 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CP-PINNs: Changepoints Detection in PDEs using Physics Informed Neural Networks with Total-Variation Penalty
Aug 18, 2022
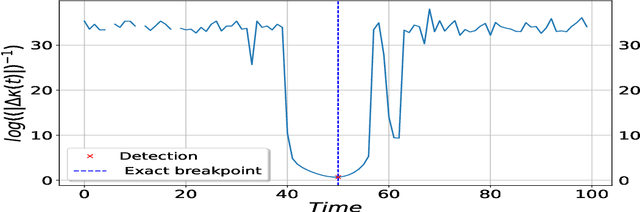
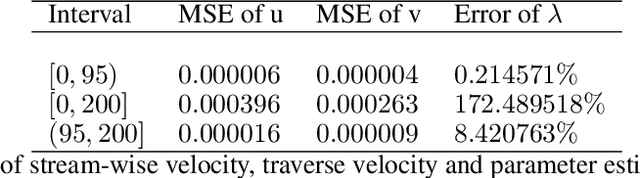
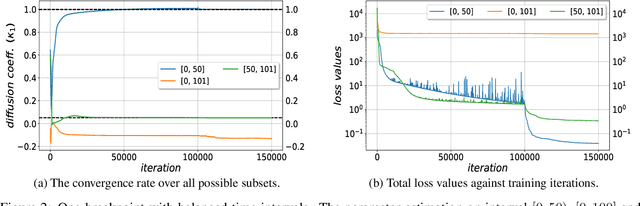
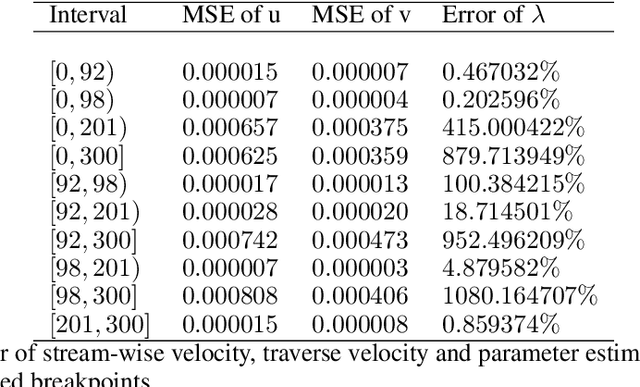
We consider the inverse problem for the Partial Differential Equations (PDEs) such that the parameters of the dependency structure can exhibit random changepoints over time. This can arise, for example, when the physical system is either under malicious attack (e.g., hacker attacks on power grids and internet networks) or subject to extreme external conditions (e.g., weather conditions impacting electricity grids or large market movements impacting valuations of derivative contracts). For that purpose, we employ Physics Informed Neural Networks (PINNs) -- universal approximators that can incorporate prior information from any physical law described by a system of PDEs. This prior knowledge acts in the training of the neural network as a regularization that limits the space of admissible solutions and increases the correctness of the function approximation. We show that when the true data generating process exhibits changepoints in the PDE dynamics, this regularization can lead to a complete miss-calibration and a failure of the model. Therefore, we propose an extension of PINNs using a Total-Variation penalty which accommodates (multiple) changepoints in the PDE dynamics. These changepoints can occur at random locations over time, and they are estimated together with the solutions. We propose an additional refinement algorithm that combines changepoints detection with a reduced dynamic programming method that is feasible for the computationally intensive PINNs methods, and we demonstrate the benefits of the proposed model empirically using examples of different equations with changes in the parameters. In case of no changepoints in the data, the proposed model reduces to the original PINNs model. In the presence of changepoints, it leads to improvements in parameter estimation, better model fitting, and a lower training error compared to the original PINNs model.
