 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semi-supervised learning for medical image classification using imbalanced training data
Aug 20, 2021
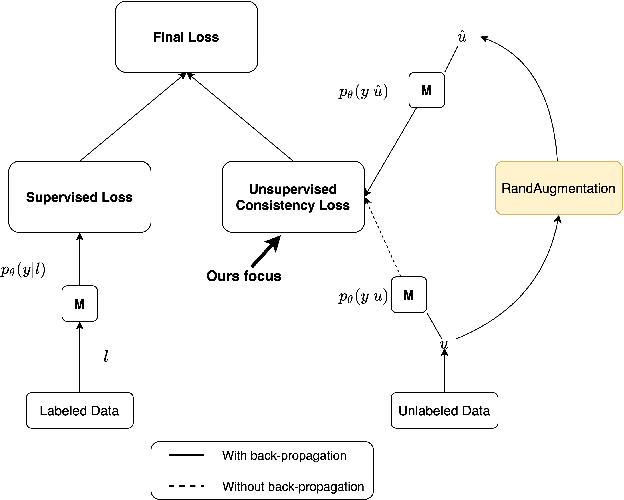
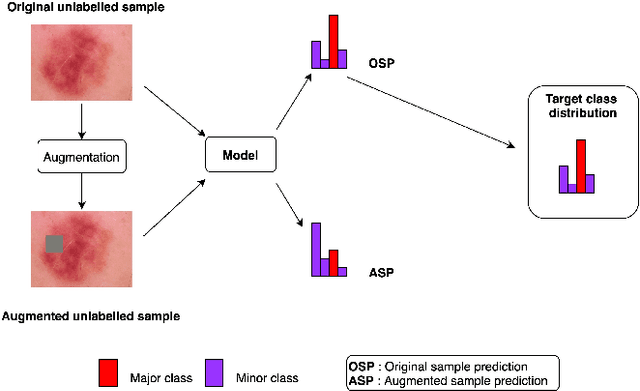
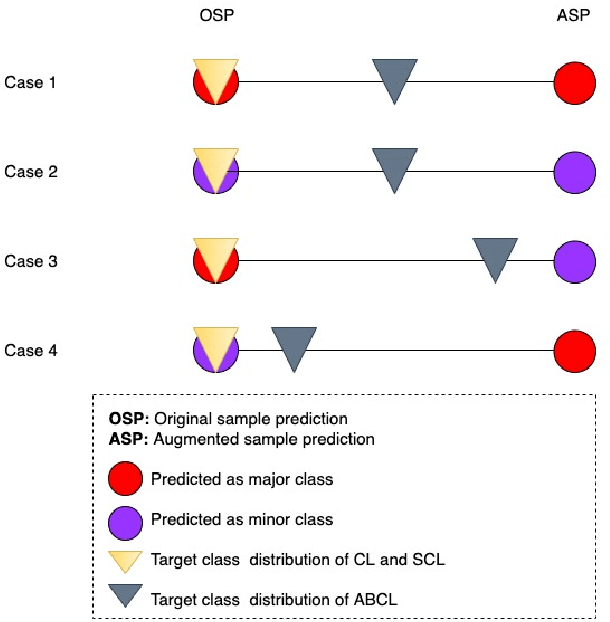
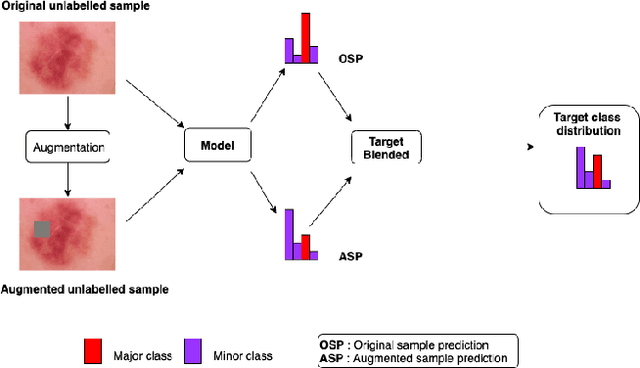
Medical image classification is often challenging for two reasons: a lack of labelled examples due to expensive and time-consuming annotation protocols, and imbalanced class labels due to the relative scarcity of disease-positive individuals in the wider population. Semi-supervised learning (SSL) methods exist for dealing with a lack of labels, but they generally do not address the problem of class imbalance. In this study we propose Adaptive Blended Consistency Loss (ABCL), a drop-in replacement for consistency loss in perturbation-based SSL methods. ABCL counteracts data skew by adaptively mixing the target class distribution of the consistency loss in accordance with class frequency. Our experiments with ABCL reveal improvements to unweighted average recall on two different imbalanced medical image classification datasets when compared with existing consistency losses that are not designed to counteract class imbalance.
