 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Novel Sleep Stage Classification Using CNN Generated by an Efficient Neural Architecture Search with a New Data Processing Trick
Oct 27, 2021
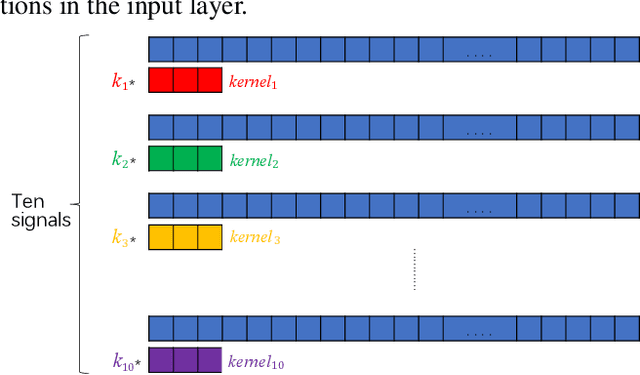

With the development of automatic sleep stage classification (ASSC) techniques, many classical methods such as k-means, decision tree, and SVM have been used in automatic sleep stage classification. However, few methods explore deep learning on ASSC. Meanwhile, most deep learning methods require extensive expertise and suffer from a mass of handcrafted steps which are time-consuming especially when dealing with multi-classification tasks. In this paper, we propose an efficient five-sleep-stage classification method using convolutional neural networks (CNNs) with a novel data processing trick and we design neural architecture search (NAS) technique based on genetic algorithm (GA), NAS-G, to search for the best CNN architecture. Firstly, we attach each kernel with an adaptive coefficient to enhance the signal processing of the inputs. This can enhance the propagation of informative features and suppress the propagation of useless features in the early stage of the network. Then, we make full use of GA's heuristic search and the advantage of no need for the gradient to search for the best architecture of CNN. This can achieve a CNN with better performance than a handcrafted one in a large search space at the minimum cost. We verify the convergence of our data processing trick and compare the performance of traditional CNNs before and after using our trick. Meanwhile, we compare the performance between the CNN generated through NAS-G and the traditional CNNs with our trick. The experiments demonstrate that the convergence of CNNs with data processing trick is faster than without data processing trick and the CNN with data processing trick generated by NAS-G outperforms the handcrafted counterparts that use the data processing trick too.
Clustering in Recurrent Neural Networks for Micro-Segmentation using Spending Personality
Sep 20, 2021
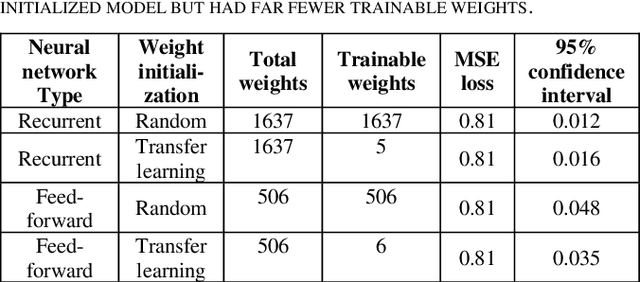
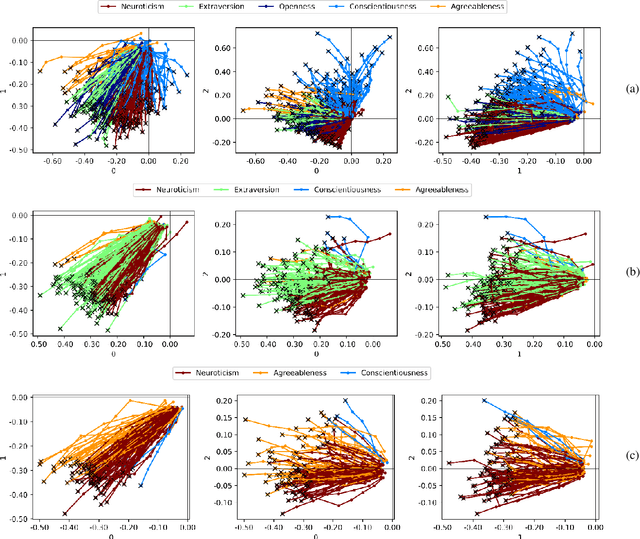
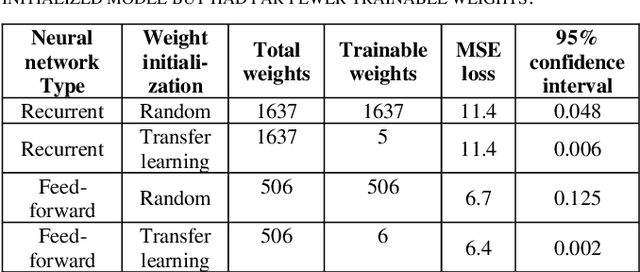
Customer segmentation has long been a productive field in banking. However, with new approaches to traditional problems come new opportunities. Fine-grained customer segments are notoriously elusive and one method of obtaining them is through feature extraction. It is possible to assign coefficients of standard personality traits to financial transaction classes aggregated over time. However, we have found that the clusters formed are not sufficiently discriminatory for micro-segmentation. In this study, we extract temporal features with continuous values from the hidden states of neural networks predicting customers' spending personality from their financial transactions. We consider both temporal and non-sequential models, using long short-term memory (LSTM) and feed-forward neural networks, respectively. We found that recurrent neural networks produce micro-segments where feed-forward networks produce only course segments. Finally, we show that classification using these extracted features performs at least as well as bespoke models on two common metrics, namely loan default rate and customer liquidity index.
