 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RF-Net: a Unified Meta-learning Framework for RF-enabled One-shot Human Activity Recognition
Oct 29, 2021
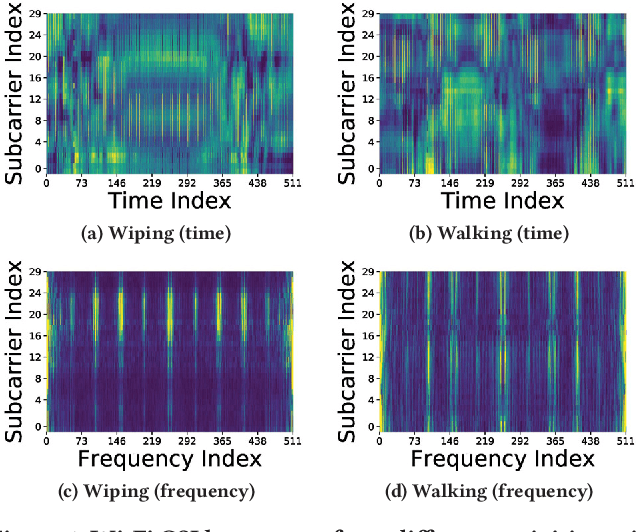
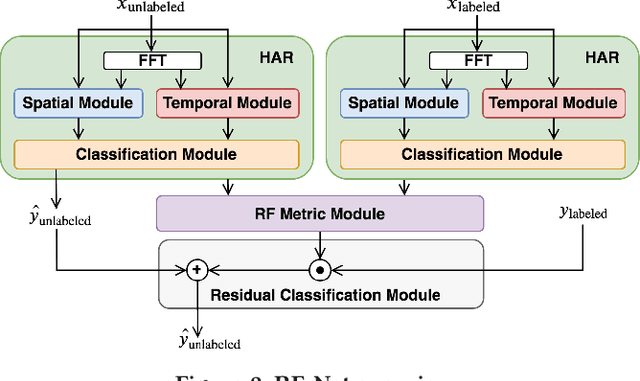

Radio-Frequency (RF) based device-free Human Activity Recognition (HAR) rises as a promising solution for many applications. However, device-free (or contactless) sensing is often more sensitive to environment changes than device-based (or wearable) sensing. Also, RF datasets strictly require on-line labeling during collection, starkly different from image and text data collections where human interpretations can be leveraged to perform off-line labeling. Therefore, existing solutions to RF-HAR entail a laborious data collection process for adapting to new environments. To this end, we propose RF-Net as a meta-learning based approach to one-shot RF-HAR; it reduces the labeling efforts for environment adaptation to the minimum level. In particular, we first examine three representative RF sensing techniques and two major meta-learning approaches. The results motivate us to innovate in two designs: i) a dual-path base HAR network, where both time and frequency domains are dedicated to learning powerful RF features including spatial and attention-based temporal ones, and ii) a metric-based meta-learning framework to enhance the fast adaption capability of the base network, including an RF-specific metric module along with a residual classification module. We conduct extensive experiments based on all three RF sensing techniques in multiple real-world indoor environments; all results strongly demonstrate the efficacy of RF-Net compared with state-of-the-art baselines.
