 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-in-the-Loop and AI: Crowdsourcing Metadata Vocabulary for Materials Science
Dec 10, 2025



Metadata vocabularies are essential for advancing FAIR and FARR data principles, but their development constrained by limited human resources and inconsistent standardization practices. This paper introduces MatSci-YAMZ, a platform that integrates artificial intelligence (AI) and human-in-the-loop (HILT), including crowdsourcing, to support metadata vocabulary development. The paper reports on a proof-of-concept use case evaluating the AI-HILT model in materials science, a highly interdisciplinary domain Six (6) participants affiliated with the NSF Institute for Data-Driven Dynamical Design (ID4) engaged with the MatSci-YAMZ plaform over several weeks, contributing term definitions and providing examples to prompt the AI-definitions refinement. Nineteen (19) AI-generated definitions were successfully created, with iterative feedback loops demonstrating the feasibility of AI-HILT refinement. Findings confirm the feasibility AI-HILT model highlighting 1) a successful proof of concept, 2) alignment with FAIR and open-science principles, 3) a research protocol to guide future studies, and 4) the potential for scalability across domains. Overall, MatSci-YAMZ's underlying model has the capacity to enhance semantic transparency and reduce time required for consensus building and metadata vocabulary development.
Rate-Distortion Guided Knowledge Graph Construction from Lecture Notes Using Gromov-Wasserstein Optimal Transport
Nov 18, 2025Task-oriented knowledge graphs (KGs) enable AI-powered learning assistant systems to automatically generate high-quality multiple-choice questions (MCQs). Yet converting unstructured educational materials, such as lecture notes and slides, into KGs that capture key pedagogical content remains difficult. We propose a framework for knowledge graph construction and refinement grounded in rate-distortion (RD) theory and optimal transport geometry. In the framework, lecture content is modeled as a metric-measure space, capturing semantic and relational structure, while candidate KGs are aligned using Fused Gromov-Wasserstein (FGW) couplings to quantify semantic distortion. The rate term, expressed via the size of KG, reflects complexity and compactness. Refinement operators (add, merge, split, remove, rewire) minimize the rate-distortion Lagrangian, yielding compact, information-preserving KGs. Our prototype applied to data science lectures yields interpretable RD curves and shows that MCQs generated from refined KGs consistently surpass those from raw notes on fifteen quality criteria. This study establishes a principled foundation for information-theoretic KG optimization in personalized and AI-assisted education.
Enhancing Semantic Interoperability Across Materials Science With HIVE4MAT
Nov 01, 2024



HIVE4MAT is a linked data interactive application for navigating ontologies of value to materials science. HIVE enables automatic indexing of textual resources with standardized terminology. This article presents the motivation underlying HIVE4MAT, explains the system architecture, reports on two evaluations, and discusses future plans.
Making Sense of Metadata Mess: Alignment & Risk Assessment for Diatom Data Use Case
Nov 01, 2024Biologists study Diatoms, a fundamental algae, to assess the health of aquatic systems. Diatom specimens have traditionally been preserved on analog slides, where a single slide can contain thousands of these microscopic organisms. Digitization of these collections presents both metadata challenges and opportunities. This paper reports on metadata research aimed at providing access to a digital portion of the Academy of Natural Sciences' Diatom Herbarium, Drexel University. We report results of a 3-part study covering 1) a review of relevant metadata standards and a microscopy metadata framework shared by Hammer et al., 2) a baseline metadata alignment mapping current diatom metadata properties to standard metadata types, and 3) a metadata risk analysis associated with the course of standard data curation practices. This research is part of an effort involving the transfer of these digital slides to an new system, DataFed, to support global accessible. The final section of this paper includes a conclusion and discusses next steps.
