 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Highly precise AMCW time-of-flight scanning sensor based on digital-parallel demodulation
Dec 16, 2021
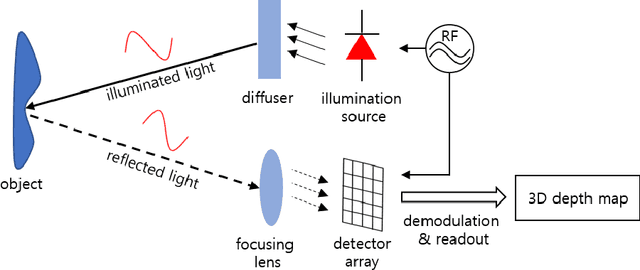
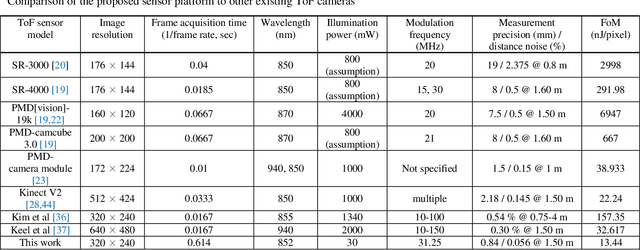
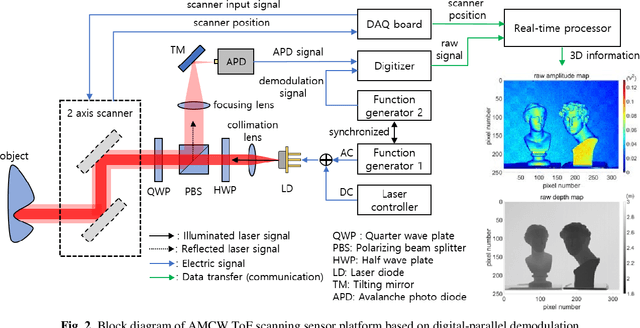
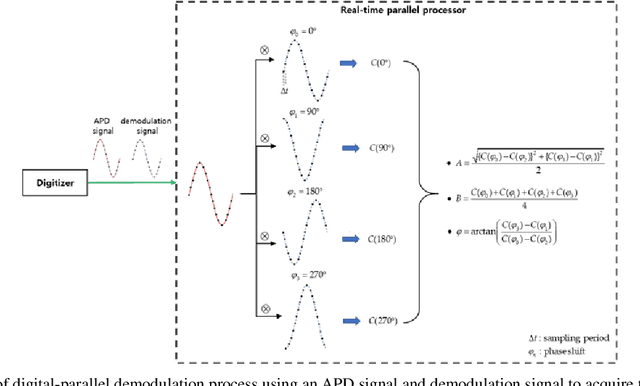
In this paper, a novel amplitude-modulated continuous wave (AMCW) time-of-flight (ToF) scanning sensor based on digital-parallel demodulation is proposed and demonstrated in the aspect of distance measurement precision. Since digital-parallel demodulation utilizes a high-amplitude demodulation signal with zero-offset, the proposed sensor platform can maintain extremely high demodulation contrast. Meanwhile, as all cross correlated samples are calculated in parallel and in extremely short integration time, the proposed sensor platform can utilize a 2D laser scanning structure with a single photo detector, maintaining a moderate frame rate. This optical structure can increase the received optical SNR and remove the crosstalk of image pixel array. Based on these measurement properties, the proposed AMCW ToF scanning sensor shows highly precise 3D depth measurement performance. In this study, this precise measurement performance is explained in detail. Additionally, the actual measurement performance of the proposed sensor platform is experimentally validated under various conditions.