* 14 pages
Adaptive Latent Space Tuning for Non-Stationary Distributions
Jun 06, 2021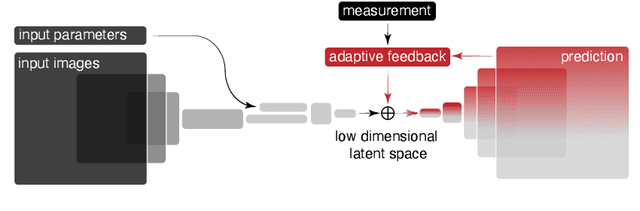
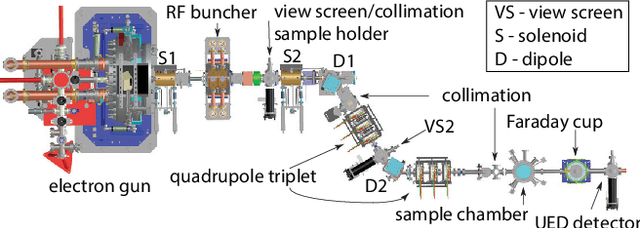
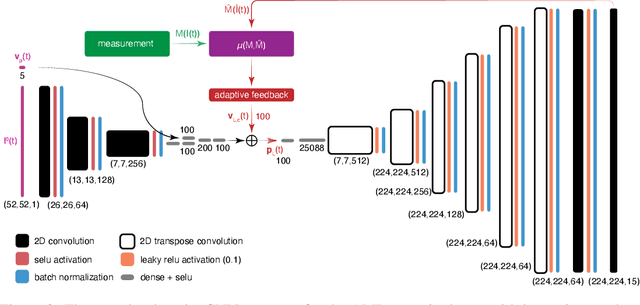
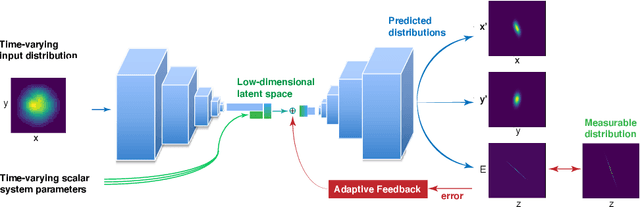
Powerful deep learning tools, such as convolutional neural networks (CNN), are able to learn the input-output relationships of large complicated systems directly from data. Encoder-decoder deep CNNs are able to extract features directly from images, mix them with scalar inputs within a general low-dimensional latent space, and then generate new complex 2D outputs which represent complex physical phenomenon. One important challenge faced by deep learning methods is large non-stationary systems whose characteristics change quickly with time for which re-training is not feasible. In this paper we present a method for adaptive tuning of the low-dimensional latent space of deep encoder-decoder style CNNs based on real-time feedback to quickly compensate for unknown and fast distribution shifts. We demonstrate our approach for predicting the properties of a time-varying charged particle beam in a particle accelerator whose components (accelerating electric fields and focusing magnetic fields) are also quickly changing with time.
Fast Forward Indexes for Efficient Document Ranking
Oct 12, 2021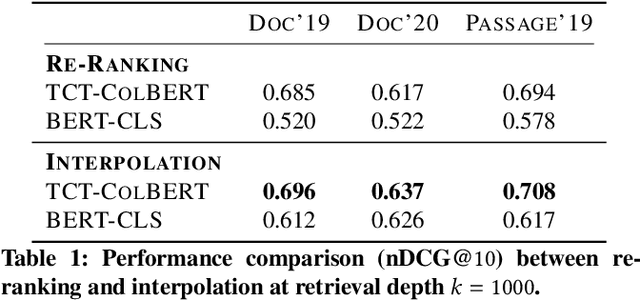

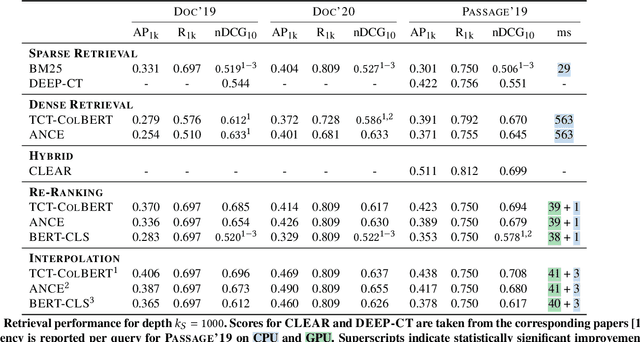
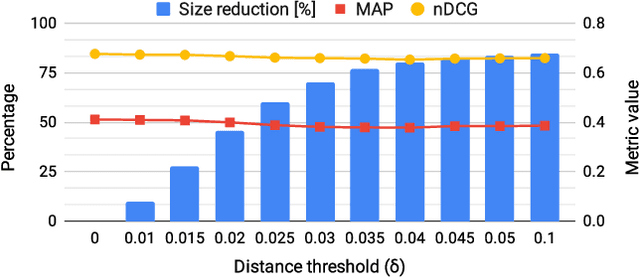
Neural approaches, specifically transformer models, for ranking documents have delivered impressive gains in ranking performance. However, query processing using such over-parameterized models is both resource and time intensive. Consequently, to keep query processing costs manageable, trade-offs are made to reduce the number of documents to be re-ranked or consider leaner models with fewer parameters. In this paper, we propose the fast-forward index -- a simple vector forward index that facilitates ranking documents using interpolation-based ranking models. Fast-forward indexes pre-compute the dense transformer-based vector representations of documents and passages for fast CPU-based semantic similarity computation during query processing. We propose theoretically grounded index pruning and early stopping techniques to improve the query-processing throughput using fast-forward indexes. We conduct extensive large-scale experiments over the TREC-DL datasets and show up to 75% improvement in query-processing performance over hybrid indexes using only CPUs. Along with the efficiency benefits, we show that fast-forward indexes can deliver superior ranking performance due to the complementary benefits of interpolation between lexical and semantic similarities.
