 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Generalization of Change-Point Detection in Time Series Data Based on Direct Density Ratio Estimation
Jan 17, 2020
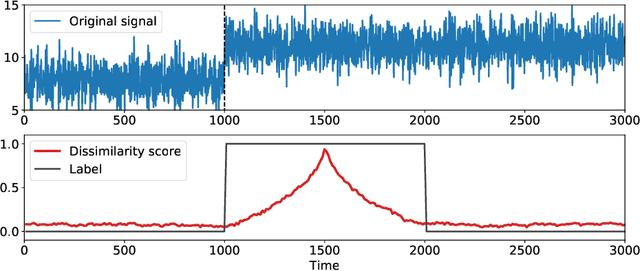
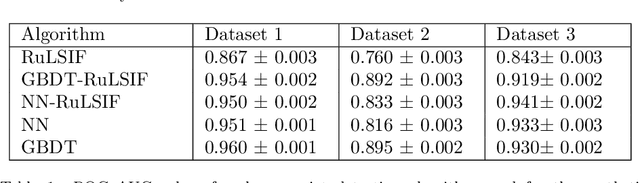
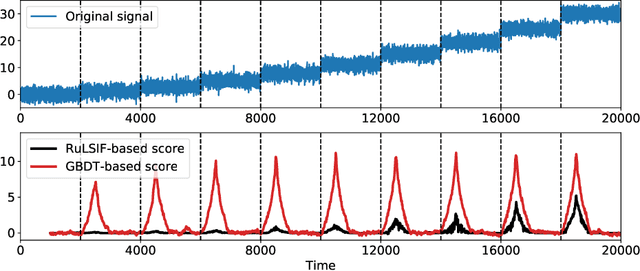
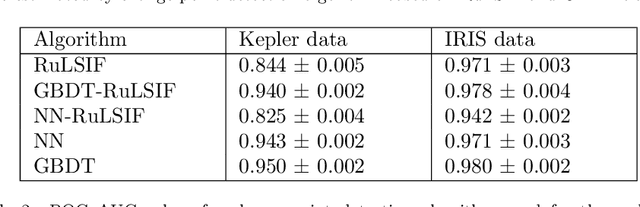
The goal of the change-point detection is to discover changes of time series distribution. One of the state of the art approaches of the change-point detection are based on direct density ratio estimation. In this work we show how existing algorithms can be generalized using various binary classification and regression models. In particular, we show that the Gradient Boosting over Decision Trees and Neural Networks can be used for this purpose. The algorithms are tested on several synthetic and real-world datasets. The results show that the proposed methods outperform classical RuLSIF algorithm. Discussion of cases where the proposed algorithms have advantages over existing methods are also provided.
RSKNet-MTSP: Effective and Portable Deep Architecture for Speaker Verification
Aug 30, 2021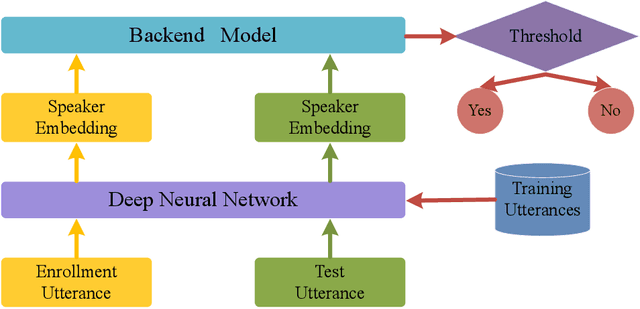
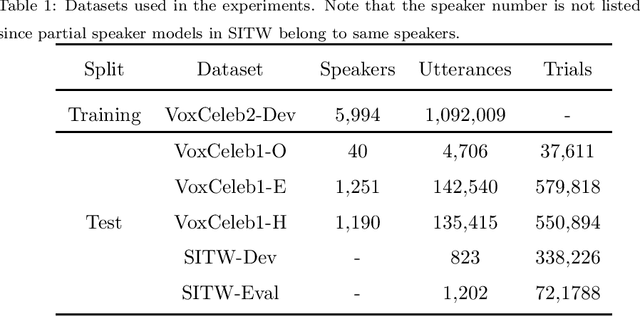
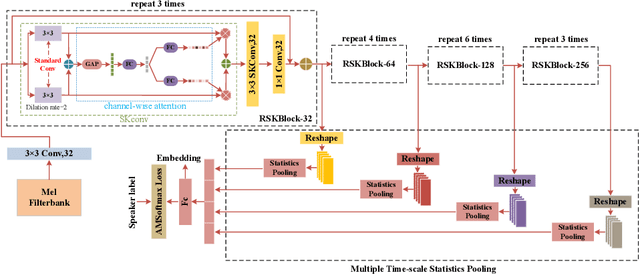

The convolutional neural network (CNN) based approaches have shown great success for speaker verification (SV) tasks, where modeling long temporal context and reducing information loss of speaker characteristics are two important challenges significantly affecting the verification performance. Previous works have introduced dilated convolution and multi-scale aggregation methods to address above challenges. However, such methods are also hard to make full use of some valuable information, which make it difficult to substantially improve the verification performance. To address above issues, we construct a novel CNN-based architecture for SV, called RSKNet-MTSP, where a residual selective kernel block (RSKBlock) and a multiple time-scale statistics pooling (MTSP) module are first