 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Using Active Speaker Faces for Diarization in TV shows
Mar 30, 2022
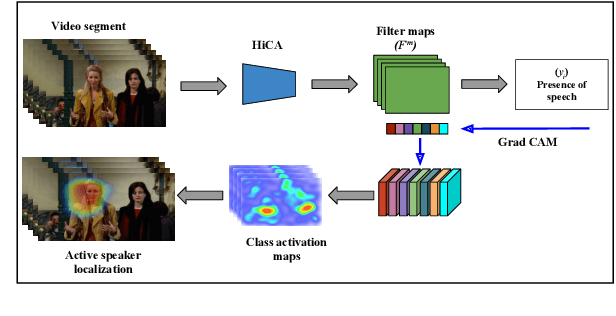
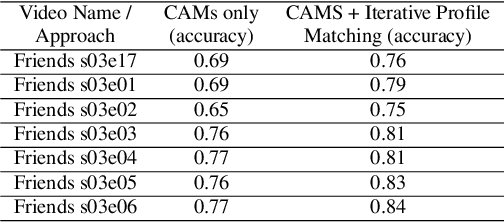
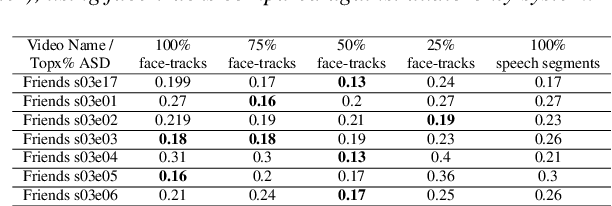
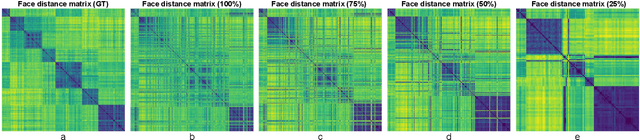
Speaker diarization is one of the critical components of computational media intelligence as it enables a character-level analysis of story portrayals and media content understanding. Automated audio-based speaker diarization of entertainment media poses challenges due to the diverse acoustic conditions present in media content, be it background music, overlapping speakers, or sound effects. At the same time, speaking faces in the visual modality provide complementary information and not prone to the errors seen in the audio modality. In this paper, we address the problem of speaker diarization in TV shows using the active speaker faces. We perform face clustering on the active speaker faces and show superior speaker diarization performance compared to the state-of-the-art audio-based diarization methods. We additionally report a systematic analysis of the impact of active speaker face detection quality on the diarization performance. We also observe that a moderately well-performing active speaker system could outperform the audio-based diarization systems.
CenterNet++ for Object Detection
Apr 18, 2022

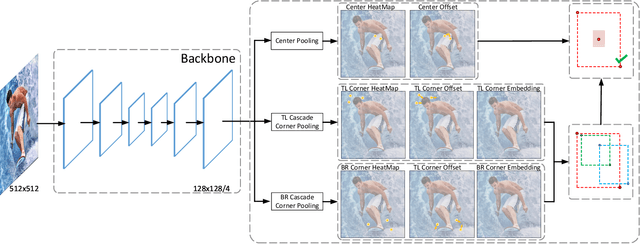
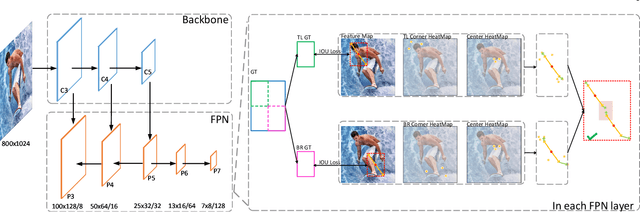
There are two mainstreams for object detection: top-down and bottom-up. The state-of-the-art approaches mostly belong to the first category. In this paper, we demonstrate that the bottom-up approaches are as competitive as the top-down and enjoy higher recall. Our approach, named CenterNet, detects each object as a triplet keypoints (top-left and bottom-right corners and the center keypoint). We firstly group the corners by some designed cues and further confirm the objects by the center keypoints. The corner keypoints equip the approach with the ability to detect objects of various scales and shapes and the center keypoint avoids the confusion brought by a large number of false-positive proposals. Our approach is a kind of anchor-free detector because it does not need to define explicit anchor boxes. We adapt our approach to the backbones with different structures, i.e., the 'hourglass' like networks and the the 'pyramid' like networks, which detect objects on a single-resolution feature map and multi-resolution feature maps, respectively. On the MS-COCO dataset, CenterNet with Res2Net-101 and Swin-Transformer achieves APs of 53.7% and 57.1%, respectively, outperforming all existing bottom-up detectors and achieving state-of-the-art. We also design a real-time CenterNet, which achieves a good trade-off between accuracy and speed with an AP of 43.6% at 30.5 FPS. https://github.com/Duankaiwen/PyCenterNet.