Semantic Discord: Finding Unusual Local Patterns for Time Series
Jan 30, 2020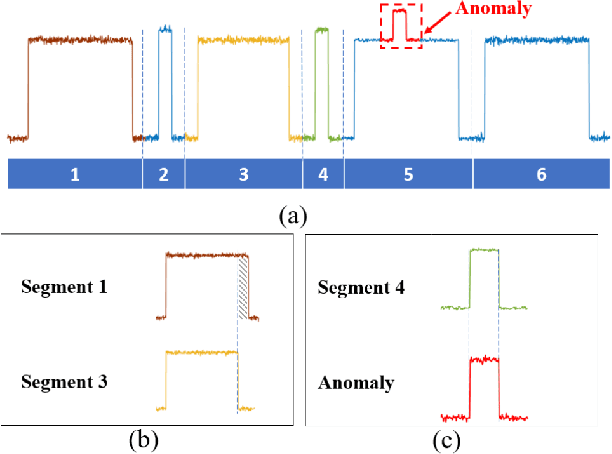
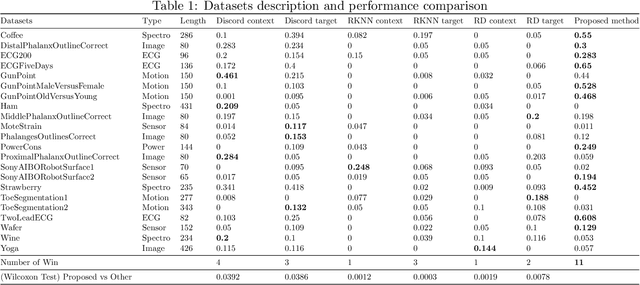

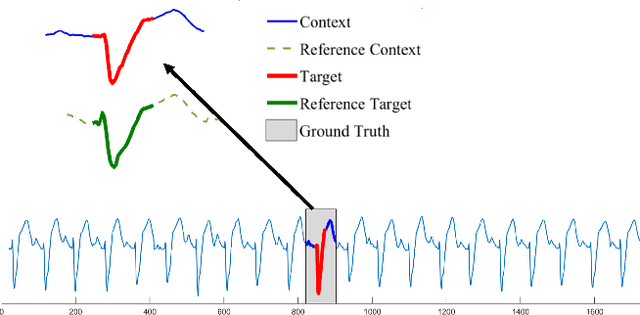
Finding anomalous subsequence in a long time series is a very important but difficult problem. Existing state-of-the-art methods have been focusing on searching for the subsequence that is the most dissimilar to the rest of the subsequences; however, they do not take into account the background patterns that contain the anomalous candidates. As a result, such approaches are likely to miss local anomalies. We introduce a new definition named \textit{semantic discord}, which incorporates the context information from larger subsequences containing the anomaly candidates. We propose an efficient algorithm with a derived lower bound that is up to 3 orders of magnitude faster than the brute force algorithm in real world data. We demonstrate that our method significantly outperforms the state-of-the-art methods in locating anomalies by extensive experiments. We further explain the interpretability of semantic discord.