Planning under periodic observations: bounds and bounding-based solutions
Aug 05, 2022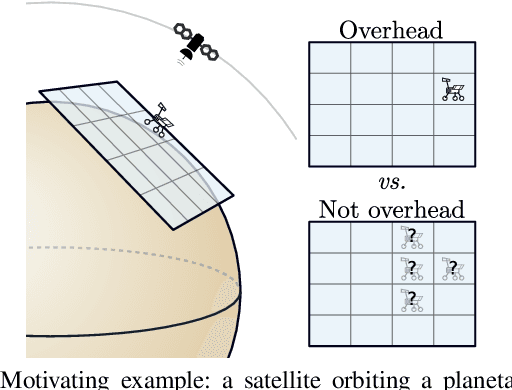
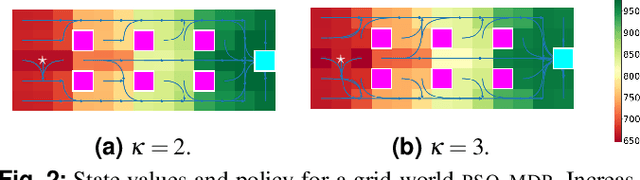
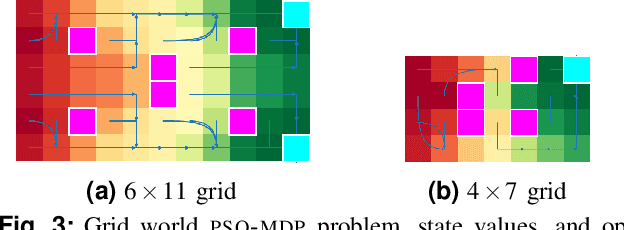
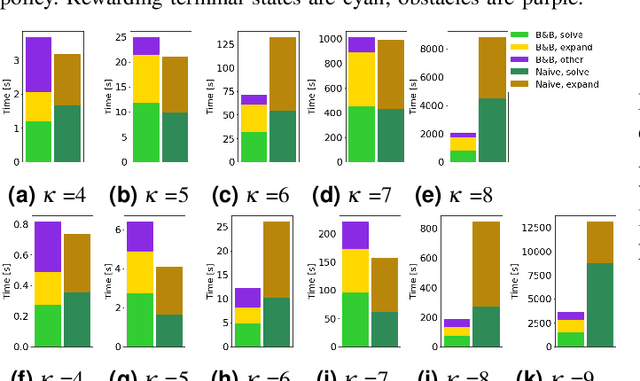
We study planning problems faced by robots operating in uncertain environments with incomplete knowledge of state, and actions that are noisy and/or imprecise. This paper identifies a new problem sub-class that models settings in which information is revealed only intermittently through some exogenous process that provides state information periodically. Several practical domains fit this model, including the specific scenario that motivates our research: autonomous navigation of a planetary exploration rover augmented by remote imaging. With an eye to efficient specialized solution methods, we examine the structure of instances of this sub-class. They lead to Markov Decision Processes with exponentially large action-spaces but for which, as those actions comprise sequences of more atomic elements, one may establish performance bounds by comparing policies under different information assumptions. This provides a way in which to construct performance bounds systematically. Such bounds are useful because, in conjunction with the insights they confer, they can be employed in bounding-based methods to obtain high-quality solutions efficiently; the empirical results we present demonstrate their effectiveness for the considered problems. The foregoing has also alluded to the distinctive role that time plays for these problems -- more specifically: time until information is revealed -- and we uncover and discuss several interesting subtleties in this regard.
Predict+Optimize for Packing and Covering LPs with Unknown Parameters in Constraints
Sep 08, 2022
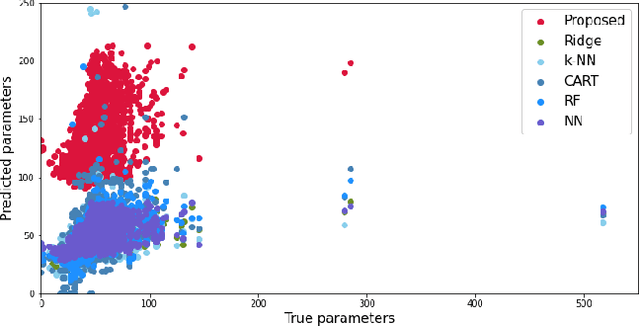


Predict+Optimize is a recently proposed framework which combines machine learning and constrained optimization, tackling optimization problems that contain parameters that are unknown at solving time. The goal is to predict the unknown parameters and use the estimates to solve for an estimated optimal solution to the optimization problem. However, all prior works have focused on the case where unknown parameters appear only in the optimization objective and not the constraints, for the simple reason that if the constraints were not known exactly, the estimated optimal solution might not even be feasible under the true parameters. The contributions of this paper are two-fold. First, we propose a novel and practically relevant framework for the Predict+Optimize setting, but with unknown parameters in both the objective and the constraints. We introduce the notion of a correction function, and an additional penalty term in the loss function, modelling practical scenarios where an estimated optimal solution can be modified into a feasible solution after the true parameters are revealed, but at an additional cost. Second, we propose a corresponding algorithmic approach for our framework, which handles all packing and covering linear programs. Our approach is inspired by the prior work of Mandi and Guns, though with crucial modifications and re-derivations for our very different setting. Experimentation demonstrates the superior empirical performance of our method over classical approaches.
