 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Generative Trees: Adversarial and Copycat
Jan 26, 2022
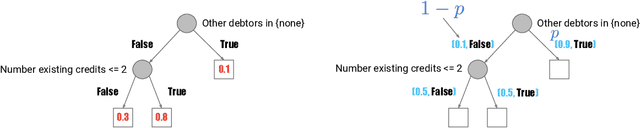

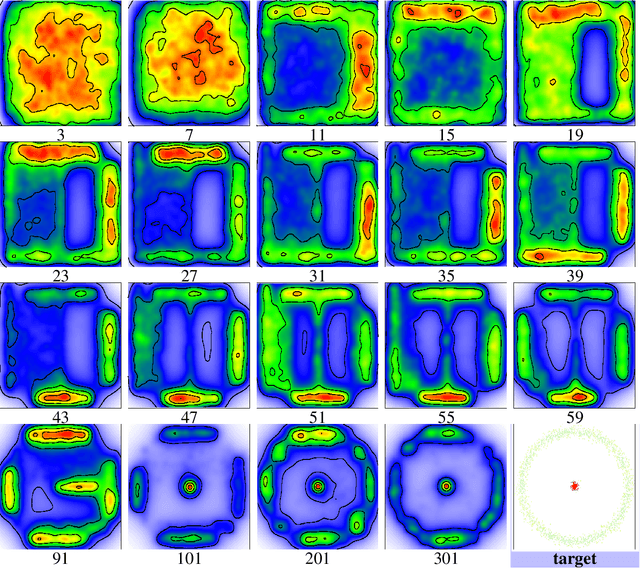
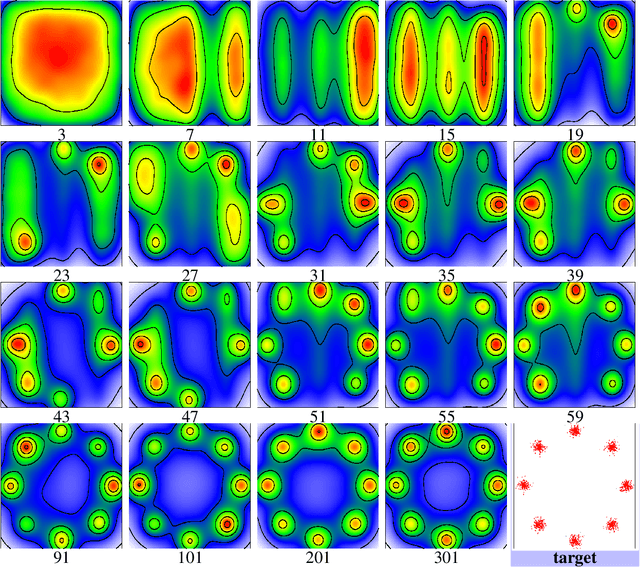
While Generative Adversarial Networks (GANs) achieve spectacular results on unstructured data like images, there is still a gap on tabular data, data for which state of the art supervised learning still favours to a large extent decision tree (DT)-based models. This paper proposes a new path forward for the generation of tabular data, exploiting decades-old understanding of the supervised task's best components for DT induction, from losses (properness), models (tree-based) to algorithms (boosting). The \textit{properness} condition on the supervised loss -- which postulates the optimality of Bayes rule -- leads us to a variational GAN-style loss formulation which is \textit{tight} when discriminators meet a calibration property trivially satisfied by DTs, and, under common assumptions about the supervised loss, yields "one loss to train against them all" for the generator: the $\chi^2$. We then introduce tree-based generative models, \textit{generative trees} (GTs), meant to mirror on the generative side the good properties of DTs for classifying tabular data, with a boosting-compliant \textit{adversarial} training algorithm for GTs. We also introduce \textit{copycat training}, in which the generator copies at run time the underlying tree (graph) of the discriminator DT and completes it for the hardest discriminative task, with boosting compliant convergence. We test our algorithms on tasks including fake/real distinction, training from fake data and missing data imputation. Each one of these tasks displays that GTs can provide comparatively simple -- and interpretable -- contenders to sophisticated state of the art methods for data generation (using neural network models) or missing data imputation (relying on multiple imputation by chained equations with complex tree-based modeling).
