 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time-Optimal Planning for Quadrotor Waypoint Flight
Aug 10, 2021
Quadrotors are among the most agile flying robots. However, planning time-optimal trajectories at the actuation limit through multiple waypoints remains an open problem. This is crucial for applications such as inspection, delivery, search and rescue, and drone racing. Early works used polynomial trajectory formulations, which do not exploit the full actuator potential because of their inherent smoothness. Recent works resorted to numerical optimization but require waypoints to be allocated as costs or constraints at specific discrete times. However, this time allocation is a priori unknown and renders previous works incapable of producing truly time-optimal trajectories. To generate truly time-optimal trajectories, we propose a solution to the time allocation problem while exploiting the full quadrotor's actuator potential. We achieve this by introducing a formulation of progress along the trajectory, which enables the simultaneous optimization of the time allocation and the trajectory itself. We compare our method against related approaches and validate it in real-world flights in one of the world's largest motion-capture systems, where we outperform human expert drone pilots in a drone-racing task.
* Narrated video footage available at https://youtu.be/ZPI8U1uSJUs
A Near-Optimal Algorithm for Univariate Zeroth-Order Budget Convex Optimization
Aug 13, 2022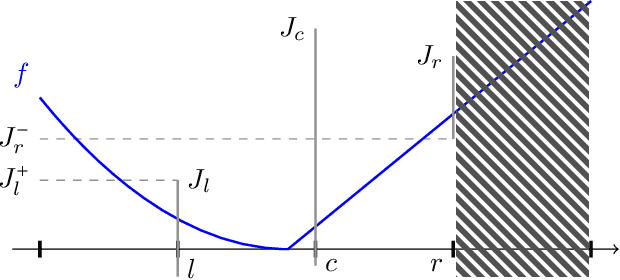
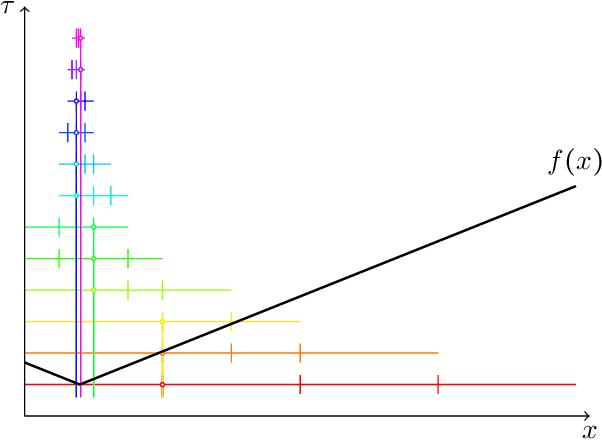
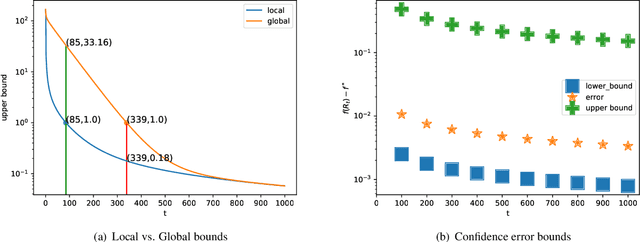
This paper studies a natural generalization of the problem of minimizing a univariate convex function $f$ by querying its values sequentially. At each time-step $t$, the optimizer can invest a budget $b_t$ in a query point $X_t$ of their choice to obtain a fuzzy evaluation of $f$ at $X_t$ whose accuracy depends on the amount of budget invested in $X_t$ across times. This setting is motivated by the minimization of objectives whose values can only be determined approximately through lengthy or expensive computations. We design an any-time parameter-free algorithm called Dyadic Search, for which we prove near-optimal optimization error guarantees. As a byproduct of our analysis, we show that the classical dependence on the global Lipschitz constant in the error bounds is an artifact of the granularity of the budget. Finally, we illustrate our theoretical findings with numerical simulations.
