 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pay Attention to Hidden States for Video Deblurring: Ping-Pong Recurrent Neural Networks and Selective Non-Local Attention
Apr 07, 2022

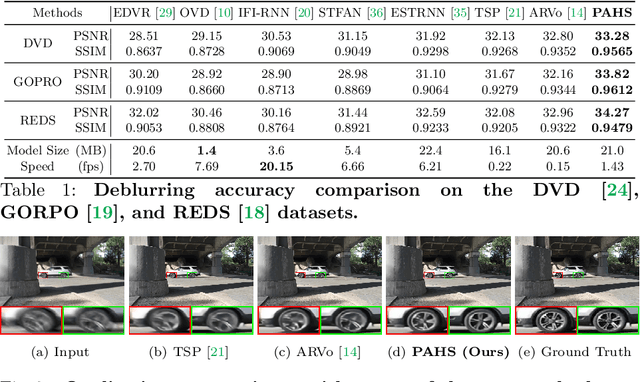
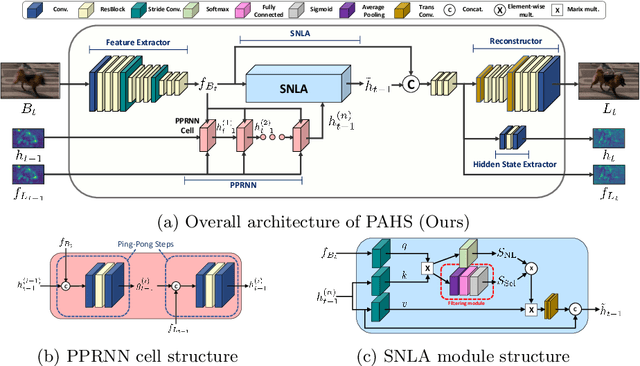

Video deblurring models exploit information in the neighboring frames to remove blur caused by the motion of the camera and the objects. Recurrent Neural Networks~(RNNs) are often adopted to model the temporal dependency between frames via hidden states. When motion blur is strong, however, hidden states are hard to deliver proper information due to the displacement between different frames. While there have been attempts to update the hidden states, it is difficult to handle misaligned features beyond the receptive field of simple modules. Thus, we propose 2 modules to supplement the RNN architecture for video deblurring. First, we design Ping-Pong RNN~(PPRNN) that acts on updating the hidden states by referring to the features from the current and the previous time steps alternately. PPRNN gathers relevant information from the both features in an iterative and balanced manner by utilizing its recurrent architecture. Second, we use a Selective Non-Local Attention~(SNLA) module to additionally refine the hidden state by aligning it with the positional information from the input frame feature. The attention score is scaled by the relevance to the input feature to focus on the necessary information. By paying attention to hidden states with both modules, which have strong synergy, our PAHS framework improves the representation powers of RNN structures and achieves state-of-the-art deblurring performance on standard benchmarks and real-world videos.
Differential Privacy Amplification in Quantum and Quantum-inspired Algorithms
Mar 07, 2022
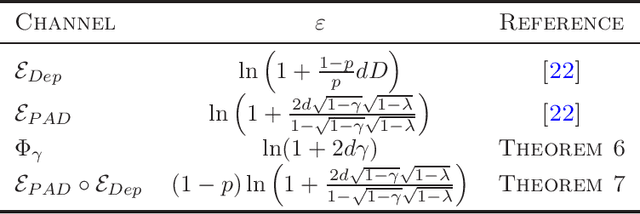
Differential privacy provides a theoretical framework for processing a dataset about $n$ users, in a way that the output reveals a minimal information about any single user. Such notion of privacy is usually ensured by noise-adding mechanisms and amplified by several processes, including subsampling, shuffling, iteration, mixing and diffusion. In this work, we provide privacy amplification bounds for quantum and quantum-inspired algorithms. In particular, we show for the first time, that algorithms running on quantum encoding of a classical dataset or the outcomes of quantum-inspired classical sampling, amplify differential privacy. Moreover, we prove that a quantum version of differential privacy is amplified by the composition of quantum channels, provided that they satisfy some mixing conditions.
