 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spatio-Temporal Dual-Stream Neural Network for Sequential Whole-Body PET Segmentation
Jun 09, 2021
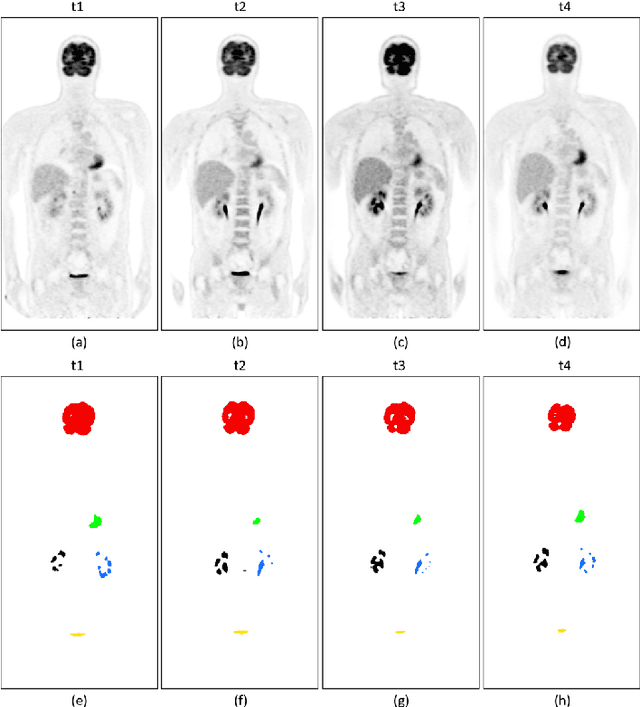

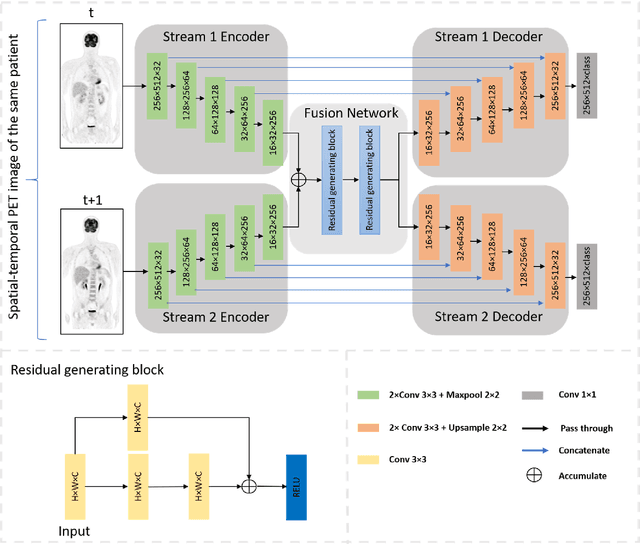
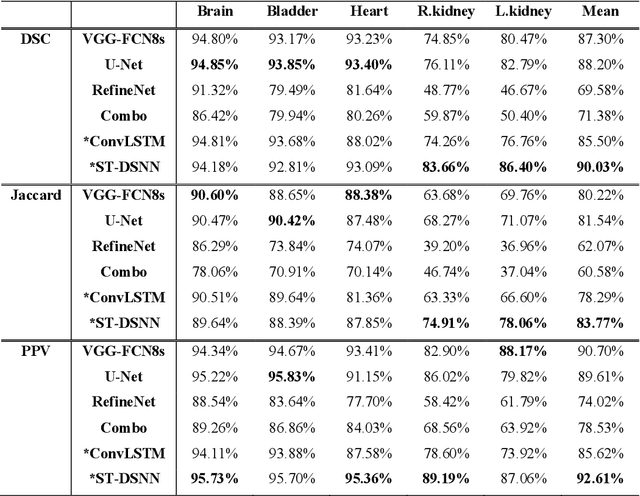
Sequential whole-body 18F-Fluorodeoxyglucose (FDG) positron emission tomography (PET) scans are regarded as the imaging modality of choice for the assessment of treatment response in the lymphomas because they detect treatment response when there may not be changes on anatomical imaging. Any computerized analysis of lymphomas in whole-body PET requires automatic segmentation of the studies so that sites of disease can be quantitatively monitored over time. State-of-the-art PET image segmentation methods are based on convolutional neural networks (CNNs) given their ability to leverage annotated datasets to derive high-level features about the disease process. Such methods, however, focus on PET images from a single time-point and discard information from other scans or are targeted towards specific organs and cannot cater for the multiple structures in whole-body PET images. In this study, we propose a spatio-temporal 'dual-stream' neural network (ST-DSNN) to segment sequential whole-body PET scans. Our ST-DSNN learns and accumulates image features from the PET images done over time. The accumulated image features are used to enhance the organs / structures that are consistent over time to allow easier identification of sites of active lymphoma. Our results show that our method outperforms the state-of-the-art PET image segmentation methods.
