 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PAC Model Checking of Black-Box Continuous-Time Dynamical Systems
Jul 17, 2020
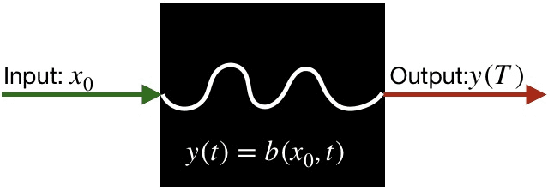
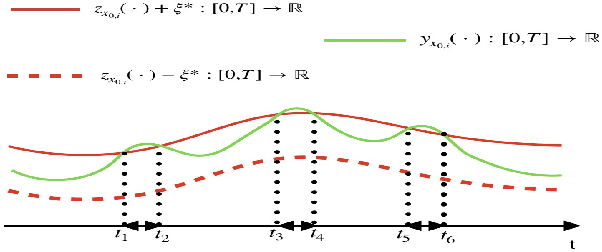
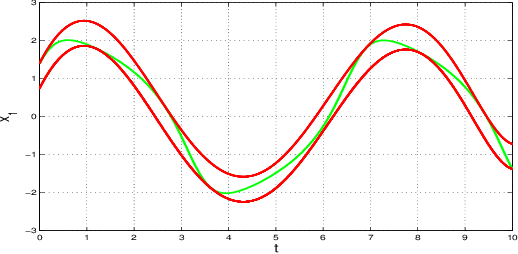
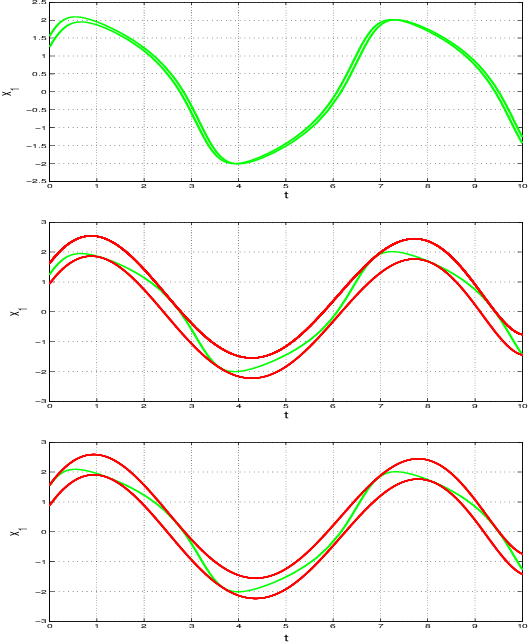
In this paper we present a novel model checking approach to finite-time safety verification of black-box continuous-time dynamical systems within the framework of probably approximately correct (PAC) learning. The black-box dynamical systems are the ones, for which no model is given but whose states changing continuously through time within a finite time interval can be observed at some discrete time instants for a given input. The new model checking approach is termed as PAC model checking due to incorporation of learned models with correctness guarantees expressed using the terms error probability and confidence. Based on the error probability and confidence level, our approach provides statistically formal guarantees that the time-evolving trajectories of the black-box dynamical system over finite time horizons fall within the range of the learned model plus a bounded interval, contributing to insights on the reachability of the black-box system and thus on the satisfiability of its safety requirements. The learned model together with the bounded interval is obtained by scenario optimization, which boils down to a linear programming problem. Three examples demonstrate the performance of our approach.
