 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREMEDI: A Benchmark for Retention and Unlearning Evaluation in Multi-label Clinical Disease Inference
Jun 05, 2026Language models trained for clinical disease inference are trained on patient data, which may include sensitive and private information, and data owners may request the removal of their data from a trained model due to privacy or copyright concerns. However, exactly unlearning patient-specific data is intractable, and retraining with minor data removal is resource-intensive. While there exists several machine unlearning methods that can be used, their utility is generally restricted to non-medical domains. Moreover, the existing benchmarks for evaluating such unlearning methods primarily utilize synthetically curated datasets, which are not truly representative of real-world systems. Hence, the effectiveness of these unlearning methods in the medical domain is largely unclear. To this end, we introduce REMEDI, an extensive benchmark for machine unlearning tailored to multi-label and multiclass clinical disease inference, where label correlations, longitudinal structure, and safety constraints make unlearning particularly challenging. Unlike the existing benchmarks, REMEDI considers: (1) a relevant application domain (medical), (2) comprehensive unlearning setups involving diverse sets of forget instances, (3) challenging unlearning scenarios including multi-label and multi-class classification tasks, and (4) evaluation metrics involving performance both in terms of utility and extent of unlearning achieved. REMEDI is developed using the MIMIC-III clinical database that contains comprehensive clinical data of patients. Experiments with existing unlearning methods indicate that there exists a trade-off between utility and unlearning performance. They are also largely unsuited to multi-label classification tasks. To facilitate reproducibility, we make our benchmark publicly available.
Cross-Modal Rationale Transfer for Explainable Humanitarian Classification on Social Media
Mar 19, 2026Advances in social media data dissemination enable the provision of real-time information during a crisis. The information comes from different classes, such as infrastructure damages, persons missing or stranded in the affected zone, etc. Existing methods attempted to classify text and images into various humanitarian categories, but their decision-making process remains largely opaque, which affects their deployment in real-life applications. Recent work has sought to improve transparency by extracting textual rationales from tweets to explain predicted classes. However, such explainable classification methods have mostly focused on text, rather than crisis-related images. In this paper, we propose an interpretable-by-design multimodal classification framework. Our method first learns the joint representation of text and image using a visual language transformer model and extracts text rationales. Next, it extracts the image rationales via the mapping with text rationales. Our approach demonstrates how to learn rationales in one modality from another through cross-modal rationale transfer, which saves annotation effort. Finally, tweets are classified based on extracted rationales. Experiments are conducted over CrisisMMD benchmark dataset, and results show that our proposed method boosts the classification Macro-F1 by 2-35% while extracting accurate text tokens and image patches as rationales. Human evaluation also supports the claim that our proposed method is able to retrieve better image rationale patches (12%) that help to identify humanitarian classes. Our method adapts well to new, unseen datasets in zero-shot mode, achieving an accuracy of 80%.
GRACE: GRaph-based Addiction Care prEdiction
Oct 23, 2025Determining the appropriate locus of care for addiction patients is one of the most critical clinical decisions that affects patient treatment outcomes and effective use of resources. With a lack of sufficient specialized treatment resources, such as inpatient beds or staff, there is an unmet need to develop an automated framework for the same. Current decision-making approaches suffer from severe class imbalances in addiction datasets. To address this limitation, we propose a novel graph neural network (GRACE) framework that formalizes locus of care prediction as a structured learning problem. Further, we perform extensive feature engineering and propose a new approach of obtaining an unbiased meta-graph to train a GNN to overcome the class imbalance problem. Experimental results in real-world data show an improvement of 11-35% in terms of the F1 score of the minority class over competitive baselines. The codes and note embeddings are available at https://anonymous.4open.science/r/GRACE-F8E1/.
