 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Jarzynski Estimator with Deterministic Virtual Trajectories
Feb 28, 2021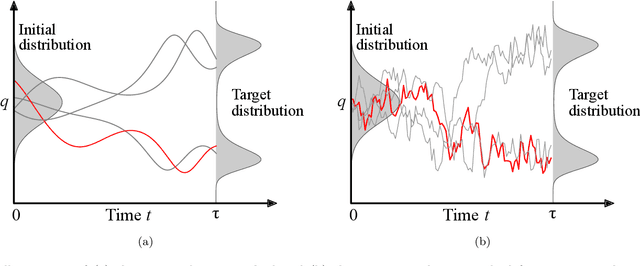
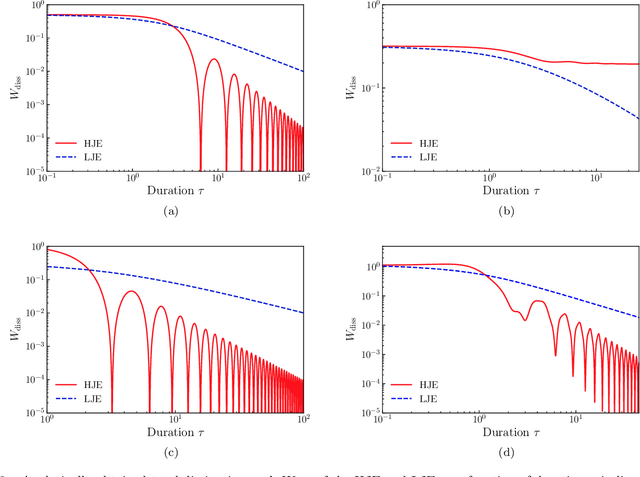
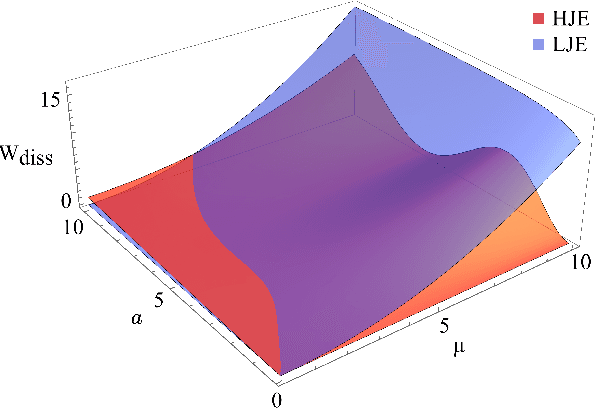
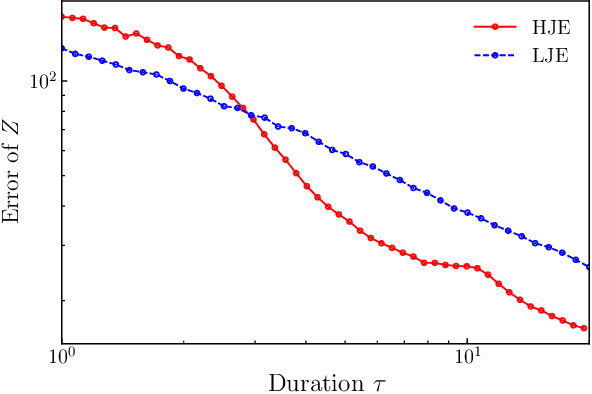
The Jarzynski estimator is a powerful tool that uses nonequilibrium statistical physics to numerically obtain partition functions of probability distributions. The estimator reconstructs partition functions with trajectories of simulated Langevin dynamics through the Jarzynski equality. However, the original estimator suffers from its slow convergence because it depends on rare trajectories of stochastic dynamics. In this paper we present a method to significantly accelerate the convergence by introducing deterministic virtual trajectories generated in augmented state space under Hamiltonian dynamics. We theoretically show that our approach achieves second-order acceleration compared to a naive estimator with Langevin dynamics and zero variance estimation on harmonic potentials. Moreover, we conduct numerical experiments on three multimodal distributions where the proposed method outperforms the conventional method, and provide theoretical explanations.