Time-Variant Variational Transfer for Value Functions
May 26, 2020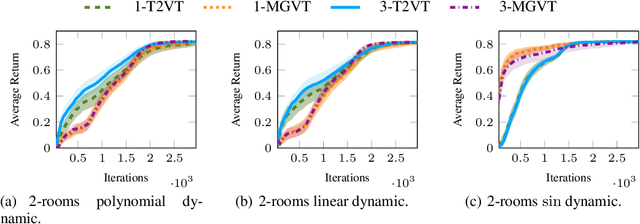
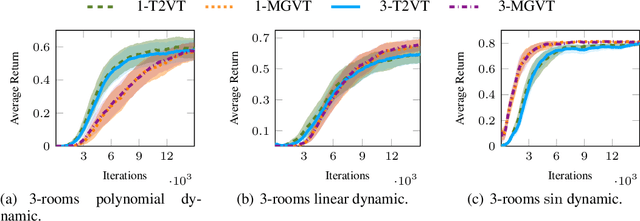
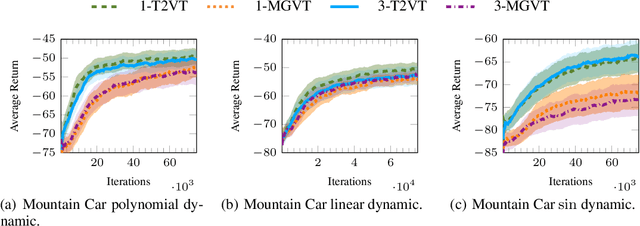
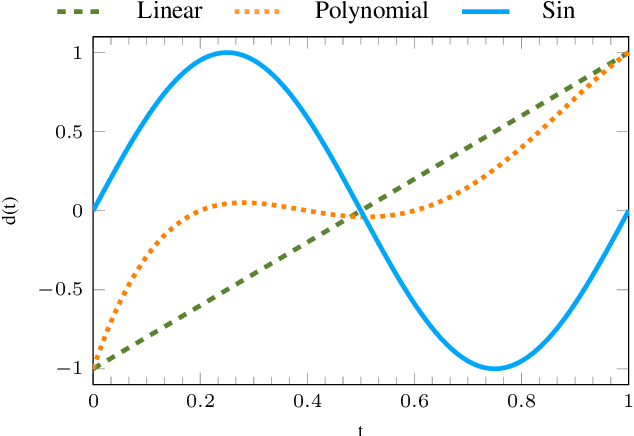
In most transfer learning approaches to reinforcement learning (RL) the distribution over the tasks is assumed to be stationary. Therefore, the target and source tasks are i.i.d. samples of the same distribution. In the context of this work, we will consider the problem of transferring value functions through a variational method when the distribution generating the tasks is time-variant, proposing a solution leveraging this temporal structure inherent to the task generating process. Moreover, by means of a finite sample analysis, the previously mentioned solution will be theoretically compared to its time-invariant version. Finally, we will provide an experimental evaluation of the proposed technique with three distinct time dynamics in three different RL environments.
AI Gone Astray: Technical Supplement
Mar 01, 2022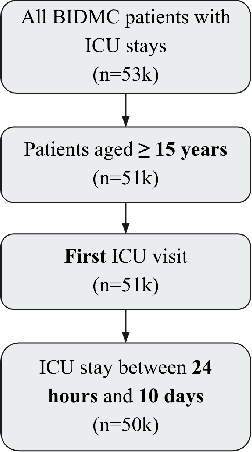
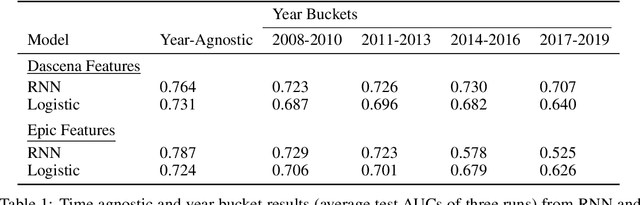
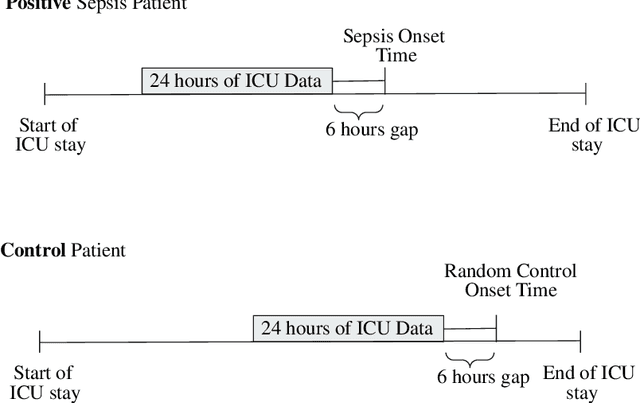
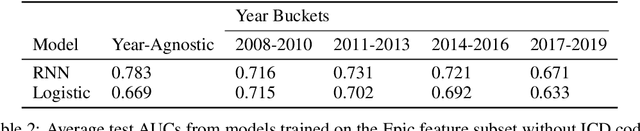
This study is a technical supplement to "AI gone astray: How subtle shifts in patient data send popular algorithms reeling, undermining patient safety." from STAT News, which investigates the effect of time drift on clinically deployed machine learning models. We use MIMIC-IV, a publicly available dataset, to train models that replicate commercial approaches by Dascena and Epic to predict the onset of sepsis, a deadly and yet treatable condition. We observe some of these models degrade overtime; most notably an RNN built on Epic features degrades from a 0.729 AUC to a 0.525 AUC over a decade, leading us to investigate technical and clinical drift as root causes of this performance drop.
