 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman vs Objective Evaluation of Colourisation Performance
Apr 11, 2022
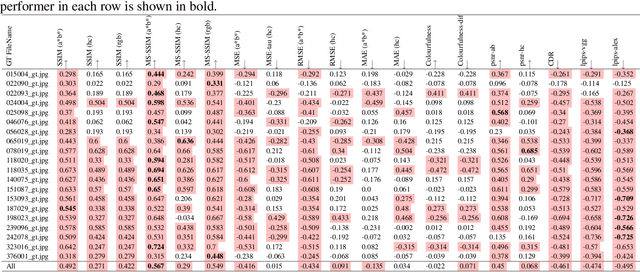
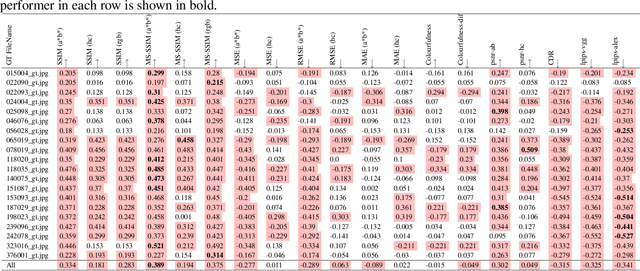
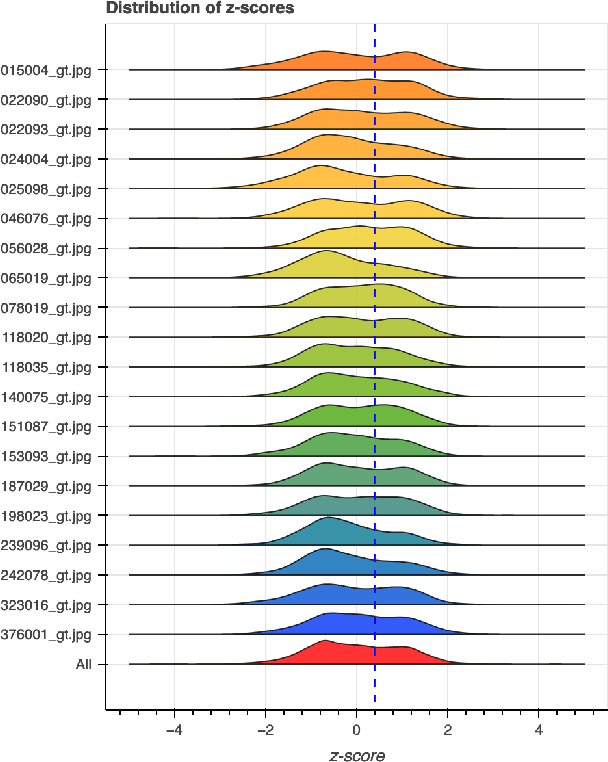
Automatic colourisation of grey-scale images is the process of creating a full-colour image from the grey-scale prior. It is an ill-posed problem, as there are many plausible colourisations for a given grey-scale prior. The current SOTA in auto-colourisation involves image-to-image type Deep Convolutional Neural Networks with Generative Adversarial Networks showing the greatest promise. The end goal of colourisation is to produce full colour images that appear plausible to the human viewer, but human assessment is costly and time consuming. This work assesses how well commonly used objective measures correlate with human opinion. We also attempt to determine what facets of colourisation have the most significant effect on human opinion. For each of 20 images from the BSD dataset, we create 65 recolourisations made up of local and global changes. Opinion scores are then crowd sourced using the Amazon Mechanical Turk and together with the images this forms an extensible dataset called the Human Evaluated Colourisation Dataset (HECD). While we find statistically significant correlations between human-opinion scores and a small number of objective measures, the strength of the correlations is low. There is also evidence that human observers are most intolerant to an incorrect hue of naturally occurring objects.