Evaluating the phase dynamics of coupled oscillators via time-variant topological features
May 08, 2020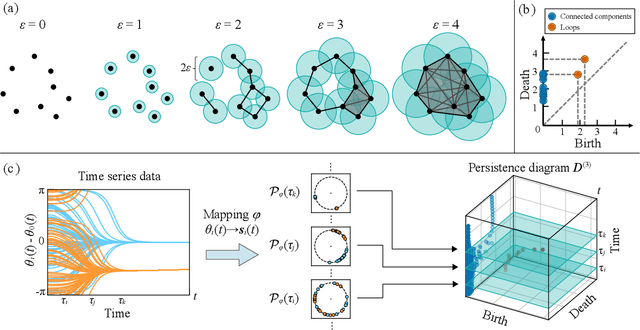
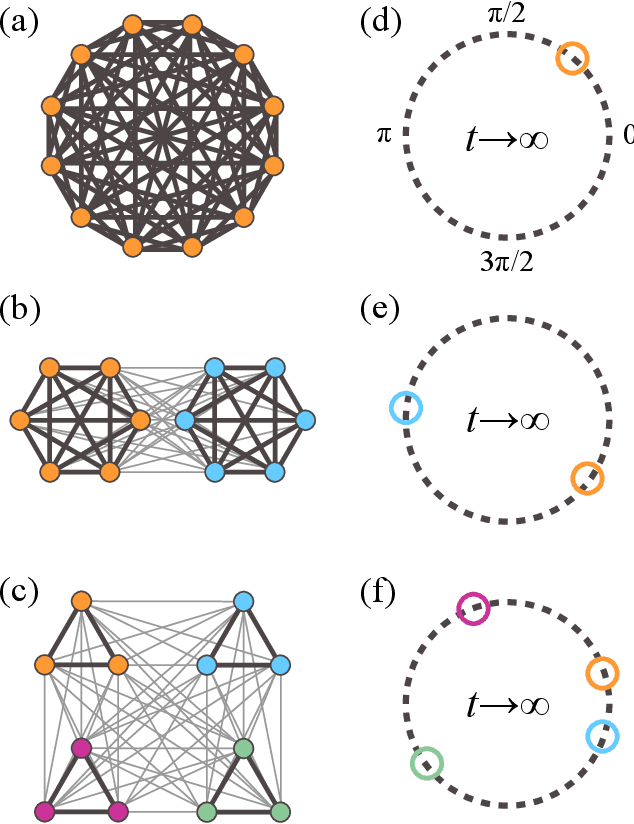
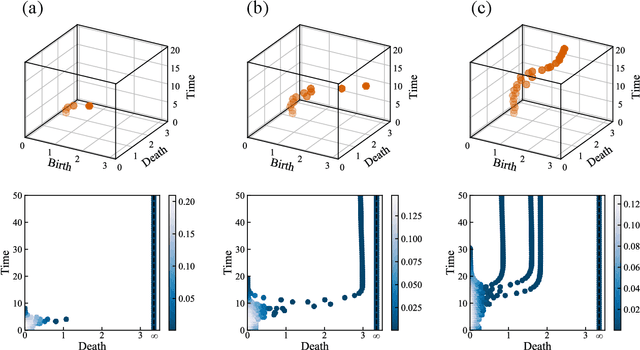
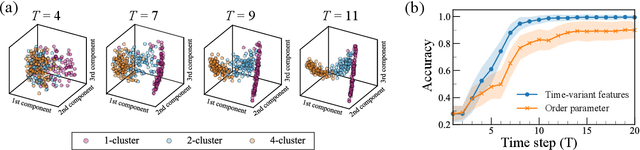
The characterization of phase dynamics in coupled oscillators offers insights into fundamental phenomena in complex systems. To describe the collective dynamics in the oscillatory system, order parameters are often used but are insufficient for identifying more specific behaviors. We therefore propose a topological approach that constructs quantitative features describing the phase evolution of oscillators. Here, the phase data are mapped into a high-dimensional space at each time point, and topological features describing the shape of the data are subsequently extracted from the mapped points. We extend these features to time-variant topological features by considering the evolution time, which serves as an additional dimension in the topological-feature space. The resulting time-variant features provide crucial insights into the time evolution of phase dynamics. We combine these features with the machine learning kernel method to characterize the multicluster synchronized dynamics at a very early stage of the evolution. Furthermore, we demonstrate the usefulness of our method for qualitatively explaining chimera states, which are states of stably coexisting coherent and incoherent groups in systems of identical phase oscillators. The experimental results show that our method is generally better than those using order parameters, especially if only data on the early-stage dynamics are available.