Policy Gradients Incorporating the Future
Aug 04, 2021

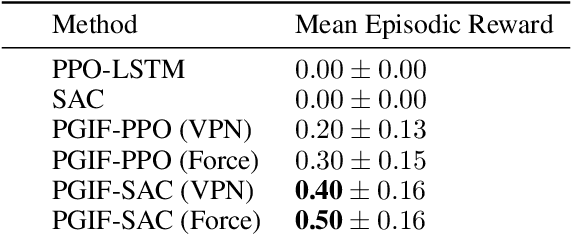

Reasoning about the future -- understanding how decisions in the present time affect outcomes in the future -- is one of the central challenges for reinforcement learning (RL), especially in highly-stochastic or partially observable environments. While predicting the future directly is hard, in this work we introduce a method that allows an agent to "look into the future" without explicitly predicting it. Namely, we propose to allow an agent, during its training on past experience, to observe what \emph{actually} happened in the future at that time, while enforcing an information bottleneck to avoid the agent overly relying on this privileged information. This gives our agent the opportunity to utilize rich and useful information about the future trajectory dynamics in addition to the present. Our method, Policy Gradients Incorporating the Future (PGIF), is easy to implement and versatile, being applicable to virtually any policy gradient algorithm. We apply our proposed method to a number of off-the-shelf RL algorithms and show that PGIF is able to achieve higher reward faster in a variety of online and offline RL domains, as well as sparse-reward and partially observable environments.
Lung Cancer Lesion Detection in Histopathology Images Using Graph-Based Sparse PCA Network
Oct 27, 2021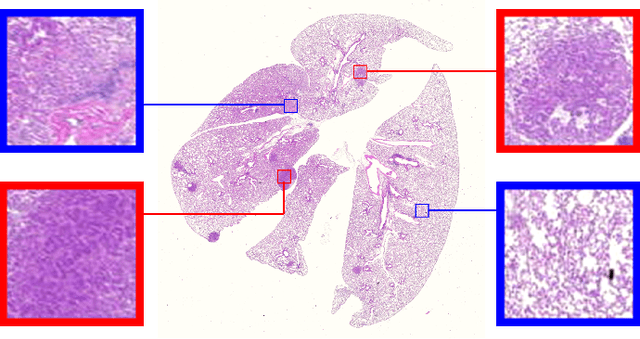
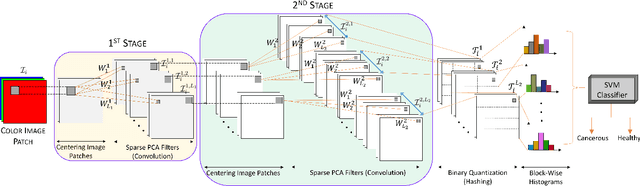
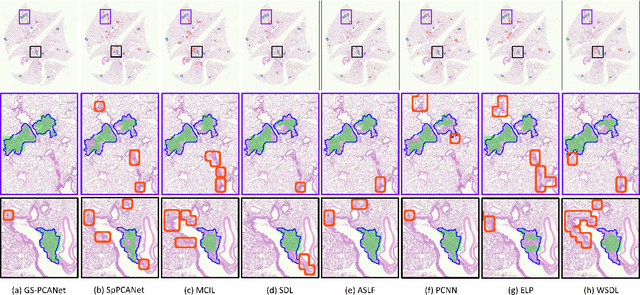
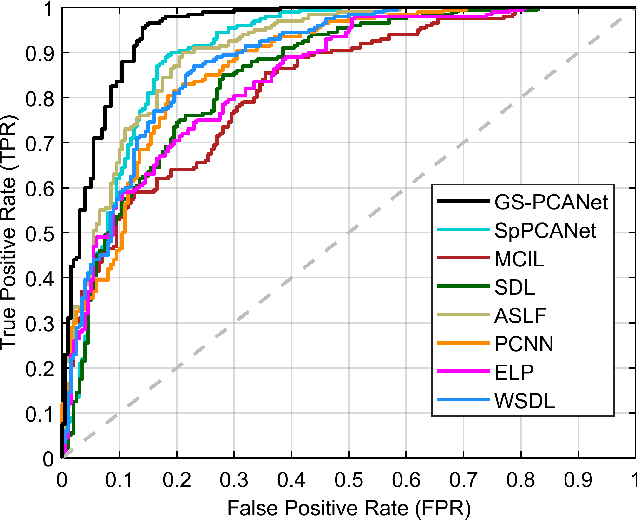
Early detection of lung cancer is critical for improvement of patient survival. To address the clinical need for efficacious treatments, genetically engineered mouse models (GEMM) have become integral in identifying and evaluating the molecular underpinnings of this complex disease that may be exploited as therapeutic targets. Assessment of GEMM tumor burden on histopathological sections performed by manual inspection is both time consuming and prone to subjective bias. Therefore, an interplay of needs and challenges exists for computer-aided diagnostic tools, for accurate and efficient analysis of these histopathology images. In this paper, we propose a simple machine learning approach called the graph-based sparse principal component analysis (GS-PCA) network, for automated detection of cancerous lesions on histological lung slides stained by hematoxylin and eosin (H&E). Our method comprises four steps: 1) cascaded graph-based sparse PCA, 2) PCA binary hashing, 3) block-wise histograms, and 4) support vector machine (SVM) classification. In our proposed architecture, graph-based sparse PCA is employed to learn the filter banks of the multiple stages of a convolutional network. This is followed by PCA hashing and block histograms for indexing and pooling. The meaningful features extracted from this GS-PCA are then fed to an SVM classifier. We evaluate the performance of the proposed algorithm on H&E slides obtained from an inducible K-rasG12D lung cancer mouse model using precision/recall rates, F-score, Tanimoto coefficient, and area under the curve (AUC) of the receiver operator characteristic (ROC) and show that our algorithm is efficient and provides improved detection accuracy compared to existing algorithms.
