 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time Video Inference on Edge Devices via Adaptive Model Streaming
Jun 11, 2020
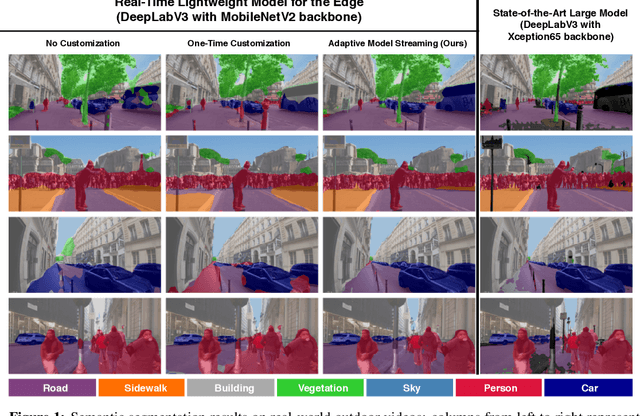

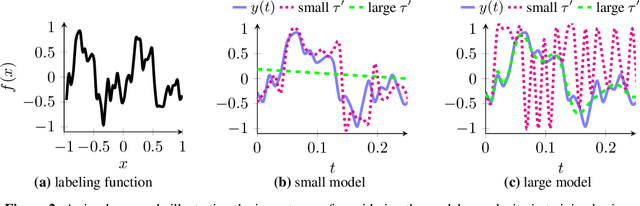
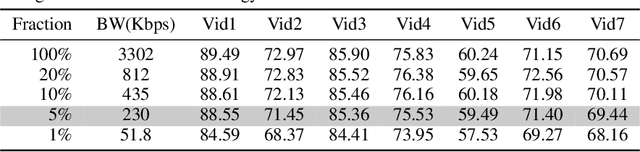
Real-time video inference on compute-limited edge devices like mobile phones and drones is challenging due to the high computation cost of Deep Neural Network models. In this paper we propose Adaptive Model Streaming (AMS), a cloud-assisted approach to real-time video inference on edge devices. The key idea in AMS is to use online learning to continually adapt a lightweight model running on an edge device to boost its performance on the video scenes in real-time. The model is trained in a cloud server and is periodically sent to the edge device. We discuss the challenges of online learning for video and present a practical design that takes into account the edge device, cloud server, and network bandwidth resource limitations. On the task of video semantic segmentation, our experimental results show 5.1--17.0 percent mean Intersection-over-Union improvement compared to a pre-trained model on several real-world videos. Our prototype can perform video segmentation at 30 frames-per-second with 40 milliseconds camera-to-label latency on a Samsung Galaxy S10+ mobile phone, using less than 400Kbps uplink and downlink bandwidth on the device.
Evaluating the phase dynamics of coupled oscillators via time-variant topological features
May 08, 2020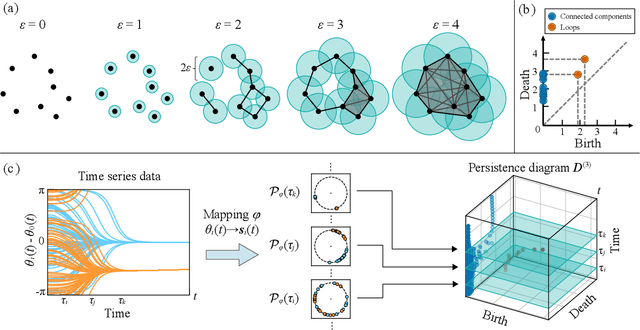