A Comprehensive Study on Torchvision Pre-trained Models for Fine-grained Inter-species Classification
Oct 14, 2021



This study aims to explore different pre-trained models offered in the Torchvision package which is available in the PyTorch library. And investigate their effectiveness on fine-grained images classification. Transfer Learning is an effective method of achieving extremely good performance with insufficient training data. In many real-world situations, people cannot collect sufficient data required to train a deep neural network model efficiently. Transfer Learning models are pre-trained on a large data set, and can bring a good performance on smaller datasets with significantly lower training time. Torchvision package offers us many models to apply the Transfer Learning on smaller datasets. Therefore, researchers may need a guideline for the selection of a good model. We investigate Torchvision pre-trained models on four different data sets: 10 Monkey Species, 225 Bird Species, Fruits 360, and Oxford 102 Flowers. These data sets have images of different resolutions, class numbers, and different achievable accuracies. We also apply their usual fully-connected layer and the Spinal fully-connected layer to investigate the effectiveness of SpinalNet. The Spinal fully-connected layer brings better performance in most situations. We apply the same augmentation for different models for the same data set for a fair comparison. This paper may help future Computer Vision researchers in choosing a proper Transfer Learning model.
* Accepted
Dynamic Planning and Learning under Recovering Rewards
Jun 28, 2021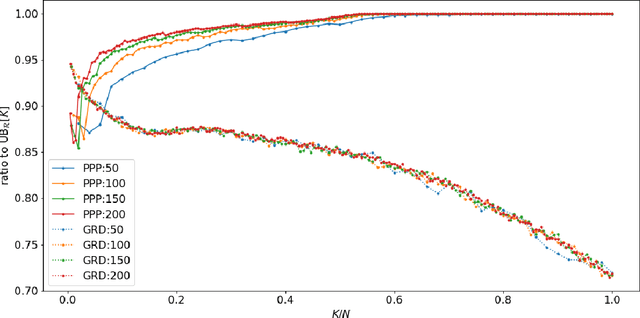
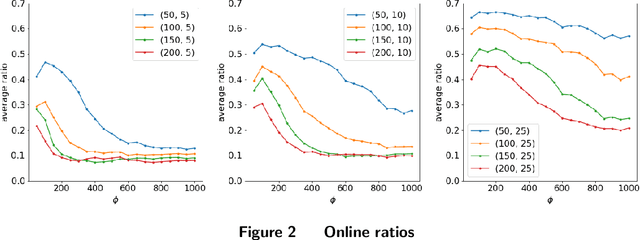
Motivated by emerging applications such as live-streaming e-commerce, promotions and recommendations, we introduce a general class of multi-armed bandit problems that have the following two features: (i) the decision maker can pull and collect rewards from at most $K$ out of $N$ different arms in each time period; (ii) the expected reward of an arm immediately drops after it is pulled, and then non parametrically recovers as the idle time increases. With the objective of maximizing expected cumulative rewards over $T$ time periods, we propose, construct and prove performance guarantees for a class of "Purely Periodic Policies". For the offline problem when all model parameters are known, our proposed policy obtains an approximation ratio that is at the order of $1-\mathcal O(1/\sqrt{K})$, which is asymptotically optimal when $K$ grows to infinity. For the online problem when the model parameters are unknown and need to be learned, we design an Upper Confidence Bound (UCB) based policy that approximately has $\widetilde{\mathcal O}(N\sqrt{T})$ regret against the offline benchmark. Our framework and policy design may have the potential to be adapted into other offline planning and online learning applications with non-stationary and recovering rewards.
