 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
StairwayGraphNet for Inter- and Intra-modality Multi-resolution Brain Graph Alignment and Synthesis
Oct 06, 2021
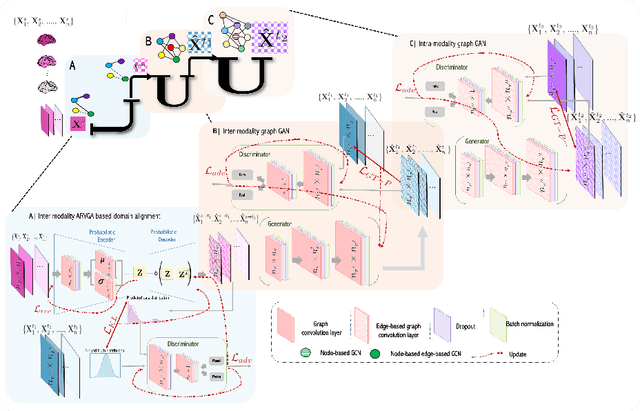
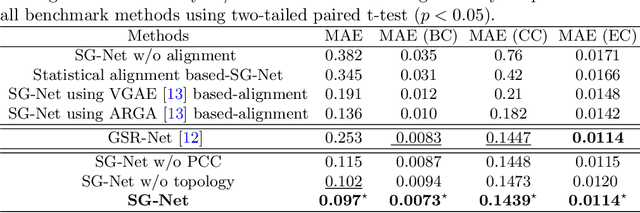
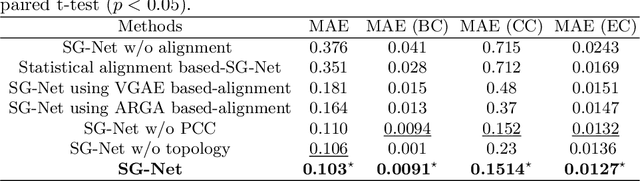
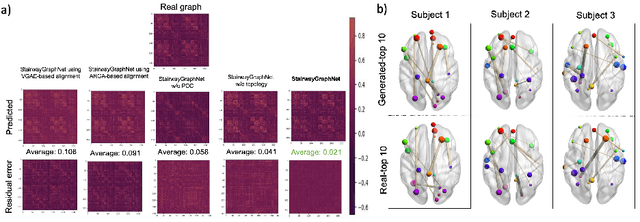
Synthesizing multimodality medical data provides complementary knowledge and helps doctors make precise clinical decisions. Although promising, existing multimodal brain graph synthesis frameworks have several limitations. First, they mainly tackle only one problem (intra- or inter-modality), limiting their generalizability to synthesizing inter- and intra-modality simultaneously. Second, while few techniques work on super-resolving low-resolution brain graphs within a single modality (i.e., intra), inter-modality graph super-resolution remains unexplored though this would avoid the need for costly data collection and processing. More importantly, both target and source domains might have different distributions, which causes a domain fracture between them. To fill these gaps, we propose a multi-resolution StairwayGraphNet (SG-Net) framework to jointly infer a target graph modality based on a given modality and super-resolve brain graphs in both inter and intra domains. Our SG-Net is grounded in three main contributions: (i) predicting a target graph from a source one based on a novel graph generative adversarial network in both inter (e.g., morphological-functional) and intra (e.g., functional-functional) domains, (ii) generating high-resolution brain graphs without resorting to the time consuming and expensive MRI processing steps, and (iii) enforcing the source distribution to match that of the ground truth graphs using an inter-modality aligner to relax the loss function to optimize. Moreover, we design a new Ground Truth-Preserving loss function to guide both generators in learning the topological structure of ground truth brain graphs more accurately. Our comprehensive experiments on predicting target brain graphs from source graphs using a multi-resolution stairway showed the outperformance of our method in comparison with its variants and state-of-the-art method.