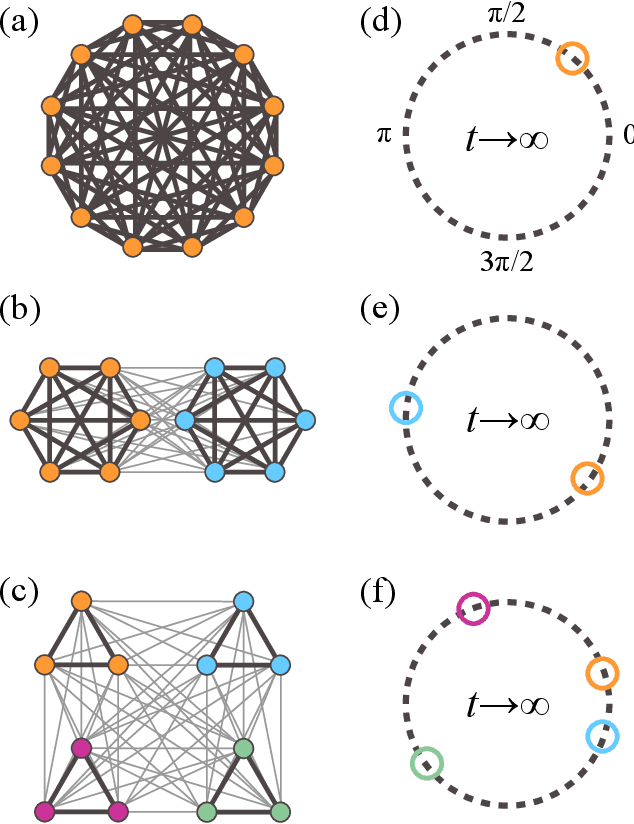
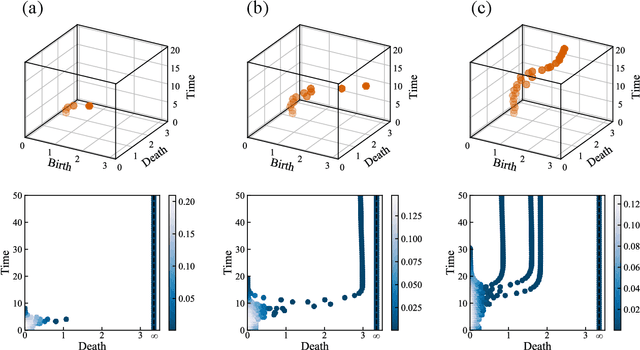
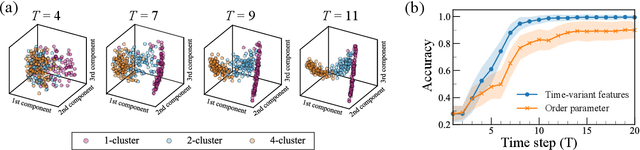
The characterization of phase dynamics in coupled oscillators offers insights into fundamental phenomena in complex systems. To describe the collective dynamics in the oscillatory system, order parameters are often used but are insufficient for identifying more specific behaviors. We therefore propose a topological approach that constructs quantitative features describing the phase evolution of oscillators. Here, the phase data are mapped into a high-dimensional space at each time point, and topological features describing the shape of the data are subsequently extracted from the mapped points. We extend these features to time-variant topological features by considering the evolution time, which serves as an additional dimension in the topological-feature space. The resulting time-variant features provide crucial insights into the time evolution of phase dynamics. We combine these features with the machine learning kernel method to characterize the multicluster synchronized dynamics at a very early stage of the evolution. Furthermore, we demonstrate the usefulness of our method for qualitatively explaining chimera states, which are states of stably coexisting coherent and incoherent groups in systems of identical phase oscillators. The experimental results show that our method is generally better than those using order parameters, especially if only data on the early-stage dynamics are available.