proposed. The RSKNet-MTSP can capture both long temporal context and neighbouring information, and gather more speaker-discriminative information from multi-scale features. In order to design a portable model for real applications with limited resources, we then present a lightweight version of RSKNet-MTSP, namely RSKNet-MTSP-L, which employs a combination technique associating the depthwise separable convolutions with low-rank factorization of weight matrices. Extensive experiments are conducted on two public SV datasets, VoxCeleb and Speaker in the Wild (SITW). The results demonstrate that 1) RSKNet-MTSP outperforms the state-of-the-art deep embedding architectures by at least 9%-26% in all test sets. 2) RSKNet-MTSP-L achieves competitive performance compared with baseline models with 17%-39% less network parameters. The ablation experiments further illustrate that our proposed approaches can achieve substantial improvement over prior methods.
Self-Supervised Multi-Frame Monocular Scene Flow
May 05, 2021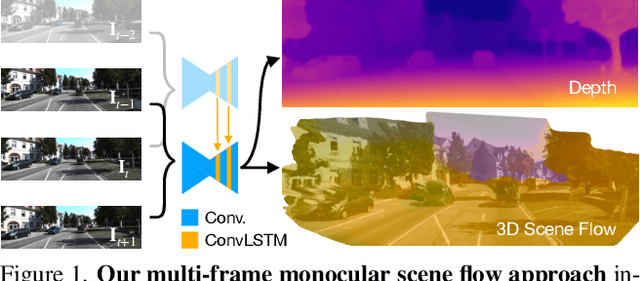

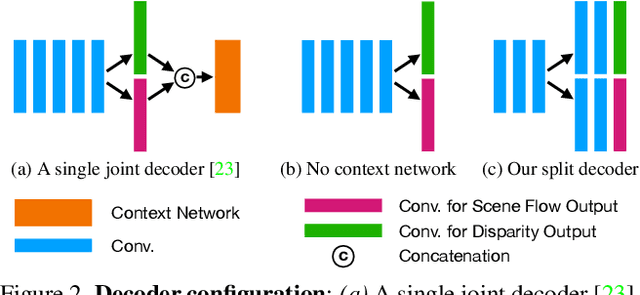
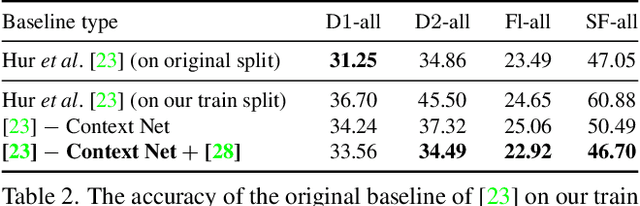
Estimating 3D scene flow from a sequence of monocular images has been gaining increased attention due to the simple, economical capture setup. Owing to the severe ill-posedness of the problem, the accuracy of current methods has been limited, especially that of efficient, real-time approaches. In this paper, we introduce a multi-frame monocular scene flow network based on self-supervised learning, improving the accuracy over previous networks while retaining real-time efficiency. Based on an advanced two-frame baseline with a split-decoder design, we propose (i) a multi-frame model using a triple frame input and convolutional LSTM connections, (ii) an occlusion-aware census loss for better accuracy, and (iii) a gradient detaching strategy to improve training stability. On the KITTI dataset, we observe state-of-the-art accuracy among monocular scene flow methods based on self-supervised learning.
