 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Nowcasting the Financial Time Series with Streaming Data Analytics under Apache Spark
Feb 23, 2022
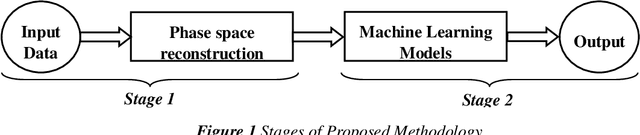
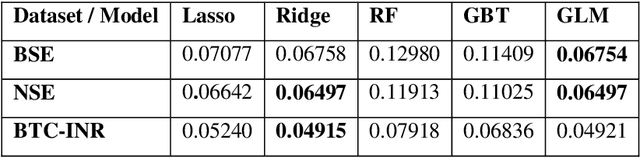
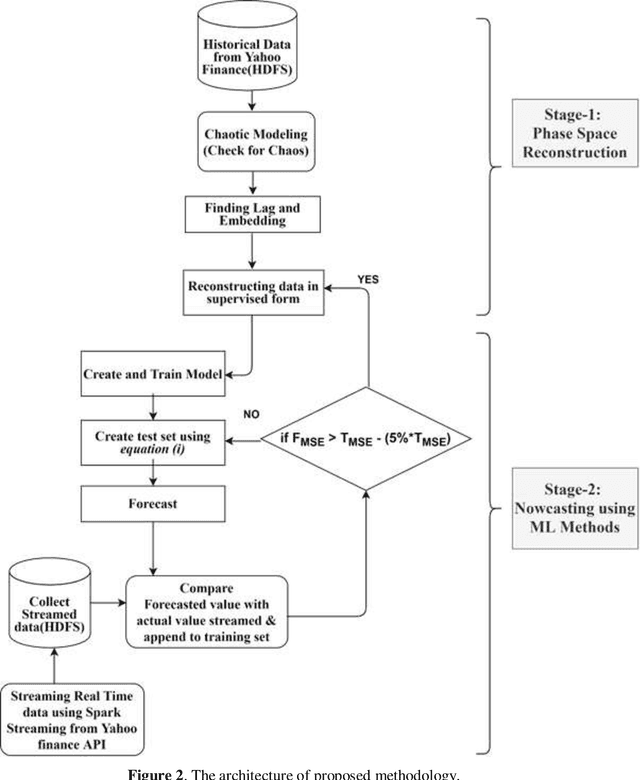
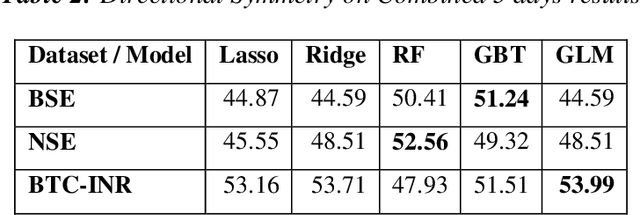
This paper proposes nowcasting of high-frequency financial datasets in real-time with a 5-minute interval using the streaming analytics feature of Apache Spark. The proposed 2 stage method consists of modelling chaos in the first stage and then using a sliding window approach for training with machine learning algorithms namely Lasso Regression, Ridge Regression, Generalised Linear Model, Gradient Boosting Tree and Random Forest available in the MLLib of Apache Spark in the second stage. For testing the effectiveness of the proposed methodology, 3 different datasets, of which two are stock markets namely National Stock Exchange & Bombay Stock Exchange, and finally One Bitcoin-INR conversion dataset. For evaluating the proposed methodology, we used metrics such as Symmetric Mean Absolute Percentage Error, Directional Symmetry, and Theil U Coefficient. We tested the significance of each pair of models using the Diebold Mariano (DM) test.
