 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Semantic Interoperability Across Materials Science With HIVE4MAT
Nov 01, 2024



HIVE4MAT is a linked data interactive application for navigating ontologies of value to materials science. HIVE enables automatic indexing of textual resources with standardized terminology. This article presents the motivation underlying HIVE4MAT, explains the system architecture, reports on two evaluations, and discusses future plans.
Knowledge Graph Question Answering for Materials Science (KGQA4MAT): Developing Natural Language Interface for Metal-Organic Frameworks Knowledge Graph (MOF-KG)
Sep 20, 2023We present a comprehensive benchmark dataset for Knowledge Graph Question Answering in Materials Science (KGQA4MAT), with a focus on metal-organic frameworks (MOFs). A knowledge graph for metal-organic frameworks (MOF-KG) has been constructed by integrating structured databases and knowledge extracted from the literature. To enhance MOF-KG accessibility for domain experts, we aim to develop a natural language interface for querying the knowledge graph. We have developed a benchmark comprised of 161 complex questions involving comparison, aggregation, and complicated graph structures. Each question is rephrased in three additional variations, resulting in 644 questions and 161 KG queries. To evaluate the benchmark, we have developed a systematic approach for utilizing ChatGPT to translate natural language questions into formal KG queries. We also apply the approach to the well-known QALD-9 dataset, demonstrating ChatGPT's potential in addressing KGQA issues for different platforms and query languages. The benchmark and the proposed approach aim to stimulate further research and development of user-friendly and efficient interfaces for querying domain-specific materials science knowledge graphs, thereby accelerating the discovery of novel materials.