Capturing and incorporating expert knowledge into machine learning models for quality prediction in manufacturing
Feb 04, 2022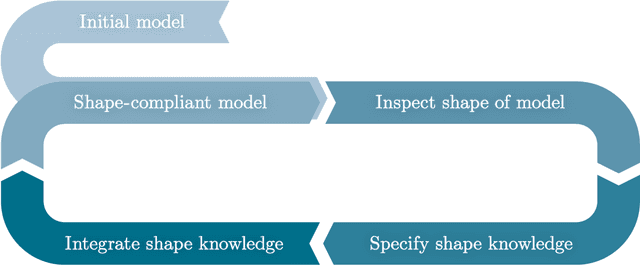

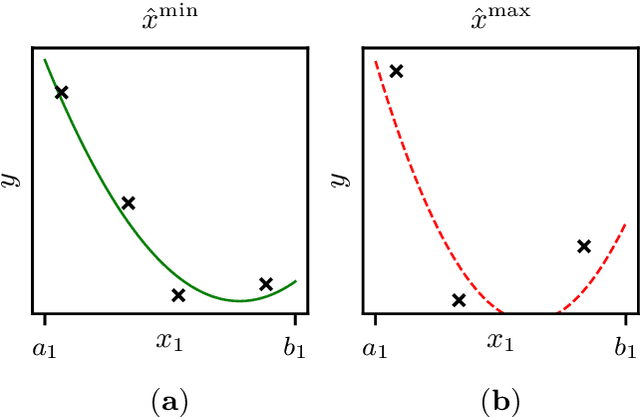
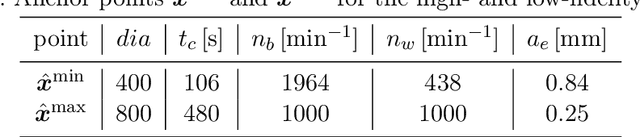
Increasing digitalization enables the use of machine learning methods for analyzing and optimizing manufacturing processes. A main application of machine learning is the construction of quality prediction models, which can be used, among other things, for documentation purposes, as assistance systems for process operators, or for adaptive process control. The quality of such machine learning models typically strongly depends on the amount and the quality of data used for training. In manufacturing, the size of available datasets before start of production is often limited. In contrast to data, expert knowledge commonly is available in manufacturing. Therefore, this study introduces a general methodology for building quality prediction models with machine learning methods on small datasets by integrating shape expert knowledge, that is, prior knowledge about the shape of the input-output relationship to be learned. The proposed methodology is applied to a brushing process with $125$ data points for predicting the surface roughness as a function of five process variables. As opposed to conventional machine learning methods for small datasets, the proposed methodology produces prediction models that strictly comply with all the expert knowledge specified by the involved process specialists. In particular, the direct involvement of process experts in the training of the models leads to a very clear interpretation and, by extension, to a high acceptance of the models. Another merit of the proposed methodology is that, in contrast to most conventional machine learning methods, it involves no time-consuming and often heuristic hyperparameter tuning or model selection step.
NLP in Human Rights Research -- Extracting Knowledge Graphs About Police and Army Units and Their Commanders
Jan 13, 2022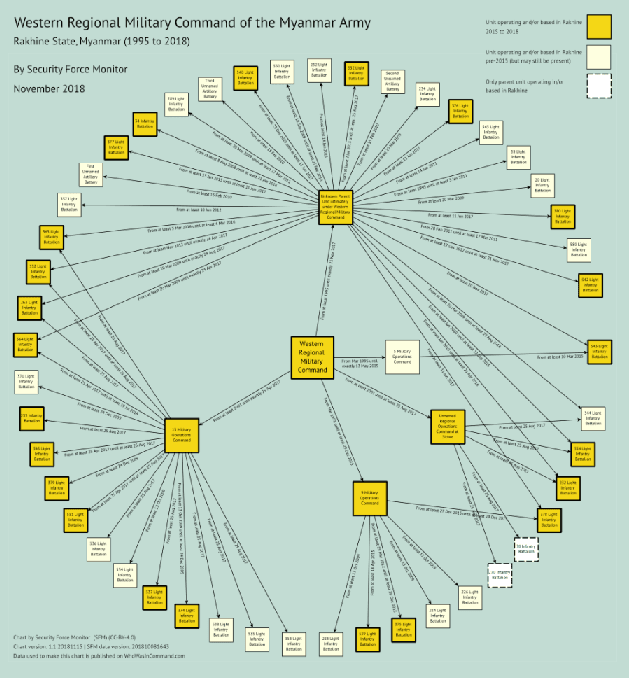
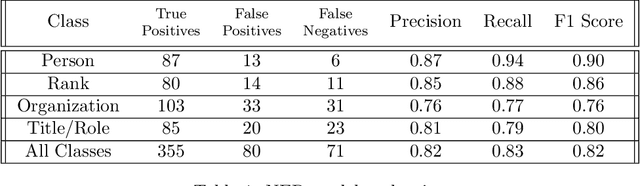
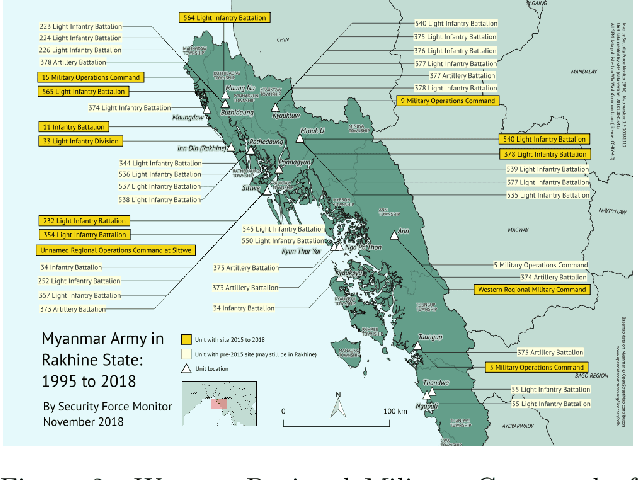

In this working paper we explore the use of an NLP system to assist the work of Security Force Monitor (SFM). SFM creates data about the organizational structure, command personnel and operations of police, army and other security forces, which assists human rights researchers, journalists and litigators in their work to help identify and bring to account specific units and personnel alleged to have committed abuses of human rights and international criminal law. This working paper presents an NLP system that extracts from English language news reports the names of security force units and the biographical details of their personnel, and infers the formal relationship between them. Published alongside this working paper are the system's code and training dataset. We find that the experimental NLP system performs the task at a fair to good level. Its performance is sufficient to justify further development into a live workflow that will give insight into whether its performance translates into savings in time and resource that would make it an effective technical intervention.
