 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adaptive Dynamic Programming for Model-free Tracking of Trajectories with Time-varying Parameters
Oct 28, 2019
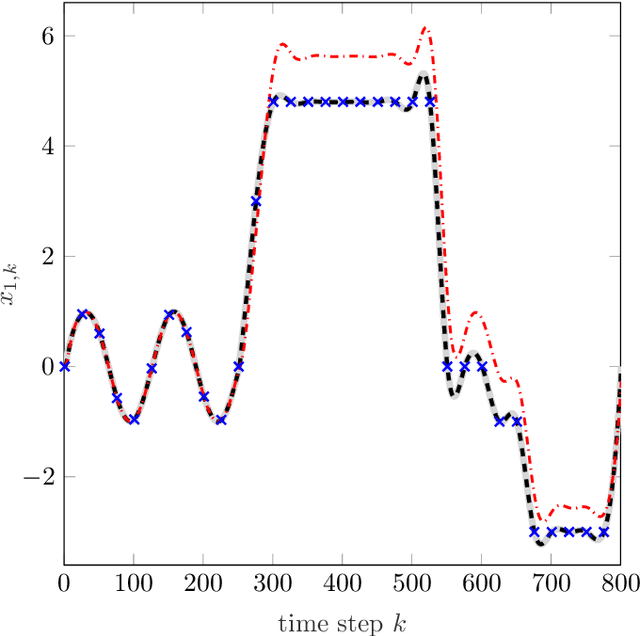
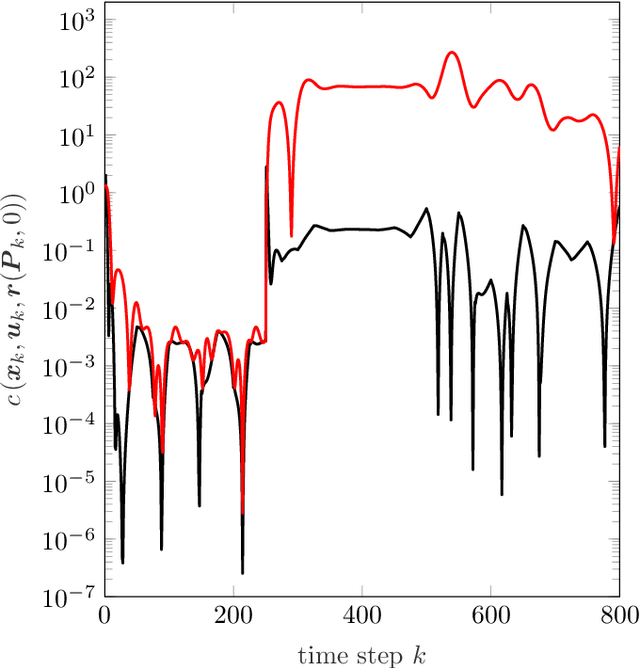
In order to autonomously learn to control unknown systems optimally w.r.t. an objective function, Adaptive Dynamic Programming (ADP) is well-suited to adapt controllers based on experience from interaction with the system. In recent years, many researchers focused on the tracking case, where the aim is to follow a desired trajectory. So far, ADP tracking controllers assume that the reference trajectory follows time-invariant exo-system dynamics-an assumption that does not hold for many applications. In order to overcome this limitation, we propose a new Q-function which explicitly incorporates a parametrized approximation of the reference trajectory. This allows to learn to track a general class of trajectories by means of ADP. Once our Q-function has been learned, the associated controller copes with time-varying reference trajectories without need of further training and independent of exo-system dynamics. After proposing our general model-free off-policy tracking method, we provide analysis of the important special case of linear quadratic tracking. We conclude our paper with an example which demonstrates that our new method successfully learns the optimal tracking controller and outperforms existing approaches in terms of tracking error and cost.
