 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAGE: A Benchmark for Knowledge Graph Construction, Question Answering, and In-Script Role-Playing over Movie Screenplays
Jan 13, 2026Movie screenplays are rich long-form narratives that interleave complex character relationships, temporally ordered events, and dialogue-driven interactions. While prior benchmarks target individual subtasks such as question answering or dialogue generation, they rarely evaluate whether models can construct a coherent story world and use it consistently across multiple forms of reasoning and generation. We introduce STAGE (Screenplay Text, Agents, Graphs and Evaluation), a unified benchmark for narrative understanding over full-length movie screenplays. STAGE defines four tasks: knowledge graph construction, scene-level event summarization, long-context screenplay question answering, and in-script character role-playing, all grounded in a shared narrative world representation. The benchmark provides cleaned scripts, curated knowledge graphs, and event- and character-centric annotations for 150 films across English and Chinese, enabling holistic evaluation of models' abilities to build world representations, abstract and verify narrative events, reason over long narratives, and generate character-consistent responses.
Distribution-free Contextual Dynamic Pricing
Sep 15, 2021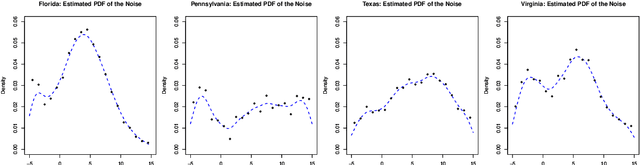

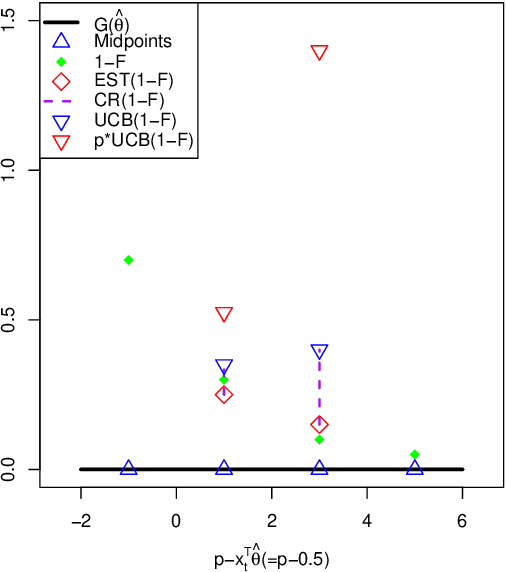
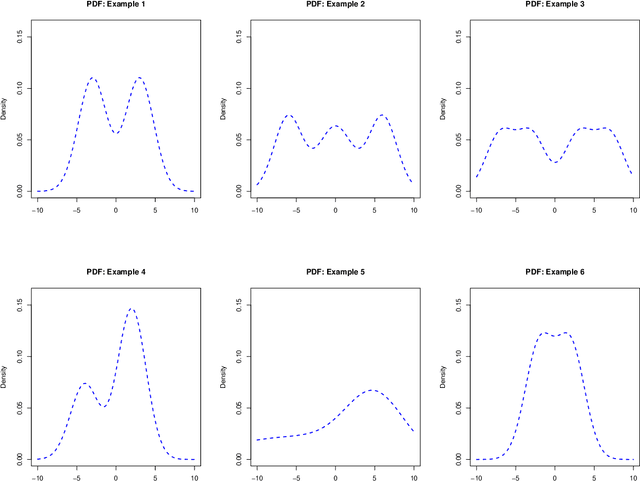
Contextual dynamic pricing aims to set personalized prices based on sequential interactions with customers. At each time period, a customer who is interested in purchasing a product comes to the platform. The customer's valuation for the product is a linear function of contexts, including product and customer features, plus some random market noise. The seller does not observe the customer's true valuation, but instead needs to learn the valuation by leveraging contextual information and historical binary purchase feedbacks. Existing models typically assume full or partial knowledge of the random noise distribution. In this paper, we consider contextual dynamic pricing with unknown random noise in the valuation model. Our distribution-free pricing policy learns both the contextual function and the market noise simultaneously. A key ingredient of our method is a novel perturbed linear bandit framework, where a modified linear upper confidence bound algorithm is proposed to balance the exploration of market noise and the exploitation of the current knowledge for better pricing. We establish the regret upper bound and a matching lower bound of our policy in the perturbed linear bandit framework and prove a sub-linear regret bound in the considered pricing problem. Finally, we demonstrate the superior performance of our policy on simulations and a real-life auto-loan dataset.