A Contactless Fingerprint Recognition System
Aug 20, 2021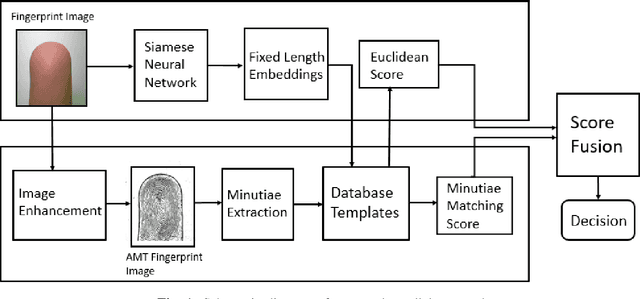
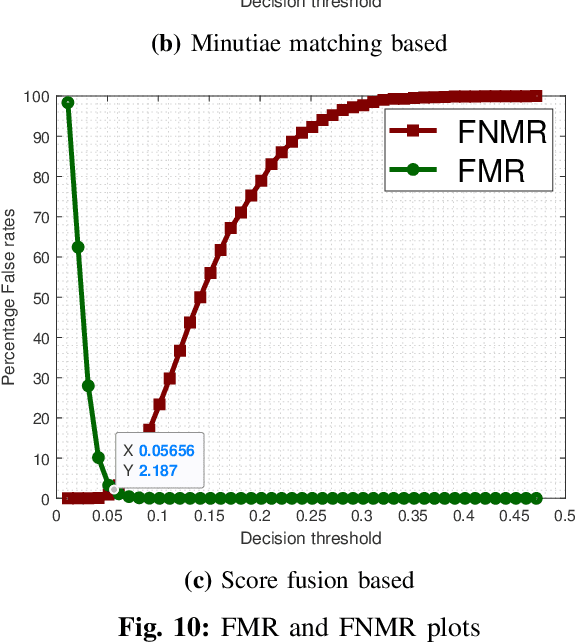
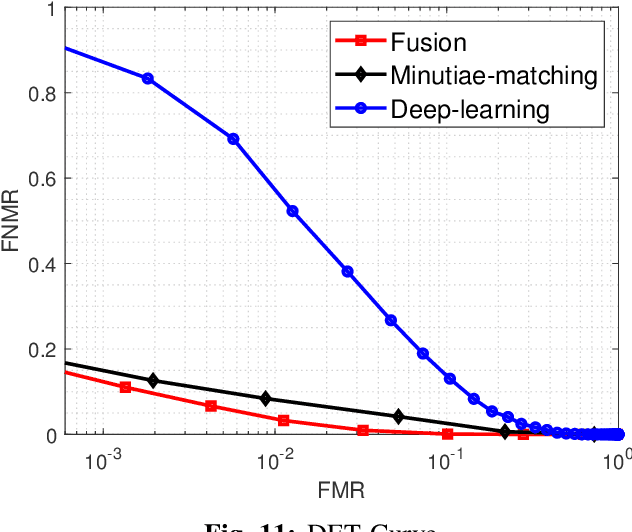
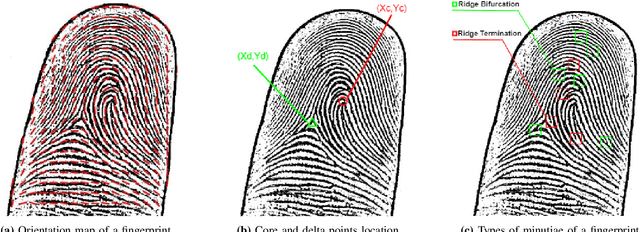
Fingerprints are one of the most widely explored biometric traits. Specifically, contact-based fingerprint recognition systems reign supreme due to their robustness, portability and the extensive research work done in the field. However, these systems suffer from issues such as hygiene, sensor degradation due to constant physical contact, and latent fingerprint threats. In this paper, we propose an approach for developing a contactless fingerprint recognition system that captures finger photo from a distance using an image sensor in a suitable environment. The captured finger photos are then processed further to obtain global and local (minutiae-based) features. Specifically, a Siamese convolutional neural network (CNN) is designed to extract global features from a given finger photo. The proposed system computes matching scores from CNN-based features and minutiae-based features. Finally, the two scores are fused to obtain the final matching score between the probe and reference fingerprint templates. Most importantly, the proposed system is developed using the Nvidia Jetson Nano development kit, which allows us to perform contactless fingerprint recognition in real-time with minimum latency and acceptable matching accuracy. The performance of the proposed system is evaluated on an in-house IITI contactless fingerprint dataset (IITI-CFD) containing 105train and 100 test subjects. The proposed system achieves an equal-error-rate of 2.19% on IITI-CFD.
