 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
End-to-end LPCNet: A Neural Vocoder With Fully-Differentiable LPC Estimation
Feb 23, 2022
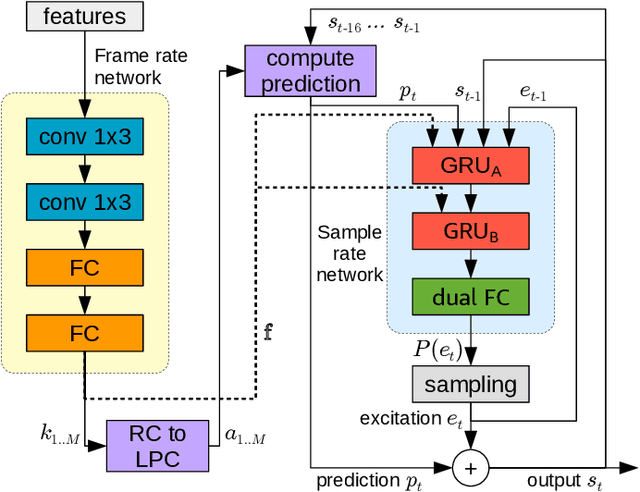
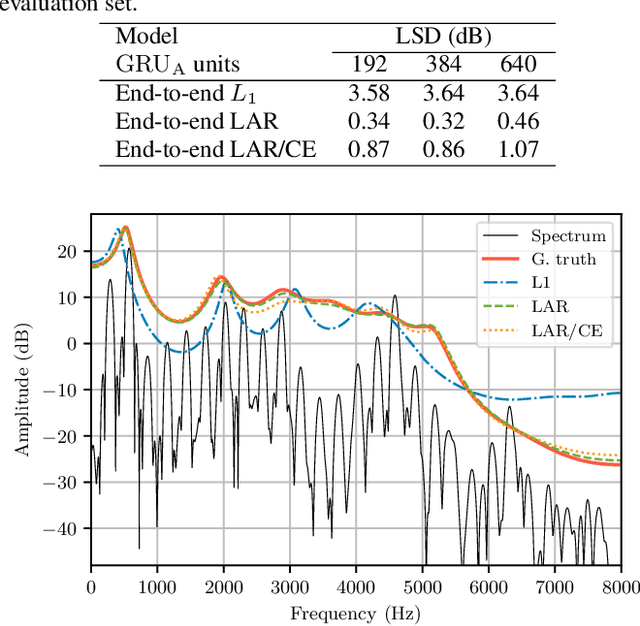
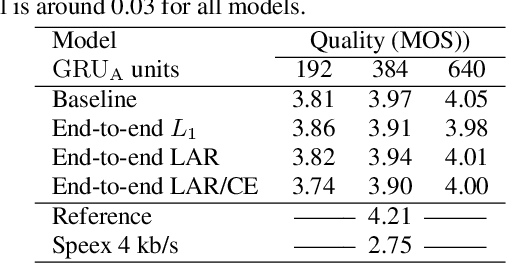
Neural vocoders have recently demonstrated high quality speech synthesis, but typically require a high computational complexity. LPCNet was proposed as a way to reduce the complexity of neural synthesis by using linear prediction~(LP) to assist an autoregressive model. At inference time, LPCNet relies on the LP coefficients being explicitly computed from the input acoustic features. That makes the design of LPCNet-based systems more complicated, while adding the constraint that the input features must represent a clean speech spectrum. We propose an end-to-end version of LPCNet that lifts these limitations by learning to infer the LP coefficients in the frame rate network from the input features. Results show that the proposed end-to-end approach can reach the same level of quality as the original LPCNet model, but without explicit LP analysis. Our open-source end-to-end model still benefits from LPCNet's low complexity, while allowing for any type of conditioning features.
Time Series Forecasting With Deep Learning: A Survey
Apr 28, 2020
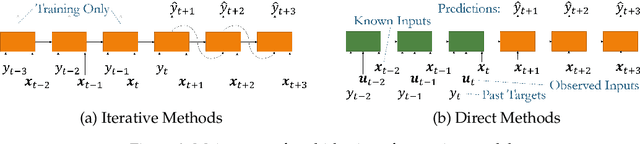
Numerous deep learning architectures have been developed to accommodate the diversity of time series datasets across different domains. In this article, we survey common encoder and decoder designs used in both one-step-ahead and multi-horizon time series forecasting -- describing how temporal information is incorporated into predictions by each model. Next, we highlight recent developments in hybrid deep learning models, which combine well-studied statistical models with neural network components to improve pure methods in either category. Lastly, we outline some ways in which deep learning can also facilitate decision support with time series data.