Cross-Modality Domain Adaptation for Vestibular Schwannoma and Cochlea Segmentation
Sep 21, 2021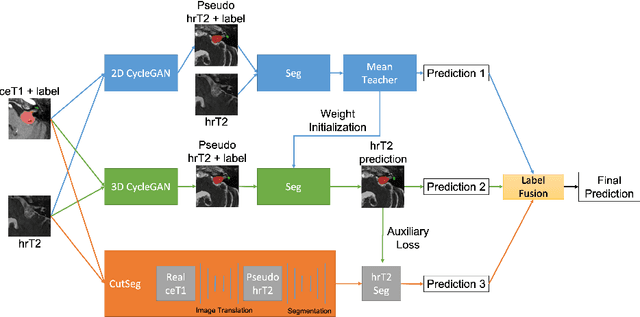


Automatic methods to segment the vestibular schwannoma (VS) tumors and the cochlea from magnetic resonance imaging (MRI) are critical to VS treatment planning. Although supervised methods have achieved satisfactory performance in VS segmentation, they require full annotations by experts, which is laborious and time-consuming. In this work, we aim to tackle the VS and cochlea segmentation problem in an unsupervised domain adaptation setting. Our proposed method leverages both the image-level domain alignment to minimize the domain divergence and semi-supervised training to further boost the performance. Furthermore, we propose to fuse the labels predicted from multiple models via noisy label correction. Our results on the challenge validation leaderboard showed that our unsupervised method has achieved promising VS and cochlea segmentation performance with mean dice score of 0.8261 $\pm$ 0.0416; The mean dice value for the tumor is 0.8302 $\pm$ 0.0772. This is comparable to the weakly-supervised based method.
What Averages Do Not Tell -- Predicting Real Life Processes with Sequential Deep Learning
Oct 31, 2021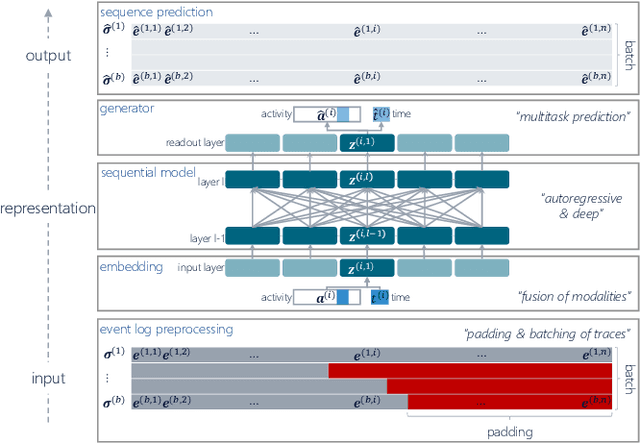
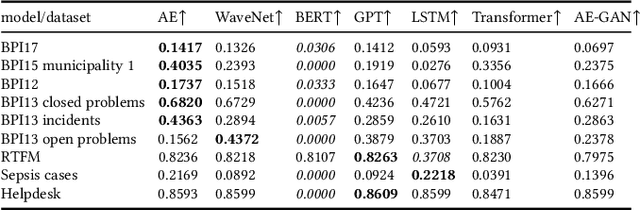
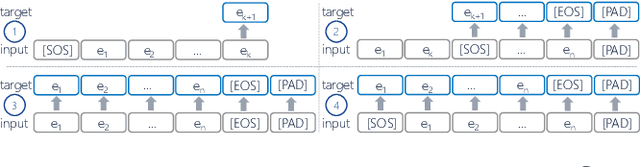
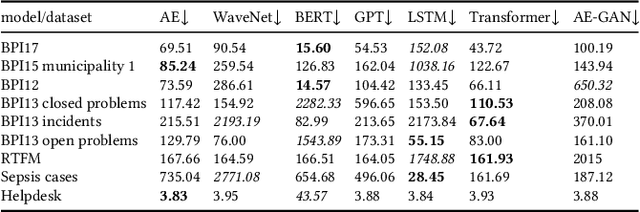
Deep Learning is proven to be an effective tool for modeling sequential data as shown by the success in Natural Language, Computer Vision and Signal Processing. Process Mining concerns discovering insights on business processes from their execution data that are logged by supporting information systems. The logged data (event log) is formed of event sequences (traces) that correspond to executions of a process. Many Deep Learning techniques have been successfully adapted for predictive Process Mining that aims to predict process outcomes, remaining time, the next event, or even the suffix of running traces. Traces in Process Mining are multimodal sequences and very differently structured than natural language sentences or images. This may require a different approach to processing. So far, there has been little focus on these differences and the challenges introduced. Looking at suffix prediction as the most challenging of these tasks, the performance of Deep Learning models was evaluated only on average measures and for a small number of real-life event logs. Comparing the results between papers is difficult due to different pre-processing and evaluation strategies. Challenges that may be relevant are the skewness of trace-length distribution and the skewness of the activity distribution in real-life event logs. We provide an end-to-end framework which enables to compare the performance of seven state-of-the-art sequential architectures in common settings. Results show that sequence modeling still has a lot of room for improvement for majority of the more complex datasets. Further research and insights are required to get consistent performance not just in average measures but additionally over all the prefixes.