(Newtonian) Space-Time Algebra
Dec 20, 2019
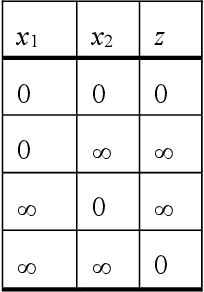
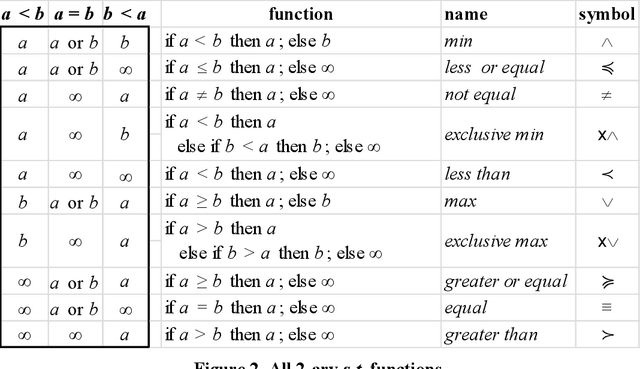

The space-time (s-t) algebra provides a mathematical model for communication and computation using values encoded as events in discretized linear (Newtonian) time. Consequently, the input-output behavior of s-t algebra and implemented functions are consistent with the flow of time. The s-t algebra and functions are formally defined. A network design framework for s-t functions is describe, and the design of temporal neural networks, a form of spiking neural networks, is discussed as an extended case study. Finally, the relationship with Allen's interval algebra is briefly discussed.
Learning Audio Representations with MLPs
Mar 16, 2022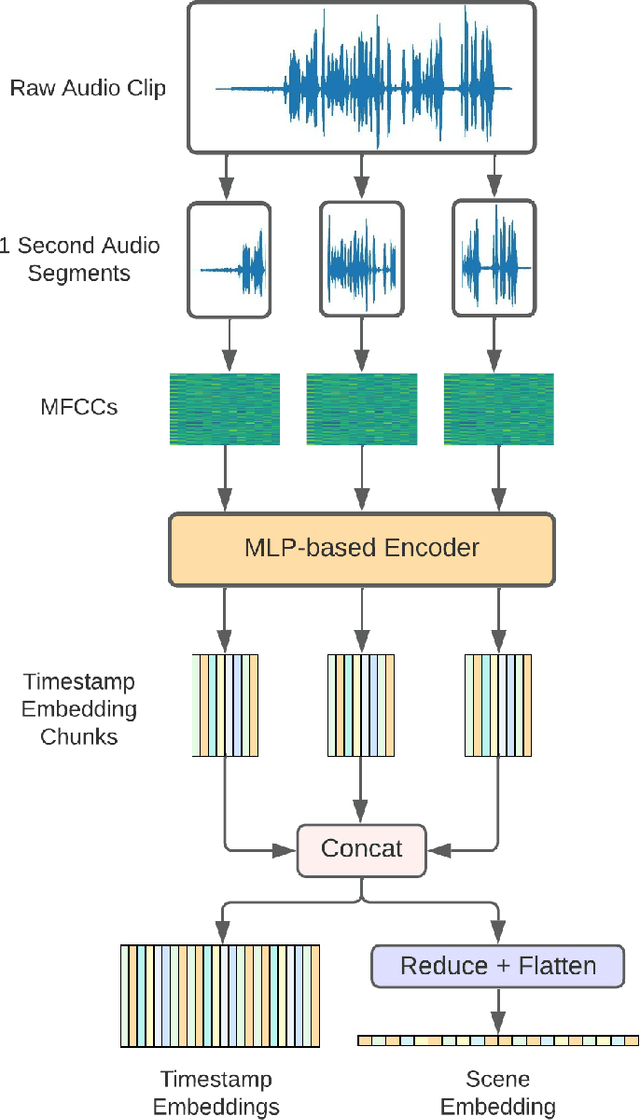
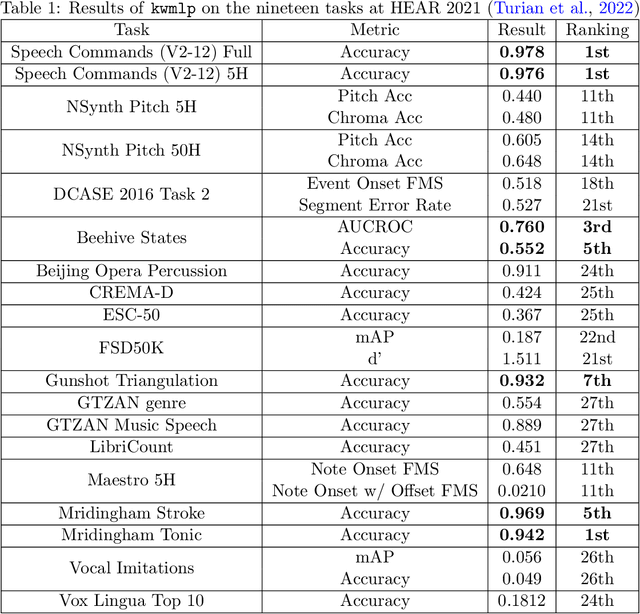
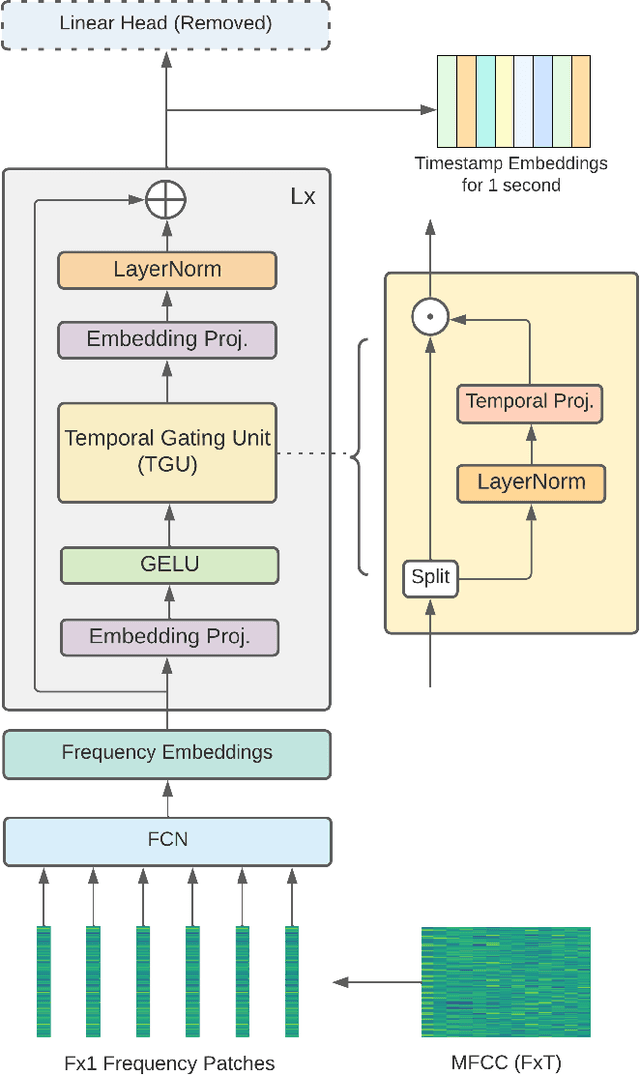
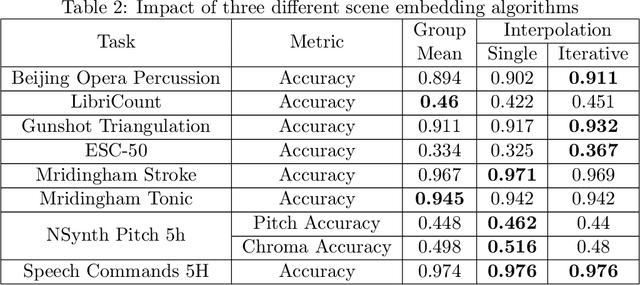
In this paper, we propose an efficient MLP-based approach for learning audio representations, namely timestamp and scene-level audio embeddings. We use an encoder consisting of sequentially stacked gated MLP blocks, which accept 2D MFCCs as inputs. In addition, we also provide a simple temporal interpolation-based algorithm for computing scene-level embeddings from timestamp embeddings. The audio representations generated by our method are evaluated across a diverse set of benchmarks at the Holistic Evaluation of Audio Representations (HEAR) challenge, hosted at the NeurIPS 2021 competition track. We achieved first place on the Speech Commands (full), Speech Commands (5 hours), and the Mridingham Tonic benchmarks. Furthermore, our approach is also the most resource-efficient among all the submitted methods, in terms of both the number of model parameters and the time required to compute embeddings.