A general class of combinatorial filters that can be minimized efficiently
Sep 10, 2022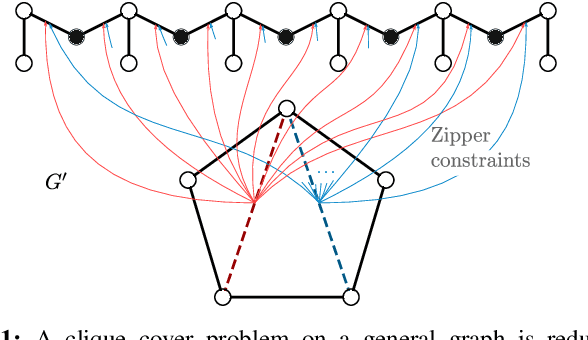
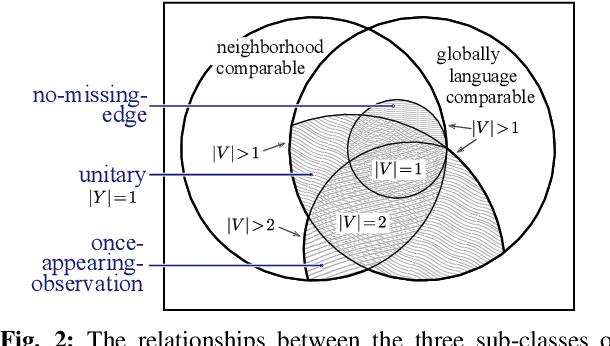
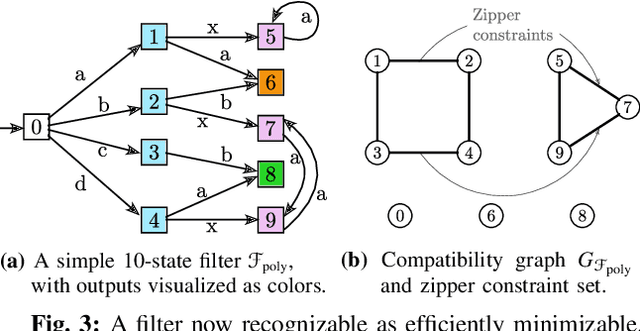
State minimization of combinatorial filters is a fundamental problem that arises, for example, in building cheap, resource-efficient robots. But exact minimization is known to be NP-hard. This paper conducts a more nuanced analysis of this hardness than up till now, and uncovers two factors which contribute to this complexity. We show each factor is a distinct source of the problem's hardness and are able, thereby, to shed some light on the role played by (1) structure of the graph that encodes compatibility relationships, and (2) determinism-enforcing constraints. Just as a line of prior work has sought to introduce additional assumptions and identify sub-classes that lead to practical state reduction, we next use this new, sharper understanding to explore special cases for which exact minimization is efficient. We introduce a new algorithm for constraint repair that applies to a large sub-class of filters, subsuming three distinct special cases for which the possibility of optimal minimization in polynomial time was known earlier. While the efficiency in each of these three cases appeared, previously, to stem from seemingly dissimilar properties, when seen through the lens of the present work, their commonality now becomes clear. We also provide entirely new families of filters that are efficiently reducible.
Adam Mickiewicz University at WMT 2022: NER-Assisted and Quality-Aware Neural Machine Translation
Sep 07, 2022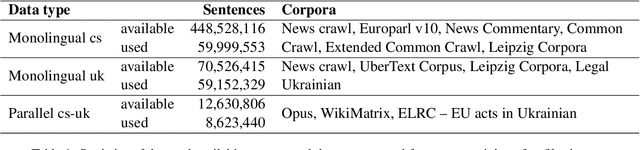
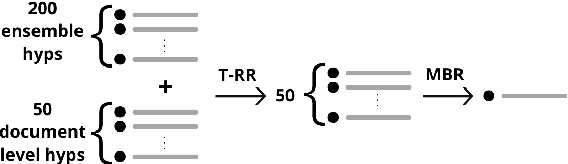
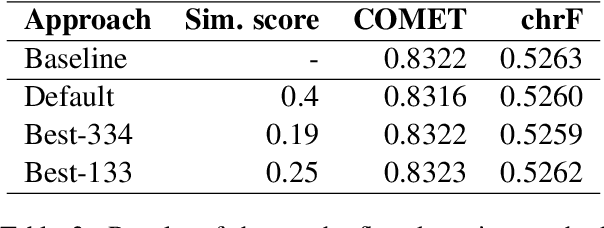
This paper presents Adam Mickiewicz University's (AMU) submissions to the constrained track of the WMT 2022 General MT Task. We participated in the Ukrainian $\leftrightarrow$ Czech translation directions. The systems are a weighted ensemble of four models based on the Transformer (big) architecture. The models use source factors to utilize the information about named entities present in the input. Each of the models in the ensemble was trained using only the data provided by the shared task organizers. A noisy back-translation technique was used to augment the training corpora. One of the models in the ensemble is a document-level model, trained on parallel and synthetic longer sequences. During the sentence-level decoding process, the ensemble generated the n-best list. The n-best list was merged with the n-best list generated by a single document-level model which translated multiple sentences at a time. Finally, existing quality estimation models and minimum Bayes risk decoding were used to rerank the n-best list so that the best hypothesis was chosen according to the COMET evaluation metric. According to the automatic evaluation results, our systems rank first in both translation directions.