Knowledge Graph Question Answering for Materials Science (KGQA4MAT): Developing Natural Language Interface for Metal-Organic Frameworks Knowledge Graph (MOF-KG)
Sep 20, 2023We present a comprehensive benchmark dataset for Knowledge Graph Question Answering in Materials Science (KGQA4MAT), with a focus on metal-organic frameworks (MOFs). A knowledge graph for metal-organic frameworks (MOF-KG) has been constructed by integrating structured databases and knowledge extracted from the literature. To enhance MOF-KG accessibility for domain experts, we aim to develop a natural language interface for querying the knowledge graph. We have developed a benchmark comprised of 161 complex questions involving comparison, aggregation, and complicated graph structures. Each question is rephrased in three additional variations, resulting in 644 questions and 161 KG queries. To evaluate the benchmark, we have developed a systematic approach for utilizing ChatGPT to translate natural language questions into formal KG queries. We also apply the approach to the well-known QALD-9 dataset, demonstrating ChatGPT's potential in addressing KGQA issues for different platforms and query languages. The benchmark and the proposed approach aim to stimulate further research and development of user-friendly and efficient interfaces for querying domain-specific materials science knowledge graphs, thereby accelerating the discovery of novel materials.
Toward a Flexible Metadata Pipeline for Fish Specimen Images
Nov 18, 2022



Flexible metadata pipelines are crucial for supporting the FAIR data principles. Despite this need, researchers seldom report their approaches for identifying metadata standards and protocols that support optimal flexibility. This paper reports on an initiative targeting the development of a flexible metadata pipeline for a collection containing over 300,000 digital fish specimen images, harvested from multiple data repositories and fish collections. The images and their associated metadata are being used for AI-related scientific research involving automated species identification, segmentation and trait extraction. The paper provides contextual background, followed by the presentation of a four-phased approach involving: 1. Assessment of the Problem, 2. Investigation of Solutions, 3. Implementation, and 4. Refinement. The work is part of the NSF Harnessing the Data Revolution, Biology Guided Neural Networks (NSF/HDR-BGNN) project and the HDR Imageomics Institute. An RDF graph prototype pipeline is presented, followed by a discussion of research implications and conclusion summarizing the results.
Temporal Concept Drift and Alignment: An empirical approach to comparing Knowledge Organization Systems over time
Aug 16, 2022

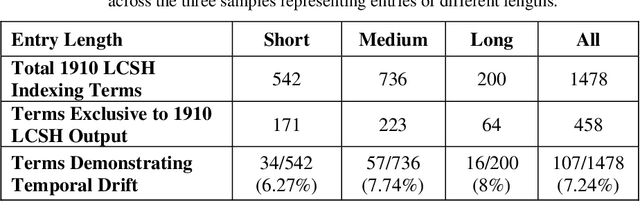
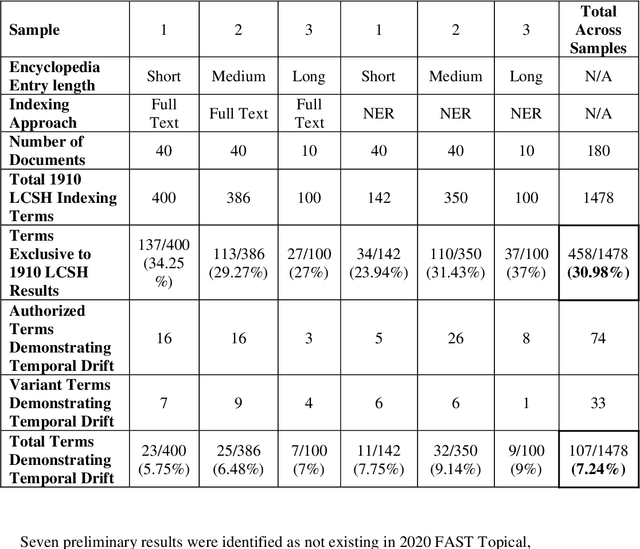
This research explores temporal concept drift and temporal alignment in knowledge organization systems (KOS). A comparative analysis is pursued using the 1910 Library of Congress Subject Headings, 2020 FAST Topical, and automatic indexing. The use case involves a sample of 90 nineteenth-century Encyclopedia Britannica entries. The entries were indexed using two approaches: 1) full-text indexing; 2) Named Entity Recognition was performed upon the entries with Stanza, Stanford's NLP toolkit, and entities were automatically indexed with the Helping Interdisciplinary Vocabulary application (HIVE), using both 1910 LCSH and FAST Topical. The analysis focused on three goals: 1) identifying results that were exclusive to the 1910 LCSH output; 2) identifying terms in the exclusive set that have been deprecated from the contemporary LCSH, demonstrating temporal concept drift; and 3) exploring the historical significance of these deprecated terms. Results confirm that historical vocabularies can be used to generate anachronistic subject headings representing conceptual drift across time in KOS and historical resources. A methodological contribution is made demonstrating how to study changes in KOS over time and improve the contextualization of historical humanities resources.