Short Term Prediction of Parking Area states Using Real Time Data and Machine Learning Techniques
Nov 29, 2019
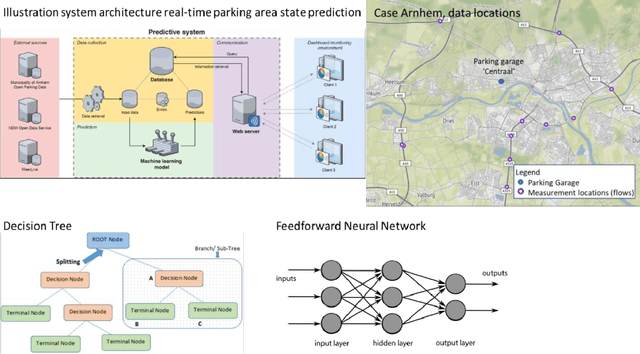
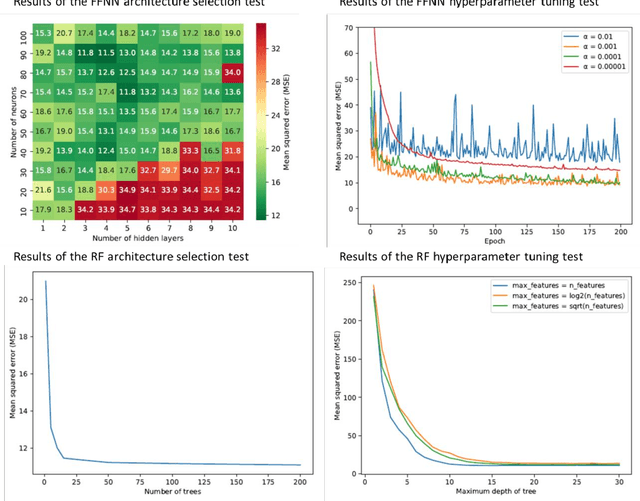
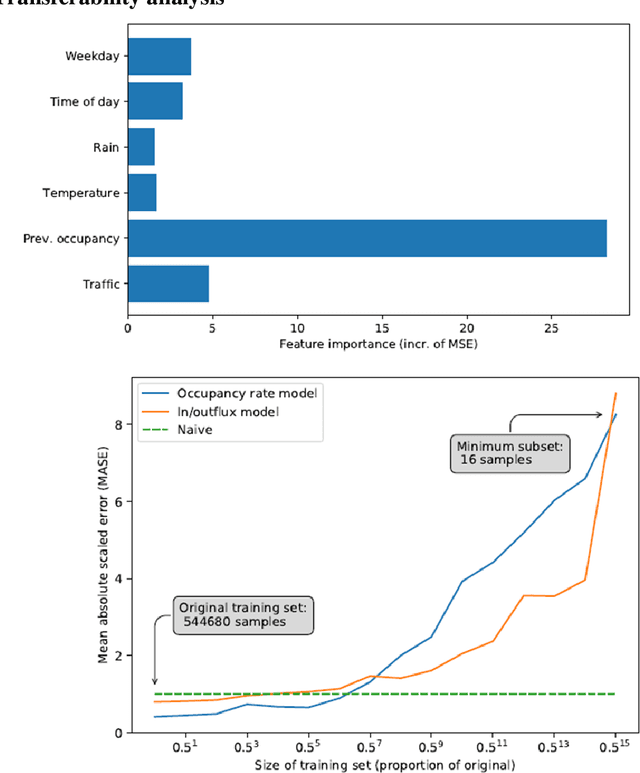
Public road authorities and private mobility service providers need information derived from the current and predicted traffic states to act upon the daily urban system and its spatial and temporal dynamics. In this research, a real-time parking area state (occupancy, in- and outflux) prediction model (up to 60 minutes ahead) has been developed using publicly available historic and real time data sources. Based on a case study in a real-life scenario in the city of Arnhem, a Neural Network-based approach outperforms a Random Forest-based one on all assessed performance measures, although the differences are small. Both are outperforming a naive seasonal random walk model. Although the performance degrades with increasing prediction horizon, the model shows a performance gain of over 150% at a prediction horizon of 60 minutes compared with the naive model. Furthermore, it is shown that predicting the in- and outflux is a far more difficult task (i.e. performance gains of 30%) which needs more training data, not based exclusively on occupancy rate. However, the performance of predicting in- and outflux is less sensitive to the prediction horizon. In addition, it is shown that real-time information of current occupancy rate is the independent variable with the highest contribution to the performance, although time, traffic flow and weather variables also deliver a significant contribution. During real-time deployment, the model performs three times better than the naive model on average. As a result, it can provide valuable information for proactive traffic management as well as mobility service providers.