Deep model with built-in self-attention alignment for acoustic echo cancellation
Aug 24, 2022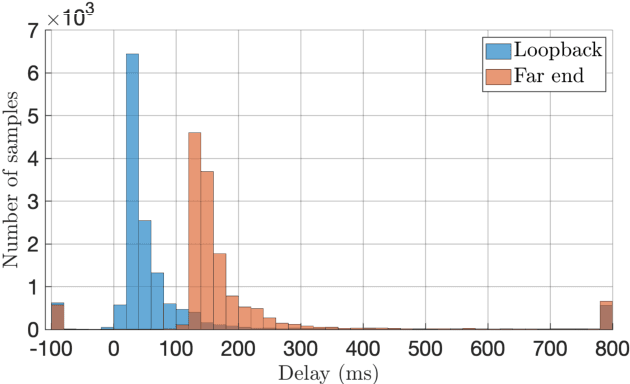

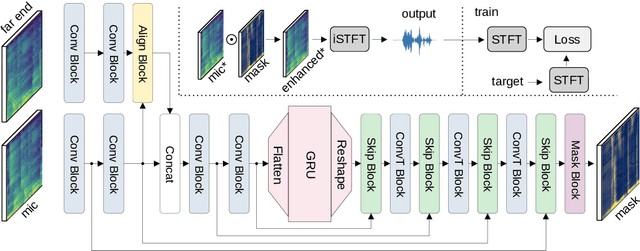
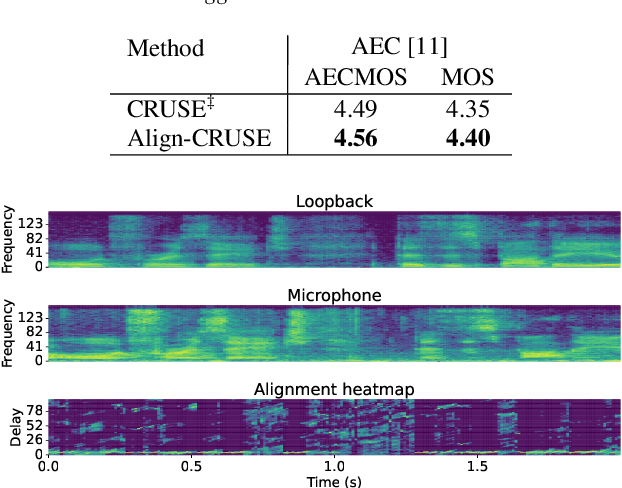
With recent research advances, deep learning models have become an attractive choice for acoustic echo cancellation (AEC) in real-time teleconferencing applications. Since acoustic echo is one of the major sources of poor audio quality, a wide variety of deep models have been proposed. However, an important but often omitted requirement for good echo cancellation quality is the synchronization of the microphone and far end signals. Typically implemented using classical algorithms based on cross-correlation, the alignment module is a separate functional block with known design limitations. In our work we propose a deep learning architecture with built-in self-attention based alignment, which is able to handle unaligned inputs, improving echo cancellation performance while simplifying the communication pipeline. Moreover, we show that our approach achieves significant improvements for difficult delay estimation cases on real recordings from AEC Challenge data set.
j-Wave: An open-source differentiable wave simulator
Jun 30, 2022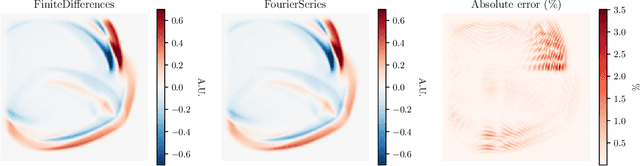
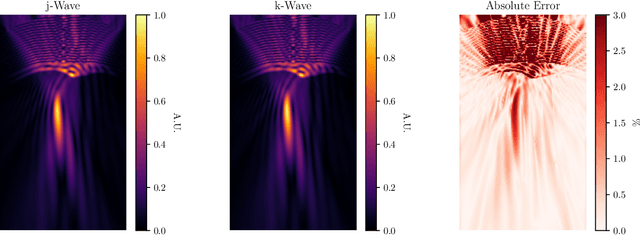
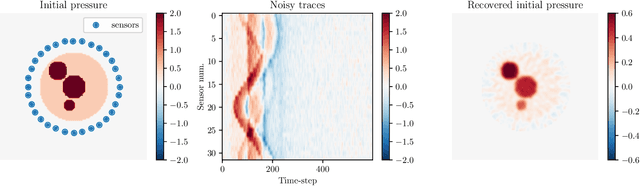
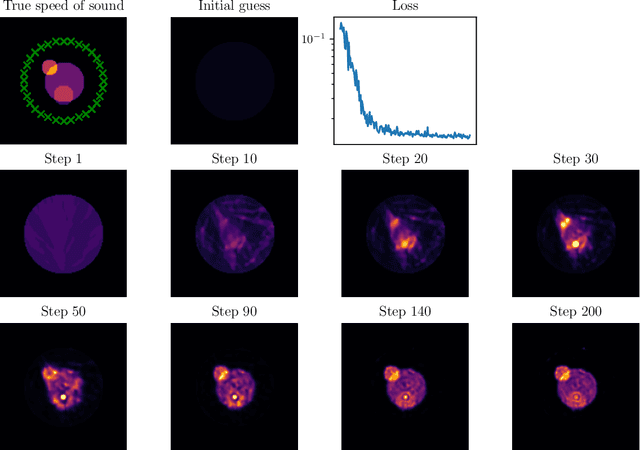
We present an open-source differentiable acoustic simulator, j-Wave, which can solve time-varying and time-harmonic acoustic problems. It supports automatic differentiation, which is a program transformation technique that has many applications, especially in machine learning and scientific computing. j-Wave is composed of modular components that can be easily customized and reused. At the same time, it is compatible with some of the most popular machine learning libraries, such as JAX and TensorFlow. The accuracy of the simulation results for known configurations is evaluated against the widely used k-Wave toolbox and a cohort of acoustic simulation software. j-Wave is available from https://github.com/ucl-bug/jwave.