Provident Vehicle Detection at Night for Advanced Driver Assistance Systems
Jul 23, 2021

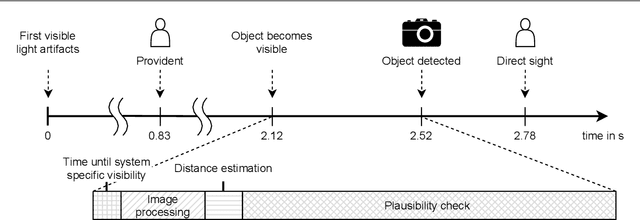

In recent years, computer vision algorithms have become more and more powerful, which enabled technologies such as autonomous driving to evolve with rapid pace. However, current algorithms mainly share one limitation: They rely on directly visible objects. This is a major drawback compared to human behavior, where indirect visual cues caused by the actual object (e.g., shadows) are already used intuitively to retrieve information or anticipate occurring objects. While driving at night, this performance deficit becomes even more obvious: Humans already process the light artifacts caused by oncoming vehicles to assume their future appearance, whereas current object detection systems rely on the oncoming vehicle's direct visibility. Based on previous work in this subject, we present with this paper a complete system capable of solving the task to providently detect oncoming vehicles at nighttime based on their caused light artifacts. For that, we outline the full algorithm architecture ranging from the detection of light artifacts in the image space, localizing the objects in the three-dimensional space, and verifying the objects over time. To demonstrate the applicability, we deploy the system in a test vehicle and use the information of providently detected vehicles to control the glare-free high beam system proactively. Using this experimental setting, we quantify the time benefit that the provident vehicle detection system provides compared to an in-production computer vision system. Additionally, the glare-free high beam use case provides a real-time and real-world visualization interface of the detection results. With this contribution, we want to put awareness on the unconventional sensing task of provident object detection and further close the performance gap between human behavior and computer vision algorithms in order to bring autonomous and automated driving a step forward.
Text to Insight: Accelerating Organic Materials Knowledge Extraction via Deep Learning
Sep 27, 2021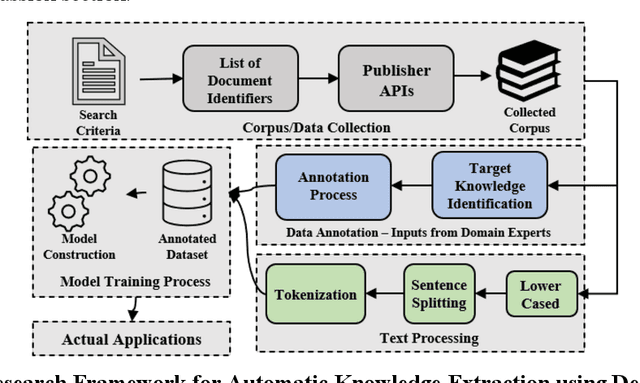

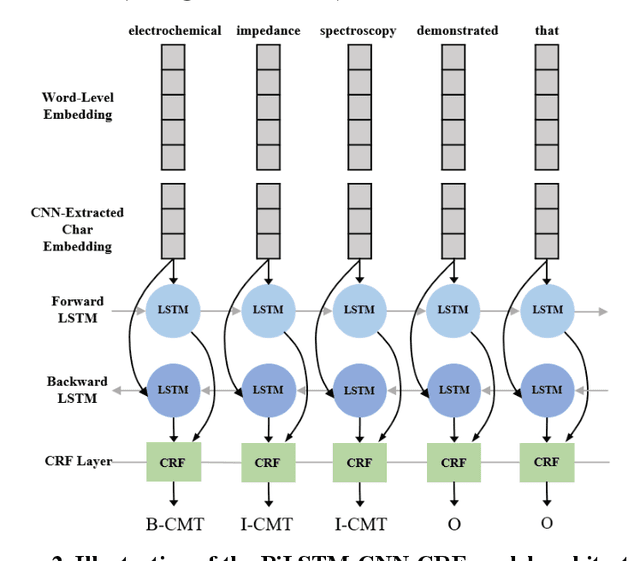
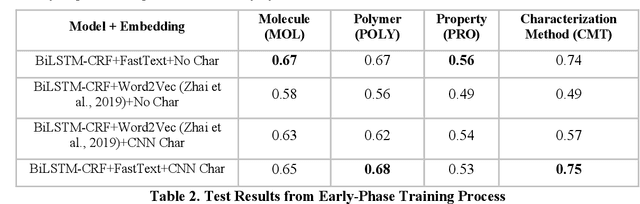
Scientific literature is one of the most significant resources for sharing knowledge. Researchers turn to scientific literature as a first step in designing an experiment. Given the extensive and growing volume of literature, the common approach of reading and manually extracting knowledge is too time consuming, creating a bottleneck in the research cycle. This challenge spans nearly every scientific domain. For the