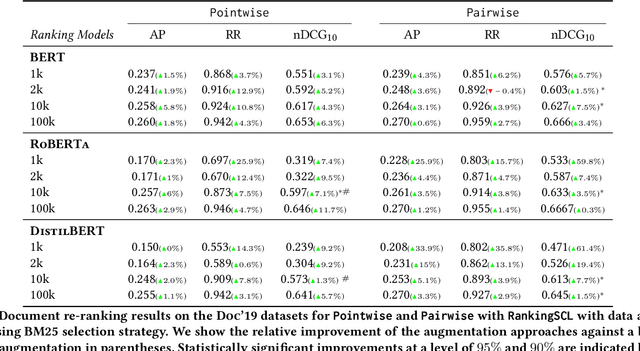
Data Augmentation for Sample Efficient and Robust Document Ranking
Nov 26, 2023Contextual ranking models have delivered impressive performance improvements over classical models in the document ranking task. However, these highly over-parameterized models tend to be data-hungry and require large amounts of data even for fine-tuning. In this paper, we propose data-augmentation methods for effective and robust ranking performance. One of the key benefits of using data augmentation is in achieving sample efficiency or learning effectively when we have only a small amount of training data. We propose supervised and unsupervised data augmentation schemes by creating training data using parts of the relevant documents in the query-document pairs. We then adapt a family of contrastive losses for the document ranking task that can exploit the augmented data to learn an effective ranking model. Our extensive experiments on subsets of the MS MARCO and TREC-DL test sets show that data augmentation, along with the ranking-adapted contrastive losses, results in performance improvements under most dataset sizes. Apart from sample efficiency, we conclusively show that data augmentation results in robust models when transferred to out-of-domain benchmarks. Our performance improvements in in-domain and more prominently in out-of-domain benchmarks show that augmentation regularizes the ranking model and improves its robustness and generalization capability.
Efficient Neural Ranking using Forward Indexes and Lightweight Encoders
Nov 02, 2023Dual-encoder-based dense retrieval models have become the standard in IR. They employ large Transformer-based language models, which are notoriously inefficient in terms of resources and latency. We propose Fast-Forward indexes -- vector forward indexes which exploit the semantic matching capabilities of dual-encoder models for efficient and effective re-ranking. Our framework enables re-ranking at very high retrieval depths and combines the merits of both lexical and semantic matching via score interpolation. Furthermore, in order to mitigate the limitations of dual-encoders, we tackle two main challenges: Firstly, we improve computational efficiency by either pre-computing representations, avoiding unnecessary computations altogether, or reducing the complexity of encoders. This allows us to considerably improve ranking efficiency and latency. Secondly, we optimize the memory footprint and maintenance cost of indexes; we propose two complementary techniques to reduce the index size and show that, by dynamically dropping irrelevant document tokens, the index maintenance efficiency can be improved substantially. We perform evaluation to show the effectiveness and efficiency of Fast-Forward indexes -- our method has low latency and achieves competitive results without the need for hardware acceleration, such as GPUs.
Understanding Lexical Biases when Identifying Gang-related Social Media Communications
Apr 22, 2023



Individuals involved in gang-related activity use mainstream social media including Facebook and Twitter to express taunts and threats as well as grief and memorializing. However, identifying the impact of gang-related activity in order to serve community member needs through social media sources has a unique set of challenges. This includes the difficulty of ethically identifying training data of individuals impacted by gang activity and the need to account for a non-standard language style commonly used in the tweets from these individuals. Our study provides evidence of methods where natural language processing tools can be helpful in efficiently identifying individuals who may be in need of community care resources such as counselors, conflict mediators, or academic/professional training programs. We demonstrate that our binary logistic classifier outperforms baseline standards in identifying individuals impacted by gang-related violence using a sample of gang-related tweets associated with Chicago. We ultimately found that the language of a tweet is highly relevant and that uses of ``big data'' methods or machine learning models need to better understand how language impacts the model's performance and how it discriminates among populations.
A Review of the Role of Causality in Developing Trustworthy AI Systems
Feb 14, 2023



State-of-the-art AI models largely lack an understanding of the cause-effect relationship that governs human understanding of the real world. Consequently, these models do not generalize to unseen data, often produce unfair results, and are difficult to interpret. This has led to efforts to improve the trustworthiness aspects of AI models. Recently, causal modeling and inference methods have emerged as powerful tools. This review aims to provide the reader with an overview of causal methods that have been developed to improve the trustworthiness of AI models. We hope that our contribution will motivate future research on causality-based solutions for trustworthy AI.
