 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adversarial Representation Learning With Closed-Form Solvers
Sep 12, 2021
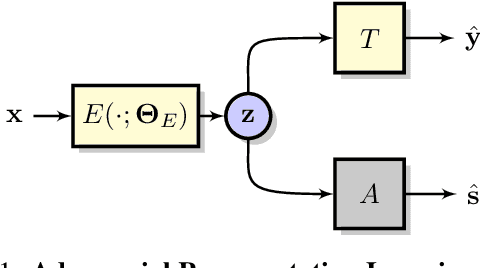
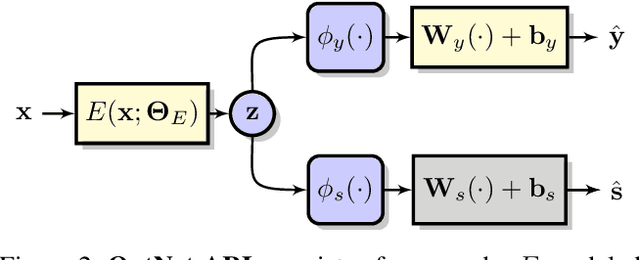
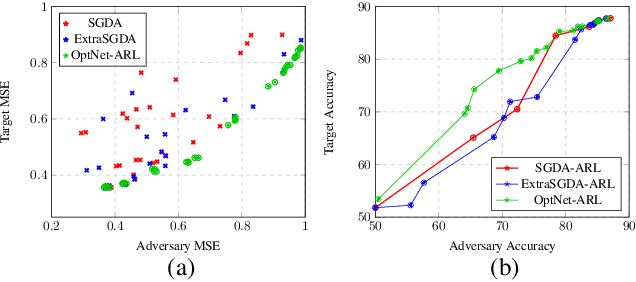
Adversarial representation learning aims to learn data representations for a target task while removing unwanted sensitive information at the same time. Existing methods learn model parameters iteratively through stochastic gradient descent-ascent, which is often unstable and unreliable in practice. To overcome this challenge, we adopt closed-form solvers for the adversary and target task. We model them as kernel ridge regressors and analytically determine an upper-bound on the optimal dimensionality of representation. Our solution, dubbed OptNet-ARL, reduces to a stable one one-shot optimization problem that can be solved reliably and efficiently. OptNet-ARL can be easily generalized to the case of multiple target tasks and sensitive attributes. Numerical experiments, on both small and large scale datasets, show that, from an optimization perspective, OptNet-ARL is stable and exhibits three to five times faster convergence. Performance wise, when the target and sensitive attributes are dependent, OptNet-ARL learns representations that offer a better trade-off front between (a) utility and bias for fair classification and (b) utility and privacy by mitigating leakage of private information than existing solutions.
FLASHE: Additively Symmetric Homomorphic Encryption for Cross-Silo Federated Learning
Sep 02, 2021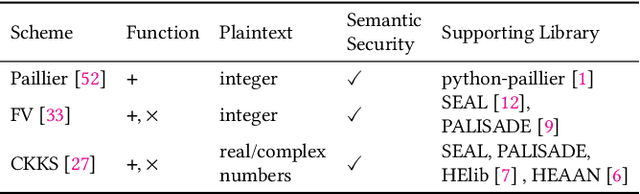
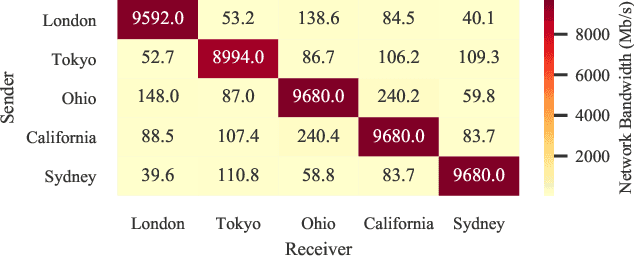
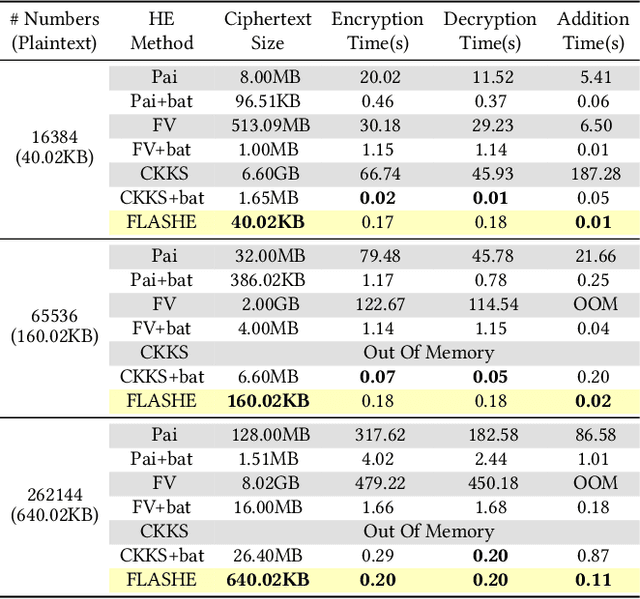
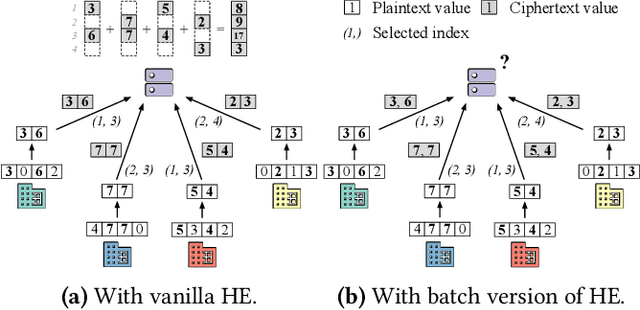
Homomorphic encryption (HE) is a promising privacy-preserving technique for cross-silo federated learning (FL), where organizations perform collaborative model training on decentralized data. Despite the strong privacy guarantee, general HE schemes result in significant computation and communication overhead. Prior works employ batch encryption to address this problem, but it is still suboptimal in mitigating communication overhead and is incompatible with sparsification techniques. In this paper, we propose FLASHE, an HE scheme tailored for cross-silo FL. To capture the minimum requirements of security and functionality, FLASHE drops the asymmetric-key design and only involves modular addition operations with random numbers. Depending on whether to accommodate sparsification techniques, FLASHE is optimized in computation efficiency with different approaches. We have implemented FLASHE as a pluggable module atop FATE, an industrial platform for cross-silo FL. Compared to plaintext training, FLASHE slightly increases the training time by $\leq6\%$, with no communication overhead.
Efficient refinements on YOLOv3 for real-time detection and assessment of diabetic foot Wagner grades
Jun 04, 2020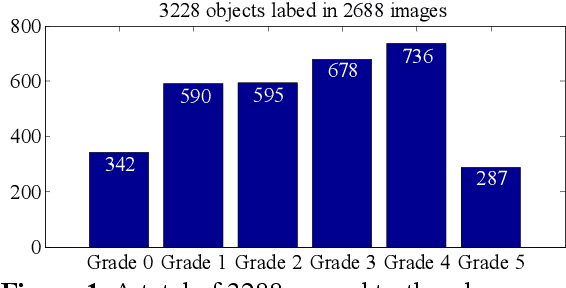
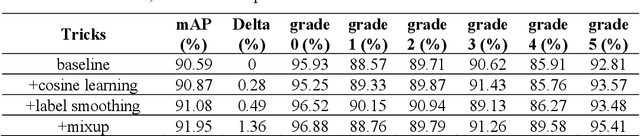
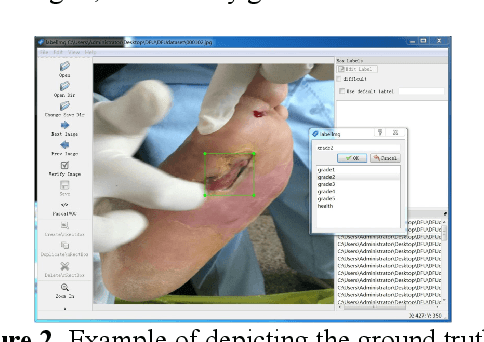
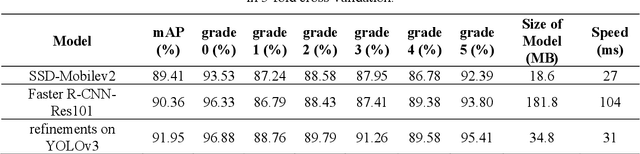
Currently, the screening of Wagner grades of diabetic feet (DF) still relies on professional podiatrists. However, in less-developed countries, podiatrists are scarce, which led to the majority of undiagnosed patients. In this study, we proposed the real-time detection and location method for Wagner grades of DF based on refinements on YOLOv3. We collected 2,688 data samples and implemented several methods, such as a visual coherent image mixup, label smoothing, and training scheduler revamping, based on the ablation study. The experimental results suggested that the refinements on YOLOv3 achieved an accuracy of 91.95% and the inference speed of a single picture reaches 31ms with the NVIDIA Tesla V100. To test the performance of the model on a smartphone, we deployed the refinements on YOLOv3 models on an Android 9 system smartphone. This work has the potential to lead to a paradigm shift for clinical treatment of the DF in the future, to provide an effective healthcare solution for DF tissue analysis and healing status.