A spatial hue similarity measure for assessment of colourisation
Nov 03, 2020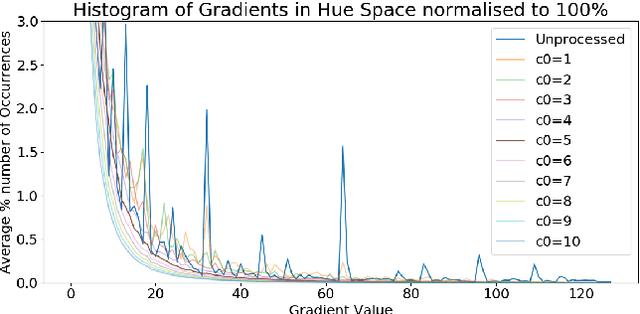
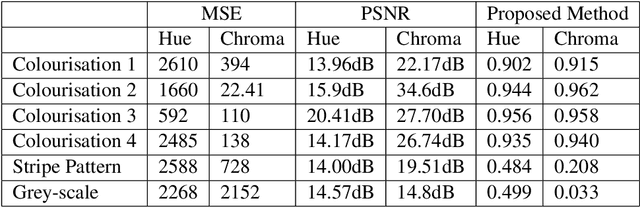
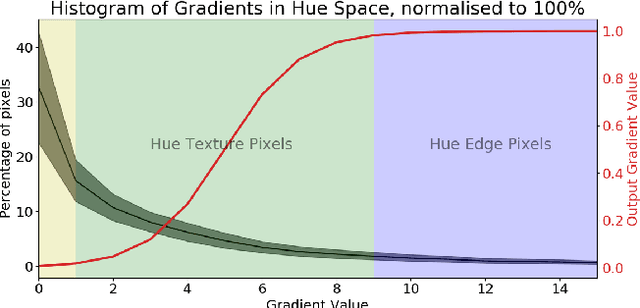

Automatic colourisation of grey-scale images is an ill-posed multi-modal problem. Where full-reference images exist, objective performance measures rely on pixel-difference techniques such as MSE and PSNR. These measures penalise any plausible modes other than the reference ground-truth; They often fail to adequately penalise implausible modes if they are close in pixel distance to the ground-truth; As these are pixel-difference methods they cannot assess spatial coherency. We use the polar form of the a*b* channels from the CIEL*a*b* colour space to separate the multi-modal problems, which we confine to the hue channel, and the common-mode which applies to the chroma channel. We apply SSIM to the chroma channel but reformulate SSIM for the hue channel to a measure we call the Spatial Hue Similarity Measure (SHSM). This reformulation allows spatially-coherent hue channels to achieve a high score while penalising spatially-incoherent modes. This method allows qualitative and quantitative performance comparison of SOTA colourisation methods and reduces reliance on subjective human visual inspection.
Batch Normalization in the final layer of generative networks
May 18, 2018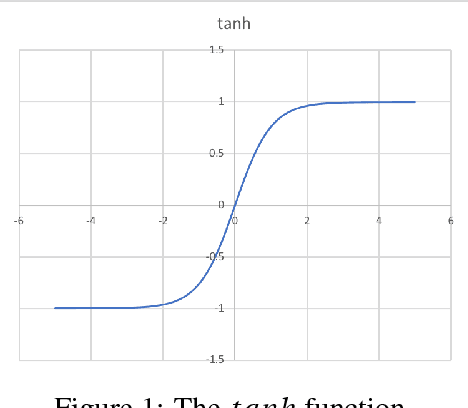
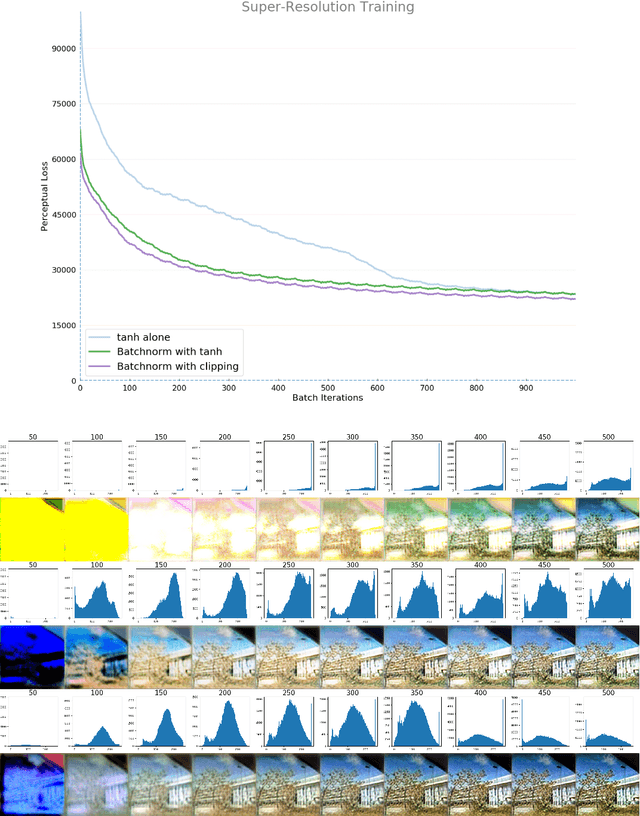
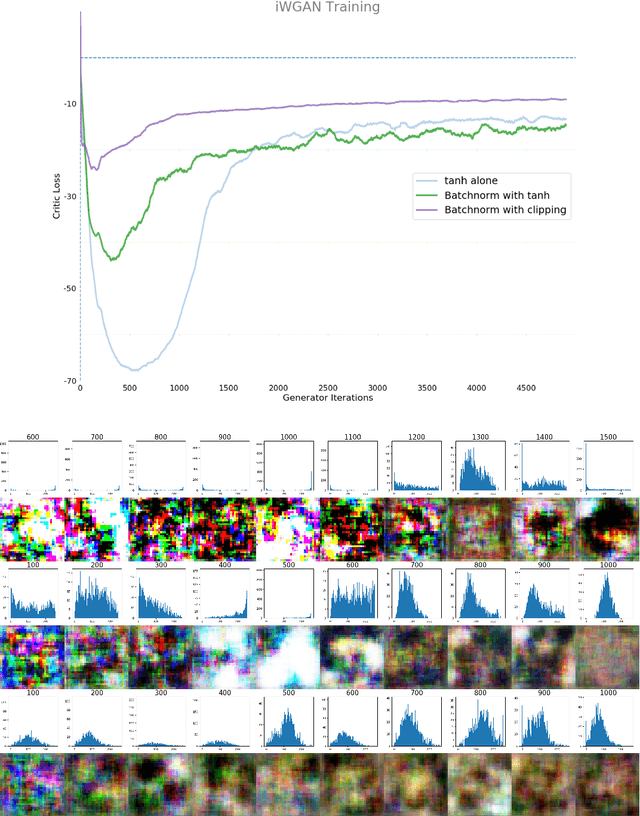
Generative Networks have shown great promise in generating photo-realistic images. Despite this, the theory surrounding them is still an active research area. Much of the useful work with Generative networks rely on heuristics that tend to produce good results. One of these heuristics is the advice not to use Batch Normalization in the final layer of the generator network. Many of the state-of-the-art