MINIROCKET: A Very Fast (Almost) Deterministic Transform for Time Series Classification
Dec 16, 2020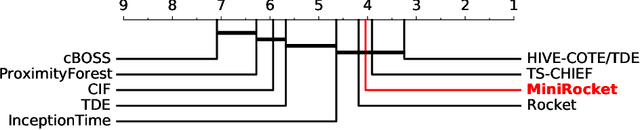

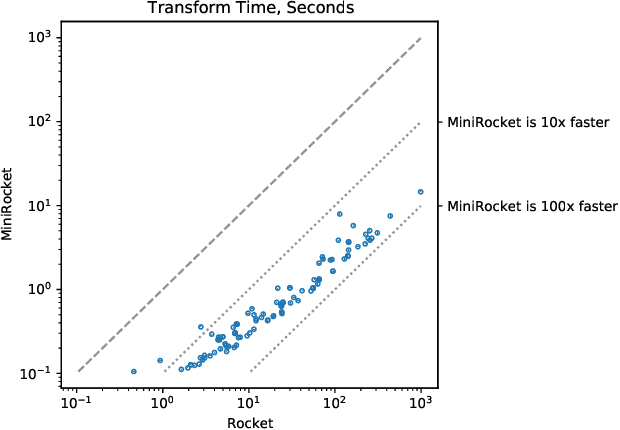
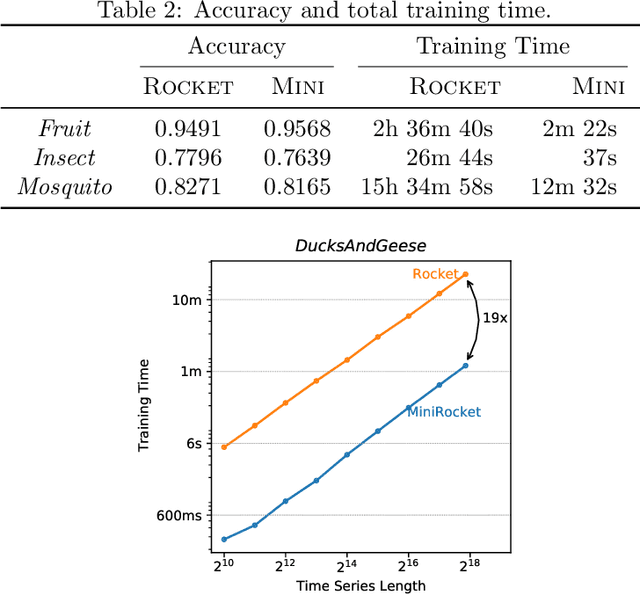
Until recently, the most accurate methods for time series classification were limited by high computational complexity. ROCKET achieves state-of-the-art accuracy with a fraction of the computational expense of most existing methods by transforming input time series using random convolutional kernels, and using the transformed features to train a linear classifier. We reformulate ROCKET into a new method, MINIROCKET, making it up to 75 times faster on larger datasets, and making it almost deterministic (and optionally, with additional computational expense, fully deterministic), while maintaining essentially the same accuracy. Using this method, it is possible to train and test a classifier on all of 109 datasets from the UCR archive to state-of-the-art accuracy in less than 10 minutes. MINIROCKET is significantly faster than any other method of comparable accuracy (including ROCKET), and significantly more accurate than any other method of even roughly-similar computational expense. As such, we suggest that MINIROCKET should now be considered and used as the default variant of ROCKET.