RESAM: Requirements Elicitation and Specification for Deep-Learning Anomaly Models with Applications to UAV Flight Controllers
Jul 18, 2022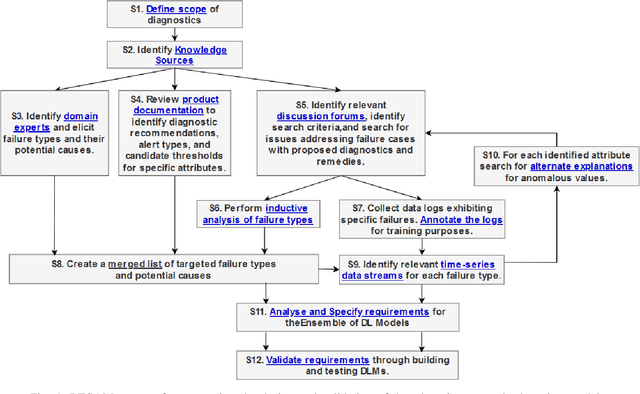
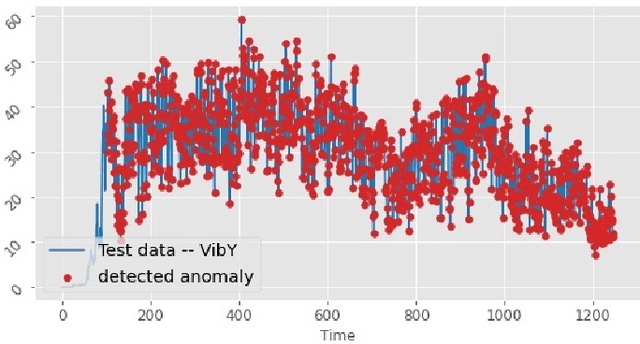
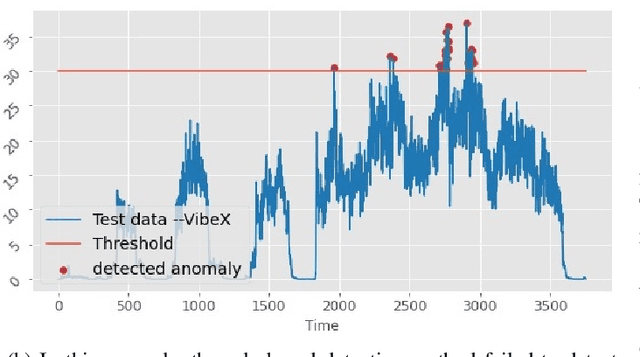
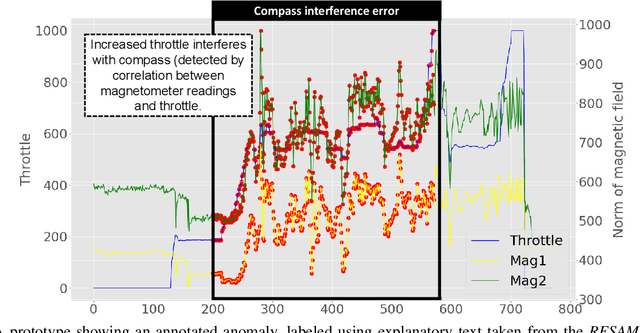
CyberPhysical systems (CPS) must be closely monitored to identify and potentially mitigate emergent problems that arise during their routine operations. However, the multivariate time-series data which they typically produce can be complex to understand and analyze. While formal product documentation often provides example data plots with diagnostic suggestions, the sheer diversity of attributes, critical thresholds, and data interactions can be overwhelming to non-experts who subsequently seek help from discussion forums to interpret their data logs. Deep learning models, such as Long Short-term memory (LSTM) networks can be used to automate these tasks and to provide clear explanations of diverse anomalies detected in real-time multivariate data-streams. In this paper we present RESAM, a requirements process that integrates knowledge from domain experts, discussion forums, and formal product documentation, to discover and specify requirements and design definitions in the form of time-series attributes that contribute to the construction of effective deep learning anomaly detectors. We present a case-study based on a flight control system for small Uncrewed Aerial Systems and demonstrate that its use guides the construction of effective anomaly detection models whilst also providing underlying support for explainability. RESAM is relevant to domains in which open or closed online forums provide discussion support for log analysis.