Extracting Event Temporal Relations via Hyperbolic Geometry
Sep 12, 2021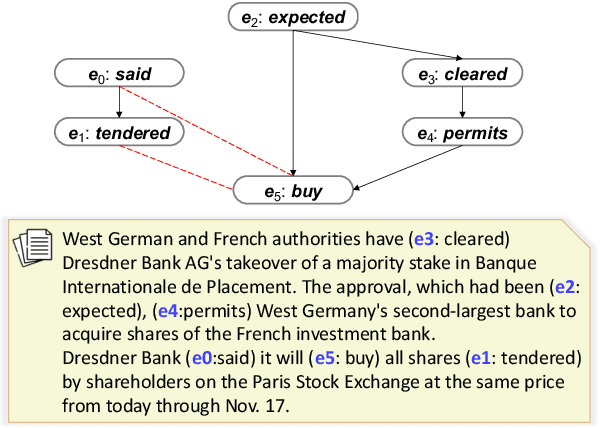
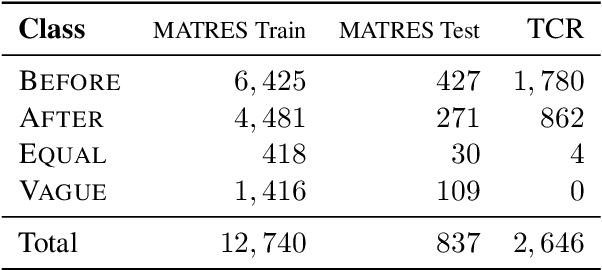

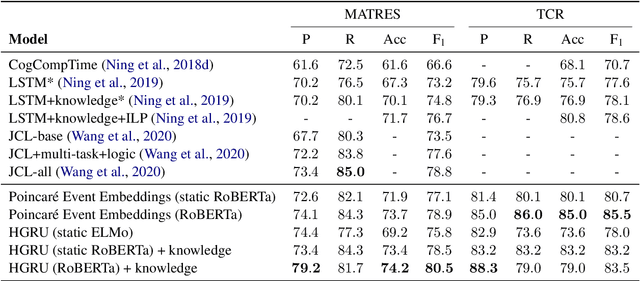
Detecting events and their evolution through time is a crucial task in natural language understanding. Recent neural approaches to event temporal relation extraction typically map events to embeddings in the Euclidean space and train a classifier to detect temporal relations between event pairs. However, embeddings in the Euclidean space cannot capture richer asymmetric relations such as event temporal relations. We thus propose to embed events into hyperbolic spaces, which are intrinsically oriented at modeling hierarchical structures. We introduce two approaches to encode events and their temporal relations in hyperbolic spaces. One approach leverages hyperbolic embeddings to directly infer event relations through simple geometrical operations. In the second one, we devise an end-to-end architecture composed of hyperbolic neural units tailored for the temporal relation extraction task. Thorough experimental assessments on widely used datasets have shown the benefits of revisiting the tasks on a different geometrical space, resulting in state-of-the-art performance on several standard metrics. Finally, the ablation study and several qualitative analyses highlighted the rich event semantics implicitly encoded into hyperbolic spaces.