FreshDiskANN: A Fast and Accurate Graph-Based ANN Index for Streaming Similarity Search
May 20, 2021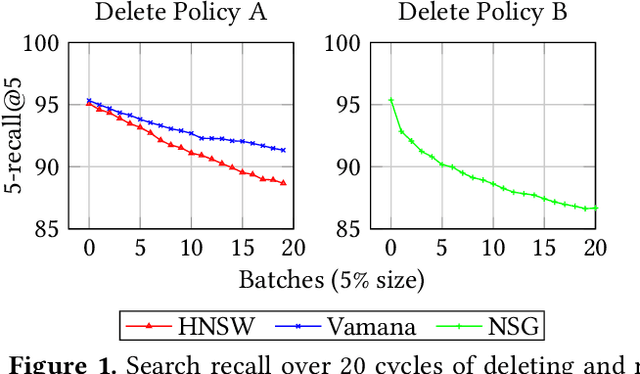
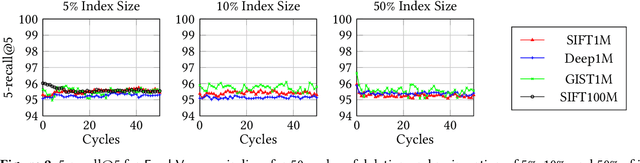
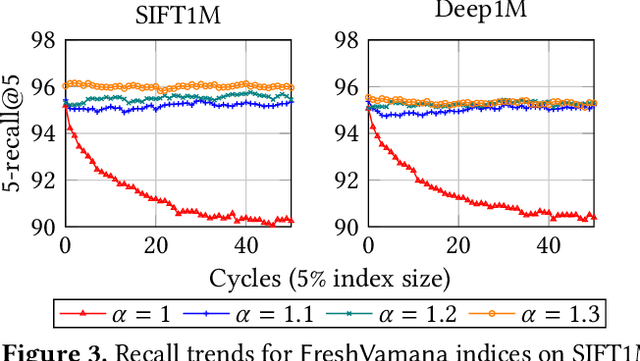
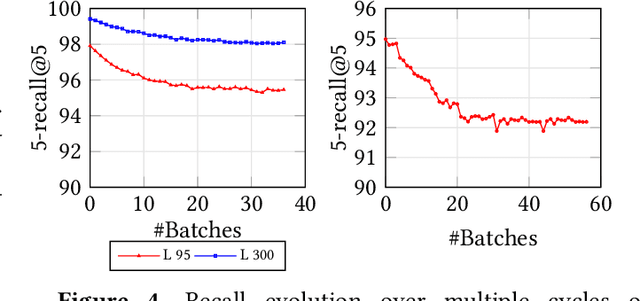
Approximate nearest neighbor search (ANNS) is a fundamental building block in information retrieval with graph-based indices being the current state-of-the-art and widely used in the industry. Recent advances in graph-based indices have made it possible to index and search billion-point datasets with high recall and millisecond-level latency on a single commodity machine with an SSD. However, existing graph algorithms for ANNS support only static indices that cannot reflect real-time changes to the corpus required by many key real-world scenarios (e.g. index of sentences in documents, email, or a news index). To overcome this drawback, the current industry practice for manifesting updates into such indices is to periodically re-build these indices, which can be prohibitively expensive. In this paper, we present the first graph-based ANNS index that reflects corpus updates into the index in real-time without compromising on search performance. Using update rules for this index, we design FreshDiskANN, a system that can index over a billion points on a workstation with an SSD and limited memory, and support thousands of concurrent real-time inserts, deletes and searches per second each, while retaining $>95\%$ 5-recall@5. This represents a 5-10x reduction in the cost of maintaining freshness in indices when compared to existing methods.
Methods of Adaptive Signal Processing on Graphs Using Vertex-Time Autoregressive Models
Mar 10, 2020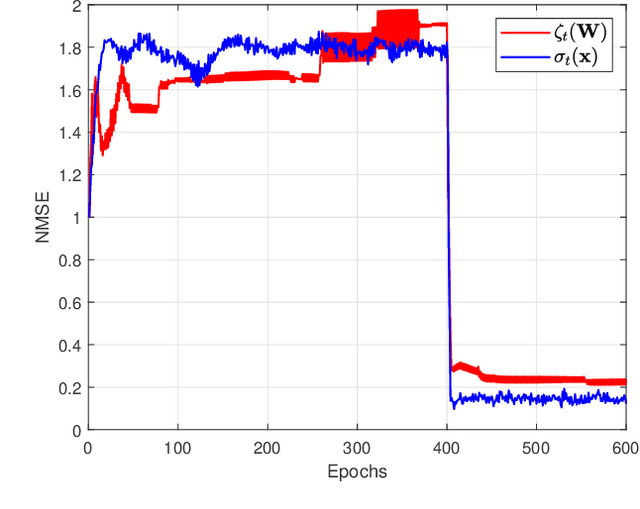
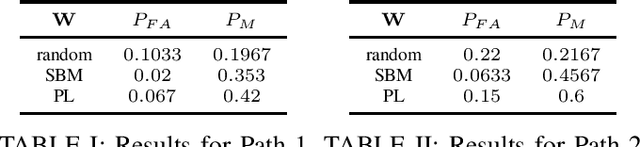
The concept of a random process has been recently extended to graph signals, whereby random graph processes are a class of multivariate stochastic processes whose coefficients are matrices with a \textit{graph-topological} structure. The system identification problem of a random graph process therefore revolves around determining its underlying topology, or mathematically, the graph shift operators (GSOs) i.e. an adjacency matrix or a Laplacian matrix. In the same work that introduced random graph processes, a \textit{batch} optimization method to solve for the GSO was also proposed for the random graph process based on a \textit{causal} vertex-time autoregressive model. To this end, the online version of this optimization problem was proposed via the framework of adaptive filtering. The modified stochastic gradient projection method was employed on the regularized least squares objective to create the filter. The recursion is divided into 3 regularized sub-problems to address issues like multi-convexity, sparsity, commutativity and bias. A discussion on convergence analysis is also included. Finally, experiments are conducted to illustrate the performance of the proposed algorithm, from traditional MSE measure to successful recovery rate regardless correct values, all of which to shed light on the potential, the limit and the possible research attempt of this work.