Random Convolution Kernels with Multi-Scale Decomposition for Preterm EEG Inter-burst Detection
Aug 04, 2021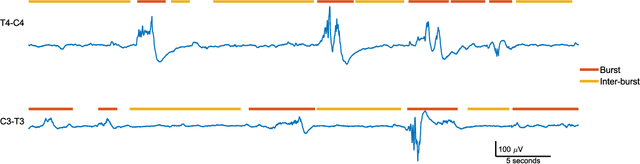
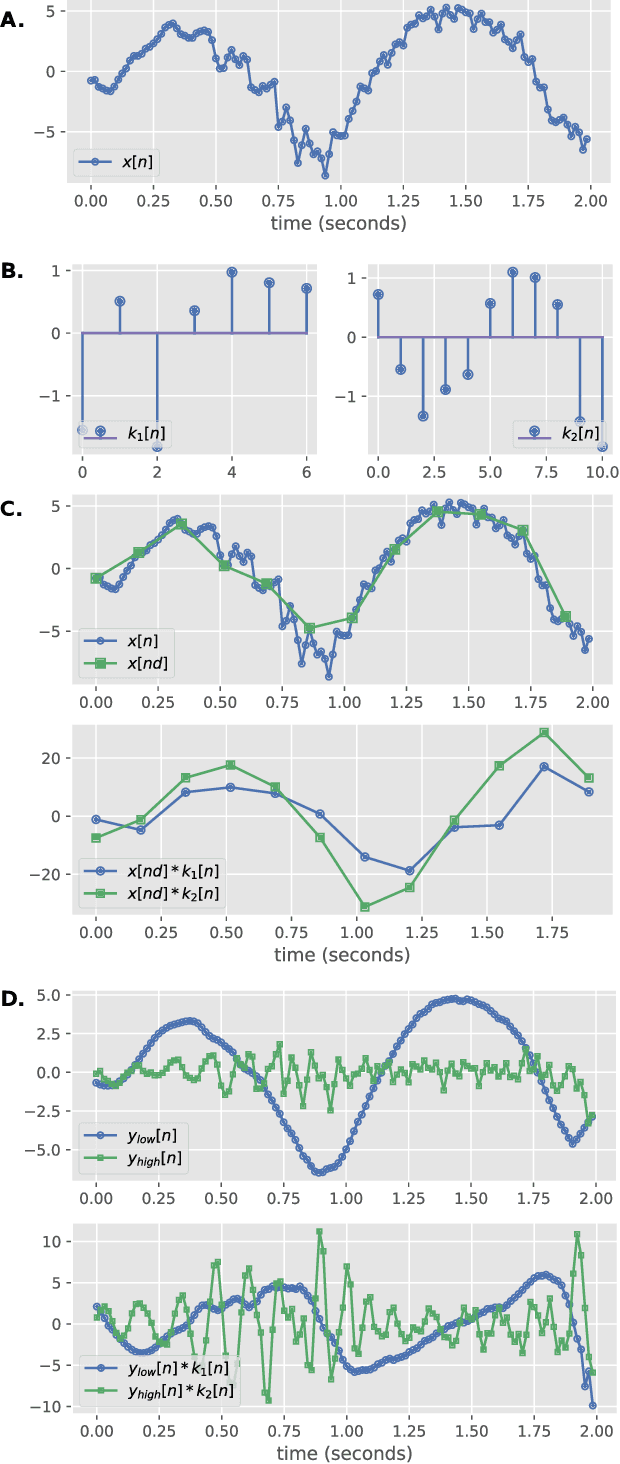
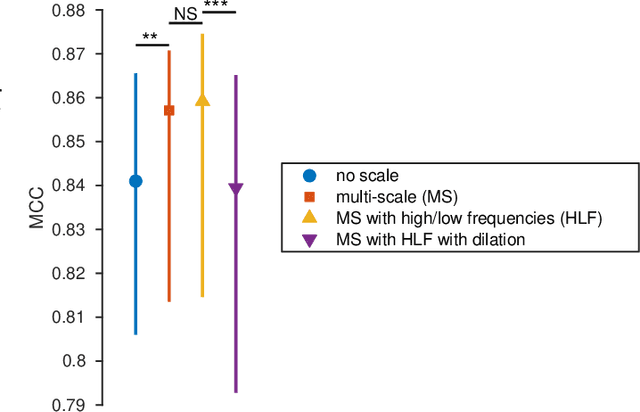
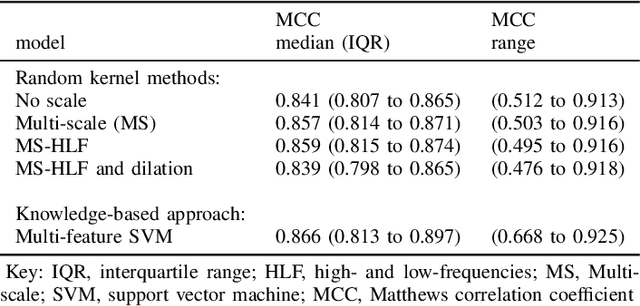
Linear classifiers with random convolution kernels are computationally efficient methods that need no design or domain knowledge. Unlike deep neural networks, there is no need to hand-craft a network architecture; the kernels are randomly generated and only the linear classifier needs training. A recently proposed method, RandOm Convolutional KErnel Transforms (ROCKETs), has shown high accuracy across a range of time-series data sets. Here we propose a multi-scale version of this method, using both high- and low-frequency components. We apply our methods to inter-burst detection in a cohort of preterm EEG recorded from 36 neonates <30 weeks gestational age. Two features from the convolution of 10,000 random kernels are combined using ridge regression. The proposed multi-scale ROCKET method out-performs the method without scale: median (interquartile range, IQR) Matthews correlation coefficient (MCC) of 0.859 (0.815 to 0.874) for multi-scale versus 0.841 (0.807 to 0.865) without scale, p<0.001. The proposed method lags behind an existing feature-based machine learning method developed with deep domain knowledge, but is fast to train and can quickly set an initial baseline threshold of performance for generic and biomedical time-series classification.