RCLC: ROI-based joint conventional and learning video compression
Jul 14, 2021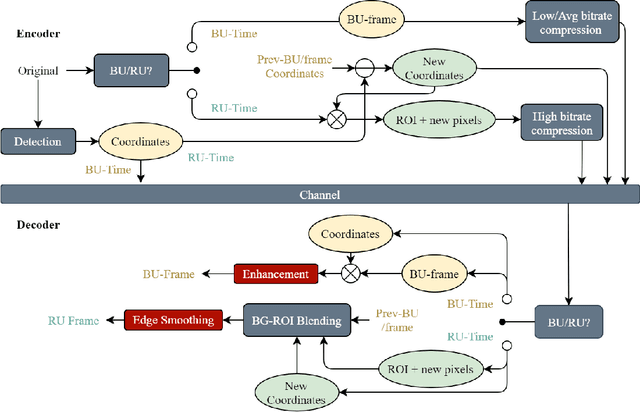
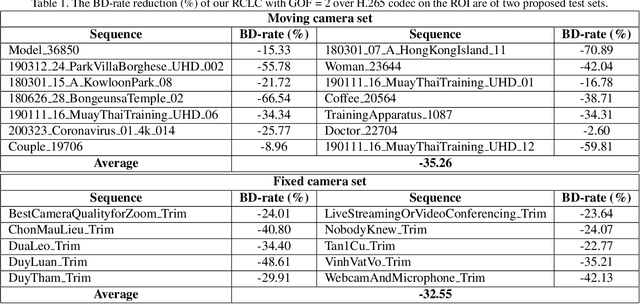
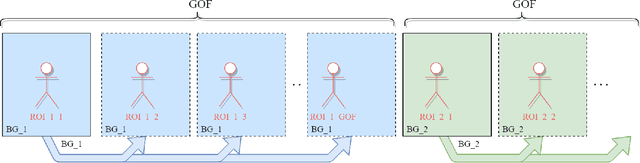
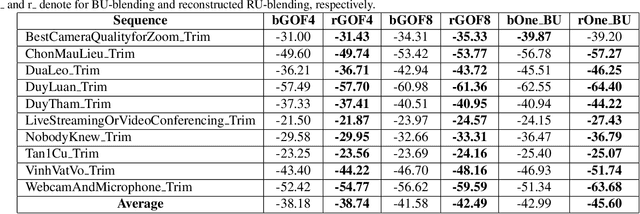
COVID-19 leads to the high demand for remote interactive systems ever seen. One of the key elements of these systems is video streaming, which requires a very high network bandwidth due to its specific real-time demand, especially with high-resolution video. Existing video compression methods are struggling in the trade-off between video quality and the speed requirement. Addressed that the background information rarely changes in most remote meeting cases, we introduce a Region-Of-Interests (ROI) based video compression framework (named RCLC) that leverages the cutting-edge learning-based and conventional technologies. In RCLC, each coming frame is marked as a background-updating (BU) or ROI-updating (RU) frame. By applying the conventional video codec, the BU frame is compressed with low-quality and high-compression, while the ROI from RU-frame is compressed with high-quality and low-compression. The learning-based methods are applied to detect the ROI, blend background-ROI, and enhance video quality. The experimental results show that our RCLC can reduce up to 32.55\% BD-rate for the ROI region compared to H.265 video codec under a similar compression time with 1080p resolution.
Ousiometrics and Telegnomics: The essence of meaning conforms to a two-dimensional powerful-weak and dangerous-safe framework with diverse corpora presenting a safety bias
Oct 13, 2021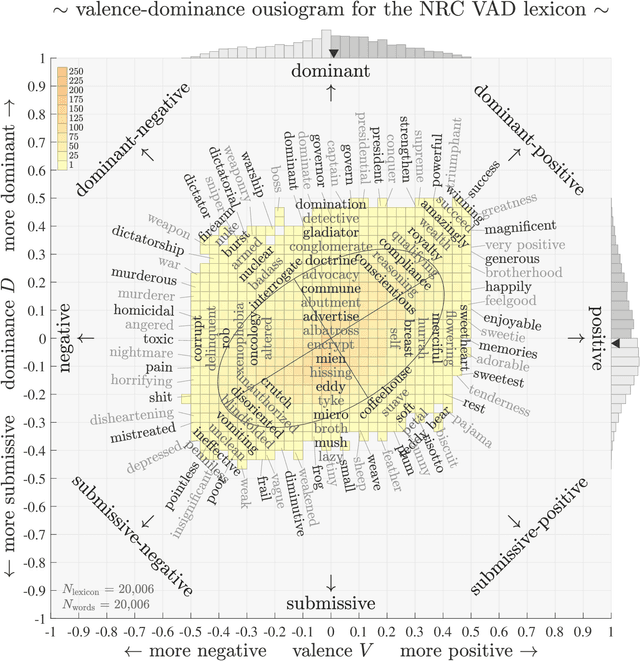
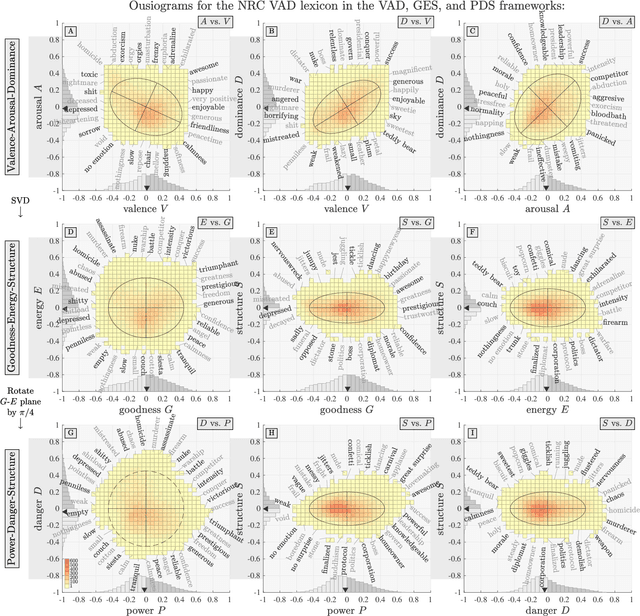
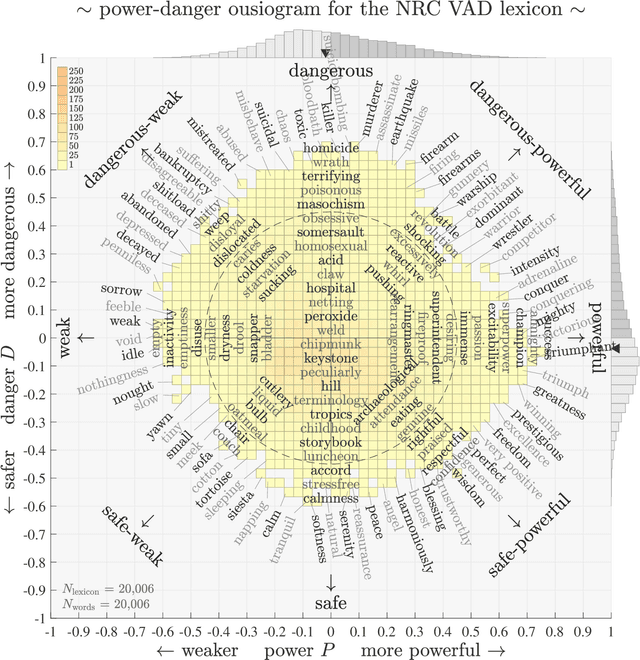
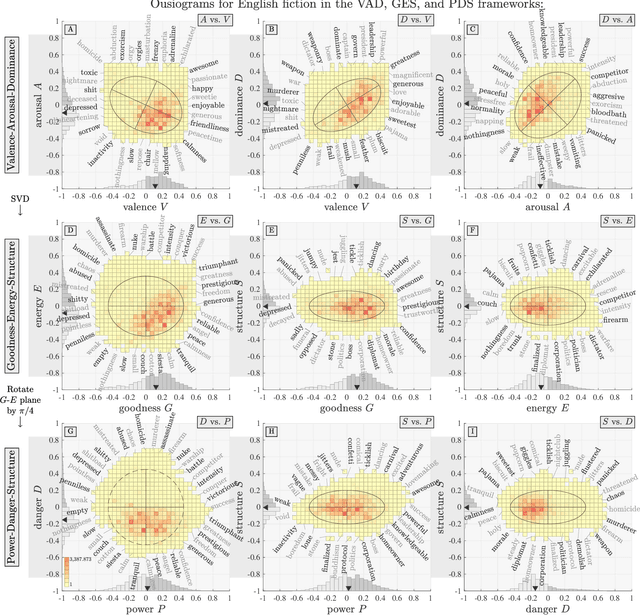