The Future of Prosody: It's about Time
May 15, 2018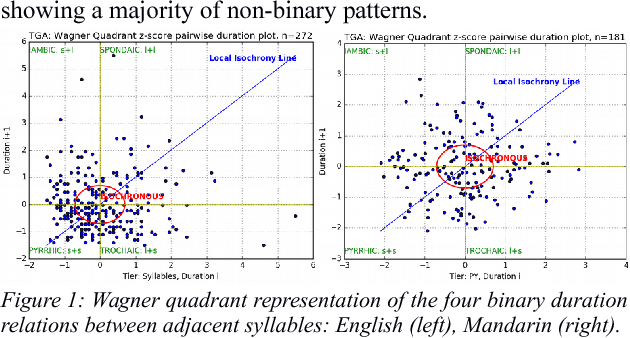
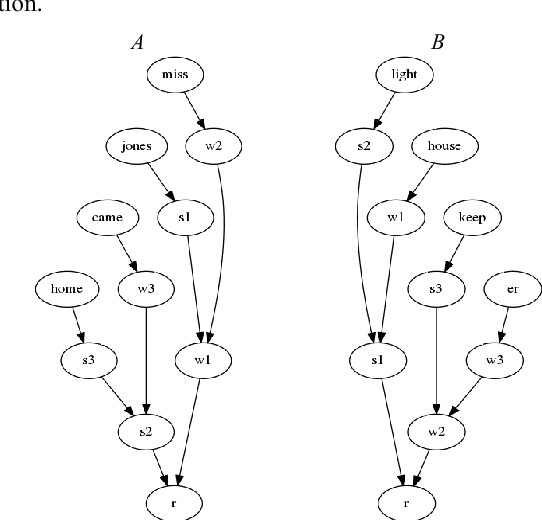
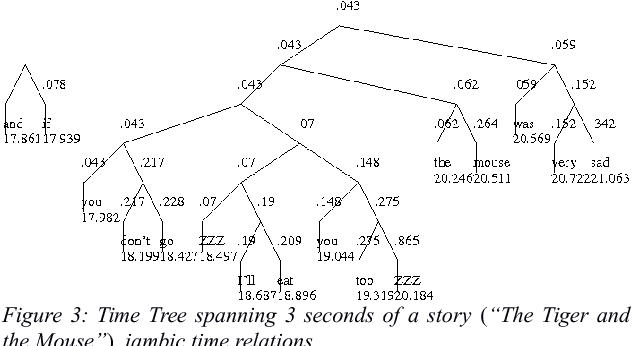
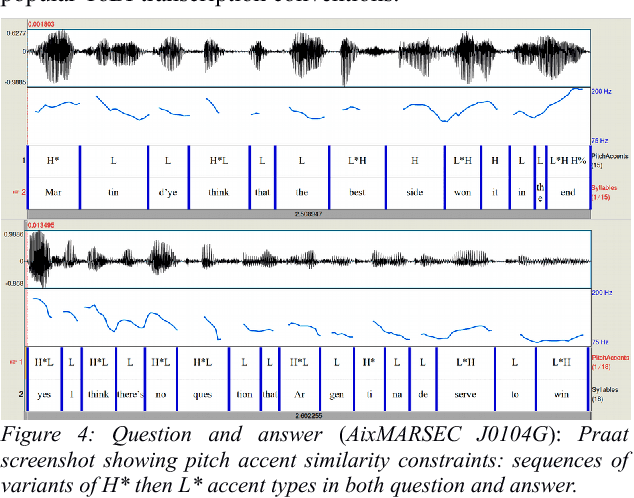
Prosody is usually defined in terms of the three distinct but interacting domains of pitch, intensity and duration patterning, or, more generally, as phonological and phonetic properties of 'suprasegmentals', speech segments which are larger than consonants and vowels. Rather than taking this approach, the concept of multiple time domains for prosody processing is taken up, and methods of time domain analysis are discussed: annotation mining with timing dispersion measures, time tree induction, oscillator models in phonology and phonetics, and finally the use of the Amplitude Envelope Modulation Spectrum (AEMS). While frequency demodulation (in the form of pitch tracking) is a central issue in prosodic analysis, in the present context it is amplitude envelope demodulation and frequency zones in the long time-domain spectra of the demodulated envelope which are focused. A generalised view is taken of oscillation as iteration in abstract prosodic models and as modulation and demodulation of a variety of rhythms in the speech signal.