Analysis of Distributed Deep Learning in the Cloud
Aug 30, 2022We aim to resolve this problem by introducing a comprehensive distributed deep learning (DDL) profiler, which can determine the various execution "stalls" that DDL suffers from while running on a public cloud. We have implemented the profiler by extending prior work to additionally estimate two types of communication stalls - interconnect and network stalls. We train popular DNN models using the profiler to characterize various AWS GPU instances and list their advantages and shortcomings for users to make an informed decision. We observe that the more expensive GPU instances may not be the most performant for all DNN models and AWS may sub-optimally allocate hardware interconnect resources. Specifically, the intra-machine interconnect can introduce communication overheads up to 90% of DNN training time and network-connected instances can suffer from up to 5x slowdown compared to training on a single instance. Further, we model the impact of DNN macroscopic features such as the number of layers and the number of gradients on communication stalls. Finally, we propose a measurement-based recommendation model for users to lower their public cloud monetary costs for DDL, given a time budget.
NasHD: Efficient ViT Architecture Performance Ranking using Hyperdimensional Computing
Sep 23, 2022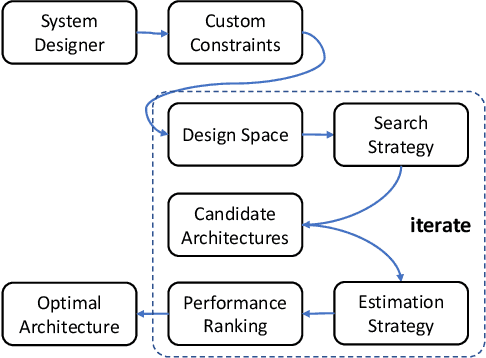
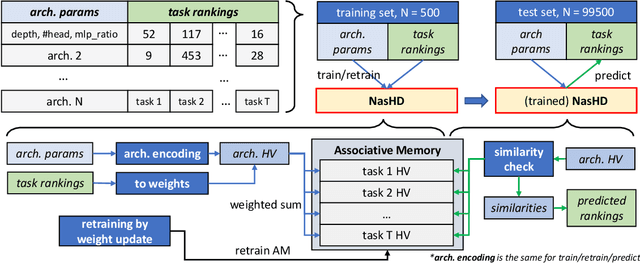
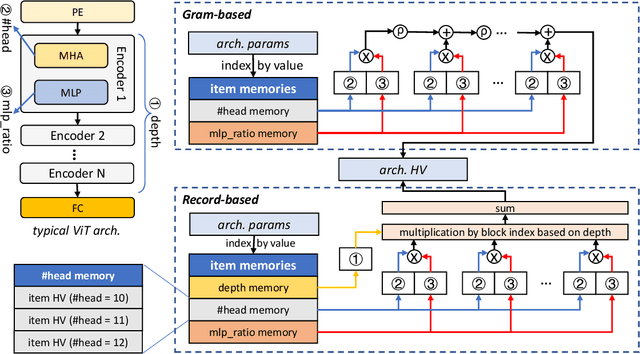
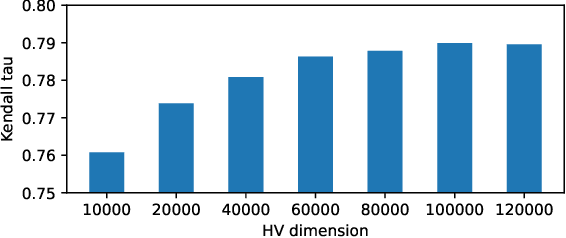
Neural Architecture Search (NAS) is an automated architecture engineering method for deep learning design automation, which serves as an alternative to the manual and error-prone process of model development, selection, evaluation and performance estimation. However, one major obstacle of NAS is the extremely demanding computation resource requirements and time-consuming iterations particularly when the dataset scales. In this paper, targeting at the emerging vision transformer (ViT), we present NasHD, a hyperdimensional computing based supervised learning model to rank the performance given the architectures and configurations. Different from other learning based methods, NasHD is faster thanks to the high parallel processing of HDC architecture. We also evaluated two HDC encoding schemes: Gram-based and Record-based of NasHD on their performance and efficiency. On the VIMER-UFO benchmark dataset of 8 applications from a diverse range of domains, NasHD Record can rank the performance of nearly 100K vision transformer models with about 1 minute while still achieving comparable results with sophisticated models.