EM-driven unsupervised learning for efficient motion segmentation
Jan 06, 2022



This paper presents a CNN-based fully unsupervised method for motion segmentation from optical flow. We assume that the input optical flow can be represented as a piecewise set of parametric motion models, typically, affine or quadratic motion models.The core idea of this work is to leverage the Expectation-Maximization (EM) framework. It enables us to design in a well-founded manner the loss function and the training procedure of our motion segmentation neural network. However, in contrast to the classical iterative EM, once the network is trained, we can provide a segmentation for any unseen optical flow field in a single inference step, with no dependence on the initialization of the motion model parameters since they are not estimated in the inference stage. Different loss functions have been investigated including robust ones. We also propose a novel data augmentation technique on the optical flow field with a noticeable impact on the performance. We tested our motion segmentation network on the DAVIS2016 dataset. Our method outperforms comparable unsupervised methods and is very efficient. Indeed, it can run at 125fps making it usable for real-time applications.
Online Motion Planning with Soft Timed Temporal Logic in Dynamic and Unknown Environment
Oct 18, 2021
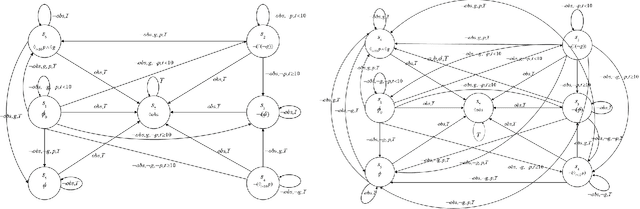
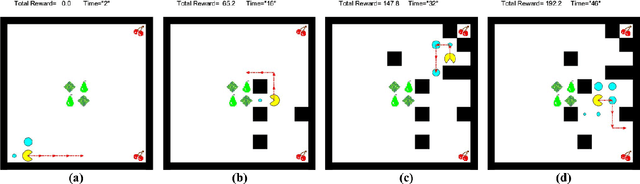
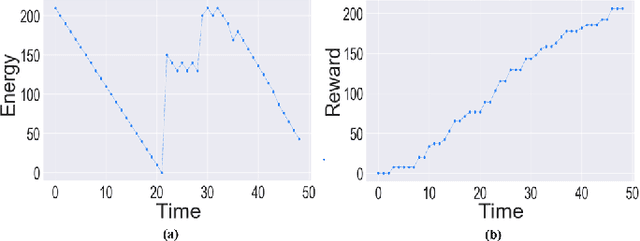
Motion planning of an autonomous system with high-level specifications has wide applications. However, research of formal languages involving timed temporal logic is still under investigation. Furthermore, many existing results rely on a key assumption that user-specified tasks are feasible in the given environment. Challenges arise when the operating environment is dynamic and unknown since the environment can be found prohibitive, leading to potentially conflicting tasks where pre-specified LTL tasks cannot be fully satisfied. Such issues become even more challenging when considering timed requirements. To address these challenges, this work proposes a control framework that considers hard constraints to enforce safety requirements and soft constraints to enable task relaxation. The metric interval temporal logic (MITL) specifications are employed to deal with time constraints. By constructing a relaxed timed product automaton, an online motion planning strategy is synthesized with a receding horizon controller to generate policies, achieving multiple objectives in decreasing order of priority 1) formally guarantee the satisfaction of hard safety constraints; 2) mostly fulfill soft timed tasks; and 3) collect time-varying rewards as much as possible. Another novelty of the relaxed structure is to consider violations of both time and tasks for infeasible cases. Simulation results are provided to validate the proposed approach.