Multi-channel Narrow-Band Deep Speech Separation with Full-band Permutation Invariant Training
Oct 12, 2021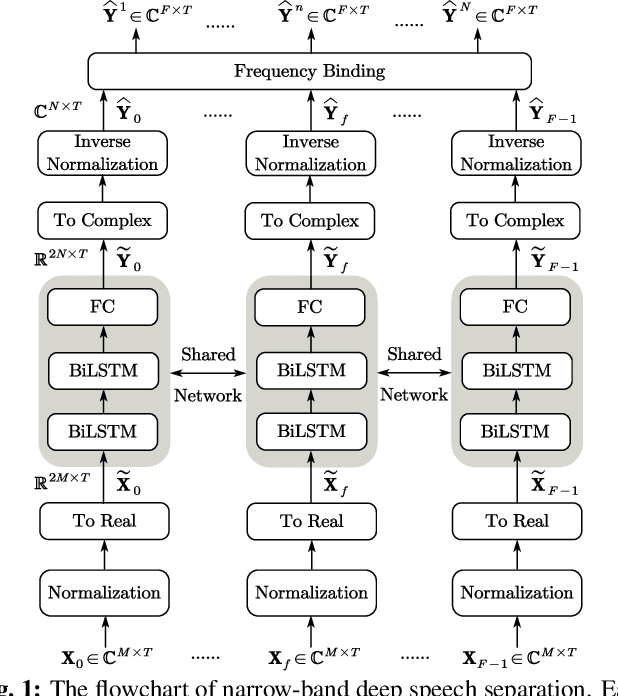
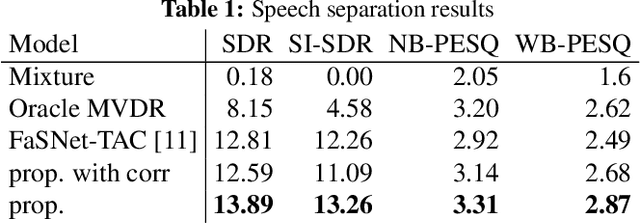
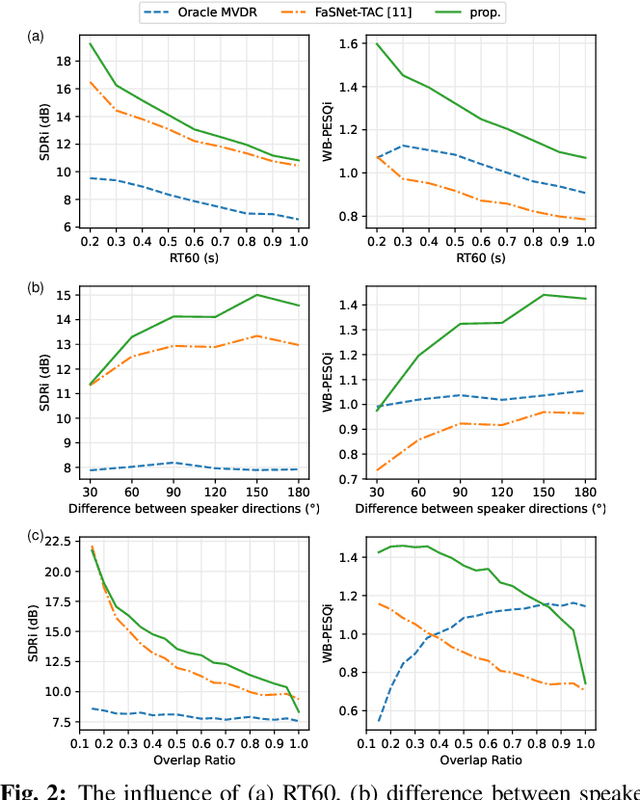
This paper addresses the problem of multi-channel multi-speech separation based on deep learning techniques. In the short time Fourier transform domain, we propose an end-to-end narrow-band network that directly takes as input the multi-channel mixture signals of one frequency, and outputs the separated signals of this frequency. In narrow-band, the spatial information (or inter-channel difference) can well discriminate between speakers at different positions. This information is intensively used in many narrow-band speech separation methods, such as beamforming and clustering of spatial vectors. The proposed network is trained to learn a rule to automatically exploit this information and perform speech separation. Such a rule should be valid for any frequency, thence the network is shared by all frequencies. In addition, a full-band permutation invariant training criterion is proposed to solve the frequency permutation problem encountered by most narrow-band methods. Experiments show that, by focusing on deeply learning the narrow-band information, the proposed method outperforms the oracle beamforming method and the state-of-the-art deep learning based method.