Continuous-Time Multi-Armed Bandits with Controlled Restarts
Jun 30, 2020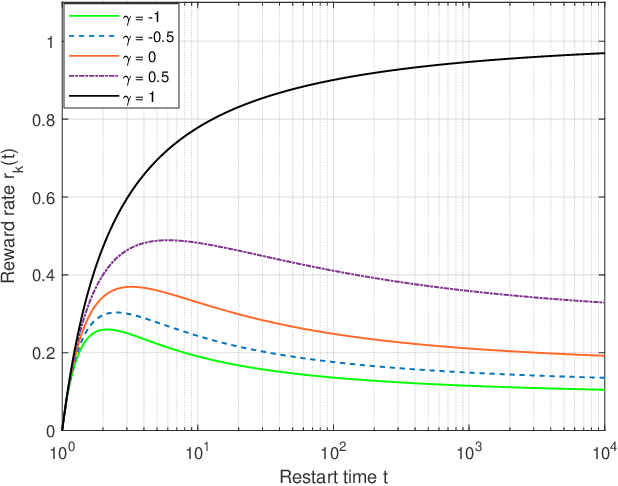
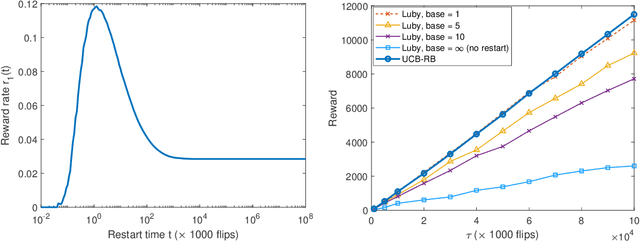
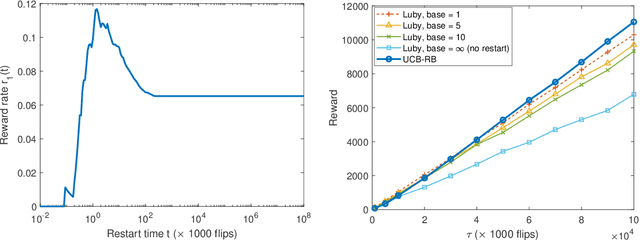
Time-constrained decision processes have been ubiquitous in many fundamental applications in physics, biology and computer science. Recently, restart strategies have gained significant attention for boosting the efficiency of time-constrained processes by expediting the completion times. In this work, we investigate the bandit problem with controlled restarts for time-constrained decision processes, and develop provably good learning algorithms. In particular, we consider a bandit setting where each decision takes a random completion time, and yields a random and correlated reward at the end, with unknown values at the time of decision. The goal of the decision-maker is to maximize the expected total reward subject to a time constraint $\tau$. As an additional control, we allow the decision-maker to interrupt an ongoing task and forgo its reward for a potentially more rewarding alternative. For this problem, we develop efficient online learning algorithms with $O(\log(\tau))$ and $O(\sqrt{\tau\log(\tau)})$ regret in a finite and continuous action space of restart strategies, respectively. We demonstrate an applicability of our algorithm by using it to boost the performance of SAT solvers.