Inter-Domain Alignment for Predicting High-Resolution Brain Networks Using Teacher-Student Learning
Oct 06, 2021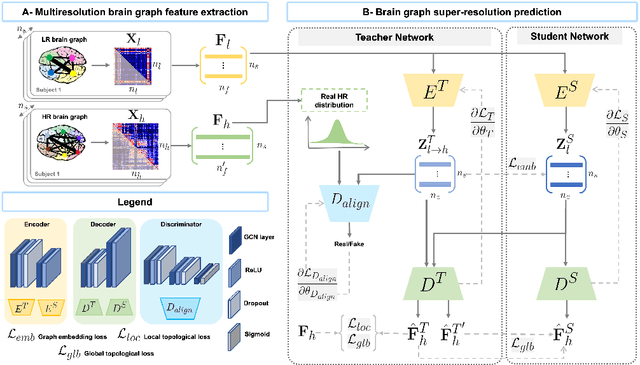

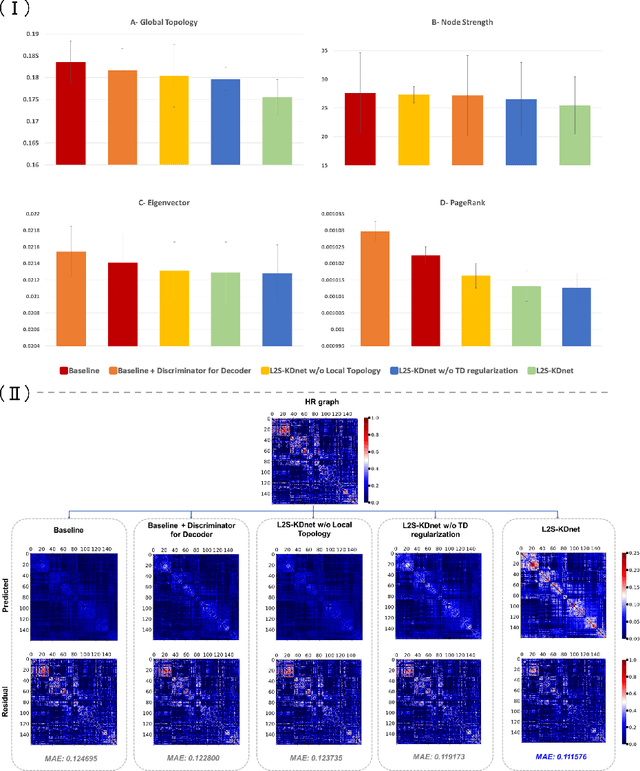
Accurate and automated super-resolution image synthesis is highly desired since it has the great potential to circumvent the need for acquiring high-cost medical scans and a time-consuming preprocessing pipeline of neuroimaging data. However, existing deep learning frameworks are solely designed to predict high-resolution (HR) image from a low-resolution (LR) one, which limits their generalization ability to brain graphs (i.e., connectomes). A small body of works has focused on superresolving brain graphs where the goal is to predict a HR graph from a single LR graph. Although promising, existing works mainly focus on superresolving graphs belonging to the same domain (e.g., functional), overlooking the domain fracture existing between multimodal brain data distributions (e.g., morphological and structural). To this aim, we propose a novel inter-domain adaptation framework namely, Learn to SuperResolve Brain Graphs with Knowledge Distillation Network (L2S-KDnet), which adopts a teacher-student paradigm to superresolve brain graphs. Our teacher network is a graph encoder-decoder that firstly learns the LR brain graph embeddings, and secondly learns how to align the resulting latent representations to the HR ground truth data distribution using an adversarial regularization. Ultimately, it decodes the HR graphs from the aligned embeddings. Next, our student network learns the knowledge of the aligned brain graphs as well as the topological structure of the predicted HR graphs transferred from the teacher. We further leverage the decoder