AI-augmented histopathologic review using image analysis to optimize DNA yield and tumor purity from FFPE slides
Apr 07, 2022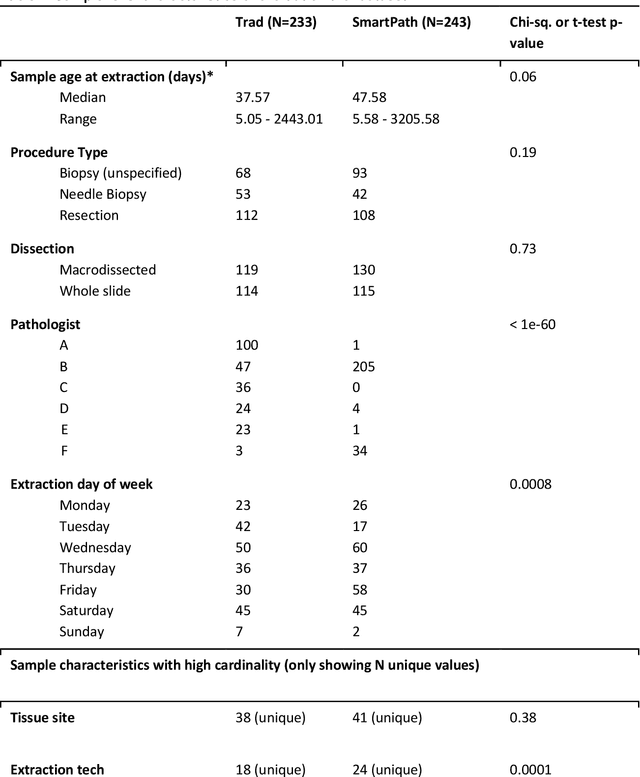
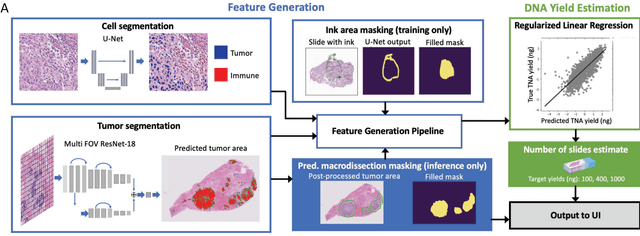
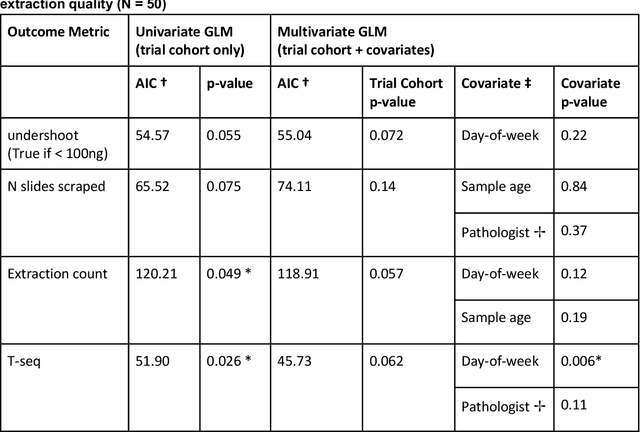
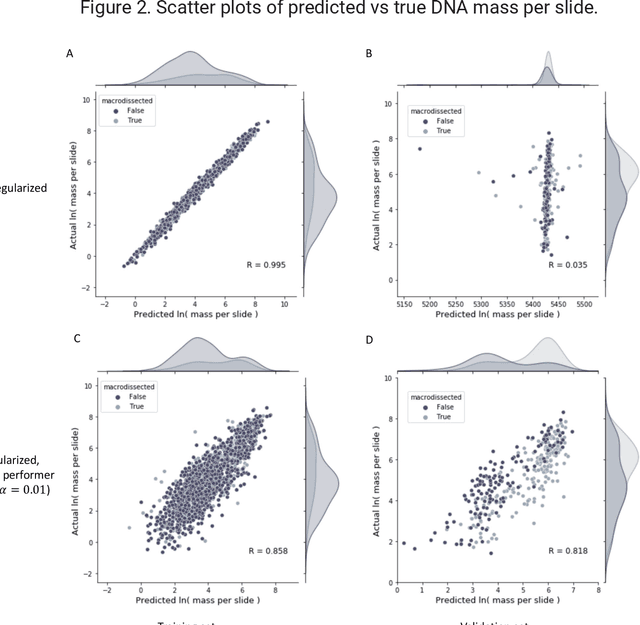
To achieve minimum DNA input and tumor purity requirements for next-generation sequencing (NGS), pathologists visually estimate macrodissection and slide count decisions. Misestimation may cause tissue waste and increased laboratory costs. We developed an AI-augmented smart pathology review system (SmartPath) to empower pathologists with quantitative metrics for determining tissue extraction parameters. Using digitized H&E-stained FFPE slides as inputs, SmartPath segments tumors, extracts cell-based features, and suggests macrodissection areas. To predict DNA yield per slide, the extracted features are correlated with known DNA yields. Then, a pathologist-defined target yield divided by the predicted DNA yield/slide gives the number of slides to scrape. Following model development, an internal validation trial was conducted within the Tempus Labs molecular sequencing laboratory. We evaluated our system on 501 clinical colorectal cancer slides, where half received SmartPath-augmented review and half traditional pathologist review. The SmartPath cohort had 25% more DNA yields within a desired target range of 100-2000ng. The SmartPath system recommended fewer slides to scrape for large tissue sections, saving tissue in these cases. Conversely, SmartPath recommended more slides to scrape