A Deep Learning-based Approach for Real-time Facemask Detection
Oct 17, 2021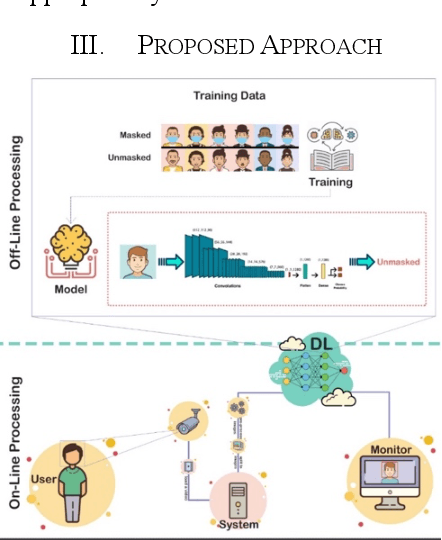
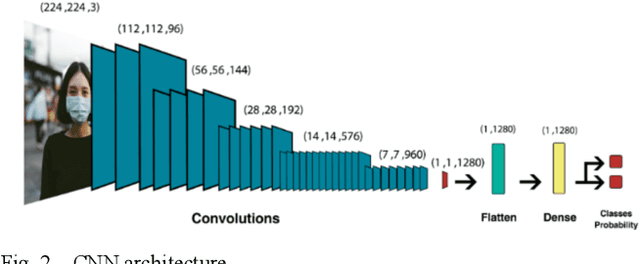
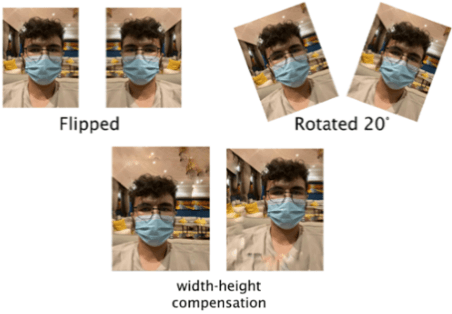

The COVID-19 pandemic is causing a global health crisis. Public spaces need to be safeguarded from the adverse effects of this pandemic. Wearing a facemask becomes one of the effective protection solutions adopted by many governments. Manual real-time monitoring of facemask wearing for a large group of people is becoming a difficult task. The goal of this paper is to use deep learning (DL), which has shown excellent results in many real-life applications, to ensure efficient real-time facemask detection. The proposed approach is based on two steps. An off-line step aiming to create a DL model that is able to detect and locate facemasks and whether they are appropriately worn. An online step that deploys the DL model at edge computing in order to detect masks in real-time. In this study, we propose to use MobileNetV2 to detect facemask in real-time. Several experiments are conducted and show good performances of the proposed approach (99% for training and testing accuracy). In addition, several comparisons with many state-of-the-art models namely ResNet50, DenseNet, and VGG16 show good performance of the MobileNetV2 in terms of training time and accuracy.
Interneurons accelerate learning dynamics in recurrent neural networks for statistical adaptation
Sep 21, 2022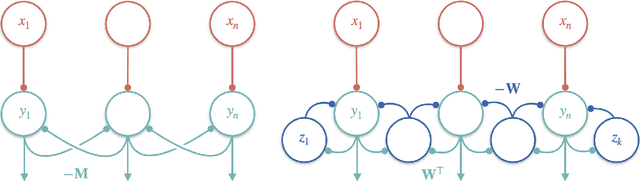
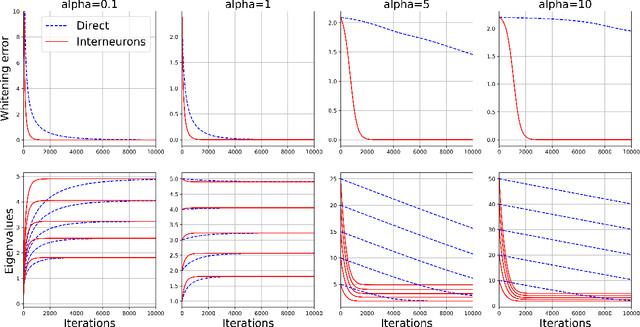
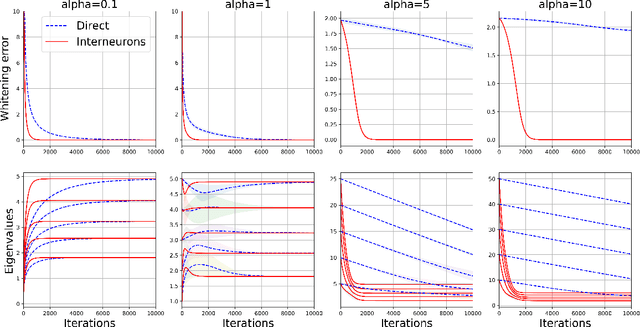
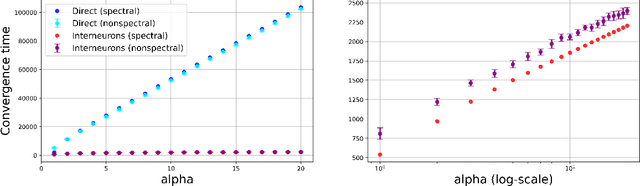
Early sensory systems in the brain rapidly adapt to fluctuating input statistics, which requires recurrent communication between neurons. Mechanistically, such recurrent communication is often indirect and mediated by local interneurons. In this work, we explore the computational benefits of mediating recurrent communication via interneurons compared with direct recurrent connections. To this end, we consider two mathematically tractable recurrent neural networks that statistically whiten their inputs -- one with direct recurrent connections and the other with interneurons that mediate recurrent communication. By analyzing the corresponding continuous synaptic dynamics and numerically simulating the networks, we show