Global Sentiment Analysis Of COVID-19 Tweets Over Time
Oct 27, 2020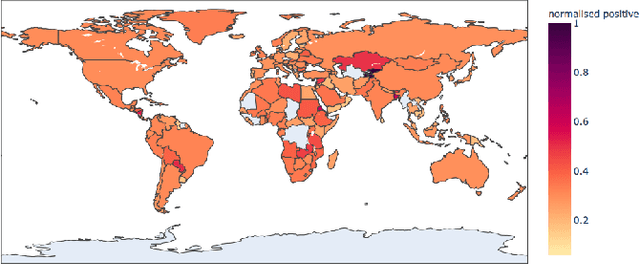
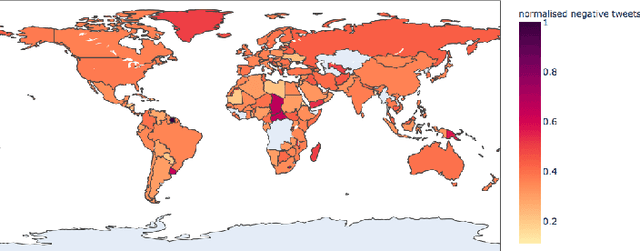
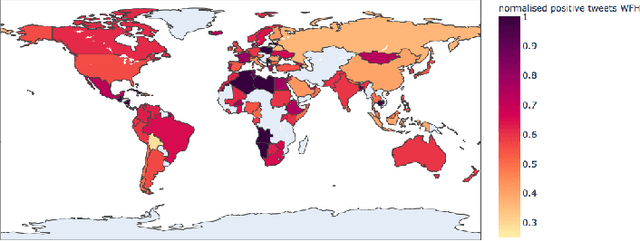
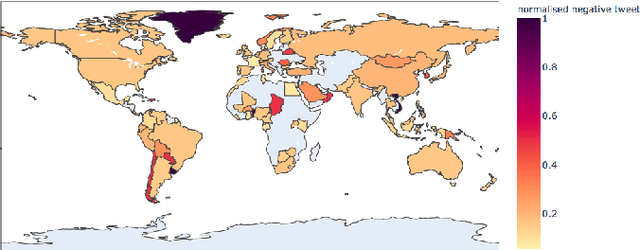
The Coronavirus pandemic has affected the normal course of life. People around the world have taken to social media to express their opinions and general emotions regarding this phenomenon that has taken over the world by storm. The social networking site, Twitter showed an unprecedented increase in tweets related to the novel Coronavirus in a very short span of time. This paper presents the global sentiment analysis of tweets related to Coronavirus and how the sentiment of people in different countries has changed over time. Furthermore, to determine the impact of Coronavirus on daily aspects of life, tweets related to Work From Home (WFH) and Online Learning were scraped and the change in sentiment over time was observed. In addition, various Machine Learning models such as Long Short Term Memory (LSTM) and Artificial Neural Networks (ANN) were implemented for sentiment classification and their accuracies were determined. Exploratory data analysis was also performed for a dataset providing information about the number of confirmed cases on a per-day basis in a few of the worst-hit countries to provide a comparison between the change in sentiment with the change in cases since the start of this pandemic till June 2020.