for samples with scant tissue sections, helping prevent costly re-extraction due to insufficient extraction yield. A statistical analysis was performed to measure the impact of covariates on the results, offering insights on how to improve future applications of SmartPath. Overall, the study demonstrated that AI-augmented histopathologic review using SmartPath could decrease tissue waste, sequencing time, and laboratory costs by optimizing DNA yields and tumor purity.
A Multi-task Joint Framework for Real-time Person Search
Dec 11, 2020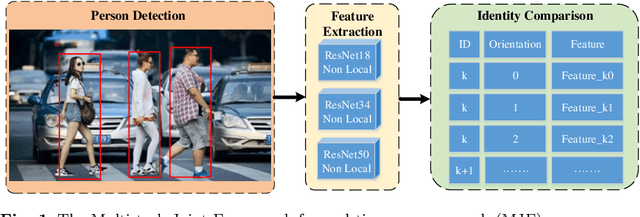
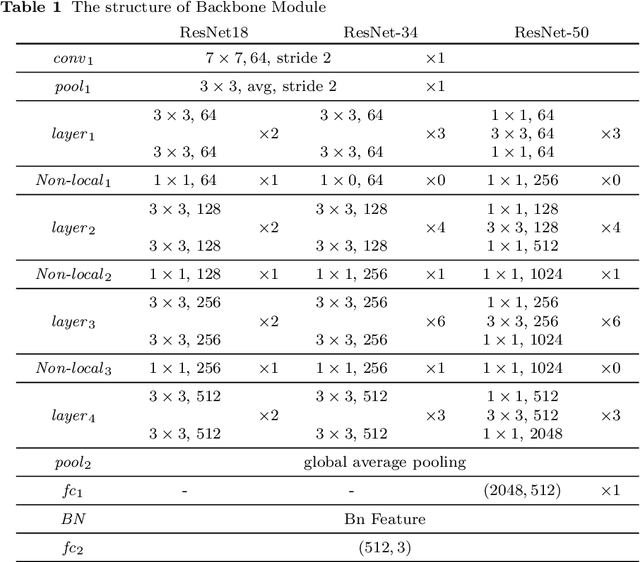
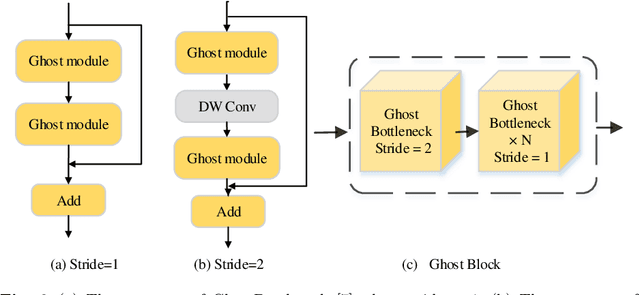

Person search generally involves three important parts: person detection, feature extraction and identity comparison. However, person search integrating detection, extraction and comparison has the following drawbacks. Firstly, the accuracy of detection will affect the accuracy of comparison. Secondly, it is difficult to achieve real-time in real-world applications. To solve these problems, we propose a Multi-task Joint Framework for real-time person search (MJF), which optimizes the person detection, feature extraction and identity comparison respectively. For the person detection module, we proposed the YOLOv5-GS model, which is trained with person dataset. It combines the advantages of the Ghostnet and the Squeeze-and-Excitation (SE) block, and improves the speed and accuracy. For the feature extraction module, we design the Model Adaptation Architecture (MAA), which could select different network according to