generative network architectures use this heuristic, but the reasons for doing so are inconsistent. This paper will show that this is not necessarily a good heuristic and that Batch Normalization can be beneficial in the final layer of the generator network either by placing it before the final non-linear activation, usually a $tanh$ or replacing the final $tanh$ activation altogether with Batch Normalization and clipping. We show that this can lead to the faster training of Generator networks by matching the generator to the mean and standard deviation of the target distribution's image colour values.
Convolutional Neural Network on Three Orthogonal Planes for Dynamic Texture Classification
Mar 16, 2017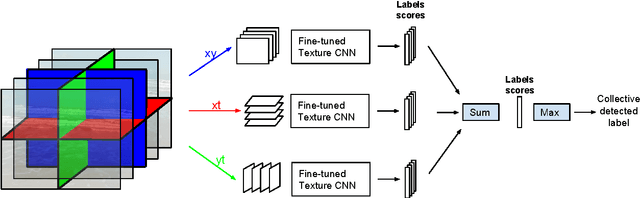
Dynamic Textures (DTs) are sequences of images of moving scenes that exhibit certain stationarity properties in time such as smoke, vegetation and fire. The analysis of DT is important for recognition, segmentation, synthesis or retrieval for a range of applications including surveillance, medical imaging and remote sensing. Deep learning methods have shown impressive results and are now the new state of the art for a wide range of computer vision tasks including image and video recognition and segmentation. In particular, Convolutional Neural Networks (CNNs) have recently proven to be well suited for texture analysis with a design similar to a filter bank approach. In this paper, we develop a new approach to DT analysis based on a CNN method applied on three orthogonal planes x y , xt and y t . We train CNNs on spatial frames and temporal slices extracted from the DT sequences and combine their outputs to obtain a competitive DT classifier. Our results on a wide range of commonly used DT classification benchmark datasets prove the robustness of our approach. Significant improvement of the state of the art is shown on the larger datasets.