Understanding and Compressing Music with Maximal Transformable Patterns
Jan 26, 2022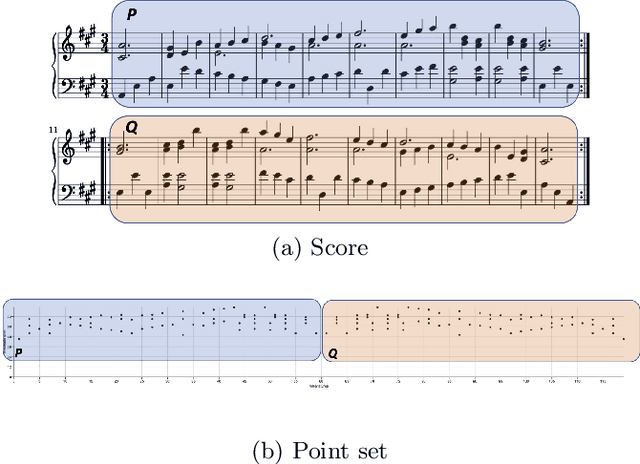
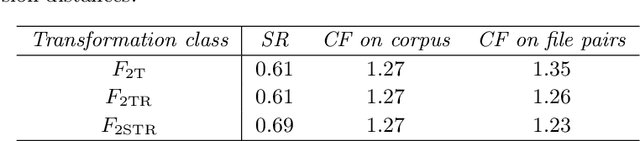
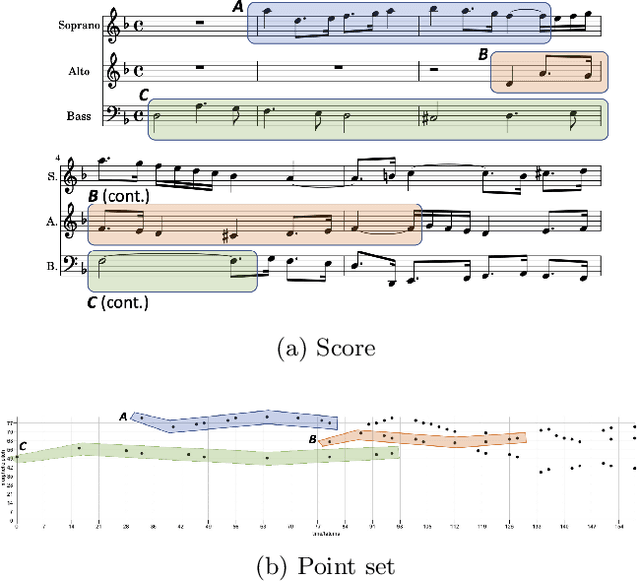

We present a polynomial-time algorithm that discovers all maximal patterns in a point set, $D\in\mathbb{R}^k$, that are related by transformations in a user-specified class, $F$, of bijections over $\mathbb{R}^k$. We also present a second algorithm that discovers the set of occurrences for each of these maximal patterns and then uses compact encodings of these occurrence sets to compute a losslessly compressed encoding of the input point set. This encoding takes the form of a set of pairs, $E=\left\lbrace\left\langle P_1, T_1\right\rangle,\left\langle P_2, T_2\right\rangle,\ldots\left\langle P_{\ell}, T_{\ell}\right\rangle\right\rbrace$, where each $\langle P_i,T_i\rangle$ consists of a maximal pattern, $P_i\subseteq D$, and a set, $T_i\subset F$, of transformations that map $P_i$ onto other subsets of $D$. Each transformation is encoded by a vector of real values that uniquely identifies it within $F$ and the length of this vector is used as a measure of the complexity of $F$. We evaluate the new compression algorithm with three transformation classes of differing complexity, on the task of classifying folk-song melodies into tune families. The most complex of the classes tested includes all combinations of the musical transformations of transposition, inversion, retrograde, augmentation and diminution. We found that broadening the transformation class improved performance on this task. However, it did not, on average, improve compression factor, which may be due to the datasets (in this case, folk-song melodies) being too short and simple to benefit from the potentially greater number of pattern relationships that are discoverable with larger transformation classes.