Online Evolutionary Batch Size Orchestration for Scheduling Deep Learning Workloads in GPU Clusters
Aug 08, 2021
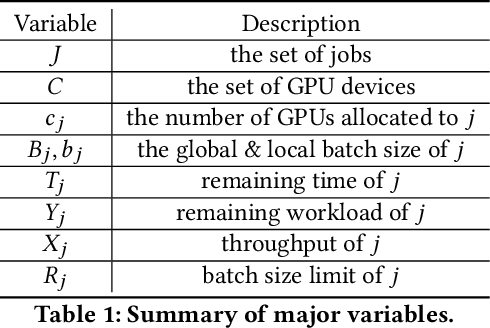
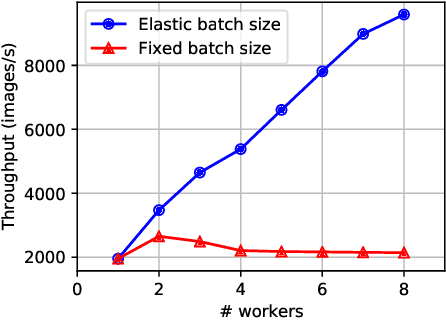
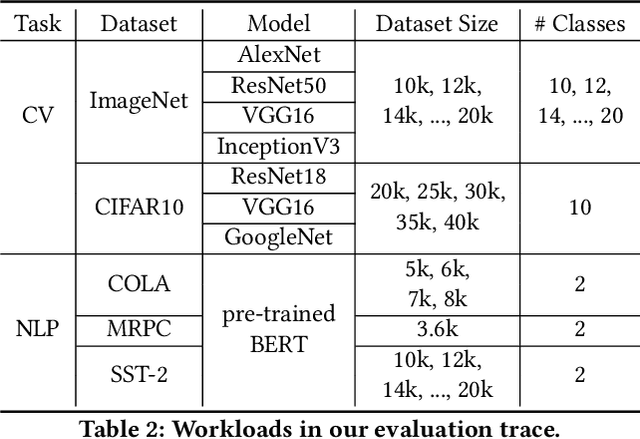
Efficient GPU resource scheduling is essential to maximize resource utilization and save training costs for the increasing amount of deep learning workloads in shared GPU clusters. Existing GPU schedulers largely rely on static policies to leverage the performance characteristics of deep learning jobs. However, they can hardly reach optimal efficiency due to the lack of elasticity. To address the problem, we propose ONES, an ONline Evolutionary Scheduler for elastic batch size orchestration. ONES automatically manages the elasticity of each job based on the training batch size, so as to maximize GPU utilization and improve scheduling efficiency. It determines the batch size for each job through an online evolutionary search that can continuously optimize the scheduling decisions. We evaluate the effectiveness of ONES with 64 GPUs on TACC's Longhorn supercomputers. The results show that ONES can outperform the prior deep learning schedulers with a significantly shorter average job completion time.