of the teacher to optimize the student network. L2S-KDnet presents the first TS architecture tailored for brain graph super-resolution synthesis that is based on inter-domain alignment. Our experimental results demonstrate substantial performance gains over benchmark methods.
How to Split a Logic Program
Sep 17, 2021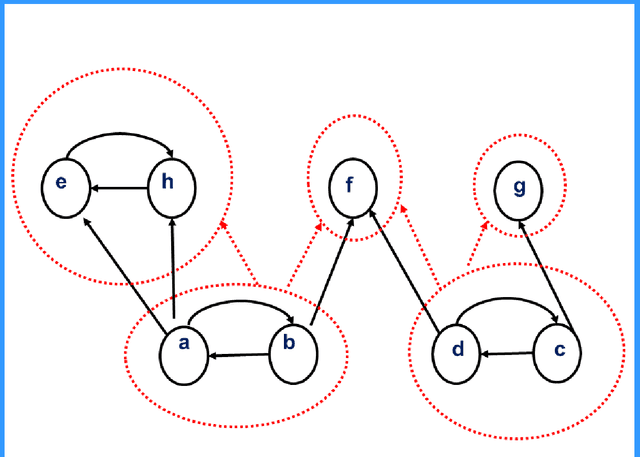
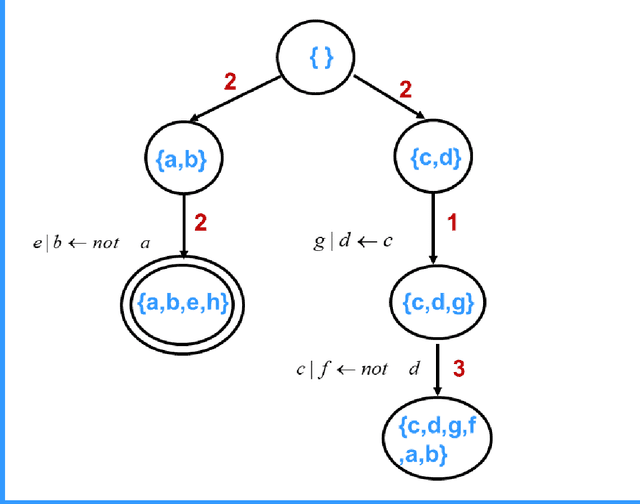
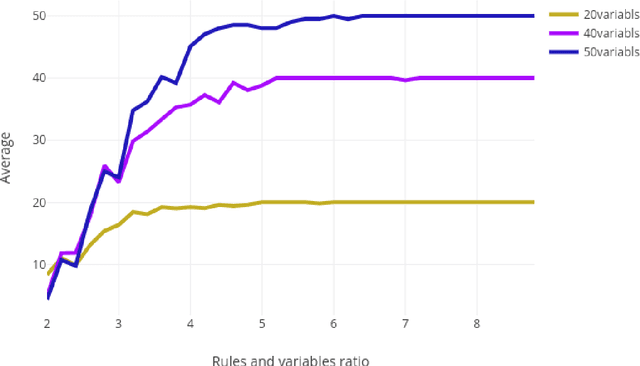
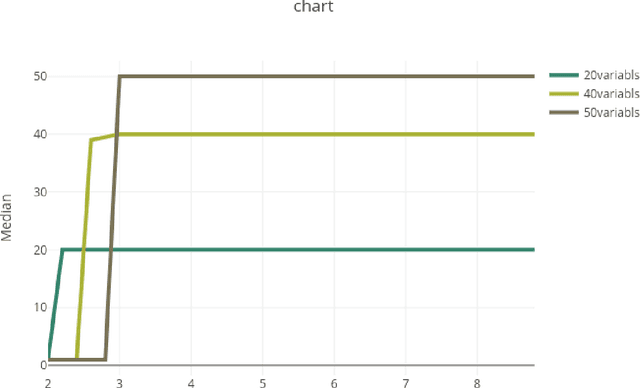
Answer Set Programming (ASP) is a successful method for solving a range of real-world applications. Despite the availability of fast ASP solvers, computing answer sets demands a very large computational power, since the problem tackled is in the second level of the polynomial hierarchy. A speed-up in answer set computation may be attained, if the program can be split into two disjoint parts, bottom and top. Thus, the bottom part is evaluated independently of the top part, and the results of the bottom part evaluation are used to simplify the top part. Lifschitz and Turner have introduced the concept of a splitting set, i.e., a set of atoms that defines the splitting. In this paper, We show that the problem of computing a splitting set with some desirable properties can be reduced to a classic Search Problem and solved in polynomial time. This allows us to conduct experiments on the size of the splitting set in various programs and lead to an interesting discovery of a source of complication in stable model computation. We also show that for Head-Cycle-Free programs, the definition of splitting sets can be adjusted to allow splitting of a broader class of programs.
* In Proceedings ICLP 2021, arXiv:2109.07914
Time Distance: A Novel Collision Prediction and Path Planning Method