TransVPR: Transformer-based place recognition with multi-level attention aggregation
Jan 06, 2022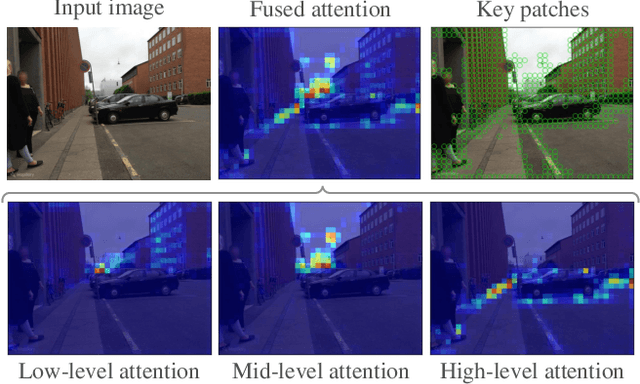

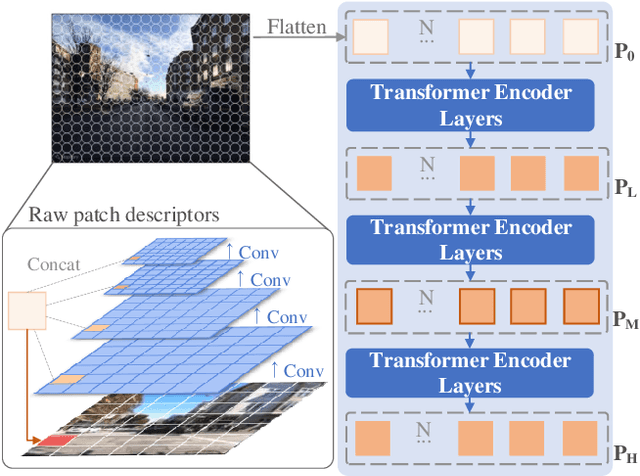
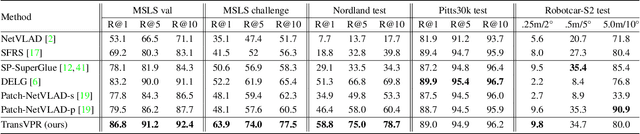
Visual place recognition is a challenging task for applications such as autonomous driving navigation and mobile robot localization. Distracting elements presenting in complex scenes often lead to deviations in the perception of visual place. To address this problem, it is crucial to integrate information from only task-relevant regions into image representations. In this paper, we introduce a novel holistic place recognition model, TransVPR, based on vision Transformers. It benefits from the desirable property of the self-attention operation in Transformers which can naturally aggregate task-relevant features. Attentions from multiple levels of the Transformer, which focus on different regions of interest, are further combined to generate a global image representation. In addition, the output tokens from Transformer layers filtered by the fused attention mask are considered as key-patch descriptors, which are used to perform spatial matching to re-rank the candidates retrieved by the global image features. The whole model allows end-to-end training with a single objective and image-level supervision. TransVPR achieves state-of-the-art performance on several real-world benchmarks while maintaining low computational time and storage requirements.
A Deep Learning and Geospatial Data-Based Channel Estimation Technique for Hybrid Massive MIMO Systems
Jan 29, 2022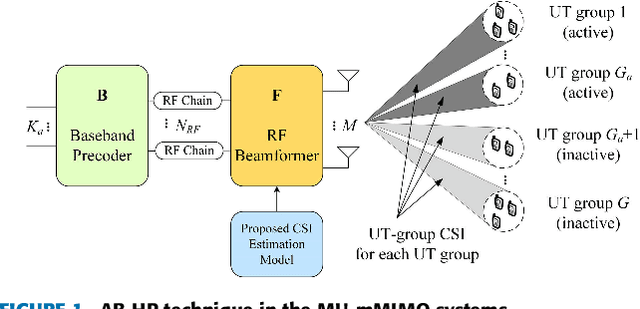
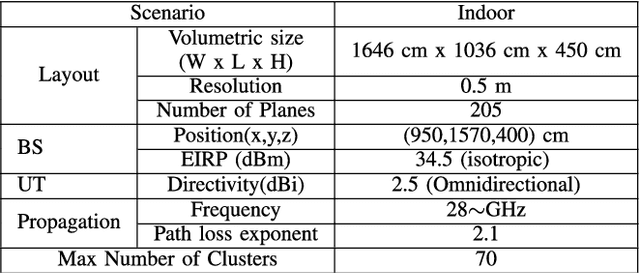

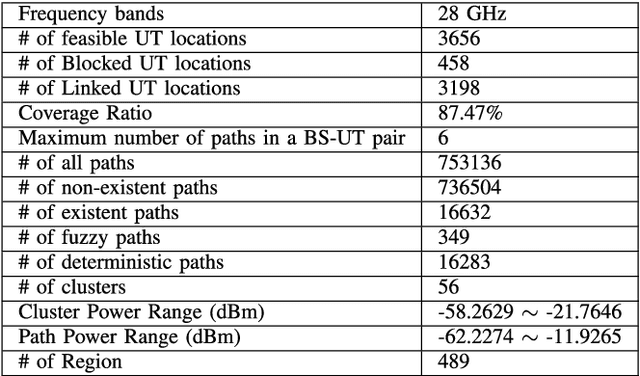
This paper presents a novel channel estimation technique for the multi-user massive multiple-input multiple-output (MU-mMIMO) systems using angular-based hybrid precoding (AB-HP). The proposed channel estimation technique generates group-wise channel state information (CSI) of user terminal (UT) zones in the service area by deep neural networks (DNN) and fuzzy c-Means (FCM) clustering. The slow time-varying CSI between the base station (BS) and feasible UT locations in the service area is calculated from the geospatial data by offline ray tracing and a DNN-based path estimation model associated with the 1-dimensional convolutional neural network (1D-CNN) and regression tree ensembles. Then, the UT-level CSI of all feasible locations is grouped into clusters by a proposed FCM clustering. Finally, the service area is divided into a number of non-overlapping UT zones. Each UT zone is characterized by a corresponding set of clusters named as UT-group CSI, which is utilized in the analog RF beamformer design of AB-HP to reduce the required large online CSI overhead in the MU-mMIMO systems. Then, the reduced-size online CSI is employed in the baseband (BB) precoder of AB-HP. Simulations are conducted in the indoor scenario at 28 GHz and tested in an AB-HP MU-mMIMO system with a uniform rectangular array (URA) having 16x16=256 antennas and 22 RF chains. Illustrative results indicate that 91.4% online CSI can be reduced by using the proposed offline channel estimation technique as compared to the conventional online channel sounding. The proposed DNN-based path estimation technique produces same amount of UT-level CSI with runtime reduced by 65.8% as compared to the computationally expensive ray tracing.