Continuous Herded Gibbs Sampling
Jun 11, 2021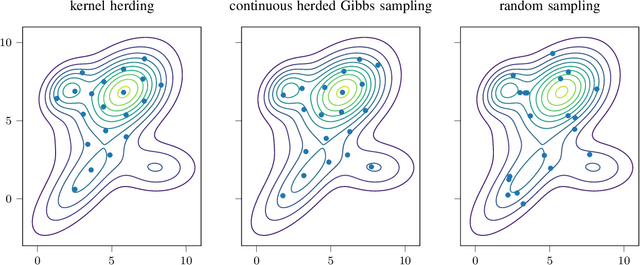
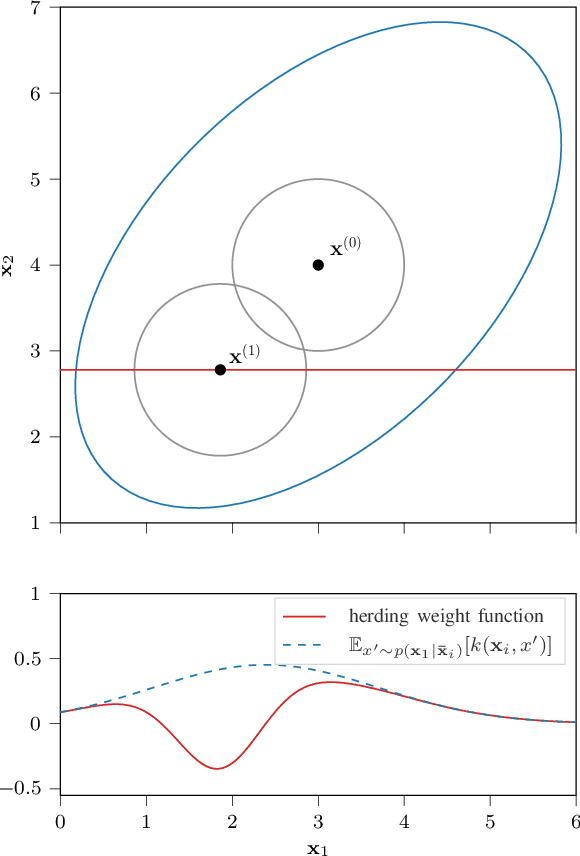
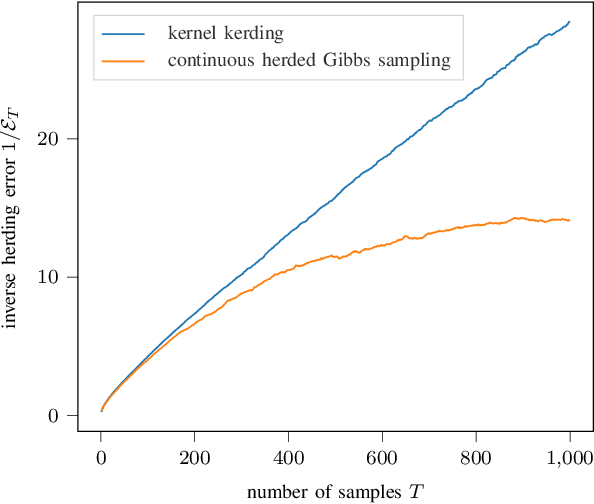
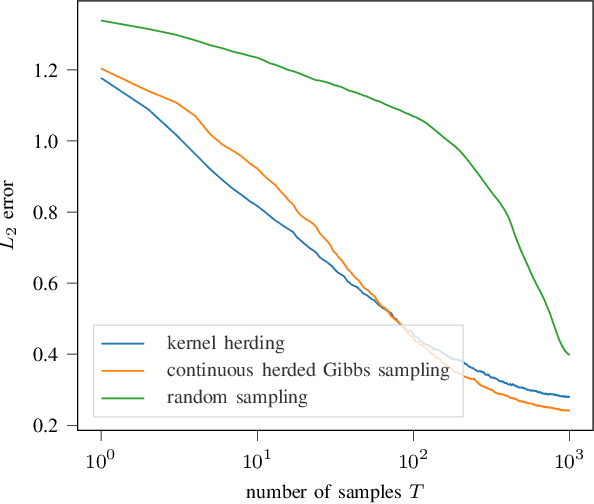
Herding is a technique to sequentially generate deterministic samples from a probability distribution. In this work, we propose a continuous herded Gibbs sampler, that combines kernel herding on continuous densities with Gibbs sampling. Our algorithm allows for deterministically sampling from high-dimensional multivariate probability densities, without directly sampling from the joint density. Experiments with Gaussian mixture densities indicate that the L2 error decreases similarly to kernel herding, while the computation time is significantly lower, i.e., linear in the number of dimensions.