Jul 07, 2019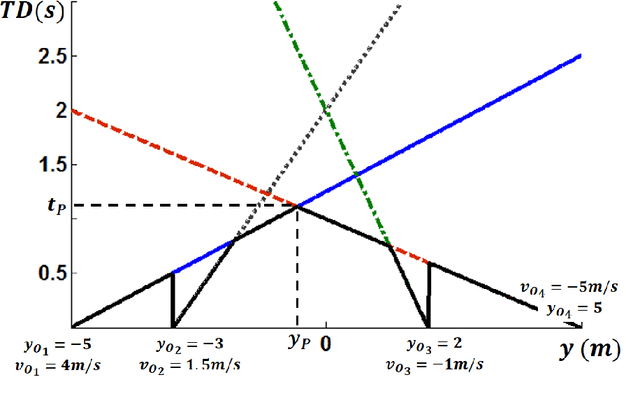
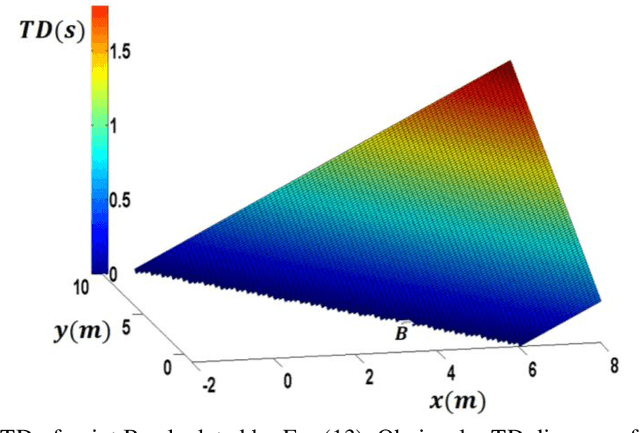
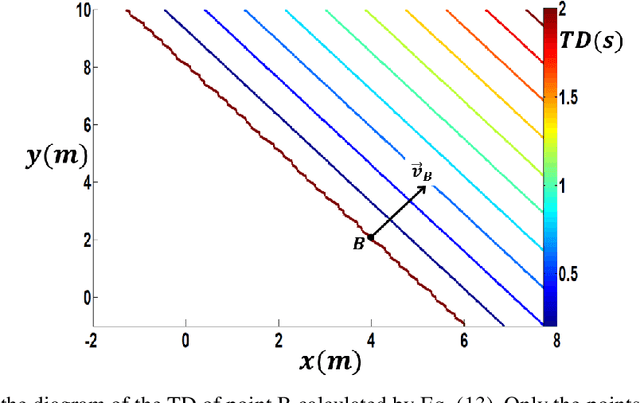
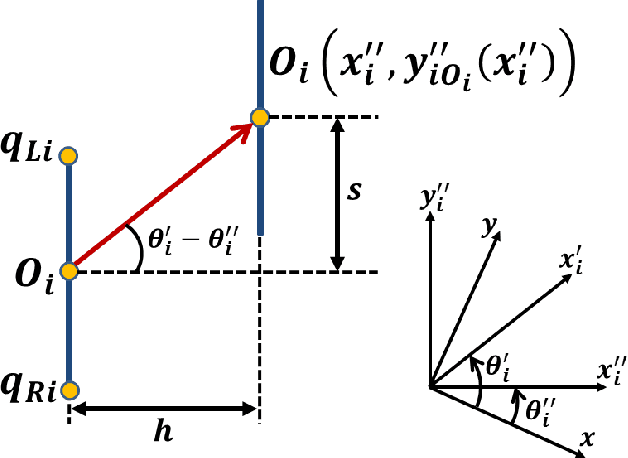
Motion planning is an active field of research in robot navigation and autonomous driving. There are plenty of classical and heuristic motion planning methods applicable to mobile robots and ground vehicles. This paper is dedicated to introducing a novel method for collision prediction and path planning. The method is called Time Distance (TD), and its basis returns to the swept volume idea. However, there are considerable differences between the TD method and existing methods associated with the swept volume concept. In this method, time is obtained as a dependent variable in TD functions. TD functions are functions of location, velocity, and geometry of objects, determining the TD of objects with respect to any location. Known as a relative concept, TD is defined as the time interval that must be spent in order for an object to reach a certain location. It is firstly defined for the one-dimensional case and then generalized to 2D space. The collision prediction algorithm consists of obtaining the TD of different points of an object (the vehicle) with respect to all objects of the environment using an explicit function which is a function of TD functions. The path planning algorithm uses TD functions and two other functions called Z-Infinity and Route Function to create the collision-free path in a dynamic environment. Both the collision prediction and the path planning algorithms are evaluated in simulations. Comparisons indicate the capability of the method to generate length optimal paths as the most effective methods do.