A Time-Optimized Content Creation Workflow for Remote Teaching
Oct 13, 2021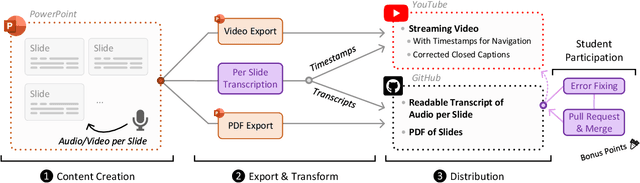
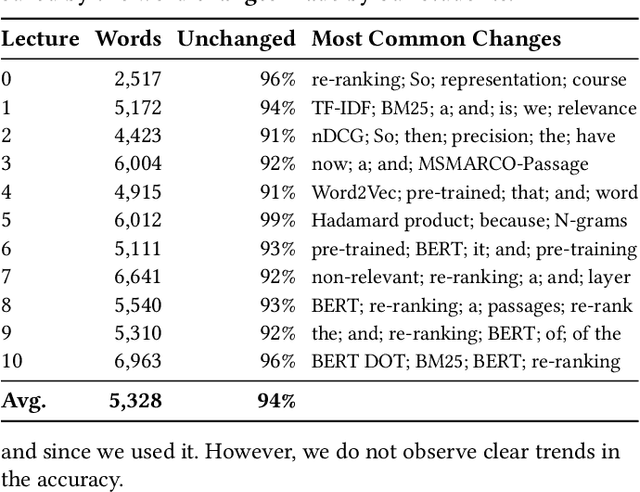
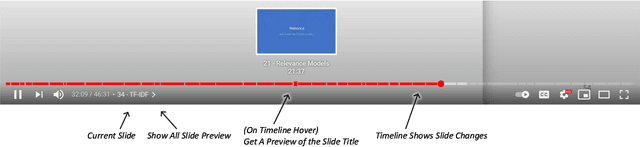

We describe our workflow to create an engaging remote learning experience for a university course, while minimizing the post-production time of the educators. We make use of ubiquitous and commonly free services and platforms, so that our workflow is inclusive for all educators and provides polished experiences for students. Our learning materials provide for each lecture: 1) a recorded video, uploaded on YouTube, with exact slide timestamp indices, which enables an enhanced navigation UI; and 2) a high-quality flow-text automated transcript of the narration with proper punctuation and capitalization, improved with a student participation workflow on GitHub. All these results could be created by hand in a time consuming and costly way. However, this would generally exceed the time available for creating course materials. Our main contribution is to automate the transformation and post-production between raw narrated slides and our published materials with a custom toolchain. Furthermore, we describe our complete workflow: from content creation to transformation and distribution. Our students gave us overwhelmingly positive feedback and especially liked our use of ubiquitous platforms. The most used feature was YouTube's chapter UI enabled through our automatically generated timestamps. The majority of students, who started using the transcripts, continued to do so. Every single transcript was corrected by students, with an average word-change of 6%. We conclude with the positive feedback that our enhanced content formats are much appreciated and utilized. Important for educators is how our low overhead production workflow was sustainable throughout a busy semester.
