 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWWAggr: A Window Wasserstein-based Aggregation for Ensemble Change Point Detection
Jun 09, 2025



Change Point Detection (CPD) aims to identify moments of abrupt distribution shifts in data streams. Real-world high-dimensional CPD remains challenging due to data pattern complexity and violation of common assumptions. Resorting to standalone deep neural networks, the current state-of-the-art detectors have yet to achieve perfect quality. Concurrently, ensembling provides more robust solutions, boosting the performance. In this paper, we investigate ensembles of deep change point detectors and realize that standard prediction aggregation techniques, e.g., averaging, are suboptimal and fail to account for problem peculiarities. Alternatively, we introduce WWAggr -- a novel task-specific method of ensemble aggregation based on the Wasserstein distance. Our procedure is versatile, working effectively with various ensembles of deep CPD models. Moreover, unlike existing solutions, we practically lift a long-standing problem of the decision threshold selection for CPD.
Normalizing self-supervised learning for provably reliable Change Point Detection
Oct 17, 2024



Change point detection (CPD) methods aim to identify abrupt shifts in the distribution of input data streams. Accurate estimators for this task are crucial across various real-world scenarios. Yet, traditional unsupervised CPD techniques face significant limitations, often relying on strong assumptions or suffering from low expressive power due to inherent model simplicity. In contrast, representation learning methods overcome these drawbacks by offering flexibility and the ability to capture the full complexity of the data without imposing restrictive assumptions. However, these approaches are still emerging in the CPD field and lack robust theoretical foundations to ensure their reliability. Our work addresses this gap by integrating the expressive power of representation learning with the groundedness of traditional CPD techniques. We adopt spectral normalization (SN) for deep representation learning in CPD tasks and prove that the embeddings after SN are highly informative for CPD. Our method significantly outperforms current state-of-the-art methods during the comprehensive evaluation via three standard CPD datasets.
COTODE: COntinuous Trajectory neural Ordinary Differential Equations for modelling event sequences
Aug 15, 2024Observation of the underlying actors that generate event sequences reveals that they often evolve continuously. Most modern methods, however, tend to model such processes through at most piecewise-continuous trajectories. To address this, we adopt a way of viewing events not as standalone phenomena but instead as observations of a Gaussian Process, which in turn governs the actor's dynamics. We propose integrating these obtained dynamics, resulting in a continuous-trajectory modification of the widely successful Neural ODE model. Through Gaussian Process theory, we were able to evaluate the uncertainty in an actor's representation, which arises from not observing them between events. This estimate led us to develop a novel, theoretically backed negative feedback mechanism. Empirical studies indicate that our model with Gaussian process interpolation and negative feedback achieves state-of-the-art performance, with improvements up to 20% AUROC against similar architectures.
Universal representations for financial transactional data: embracing local, global, and external contexts
Apr 02, 2024



Effective processing of financial transactions is essential for banking data analysis. However, in this domain, most methods focus on specialized solutions to stand-alone problems instead of constructing universal representations suitable for many problems. We present a representation learning framework that addresses diverse business challenges. We also suggest novel generative models that account for data specifics, and a way to integrate external information into a client's representation, leveraging insights from other customers' actions. Finally, we offer a benchmark, describing representation quality globally, concerning the entire transaction history; locally, reflecting the client's current state; and dynamically, capturing representation evolution over time. Our generative approach demonstrates superior performance in local tasks, with an increase in ROC-AUC of up to 14\% for the next MCC prediction task and up to 46\% for downstream tasks from existing contrastive baselines. Incorporating external information improves the scores by an additional 20\%.
