 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SleepPPG-Net: a deep learning algorithm for robust sleep staging from continuous photoplethysmography
Feb 11, 2022
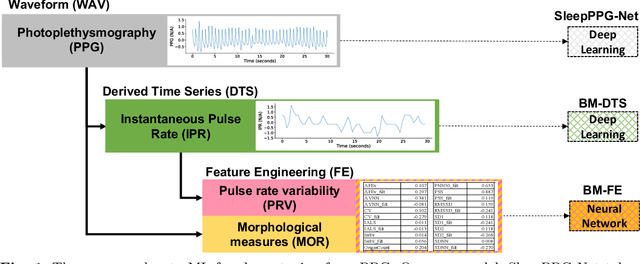
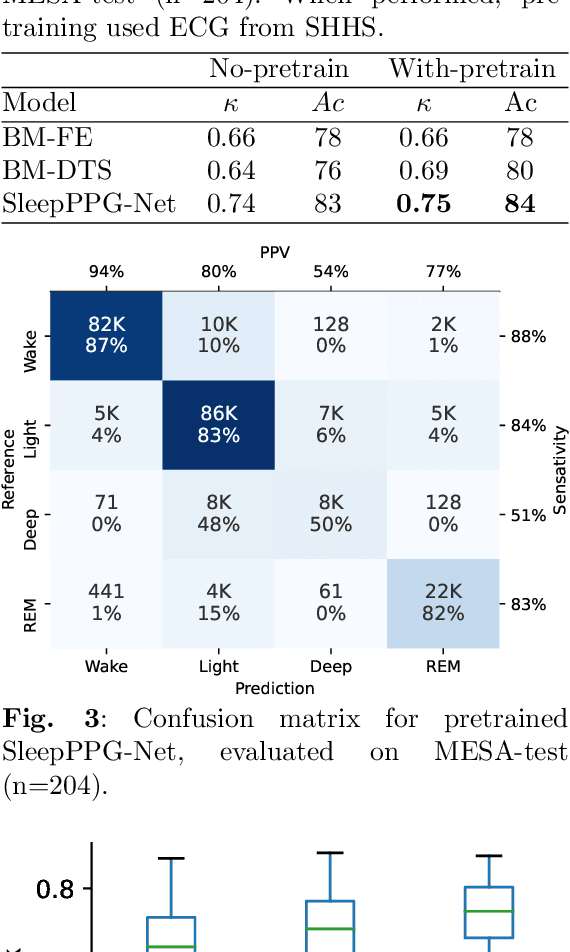
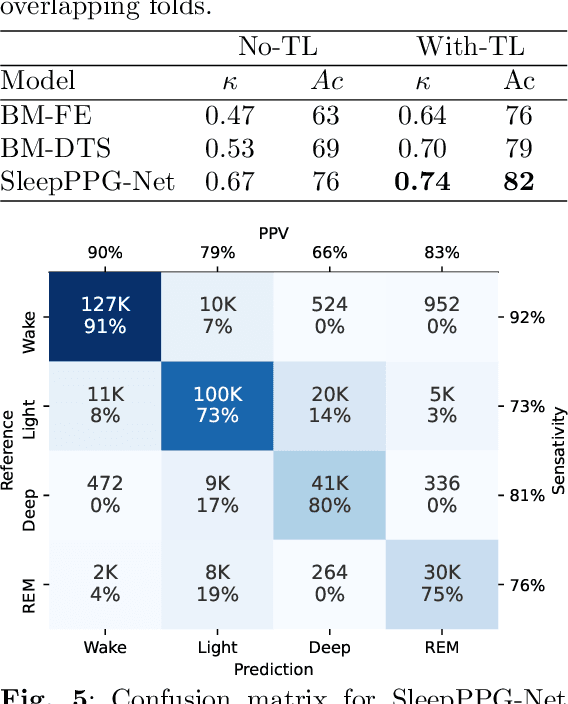
Introduction: Sleep staging is an essential component in the diagnosis of sleep disorders and management of sleep health. It is traditionally measured in a clinical setting and requires a labor-intensive labeling process. We hypothesize that it is possible to perform robust 4-class sleep staging using the raw photoplethysmography (PPG) time series and modern advances in deep learning (DL). Methods: We used two publicly available sleep databases that included raw PPG recordings, totalling 2,374 patients and 23,055 hours. We developed SleepPPG-Net, a DL model for 4-class sleep staging from the raw PPG time series. SleepPPG-Net was trained end-to-end and consists of a residual convolutional network for automatic feature extraction and a temporal convolutional network to capture long-range contextual information. We benchmarked the performance of SleepPPG-Net against models based on the best-reported state-of-the-art (SOTA) algorithms. Results: When benchmarked on a held-out test set, SleepPPG-Net obtained a median Cohen's Kappa ($\kappa$) score of 0.75 against 0.69 for the best SOTA approach. SleepPPG-Net showed good generalization performance to an external database, obtaining a $\kappa$ score of 0.74 after transfer learning. Perspective: Overall, SleepPPG-Net provides new SOTA performance. In addition, performance is high enough to open the path to the development of wearables that meet the requirements for usage in clinical applications such as the diagnosis and monitoring of obstructive sleep apnea.