Transformed CNNs: recasting pre-trained convolutional layers with self-attention
Jun 10, 2021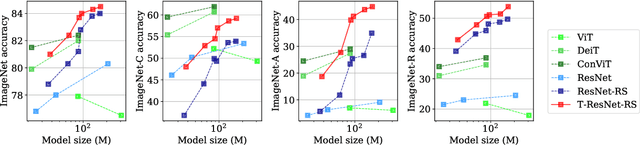
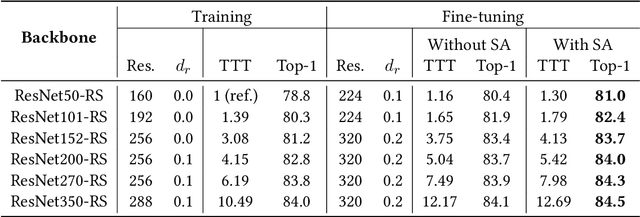
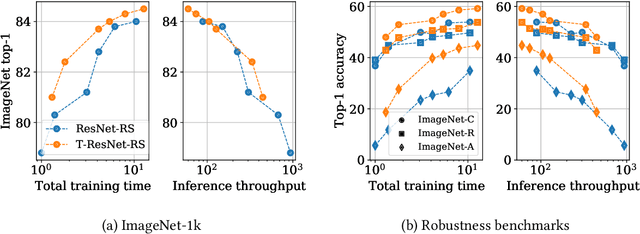
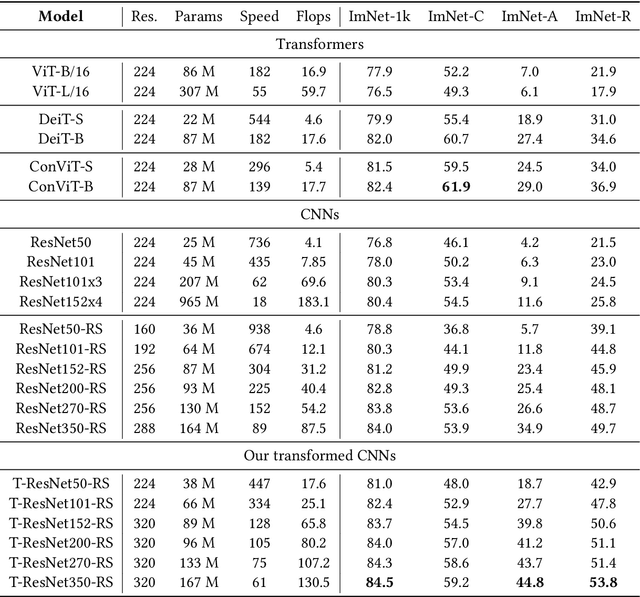
Vision Transformers (ViT) have recently emerged as a powerful alternative to convolutional networks (CNNs). Although hybrid models attempt to bridge the gap between these two architectures, the self-attention layers they rely on induce a strong computational bottleneck, especially at large spatial resolutions. In this work, we explore the idea of reducing the time spent training these layers by initializing them as convolutional layers. This enables us to transition smoothly from any pre-trained CNN to its functionally identical hybrid model, called Transformed CNN (T-CNN). With only 50 epochs of fine-tuning, the resulting T-CNNs demonstrate significant performance gains over the CNN (+2.2% top-1 on ImageNet-1k for a ResNet50-RS) as well as substantially improved robustness (+11% top-1 on ImageNet-C). We analyze the representations learnt by the T-CNN, providing deeper insights into the fruitful interplay between convolutions and self-attention. Finally, we experiment initializing the T-CNN from a partially trained CNN, and find that it reaches better performance than the corresponding hybrid model trained from scratch, while reducing training time.
LoRa-RL: Deep Reinforcement Learning for Resource Management in Hybrid Energy LoRa Wireless Networks
Sep 06, 2021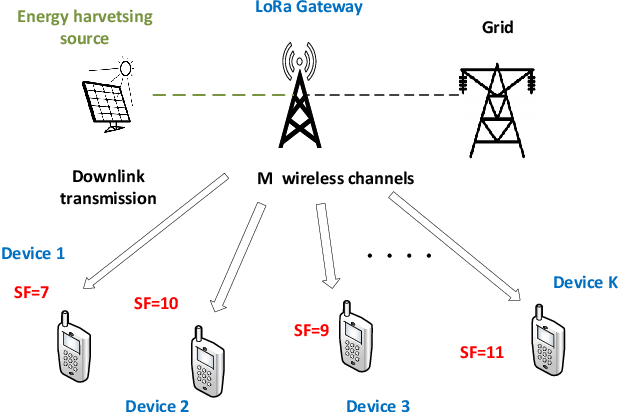
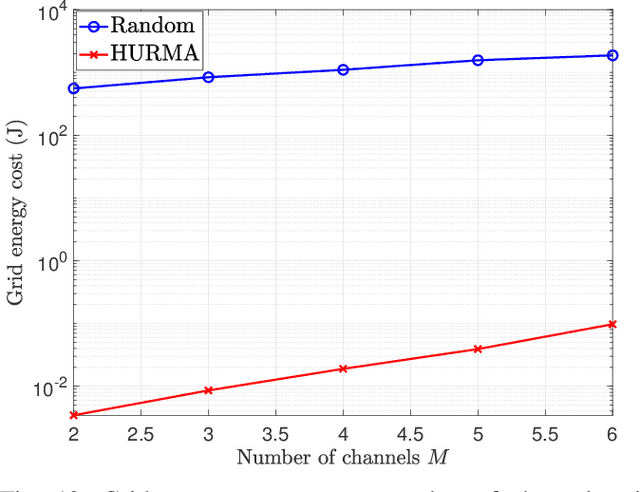