Deformable Image Registration using Neural ODEs
Aug 27, 2021



Deformable image registration, aiming to find spatial correspondence between a given image pair, is one of the most critical problems in the domain of medical image analysis. In this paper, we present a generic, fast, and accurate diffeomorphic image registration framework that leverages neural ordinary differential equations (NODEs). We model each voxel as a moving particle and consider the set of all voxels in a 3D image as a high-dimensional dynamical system whose trajectory determines the targeted deformation field. Compared with traditional optimization-based methods, our framework reduces the running time from tens of minutes to tens of seconds. Compared with recent data-driven deep learning methods, our framework is more accessible since it does not require large amounts of training data. Our experiments show that the registration results of our method outperform state-of-the-arts under various metrics, indicating that our modeling approach is well fitted for the task of deformable image registration.
Safety-aware Motion Prediction with Unseen Vehicles for Autonomous Driving
Sep 03, 2021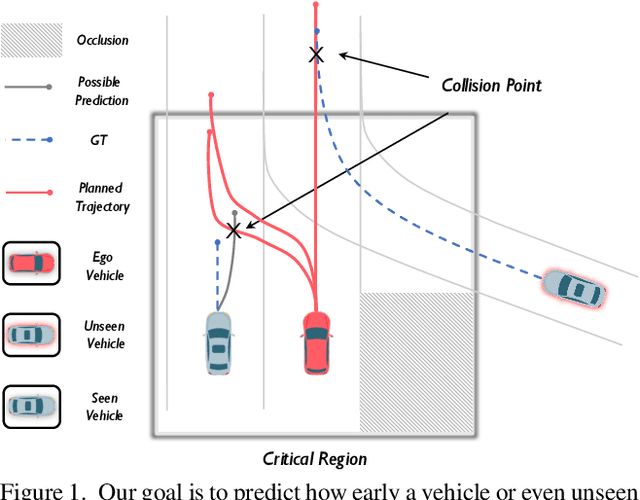
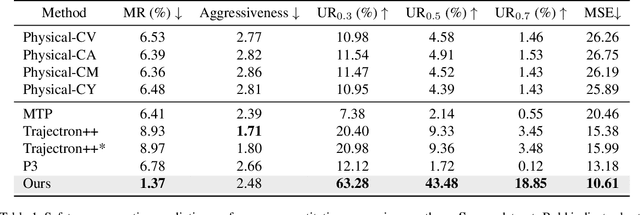


Motion prediction of vehicles is critical but challenging due to the uncertainties in complex environments and the limited visibility caused by occlusions and limited sensor ranges. In this paper, we study a new task, safety-aware motion prediction with unseen vehicles for autonomous driving. Unlike the existing trajectory prediction task for seen vehicles, we aim at predicting an occupancy map that indicates the earliest time when each location can be occupied by either seen and unseen vehicles. The ability to predict unseen vehicles is critical for safety in autonomous driving. To tackle this challenging task, we propose a safety-aware deep learning model with three new loss functions to predict the earliest occupancy map. Experiments on the large-scale autonomous driving nuScenes dataset show that our proposed model significantly outperforms the state-of-the-art baselines on the safety-aware motion prediction task. To the best of our knowledge, our approach is the first one that can predict the existence of unseen vehicles in most cases. Project page at {\url{https://github.com/xrenaa/Safety-Aware-Motion-Prediction}}.