ReenactNet: Real-time Full Head Reenactment
May 22, 2020Video-to-video synthesis is a challenging problem aiming at learning a translation function between a sequence of semantic maps and a photo-realistic video depicting the characteristics of a driving video. We propose a head-to-head system of our own implementation capable of fully transferring the human head 3D pose, facial expressions and eye gaze from a source to a target actor, while preserving the identity of the target actor. Our system produces high-fidelity, temporally-smooth and photo-realistic synthetic videos faithfully transferring the human time-varying head attributes from the source to the target actor. Our proposed implementation: 1) works in real time ($\sim 20$ fps), 2) runs on a commodity laptop with a webcam as the only input, 3) is interactive, allowing the participant to drive a target person, e.g. a celebrity, politician, etc, instantly by varying their expressions, head pose, and eye gaze, and visualising the synthesised video concurrently.
A PDE-Based Analysis of the Symmetric Two-Armed Bernoulli Bandit
Feb 11, 2022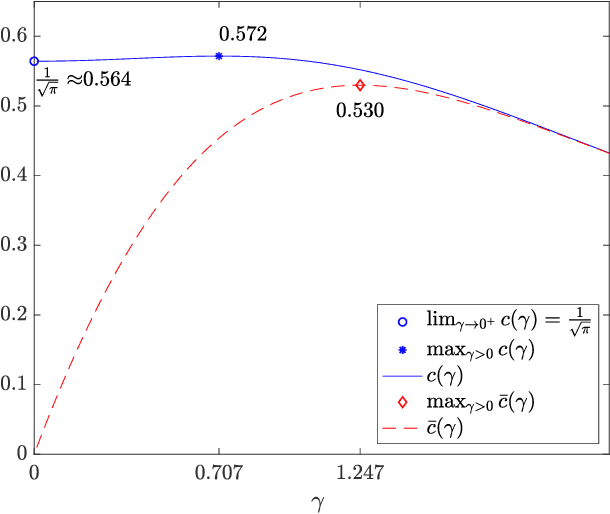
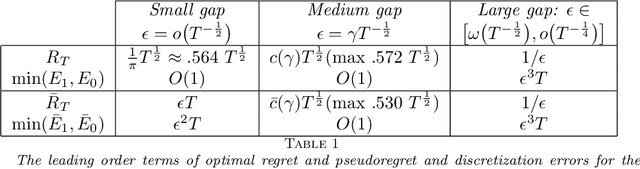
This work addresses a version of the two-armed Bernoulli bandit problem where the sum of the means of the arms is one (the symmetric two-armed Bernoulli bandit). In a regime where the gap between these means goes to zero and the number of prediction periods approaches infinity, we obtain the leading order terms of the expected regret and pseudoregret for this problem by associating each of them with a solution of a linear parabolic partial differential equation. Our results improve upon the previously known results; specifically we explicitly compute the leading order term of the optimal regret and pseudoregret in three different scaling regimes for the gap. Additionally, we obtain new non-asymptotic bounds for any given time horizon.