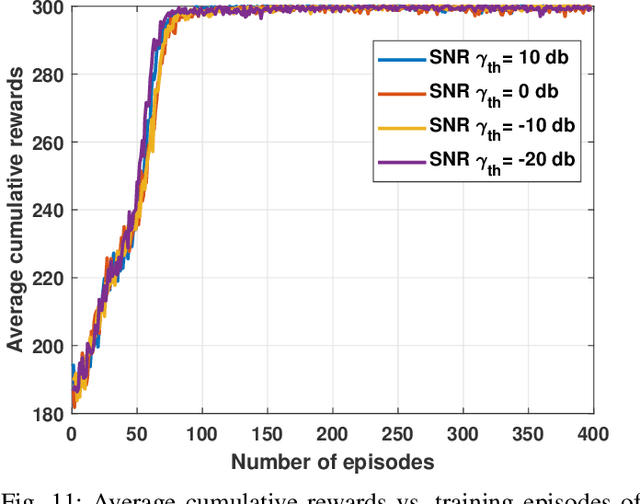
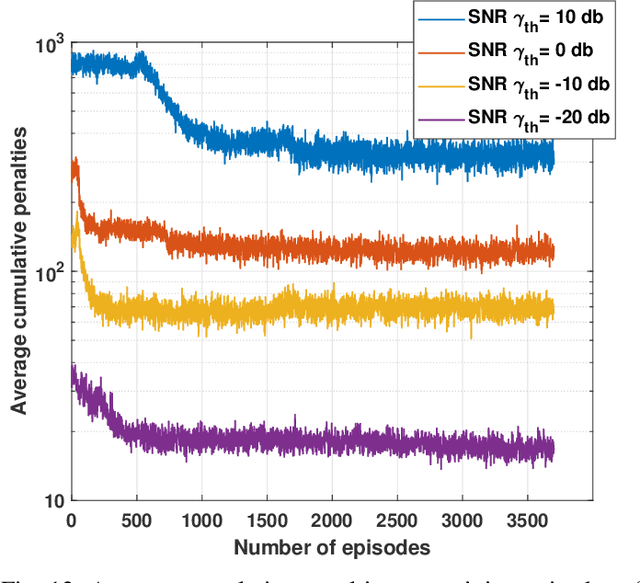
LoRa wireless networks are considered as a key enabling technology for next generation internet of things (IoT) systems. New IoT deployments (e.g., smart city scenarios) can have thousands of devices per square kilometer leading to huge amount of power consumption to provide connectivity. In this paper, we investigate green LoRa wireless networks powered by a hybrid of the grid and renewable energy sources, which can benefit from harvested energy while dealing with the intermittent supply. This paper proposes resource management schemes of the limited number of channels and spreading factors (SFs) with the objective of improving the LoRa gateway energy efficiency. First, the problem of grid power consumption minimization while satisfying the system's quality of service demands is formulated. Specifically, both scenarios the uncorrelated and time-correlated channels are investigated. The optimal resource management problem is solved by decoupling the formulated problem into two sub-problems: channel and SF assignment problem and energy management problem. Since the optimal solution is obtained with high complexity, online resource management heuristic algorithms that minimize the grid energy consumption are proposed. Finally, taking into account the channel and energy correlation, adaptable resource management schemes based on Reinforcement Learning (RL), are developed. Simulations results show that the proposed resource management schemes offer efficient use of renewable energy in LoRa wireless networks.