A priori guarantees of finite-time convergence for Deep Neural Networks
Sep 16, 2020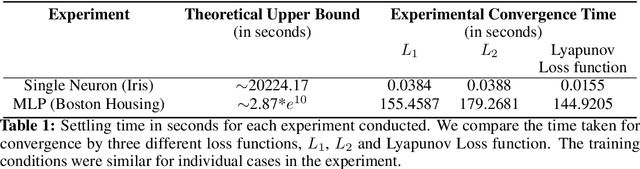
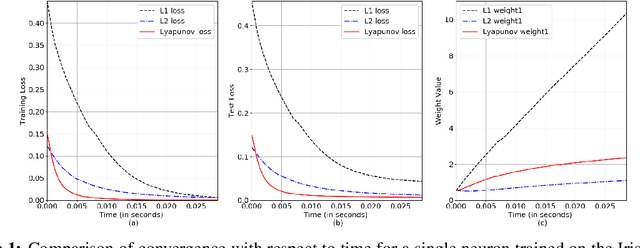
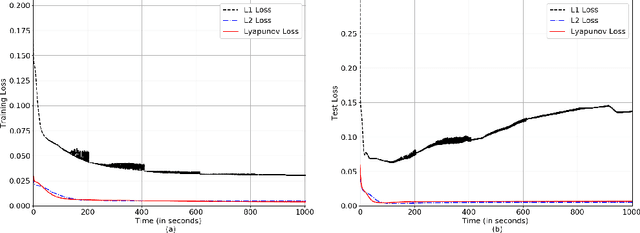
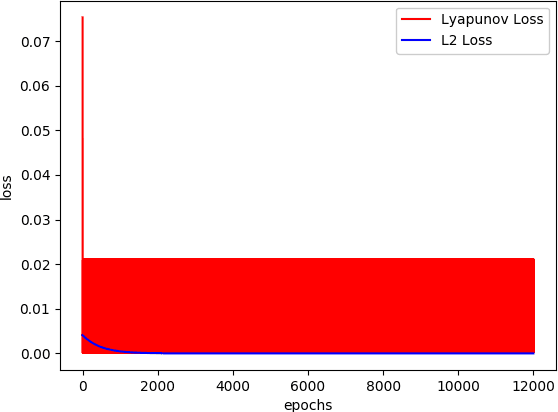
In this paper, we perform Lyapunov based analysis of the loss function to derive an a priori upper bound on the settling time of deep neural networks. While previous studies have attempted to understand deep learning using control theory framework, there is limited work on a priori finite time convergence analysis. Drawing from the advances in analysis of finite-time control of non-linear systems, we provide a priori guarantees of finite-time convergence in a deterministic control theoretic setting. We formulate the supervised learning framework as a control problem where weights of the network are control inputs and learning translates into a tracking problem. An analytical formula for finite-time upper bound on settling time is computed a priori under the assumptions of boundedness of input. Finally, we prove the robustness and sensitivity of the loss function against input perturbations.
Deep Reinforcement Learning for Shared Autonomous Vehicles (SAV) Fleet Management
Jan 15, 2022Shared Automated Vehicles (SAVs) Fleets companies are starting pilot projects nationwide. In 2020 in Fairfax Virginia it was announced the first Shared Autonomous Vehicle Fleet pilot project in Virginia. SAVs promise to improve quality of life. However, SAVs will also induce some negative externalities by generating excessive vehicle miles traveled (VMT), which leads to more congestions, energy consumption, and emissions. The excessive VMT are primarily generated via empty relocation process. Reinforcement Learning based algorithms are being researched as a possible solution to solve some of these problems: most notably minimizing waiting time for riders. But no research using Reinforcement Learning has been made about reducing parking space cost nor reducing empty cruising time. This study explores different \textbf{Reinforcement Learning approaches and then decide the best approach to help minimize the rider waiting time, parking cost, and empty travel