Automated Discovery of Real-Time Network Camera Data From Heterogeneous Web Pages
Mar 23, 2021
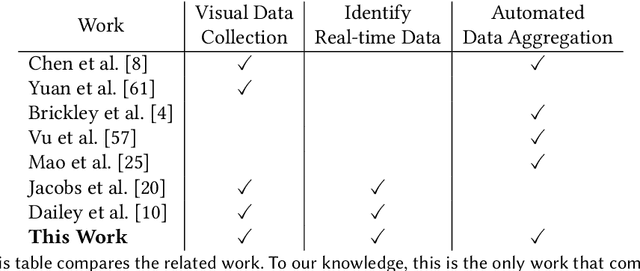


Reduction in the cost of Network Cameras along with a rise in connectivity enables entities all around the world to deploy vast arrays of camera networks. Network cameras offer real-time visual data that can be used for studying traffic patterns, emergency response, security, and other applications. Although many sources of Network Camera data are available, collecting the data remains difficult due to variations in programming interface and website structures. Previous solutions rely on manually parsing the target website, taking many hours to complete. We create a general and automated solution for aggregating Network Camera data spread across thousands of uniquely structured web pages. We analyze heterogeneous web page structures and identify common characteristics among 73 sample Network Camera websites (each website has multiple web pages). These characteristics are then used to build an automated camera discovery module that crawls and aggregates Network Camera data. Our system successfully extracts 57,364 Network Cameras from 237,257 unique web pages.
Suum Cuique: Studying Bias in Taboo Detection with a Community Perspective
Mar 22, 2022
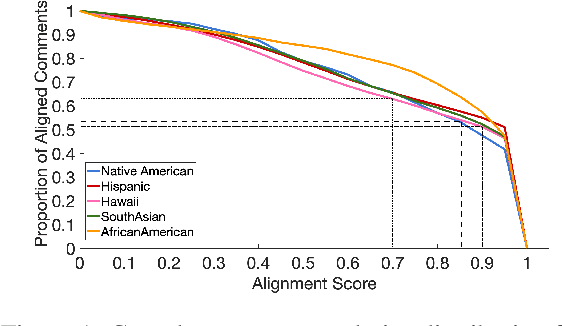
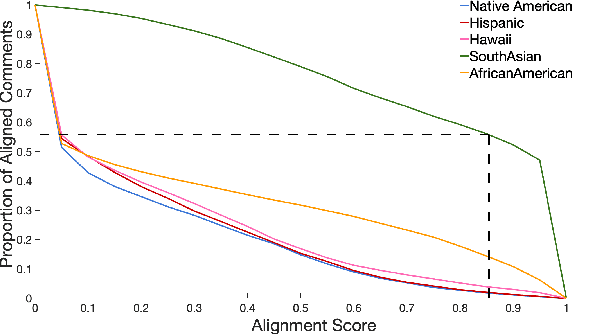
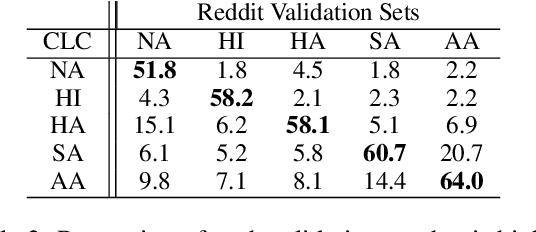
Prior research has discussed and illustrated the need to consider linguistic norms at the community level when studying taboo (hateful/offensive/toxic etc.) language. However, a methodology for doing so, that is firmly founded on community language norms is still largely absent. This can lead both to biases in taboo text classification and limitations in our understanding of the causes of bias. We propose a method to study bias in taboo classification and annotation where a community perspective is front and center. This is accomplished by using special classifiers tuned for each community's language. In essence, these classifiers represent community level language norms. We use these to study bias and find, for example, biases are largest against African Americans (7/10 datasets and all 3 classifiers examined). In contrast to previous papers we also study other communities and find, for example, strong biases against South Asians. In a small scale user study we illustrate our key idea which is that common utterances, i.e., those with high alignment scores with a community (community classifier confidence scores) are unlikely to be regarded taboo. Annotators who are community members contradict taboo classification decisions and annotations in a majority of instances. This paper is a significant step toward reducing false positive taboo decisions that over time harm minority communities.