Improving Accuracy and Explainability of Online Handwriting Recognition
Sep 14, 2022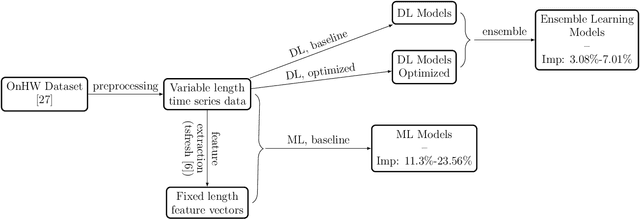
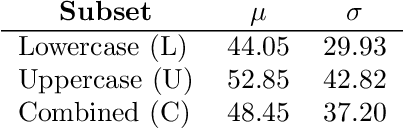
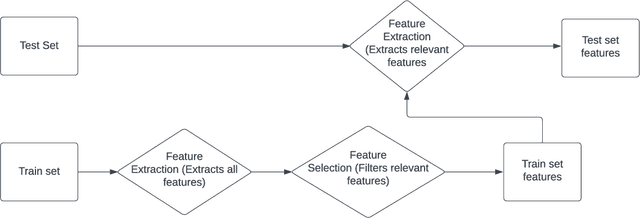
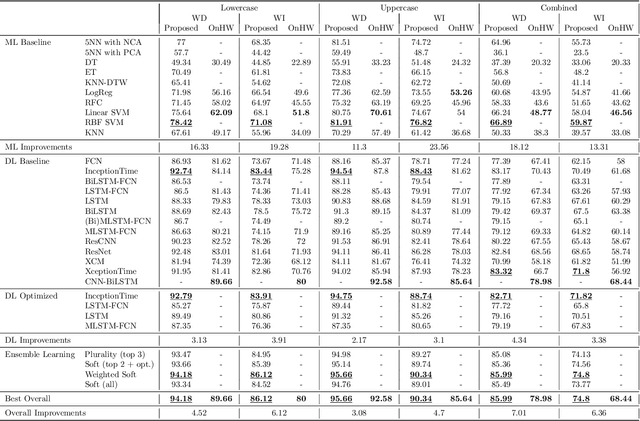
Handwriting recognition technology allows recognizing a written text from a given data. The recognition task can target letters, symbols, or words, and the input data can be a digital image or recorded by various sensors. A wide range of applications from signature verification to electronic document processing can be realized by implementing efficient and accurate handwriting recognition algorithms. Over the years, there has been an increasing interest in experimenting with different types of technology to collect handwriting data, create datasets, and develop algorithms to recognize characters and symbols. More recently, the OnHW-chars dataset has been published that contains multivariate time series data of the English alphabet collected using a ballpoint pen fitted with sensors. The authors of OnHW-chars also provided some baseline results through their machine learning (ML) and deep learning (DL) classifiers. In this paper, we develop handwriting recognition models on the OnHW-chars dataset and improve the accuracy of previous models. More specifically, our ML models provide $11.3\%$-$23.56\%$ improvements over the previous ML models, and our optimized DL models with ensemble learning provide $3.08\%$-$7.01\%$ improvements over the previous DL models. In addition to our accuracy improvements over the spectrum, we aim to provide some level of explainability for our models to provide more logic behind chosen methods and why the models make sense for the data type in the dataset. Our results are verifiable and reproducible via the provided public repository.