RAIL-KD: RAndom Intermediate Layer Mapping for Knowledge Distillation
Oct 01, 2021
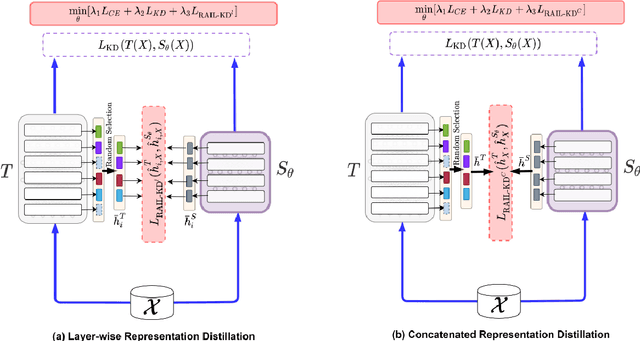
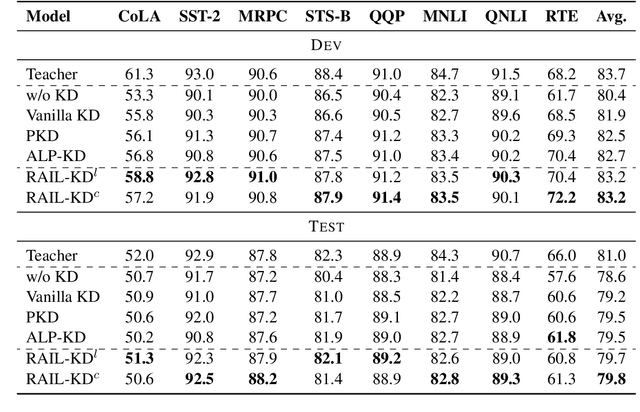
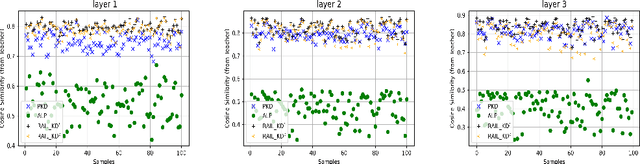
Intermediate layer knowledge distillation (KD) can improve the standard KD technique (which only targets the output of teacher and student models) especially over large pre-trained language models. However, intermediate layer distillation suffers from excessive computational burdens and engineering efforts required for setting up a proper layer mapping. To address these problems, we propose a RAndom Intermediate Layer Knowledge Distillation (RAIL-KD) approach in which, intermediate layers from the teacher model are selected randomly to be distilled into the intermediate layers of the student model. This randomized selection enforce that: all teacher layers are taken into account in the training process, while reducing the computational cost of intermediate layer distillation. Also, we show that it act as a regularizer for improving the generalizability of the student model. We perform extensive experiments on GLUE tasks as well as on out-of-domain test sets. We show that our proposed RAIL-KD approach outperforms other state-of-the-art intermediate layer KD methods considerably in both performance and training-time.