We define `ousiometrics' to be the study of essential meaning in whatever context that meaningful signals are communicated, and `telegnomics' as the study of remotely sensed knowledge. From work emerging through the middle of the 20th century, the essence of meaning has become generally accepted as being well captured by the three orthogonal dimensions of evaluation, potency, and activation (EPA). By re-examining first types and then tokens for the English language, and through the use of automatically annotated histograms -- `ousiograms' -- we find here that: 1. The essence of meaning conveyed by words is instead best described by a compass-like power-danger (PD) framework, and 2. Analysis of a disparate collection of large-scale English language corpora -- literature, news, Wikipedia, talk radio, and social media -- shows that natural language exhibits a systematic bias toward safe, low danger words -- a reinterpretation of the Pollyanna principle's positivity bias for written expression. To help justify our choice of dimension names and to help address the problems with representing observed ousiometric dimensions by bipolar adjective pairs, we introduce and explore `synousionyms' and `antousionyms' -- ousiometric counterparts of synonyms and antonyms. We further show that the PD framework revises the circumplex model of affect as a more general model of state of mind. Finally, we use our findings to construct and test a prototype `ousiometer', a telegnomic instrument that measures ousiometric time series for temporal corpora. We contend that our power-danger ousiometric framework provides a complement for entropy-based measurements, and may be of value for the study of a wide variety of communication across biological and artificial life.