Usage of specific attention improves change point detection
Apr 18, 2022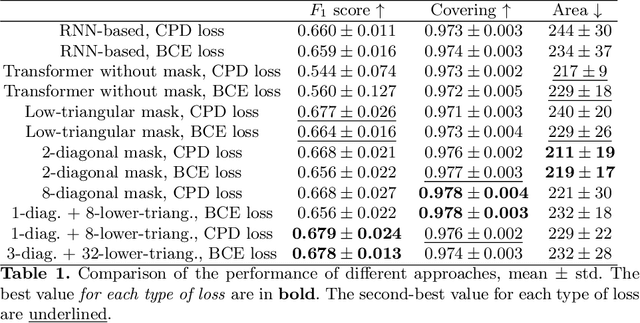
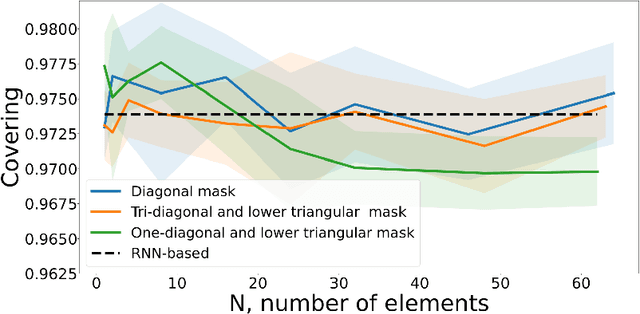
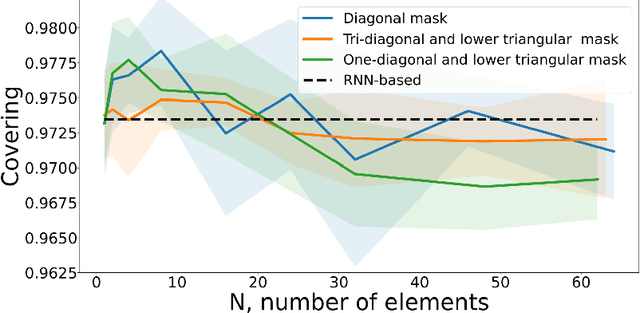
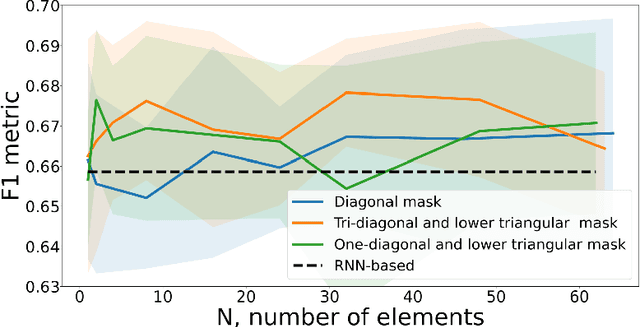
The change point is a moment of an abrupt alteration in the data distribution. Current methods for change point detection are based on recurrent neural methods suitable for sequential data. However, recent works show that transformers based on attention mechanisms perform better than standard recurrent models for many tasks. The most benefit is noticeable in the case of longer sequences. In this paper, we investigate different attentions for the change point detection task and proposed specific form of attention related to the task at hand. We show that using a special form of attention outperforms state-of-the-art results.
Deep learning model solves change point detection for multiple change types
Apr 15, 2022
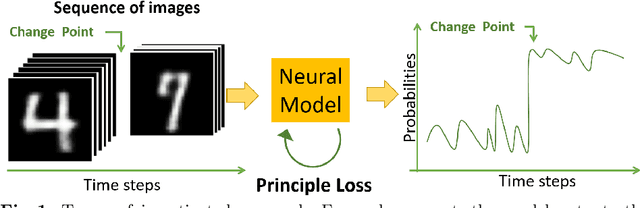

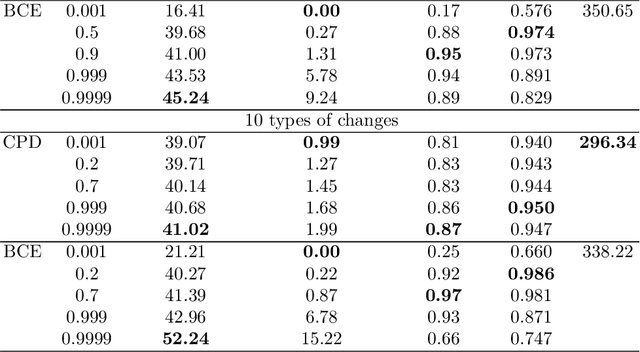
A change points detection aims to catch an abrupt disorder in data distribution. Common approaches assume that there are only two fixed distributions for data: one before and another after a change point. Real-world data are richer than this assumption. There can be multiple different distributions before and after a change. We propose an approach that works in the multiple-distributions scenario. Our approach learn representations for semi-structured data suitable for change point detection, while a common classifiers-based approach fails. Moreover, our model is more robust, when predicting change points. The datasets used for benchmarking are sequences of images with and without change points in them.
