 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Grasp Pose Estimation for Novel Objects in Densely Cluttered Environment
Jan 03, 2020

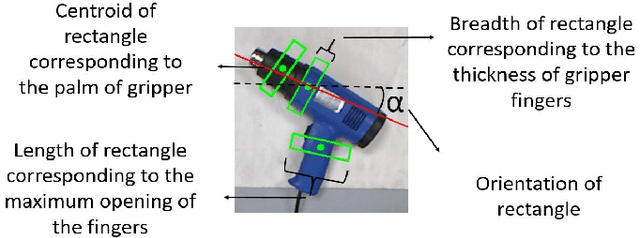
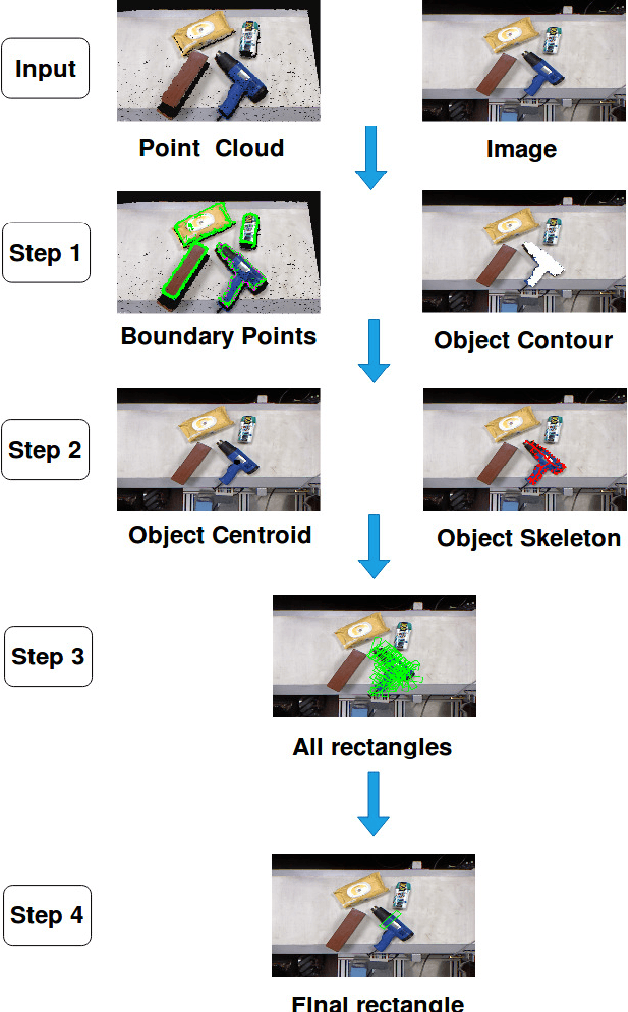
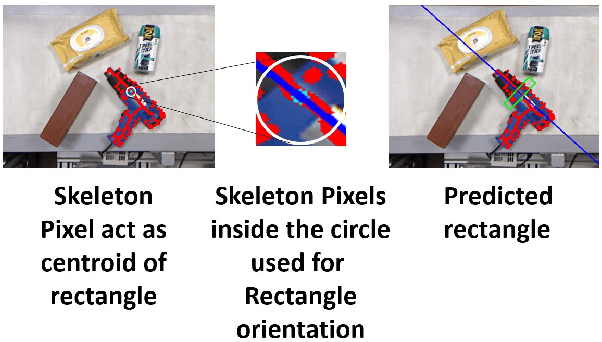
Grasping of novel objects in pick and place applications is a fundamental and challenging problem in robotics, specifically for complex-shaped objects. It is observed that the well-known strategies like \textit{i}) grasping from the centroid of object and \textit{ii}) grasping along the major axis of the object often fails for complex-shaped objects. In this paper, a real-time grasp pose estimation strategy for novel objects in robotic pick and place applications is proposed. The proposed technique estimates the object contour in the point cloud and predicts the grasp pose along with the object skeleton in the image plane. The technique is tested for the objects like ball container, hand weight, tennis ball and even for complex shape objects like blower (non-convex shape). It is observed that the proposed strategy performs very well for complex shaped objects and predicts the valid grasp configurations in comparison with the above strategies. The experimental validation of the proposed grasping technique is tested in two scenarios, when the objects are placed distinctly and when the objects are placed in dense clutter. A grasp accuracy of 88.16\% and 77.03\% respectively are reported. All the experiments are performed with a real UR10 robot manipulator along with WSG-50 two-finger gripper for grasping of objects.