Topological Persistence Machine of Phase Transitions
Apr 24, 2020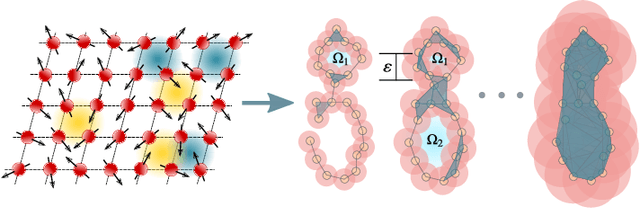
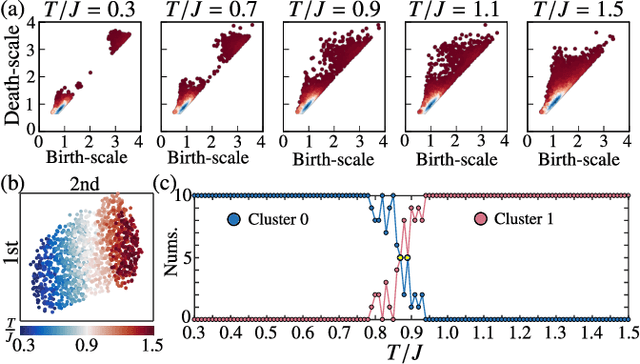
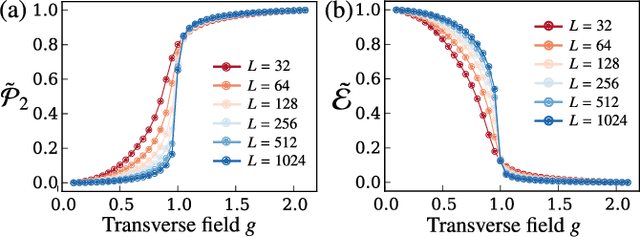
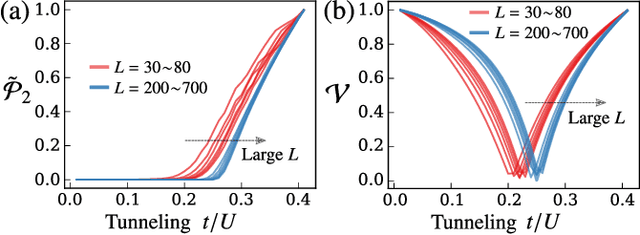
The study of phase transitions using experimental data is challenging, especially when little prior knowledge of the system is available. Topological data analysis is an emerging framework for characterizing the shape of data and has recently achieved success in detecting structural transitions in material science, such as the glass-liquid transition. However, data obtained from physical states may not have explicit shapes as structural materials. We thus propose a general framework, termed "topological persistence machine," to construct the shape of data from correlations in states, so that we can subsequently decipher phase transitions via qualitative changes in the shape. Our framework enables an effective and unified approach in phase transition analysis. We demonstrate the efficacy of the approach in terms of highly precise detection of the Berezinskii-Kosterlitz-Thouless phase transition in the classical XY model and quantum phase transitions in the transverse Ising and Bose-Hubbard models. Interestingly, while these phase transitions have proven to be notoriously difficult to analyze using traditional methods, they can be characterized through our framework without requiring prior knowledge of the phases. Our approach is thus expected to be widely applicable and will provide crucial insights for exploring the phases of experimental physical systems.
