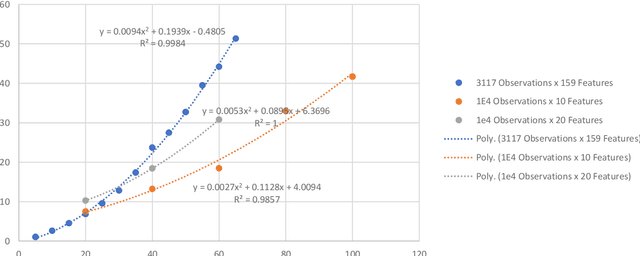
This paper presents a numerical scheme for the computation of Artificial Neural Networks' weights, without a laborious iterative procedure. The proposed algorithm adheres to the underlying theory, is highly fast, and results in remarkably low errors when applied for regression and classification of complex data-sets, such as the Griewank function of multiple variables $\mathbf{x} \in \mathbb{R}^{100}$ with random noise addition, and MNIST database for handwritten digits recognition, with $7\times10^4$ images. Interestingly, the same mathematical formulation found capable of approximating highly nonlinear functions in multiple dimensions, with low errors (e.g. $10^{-10}$) for the test set of the unknown functions, their higher-order partial derivatives, as well as numerically solving Partial Differential Equations. The method is based on the calculation of the weights of each neuron, in small neighborhoods of data, such that the corresponding local approximation matrix is invertible. Accordingly, the hyperparameters optimization is not necessary, as the neurons' number stems directly from the dimensions of the data, further improving the algorithmic speed. The overfitting is inherently eliminated, and the results are interpretable and reproducible. The complexity of the proposed algorithm is of class P with $\mathcal{O}(mn^3)$ computing time, which is linear for the observations and cubic for the features, in contrast with the NP-Complete class of standard algorithms for training ANNs. The performance of the method is high, for small as well as big datasets, and the test-set errors are similar or smaller than the train errors indicating the generalization efficiency. The supplementary computer code in Julia Language, may reproduce the validation examples, and run for other data-sets