that the network with interneurons is more robust to initialization than the network with direct recurrent connections in the sense that the convergence time for the synaptic dynamics in the network with interneurons (resp. direct recurrent connections) scales logarithmically (resp. linearly) with the spectrum of their initialization. Our results suggest that interneurons are computationally useful for rapid adaptation to changing input statistics. Interestingly, the network with interneurons is an overparameterized solution of the whitening objective for the network with direct recurrent connections, so our results can be viewed as a recurrent neural network analogue of the implicit acceleration phenomenon observed in overparameterized feedforward linear networks.
On the Horizon: Interactive and Compositional Deepfakes
Sep 21, 2022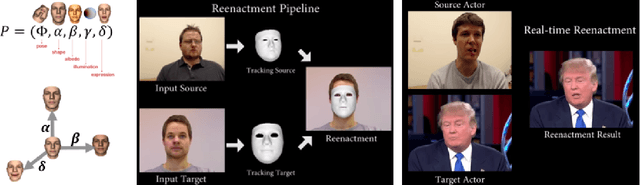
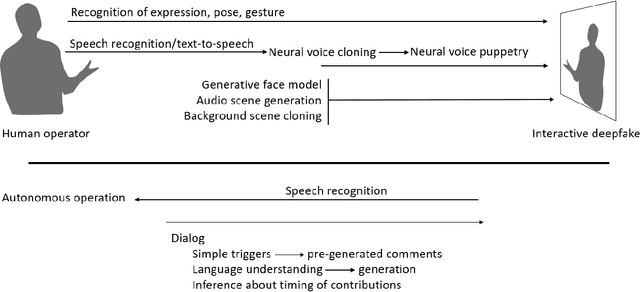
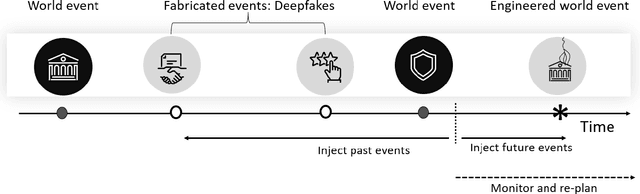
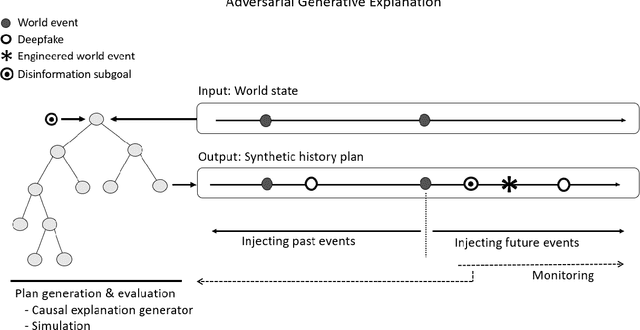
Over a five-year period, computing methods for generating high-fidelity, fictional depictions of people and events moved from exotic demonstrations by computer science research teams into ongoing use as a tool of disinformation. The methods, referred to with the portmanteau of "deepfakes," have been used to create compelling audiovisual content. Here, I share challenges ahead with malevolent uses of two classes of deepfakes that we can expect to come into practice with costly implications for society: interactive and compositional deepfakes. Interactive deepfakes have the capability to impersonate people with realistic interactive behaviors, taking advantage of advances in multimodal interaction. Compositional deepfakes leverage synthetic content in larger disinformation plans that integrate sets of deepfakes over time with observed, expected, and engineered world events to create persuasive synthetic histories. Synthetic histories can be constructed manually but may one day be guided by adversarial generative explanation (AGE) techniques. In the absence of mitigations, interactive and compositional deepfakes threaten to move us closer to a post-epistemic world, where fact cannot be distinguished from fiction. I shall describe interactive and compositional deepfakes and reflect about cautions and potential mitigations to defend against them.