the number of people. It could balance the relationship between accuracy and speed. For identity comparison, we propose a Three Dimension (3D) Pooled Table and a matching strategy to improve identification accuracy. On the condition of 1920*1080 resolution video and 500 IDs table, the identification rate (IR) and frames per second (FPS) achieved by our method could reach 93.6% and 25.7,
Time-aware Large Kernel Convolutions
Feb 08, 2020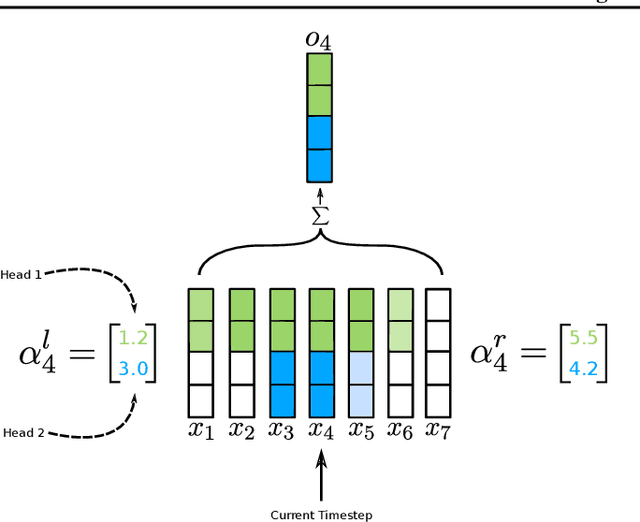

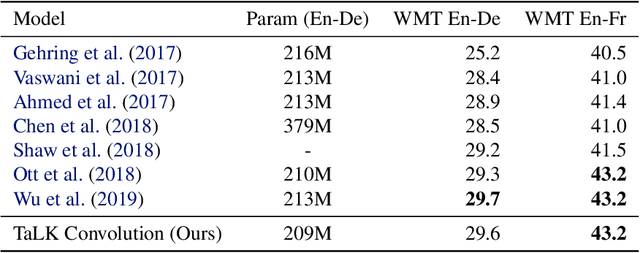
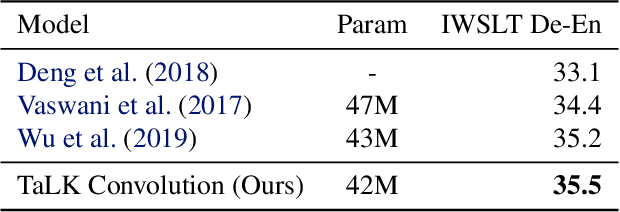
To date, most state-of-the-art sequence modelling architectures use attention to build generative models for language based tasks. Some of these models use all the available sequence tokens to generate an attention distribution which results in time complexity of $O(n^2)$. Alternatively, they utilize depthwise convolutions with softmax normalized kernels of size $k$ acting as a limited-window self-attention, resulting in time complexity of $O(k{\cdot}n)$. In this paper, we introduce Time-aware Large Kernel (TaLK) Convolutions, a novel adaptive convolution operation that learns to predict the size of a summation kernel instead of using the fixed-sized kernel matrix. This method yields a time complexity of $O(n)$, effectively making the sequence encoding process linear to the number of tokens. We evaluate the proposed method on large-scale standard machine translation and language modelling datasets and show that TaLK Convolutions constitute an efficient improvement over other attention/convolution based approaches.