Exploring Wasserstein Distance across Concept Embeddings for Ontology Matching
Jul 22, 2022



Measuring the distance between ontological elements is a fundamental component for any matching solutions. String-based distance metrics relying on discrete symbol operations are notorious for shallow syntactic matching. In this study, we explore Wasserstein distance metric across ontology concept embeddings. Wasserstein distance metric targets continuous space that can incorporate linguistic, structural, and logical information. In our exploratory study, we use a pre-trained word embeddings system, fasttext, to embed ontology element labels. We examine the effectiveness of Wasserstein distance for measuring similarity between (blocks of) ontolgoies, discovering matchings between individual elements, and refining matchings incorporating contextual information. Our experiments with the OAEI conference track and MSE benchmarks achieve competitive results compared to the leading systems such as AML and LogMap. Results indicate a promising trajectory for the application of optimal transport and Wasserstein distance to improve embedding-based unsupervised ontology matchings.
Building Open Knowledge Graph for Metal-Organic Frameworks (MOF-KG): Challenges and Case Studies
Jul 10, 2022
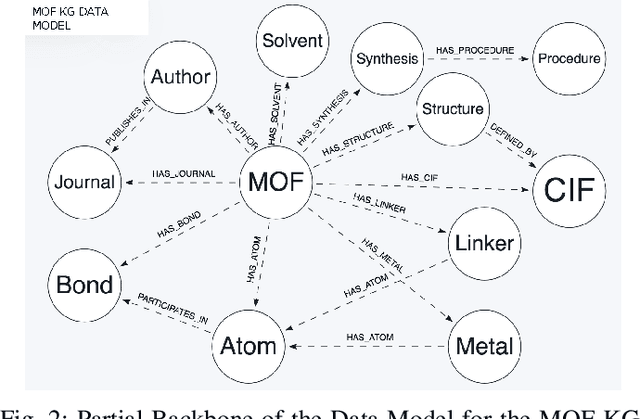
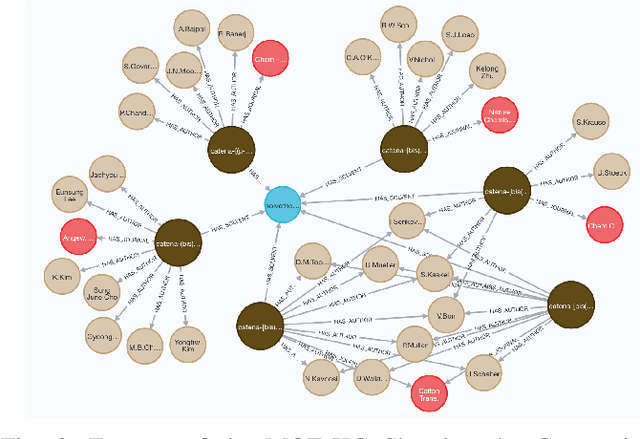
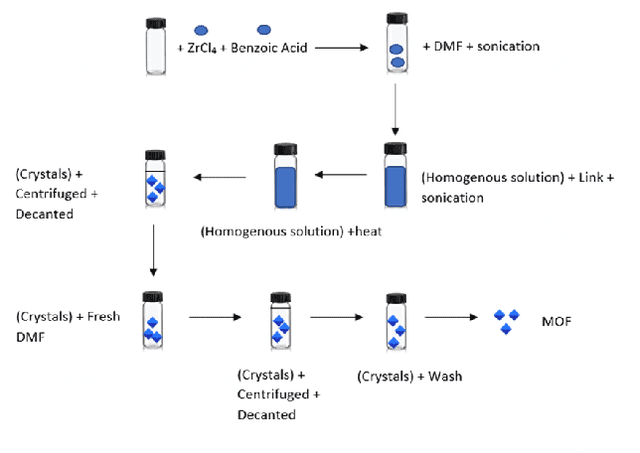