materials science, experimental data distributed across millions of publications are extremely helpful for predicting materials properties and the design of novel materials. However, only recently researchers have explored computational approaches for knowledge extraction primarily for inorganic materials. This study aims to explore knowledge extraction for organic materials. We built a research dataset composed of 855 annotated and 708,376 unannotated sentences drawn from 92,667 abstracts. We used named-entity-recognition (NER) with BiLSTM-CNN-CRF deep learning model to automatically extract key knowledge from literature. Early-phase results show a high potential for automated knowledge extraction. The paper presents our findings and a framework for supervised knowledge extraction that can be adapted to other scientific domains.
BGaitR-Net: Occluded Gait Sequence reconstructionwith temporally constrained model for gait recognition
Oct 18, 2021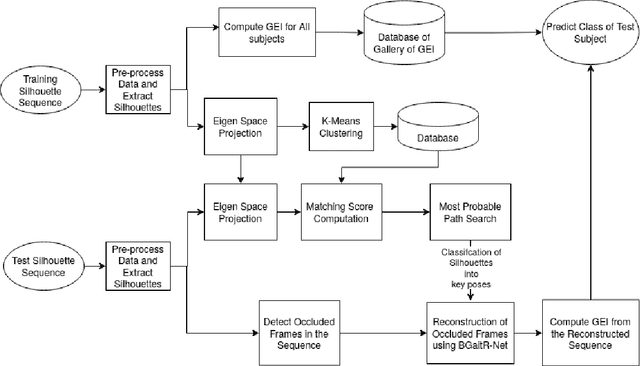
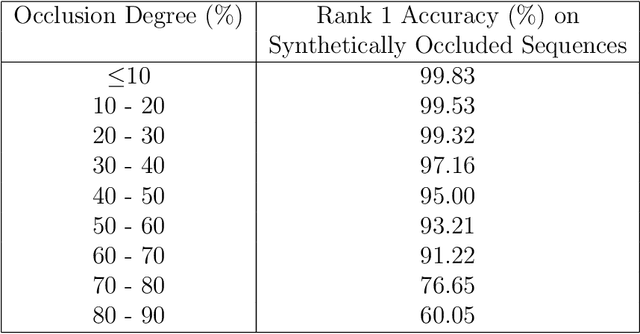

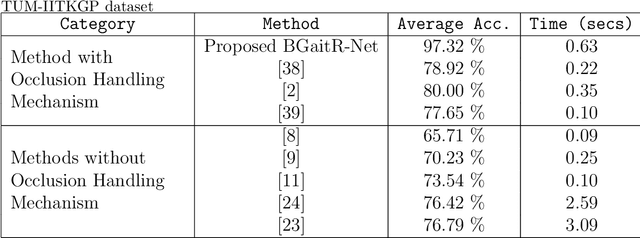
Recent advancements in computational resources and Deep Learning methodologies has significantly benefited development of intelligent vision-based surveillance applications. Gait recognition in the presence of occlusion is one of the challenging research topics in this area, and the solutions proposed by researchers to date lack in robustness and also dependent of several unrealistic constraints, which limits their practical applicability. We improve the state-of-the-art by developing novel deep learning-based algorithms to identify the occluded frames in an input sequence and next reconstruct these occluded frames by exploiting the spatio-temporal information present in the gait sequence. The multi-stage pipeline adopted in this work consists of key pose mapping, occlusion detection and reconstruction, and finally gait recognition. While the key pose mapping and occlusion detection phases are done %using Constrained KMeans Clustering and via a graph sorting algorithm, reconstruction of occluded frames is done by fusing the key pose-specific information derived in the previous step along with the spatio-temporal information contained in a gait sequence using a Bi-Directional Long Short Time Memory. This occlusion reconstruction model has been trained using synthetically occluded CASIA-B and OU-ISIR data, and the trained model is termed as Bidirectional Gait Reconstruction Network BGait-R-Net. Our LSTM-based model reconstructs occlusion and generates frames that are temporally consistent with the periodic pattern of a gait cycle, while simultaneously preserving the body structure.