Comparison of end-to-end neural network architectures and data augmentation methods for automatic infant motility assessment using wearable sensors
Jul 02, 2021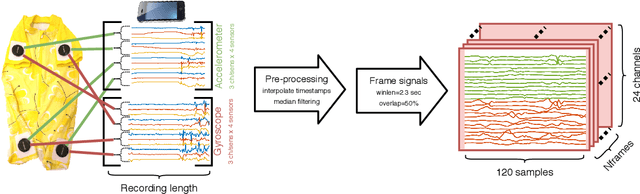
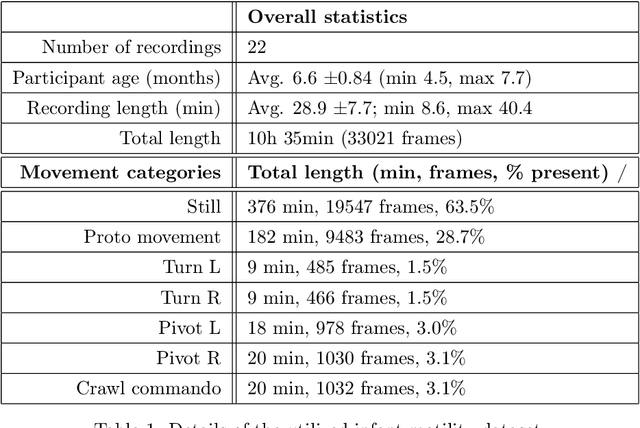
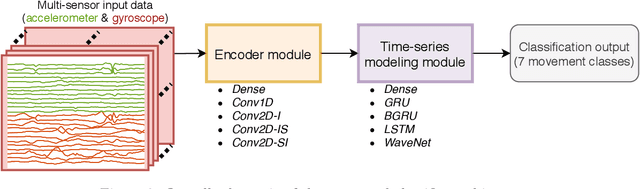
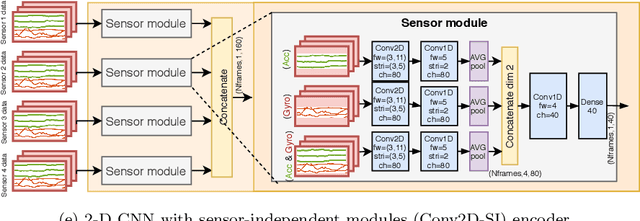
Infant motility assessment using intelligent wearables is a promising new approach for assessment of infant neurophysiological development, and where efficient signal analysis plays a central role. This study investigates the use of different end-to-end neural network architectures for processing infant motility data from wearable sensors. We focus on the performance and computational burden of alternative sensor encoder and time-series modelling modules and their combinations. In addition, we explore the benefits of data augmentation methods in ideal and non-ideal recording conditions. The experiments are conducted using a data-set of multi-sensor movement recordings from 7-month-old infants, as captured by a recently proposed smart jumpsuit for infant motility assessment. Our results indicate that the choice of the encoder module has a major impact on classifier performance. For sensor encoders, the best performance was obtained with parallel 2-dimensional convolutions for intra-sensor channel fusion with shared weights for all sensors. The results also indicate that a relatively compact feature representation is obtainable for within-sensor feature extraction without a drastic loss to classifier performance. Comparison of time-series models revealed that feed-forward dilated convolutions with residual and skip connections outperformed all RNN-based models in performance, training time, and training stability. The experiments also indicate that data augmentation improves model robustness in simulated packet loss or sensor dropout scenarios. In particular, signal- and sensor-dropout-based augmentation strategies provided considerable boosts to performance without negatively affecting the baseline performance. Overall the results provide tangible suggestions on how to optimize end-to-end neural network training for multi-channel movement sensor data.