Gradient Boosts the Approximate Vanishing Ideal
Nov 11, 2019
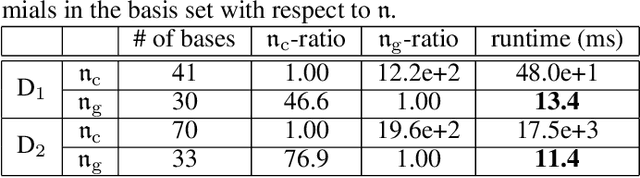
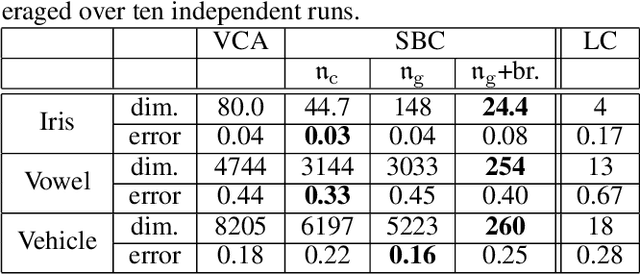
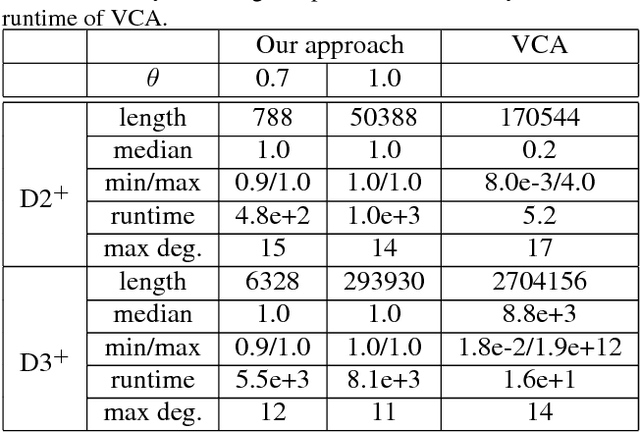
In the last decade, the approximate vanishing ideal and its basis construction algorithms have been extensively studied in computer algebra and machine learning as a general model to reconstruct the algebraic variety on which noisy data approximately lie. In particular, the basis construction algorithms developed in machine learning are widely used in applications across many fields because of their monomial-order-free property; however, they lose many of the theoretical properties of computer-algebraic algorithms. In this paper, we propose general methods that equip monomial-order-free algorithms with several advantageous theoretical properties. Specifically, we exploit the gradient to (i) sidestep the spurious vanishing problem in polynomial time to remove symbolically trivial redundant bases, (ii) achieve consistent output with respect to the translation and scaling of input, and (iii) remove nontrivially redundant bases. The proposed methods work in a fully numerical manner, whereas existing algorithms require the awkward monomial order or exponentially costly (and mostly symbolic) computation to realize properties (i) and (iii). To our knowledge, property (ii) has not been achieved by any existing basis construction algorithm of the approximate vanishing ideal.