Subgradient methods near active manifolds: saddle point avoidance, local convergence, and asymptotic normality
Aug 26, 2021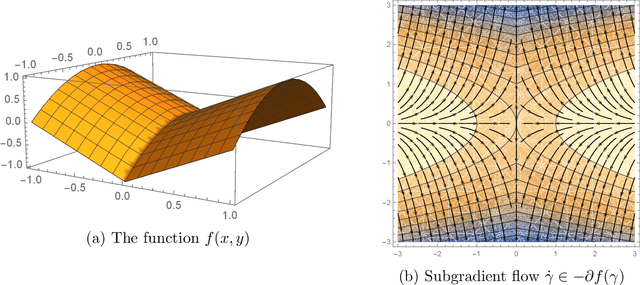
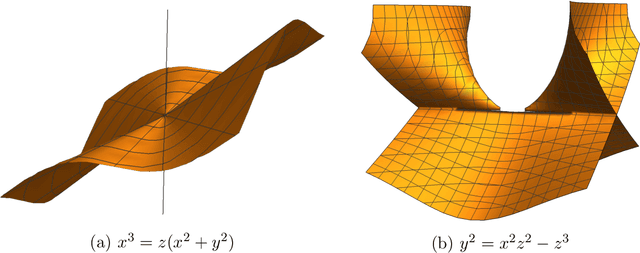
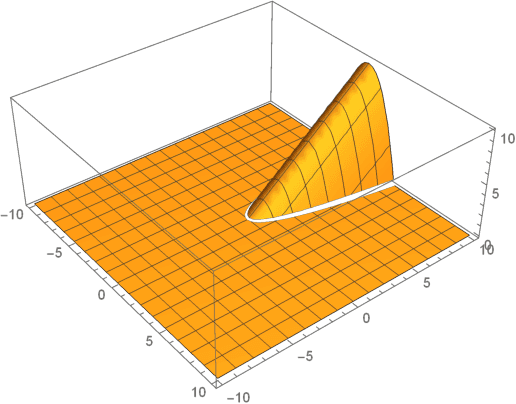
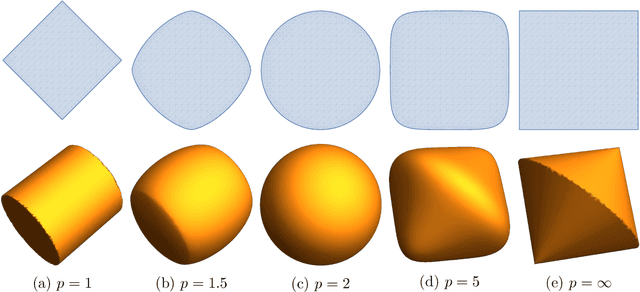
Nonsmooth optimization problems arising in practice tend to exhibit beneficial smooth substructure: their domains stratify into "active manifolds" of smooth variation, which common proximal algorithms "identify" in finite time. Identification then entails a transition to smooth dynamics, and accommodates second-order acceleration techniques. While identification is clearly useful algorithmically, empirical evidence suggests that even those algorithms that do not identify the active manifold in finite time -- notably the subgradient method -- are nonetheless affected by it. This work seeks to explain this phenomenon, asking: how do active manifolds impact the subgradient method in nonsmooth optimization? In this work, we answer this question by introducing two algorithmically useful properties -- aiming and subgradient approximation -- that fully expose the smooth substructure of the problem. We show that these properties imply that the shadow of the (stochastic) subgradient method along the active manifold is precisely an inexact Riemannian gradient method with an implicit retraction. We prove that these properties hold for a wide class of problems, including cone reducible/decomposable functions and generic semialgebraic problems. Moreover, we develop a thorough calculus, proving such properties are preserved under smooth deformations and spectral lifts. This viewpoint then leads to several algorithmic consequences that parallel results in smooth optimization, despite the nonsmoothness of the problem: local rates of convergence, asymptotic normality, and saddle point avoidance. The asymptotic normality results appear to be new even in the most classical setting of stochastic nonlinear programming. The results culminate in the following observation: the perturbed subgradient method on generic, Clarke regular semialgebraic problems, converges only to local minimizers.