Unlocking the potential of deep learning for marine ecology: overview, applications, and outlook
Sep 29, 2021

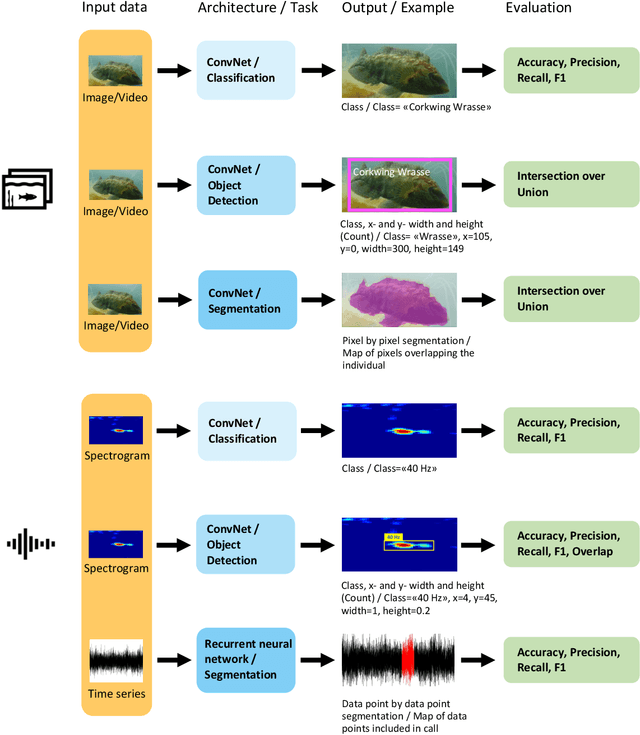
The deep learning revolution is touching all scientific disciplines and corners of our lives as a means of harnessing the power of big data. Marine ecology is no exception. These new methods provide analysis of data from sensors, cameras, and acoustic recorders, even in real time, in ways that are reproducible and rapid. Off-the-shelf algorithms can find, count, and classify species from digital images or video and detect cryptic patterns in noisy data. Using these opportunities requires collaboration across ecological and data science disciplines, which can be challenging to initiate. To facilitate these collaborations and promote the use of deep learning towards ecosystem-based management of the sea, this paper aims to bridge the gap between marine ecologists and computer scientists. We provide insight into popular deep learning approaches for ecological data analysis in plain language, focusing on the techniques of supervised learning with deep neural networks, and illustrate challenges and opportunities through established and emerging applications of deep learning to marine ecology. We use established and future-looking case studies on plankton, fishes, marine mammals, pollution, and nutrient cycling that involve object detection, classification, tracking, and segmentation of visualized data. We conclude with a broad outlook of the field's opportunities and challenges, including potential technological advances and issues with managing complex data sets.