Noise2Filter: fast, self-supervised learning and real-time reconstruction for 3D Computed Tomography
Jul 03, 2020
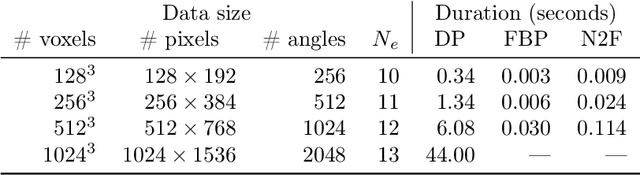
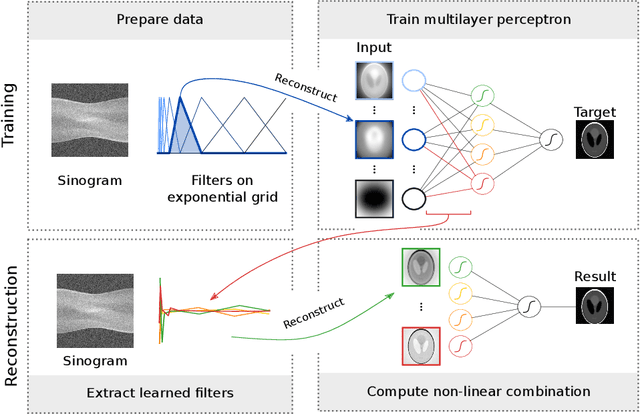
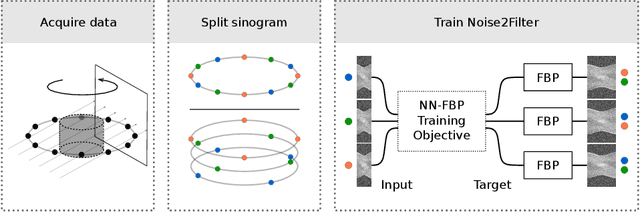
At X-ray beamlines of synchrotron light sources, the achievable time-resolution for 3D tomographic imaging of the interior of an object has been reduced to a fraction of a second, enabling rapidly changing structures to be examined. The associated data acquisition rates require sizable computational resources for reconstruction. Therefore, full 3D reconstruction of the object is usually performed after the scan has completed. Quasi-3D reconstruction -- where several interactive 2D slices are computed instead of a 3D volume -- has been shown to be significantly more efficient, and can enable the real-time reconstruction and visualization of the interior. However, quasi-3D reconstruction relies on filtered backprojection type algorithms, which are typically sensitive to measurement noise. To overcome this issue, we propose Noise2Filter, a learned filter method that can be trained using only the measured data, and does not require any additional training data. This method combines quasi-3D reconstruction, learned filters, and self-supervised learning to derive a tomographic reconstruction method that can be trained in under a minute and evaluated in real-time. We show limited loss of accuracy compared to training with additional training data, and improved accuracy compared to standard filter-based methods.