SENDER: SEmi-Nonlinear Deep Efficient Reconstructor for Extraction Canonical, Meta, and Sub Functional Connectivity in the Human Brain
Sep 12, 2022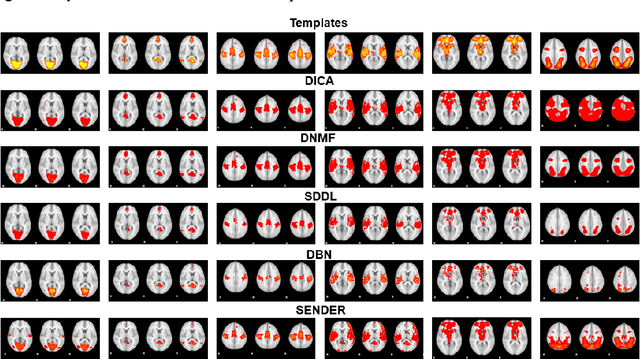
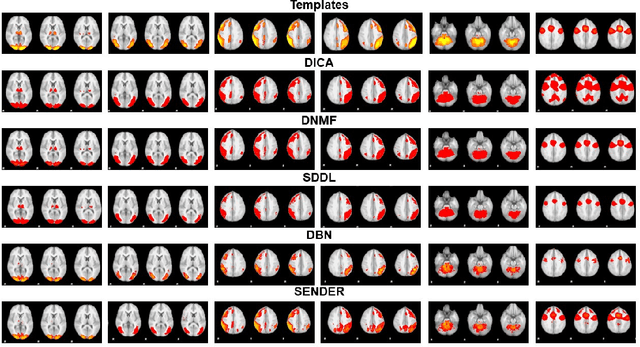
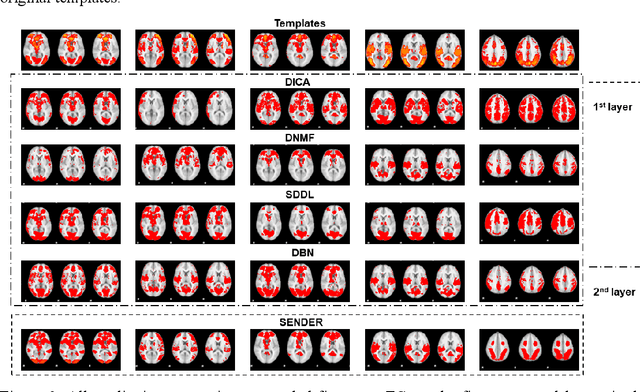
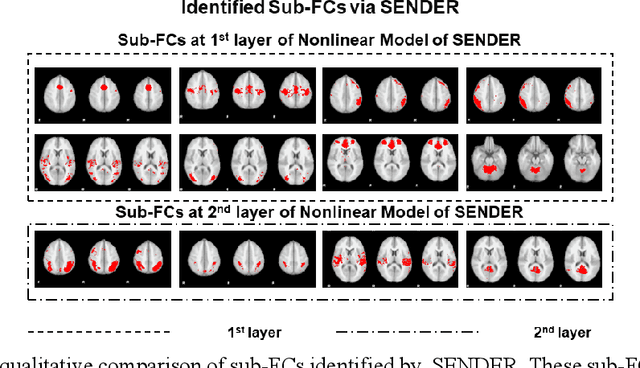
Deep Linear and Nonlinear learning methods have already been vital machine learning methods for investigating the hierarchical features such as functional connectivity in the human brain via functional Magnetic Resonance signals; however, there are three major shortcomings: 1). For deep linear learning methods, although the identified hierarchy of functional connectivity is easily explainable, it is challenging to reveal more hierarchical functional connectivity; 2). For deep nonlinear learning methods, although non-fully connected architecture reduces the complexity of neural network structures that are easy to optimize and not vulnerable to overfitting, the functional connectivity hierarchy is difficult to explain; 3). Importantly, it is challenging for Deep Linear/Nonlinear methods to detect meta and sub-functional connectivity even in the shallow layers; 4). Like most conventional Deep Nonlinear Methods, such as Deep Neural Networks, the hyperparameters must be tuned manually, which is time-consuming. Thus, in this work, we propose a novel deep hybrid learning method named SEmi-Nonlinear Deep Efficient Reconstruction (SENDER), to overcome the aforementioned shortcomings: 1). SENDER utilizes a multiple-layer stacked structure for the linear learning methods to detect the canonical functional connectivity; 2). SENDER implements a non-fully connected architecture conducted for the nonlinear learning methods to reveal the meta-functional connectivity through shallow and deeper layers; 3). SENDER incorporates the proposed background components to extract the sub-functional connectivity; 4). SENDER adopts a novel rank reduction operator to implement the hyperparameters tuning automatically. To further validate the effectiveness, we compared SENDER with four peer methodologies using real functional Magnetic Resonance Imaging data for the human brain.