Scientific evidence extraction
Sep 30, 2021

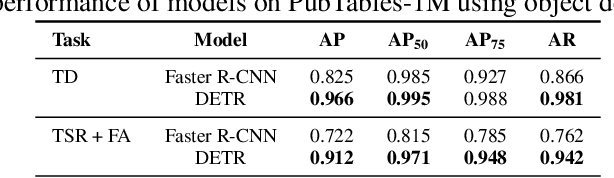
Recently, interest has grown in applying machine learning to the problem of table structure inference and extraction from unstructured documents. However, progress in this area has been challenging both to make and to measure, due to several issues that arise in training and evaluating models from labeled data. This includes challenges as fundamental as the lack of a single definitive ground truth output for each input sample and the lack of an ideal metric for measuring partial correctness for this task. To address these we propose a new dataset, PubMed Tables One Million (PubTables-1M), and a new class of metric, grid table similarity (GriTS). PubTables-1M is nearly twice as large as the previous largest comparable dataset, can be used for models across multiple architectures and modalities, and addresses issues such as ambiguity and lack of consistency in the annotations. We apply DETR to table extraction for the first time and show that object detection models trained on PubTables-1M produce excellent results out-of-the-box for all three tasks of detection, structure recognition, and functional analysis. We describe the dataset in detail to enable others to build on our work and combine this data with other datasets for these and related tasks. It is our hope that PubTables-1M and the proposed metrics can further progress in this area by creating a benchmark suitable for training and evaluating a wide variety of models for table extraction. Data and code will be released at https://github.com/microsoft/table-transformer.
Efficient Domain Adaptation of Language Models via Adaptive Tokenization
Sep 15, 2021
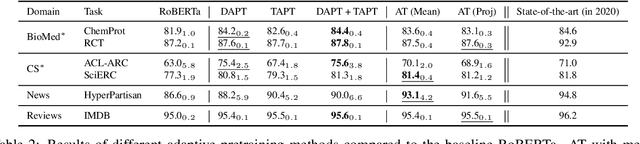

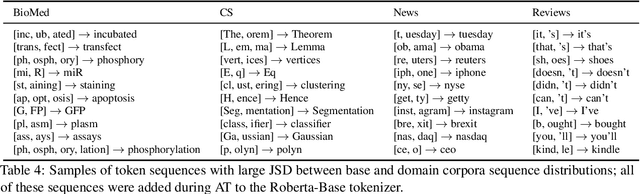
Contextual embedding-based language models trained on large data sets, such as BERT and RoBERTa, provide strong performance across a wide range of tasks and are ubiquitous in modern NLP. It has been observed that fine-tuning these models on tasks involving data from domains different from that on which they were pretrained can lead to suboptimal performance. Recent work has explored approaches to adapt pretrained language models to new domains by incorporating additional pretraining using domain-specific corpora and task data. We propose an alternative approach for transferring pretrained language models to new domains by adapting their tokenizers. We show that domain-specific subword sequences can be efficiently determined directly from divergences in the conditional token distributions of the base and domain-specific corpora. In datasets from four disparate domains, we find adaptive tokenization on a pretrained RoBERTa model provides >97% of the performance benefits of domain specific pretraining. Our approach produces smaller models and less training and inference time than other approaches using tokenizer augmentation. While adaptive tokenization incurs a 6% increase in model parameters in our experimentation, due to the introduction of 10k new domain-specific tokens, our approach, using 64 vCPUs, is 72x faster than further pretraining the language model on domain-specific corpora on 8 TPUs.