A cloud-IoT platform for passive radio sensing: challenges and application case studies
Mar 26, 2021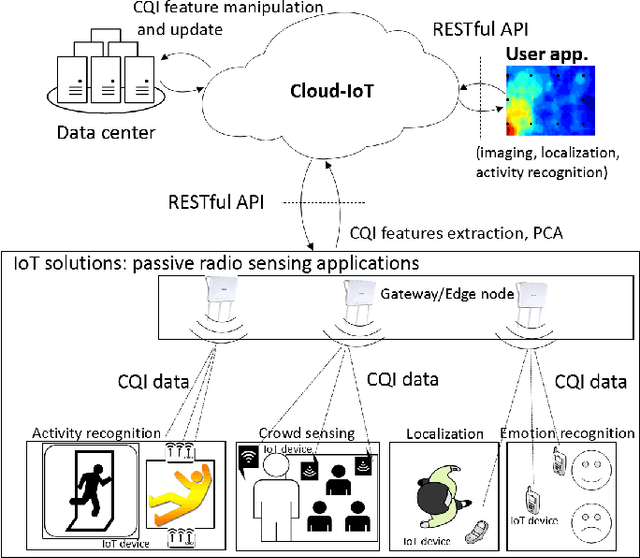
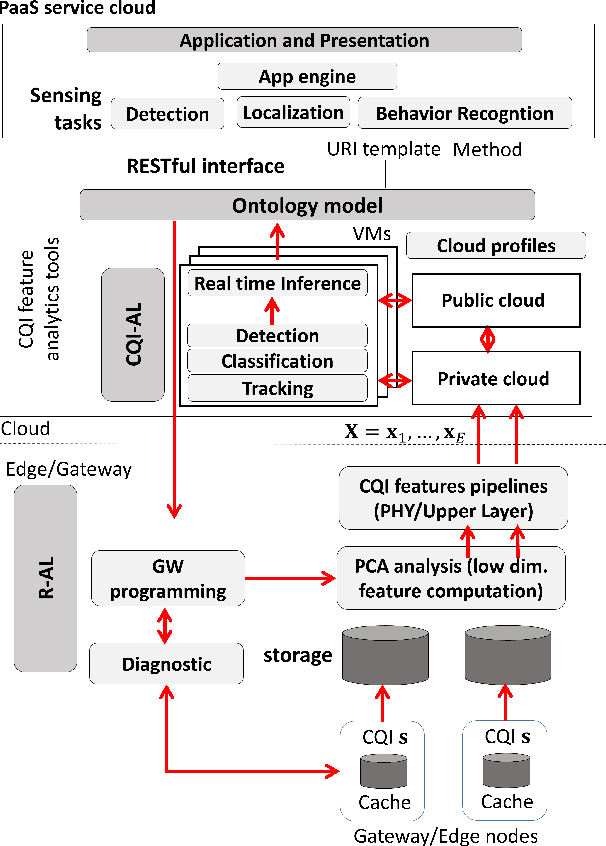
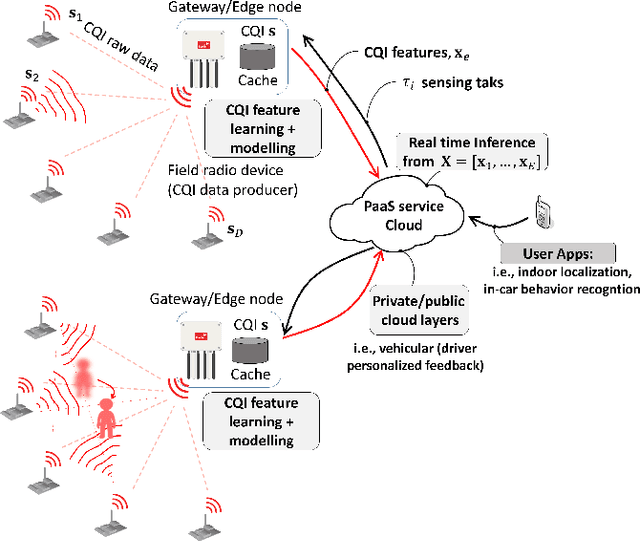
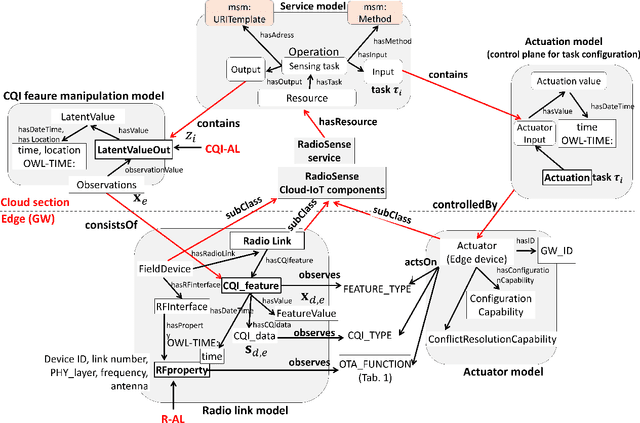
We propose a platform for the integration of passive radio sensing and vision technologies into a cloud-IoT framework that performs real-time channel quality information (CQI) time series processing and analytics. Radio sensing and vision technologies allow to passively detect and track objects or persons by using radio waves as probe signals that encode a 2D/3D view of the environment they propagate through. View reconstruction from the received radio signals, or CQI, is based on real-time data processing tools, that combine multiple radio measurements from possibly heterogeneous IoT networks. The proposed platform is designed to efficiently store and analyze CQI time series of different types and provides formal semantics for CQI data manipulation (ontology models). Post-processed data can be then accessible to third parties via JSON-REST calls. Finally, the proposed system supports the reconfiguration of CQI data collection based on the respective application. The performance of the proposed tools are evaluated through two experimental case studies that focus on assisted living applications in a smart-space environment and on driver behavior recognition for in-car control services. Both studies adopt and compare different CQI manipulation models and radio devices as supported by current and future (5G) standards.