ST-DETR: Spatio-Temporal Object Traces Attention Detection Transformer
Jul 13, 2021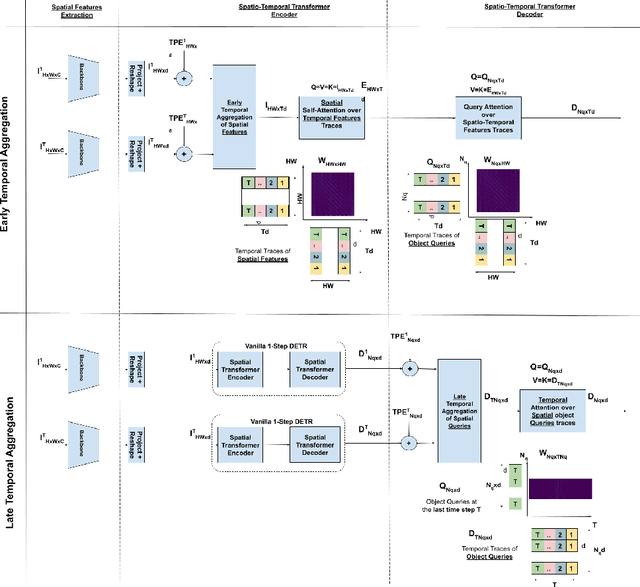

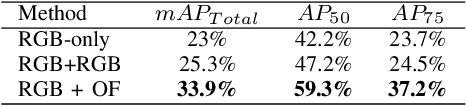

We propose ST-DETR, a Spatio-Temporal Transformer-based architecture for object detection from a sequence of temporal frames. We treat the temporal frames as sequences in both space and time and employ the full attention mechanisms to take advantage of the features correlations over both dimensions. This treatment enables us to deal with frames sequence as temporal object features traces over every location in the space. We explore two possible approaches; the early spatial features aggregation over the temporal dimension, and the late temporal aggregation of object query spatial features. Moreover, we propose a novel Temporal Positional Embedding technique to encode the time sequence information. To evaluate our approach, we choose the Moving Object Detection (MOD)task, since it is a perfect candidate to showcase the importance of the temporal dimension. Results show a significant 5% mAP improvement on the KITTI MOD dataset over the 1-step spatial baseline.
Corridor for new mobility Aachen-Düsseldorf: Methods and concepts of the research project ACCorD
Jul 13, 2021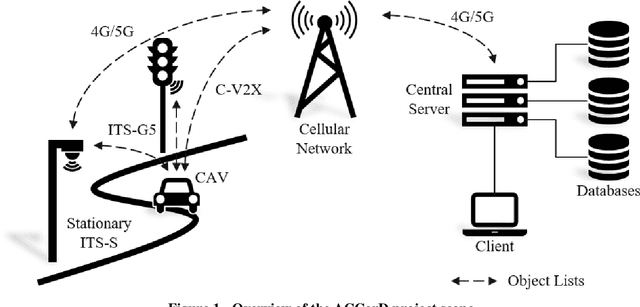
With the Corridor for New Mobility Aachen - D\"usseldorf, an integrated development environment is created, incorporating existing test capabilities, to systematically test and validate automated vehicles in interaction with connected Intelligent Transport Systems Stations (ITS-Ss). This is achieved through a time- and cost-efficient toolchain and methodology, in which simulation, closed test sites as well as test fields in public transport are linked in the best possible way. By implementing a digital twin, the recorded traffic events can be visualized in real-time and driving functions can be tested in the simulation based on real data. In order to represent diverse traffic scenarios, the corridor contains a highway section, a rural area, and urban areas. First, this paper outlines the project goals before describing the individual project contents in more detail. These include the concepts of traffic detection, driving function development, digital twin development, and public involvement.