Similarity learning for wells based on logging data
Feb 11, 2022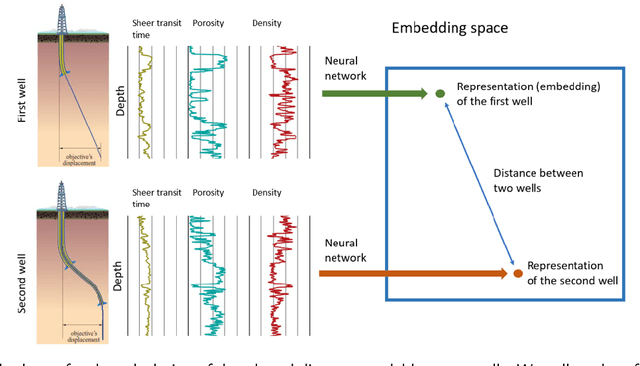


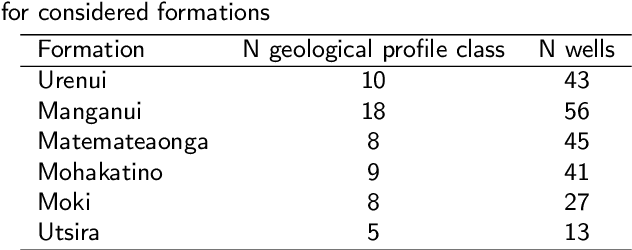
One of the first steps during the investigation of geological objects is the interwell correlation. It provides information on the structure of the objects under study, as it comprises the framework for constructing geological models and assessing hydrocarbon reserves. Today, the detailed interwell correlation relies on manual analysis of well-logging data. Thus, it is time-consuming and of a subjective nature. The essence of the interwell correlation constitutes an assessment of the similarities between geological profiles. There were many attempts to automate the process of interwell correlation by means of rule-based approaches, classic machine learning approaches, and deep learning approaches in the past. However, most approaches are of limited usage and inherent subjectivity of experts. We propose a novel framework to solve the geological profile similarity estimation based on a deep learning model. Our similarity model takes well-logging data as input and provides the similarity of wells as output. The developed framework enables (1) extracting patterns and essential characteristics of geological profiles within the wells and (2) model training following the unsupervised paradigm without the need for manual analysis and interpretation of well-logging data. For model testing, we used two open datasets originating in New Zealand and Norway. Our data-based similarity models provide high performance: the accuracy of our model is $0.926$ compared to $0.787$ for baselines based on the popular gradient boosting approach. With them, an oil\&gas practitioner can improve interwell correlation quality and reduce operation time.