Building Open Knowledge Graph for Metal-Organic Frameworks (MOF-KG): Challenges and Case Studies
Jul 10, 2022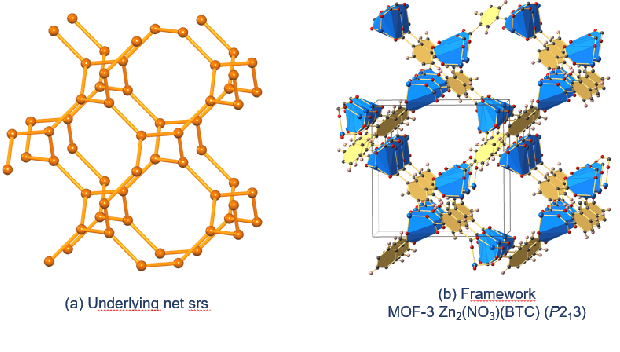
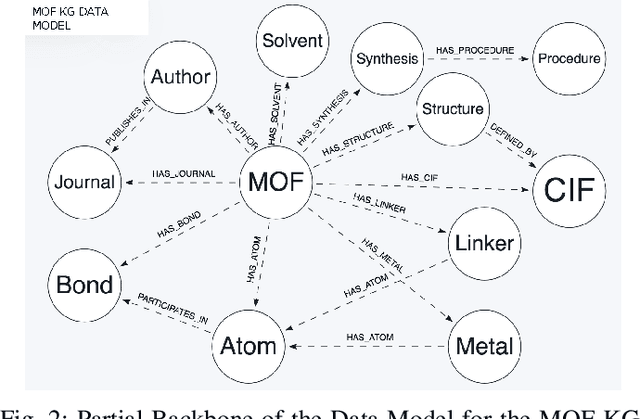
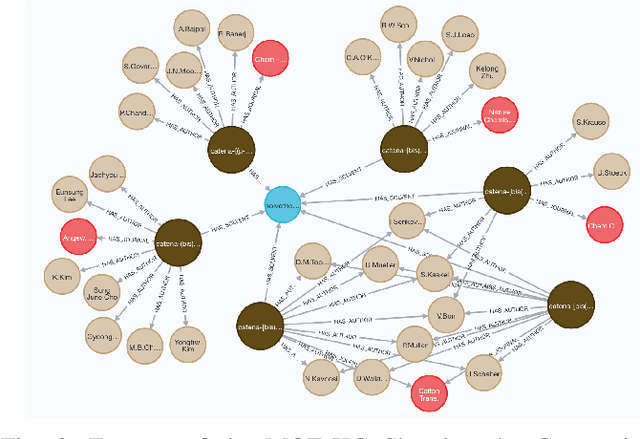
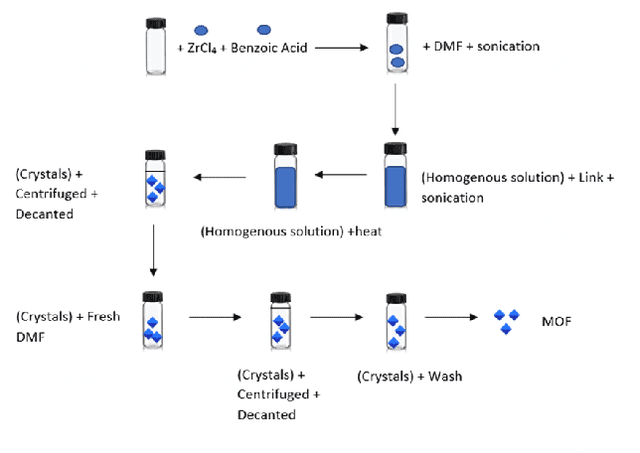
Metal-Organic Frameworks (MOFs) are a class of modular, porous crystalline materials that have great potential to revolutionize applications such as gas storage, molecular separations, chemical sensing, catalysis, and drug delivery. The Cambridge Structural Database (CSD) reports 10,636 synthesized MOF crystals which in addition contains ca. 114,373 MOF-like structures. The sheer number of synthesized (plus potentially synthesizable) MOF structures requires researchers pursue computational techniques to screen and isolate MOF candidates. In this demo paper, we describe our effort on leveraging knowledge graph methods to facilitate MOF prediction, discovery, and synthesis. We present challenges and case studies about (1) construction of a MOF knowledge graph (MOF-KG) from structured and unstructured sources and (2) leveraging the MOF-KG for discovery of new or missing knowledge.
Text to Insight: Accelerating Organic Materials Knowledge Extraction via Deep Learning
Sep 27, 2021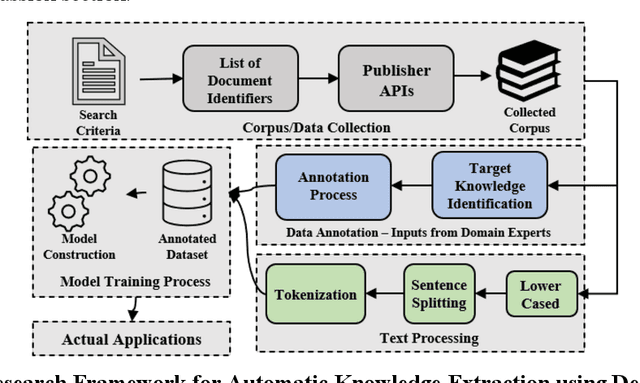

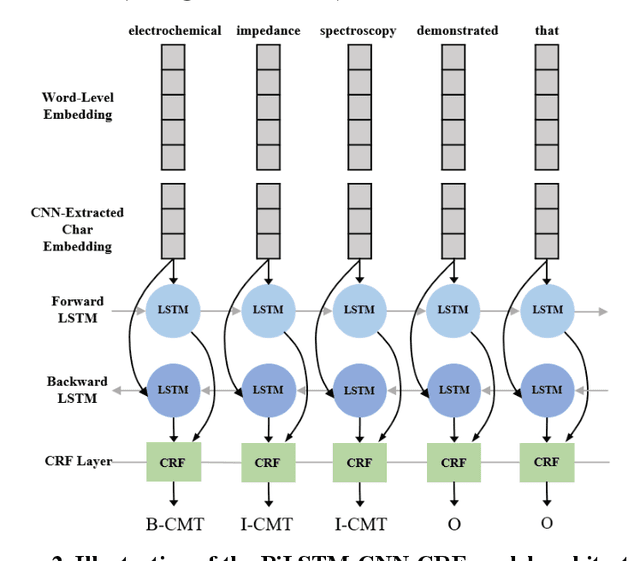
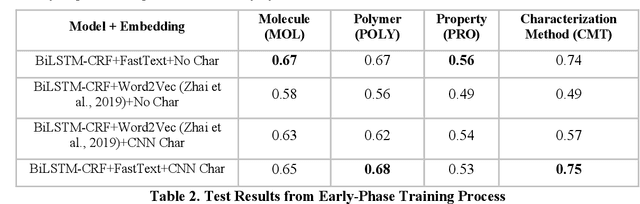