Style-Based Global Appearance Flow for Virtual Try-On
Apr 03, 2022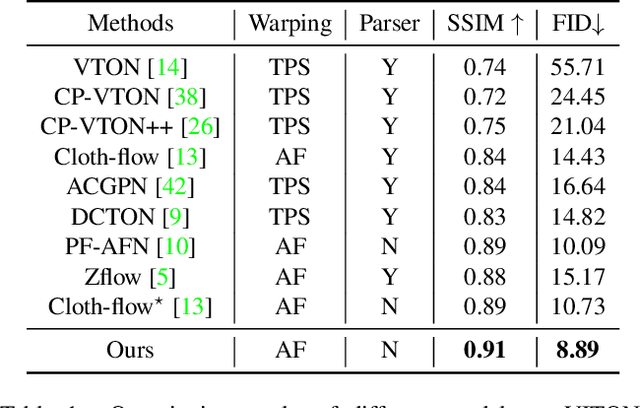
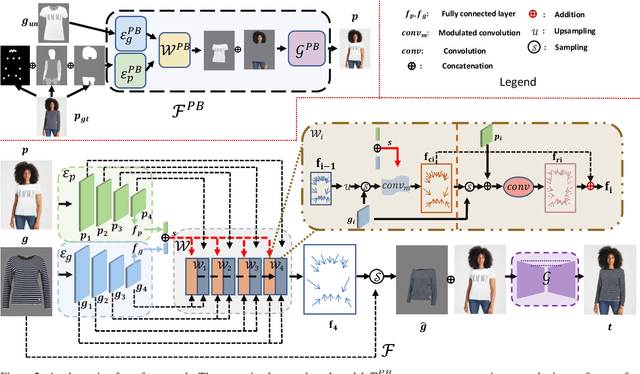

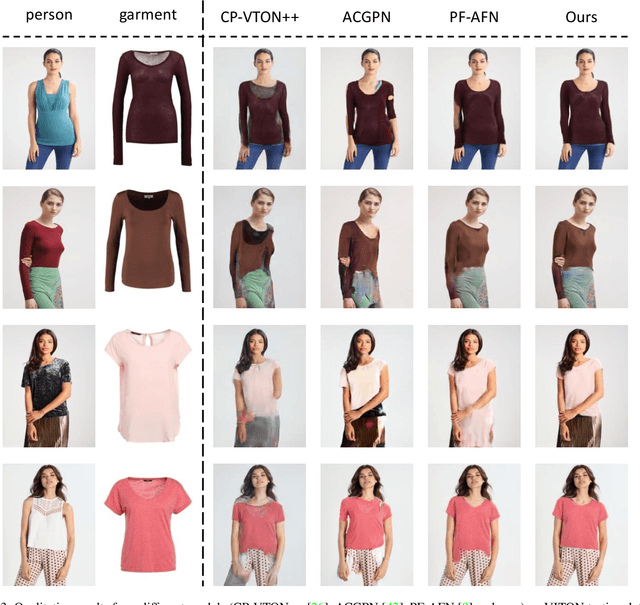
Image-based virtual try-on aims to fit an in-shop garment into a clothed person image. To achieve this, a key step is garment warping which spatially aligns the target garment with the corresponding body parts in the person image. Prior methods typically adopt a local appearance flow estimation model. They are thus intrinsically susceptible to difficult body poses/occlusions and large mis-alignments between person and garment images (see Fig.~\ref{fig:fig1}). To overcome this limitation, a novel global appearance flow estimation model is proposed in this work. For the first time, a StyleGAN based architecture is adopted for appearance flow estimation. This enables us to take advantage of a global style vector to encode a whole-image context to cope with the aforementioned challenges. To guide the StyleGAN flow generator to pay more attention to local garment deformation, a flow refinement module is introduced to add local context. Experiment results on a popular virtual try-on benchmark show that our method achieves new state-of-the-art performance. It is particularly effective in a `in-the-wild' application scenario where the reference image is full-body resulting in a large mis-alignment with the garment image (Fig.~\ref{fig:fig1} Top). Code is available at: \url{https://github.com/SenHe/Flow-Style-VTON}.