Supervised Contrastive Learning Approach for Contextual Ranking
Jul 07, 2022
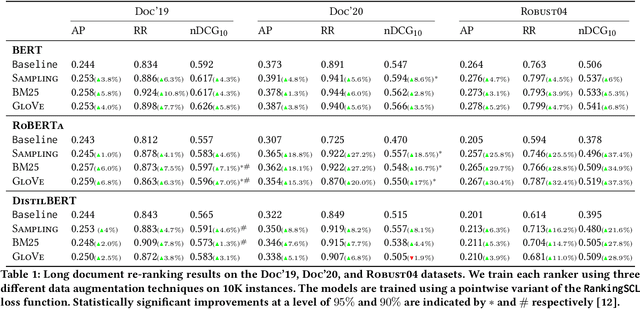
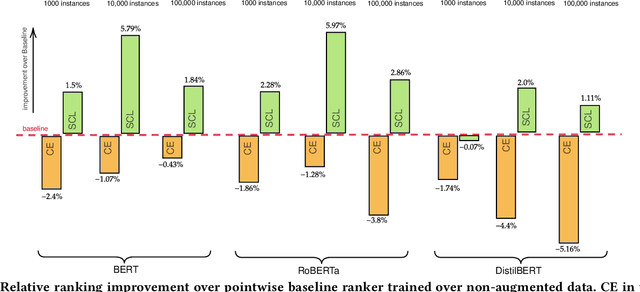
Contextual ranking models have delivered impressive performance improvements over classical models in the document ranking task. However, these highly over-parameterized models tend to be data-hungry and require large amounts of data even for fine tuning. This paper proposes a simple yet effective method to improve ranking performance on smaller datasets using supervised contrastive learning for the document ranking problem. We perform data augmentation by creating training data using parts of the relevant documents in the query-document pairs. We then use a supervised contrastive learning objective to learn an effective ranking model from the augmented dataset. Our experiments on subsets of the TREC-DL dataset show that, although data augmentation leads to an increasing the training data sizes, it does not necessarily improve the performance using existing pointwise or pairwise training objectives. However, our proposed supervised contrastive loss objective leads to performance improvements over the standard non-augmented setting showcasing the utility of data augmentation using contrastive losses. Finally, we show the real benefit of using supervised contrastive learning objectives by showing marked improvements in smaller ranking datasets relating to news (Robust04), finance (FiQA), and scientific fact checking (SciFact).
MTLTS: A Multi-Task Framework To Obtain Trustworthy Summaries From Crisis-Related Microblogs
Dec 10, 2021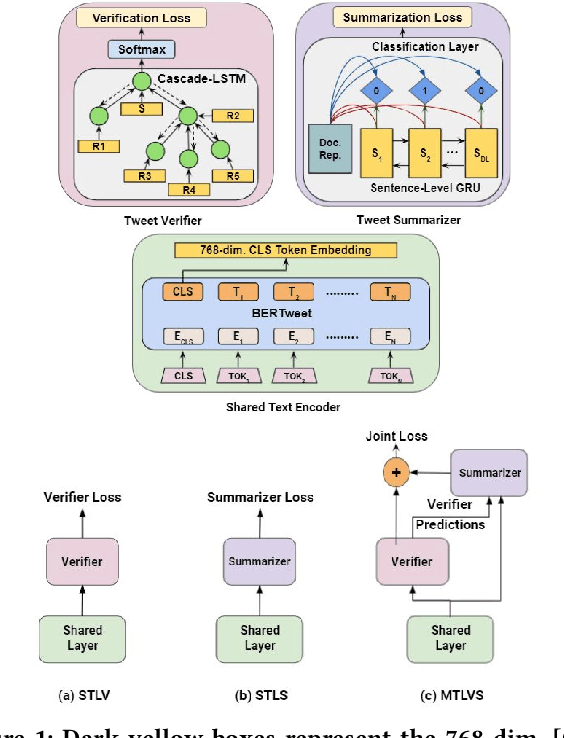
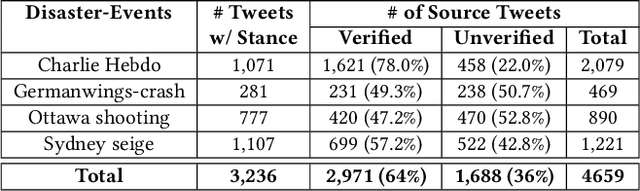
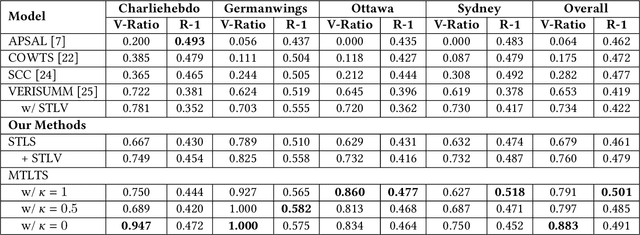
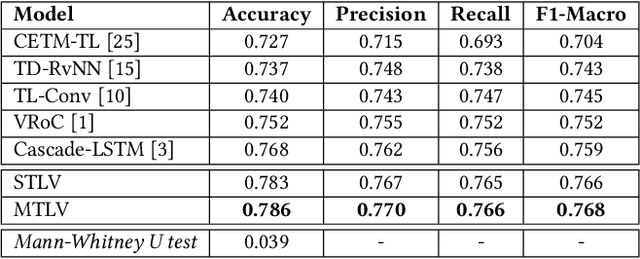
Occurrences of catastrophes such as natural or man-made disasters trigger the spread of rumours over social media at a rapid pace. Presenting a trustworthy and summarized account of the unfolding event in near real-time to the consumers of such potentially unreliable information thus becomes an important task. In this work, we propose MTLTS, the first end-to-end solution for the task that jointly determines the credibility and summary-worthiness of tweets. Our credibility verifier is designed to recursively learn the structural properties of a Twitter conversation