Visual-Tactile Multimodality for Following Deformable Linear Objects Using Reinforcement Learning
Mar 31, 2022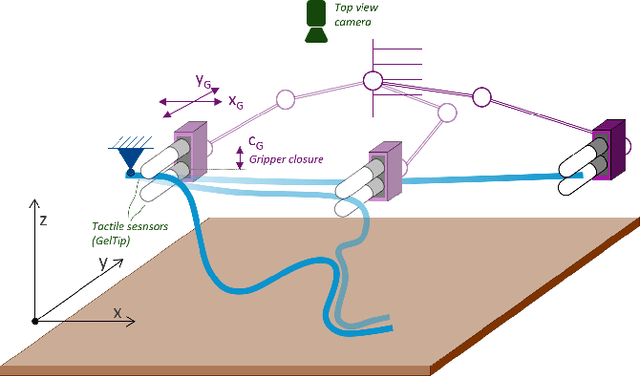
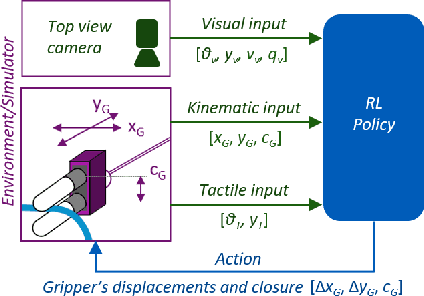
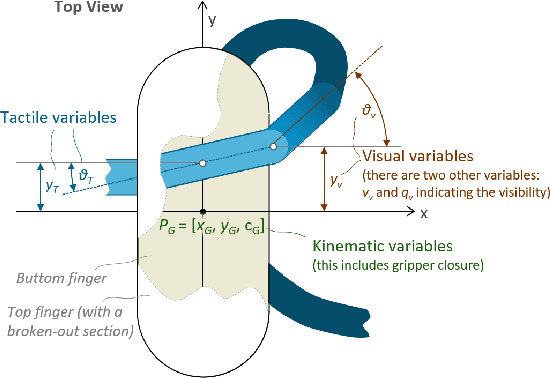

Manipulation of deformable objects is a challenging task for a robot. It will be problematic to use a single sensory input to track the behaviour of such objects: vision can be subjected to occlusions, whereas tactile inputs cannot capture the global information that is useful for the task. In this paper, we study the problem of using vision and tactile inputs together to complete the task of following deformable linear objects, for the first time. We create a Reinforcement Learning agent using different sensing modalities and investigate how its behaviour can be boosted using visual-tactile fusion, compared to using a single sensing modality. To this end, we developed a benchmark in simulation for manipulating the deformable linear objects using multimodal sensing inputs. The policy of the agent uses distilled information, e.g., the pose of the object in both visual and tactile perspectives, instead of the raw sensing signals, so that it can be directly transferred to real environments. In this way, we disentangle the perception system and the learned control policy. Our extensive experiments show that the use of both vision and tactile inputs, together with proprioception, allows the agent to complete the task in up to 92% of cases, compared to 77% when only one of the signals is given. Our results can provide valuable insights for the future design of tactile sensors and for deformable objects manipulation.