More but Correct: Generating Diversified and Entity-revised Medical Response
Aug 19, 2021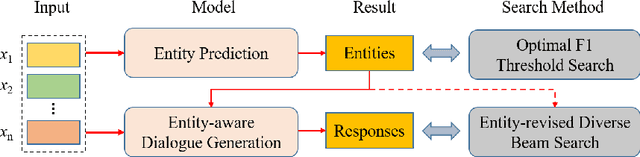
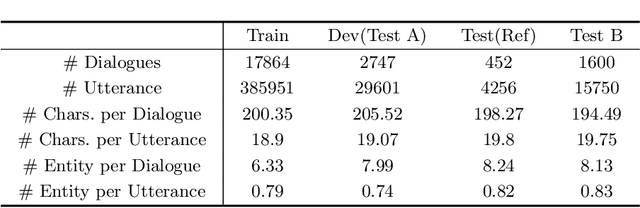
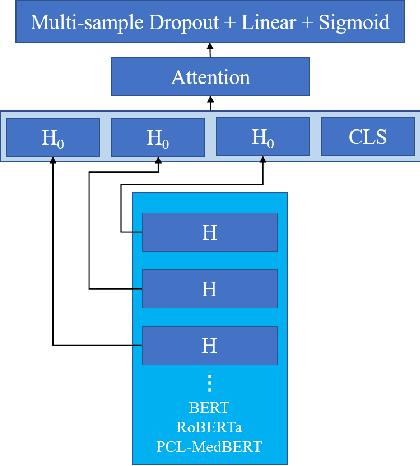
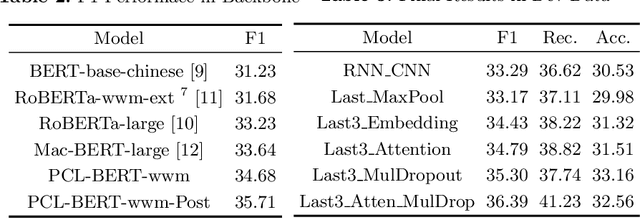
Medical Dialogue Generation (MDG) is intended to build a medical dialogue system for intelligent consultation, which can communicate with patients in real-time, thereby improving the efficiency of clinical diagnosis with broad application prospects. This paper presents our proposed framework for the Chinese MDG organized by the 2021 China conference on knowledge graph and semantic computing (CCKS) competition, which requires generating context-consistent and medically meaningful responses conditioned on the dialogue history. In our framework, we propose a pipeline system composed of entity prediction and entity-aware dialogue generation, by adding predicted entities to the dialogue model with a fusion mechanism, thereby utilizing information from different sources. At the decoding stage, we propose a new decoding mechanism named Entity-revised Diverse Beam Search (EDBS) to improve entity correctness and promote the length and quality of the final response. The proposed method wins both the CCKS and the International Conference on Learning Representations (ICLR) 2021 Workshop Machine Learning for Preventing and Combating Pandemics (MLPCP) Track 1 Entity-aware MED competitions, which demonstrate the practicality and effectiveness of our method.
Time-Aware Music Recommender Systems: Modeling the Evolution of Implicit User Preferences and User Listening Habits in A Collaborative Filtering Approach
Aug 26, 2020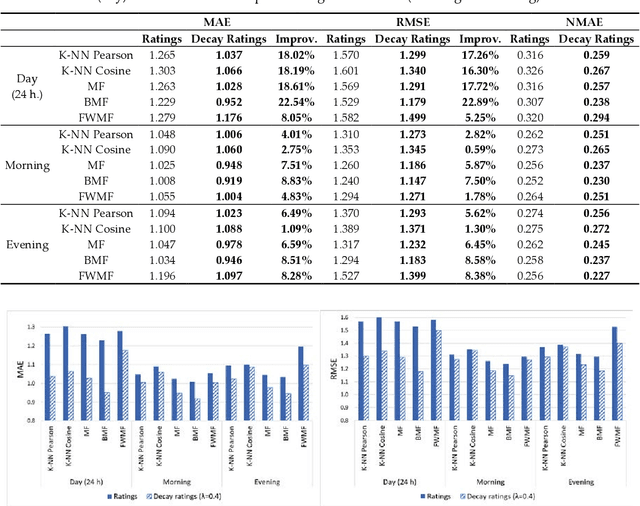
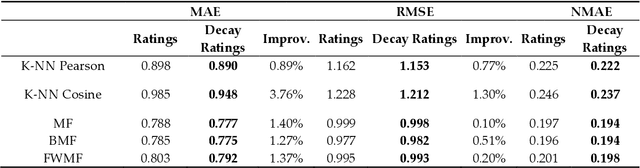
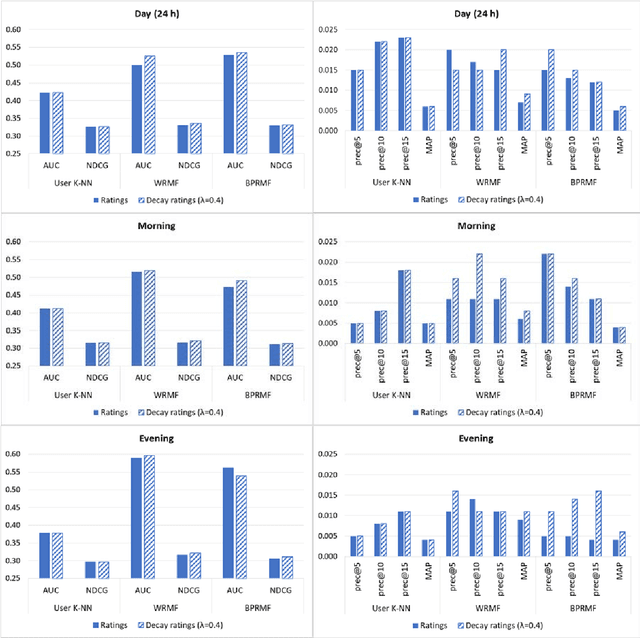
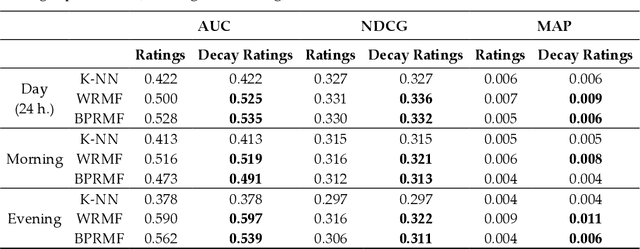
Online streaming services have become the most popular way of listening to music. The majority of these services are endowed with recommendation mechanisms that help users to discover songs and artists that may interest them from the vast amount of music available. However, many are not reliable as they may not take into account contextual aspects or the ever-evolving user behavior. Therefore, it is necessary