Improving the Deployment of Recycling Classification through Efficient Hyper-Parameter Analysis
Oct 22, 2021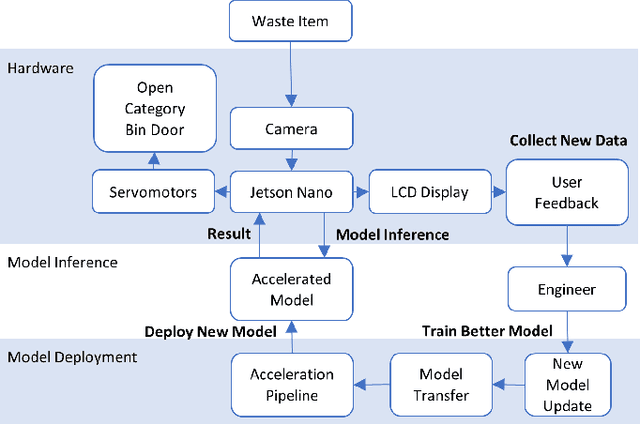
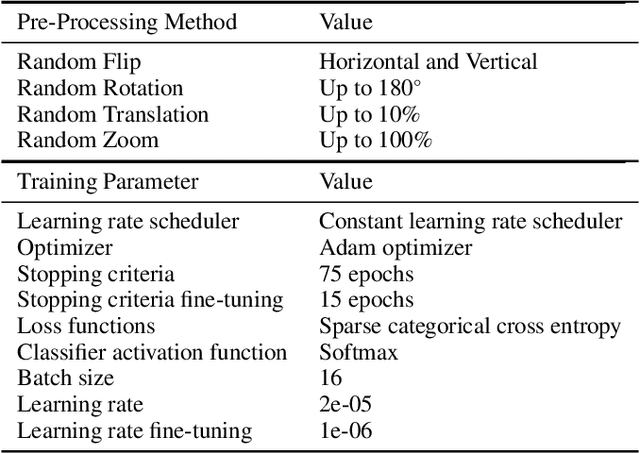
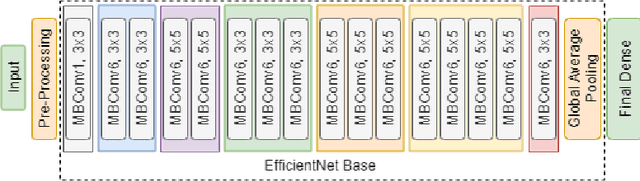
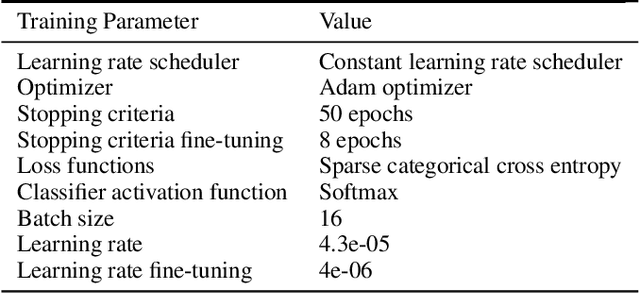
The paradigm of automated waste classification has recently seen a shift in the domain of interest from conventional image processing techniques to powerful computer vision algorithms known as convolutional neural networks (CNN). Historically, CNNs have demonstrated a strong dependency on powerful hardware for real-time classification, yet the need for deployment on weaker embedded devices is greater than ever. The work in this paper proposes a methodology for reconstructing and tuning conventional image classification models, using EfficientNets, to decrease their parameterisation with no trade-off in model accuracy and develops a pipeline through TensorRT for accelerating such models to run at real-time on an NVIDIA Jetson Nano embedded device. The train-deployment discrepancy, relating how poor data augmentation leads to a discrepancy in model accuracy between training and deployment, is often neglected in many papers and thus the work is extended by analysing and evaluating the impact real world perturbations had on model accuracy once deployed. The scope of the work concerns developing a more efficient variant of WasteNet, a collaborative recycling classification model. The newly developed model scores a test-set accuracy of 95.8% with a real world accuracy of 95%, a 14% increase over the original. Our acceleration pipeline boosted model throughput by 750% to 24 inferences per second on the Jetson Nano and real-time latency of the system was verified through servomotor latency analysis.