cascade, along with the stances of replies towards the source tweet. We then take a hierarchical multi-task learning approach, where the verifier is trained at a lower layer, and the summarizer is trained at a deeper layer where it utilizes the verifier predictions to determine the salience of a tweet. Different from existing disaster-specific summarizers, we model tweet summarization as a supervised task. Such an approach can automatically learn summary-worthy features, and can therefore generalize well across domains. When trained on the PHEME dataset [29], not only do we outperform the strongest baselines for the auxiliary task of verification/rumour detection, we also achieve 21 - 35% gains in the verified ratio of summary tweets, and 16 - 20% gains in ROUGE1-F1 scores over the existing state-of-the-art solutions for the primary task of trustworthy summarization.
Fast Forward Indexes for Efficient Document Ranking
Oct 12, 2021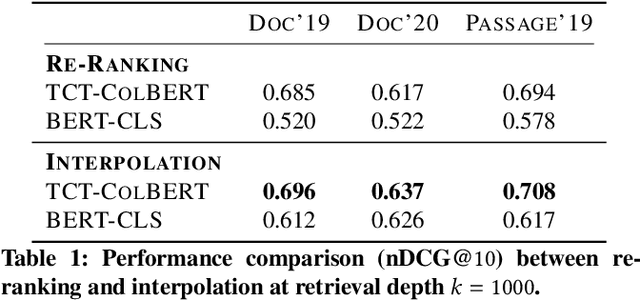

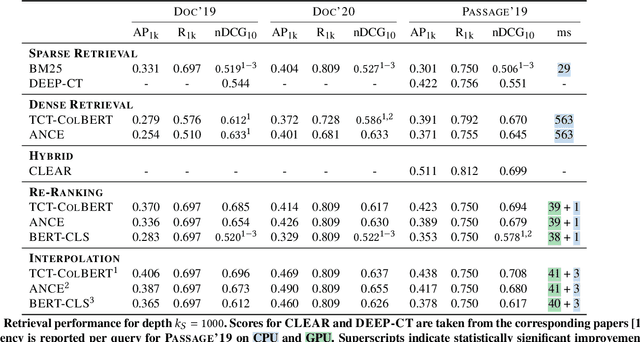
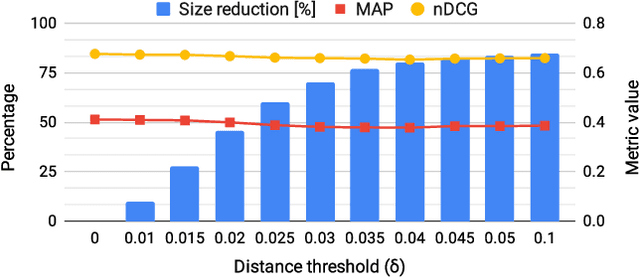
Neural approaches, specifically transformer models, for ranking documents have delivered impressive gains in ranking performance. However, query processing using such over-parameterized models is both resource and time intensive. Consequently, to keep query processing costs manageable, trade-offs are made to reduce the number of documents to be re-ranked or consider leaner models with fewer parameters. In this paper, we propose the fast-forward index -- a simple vector forward index that facilitates ranking documents using interpolation-based ranking models. Fast-forward indexes pre-compute the dense transformer-based vector representations of documents and passages for fast CPU-based semantic similarity computation during query processing. We propose theoretically grounded index pruning and early stopping techniques to improve the query-processing throughput using fast-forward indexes. We conduct extensive large-scale experiments over the TREC-DL datasets and show up to 75% improvement in query-processing performance over hybrid indexes using only CPUs. Along with the efficiency benefits, we show that fast-forward indexes can deliver superior ranking performance due to the complementary benefits of interpolation between lexical and semantic similarities.