Driving Safety Prediction and Safe Route Mapping Using In-vehicle and Roadside Data
Sep 12, 2022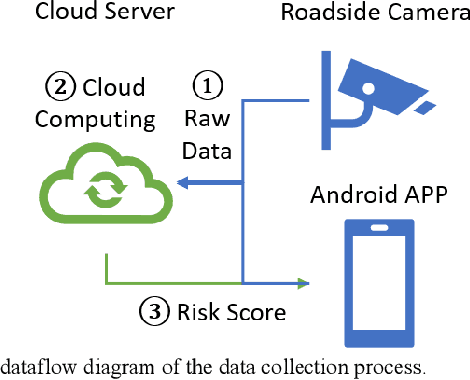
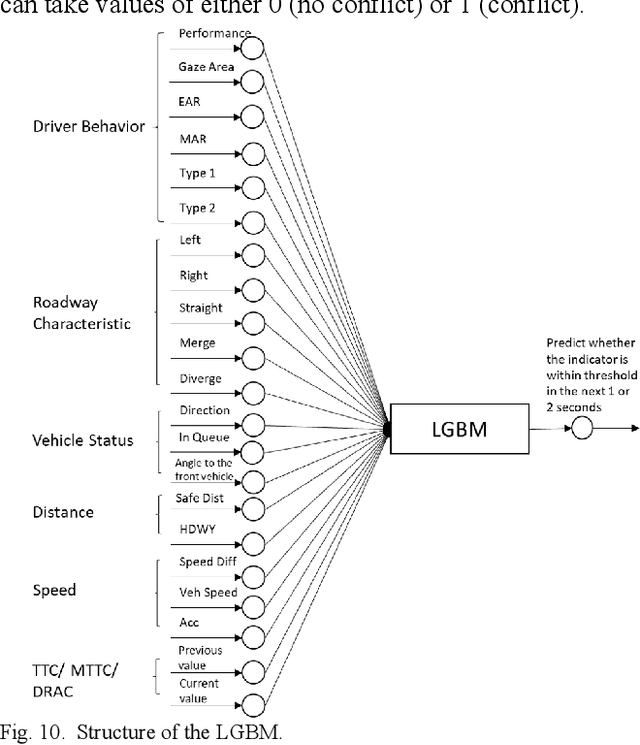
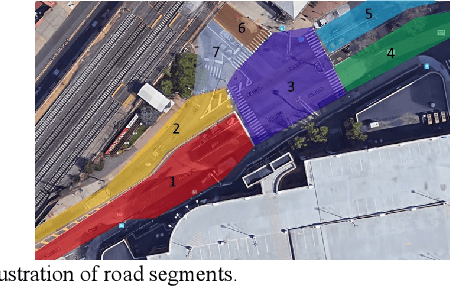
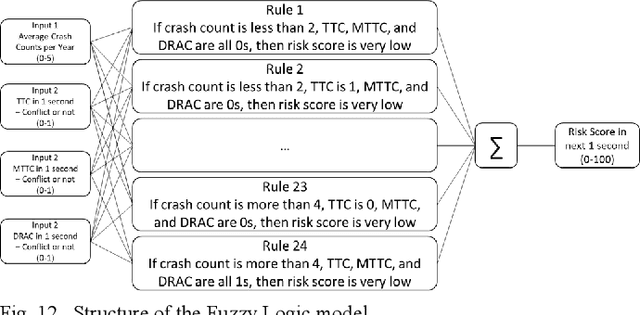
Risk assessment of roadways is commonly practiced based on historical crash data. Information on driver behaviors and real-time traffic situations is sometimes missing. In this paper, the Safe Route Mapping (SRM) model, a methodology for developing dynamic risk heat maps of roadways, is extended to consider driver behaviors when making predictions. An Android App is designed to gather drivers' information and upload it to a server. On the server, facial recognition extracts drivers' data, such as facial landmarks, gaze directions, and emotions. The driver's drowsiness and distraction are detected, and driving performance is evaluated. Meanwhile, dynamic traffic information is captured by a roadside camera and uploaded to the same server. A longitudinal-scanline-based arterial traffic video analytics is applied to recognize vehicles from the video to build speed and trajectory profiles. Based on these data, a LightGBM model is introduced to predict conflict indices for drivers in the next one or two seconds. Then, multiple data sources, including historical crash counts and predicted traffic conflict indicators, are combined using a Fuzzy logic model to calculate risk scores for road segments. The proposed SRM model is illustrated using data collected from an actual traffic intersection and a driving simulation platform. The prediction results show that the model is accurate, and the added driver behavior features will improve the model's performance. Finally, risk heat maps are generated for visualization purposes. The authorities can use the dynamic heat map to designate safe corridors and dispatch law enforcement and drivers for early warning and trip planning.