to develop systems that consider these aspects. In the field of music, time is one of the most important factors influencing user preferences and managing its effects, and is the motivation behind the work presented in this paper. Here, the temporal information regarding when songs are played is examined. The purpose is to model both the evolution of user preferences in the form of evolving implicit ratings and user listening behavior. In the collaborative filtering method proposed in this work, daily listening habits are captured in order to characterize users and provide them with more reliable recommendations. The results of the validation prove that this approach outperforms other methods in generating both context-aware and context-free recommendations
Lifelong Infinite Mixture Model Based on Knowledge-Driven Dirichlet Process
Aug 25, 2021
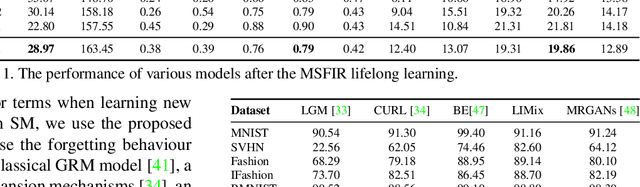
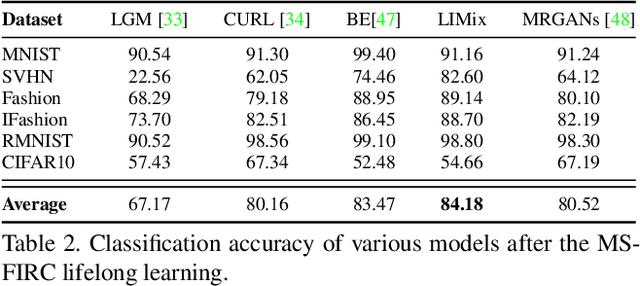

Recent research efforts in lifelong learning propose to grow a mixture of models to adapt to an increasing number of tasks. The proposed methodology shows promising results in overcoming catastrophic forgetting. However, the theory behind these successful models is still not well understood. In this paper, we perform the theoretical analysis for lifelong learning models by deriving the risk bounds based on the discrepancy distance between the probabilistic representation of data generated by the model and that corresponding to the target dataset. Inspired by the theoretical analysis, we introduce a new lifelong learning approach, namely the Lifelong Infinite Mixture (LIMix) model, which can automatically expand its network architectures or choose an appropriate component to adapt its parameters for learning a new task, while preserving its previously learnt information. We propose to incorporate the knowledge by means of Dirichlet processes by using a gating mechanism which computes the dependence between the knowledge learnt previously and stored in each component, and a new set of data. Besides, we train a compact Student model which can accumulate cross-domain representations over time and make quick inferences. The code is available at https://github.com/dtuzi123/Lifelong-infinite-mixture-model.