Transmitter IQ Skew Calibration using Direct Detection
Jun 01, 2021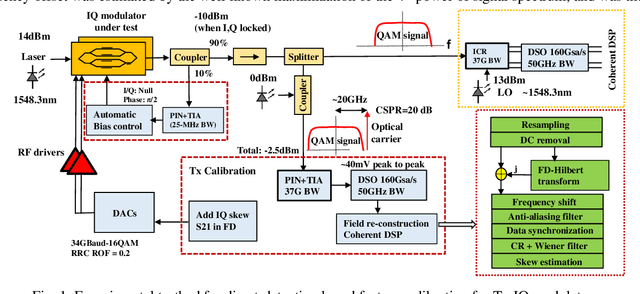
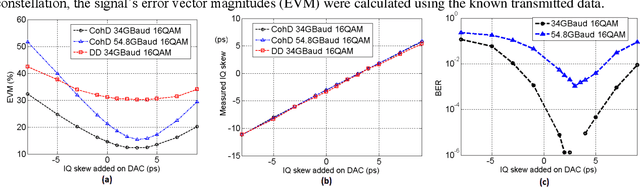
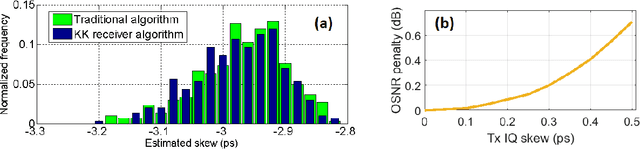
We propose a transmitter skew calibration based on direct detection of coherent signals with estimation errors of +/-0.2ps, providing a reliable, accurate and low-cost scheme to calibrate skew for coherent transceivers. In October 2019, this work was submitted / was exposed to Optical Fiber Communication Conference 2020 but an acceptance was not granted. We claimed the first time to use a direct detection-based feedback method for coherent transmitter calibration.
Perception Framework through Real-Time Semantic Segmentation and Scene Recognition on a Wearable System for the Visually Impaired
Mar 06, 2021

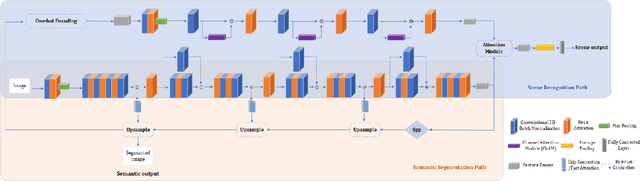
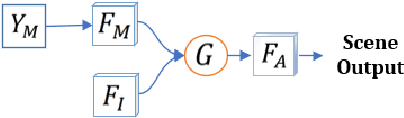
As the scene information, including objectness and scene type, are important for people with visual impairment, in this work we present a multi-task efficient perception system for the scene parsing and recognition tasks. Building on the compact ResNet backbone, our designed network architecture has two paths with shared parameters. In the structure, the semantic segmentation path integrates fast attention, with the aim of harvesting long-range contextual information in an efficient manner. Simultaneously, the scene recognition path attains the scene type inference by passing the semantic features into semantic-driven attention networks and combining the semantic extracted representations with the RGB extracted representations through a gated attention module. In the experiments, we have verified the systems' accuracy and efficiency on both public datasets and real-world scenes. This system runs on a wearable belt with an Intel RealSense LiDAR camera and an Nvidia Jetson AGX Xavier processor, which can accompany visually impaired people and provide assistive scene information in their navigation tasks.
High Performance Convolution Using Sparsity and Patterns for Inference in Deep Convolutional Neural Networks
Apr 16, 2021
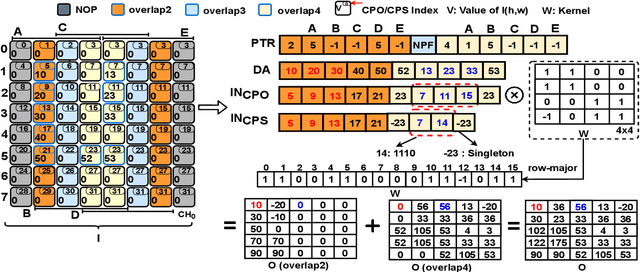
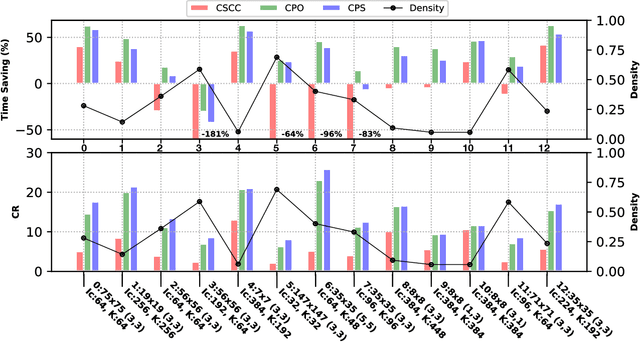
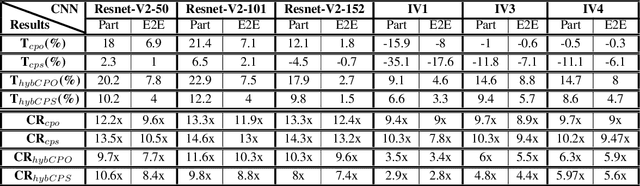