Improving Accuracy of Permutation DAG Search using Best Order Score Search
Aug 17, 2021The Sparsest Permutation (SP) algorithm is accurate but limited to about 9 variables in practice; the Greedy Sparest Permutation (GSP) algorithm is faster but less weak theoretically. A compromise can be given, the Best Order Score Search, which gives results as accurate as SP but for much larger and denser graphs. BOSS (Best Order Score Search) is more accurate for two reason: (a) It assumes the "brute faithfuness" assumption, which is weaker than faithfulness, and (b) it uses a different traversal of permutations than the depth first traversal used by GSP, obtained by taking each variable in turn and moving it to the position in the permutation that optimizes the model score. Results are given comparing BOSS to several related papers in the literature in terms of performance, for linear, Gaussian data. In all cases, with the proper parameter settings, accuracy of BOSS is lifted considerably with respect to competing approaches. In configurations tested, models with 60 variables are feasible with large samples out to about an average degree of 12 in reasonable time, with near-perfect accuracy, and sparse models with an average degree of 4 are feasible out to about 300 variables on a laptop, again with near-perfect accuracy. Mixed continuous discrete and all-discrete datasets were also tested. The mixed data analysis showed advantage for BOSS over GES more apparent at higher depths with the same score; the discrete data analysis showed a very small advantage for BOSS over GES with the same score, perhaps not enough to prefer it.
Structured World Belief for Reinforcement Learning in POMDP
Jul 19, 2021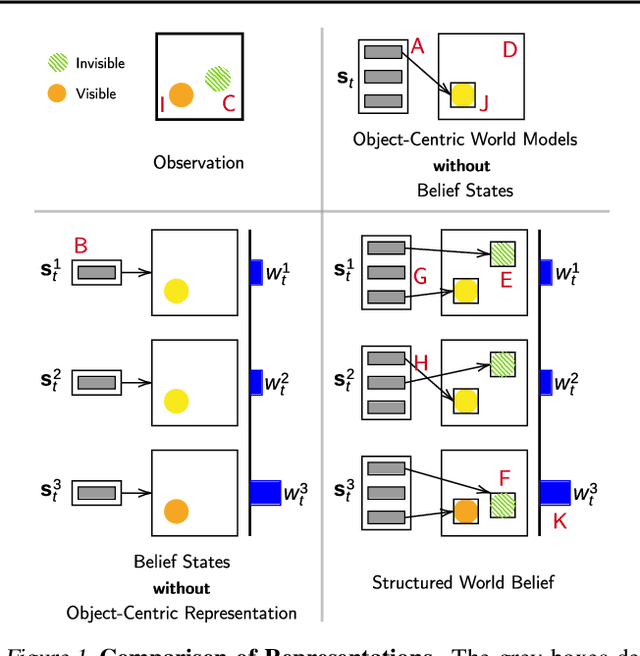
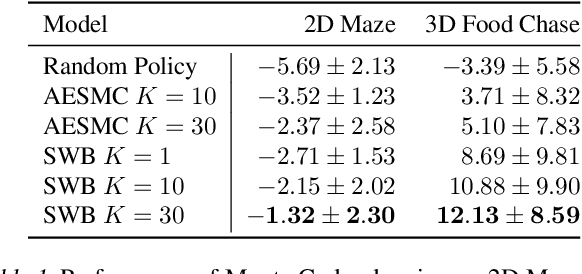
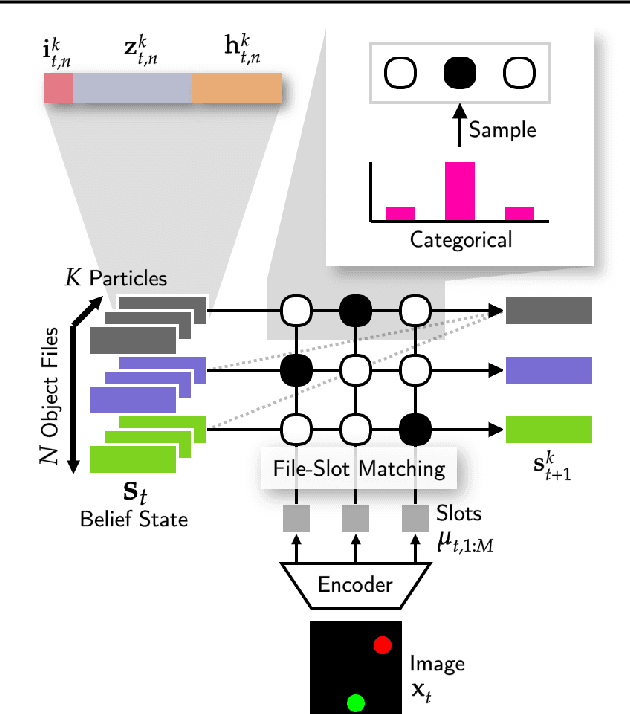