Spurious Vanishing Problem in Approximate Vanishing Ideal
Jan 25, 2019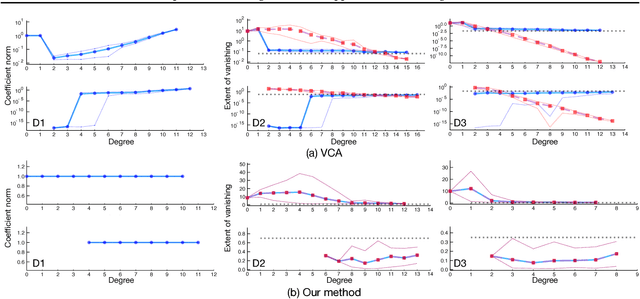
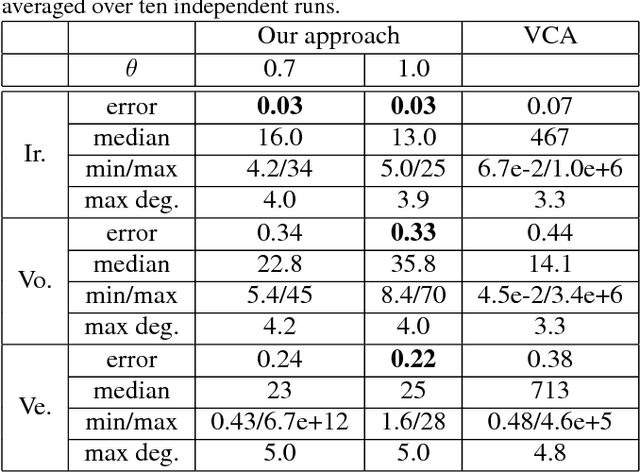
Approximate vanishing ideal, which is a new concept from computer algebra, is a set of polynomials that almost takes a zero value for a set of given data points. The introduction of approximation to exact vanishing ideal has played a critical role in capturing the nonlinear structures of noisy data by computing the approximate vanishing polynomials. However, approximate vanishing has a theoretical problem, which is giving rise to the spurious vanishing problem that any polynomial turns into an approximate vanishing polynomial by coefficient scaling. In the present paper, we propose a general method that enables many basis construction methods to overcome this problem. Furthermore, a coefficient truncation method is proposed that balances the theoretical soundness and computational cost. The experiments show that the proposed method overcomes the spurious vanishing problem and significantly increases the accuracy of classification.
Approximate Vanishing Ideal via Data Knotting
Jan 29, 2018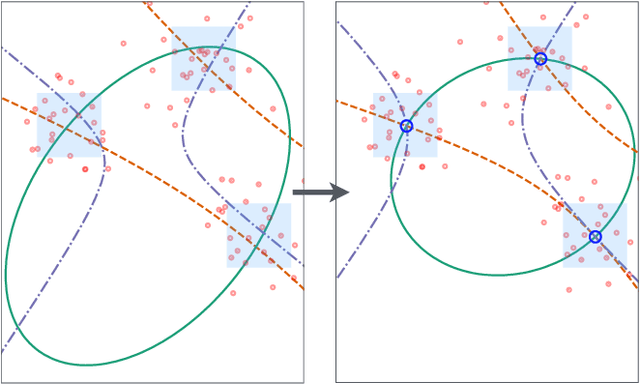


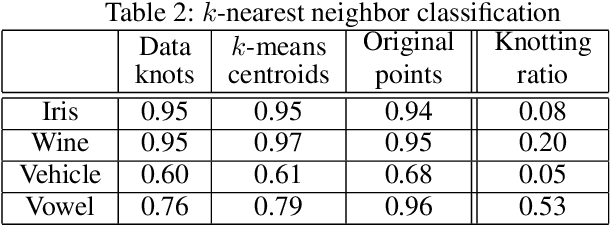
The vanishing ideal is a set of polynomials that takes zero value on the given data points. Originally proposed in computer algebra, the vanishing ideal has been recently exploited for extracting the nonlinear structures of data in many applications. To avoid overfitting to noisy data, the polynomials are often designed to approximately rather than exactly equal zero on the designated data. Although such approximations empirically demonstrate high performance, the sound algebraic structure of the vanishing ideal is lost. The present paper proposes a vanishing ideal that is tolerant to noisy data and also pursued to have a better algebraic structure. As a new problem, we simultaneously find a set of polynomials and data points for which the polynomials approximately vanish on the input data points, and almost exactly vanish on the discovered data points. In experimental classification tests, our method discovered much fewer and lower-degree polynomials than an existing state-of-the-art method. Consequently, our method accelerated the runtime of the classification tasks without degrading the classification accuracy.