Equilibrium and non-Equilibrium regimes in the learning of Restricted Boltzmann Machines
Jun 04, 2021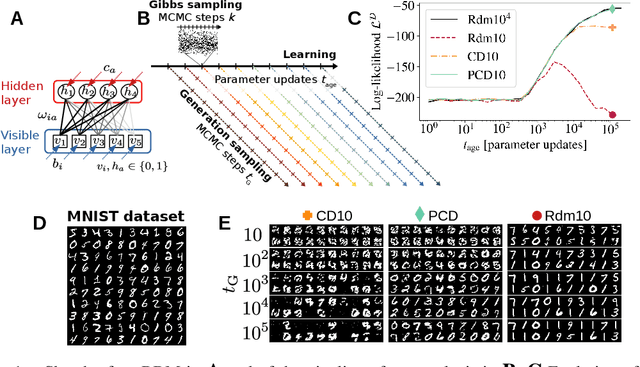
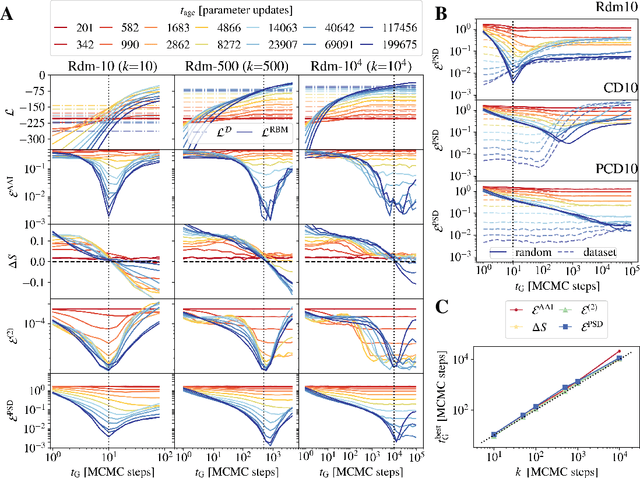
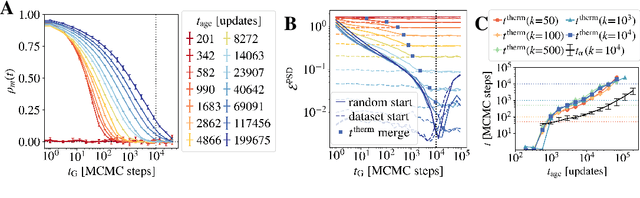
Training Restricted Boltzmann Machines (RBMs) has been challenging for a long time due to the difficulty of computing precisely the log-likelihood gradient. Over the past decades, many works have proposed more or less successful training recipes but without studying the crucial quantity of the problem: the mixing time i.e. the number of Monte Carlo iterations needed to sample new configurations from a model. In this work, we show that this mixing time plays a crucial role in the dynamics and stability of the trained model, and that RBMs operate in two well-defined regimes, namely equilibrium and out-of-equilibrium, depending on the interplay between this mixing time of the model and the number of steps, $k$, used to approximate the gradient. We further show empirically that this mixing time increases with the learning, which often implies a transition from one regime to another as soon as $k$ becomes smaller than this time. In particular, we show that using the popular $k$ (persistent) contrastive divergence approaches, with $k$ small, the dynamics of the learned model are extremely slow and often dominated by strong out-of-equilibrium effects. On the contrary, RBMs trained in equilibrium display faster dynamics, and a smooth convergence to dataset-like configurations during the sampling. Finally we discuss how to exploit in practice both regimes depending on the task one aims to fulfill: (i) short $k$s can be used to generate convincing samples in short times, (ii) large $k$ (or increasingly large) must be used to learn the correct equilibrium distribution of the RBM.