A Series of Unfortunate Counterfactual Events: the Role of Time in Counterfactual Explanations
Oct 09, 2020
Counterfactual explanations are a prominent example of post-hoc interpretability methods in the explainable Artificial Intelligence research domain. They provide individuals with alternative scenarios and a set of recommendations to achieve a sought-after machine learning model outcome. Recently, the literature has identified desiderata of counterfactual explanations, such as feasibility, actionability and sparsity that should support their applicability in real-world contexts. However, we show that the literature has neglected the problem of the time dependency of counterfactual explanations. We argue that, due to their time dependency and because of the provision of recommendations, even feasible, actionable and sparse counterfactual explanations may not be appropriate in real-world applications. This is due to the possible emergence of what we call "unfortunate counterfactual events." These events may occur due to the retraining of machine learning models whose outcomes have to be explained via counterfactual explanation. Series of unfortunate counterfactual events frustrate the efforts of those individuals who successfully implemented the recommendations of counterfactual explanations. This negatively affects people's trust in the ability of institutions to provide machine learning-supported decisions consistently. We introduce an approach to address the problem of the emergence of unfortunate counterfactual events that makes use of histories of counterfactual explanations. In the final part of the paper we propose an ethical analysis of two distinct strategies to cope with the challenge of unfortunate counterfactual events. We show that they respond to an ethically responsible imperative to preserve the trustworthiness of credit lending organizations, the decision models they employ, and the social-economic function of credit lending.
Control of Unknown Nonlinear Systems with Linear Time-Varying MPC
Apr 09, 2020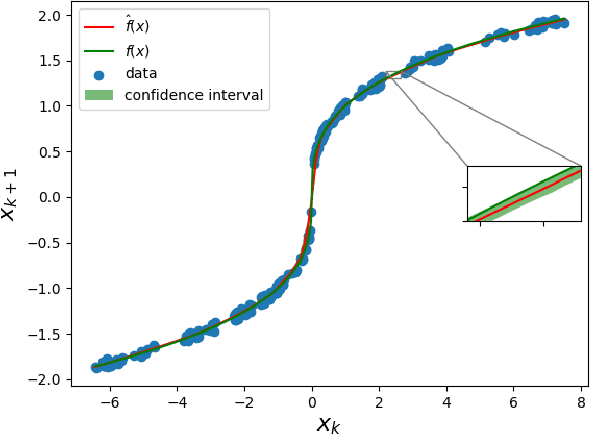
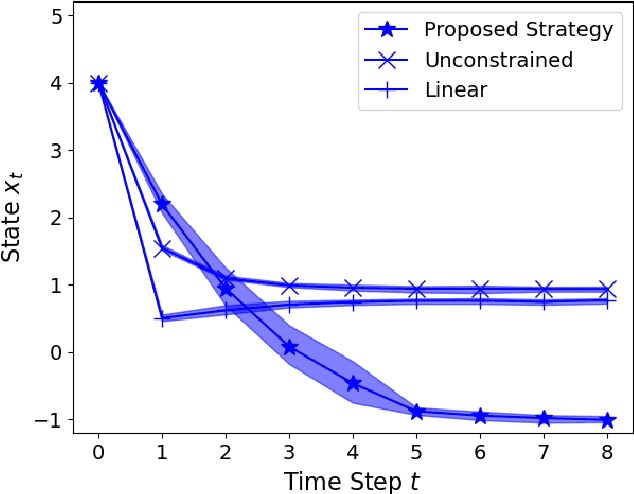
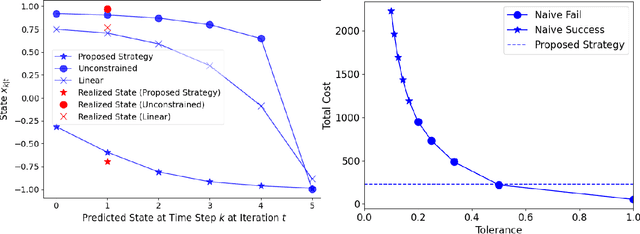
We present a Model Predictive Control (MPC) strategy for unknown input-affine nonlinear dynamical systems. A non-parametric method is used to estimate the nonlinear dynamics from observed data. The estimated nonlinear dynamics are then linearized over time varying regions of the state space to construct an Affine Time Varying (ATV) model. Error bounds arising from the estimation and linearization procedure are computed by using sampling techniques. The ATV model and the uncertainty sets are used to design a robust Model Predictive Control (MPC) problem which guarantees safety for the unknown system with high probability. A simple nonlinear example demonstrates the effectiveness of the approach where commonly used linearization methods fail.