RIS-aided Wireless Communication with $1$-bit Discrete Optimization for Signal Enhancement
Sep 12, 2022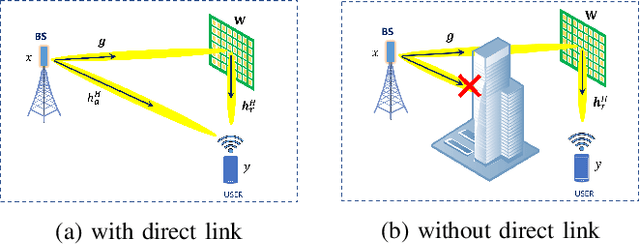
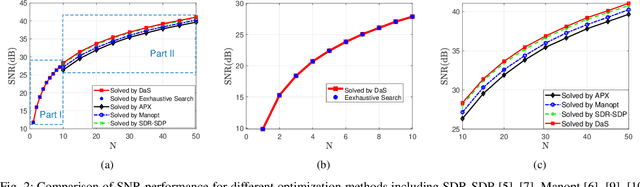
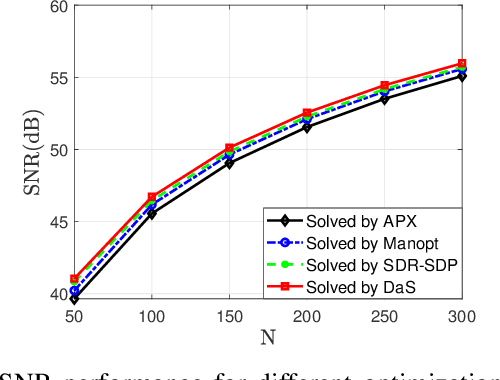
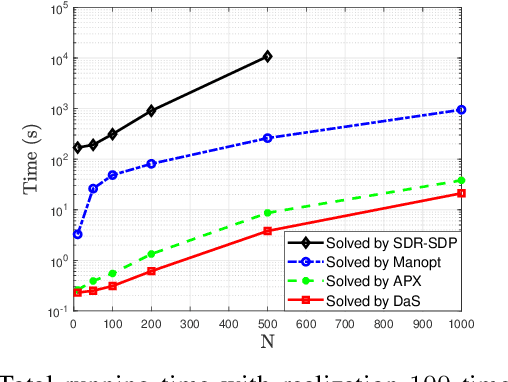
In recent years, a brand-new technology, reconfigurable intelligent surface (RIS) has been widely studied for reconfiguring the wireless propagation environment. RIS is an artificial surface of electromagnetic material that is capable of customizing the propagation of the wave impinging upon it. Utilizing RIS for communication service like signal enhancement usually lead to non-convex optimization problems. Existing optimization methods either suffers from scalability issues for $N$ number of RIS elements large, or may lead to suboptimal solutions in some scenario. In this paper, we propose a divide-and-sort (DaS) discrete optimization approach, that is guaranteed to find the global optimal phase shifts for $1$-bit RIS, and has time complexity $\mathcal{O}(N \log(N))$. Numerical experiments show that the proposed approach achieves a better ``performance--complexity tradeoff'' over other methods for $1$-bit RIS.