QuickBrowser: A Unified Model to Detect and Read Simple Object in Real-time
Feb 15, 2021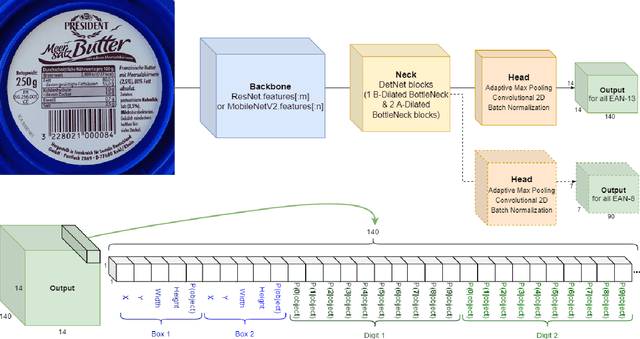
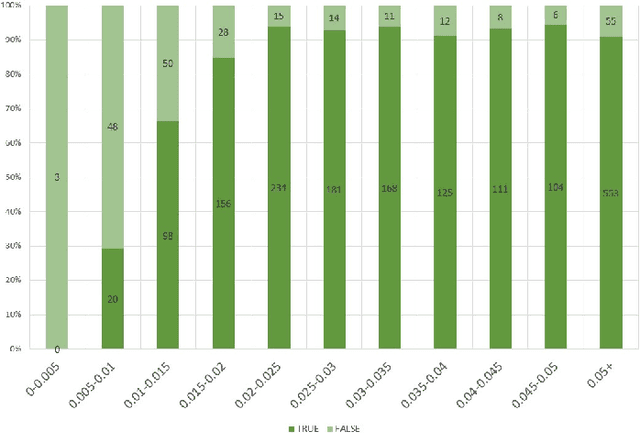
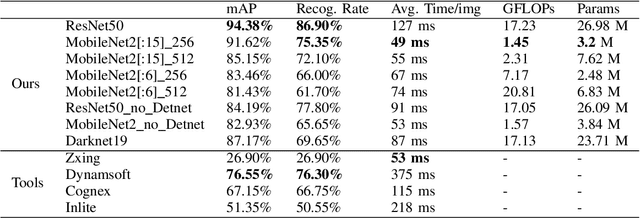

There are many real-life use cases such as barcode scanning or billboard reading where people need to detect objects and read the object contents. Commonly existing methods are first trying to localize object regions, then determine layout and lastly classify content units. However, for simple fixed structured objects like license plates, this approach becomes overkill and lengthy to run. This work aims to solve this detect-and-read problem in a lightweight way by integrating multi-digit recognition into a one-stage object detection model. Our unified method not only eliminates the duplication in feature extraction (one for localizing, one again for classifying) but also provides useful contextual information around object regions for classification. Additionally, our choice of backbones and modifications in architecture, loss function, data augmentation and training make the method robust, efficient and speedy. Secondly, we made a public benchmark dataset of diverse real-life 1D barcodes for a reliable evaluation, which we collected, annotated and checked carefully. Eventually, experimental results prove the method's efficiency on the barcode problem by outperforming industrial tools in both detecting and decoding rates with a real-time fps at a VGA-similar resolution. It also did a great job expectedly on the license-plate recognition task (on the AOLP dataset) by outperforming the current state-of-the-art method significantly in terms of recognition rate and inference time.