Texture segmentation with Fully Convolutional Networks
Mar 15, 2017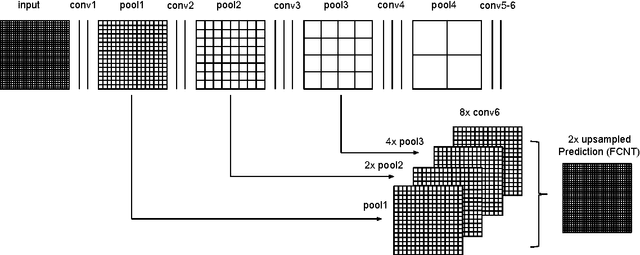

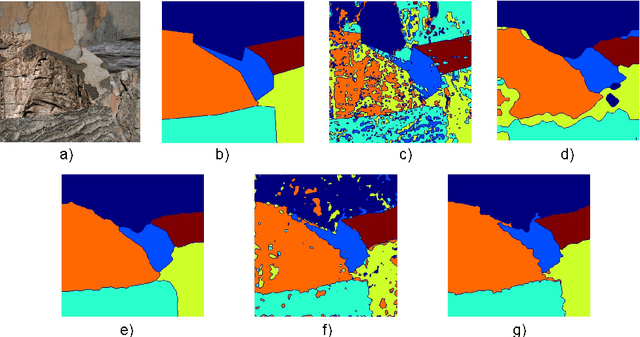
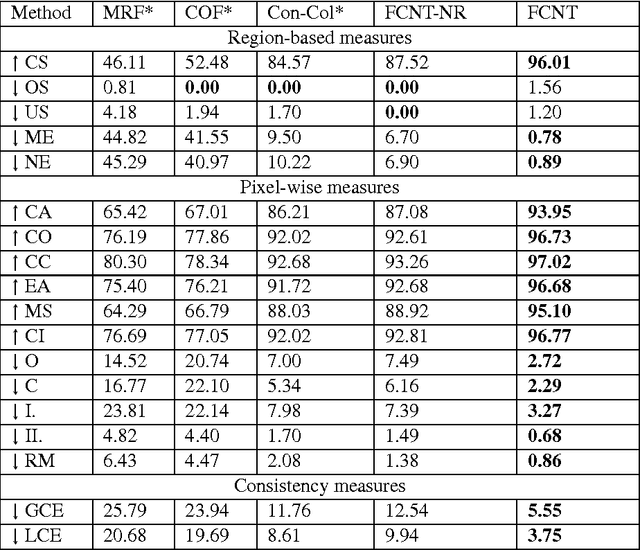
In the last decade, deep learning has contributed to advances in a wide range computer vision tasks including texture analysis. This paper explores a new approach for texture segmentation using deep convolutional neural networks, sharing important ideas with classic filter bank based texture segmentation methods. Several methods are developed to train Fully Convolutional Networks to segment textures in various applications. We show in particular that these networks can learn to recognize and segment a type of texture, e.g. wood and grass from texture recognition datasets (no training segmentation). We demonstrate that Fully Convolutional Networks can learn from repetitive patterns to segment a particular texture from a single image or even a part of an image. We take advantage of these findings to develop a method that is evaluated on a series of supervised and unsupervised experiments and improve the state of the art on the Prague texture segmentation datasets.