A cost-benefit analysis of cross-lingual transfer methods
May 14, 2021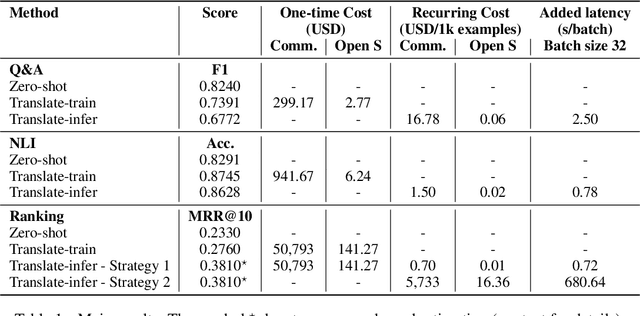
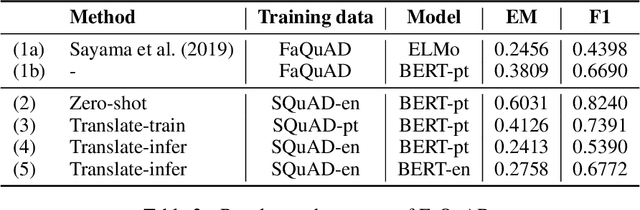
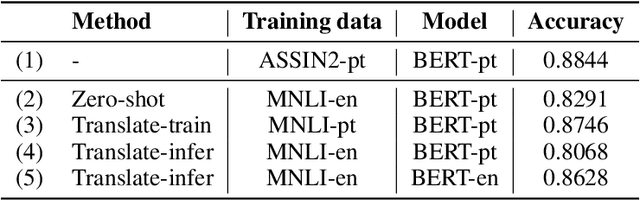
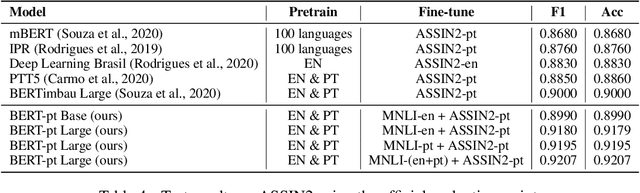
An effective method for cross-lingual transfer is to fine-tune a bilingual or multilingual model on a supervised dataset in one language and evaluating it on another language in a zero-shot manner. Translating examples at training time or inference time are also viable alternatives. However, there are costs associated with these methods that are rarely addressed in the literature. In this work, we analyze cross-lingual methods in terms of their effectiveness (e.g., accuracy), development and deployment costs, as well as their latencies at inference time. Our experiments on three tasks indicate that the best cross-lingual method is highly task-dependent. Finally, by combining zero-shot and translation methods, we achieve the state-of-the-art in two of the three datasets used in this work. Based on these results, we question the need for manually labeled training data in a target language. Code, models and translated datasets are available at https://github.com/unicamp-dl/cross-lingual-analysis
A systematic evaluation of methods for cell phenotype classification using single-cell RNA sequencing data
Oct 01, 2021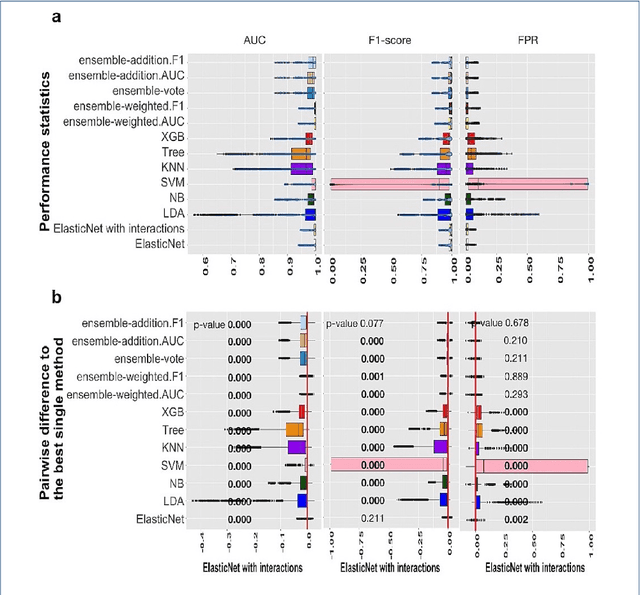
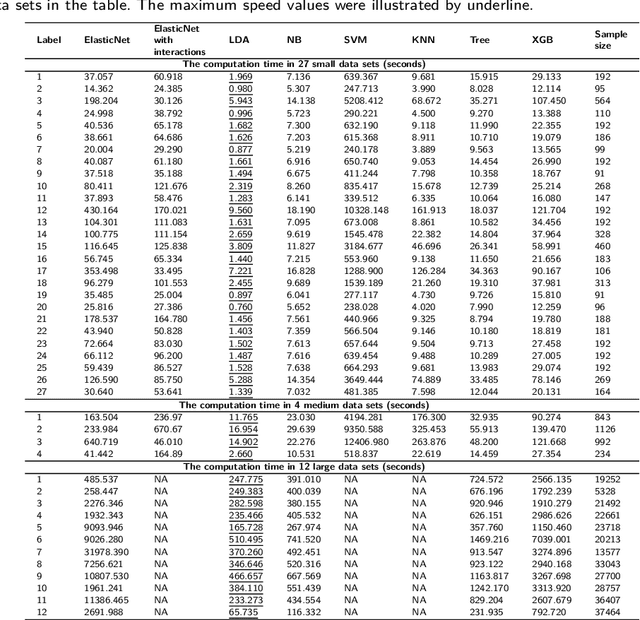
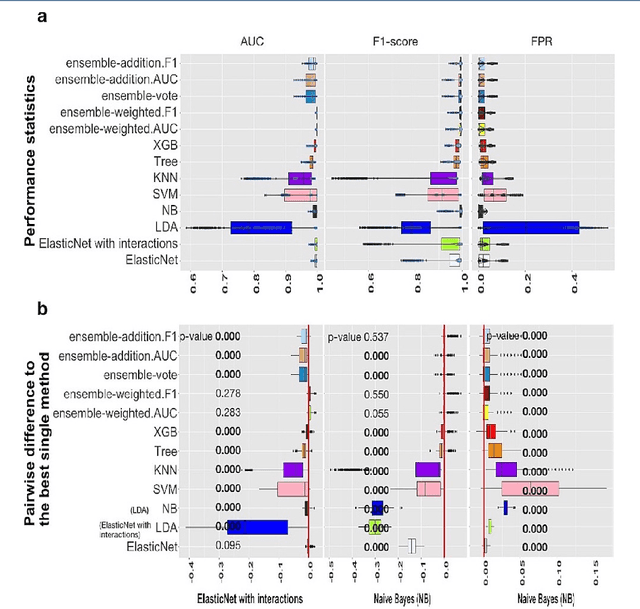
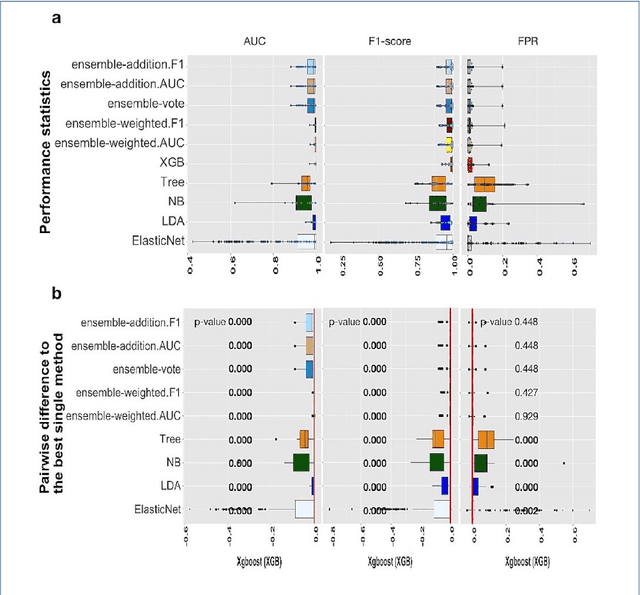