On the Role of Multi-Objective Optimization to the Transit Network Design Problem
Jan 27, 2022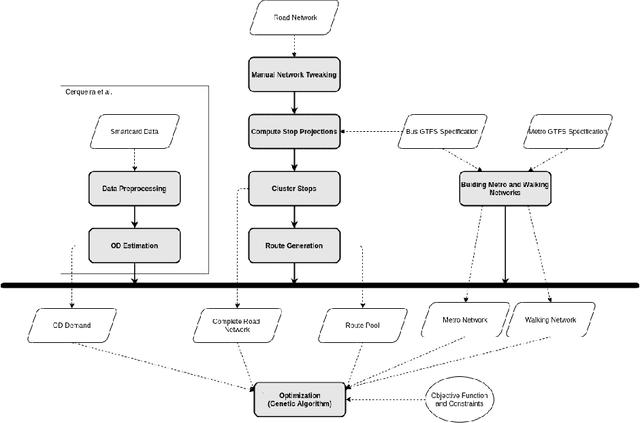
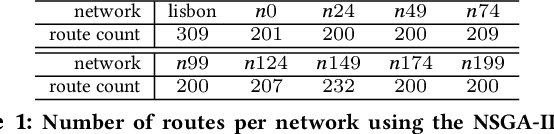
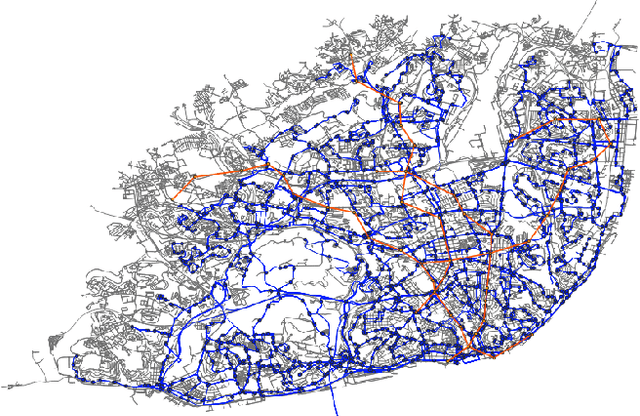
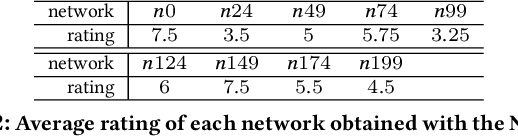
Ongoing traffic changes, including those triggered by the COVID-19 pandemic, reveal the necessity to adapt our public transport systems to the ever-changing users' needs. This work shows that single and multi objective stances can be synergistically combined to better answer the transit network design problem (TNDP). Single objective formulations are dynamically inferred from the rating of networks in the approximated (multi-objective) Pareto Front, where a regression approach is used to infer the optimal weights of transfer needs, times, distances, coverage, and costs. As a guiding case study, the solution is applied to the multimodal public transport network in the city of Lisbon, Portugal. The system takes individual trip data given by smartcard validations at CARRIS buses and METRO subway stations and uses them to estimate the origin-destination demand in the city. Then, Genetic Algorithms are used, considering both single and multi objective approaches, to redesign the bus network that better fits the observed traffic demand. The proposed TNDP optimization proved to improve results, with reductions in objective functions of up to 28.3%. The system managed to extensively reduce the number of routes, and all passenger related objectives, including travel time and transfers per trip, significantly improve. Grounded on automated fare collection data, the system can incrementally redesign the bus network to dynamically handle ongoing changes to the city traffic.