Deploying deep Convolutional Neural Networks (CNNs) is impacted by their memory footprint and speed requirements, which mainly come from convolution. Widely-used convolution algorithms, im2col and MEC, produce a lowered matrix from an activation map by redundantly storing the map's elements included at horizontal and/or vertical kernel overlappings without considering the sparsity of the map. Using the sparsity of the map, this paper proposes two new convolution algorithms dubbed Compressed Pattern Overlap (CPO) and Compressed Pattern Sets (CPS) that simultaneously decrease the memory footprint and increase the inference speed while preserving the accuracy. CPO recognizes non-zero elements (NZEs) at horizontal and vertical overlappings in the activation maps. CPS further improves the memory savings of CPO by compressing the index positions of neighboring NZEs. In both algorithms, channels/regions of the activation maps with all zeros are skipped. Then, CPO/CPS performs convolution via Sparse Matrix-Vector Multiplication (SpMv) done on their sparse representations. Experimental results conducted on CPUs show that average per-layer time savings reach up to 63% and Compression Ratio (CR) up to 26x with respect to im2col. In some layers, our average per layer CPO/CPS time savings are better by 28% and CR is better by 9.2x than the parallel implementation of MEC. For a given CNN's inference, we offline select for each convolution layer the best convolutional algorithm in terms of time between either CPO or CPS and im2col. Our algorithms were selected up to 56% of the non-pointwise convolutional layers. Our offline selections yield CNN inference time savings up to 9% and CR up to 10x.
Data-driven Neural Architecture Learning For Financial Time-series Forecasting
Mar 05, 2019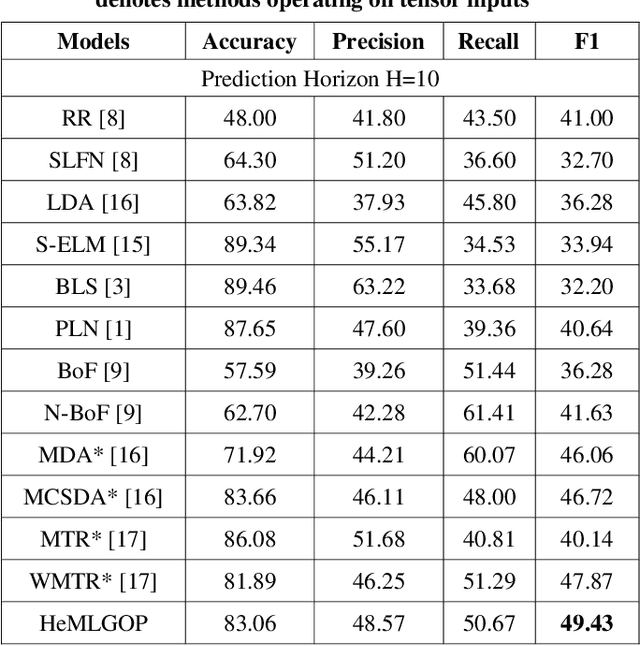
Forecasting based on financial time-series is a challenging task since most real-world data exhibits nonstationary property and nonlinear dependencies. In addition, different data modalities often embed different nonlinear relationships which are difficult to capture by human-designed models. To tackle the supervised learning task in financial time-series prediction, we propose the application of a recently formulated algorithm that adaptively learns a mapping function, realized by a heterogeneous neural architecture composing of Generalized Operational Perceptron, given a set of labeled data. With a modified objective function, the proposed algorithm can accommodate the frequently observed imbalanced data distribution problem. Experiments on a large-scale Limit Order Book dataset demonstrate that the proposed algorithm outperforms related algorithms, including tensor-based methods which have access to a broader set of input information.