Dual-path Attention is All You Need for Audio-Visual Speech Extraction
Jul 09, 2022
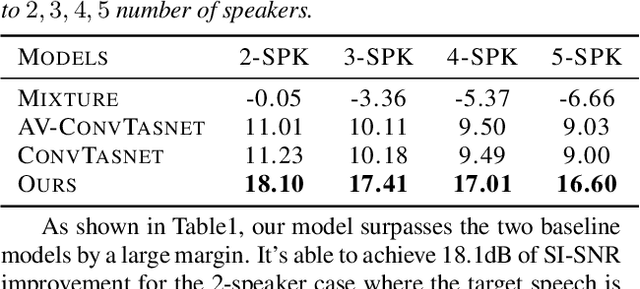
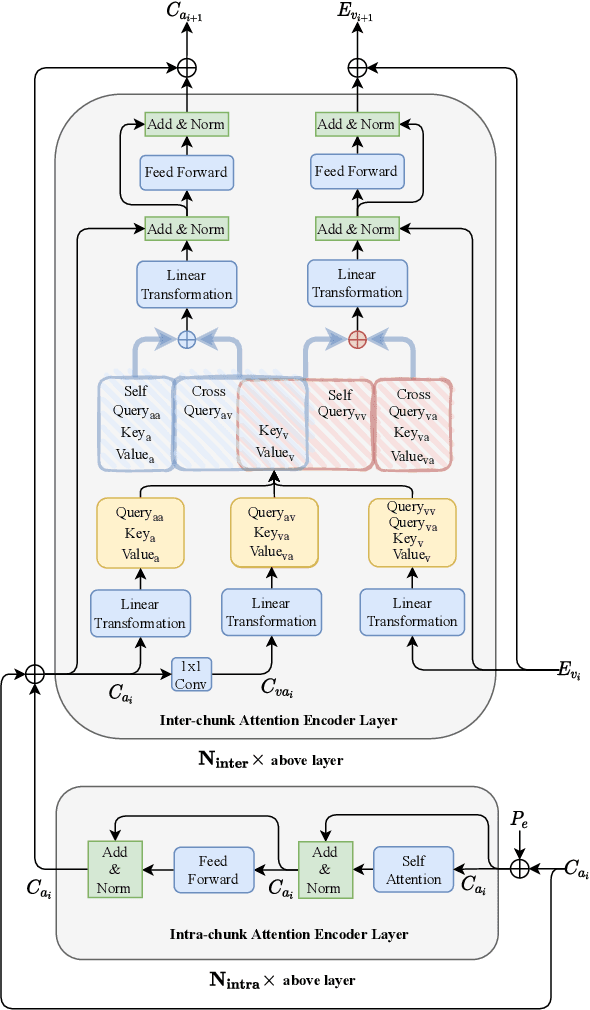
Audio-visual target speech extraction, which aims to extract a certain speaker's speech from the noisy mixture by looking at lip movements, has made significant progress combining time-domain speech separation models and visual feature extractors (CNN). One problem of fusing audio and video information is that they have different time resolutions. Most current research upsamples the visual features along the time dimension so that audio and video features are able to align in time. However, we believe that lip movement should mostly contain long-term, or phone-level information. Based on this assumption, we propose a new way to fuse audio-visual features. We observe that for DPRNN \cite{dprnn}, the interchunk dimension's time resolution could be very close to the time resolution of video frames. Like \cite{sepformer}, the LSTM in DPRNN is replaced by intra-chunk and inter-chunk self-attention, but in the proposed algorithm, inter-chunk attention incorporates the visual features as an additional feature stream. This prevents the upsampling of visual cues, resulting in more efficient audio-visual fusion. The result shows we achieve superior results compared with other time-domain based audio-visual fusion models.
LEAPER: Modeling Cloud FPGA-based Systems via Transfer Learning
Aug 22, 2022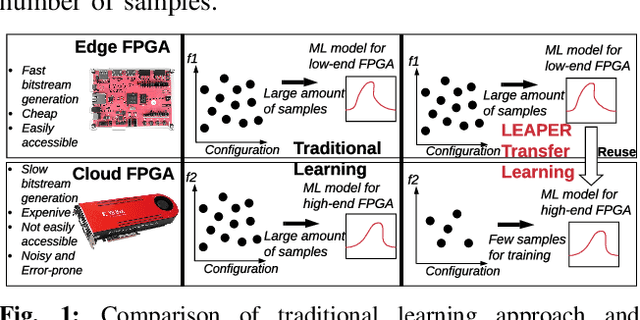
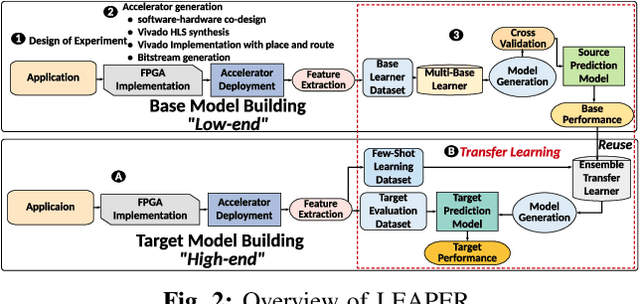
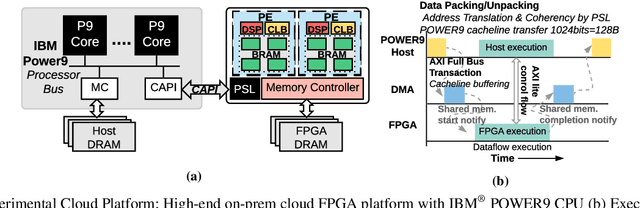
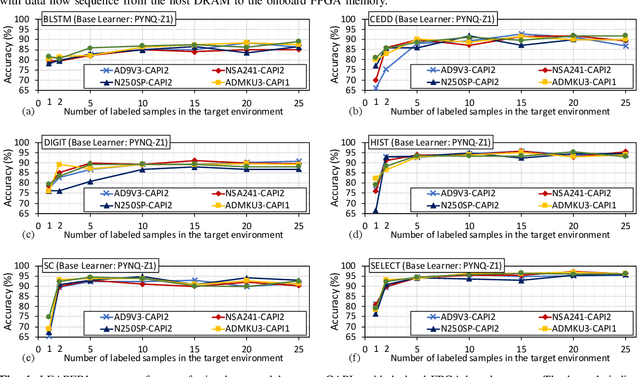
Machine-learning-based models have recently gained traction as a way to overcome the slow downstream implementation process of FPGAs by building models that provide fast and accurate performance predictions. However, these models suffer from two main limitations: (1) training requires large amounts of data (features extracted from FPGA synthesis and implementation reports), which is cost-inefficient because of the time-consuming FPGA design cycle; (2) a model trained for a specific environment cannot predict for a new, unknown environment. In a cloud system, where getting access to platforms is typically costly, data collection for ML models can significantly increase the total cost-ownership (TCO) of a system. To