The R package sentometrics to compute, aggregate and predict with textual sentiment
Oct 20, 2021
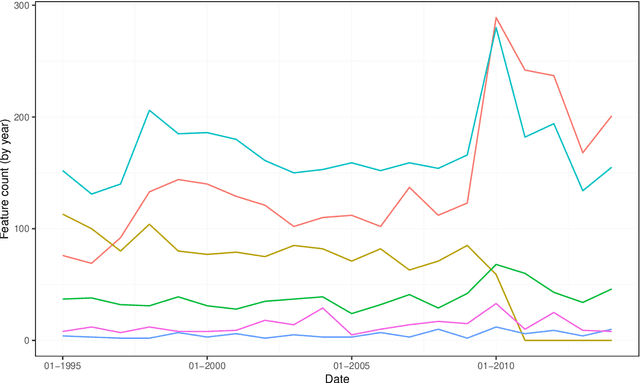
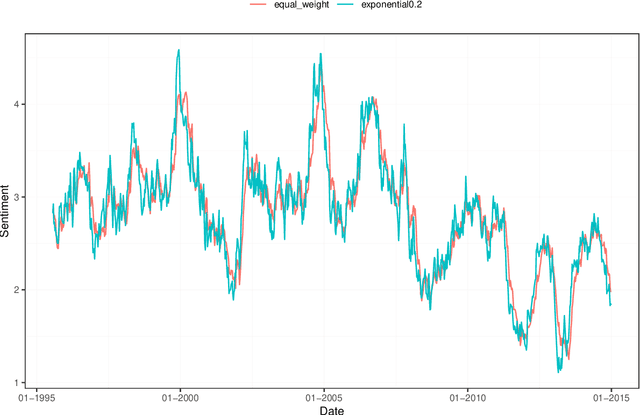

We provide a hands-on introduction to optimized textual sentiment indexation using the R package sentometrics. Textual sentiment analysis is increasingly used to unlock the potential information value of textual data. The sentometrics package implements an intuitive framework to efficiently compute sentiment scores of numerous texts, to aggregate the scores into multiple time series, and to use these time series to predict other variables. The workflow of the package is illustrated with a built-in corpus of news articles from two major U.S. journals to forecast the CBOE Volatility Index.
Semantic Segmentation In-the-Wild Without Seeing Any Segmentation Examples
Dec 06, 2021Semantic segmentation is a key computer vision task that has been actively researched for decades. In recent years, supervised methods have reached unprecedented accuracy, however they require many pixel-level annotations for every new class category which is very time-consuming and expensive. Additionally, the ability of current semantic segmentation networks to handle a large number of categories is limited. That means that images containing rare class categories are unlikely to be well segmented by current methods. In this paper we propose a novel approach for creating semantic segmentation masks for every object, without the need for training segmentation networks or seeing any segmentation masks. Our method takes as input the image-level labels of the class categories present in the image; they can be obtained automatically or manually. We utilize a vision-language embedding model (specifically CLIP) to create a rough segmentation map for each class, using model interpretability methods. We refine the maps using a test-time augmentation technique. The output of this stage provides pixel-level pseudo-labels, instead of the manual pixel-level labels required by supervised methods. Given the pseudo-labels, we utilize single-image segmentation techniques to obtain high-quality output segmentation masks. Our method is shown quantitatively and qualitatively to outperform methods that use a similar amount of supervision. Our results are particularly remarkable for images containing rare categories.