Resource Allocation for Multiuser Edge Inference with Batching and Early Exiting (Extended Version)
Apr 11, 2022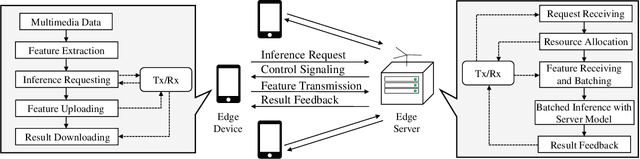

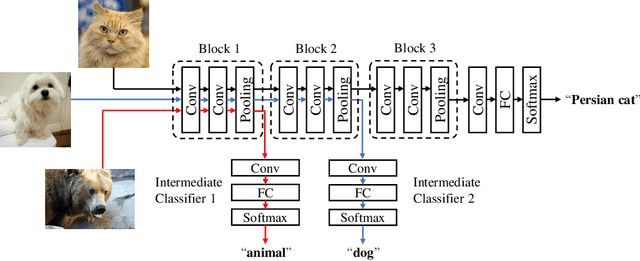
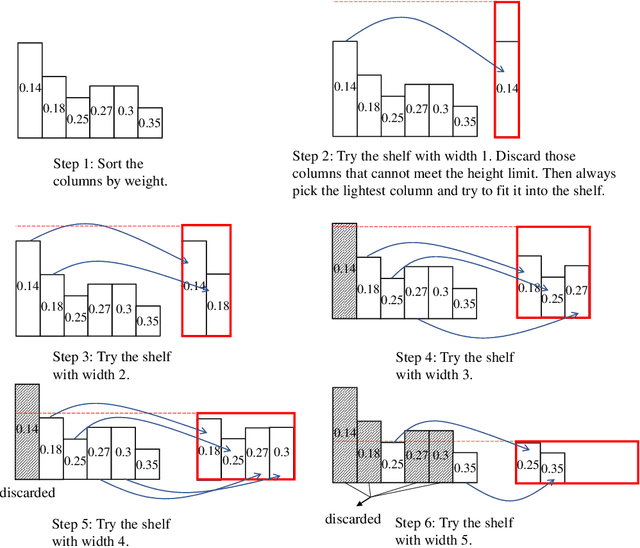
The deployment of inference services at the network edge, called edge inference, offloads computation-intensive inference tasks from mobile devices to edge servers, thereby enhancing the former's capabilities and battery lives. In a multiuser system, the joint allocation of communication-and-computation ($\text{C}^\text{2}$) resources (i.e., scheduling and bandwidth allocation) is made challenging by adopting efficient inference techniques, batching and early exiting, and further complicated by the heterogeneity in users' requirements on accuracy and latency. Batching groups multiple tasks into one batch for parallel processing to reduce time-consuming memory access and thereby boosts the throughput (i.e., completed task per second). On the other hand, early exiting allows a task to exit from a deep-neural network without traversing the whole network to support a tradeoff between accuracy and latency. In this work, we study optimal $\text{C}^\text{2}$ resource allocation with batching and early exiting, which is an NP-complete integer program. A set of efficient algorithms are designed under the criterion of maximum throughput by tackling the challenge. Experimental results demonstrate that both optimal and sub-optimal $\text{C}^\text{2}$ resource allocation algorithms can leverage integrated batching and early exiting to achieve 200% throughput gain over conventional schemes.
Human vs Objective Evaluation of Colourisation Performance
Apr 11, 2022
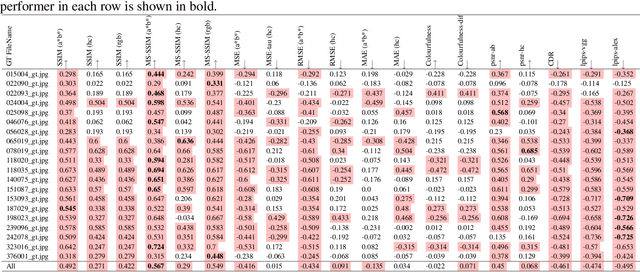
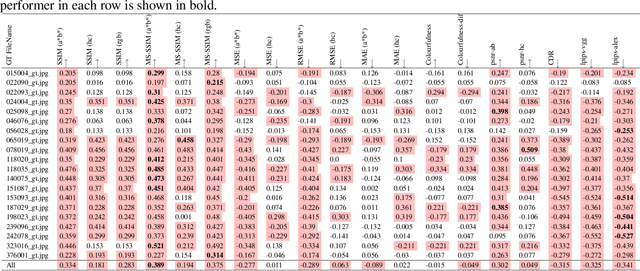
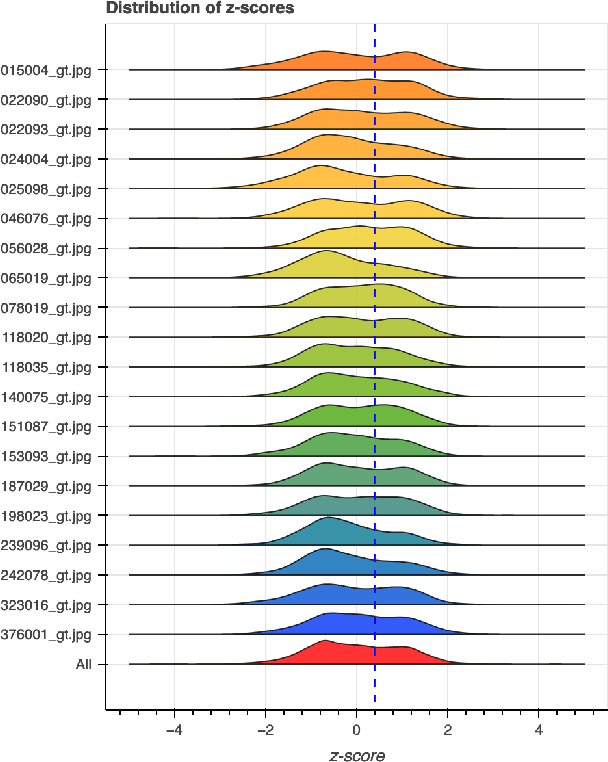