Fast and selective super-resolution ultrasound in vivo with sono-switchable nanodroplets
Mar 08, 2022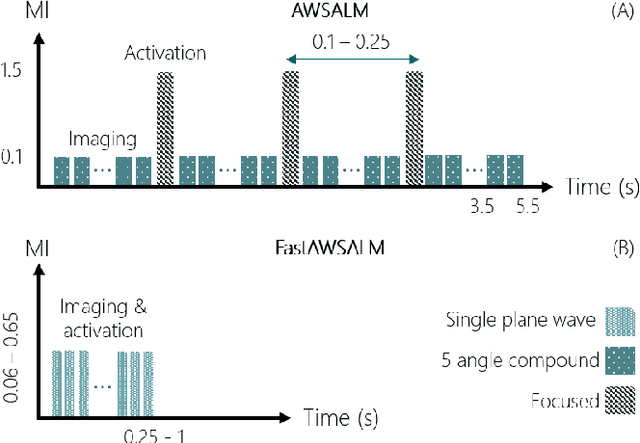
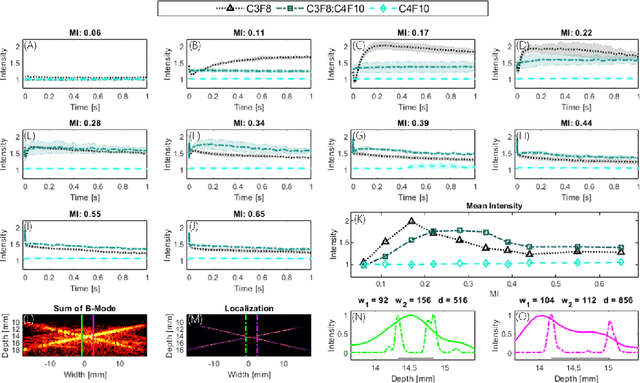
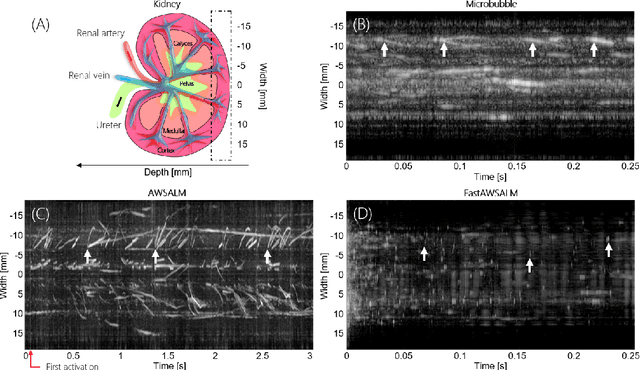
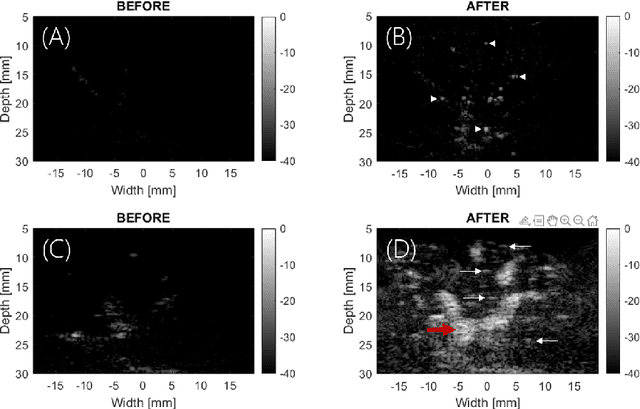
Perfusion by the microcirculation is key to the development, maintenance and pathology of tissue. Its measurement with high spatiotemporal resolution is consequently valuable but remains a challenge in deep tissue. Ultrasound Localization Microscopy (ULM) provides very high spatiotemporal resolution but the use of microbubbles requires low contrast agent concentrations, a long acquisition time, and gives little control over the spatial and temporal distribution of the bubbles. The present study is the first to demonstrate Acoustic Wave Sparsely-Activated Localization Microscopy (AWSALM) and fast-AWSALM for in vivo super-resolution ultrasound imaging, offering contrast on demand and vascular selectivity. Three different formulations of sono-switchable contrast agents were tested. We demonstrate their use with ultrasound mechanical indices well within recommended safety limits to enable fast on-demand sparse switching at very high agent concentrations. We produce super-localization maps of the rabbit renal vasculature with acquisition times between 5.5 s and 0.25 s, and an 4-fold improvement in spatial resolution. We present the unique selectivity of AWSALM in visualizing specific vascular branches and downstream microvasculature, and we show super-localized kidney structures in systole and diastole with fast-AWSALM. In conclusion we demonstrate the feasibility of fast and selective measurement of microvascular dynamics in vivo with subwavelength resolution using ultrasound and sono-switchable nanodroplets.