SOMA: Solving Optical Marker-Based MoCap Automatically
Oct 09, 2021

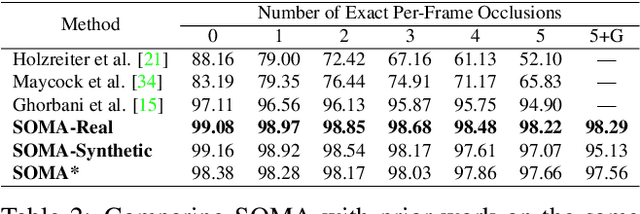
Marker-based optical motion capture (mocap) is the "gold standard" method for acquiring accurate 3D human motion in computer vision, medicine, and graphics. The raw output of these systems are noisy and incomplete 3D points or short tracklets of points. To be useful, one must associate these points with corresponding markers on the captured subject; i.e. "labelling". Given these labels, one can then "solve" for the 3D skeleton or body surface mesh. Commercial auto-labeling tools require a specific calibration procedure at capture time, which is not possible for archival data. Here we train a novel neural network called SOMA, which takes raw mocap point clouds with varying numbers of points, labels them at scale without any calibration data, independent of the capture technology, and requiring only minimal human intervention. Our key insight is that, while labeling point clouds is highly ambiguous, the 3D body provides strong constraints on the solution that can be exploited by a learning-based method. To enable learning, we generate massive training sets of simulated noisy and ground truth mocap markers animated by 3D bodies from AMASS. SOMA exploits an architecture with stacked self-attention elements to learn the spatial structure of the 3D body and an optimal transport layer to constrain the assignment (labeling) problem while rejecting outliers. We extensively evaluate SOMA both quantitatively and qualitatively. SOMA is more accurate and robust than existing state of the art research methods and can be applied where commercial systems cannot. We automatically label over 8 hours of archival mocap data across 4 different datasets captured using various technologies and output SMPL-X body models. The model and data is released for research purposes at https://soma.is.tue.mpg.de/.
Time Series Learning using Monotonic Logical Properties
Aug 01, 2018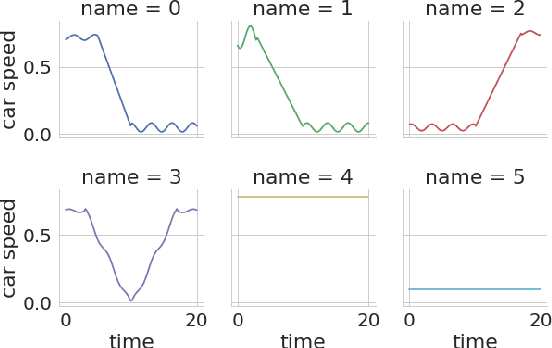
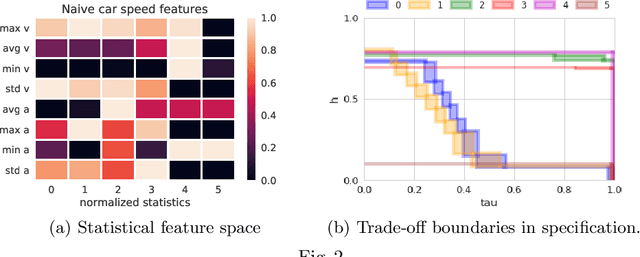
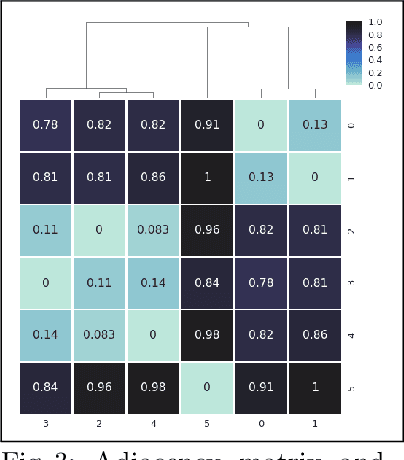
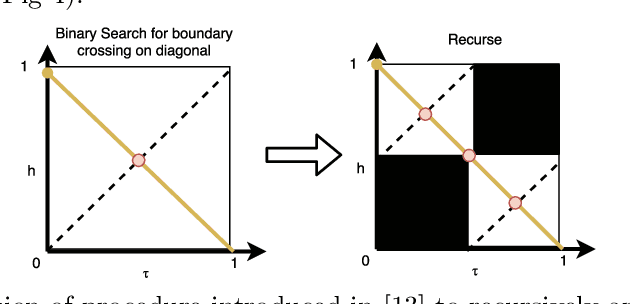
Cyber-physical systems of today are generating large volumes of time-series data. As manual inspection of such data is not tractable, the need for learning methods to help discover logical structure in the data has increased. We propose a logic-based framework that allows domain-specific knowledge to be embedded into formulas in a parametric logical specification over time-series data. The key idea is to then map a time series to a surface in the parameter space of the formula. Given this mapping, we identify the Hausdorff distance between boundaries as a natural distance metric between two time-series data under the lens of the parametric specification. This enables embedding non-trivial domain-specific knowledge into the distance metric and then using off-the-shelf machine learning tools to label the data. After labeling the data, we demonstrate how to extract a logical specification for each label. Finally, we showcase our technique on real world traffic data to learn classifiers/monitors for slow-downs and traffic jams.