Occupancy Map Prediction for Improved Indoor Robot Navigation
Mar 08, 2022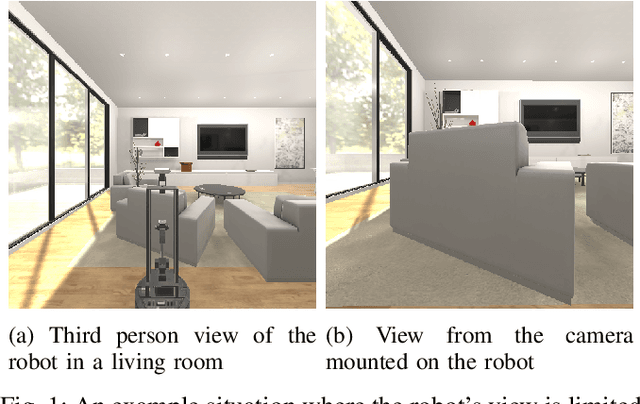
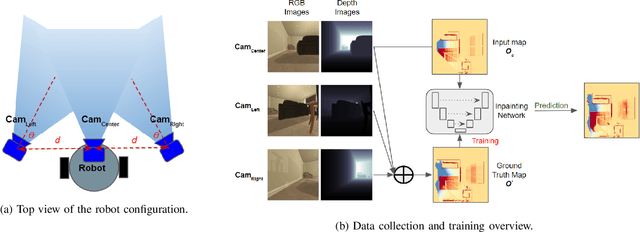
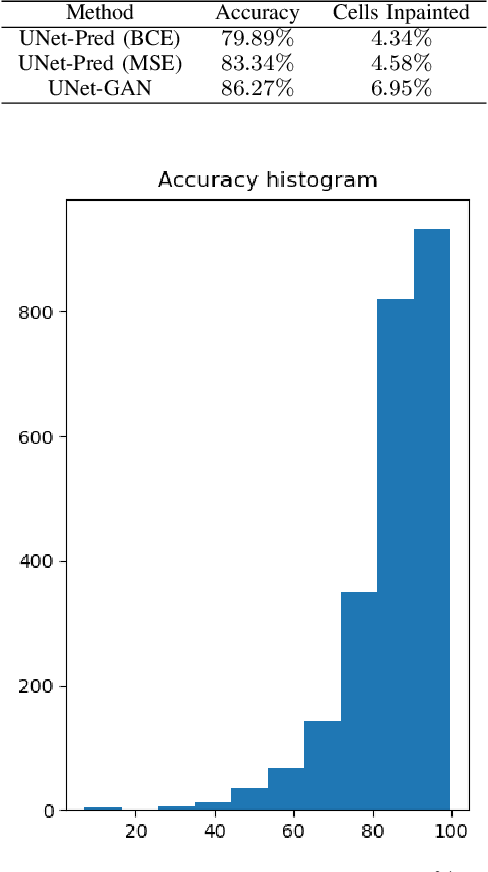
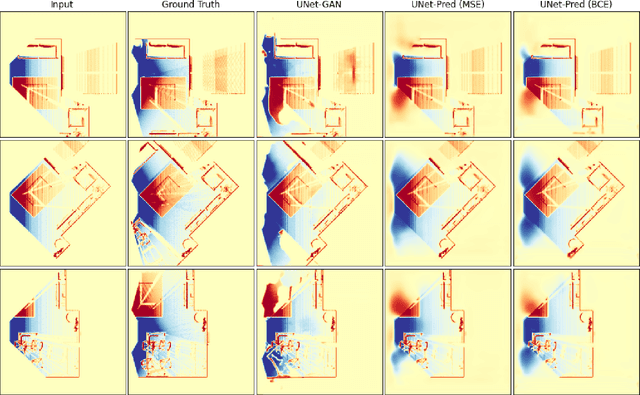
In the typical path planning pipeline for a ground robot, we build a map (e.g., an occupancy grid) of the environment as the robot moves around. While navigating indoors, a ground robot's knowledge about the environment may be limited by the occlusions in its surroundings. Therefore, the map will have many as-yet-unknown regions that may need to be avoided by a conservative planner. Instead, if a robot is able to correctly infer what its surroundings and occluded regions look like, the navigation can be further optimized. In this work, we propose an approach using pix2pix and UNet to infer the occupancy grid in unseen areas near the robot as an image-to-image translation task. Our approach simplifies the task of occupancy map prediction for the deep learning network and reduces the amount of data required compared to similar existing methods. We show that the predicted map improves the navigation time in simulations over the existing approaches.