Optimizing Neural Network for Computer Vision task in Edge Device
Oct 02, 2021

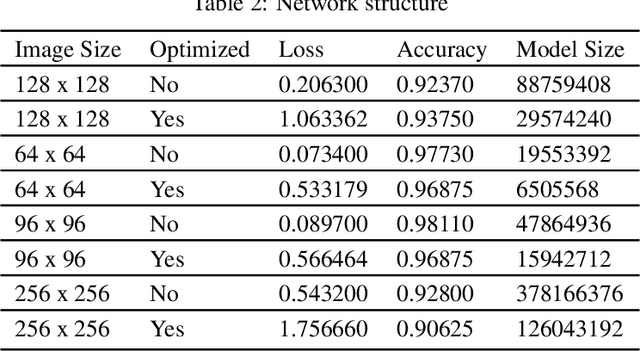
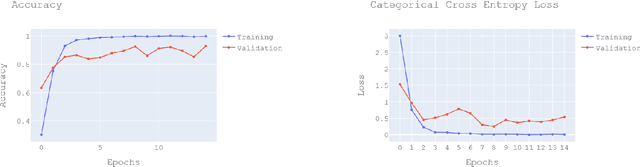
The field of computer vision has grown very rapidly in the past few years due to networks like convolution neural networks and their variants. The memory required to store the model and computational expense are very high for such a network limiting it to deploy on the edge device. Many times, applications rely on the cloud but that makes it hard for working in real-time due to round-trip delays. We overcome these problems by deploying the neural network on the edge device itself. The computational expense for edge devices is reduced by reducing the floating-point precision of the parameters in the model. After this the memory required for the model decreases and the speed of the computation increases where the performance of the model is least affected. This makes an edge device to predict from the neural network all by itself.
Generative adversarial network based on chaotic time series
May 24, 2019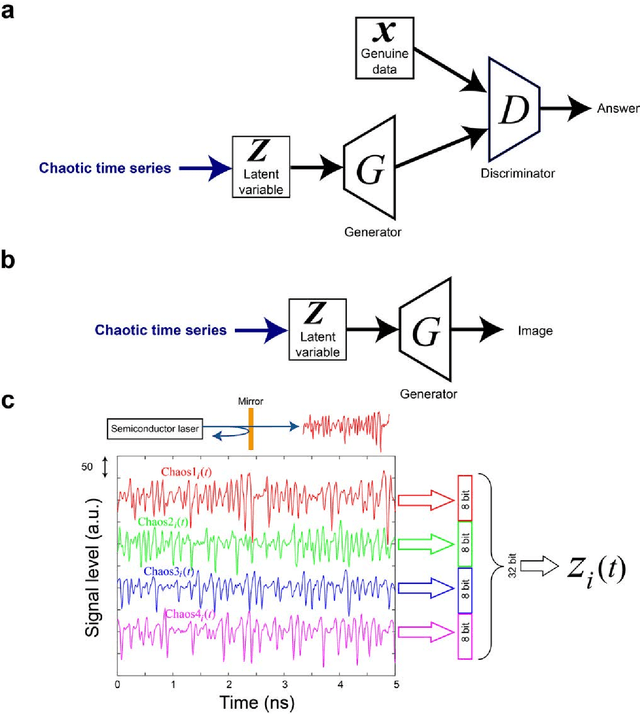
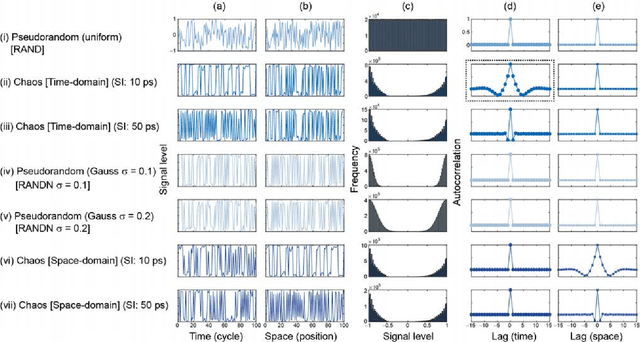
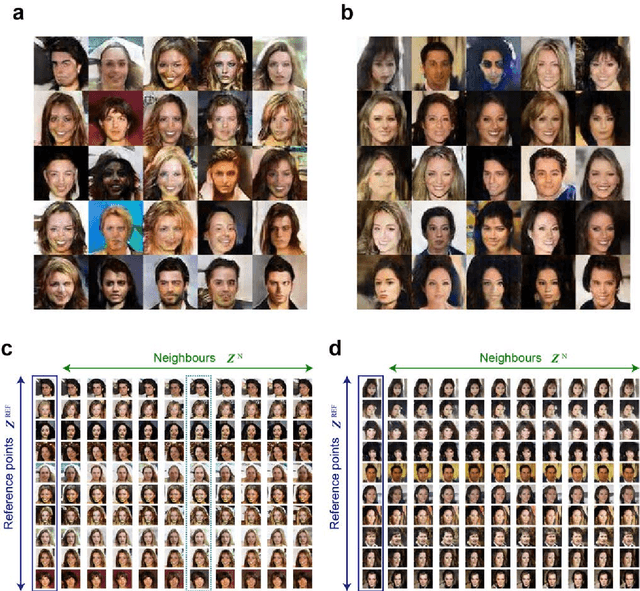
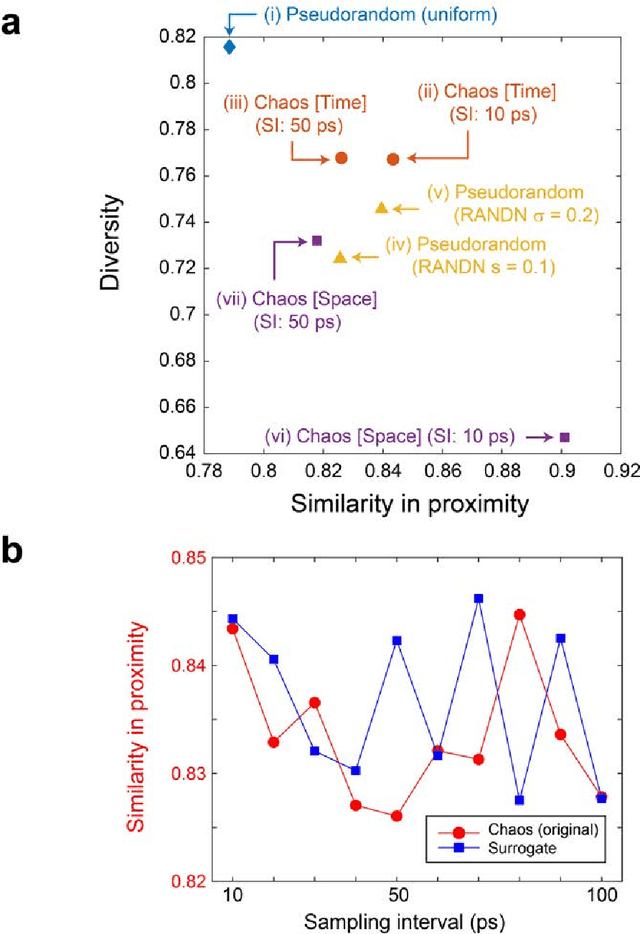
Generative adversarial network (GAN) is gaining increased importance in artificially constructing natural images and related functionalities wherein two networks called generator and discriminator are evolving through adversarial mechanisms. Using deep convolutional neural networks and related techniques, high-resolution, highly realistic scenes, human faces, among others have been generated. While GAN in general needs a large amount of genuine training data sets, it is noteworthy that vast amounts of pseudorandom numbers are required. Here we utilize chaotic time series generated experimentally by semiconductor lasers for the latent variables of GAN whereby the inherent nature of chaos can be reflected or transformed into the generated output data. We show that the similarity in proximity, which is a degree of robustness of the generated images with respects to a minute change in the input latent variables, is enhanced while the versatility as a whole is not severely degraded. Furthermore, we demonstrate that the surrogate chaos time series eliminates the signature of generated images that is originally observed corresponding to the negative autocorrelation inherent in the chaos sequence. We also discuss the impact of utilizing chaotic time series in retrieving images from the trained generator.