overcome these limitations, we propose LEAPER, a transfer learning-based approach for FPGA-based systems that adapts an existing ML-based model to a new, unknown environment to provide fast and accurate performance and resource utilization predictions. Experimental results show that our approach delivers, on average, 85% accuracy when we use our transferred model for prediction in a cloud environment with 5-shot learning and reduces design-space exploration time by 10x, from days to only a few hours.
Concepts and Experiments on Psychoanalysis Driven Computing
Sep 29, 2022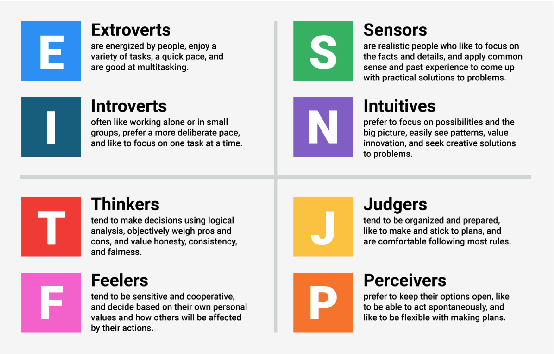
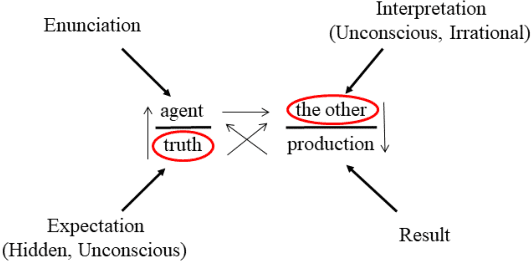
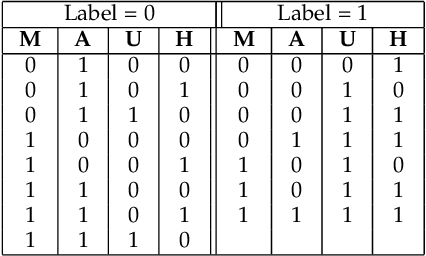
This research investigates the effective incorporation of the human factor and user perception in text-based interactive media. In such contexts, the reliability of user texts is often compromised by behavioural and emotional dimensions. To this end, several attempts have been made in the state of the art, to introduce psychological approaches in such systems, including computational psycholinguistics, personality traits and cognitive psychology methods. In contrast, our method is fundamentally different since we employ a psychoanalysis-based approach; in particular, we use the notion of Lacanian discourse types, to capture and deeply understand real (possibly elusive) characteristics, qualities and contents of texts, and evaluate their reliability. As far as we know, this is the first time computational methods are systematically combined with psychoanalysis. We believe such psychoanalytic framework is fundamentally more effective than standard methods, since it addresses deeper, quite primitive elements of human personality, behaviour and expression which usually escape methods functioning at "higher", conscious layers. In fact, this research is a first attempt to form a new paradigm of psychoanalysis-driven interactive technologies, with broader impact and diverse applications. To exemplify this generic approach, we apply it to the case-study of fake news detection; we first demonstrate certain limitations of the well-known Myers-Briggs Type Indicator (MBTI) personality type method, and then propose and evaluate our new method of analysing user texts and detecting fake news based on the Lacanian discourses psychoanalytic approach.