Background: Single-cell RNA sequencing (scRNA-seq) yields valuable insights about gene expression and gives critical information about complex tissue cellular composition. In the analysis of single-cell RNA sequencing, the annotations of cell subtypes are often done manually, which is time-consuming and irreproducible. Garnett is a cell-type annotation software based the on elastic net method. Besides cell-type annotation, supervised machine learning methods can also be applied to predict other cell phenotypes from genomic data. Despite the popularity of such applications, there is no existing study to systematically investigate the performance of those supervised algorithms in various sizes of scRNA-seq data sets. Methods and Results: This study evaluates 13 popular supervised machine learning algorithms to classify cell phenotypes, using published real and simulated data sets with diverse cell sizes. The benchmark contained two parts. In the first part, we used real data sets to assess the popular supervised algorithms' computing speed and cell phenotype classification performance. The classification performances were evaluated using AUC statistics, F1-score, precision, recall, and false-positive rate. In the second part, we evaluated gene selection performance using published simulated data sets with a known list of real genes. Conclusion: The study outcomes showed that ElasticNet with interactions performed best in small and medium data sets. NB was another appropriate method for medium data sets. In large data sets, XGB works excellent. Ensemble algorithms were not significantly superior to individual machine learning methods. Adding interactions to ElasticNet can help, and the improvement was significant in small data sets.