Practical Challenges in Differentially-Private Federated Survival Analysis of Medical Data
Feb 08, 2022
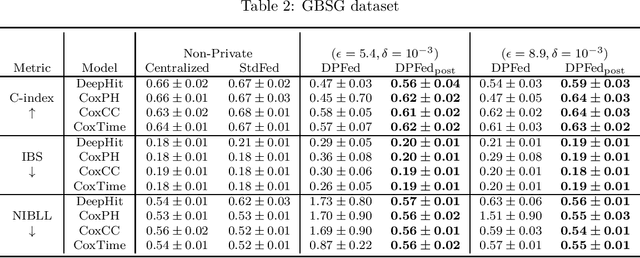
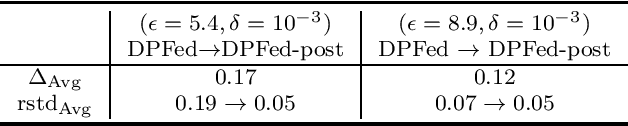
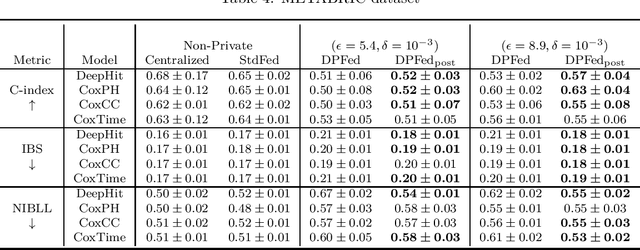
Survival analysis or time-to-event analysis aims to model and predict the time it takes for an event of interest to happen in a population or an individual. In the medical context this event might be the time of dying, metastasis, recurrence of cancer, etc. Recently, the use of neural networks that are specifically designed for survival analysis has become more popular and an attractive alternative to more traditional methods. In this paper, we take advantage of the inherent properties of neural networks to federate the process of training of these models. This is crucial in the medical domain since data is scarce and collaboration of multiple health centers is essential to make a conclusive decision about the properties of a treatment or a disease. To ensure the privacy of the datasets, it is common to utilize differential privacy on top of federated learning. Differential privacy acts by introducing random noise to different stages of training, thus making it harder for an adversary to extract details about the data. However, in the realistic setting of small medical datasets and only a few data centers, this noise makes it harder for the models to converge. To address this problem, we propose DPFed-post which adds a post-processing stage to the private federated learning scheme. This extra step helps to regulate the magnitude of the noisy average parameter update and easier convergence of the model. For our experiments, we choose 3 real-world datasets in the realistic setting when each health center has only a few hundred records, and we show that DPFed-post successfully increases the performance of the models by an average of up to $17\%$ compared to the standard differentially private federated learning scheme.