Integrating Statistical Uncertainty into Neural Network-Based Speech Enhancement
Mar 04, 2022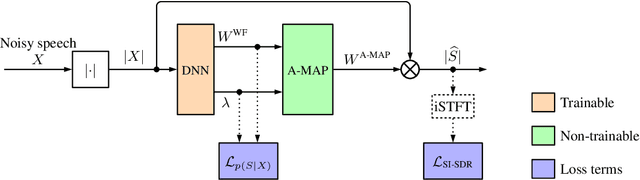
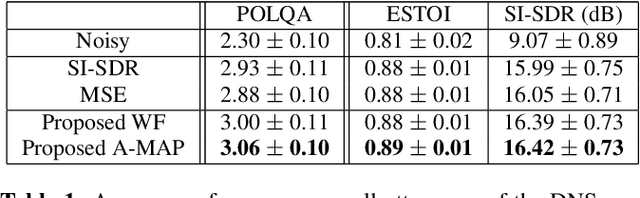
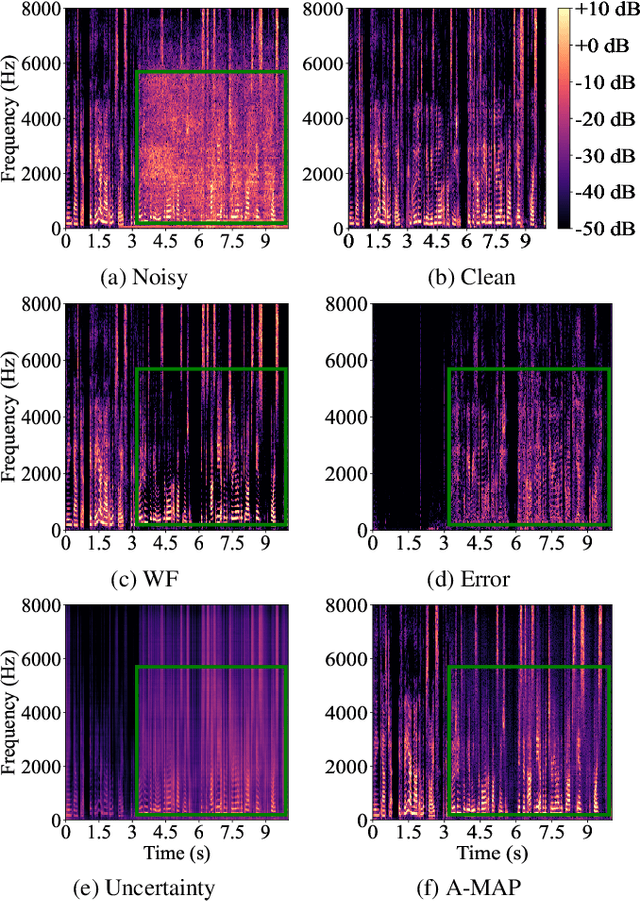
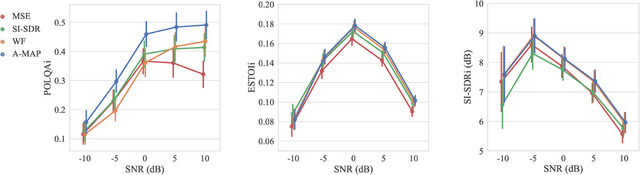
Speech enhancement in the time-frequency domain is often performed by estimating a multiplicative mask to extract clean speech. However, most neural network-based methods perform point estimation, i.e., their output consists of a single mask. In this paper, we study the benefits of modeling uncertainty in neural network-based speech enhancement. For this, our neural network is trained to map a noisy spectrogram to the Wiener filter and its associated variance, which quantifies uncertainty, based on the maximum a posteriori (MAP) inference of spectral coefficients. By estimating the distribution instead of the point estimate, one can model the uncertainty associated with each estimate. We further propose to use the estimated Wiener filter and its uncertainty to build an approximate MAP (A-MAP) estimator of spectral magnitudes, which in turn is combined with the MAP inference of spectral coefficients to form a hybrid loss function to jointly reinforce the estimation. Experimental results on different datasets show that the proposed method can not only capture the uncertainty associated with the estimated filters, but also yield a higher enhancement performance over comparable models that do not take uncertainty into account.