Cross-Camera View-Overlap Recognition
Aug 24, 2022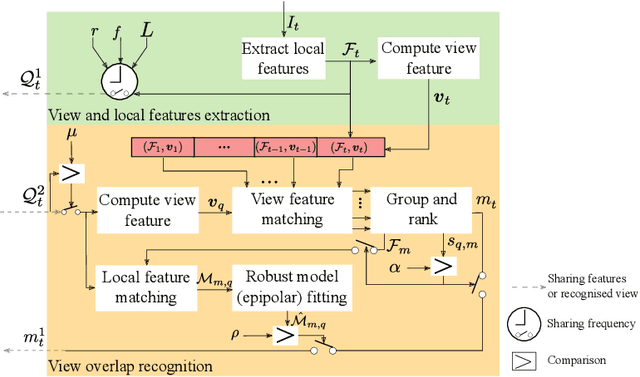
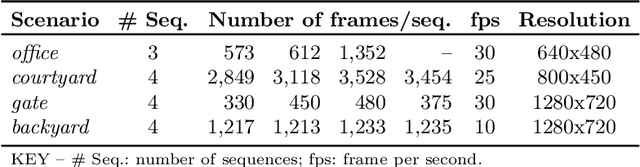
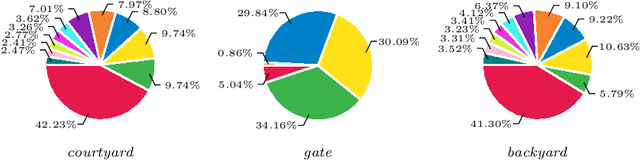
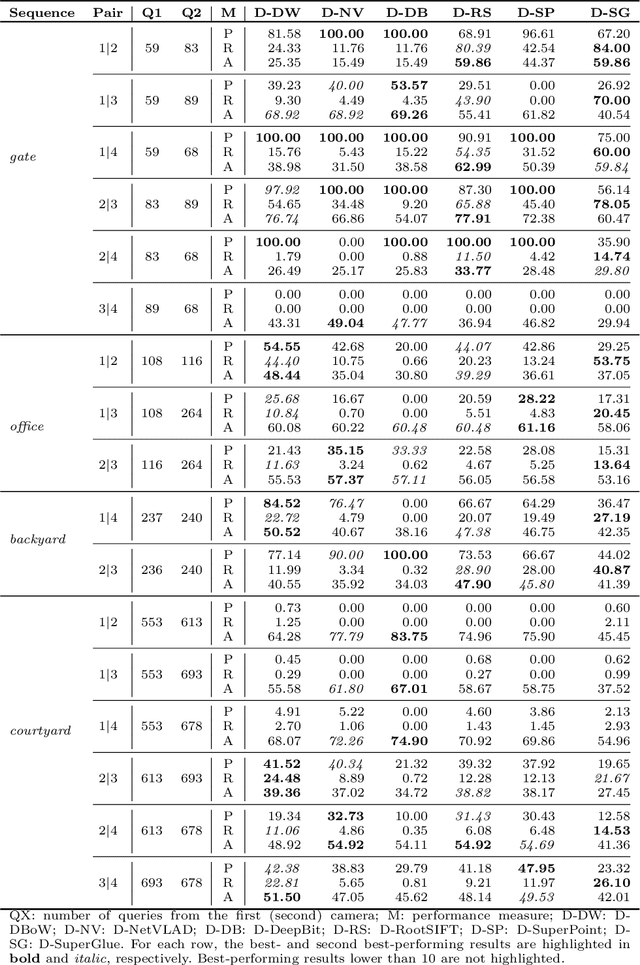
We propose a decentralised view-overlap recognition framework that operates across freely moving cameras without the need of a reference 3D map. Each camera independently extracts, aggregates into a hierarchical structure, and shares feature-point descriptors over time. A view overlap is recognised by view-matching and geometric validation to discard wrongly matched views. The proposed framework is generic and can be used with different descriptors. We conduct the experiments on publicly available sequences as well as new sequences we collected with hand-held cameras. We show that Oriented FAST and Rotated BRIEF (ORB) features with Bags of Binary Words within the proposed framework lead to higher precision and a higher or similar accuracy compared to NetVLAD, RootSIFT, and SuperGlue.