Intrinsic Spike Timing Dependent Plasticity in Stochastic Magnetic Tunnel Junctions Mediated by Heat Dynamics
Aug 28, 2021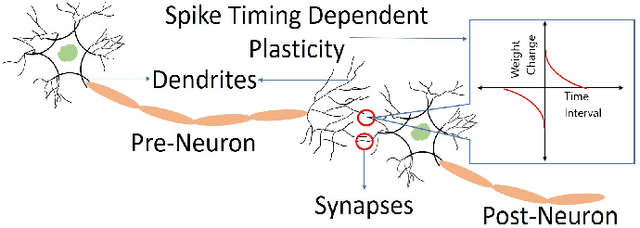
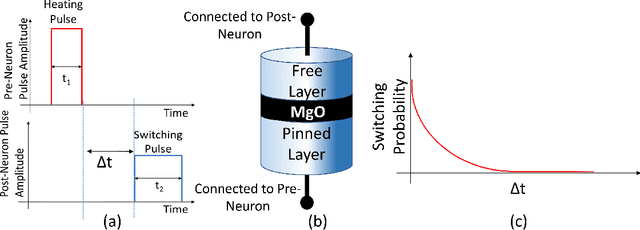
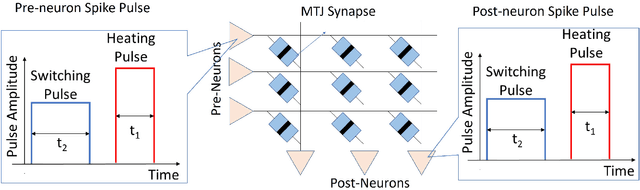
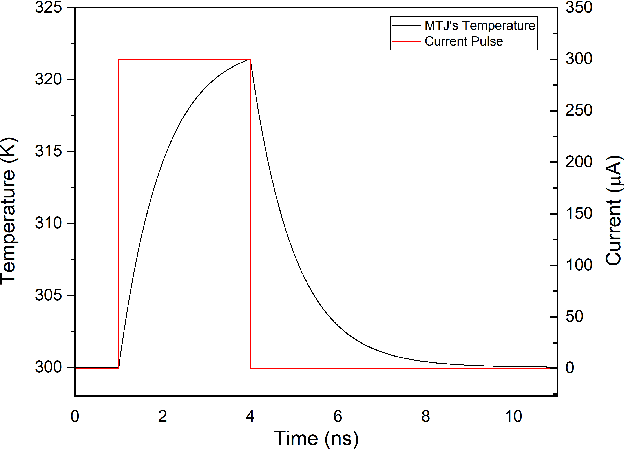
The quest for highly efficient cognitive computing has led to extensive research interest for the field of neuromorphic computing. Neuromorphic computing aims to mimic the behavior of biological neurons and synapses using solid-state devices and circuits. Among various approaches, emerging non-volatile memory technologies are of special interest for mimicking neuro-synaptic behavior. These devices allow the mapping of the rich dynamics of biological neurons and synapses onto their intrinsic device physics. In this letter, we focus on Spike Timing Dependent Plasticity (STDP) behavior of biological synapses and propose a method to implement the STDP behavior in Magnetic Tunnel Junction (MTJ) devices. Specifically, we exploit the time-dependent heat dynamics and the response of an MTJ to the instantaneous temperature to imitate the STDP behavior. Our simulations, based on a macro-spin model for magnetization dynamics, show that, STDP can be imitated in stochastic magnetic tunnel junctions by applying simple voltage waveforms as the spiking response of pre- and post-neurons across an MTJ device.
HAC Explore: Accelerating Exploration with Hierarchical Reinforcement Learning
Aug 12, 2021
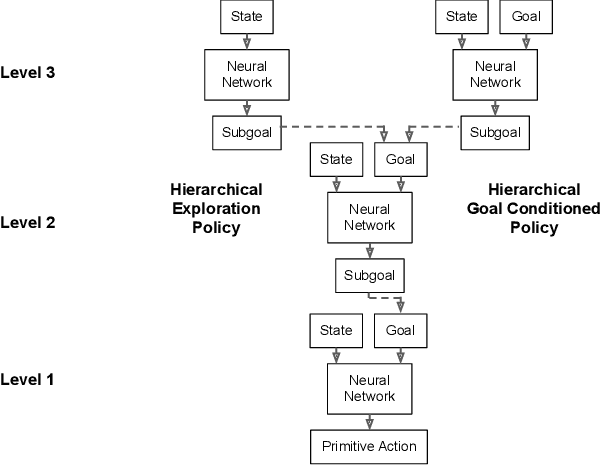
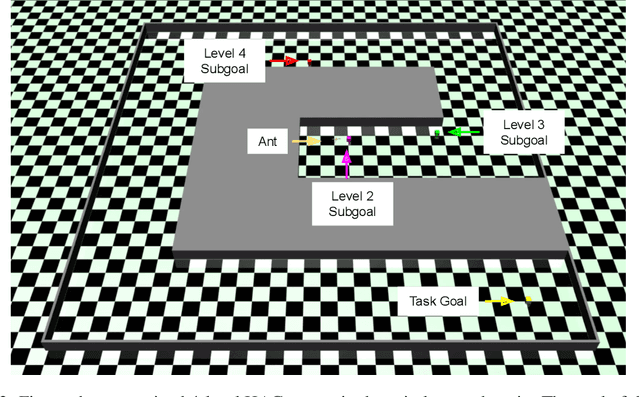
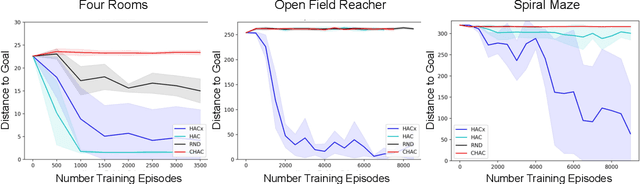
Sparse rewards and long time horizons remain challenging for reinforcement learning algorithms. Exploration bonuses can help in sparse reward settings by encouraging agents to explore the state space, while hierarchical approaches can assist with long-horizon tasks by decomposing lengthy tasks into shorter subtasks. We propose HAC Explore (HACx), a new method that combines these approaches by integrating the exploration bonus method Random Network Distillation (RND) into the hierarchical approach Hierarchical Actor-Critic (HAC). HACx outperforms either component method on its own, as well as an existing approach to combining hierarchy and exploration, in a set of difficult simulated robotics tasks. HACx is the first RL method to solve a sparse reward, continuous-control task that requires over 1,000 actions.