The Analysis of Online Event Streams: Predicting the Next Activity for Anomaly Detection
Mar 17, 2022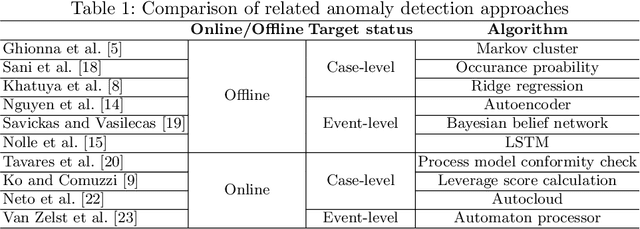
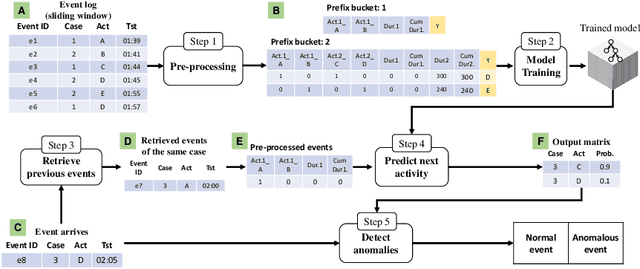
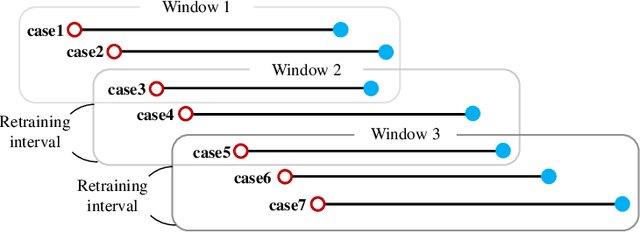
Anomaly detection in process mining focuses on identifying anomalous cases or events in process executions. The resulting diagnostics are used to provide measures to prevent fraudulent behavior, as well as to derive recommendations for improving process compliance and security. Most existing techniques focus on detecting anomalous cases in an offline setting. However, to identify potential anomalies in a timely manner and take immediate countermeasures, it is necessary to detect event-level anomalies online, in real-time. In this paper, we propose to tackle the online event anomaly detection problem using next-activity prediction methods. More specifically, we investigate the use of both ML models (such as RF and XGBoost) and deep models (such as LSTM) to predict the probabilities of next-activities and consider the events predicted unlikely as anomalies. We compare these predictive anomaly detection methods to four classical unsupervised anomaly detection approaches (such as Isolation forest and LOF) in the online setting. Our evaluation shows that the proposed method using ML models tends to outperform the one using a deep model, while both methods outperform the classical unsupervised approaches in detecting anomalous events.
A Physics-Informed Neural Network Framework For Partial Differential Equations on 3D Surfaces: Time-Dependent Problems
Mar 19, 2021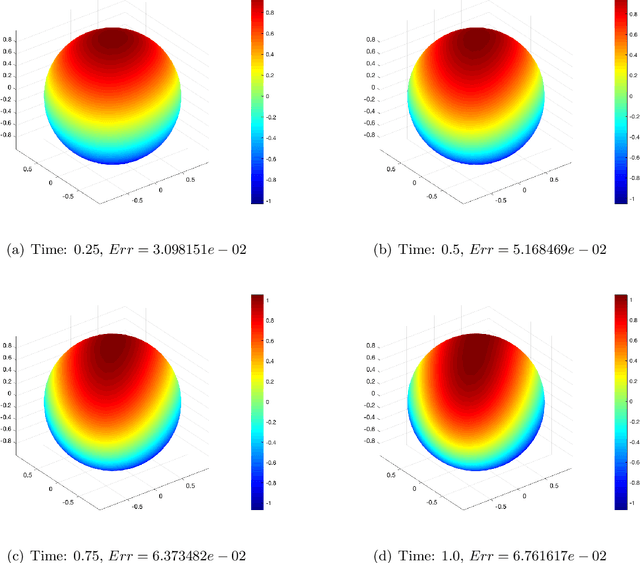