Mapping Husserlian phenomenology onto active inference
Aug 24, 2022
Phenomenology is the rigorous descriptive study of conscious experience. Recent attempts to formalize Husserlian phenomenology provide us with a mathematical model of perception as a function of prior knowledge and expectation. In this paper, we re-examine elements of Husserlian phenomenology through the lens of active inference. In doing so, we aim to advance the project of computational phenomenology, as recently outlined by proponents of active inference. We propose that key aspects of Husserl's descriptions of consciousness can be mapped onto aspects of the generative models associated with the active inference approach. We first briefly review active inference. We then discuss Husserl's phenomenology, with a focus on time consciousness. Finally, we present our mapping from Husserlian phenomenology to active inference.
A Data-dependent Approach for High Dimensional (Robust) Wasserstein Alignment
Sep 07, 2022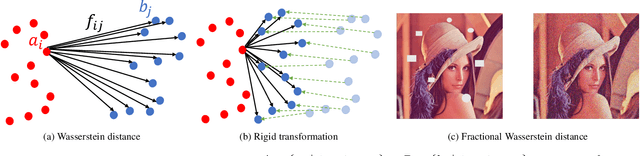
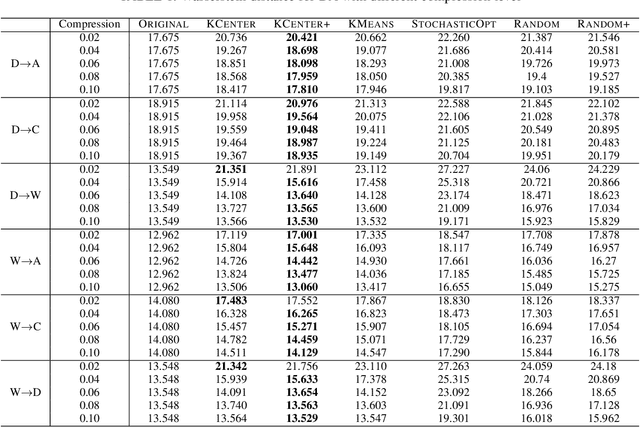
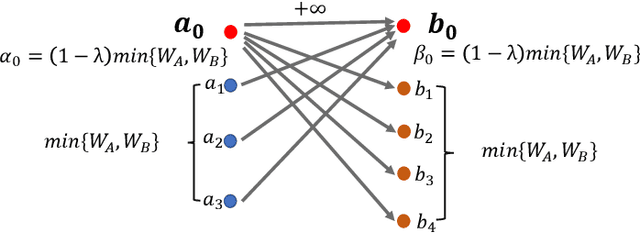
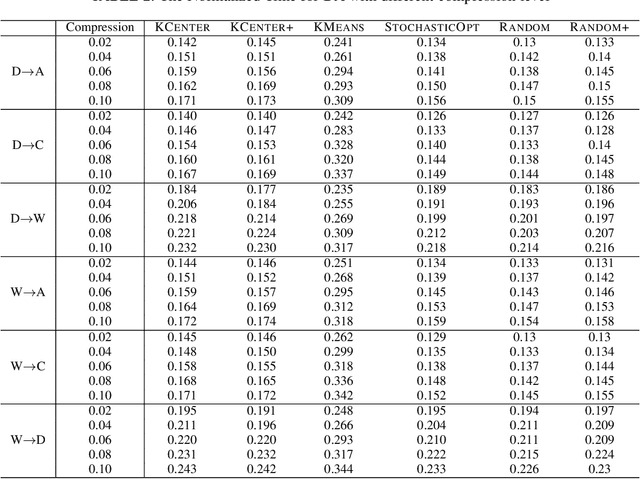
Many real-world problems can be formulated as the alignment between two geometric patterns. Previously, a great amount of research focus on the alignment of 2D or 3D patterns in the field of computer vision. Recently, the alignment problem in high dimensions finds several novel applications in practice. However, the research is still rather limited in the algorithmic aspect. To the best of our knowledge, most existing approaches are just simple extensions of their counterparts for 2D and 3D cases, and often suffer from the issues such as high computational complexities. In this paper, we propose an effective framework to compress the high dimensional geometric patterns. Any existing alignment method can be applied to the compressed geometric patterns and the time complexity can be significantly reduced. Our idea is inspired by the observation that high dimensional data often has a low intrinsic dimension. Our framework is a "data-dependent" approach that has the complexity depending on the intrinsic dimension of the input data. Our experimental results reveal that running the alignment algorithm on compressed patterns can achieve similar qualities, comparing with the results on the original patterns, but the runtimes (including the times cost for compression) are substantially lower.