Metal-Organic Frameworks (MOFs) are a class of modular, porous crystalline materials that have great potential to revolutionize applications such as gas storage, molecular separations, chemical sensing, catalysis, and drug delivery. The Cambridge Structural Database (CSD) reports 10,636 synthesized MOF crystals which in addition contains ca. 114,373 MOF-like structures. The sheer number of synthesized (plus potentially synthesizable) MOF structures requires researchers pursue computational techniques to screen and isolate MOF candidates. In this demo paper, we describe our effort on leveraging knowledge graph methods to facilitate MOF prediction, discovery, and synthesis. We present challenges and case studies about (1) construction of a MOF knowledge graph (MOF-KG) from structured and unstructured sources and (2) leveraging the MOF-KG for discovery of new or missing knowledge.
FAIR Metadata: A Community-driven Vocabulary Application
Nov 06, 2021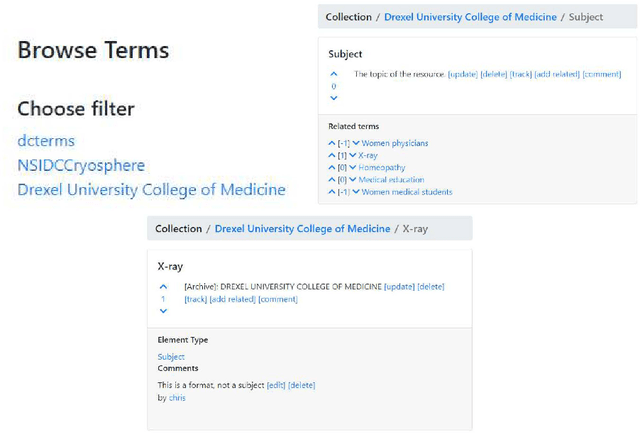
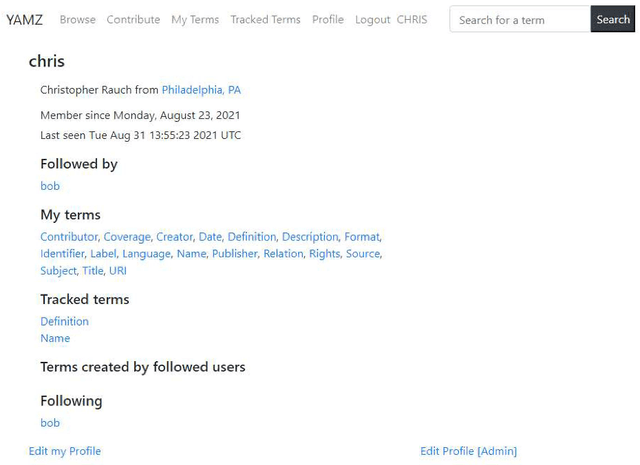
FAIR metadata is critical to supporting FAIR data overall. Transparency, community engagement, and flexibility are key aspects of FAIR that apply to metadata. This paper presents YAMZ (Yet Another Metadata Zoo), a community-driven vocabulary application that supports FAIR. The history ofYAMZ and its original features are reviewed, followed by a presentation of recent innovations and a discussion of how YAMZ supports FAIR principles. The conclusion identifies next steps and key outputs.