Principled change point detection via representation learning
Jun 04, 2021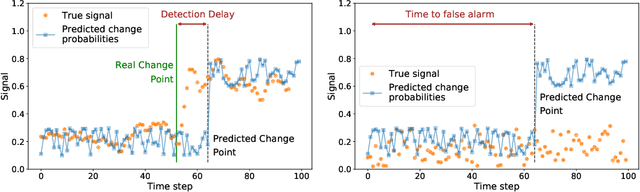
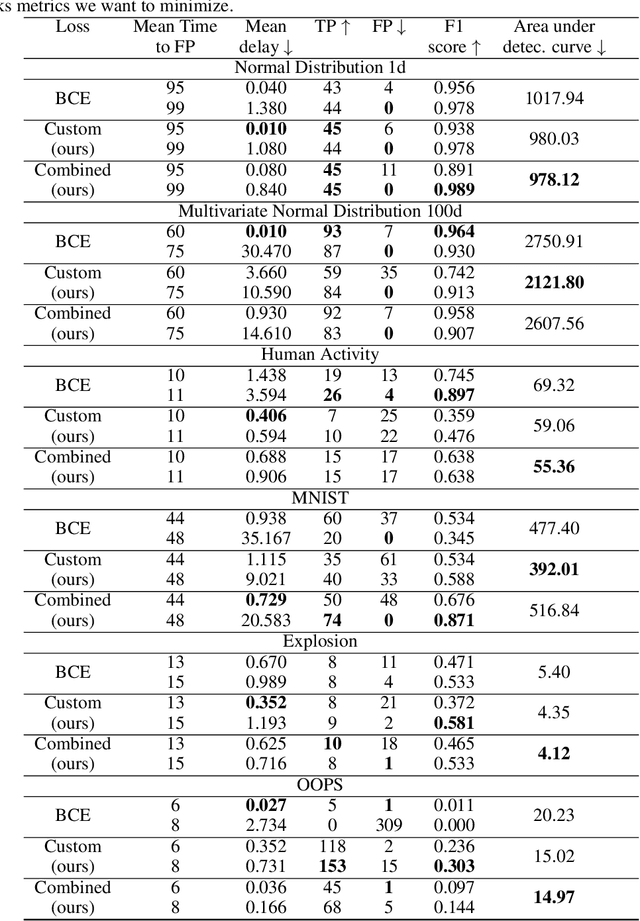
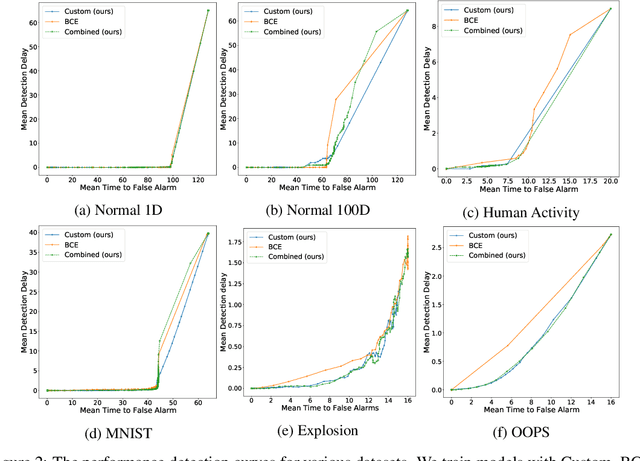
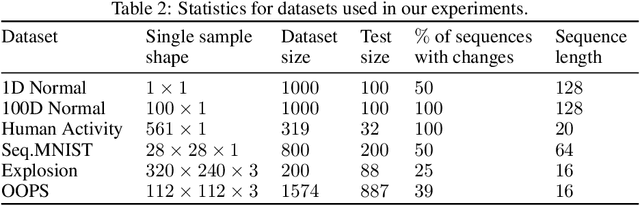
Change points are abrupt alterations in the distribution of sequential data. A change-point detection (CPD) model aims at quick detection of such changes. Classic approaches perform poorly for semi-structured sequential data because of the absence of adequate data representation learning. To deal with it, we introduce a principled differentiable loss function that considers the specificity of the CPD task. The theoretical results suggest that this function approximates well classic rigorous solutions. For such loss function, we propose an end-to-end method for the training of deep representation learning CPD models. Our experiments provide evidence that the proposed approach improves baseline results of change point detection for various data types, including real-world videos and image sequences, and improve representations for them.