A Framework for Real-time Traffic Trajectory Tracking, Speed Estimation, and Driver Behavior Calibration at Urban Intersections Using Virtual Traffic Lanes
Jun 18, 2021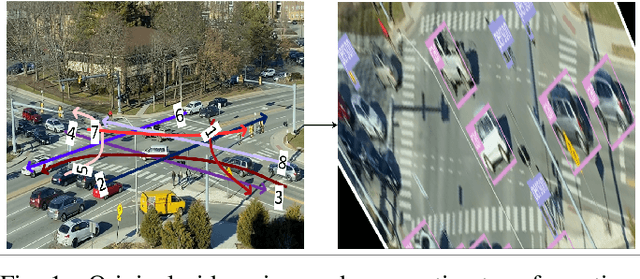


In a previous study, we presented VT-Lane, a three-step framework for real-time vehicle detection, tracking, and turn movement classification at urban intersections. In this study, we present a case study incorporating the highly accurate trajectories and movement classification obtained via VT-Lane for the purpose of speed estimation and driver behavior calibration for traffic at urban intersections. First, we use a highly instrumented vehicle to verify the estimated speeds obtained from video inference. The results of the speed validation show that our method can estimate the average travel speed of detected vehicles in real-time with an error of 0.19 m/sec, which is equivalent to 2% of the average observed travel speeds in the intersection of the study. Instantaneous speeds (at the resolution of 30 Hz) were found to be estimated with an average error of 0.21 m/sec and 0.86 m/sec respectively for free-flowing and congested traffic conditions. We then use the estimated speeds to calibrate the parameters of a driver behavior model for the vehicles in the area of study. The results show that the calibrated model replicates the driving behavior with an average error of 0.45 m/sec, indicating the high potential for using this framework for automated, large-scale calibration of car-following models from roadside traffic video data, which can lead to substantial improvements in traffic modeling via microscopic simulation.
Evaluating Elements of Web-based Data Enrichment for Pseudo-Relevance Feedback Retrieval
Mar 10, 2022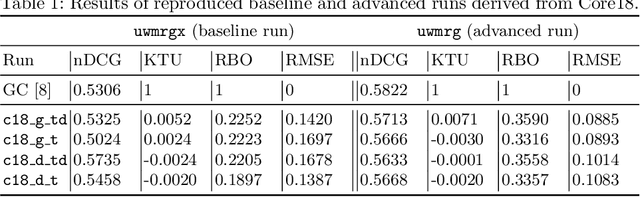
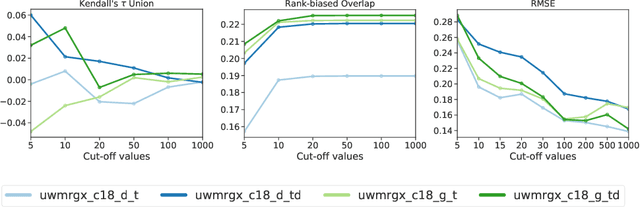
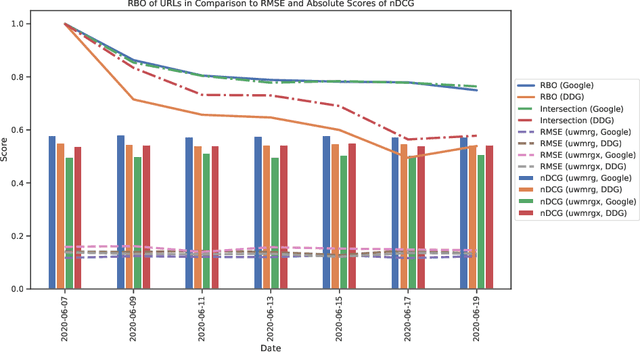
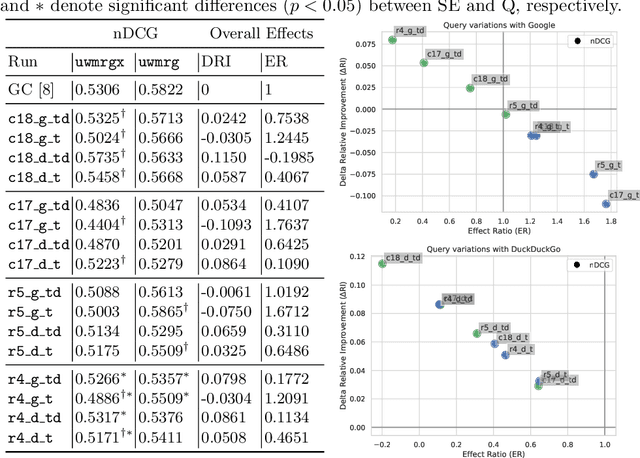
In this work, we analyze a pseudo-relevance retrieval method based on the results of web search engines. By enriching topics with text data from web search engine result pages and linked contents, we train topic-specific and cost-efficient classifiers that can be used to search test collections for relevant documents. Building upon attempts initially made at TREC Common Core 2018 by Grossman and Cormack, we address questions of system performance over time considering different search engines, queries, and test collections. Our experimental results show how and to which extent the considered components affect the retrieval performance. Overall, the analyzed method is robust in terms of average retrieval performance and a promising way to use web content for the data enrichment of relevance feedback methods.