Data-Driven Machine Learning Models for a Multi-Objective Flapping Fin Unmanned Underwater Vehicle Control System
Sep 14, 2022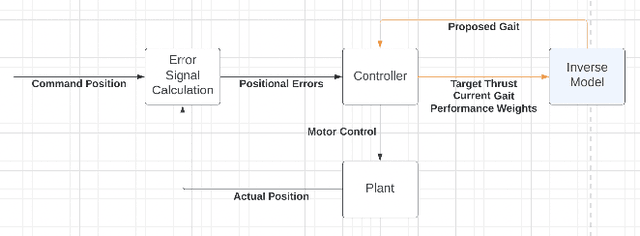

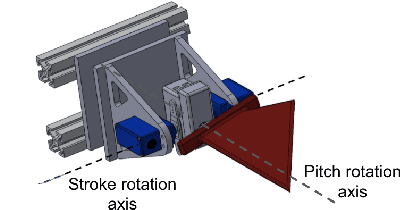
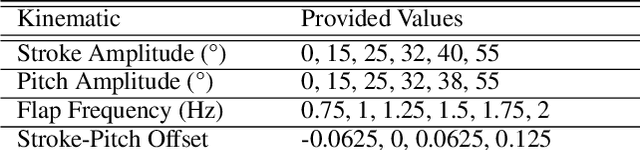
Flapping-fin unmanned underwater vehicle (UUV) propulsion systems provide high maneuverability for naval tasks such as surveillance and terrain exploration. Recent work has explored the use of time-series neural network surrogate models to predict thrust from vehicle design and fin kinematics. We develop a search-based inverse model that leverages a kinematics-to-thrust neural network model for control system design. Our inverse model finds a set of fin kinematics with the multi-objective goal of reaching a target thrust and creating a smooth kinematic transition between flapping cycles. We demonstrate how a control system integrating this inverse model can make online, cycle-to-cycle adjustments to prioritize different system objectives.
Smells like Teen Spirit: An Exploration of Sensorial Style in Literary Genres
Sep 26, 2022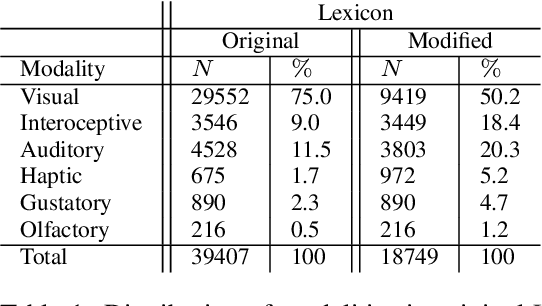
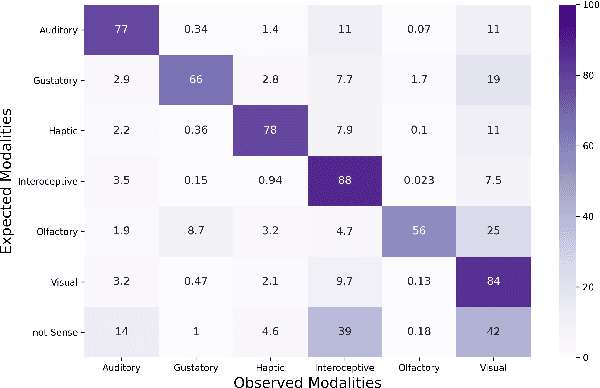
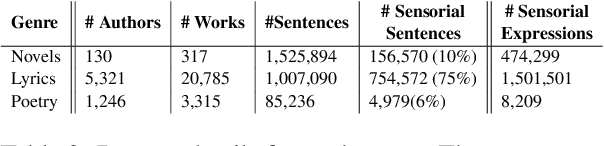
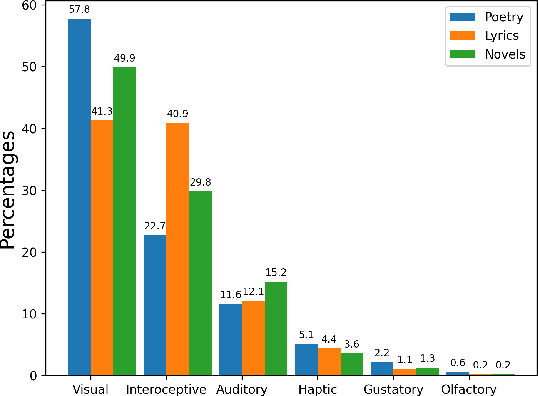
It is well recognized that sensory perceptions and language have interconnections through numerous studies in psychology, neuroscience, and sensorial linguistics. Set in this rich context we ask whether the use of sensorial language in writings is part of linguistic style? This question is important from the view of stylometrics research where a rich set of language features have been explored, but with insufficient attention given to features related to sensorial language. Taking this as the goal we explore several angles about sensorial language and style in collections of lyrics, novels, and poetry. We find, for example, that