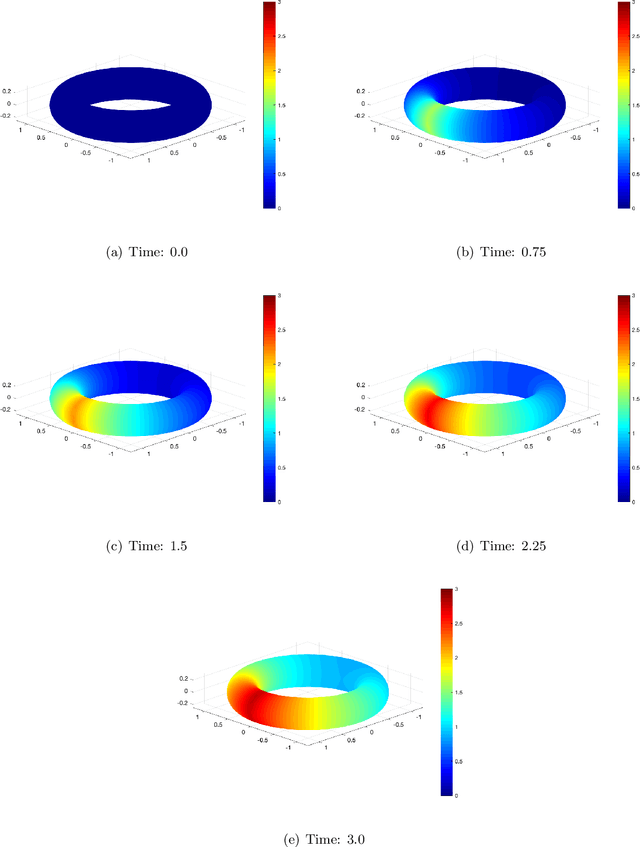
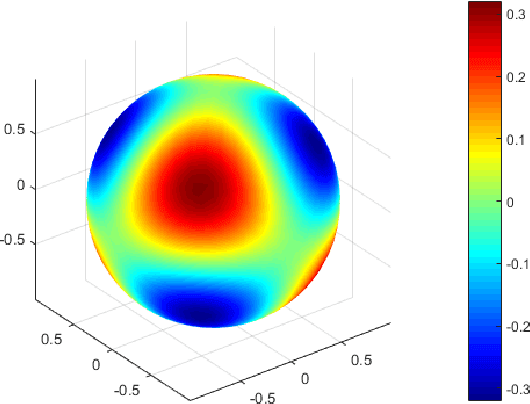
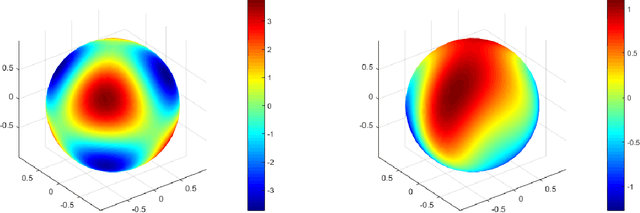
In this paper, we show a physics-informed neural network solver for the time-dependent surface PDEs. Unlike the traditional numerical solver, no extension of PDE and mesh on the surface is needed. We show a simplified prior estimate of the surface differential operators so that PINN's loss value will be an indicator of the residue of the surface PDEs. Numerical experiments verify efficacy of our algorithm.
Gym-$μ$RTS: Toward Affordable Full Game Real-time Strategy Games Research with Deep Reinforcement Learning
May 21, 2021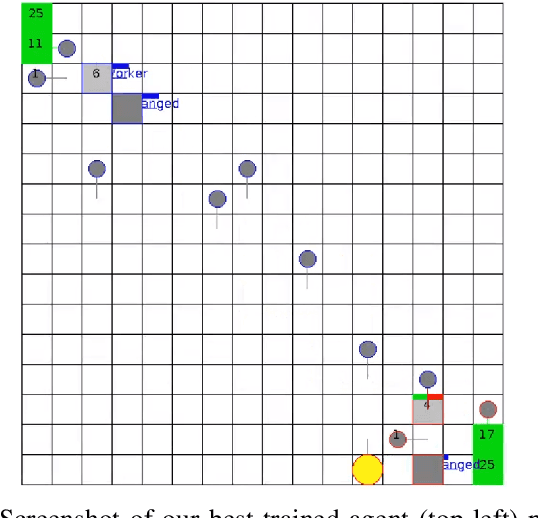
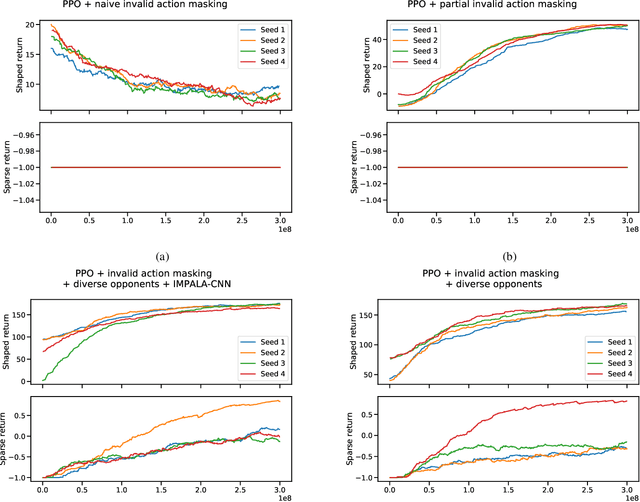
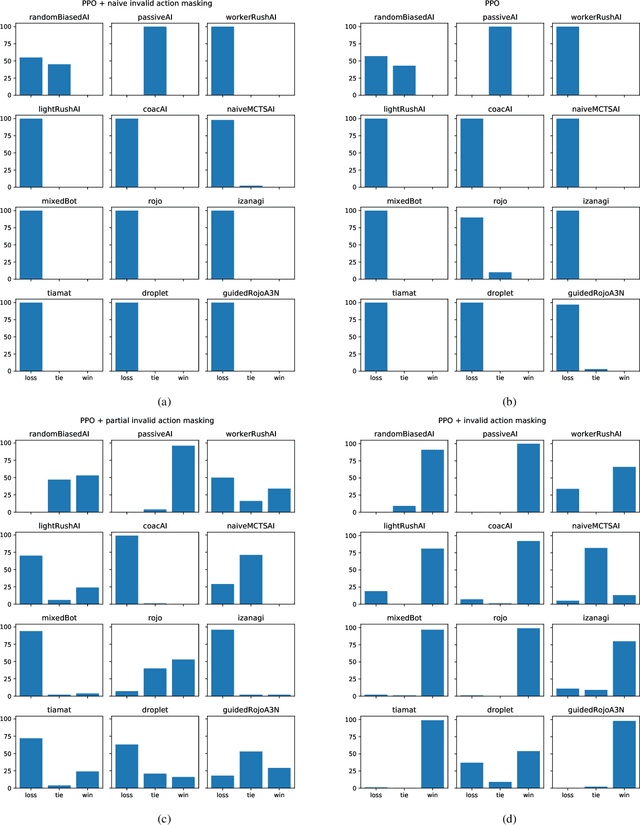
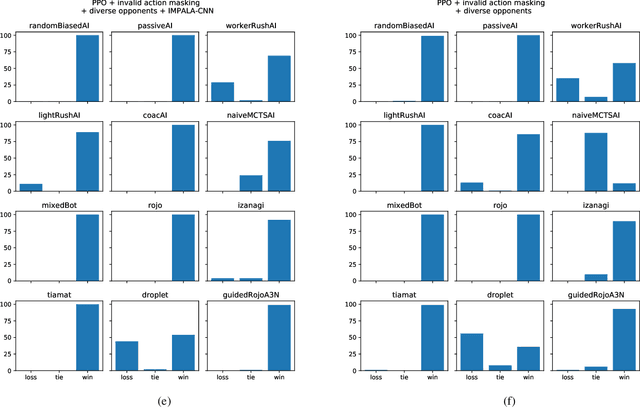
In recent years, researchers have achieved great success in applying Deep Reinforcement Learning (DRL) algorithms to Real-time Strategy (RTS) games, creating strong autonomous agents that could defeat professional players in StarCraft~II. However, existing approaches to tackle full games have high computational costs, usually requiring the use of thousands of GPUs and CPUs for weeks. This paper has two main contributions to address this issue: 1) We introduce Gym-$\mu$RTS (pronounced "gym-micro-RTS") as a fast-to-run RL environment for full-game RTS research and 2) we present a collection of techniques to scale DRL to play full-game $\mu$RTS as well as ablation studies to demonstrate their empirical importance. Our best-trained bot can defeat every $\mu$RTS bot we tested from the past $\mu$RTS competitions when working in a single-map setting, resulting in a state-of-the-art DRL agent while only taking about 60 hours of training using a single machine (one GPU, three vCPU, 16GB RAM).