Targeted Gradient Descent: A Novel Method for Convolutional Neural Networks Fine-tuning and Online-learning
Sep 29, 2021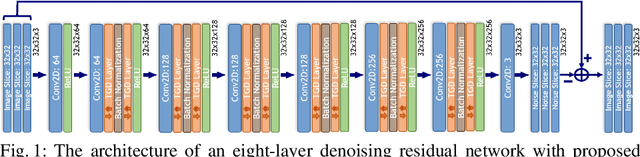
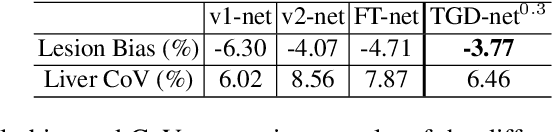
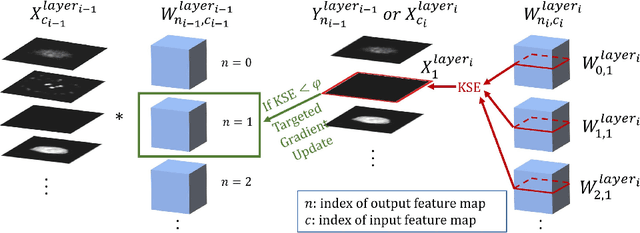

A convolutional neural network (ConvNet) is usually trained and then tested using images drawn from the same distribution. To generalize a ConvNet to various tasks often requires a complete training dataset that consists of images drawn from different tasks. In most scenarios, it is nearly impossible to collect every possible representative dataset as a priori. The new data may only become available after the ConvNet is deployed in clinical practice. ConvNet, however, may generate artifacts on out-of-distribution testing samples. In this study, we present Targeted Gradient Descent (TGD), a novel fine-tuning method that can extend a pre-trained network to a new task without revisiting data from the previous task while preserving the knowledge acquired from previous training. To a further extent, the proposed method also enables online learning of patient-specific data. The method is built on the idea of reusing a pre-trained ConvNet's redundant kernels to learn new knowledge. We compare the performance of TGD to several commonly used training approaches on the task of Positron emission tomography (PET) image denoising. Results from clinical images show that TGD generated results on par with training-from-scratch while significantly reducing data preparation and network training time. More importantly, it enables online learning on the testing study to enhance the network's generalization capability in real-world applications.
Fourier Neural Operator Networks: A Fast and General Solver for the Photoacoustic Wave Equation
Aug 20, 2021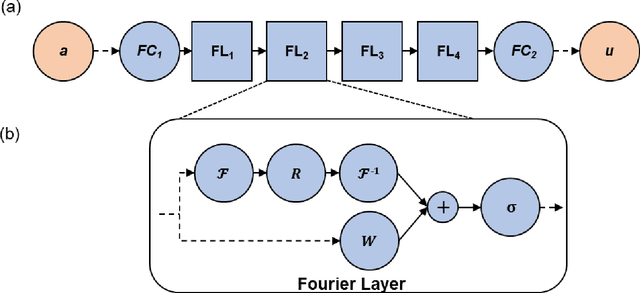
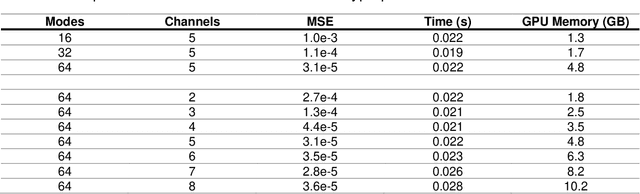
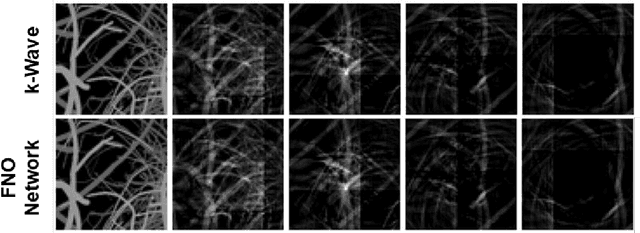
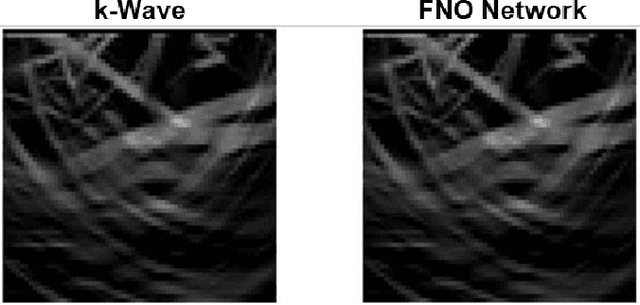
Simulation tools for photoacoustic wave propagation have played a key role in advancing photoacoustic imaging by providing quantitative and qualitative insights into parameters affecting image quality. Classical methods for numerically solving the photoacoustic wave equation relies on a fine discretization of space and can become computationally expensive for large computational grids. In this work, we apply Fourier Neural Operator (FNO) networks as a fast data-driven deep learning method for solving the 2D photoacoustic wave equation in a homogeneous medium. Comparisons between the FNO network and pseudo-spectral time domain approach demonstrated that the FNO network generated comparable simulations with small errors and was several orders of magnitude faster. Moreover, the FNO network was generalizable and can generate simulations not observed in the training data.