Greykite: Deploying Flexible Forecasting at Scale at LinkedIn
Jul 15, 2022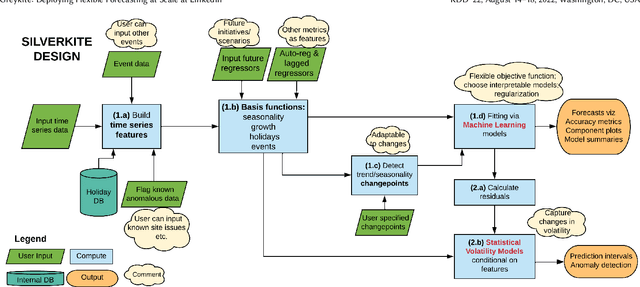
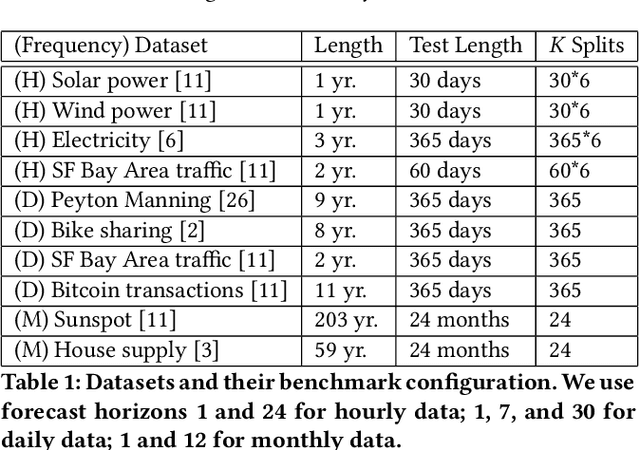
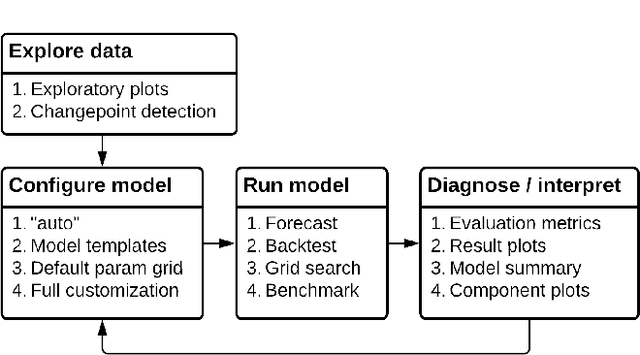
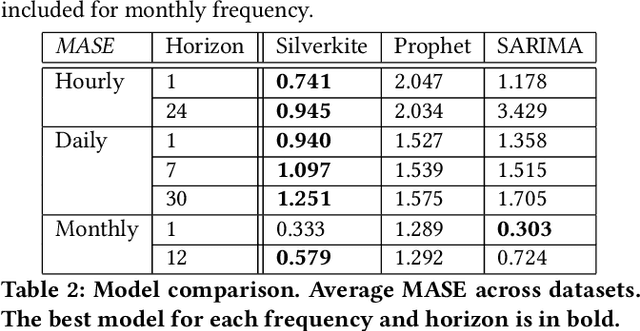
Forecasts help businesses allocate resources and achieve objectives. At LinkedIn, product owners use forecasts to set business targets, track outlook, and monitor health. Engineers use forecasts to efficiently provision hardware. Developing a forecasting solution to meet these needs requires accurate and interpretable forecasts on diverse time series with sub-hourly to quarterly frequencies. We present Greykite, an open-source Python library for forecasting that has been deployed on over twenty use cases at LinkedIn. Its flagship algorithm, Silverkite, provides interpretable, fast, and highly flexible univariate forecasts that capture effects such as time-varying growth and seasonality, autocorrelation, holidays, and regressors. The library enables self-serve accuracy and trust by facilitating data exploration, model configuration, execution, and interpretation. Our benchmark results show excellent out-of-the-box speed and accuracy on datasets from a variety of domains. Over the past two years, Greykite forecasts have been trusted by Finance, Engineering, and Product teams for resource planning and allocation, target setting and progress tracking, anomaly detection and root cause analysis. We expect Greykite to be useful to forecast practitioners with similar applications who need accurate, interpretable forecasts that capture complex dynamics common to time series related to human activity.