A Framework for Pedestrian Sub-classification and Arrival Time Prediction at Signalized Intersection Using Preprocessed Lidar Data
Jan 15, 2022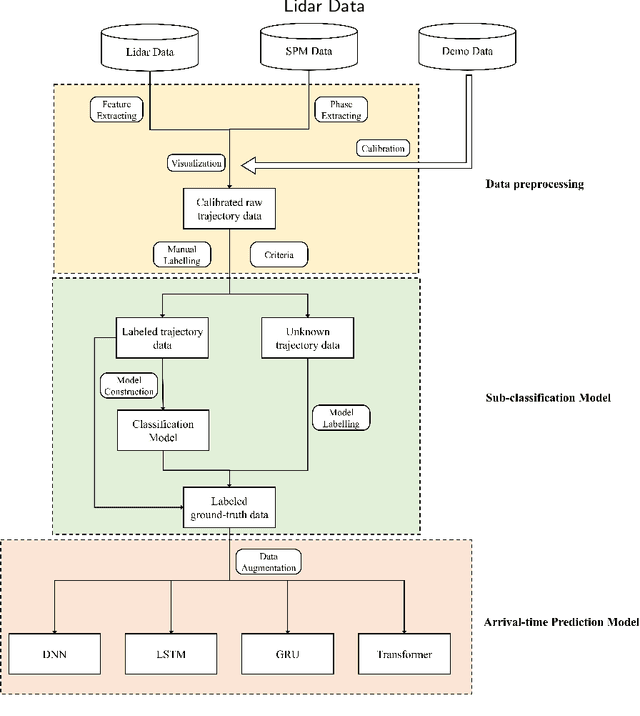

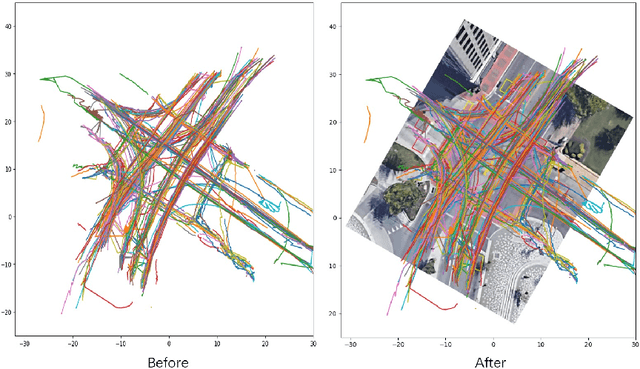
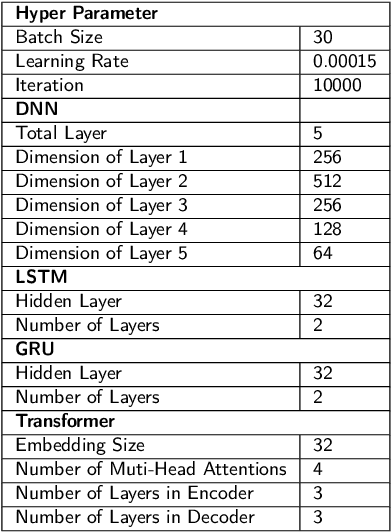
The mortality rate for pedestrians using wheelchairs was 36% higher than the overall population pedestrian mortality rate. However, there is no data to clarify the pedestrians' categories in both fatal and nonfatal accidents, since police reports often do not keep a record of whether a victim was using a wheelchair or has a disability. Currently, real-time detection of vulnerable road users using advanced traffic sensors installed at the infrastructure side has a great potential to significantly improve traffic safety at the intersection. In this research, we develop a systematic framework with a combination of machine learning and deep learning models to distinguish disabled people from normal walk pedestrians and predict the time needed to reach the next side of the intersection. The proposed framework shows high performance both at vulnerable user classification and arrival time prediction accuracy.