Scientific literature is one of the most significant resources for sharing knowledge. Researchers turn to scientific literature as a first step in designing an experiment. Given the extensive and growing volume of literature, the common approach of reading and manually extracting knowledge is too time consuming, creating a bottleneck in the research cycle. This challenge spans nearly every scientific domain. For the materials science, experimental data distributed across millions of publications are extremely helpful for predicting materials properties and the design of novel materials. However, only recently researchers have explored computational approaches for knowledge extraction primarily for inorganic materials. This study aims to explore knowledge extraction for organic materials. We built a research dataset composed of 855 annotated and 708,376 unannotated sentences drawn from 92,667 abstracts. We used named-entity-recognition (NER) with BiLSTM-CNN-CRF deep learning model to automatically extract key knowledge from literature. Early-phase results show a high potential for automated knowledge extraction. The paper presents our findings and a framework for supervised knowledge extraction that can be adapted to other scientific domains.
HIVE-4-MAT: Advancing the Ontology Infrastructure for Materials Science
Jan 20, 2021

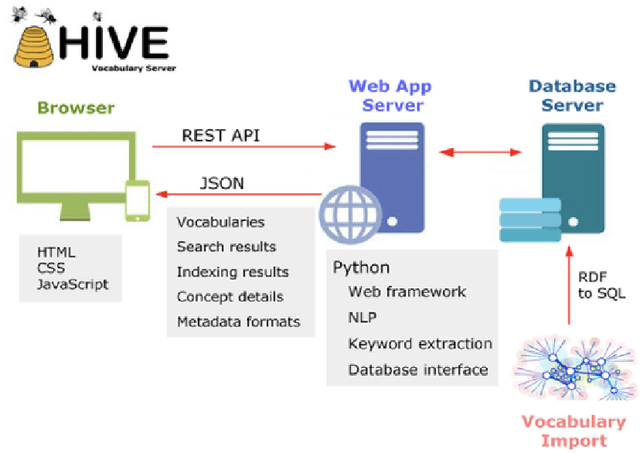
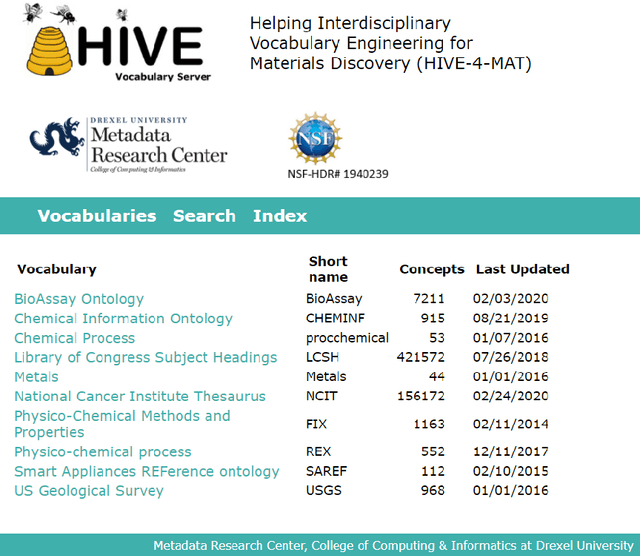
Introduces HIVE-4-MAT - Helping Interdisciplinary Vocabulary Engineering for Materials Science, an automatic linked data ontology application. Covers contextual background for materials science, shared ontology infrastructures, and reviews the knowledge extraction and indexing process. HIVE-4-MAT's vocabulary browsing, term search and selection, and knowledge extraction and indexing are reviewed, and plans to integrate named entity recognition. Conclusion highlights next steps with relation extraction to support better ontologies.