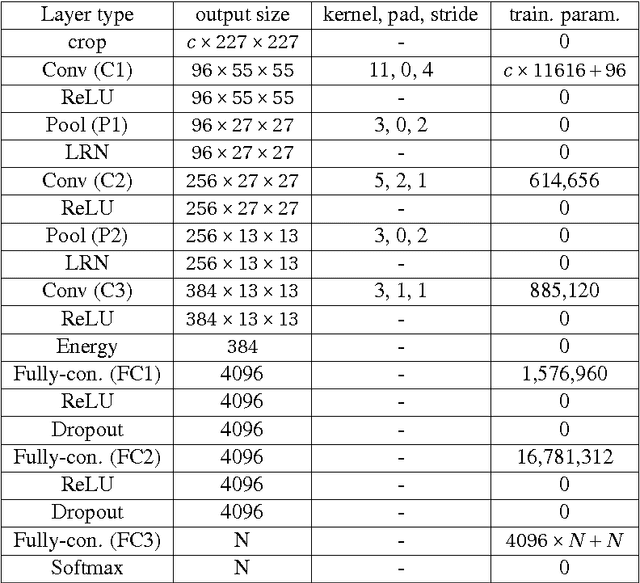
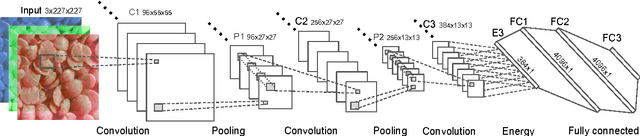
Using Filter Banks in Convolutional Neural Networks for Texture Classification
Sep 23, 2016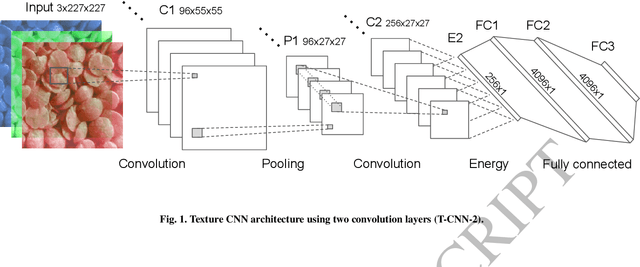


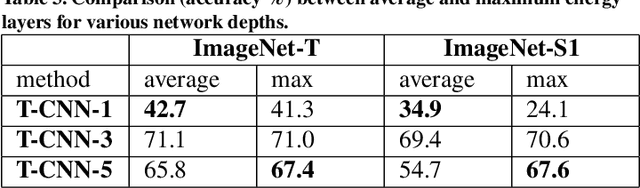
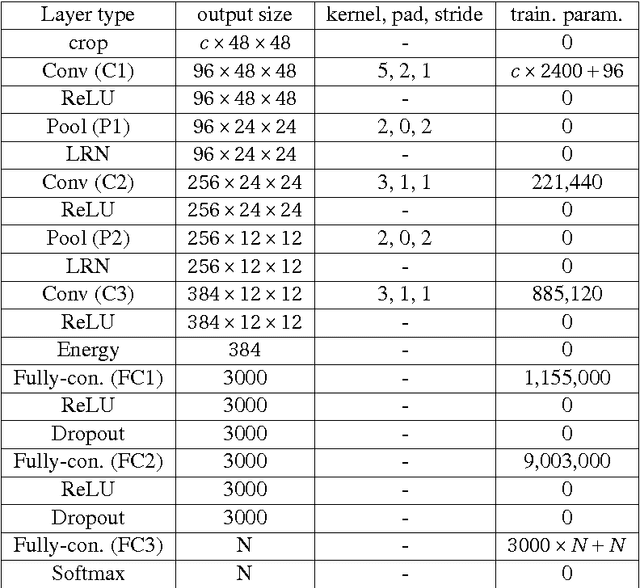
Deep learning has established many new state of the art solutions in the last decade in areas such as object, scene and speech recognition. In particular Convolutional Neural Network (CNN) is a category of deep learning which obtains excellent results in object detection and recognition tasks. Its architecture is indeed well suited to object analysis by learning and classifying complex (deep) features that represent parts of an object or the object itself. However, some of its features are very similar to texture analysis methods. CNN layers can be thought of as filter banks of complexity increasing with the depth. Filter banks are powerful tools to extract texture features and have been widely used in texture analysis. In this paper we develop a simple network architecture named Texture CNN (T-CNN) which explores this observation. It is built on the idea that the overall shape information extracted by the fully connected layers of a classic CNN is of minor importance in texture analysis. Therefore, we pool an energy measure from the last convolution layer which we connect to a fully connected layer. We show that our approach can improve the performance of a network while greatly reducing the memory usage and computation.