Object-centric world models provide structured representation of the scene and can be an important backbone in reinforcement learning and planning. However, existing approaches suffer in partially-observable environments due to the lack of belief states. In this paper, we propose Structured World Belief, a model for learning and inference of object-centric belief states. Inferred by Sequential Monte Carlo (SMC), our belief states provide multiple object-centric scene hypotheses. To synergize the benefits of SMC particles with object representations, we also propose a new object-centric dynamics model that considers the inductive bias of object permanence. This enables tracking of object states even when they are invisible for a long time. To further facilitate object tracking in this regime, we allow our model to attend flexibly to any spatial location in the image which was restricted in previous models. In experiments, we show that object-centric belief provides a more accurate and robust performance for filtering and generation. Furthermore, we show the efficacy of structured world belief in improving the performance of reinforcement learning, planning and supervised reasoning.
Segmentation of Shoulder Muscle MRI Using a New Region and Edge based Deep Auto-Encoder
Aug 26, 2021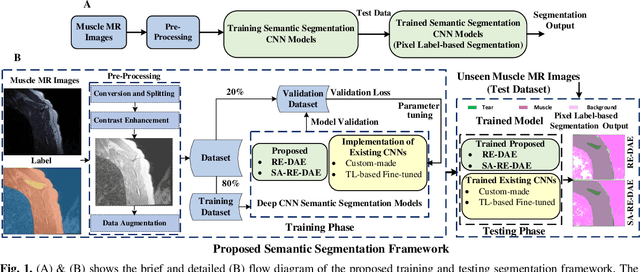
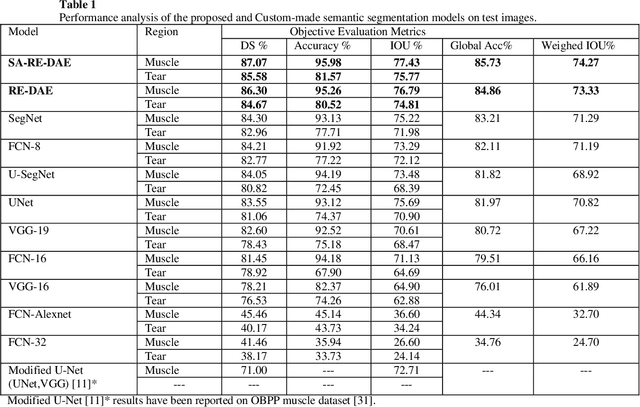
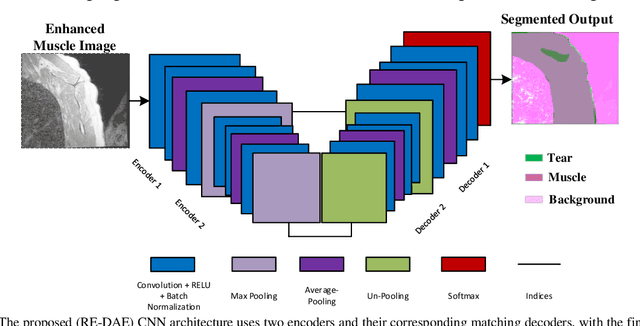
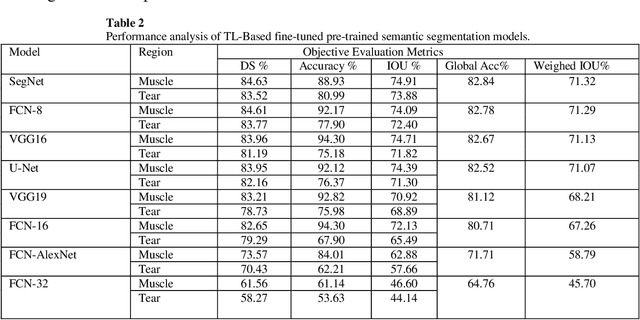
Automatic segmentation of shoulder muscle MRI is challenging due to the high variation in muscle size, shape, texture, and spatial position of tears. Manual segmentation of tear and muscle portion is hard, time-consuming, and subjective to pathological expertise. This work proposes a new Region and Edge-based Deep Auto-Encoder (RE-DAE) for shoulder muscle MRI segmentation. The proposed RE-DAE harmoniously employs average and max-pooling operation in the encoder and decoder blocks of the Convolutional Neural Network (CNN). Region-based segmentation incorporated in the Deep Auto-Encoder (DAE) encourages the network to extract smooth and homogenous regions. In contrast, edge-based segmentation tries to learn the boundary and anatomical information. These two concepts, systematically