Policy Teaching via Environment Poisoning: Training-time Adversarial Attacks against Reinforcement Learning
Mar 28, 2020
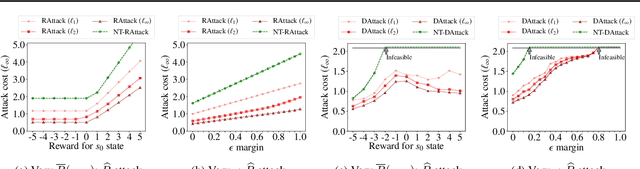
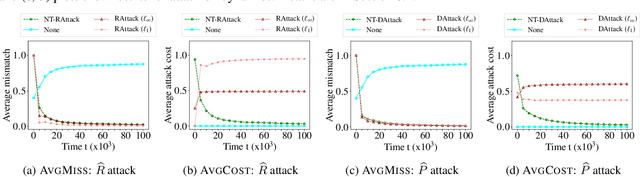
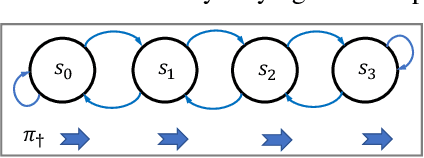
We study a security threat to reinforcement learning where an attacker poisons the learning environment to force the agent into executing a target policy chosen by the attacker. As a victim, we consider RL agents whose objective is to find a policy that maximizes average reward in undiscounted infinite-horizon problem settings. The attacker can manipulate the rewards or the transition dynamics in the learning environment at training-time and is interested in doing so in a stealthy manner. We propose an optimization framework for finding an \emph{optimal stealthy attack} for different measures of attack cost. We provide sufficient technical conditions under which the attack is feasible and provide lower/upper bounds on the attack cost. We instantiate our attacks in two settings: (i) an \emph{offline} setting where the agent is doing planning in the poisoned environment, and (ii) an \emph{online} setting where the agent is learning a policy using a regret-minimization framework with poisoned feedback. Our results show that the attacker can easily succeed in teaching any target policy to the victim under mild conditions and highlight a significant security threat to reinforcement learning agents in practice.
Distribution-free Contextual Dynamic Pricing
Sep 15, 2021

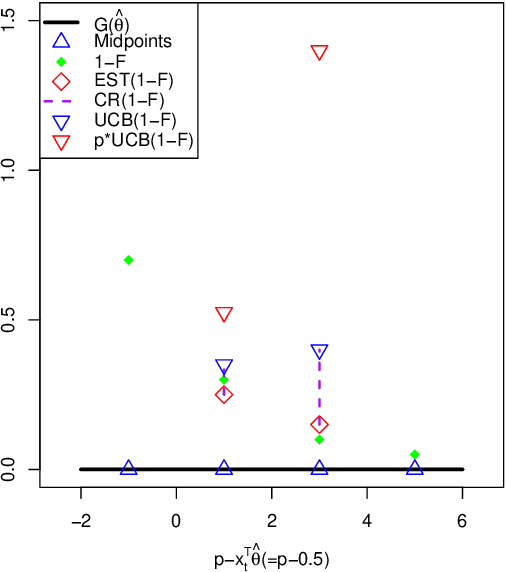
Contextual dynamic pricing aims to set personalized prices based on sequential interactions with customers. At each time period, a customer who is interested in purchasing a product comes to the platform. The customer's valuation for the product is a linear function of contexts, including product and customer features, plus some random market noise. The seller does not observe the customer's true valuation, but instead needs to learn the valuation by leveraging contextual information and historical binary purchase feedbacks. Existing models typically assume full or partial knowledge of the random noise distribution. In this paper, we consider contextual dynamic pricing with unknown random noise in the valuation model. Our distribution-free pricing policy learns both the contextual function and the market noise simultaneously. A key ingredient of our method is a novel perturbed linear bandit framework, where a modified linear upper confidence bound algorithm is proposed to balance the exploration of market noise and the exploitation of the current knowledge for better pricing. We establish the regret upper bound and a matching lower bound of our policy in the perturbed linear bandit framework and prove a sub-linear regret bound in the considered pricing problem. Finally, we demonstrate the superior performance of our policy on simulations and a real-life auto-loan dataset.