Automatic colourisation of grey-scale images is the process of creating a full-colour image from the grey-scale prior. It is an ill-posed problem, as there are many plausible colourisations for a given grey-scale prior. The current SOTA in auto-colourisation involves image-to-image type Deep Convolutional Neural Networks with Generative Adversarial Networks showing the greatest promise. The end goal of colourisation is to produce full colour images that appear plausible to the human viewer, but human assessment is costly and time consuming. This work assesses how well commonly used objective measures correlate with human opinion. We also attempt to determine what facets of colourisation have the most significant effect on human opinion. For each of 20 images from the BSD dataset, we create 65 recolourisations made up of local and global changes. Opinion scores are then crowd sourced using the Amazon Mechanical Turk and together with the images this forms an extensible dataset called the Human Evaluated Colourisation Dataset (HECD). While we find statistically significant correlations between human-opinion scores and a small number of objective measures, the strength of the correlations is low. There is also evidence that human observers are most intolerant to an incorrect hue of naturally occurring objects.
A Deep Learning Approach to Probabilistic Forecasting of Weather
Mar 24, 2022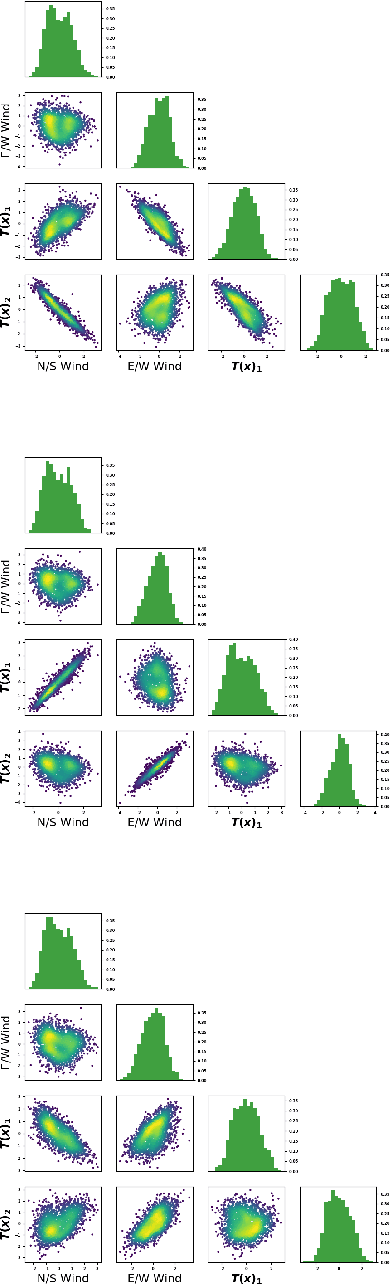
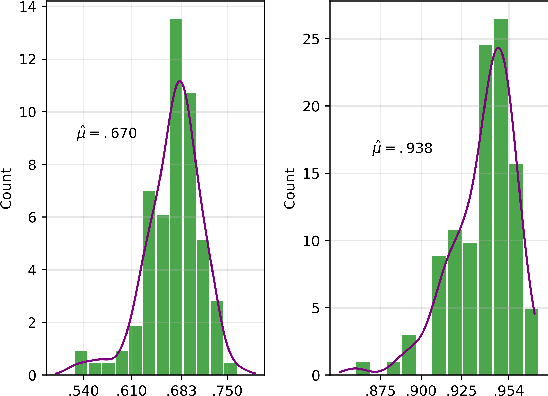
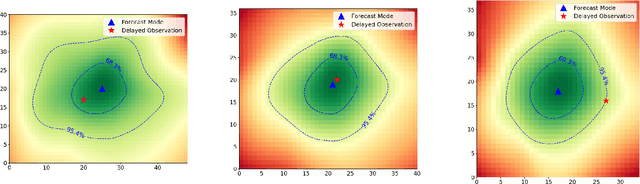
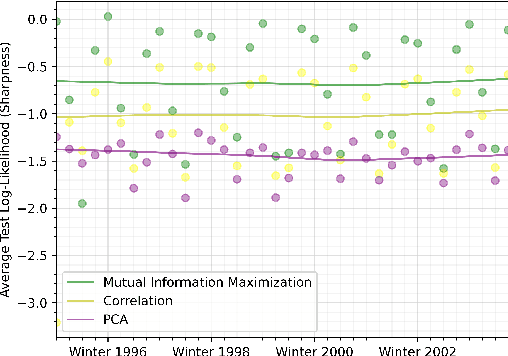
We discuss an approach to probabilistic forecasting based on two chained machine-learning steps: a dimensional reduction step that learns a reduction map of predictor information to a low-dimensional space in a manner designed to preserve information about forecast quantities; and a density estimation step that uses the probabilistic machine learning technique of normalizing flows to compute the joint probability density of reduced predictors and forecast quantities. This joint density is then renormalized to produce the conditional forecast distribution. In this method, probabilistic calibration testing plays the role of a regularization procedure, preventing overfitting in the second step, while effective dimensional reduction from the first step is the source of forecast sharpness. We verify the method using a 22-year 1-hour cadence time series of Weather Research and Forecasting (WRF) simulation data of surface wind on a grid.