Zero-Shot Personalized Speech Enhancement through Speaker-Informed Model Selection
May 08, 2021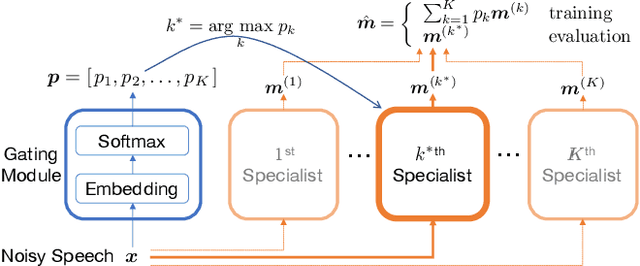
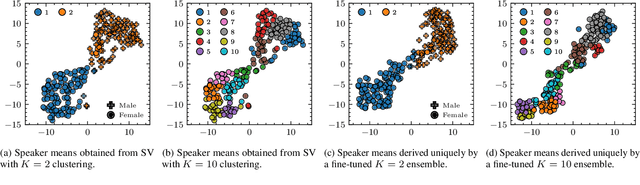
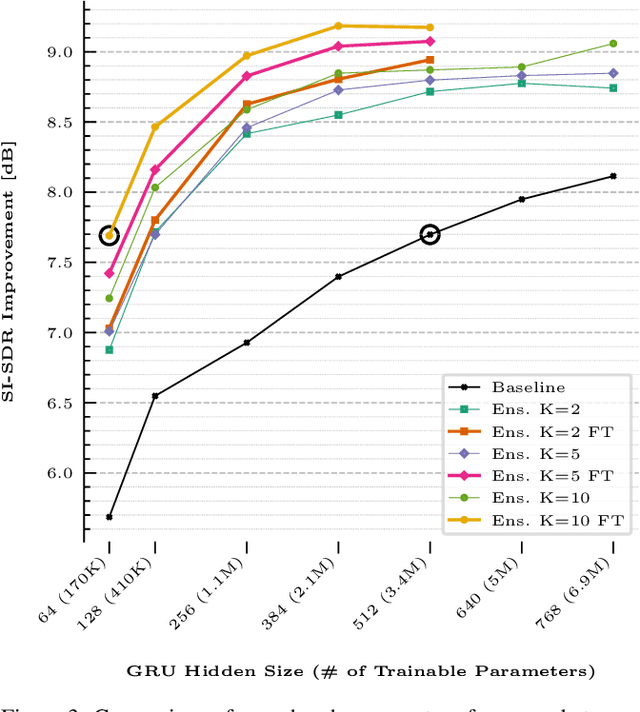
This paper presents a novel zero-shot learning approach towards personalized speech enhancement through the use of a sparsely active ensemble model. Optimizing speech denoising systems towards a particular test-time speaker can improve performance and reduce run-time complexity. However, test-time model adaptation may be challenging if collecting data from the test-time speaker is not possible. To this end, we propose using an ensemble model wherein each specialist module denoises noisy utterances from a distinct partition of training set speakers. The gating module inexpensively estimates test-time speaker characteristics in the form of an embedding vector and selects the most appropriate specialist module for denoising the test signal. Grouping the training set speakers into non-overlapping semantically similar groups is non-trivial and ill-defined. To do this, we first train a Siamese network using noisy speech pairs to maximize or minimize the similarity of its output vectors depending on whether the utterances derive from the same speaker or not. Next, we perform k-means clustering on the latent space formed by the averaged embedding vectors per training set speaker. In this way, we designate speaker groups and train specialist modules optimized around partitions of the complete training set. Our experiments show that ensemble models made up of low-capacity specialists can outperform high-capacity generalist models with greater efficiency and improved adaptation towards unseen test-time speakers.