combined in a DAE, generate a discriminative and sparse hybrid feature space (exploiting both region homogeneity and boundaries). Moreover, the concept of static attention is exploited in the proposed RE-DAE that helps in effectively learning the tear region. The performances of the proposed MRI segmentation based DAE architectures have been tested using a 3D MRI shoulder muscle dataset using the hold-out cross-validation technique. The MRI data has been collected from the Korea University Anam Hospital, Seoul, South Korea. Experimental comparisons have been conducted by employing innovative custom-made and existing pre-trained CNN architectures both using transfer learning and fine-tuning. Objective evaluation on the muscle datasets using the proposed SA-RE-DAE showed a dice similarity of 85.58% and 87.07%, an accuracy of 81.57% and 95.58% for tear and muscle regions, respectively. The high visual quality and the objective result suggest that the proposed SA-RE-DAE is able to correctly segment tear and muscle regions in shoulder muscle MRI for better clinical decisions.
Scaling Scaling Laws with Board Games
Apr 15, 2021
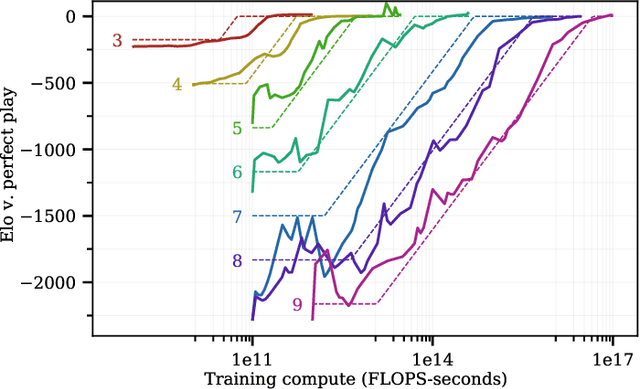
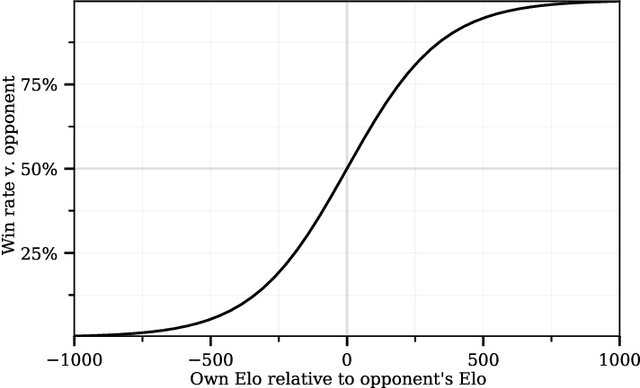
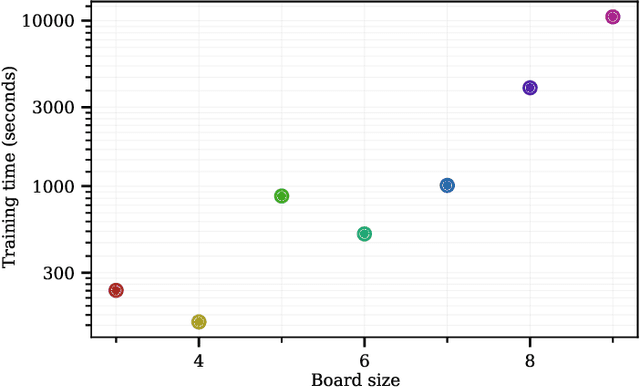
The largest experiments in machine learning now require resources far beyond the budget of all but a few institutions. Fortunately, it has recently been shown that the results of these huge experiments can often be extrapolated from the results of a sequence of far smaller, cheaper experiments. In this work, we show that not only can the extrapolation be done based on the size of the model, but on the size of the problem as well. By conducting a sequence of experiments using AlphaZero and Hex, we show that the performance achievable with a fixed amount of compute degrades predictably as the game gets larger and harder. Along with our main result, we further show that the test-time and train-time compute available to an agent can be traded off while maintaining performance.