Computational-Statistical Gaps in Reinforcement Learning
Feb 11, 2022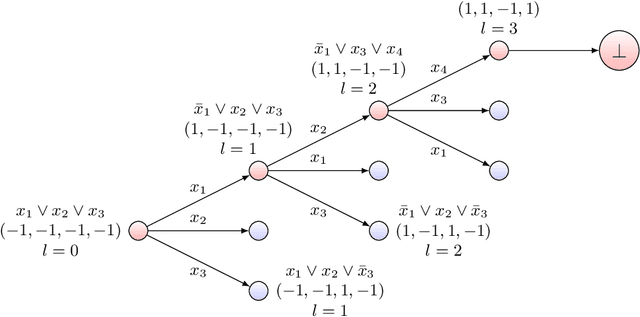
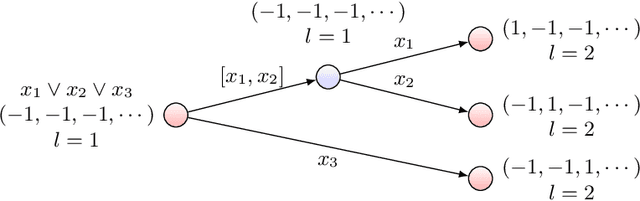
Reinforcement learning with function approximation has recently achieved tremendous results in applications with large state spaces. This empirical success has motivated a growing body of theoretical work proposing necessary and sufficient conditions under which efficient reinforcement learning is possible. From this line of work, a remarkably simple minimal sufficient condition has emerged for sample efficient reinforcement learning: MDPs with optimal value function $V^*$ and $Q^*$ linear in some known low-dimensional features. In this setting, recent works have designed sample efficient algorithms which require a number of samples polynomial in the feature dimension and independent of the size of state space. They however leave finding computationally efficient algorithms as future work and this is considered a major open problem in the community. In this work, we make progress on this open problem by presenting the first computational lower bound for RL with linear function approximation: unless NP=RP, no randomized polynomial time algorithm exists for deterministic transition MDPs with a constant number of actions and linear optimal value functions. To prove this, we show a reduction from Unique-Sat, where we convert a CNF formula into an MDP with deterministic transitions, constant number of actions and low dimensional linear optimal value functions. This result also exhibits the first computational-statistical gap in reinforcement learning with linear function approximation, as the underlying statistical problem is information-theoretically solvable with a polynomial number of queries, but no computationally efficient algorithm exists unless NP=RP. Finally, we also prove a quasi-polynomial time lower bound under the Randomized Exponential Time Hypothesis.