Mutual information neural estimation for unsupervised multi-modal registration of brain images
Jan 25, 2022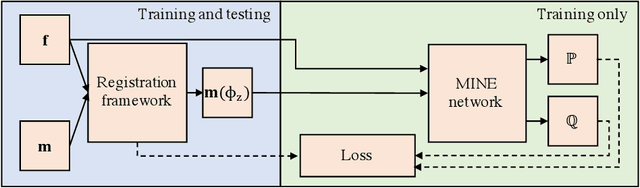
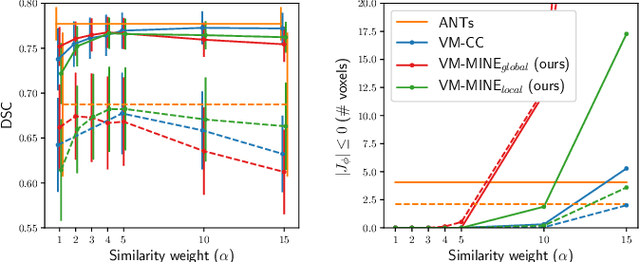
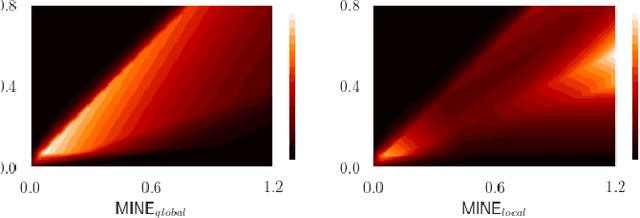
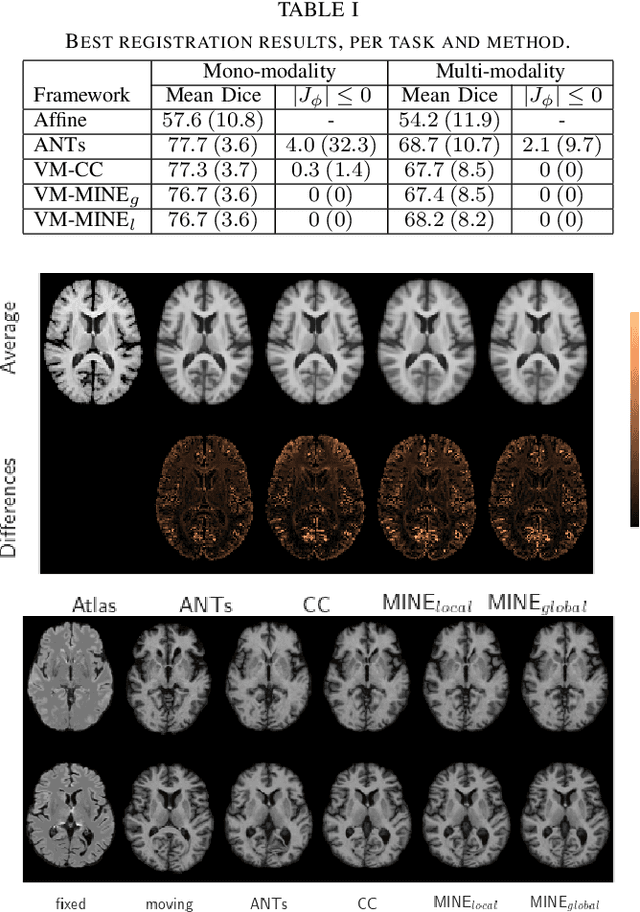
Many applications in image-guided surgery and therapy require fast and reliable non-linear, multi-modal image registration. Recently proposed unsupervised deep learning-based registration methods have demonstrated superior performance compared to iterative methods in just a fraction of the time. Most of the learning-based methods have focused on mono-modal image registration. The extension to multi-modal registration depends on the use of an appropriate similarity function, such as the mutual information (MI). We propose guiding the training of a deep learning-based registration method with MI estimation between an image-pair in an end-to-end trainable network. Our results show that a small, 2-layer network produces competitive results in both mono- and multimodal registration, with sub-second run-times. Comparisons to both iterative and deep learning-based methods show that our MI-based method produces topologically and qualitatively superior results with an extremely low rate of non-diffeomorphic transformations. Real-time clinical application will benefit from a better visual matching of anatomical structures and less registration failures/outliers.
Similarity learning for wells based on logging data
Feb 11, 2022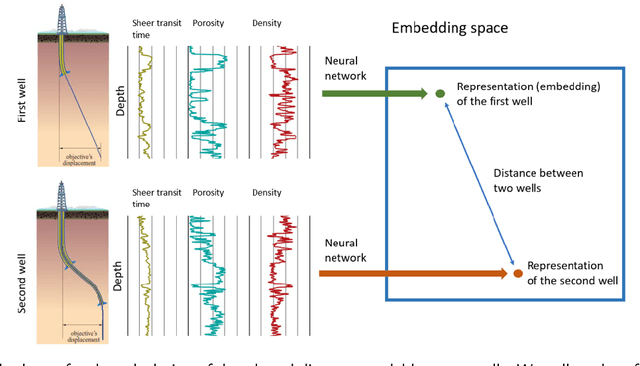


One of the first steps during the investigation of geological objects is the interwell correlation. It provides information on the structure of the objects under study, as it comprises the framework for constructing geological models and assessing hydrocarbon reserves. Today, the detailed interwell correlation relies on manual analysis of well-logging data. Thus, it is time-consuming and of a subjective nature. The essence of the interwell correlation constitutes an assessment of the similarities between geological profiles. There were many attempts to automate the process of interwell correlation by means of rule-based approaches, classic machine learning approaches, and deep learning approaches in the past. However, most approaches are of limited usage and inherent subjectivity of experts. We propose a novel framework to solve the geological profile similarity estimation based on a deep learning model. Our similarity model takes well-logging data as input and provides the similarity of wells as output. The developed framework enables (1) extracting patterns and essential characteristics of geological profiles within the wells and (2) model training following the unsupervised paradigm without the need for manual analysis and interpretation of well-logging data. For model testing, we used two open datasets originating in New Zealand and Norway. Our data-based similarity models provide high performance: the accuracy of our model is $0.926$ compared to $0.787$ for baselines based on the popular gradient boosting approach. With them, an oil\&gas practitioner can improve interwell correlation quality and reduce operation time.