A Survey on Machine Learning Algorithms for Applications in Cognitive Radio Networks
Jun 19, 2021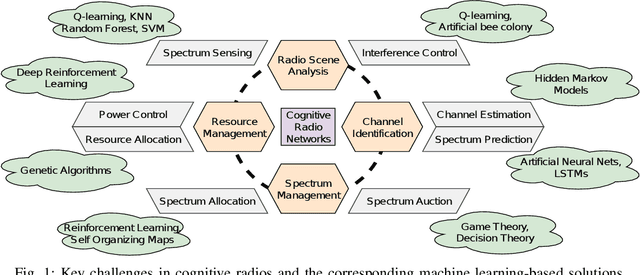
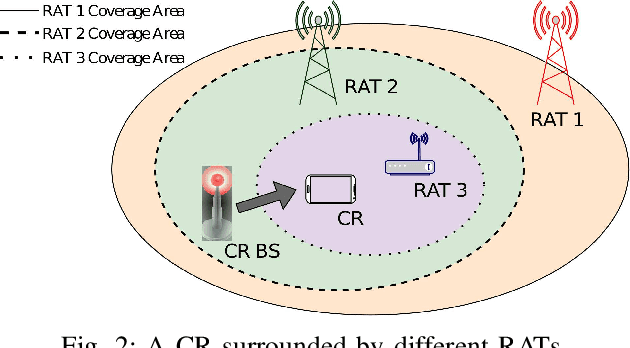
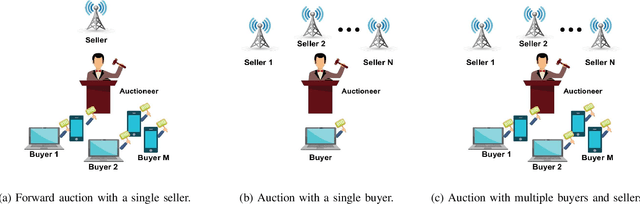
In this paper, we present a survey on the utility of machine learning (ML) algorithms for applications in cognitive radio networks (CRN). We start with a high-level overview of some of the major challenges in CRNs, and mention the ML architectures and algorithms that can be used to alleviate them. In particular, our focus is on two fundamental applications in CRNs, namely spectrum sensing -- with non-cooperative and cooperative scenarios, and dynamic spectrum access -- with spectrum auction and prediction. We present a detailed study of recent advancements in the field of ML in CRNs for these applications, and briefly discuss the set of challenges in real-time implementation of ML techniques for CRNs.
MALI: A memory efficient and reverse accurate integrator for Neural ODEs
Mar 03, 2021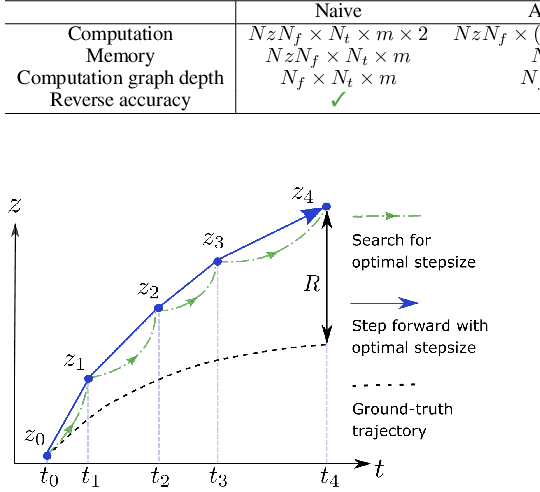
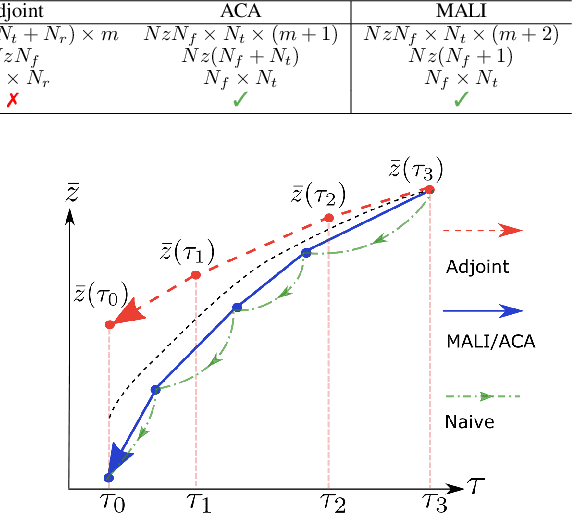
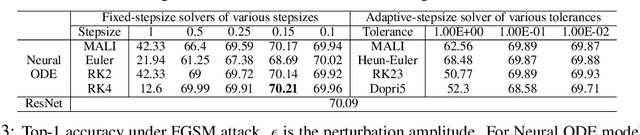
Neural ordinary differential equations (Neural ODEs) are a new family of deep-learning models with continuous depth. However, the numerical estimation of the gradient in the continuous case is not well solved: existing implementations of the adjoint method suffer from inaccuracy in reverse-time trajectory, while the naive method and the adaptive checkpoint adjoint method (ACA) have a memory cost that grows with integration time. In this project, based on the asynchronous leapfrog (ALF) solver, we propose the Memory-efficient ALF Integrator (MALI), which has a constant memory cost \textit{w.r.t} number of solver steps in integration similar to the adjoint method, and guarantees accuracy in reverse-time trajectory (hence accuracy in gradient estimation). We validate MALI in various tasks: on image recognition tasks, to our knowledge, MALI is the first to enable feasible training of a Neural ODE on ImageNet and outperform a well-tuned ResNet, while existing methods fail due to either heavy memory burden or inaccuracy; for time series modeling, MALI significantly outperforms the adjoint method; and for continuous generative models, MALI achieves new state-of-the-art performance. We provide a pypi package at \url{https://jzkay12.github.io/TorchDiffEqPack/}
* https://openreview.net/forum?id=blfSjHeFM_e
E(n) Equivariant Normalizing Flows
Jun 08, 2021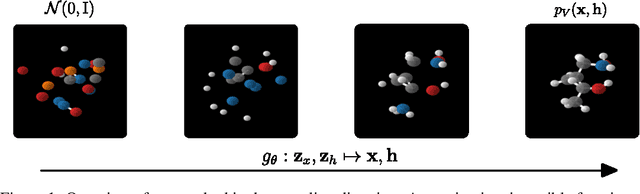
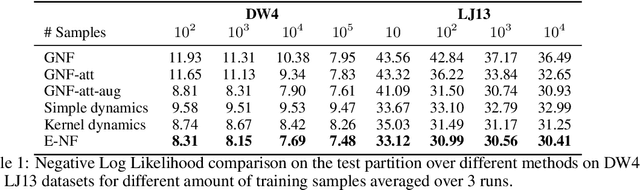

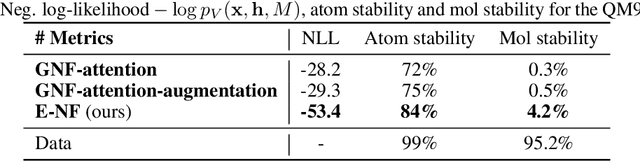
This paper introduces a generative model equivariant to Euclidean symmetries: E(n) Equivariant Normalizing Flows (E-NFs). To construct E-NFs, we take the discriminative E(n) graph neural networks and integrate them as a differential equation to obtain an invertible equivariant function: a continuous-time normalizing flow. We demonstrate that E-NFs considerably outperform baselines and existing methods from the literature on particle systems such as DW4 and LJ13, and on molecules from QM9 in terms of log-likelihood. To the best of our knowledge, this is the first flow that jointly generates molecule features and positions in 3D.