RoutedFusion: Learning Real-time Depth Map Fusion
Jan 13, 2020
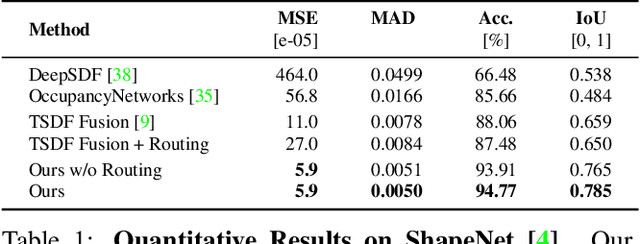

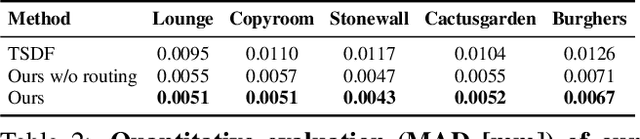
The efficient fusion of depth maps is a key part of most state-of-the-art 3D reconstruction methods. Besides requiring high accuracy, these depth fusion methods need to be scalable and real-time capable. To this end, we present a novel real-time capable machine learning-based method for depth map fusion. Similar to the seminal depth map fusion approach by Curless and Levoy, we only update a local group of voxels to ensure real-time capability. Instead of a simple linear fusion of depth information, we propose a neural network that predicts non-linear updates to better account for typical fusion errors. Our network is composed of a 2D depth routing network and a 3D depth fusion network which efficiently handle sensor-specific noise and outliers. This is especially useful for surface edges and thin objects for which the original approach suffers from thickening artifacts. Our method outperforms the traditional fusion approach and related learned approaches on both synthetic and real data. We demonstrate the performance of our method in reconstructing fine geometric details from noise and outlier contaminated data on various scenes
DACFL: Dynamic Average Consensus Based Federated Learning in Decentralized Topology
Nov 10, 2021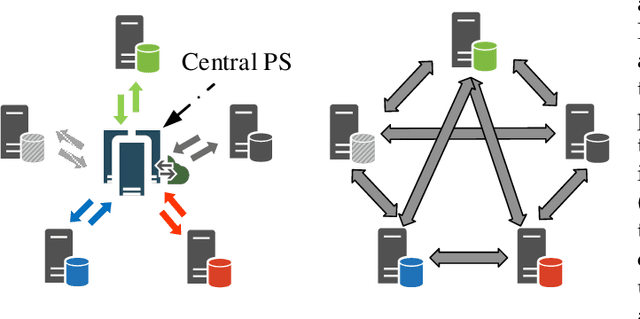

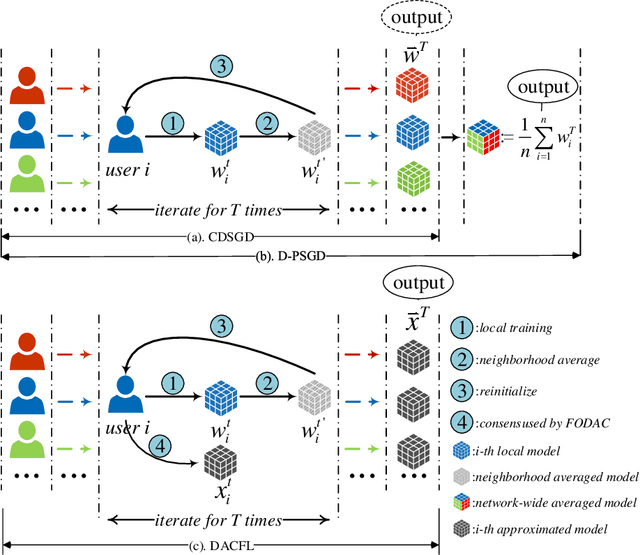
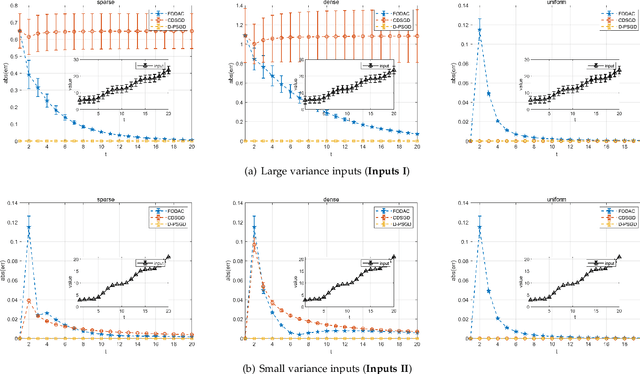
Federated learning (FL) is a burgeoning distributed machine learning framework where a central parameter server (PS) coordinates many local users to train a globally consistent model. Conventional federated learning inevitably relies on a centralized topology with a PS. As a result, it will paralyze once the PS fails. To alleviate such a single point failure, especially on the PS, some existing work has provided decentralized FL (DFL) implementations like CDSGD and D-PSGD to facilitate FL in a decentralized topology. However, there are still some problems with these methods, e.g., significant divergence between users' final models in CDSGD and a network-wide model average necessity in D-PSGD. In order to solve these deficiency, this paper devises a new DFL implementation coined as DACFL, where each user trains its model using its own training data and exchanges the intermediate models with its neighbors through a symmetric and doubly stochastic matrix. The DACFL treats the progress of each user's local training as a discrete-time process and employs a first order dynamic average consensus (FODAC) method to track the \textit{average model} in the absence of the PS. In this paper, we also provide a theoretical convergence analysis of DACFL on the premise of i.i.d data to strengthen its rationality. The experimental results on MNIST, Fashion-MNIST and CIFAR-10 validate the feasibility of our solution in both time-invariant and time-varying network topologies, and declare that DACFL outperforms D-PSGD and CDSGD in most cases.