Multi tasks RetinaNet for mitosis detection
Aug 26, 2022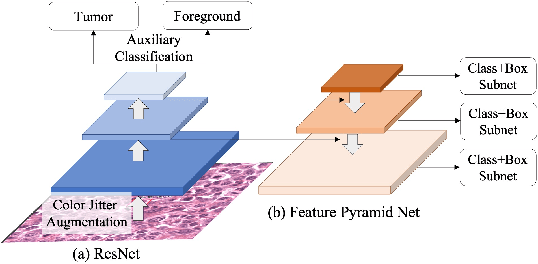
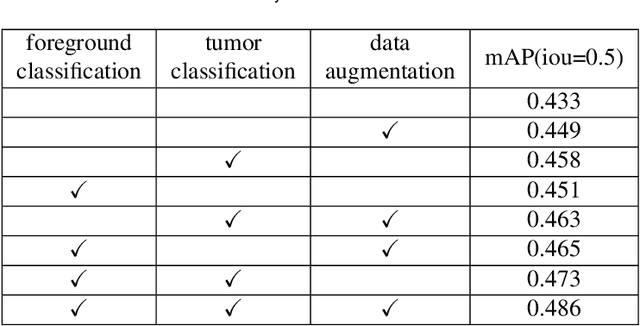
The account of mitotic cells is a key feature in tumor diagnosis. However, due to the variability of mitotic cell morphology, it is a highly challenging task to detect mitotic cells in tumor tissues. At the same time, although advanced deep learning method have achieved great success in cell detection, the performance is often unsatisfactory when tested data from another domain (i.e. the different tumor types and different scanners). Therefore, it is necessary to develop algorithms for detecting mitotic cells with robustness in domain shifts scenarios. Our work further proposes a foreground detection and tumor classification task based on the baseline(Retinanet), and utilizes data augmentation to improve the domain generalization performance of our model. We achieve the state-of-the-art performance (F1 score: 0.5809) on the challenging premilary test dataset.