DIODE: Dilatable Incremental Object Detection
Aug 12, 2021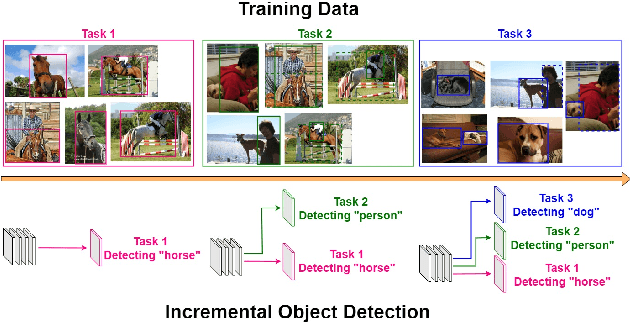



To accommodate rapid changes in the real world, the cognition system of humans is capable of continually learning concepts. On the contrary, conventional deep learning models lack this capability of preserving previously learned knowledge. When a neural network is fine-tuned to learn new tasks, its performance on previously trained tasks will significantly deteriorate. Many recent works on incremental object detection tackle this problem by introducing advanced regularization. Although these methods have shown promising results, the benefits are often short-lived after the first incremental step. Under multi-step incremental learning, the trade-off between old knowledge preserving and new task learning becomes progressively more severe. Thus, the performance of regularization-based incremental object detectors gradually decays for subsequent learning steps. In this paper, we aim to alleviate this performance decay on multi-step incremental detection tasks by proposing a dilatable incremental object detector (DIODE). For the task-shared parameters, our method adaptively penalizes the changes of important weights for previous tasks. At the same time, the structure of the model is dilated or expanded by a limited number of task-specific parameters to promote new task learning. Extensive experiments on PASCAL VOC and COCO datasets demonstrate substantial improvements over the state-of-the-art methods. Notably, compared with the state-of-the-art methods, our method achieves up to 6.0% performance improvement by increasing the number of parameters by just 1.2% for each newly learned task.
Hybrid Autoregressive Solver for Scalable Abductive Natural Language Inference
Jul 25, 2021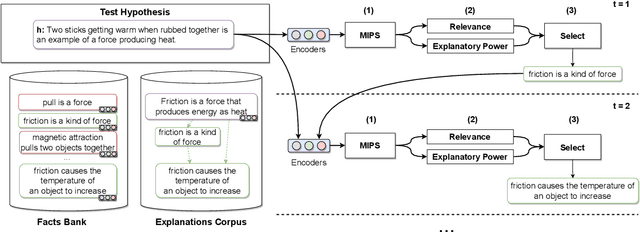

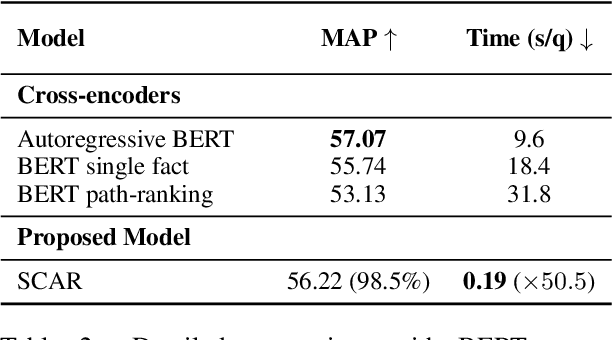
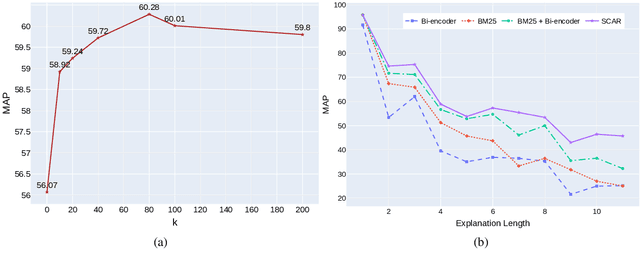
Regenerating natural language explanations for science questions is a challenging task for evaluating complex multi-hop and abductive inference capabilities. In this setting, Transformers trained on human-annotated explanations achieve state-of-the-art performance when adopted as cross-encoder architectures. However, while much attention has been devoted to the quality of the constructed explanations, the problem of performing abductive inference at scale is still under-studied. As intrinsically not scalable, the cross-encoder architectural paradigm is not suitable for efficient multi-hop inference on massive facts banks. To maximise both accuracy and inference time, we propose a hybrid abductive solver that autoregressively combines a dense bi-encoder with a sparse model of explanatory power, computed leveraging explicit patterns in the explanations. Our experiments demonstrate that the proposed framework can achieve performance comparable with the state-of-the-art cross-encoder while being $\approx 50$ times faster and scalable to corpora of millions of facts. Moreover, we study the impact of the hybridisation on semantic drift and science question answering without additional training, showing that it boosts the quality of the explanations and contributes to improved downstream inference performance.