On the Performance of HAPS-assisted Hybrid RF-FSO Multicast Communication Systems
Sep 21, 2021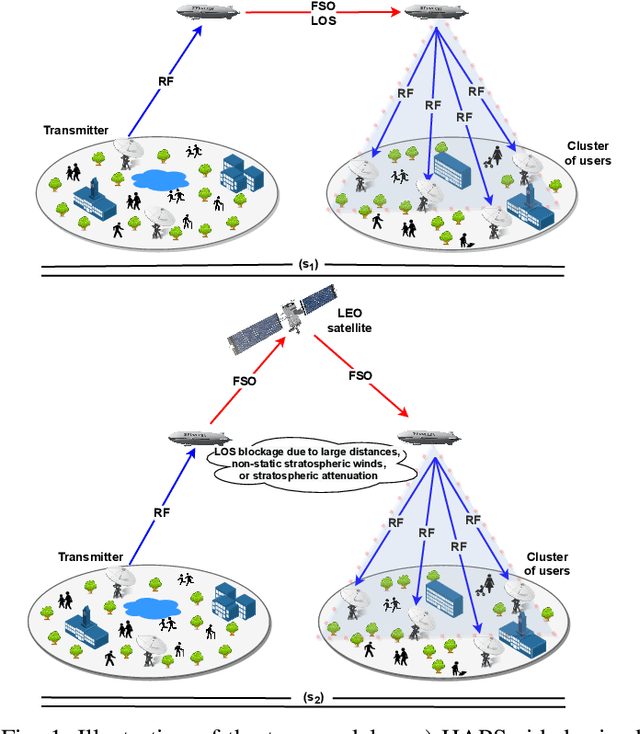
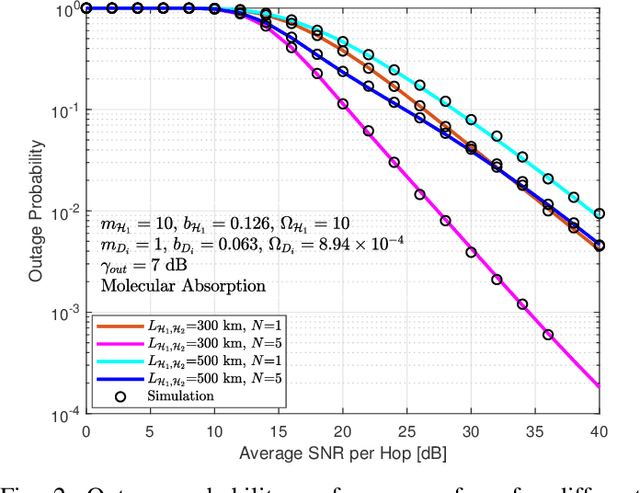
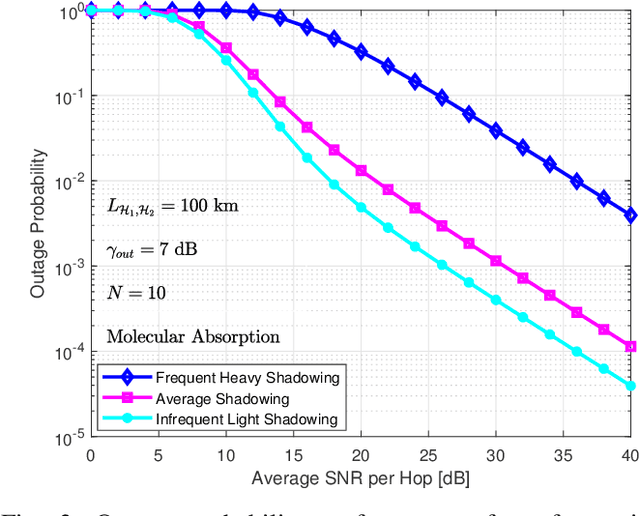
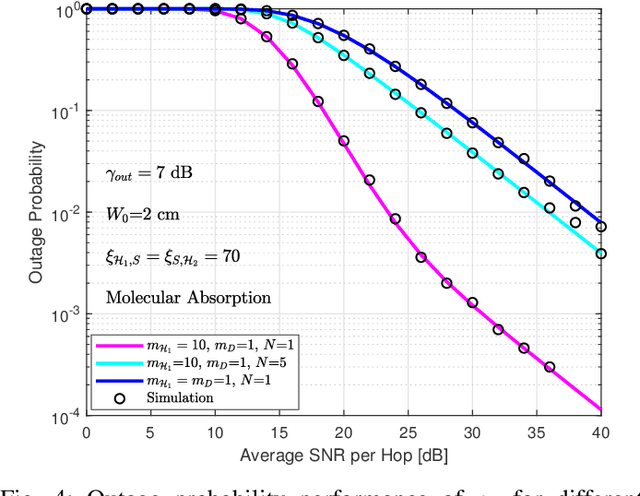
Multicast routing is considered a promising approach for real-time applications to address the massive data traffic demands. In this work, we study the outage probability of a multicast downlink communication network for non-terrestrial communication systems. More precisely, we propose two practical use-cases. In the former model, we propose a high altitude platform station (HAPS) aided mixed radio frequency (RF)/ free-space optical (FSO)/RF communication scheme where a terrestrial ground station intends to communicate with a cluster of nodes through two stratospheric HAPS systems. In the latter model, we assume that the line of sight (LOS) connectivity is inaccessible between the two HAPS systems due to high attenuation caused by large propagation distances. Thereby, we propose a low Earth orbit (LEO) satellite-aided mixed RF/FSO/FSO/RF communication. For the proposed scenarios, outage probability expressions are derived and validated with Monte Carlo (MC) simulations under different conditions.