DMCNet: Diversified Model Combination Network for Understanding Engagement from Video Screengrabs
Apr 13, 2022
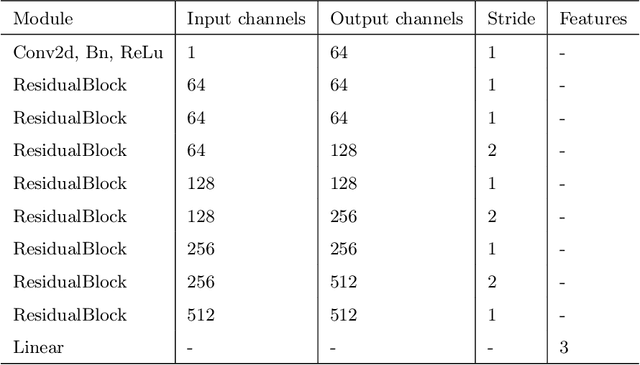
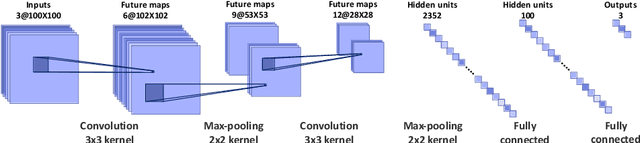
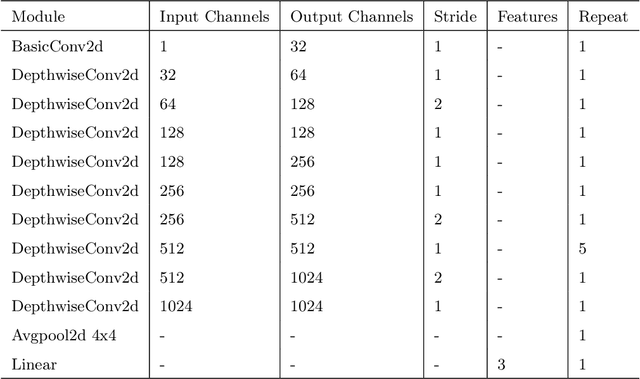
Engagement is an essential indicator of the Quality-of-Learning Experience (QoLE) and plays a major role in developing intelligent educational interfaces. The number of people learning through Massively Open Online Courses (MOOCs) and other online resources has been increasing rapidly because they provide us with the flexibility to learn from anywhere at any time. This provides a good learning experience for the students. However, such learning interface requires the ability to recognize the level of engagement of the students for a holistic learning experience. This is useful for both students and educators alike. However, understanding engagement is a challenging task, because of its subjectivity and ability to collect data. In this paper, we propose a variety of models that have been trained on an open-source dataset of video screengrabs. Our non-deep learning models are based on the combination of popular algorithms such as Histogram of Oriented Gradient (HOG), Support Vector Machine (SVM), Scale Invariant Feature Transform (SIFT) and Speeded Up Robust Features (SURF). The deep learning methods include Densely Connected Convolutional Networks (DenseNet-121), Residual Network (ResNet-18) and MobileNetV1. We show the performance of each models using a variety of metrics such as the Gini Index, Adjusted F-Measure (AGF), and Area Under receiver operating characteristic Curve (AUC). We use various dimensionality reduction techniques such as Principal Component Analysis (PCA) and t-Distributed Stochastic Neighbor Embedding (t-SNE) to understand the distribution of data in the feature sub-space. Our work will thereby assist the educators and students in obtaining a fruitful and efficient online learning experience.