FireNet: Real-time Segmentation of Fire Perimeter from Aerial Video
Oct 14, 2019

In this paper, we share our approach to real-time segmentation of fire perimeter from aerial full-motion infrared video. We start by describing the problem from a humanitarian aid and disaster response perspective. Specifically, we explain the importance of the problem, how it is currently resolved, and how our machine learning approach improves it. To test our models we annotate a large-scale dataset of 400,000 frames with guidance from domain experts. Finally, we share our approach currently deployed in production with inference speed of 20 frames per second and an accuracy of 92 (F1 Score).
MAP-CSI: Single-site Map-Assisted Localization Using Massive MIMO CSI
Oct 01, 2021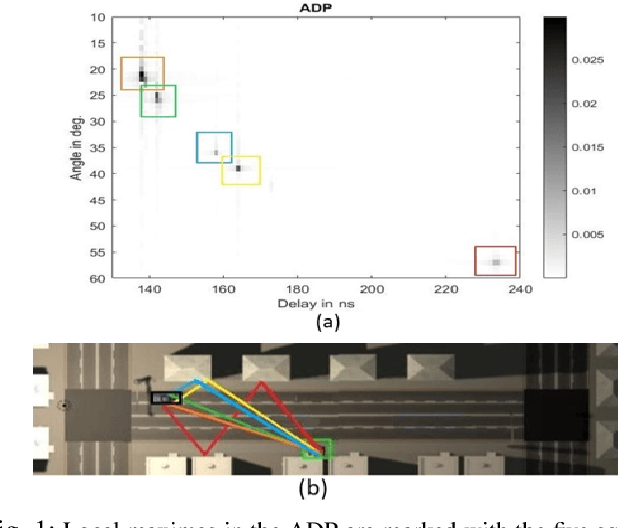
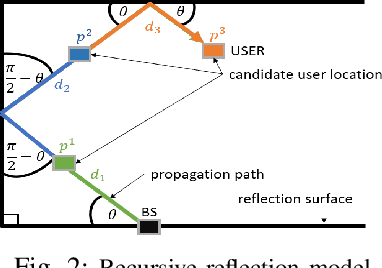

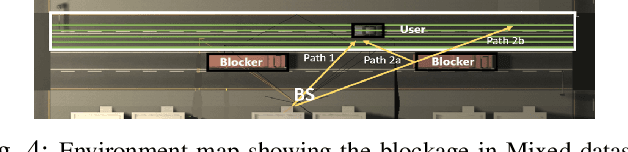
This paper presents a new map-assisted localization approach utilizing Chanel State Information (CSI) in Massive Multiple-Input Multiple-Output (MIMO) systems. Map-assisted localization is an environment-aware approach in which the communication system has information regarding the surrounding environment. By combining radio frequency ray tracing parameters of the multipath components (MPC) with the environment map, it is possible to accomplish localization. Unfortunately, in real-world scenarios, ray tracing parameters are typically not explicitly available. Thus, additional complexity is added at a base station to obtain this information. On the other hand, CSI is a common communication parameter, usually estimated for any communication channel. In this work, we leverage the already available CSI data to propose a novel map-assisted CSI localization approach, referred to as MAP-CSI. We show that Angle-of-Departure (AoD) and Time-of-Arrival (ToA) can be extracted from CSI and then be used in combination with the environment map to localize the user. We perform simulations on a public MIMO dataset and show that our method works for both line-of-sight (LOS) and non-line-of-sight (NLOS) scenarios. We compare our method to the state-of-the-art (SoA) method that uses the ray tracing data. Using MAP-CSI, we accomplish an average localization error of 1.8 m in LOS and 2.8 m in mixed (combination of LOS and NLOS samples) scenarios. On the other hand, SoA ray tracing has an average error of 1.0 m and 2.2 m, respectively, but requires explicit AoD and ToA information to perform the localization task.