Enel: Context-Aware Dynamic Scaling of Distributed Dataflow Jobs using Graph Propagation
Aug 27, 2021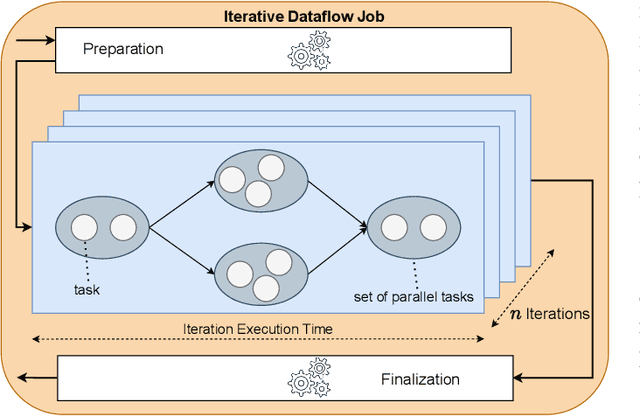

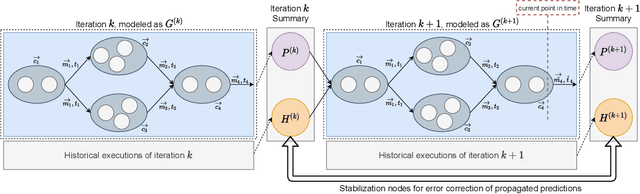
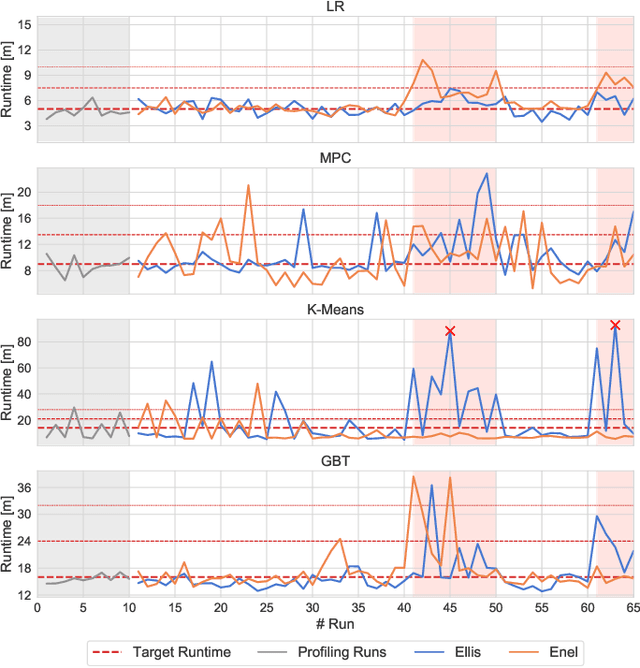
Distributed dataflow systems like Spark and Flink enable the use of clusters for scalable data analytics. While runtime prediction models can be used to initially select appropriate cluster resources given target runtimes, the actual runtime performance of dataflow jobs depends on several factors and varies over time. Yet, in many situations, dynamic scaling can be used to meet formulated runtime targets despite significant performance variance. This paper presents Enel, a novel dynamic scaling approach that uses message propagation on an attributed graph to model dataflow jobs and, thus, allows for deriving effective rescaling decisions. For this, Enel incorporates descriptive properties that capture the respective execution context, considers statistics from individual dataflow tasks, and propagates predictions through the job graph to eventually find an optimized new scale-out. Our evaluation of Enel with four iterative Spark jobs shows that our approach is able to identify effective rescaling actions, reacting for instance to node failures, and can be reused across different execution contexts.