An STDP-Based Supervised Learning Algorithm for Spiking Neural Networks
Mar 07, 2022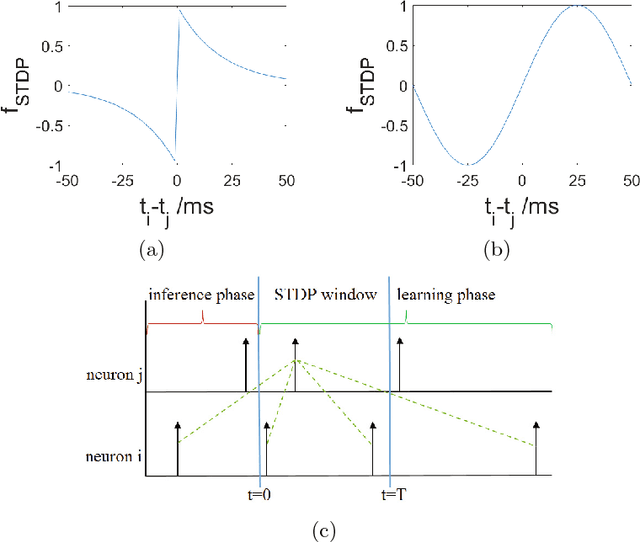
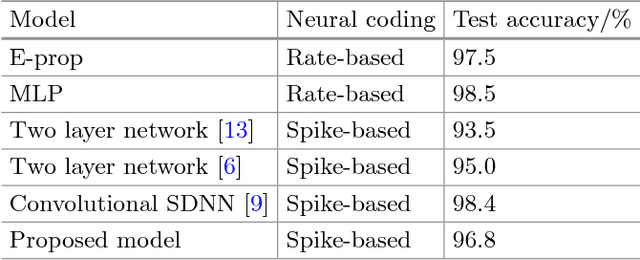
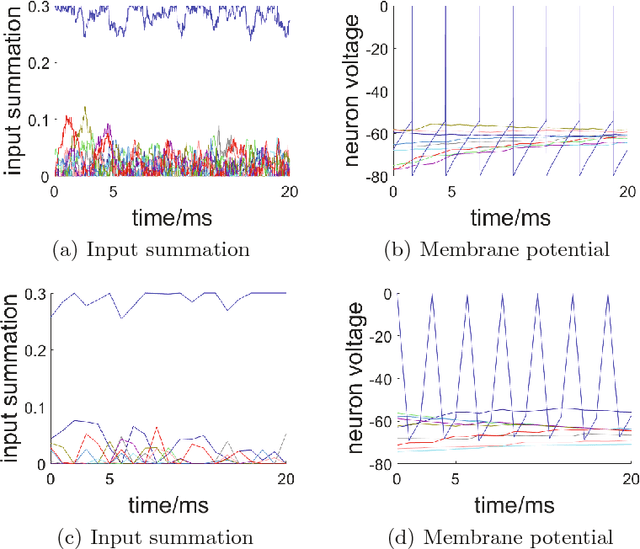
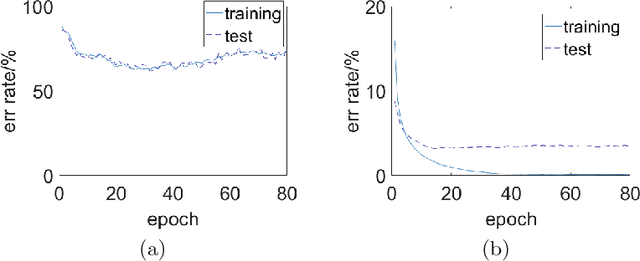
Compared with rate-based artificial neural networks, Spiking Neural Networks (SNN) provide a more biological plausible model for the brain. But how they perform supervised learning remains elusive. Inspired by recent works of Bengio et al., we propose a supervised learning algorithm based on Spike-Timing Dependent Plasticity (STDP) for a hierarchical SNN consisting of Leaky Integrate-and-fire (LIF) neurons. A time window is designed for the presynaptic neuron and only the spikes in this window take part in the STDP updating process. The model is trained on the MNIST dataset. The classification accuracy approach that of a Multilayer Perceptron (MLP) with similar architecture trained by the standard back-propagation algorithm.