* \copyright 2022 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Scientific Discovery and the Cost of Measurement -- Balancing Information and Cost in Reinforcement Learning
Dec 14, 2021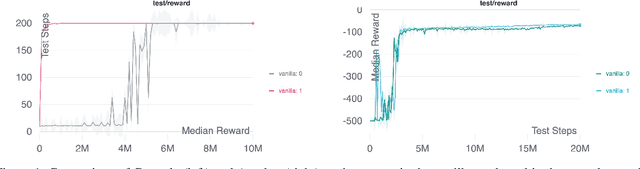
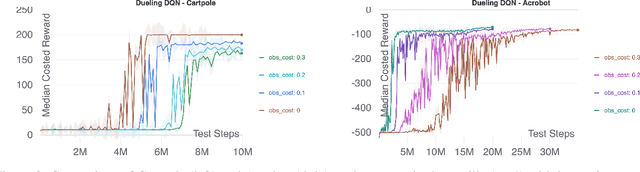


The use of reinforcement learning (RL) in scientific applications, such as materials design and automated chemistry, is increasing. A major challenge, however, lies in fact that measuring the state of the system is often costly and time consuming in scientific applications, whereas policy learning with RL requires a measurement after each time step. In this work, we make the measurement costs explicit in the form of a costed reward and propose a framework that enables off-the-shelf deep RL algorithms to learn a policy for both selecting actions and determining whether or not to measure the current state of the system at each time step. In this way, the agents learn to balance the need for information with the cost of information. Our results show that when trained under this regime, the Dueling DQN and PPO agents can learn optimal action policies whilst making up to 50\% fewer state measurements, and recurrent neural networks can produce a greater than 50\% reduction in measurements. We postulate the these reduction can help to lower the barrier to applying RL to real-world scientific applications.
No-Regret Learning with Unbounded Losses: The Case of Logarithmic Pooling
Feb 22, 2022For each of $T$ time steps, $m$ experts report probability distributions over $n$ outcomes; we wish to learn to aggregate these forecasts in a way that attains a no-regret guarantee. We focus on the fundamental and practical aggregation method known as logarithmic pooling -- a weighted average of log odds -- which is in a certain sense the optimal choice of pooling method if one is interested in minimizing log loss (as we take to be our loss function). We consider the problem of learning the best set of parameters (i.e. expert weights) in an online adversarial setting. We assume (by necessity) that the adversarial choices of outcomes and forecasts are consistent, in the sense that experts report calibrated forecasts. Our main result is an algorithm based on online mirror descent that learns expert weights in a way that attains $O(\sqrt{T} \log T)$ expected regret as compared with the best weights in hindsight.
Enhancing crowd flow prediction in various spatial and temporal granularities
Mar 12, 2022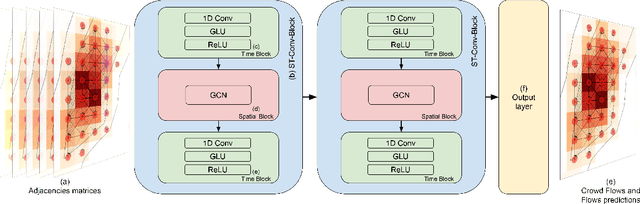
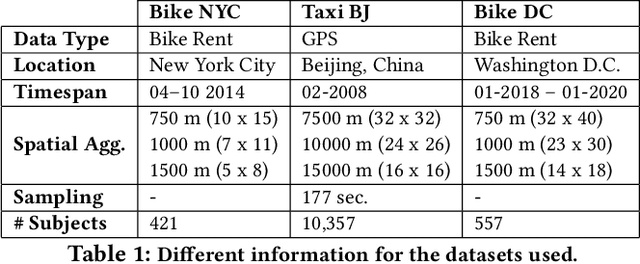
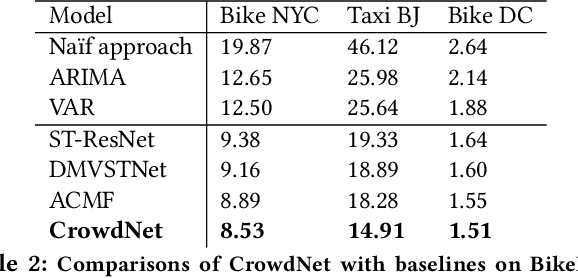
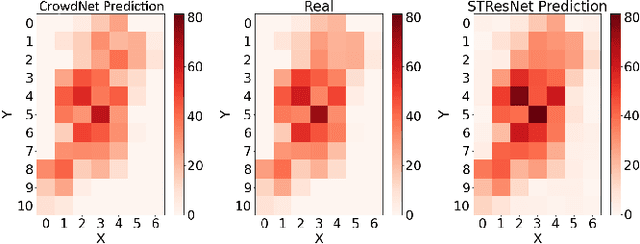