An Efficient Point of Gaze Estimator for Low-Resolution Imaging Systems Using Extracted Ocular Features Based Neural Architecture
Jun 09, 2021
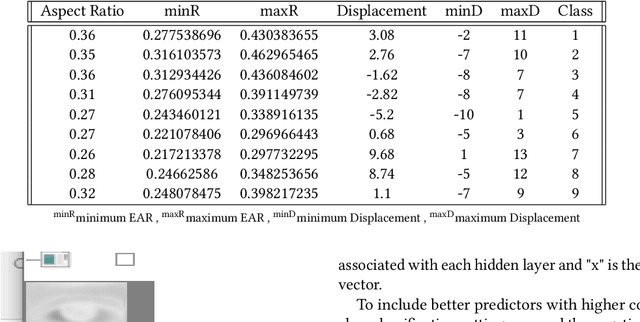

A user's eyes provide means for Human Computer Interaction (HCI) research as an important modal. The time to time scientific explorations of the eye has already seen an upsurge of the benefits in HCI applications from gaze estimation to the measure of attentiveness of a user looking at a screen for a given time period. The eye tracking system as an assisting, interactive tool can be incorporated by physically disabled individuals, fitted best for those who have eyes as only a limited set of communication. The threefold objective of this paper is - 1. To introduce a neural network based architecture to predict users' gaze at 9 positions displayed in the 11.31{\deg} visual range on the screen, through a low resolution based system such as a webcam in real time by learning various aspects of eyes as an ocular feature set. 2.A collection of coarsely supervised feature set obtained in real time which is also validated through the user case study presented in the paper for 21 individuals ( 17 men and 4 women ) from whom a 35k set of instances was derived with an accuracy score of 82.36% and f1_score of 82.2% and 3.A detailed study over applicability and underlying challenges of such systems. The experimental results verify the feasibility and validity of the proposed eye gaze tracking model.
Automated Seed Quality Testing System using GAN & Active Learning
Oct 02, 2021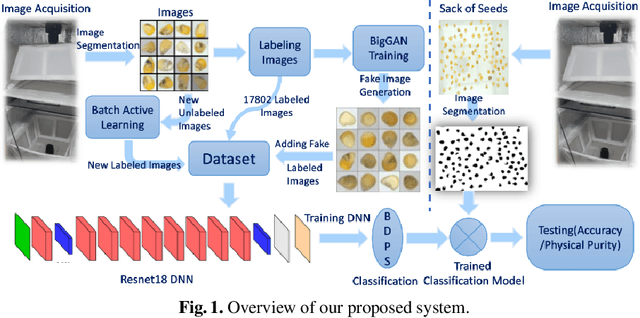
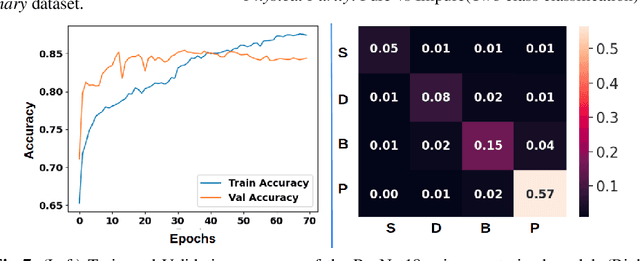


Quality assessment of agricultural produce is a crucial step in minimizing food stock wastage. However, this is currently done manually and often requires expert supervision, especially in smaller seeds like corn. We propose a novel computer vision-based system for automating this process. We build a novel seed image acquisition setup, which captures both the top and bottom views. Dataset collection for this problem has challenges of data annotation costs/time and class imbalance. We address these challenges by i.) using a Conditional Generative Adversarial Network (CGAN) to generate real-looking images for the classes with lesser images and ii.) annotate a large dataset with minimal expert human intervention by using a Batch Active Learning (BAL) based annotation tool. We benchmark different image classification models on the dataset obtained. We are able to get accuracies of up to 91.6% for testing the physical purity of seed samples.