Computational Complexity of Normalizing Constants for the Product of Determinantal Point Processes
Nov 28, 2021
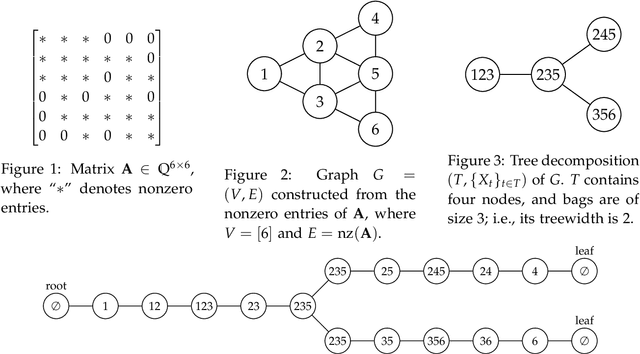
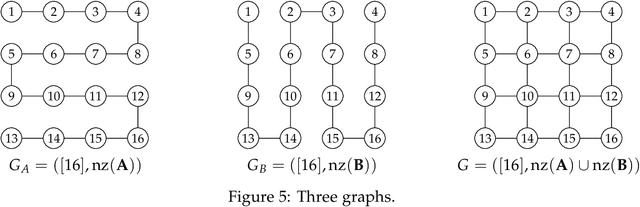
We consider the product of determinantal point processes (DPPs), a point process whose probability mass is proportional to the product of principal minors of multiple matrices, as a natural, promising generalization of DPPs. We study the computational complexity of computing its normalizing constant, which is among the most essential probabilistic inference tasks. Our complexity-theoretic results (almost) rule out the existence of efficient algorithms for this task unless the input matrices are forced to have favorable structures. In particular, we prove the following: (1) Computing $\sum_S\det({\bf A}_{S,S})^p$ exactly for every (fixed) positive even integer $p$ is UP-hard and Mod$_3$P-hard, which gives a negative answer to an open question posed by Kulesza and Taskar. (2) $\sum_S\det({\bf A}_{S,S})\det({\bf B}_{S,S})\det({\bf C}_{S,S})$ is NP-hard to approximate within a factor of $2^{O(|I|^{1-\epsilon})}$ or $2^{O(n^{1/\epsilon})}$ for any $\epsilon>0$, where $|I|$ is the input size and $n$ is the order of the input matrix. This result is stronger than the #P-hardness for the case of two matrices derived by Gillenwater. (3) There exists a $k^{O(k)}n^{O(1)}$-time algorithm for computing $\sum_S\det({\bf A}_{S,S})\det({\bf B}_{S,S})$, where $k$ is the maximum rank of $\bf A$ and $\bf B$ or the treewidth of the graph formed by nonzero entries of $\bf A$ and $\bf B$. Such parameterized algorithms are said to be fixed-parameter tractable. These results can be extended to the fixed-size case. Further, we present two applications of fixed-parameter tractable algorithms given a matrix $\bf A$ of treewidth $w$: (4) We can compute a $2^{\frac{n}{2p-1}}$-approximation to $\sum_S\det({\bf A}_{S,S})^p$ for any fractional number $p>1$ in $w^{O(wp)}n^{O(1)}$ time. (5) We can find a $2^{\sqrt n}$-approximation to unconstrained MAP inference in $w^{O(w\sqrt n)}n^{O(1)}$ time.