Thanks to the diffusion of the Internet of Things, nowadays it is possible to sense human mobility almost in real time using unconventional methods (e.g., number of bikes in a bike station). Due to the diffusion of such technologies, the last years have witnessed a significant growth of human mobility studies, motivated by their importance in a wide range of applications, from traffic management to public security and computational epidemiology. A mobility task that is becoming prominent is crowd flow prediction, i.e., forecasting aggregated incoming and outgoing flows in the locations of a geographic region. Although several deep learning approaches have been proposed to solve this problem, their usage is limited to specific types of spatial tessellations and cannot provide sufficient explanations of their predictions. We propose CrowdNet, a solution to crowd flow prediction based on graph convolutional networks. Compared with state-of-the-art solutions, CrowdNet can be used with regions of irregular shapes and provide meaningful explanations of the predicted crowd flows. We conduct experiments on public data varying the spatio-temporal granularity of crowd flows to show the superiority of our model with respect to existing methods, and we investigate CrowdNet's reliability to missing or noisy input data. Our model is a step forward in the design of reliable deep learning models to predict and explain human displacements in urban environments.
Cluster Head Detection for Hierarchical UAV Swarm With Graph Self-supervised Learning
Mar 08, 2022
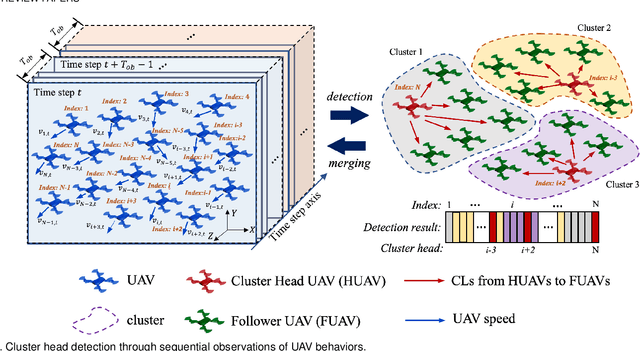
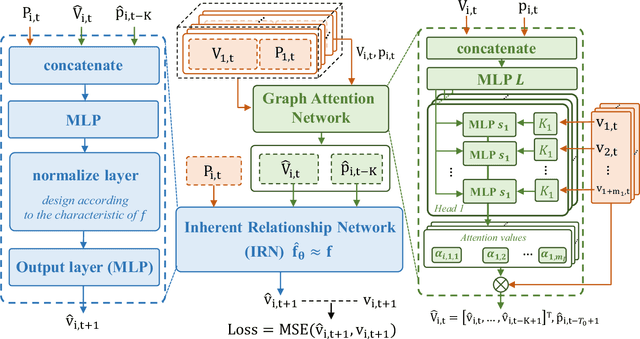

In this paper, we study the cluster head detection problem of a two-level unmanned aerial vehicle (UAV) swarm network (USNET) with multiple UAV clusters, where the inherent follow strategy (IFS) of low-level follower UAVs (FUAVs) with respect to high-level cluster head UAVs (HUAVs) is unknown. We first propose a graph attention self-supervised learning algorithm (GASSL) to detect the HUAVs of a single UAV cluster, where the GASSL can fit the IFS at the same time. Then, to detect the HUAVs in the USNET with multiple UAV clusters, we develop a multi-cluster graph attention self-supervised learning algorithm (MC-GASSL) based on the GASSL. The MC-GASSL clusters the USNET with a gated recurrent unit (GRU)-based metric learning scheme and finds the HUAVs in each cluster with GASSL. Numerical results show that the GASSL can detect the HUAVs in single UAV clusters obeying various kinds of IFSs with over 98% average accuracy. The simulation results also show that the clustering purity of the USNET with MC-GASSL exceeds that with traditional clustering algorithms by at least 10% average. Furthermore, the MC-GASSL can efficiently detect all the HUAVs in USNETs with various IFSs and cluster numbers with low detection redundancies.