Online Learning for Orchestration of Inference in Multi-User End-Edge-Cloud Networks
Feb 21, 2022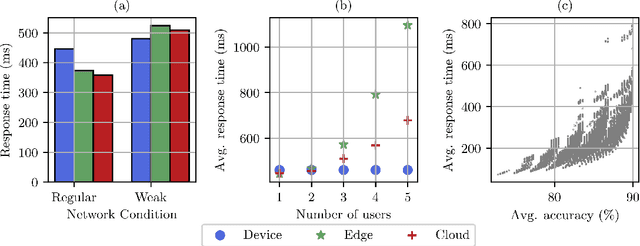

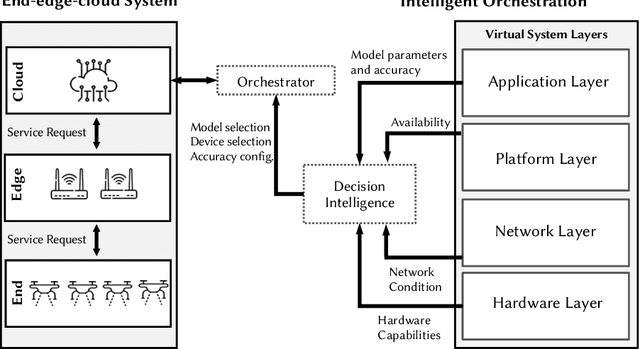

Deep-learning-based intelligent services have become prevalent in cyber-physical applications including smart cities and health-care. Deploying deep-learning-based intelligence near the end-user enhances privacy protection, responsiveness, and reliability. Resource-constrained end-devices must be carefully managed in order to meet the latency and energy requirements of computationally-intensive deep learning services. Collaborative end-edge-cloud computing for deep learning provides a range of performance and efficiency that can address application requirements through computation offloading. The decision to offload computation is a communication-computation co-optimization problem that varies with both system parameters (e.g., network condition) and workload characteristics (e.g., inputs). On the other hand, deep learning model optimization provides another source of tradeoff between latency and model accuracy. An end-to-end decision-making solution that considers such computation-communication problem is required to synergistically find the optimal offloading policy and model for deep learning services. To this end, we propose a reinforcement-learning-based computation offloading solution that learns optimal offloading policy considering deep learning model selection techniques to minimize response time while providing sufficient accuracy. We demonstrate the effectiveness of our solution for edge devices in an end-edge-cloud system and evaluate with a real-setup implementation using multiple AWS and ARM core configurations. Our solution provides 35% speedup in the average response time compared to the state-of-the-art with less than 0.9% accuracy reduction, demonstrating the promise of our online learning framework for orchestrating DL inference in end-edge-cloud systems.
An initial alignment between neural network and target is needed for gradient descent to learn
Feb 25, 2022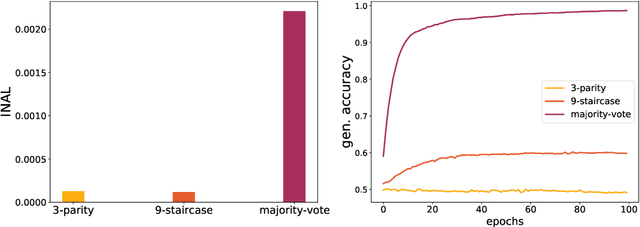
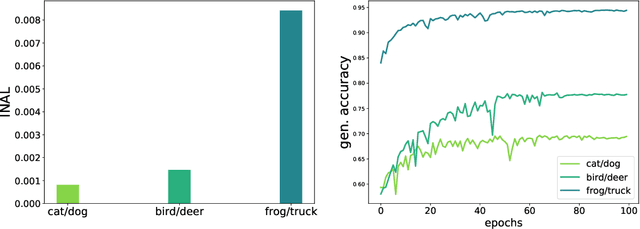
This paper introduces the notion of "Initial Alignment" (INAL) between a neural network at initialization and a target function. It is proved that if a network and target function do not have a noticeable INAL, then noisy gradient descent on a fully connected network with normalized i.i.d. initialization will not learn in polynomial time. Thus a certain amount of knowledge about the target (measured by the INAL) is needed in the architecture design. This also provides an answer to an open problem posed in [AS20]. The results are based on deriving lower-bounds for descent algorithms on symmetric neural networks without explicit knowledge of the target function beyond its INAL.