Noise reduction in Laguerre-domain discrete delay estimation
Jul 26, 2022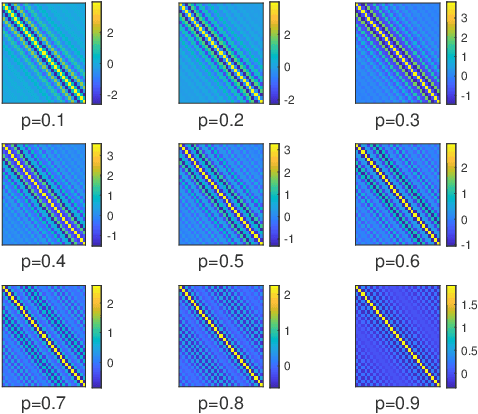
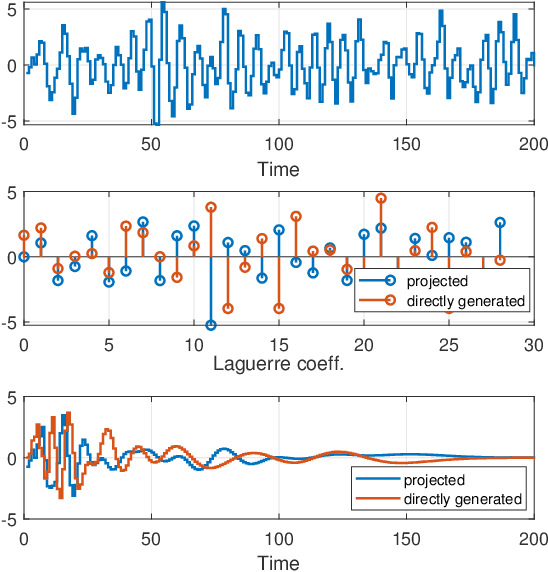
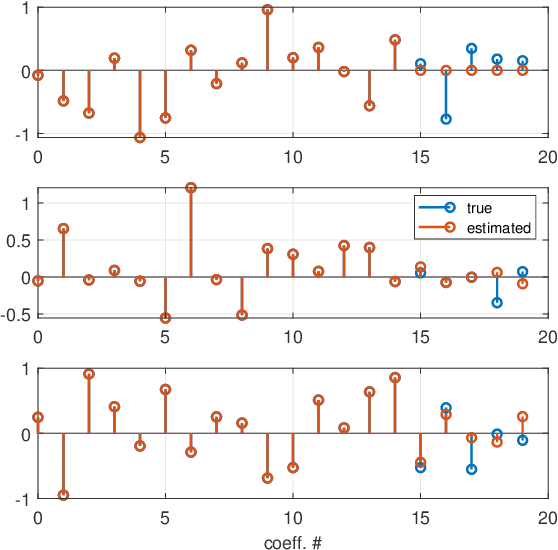
This paper introduces a stochastic framework for a recently proposed discrete-time delay estimation method in Laguerre-domain, i.e. with the delay block input and output signals being represented by the corresponding Laguerre series. A novel Laguerre domain disturbance model is devised, which allows the involved signals to be square-summable sequences and is suitable in a number of important applications. The relation to two commonly used time-domain disturbance models is clarified. Furthermore, by forming the input signal in a certain way, the signal shape of an additive output disturbance can be estimated and utilized for noise reduction. It is demonstrated that a significant improvement in the delay estimation error is achieved when the noise sequence is correlated. The noise reduction approach is applicable to other Laguerre-domain problems than pure delay estimation.
High Probability Bounds for Stochastic Subgradient Schemes with Heavy Tailed Noise
Aug 17, 2022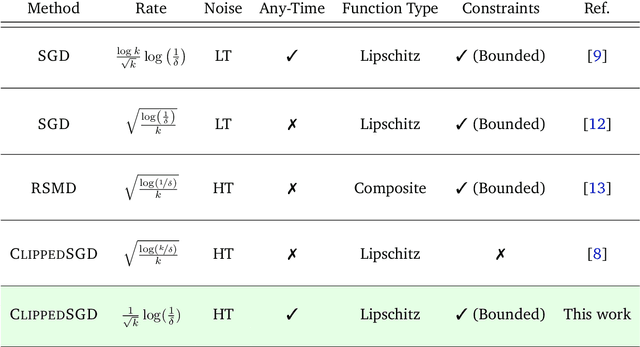
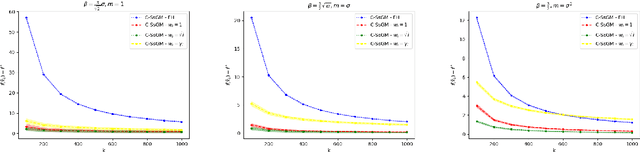

In this work we study high probability bounds for stochastic subgradient methods under heavy tailed noise. In this case the noise is only assumed to have finite variance as opposed to a sub-Gaussian distribution for which it is known that standard subgradient methods enjoys high probability bounds. We analyzed a clipped version of the projected stochastic subgradient method, where subgradient estimates are truncated whenever they have large norms. We show that this clipping strategy leads both to near optimal any-time and finite horizon bounds for many classical averaging schemes. Preliminary experiments are shown to support the validity of the method.