individual use of sensorial language is not a random phenomenon; choice is likely involved. Also, sensorial style is generally stable over time - the shifts are extremely small. Moreover, style can be extracted from just a few hundred sentences that have sensorial terms. We also identify representative and distinctive features within each genre. For example, we observe that 4 of the top 6 representative features in novels collection involved individuals using olfactory language where we expected them to use non-olfactory language.
Amercing: An Intuitive, Elegant and Effective Constraint for Dynamic Time Warping
Nov 26, 2021
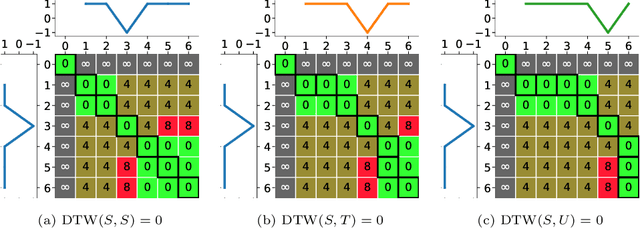
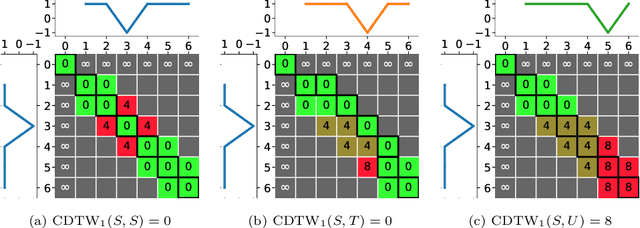
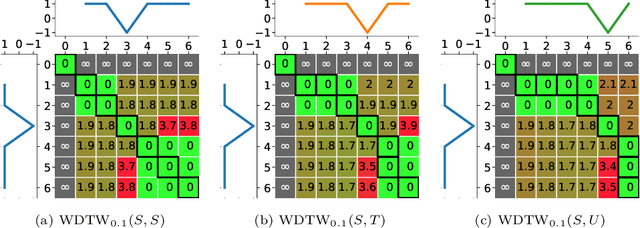
Dynamic Time Warping (DTW), and its constrained (CDTW) and weighted (WDTW) variants, are time series distances with a wide range of applications. They minimize the cost of non-linear alignments between series. CDTW and WDTW have been introduced because DTW is too permissive in its alignments. However, CDTW uses a crude step function, allowing unconstrained flexibility within the window, and none beyond it. WDTW's multiplicative weight is relative to the distances between aligned points along a warped path, rather than being a direct function of the amount of warping that is introduced. In this paper, we introduce Amerced Dynamic Time Warping (ADTW), a new, intuitive, DTW variant that penalizes the act of warping by a fixed additive cost. Like CDTW and WDTW, ADTW constrains the amount of warping. However, it avoids both abrupt discontinuities in the amount of warping allowed and the limitations of a multiplicative penalty. We formally introduce ADTW, prove some of its properties, and discuss its parameterization. We show on a simple example how it can be parameterized to achieve an intuitive outcome, and demonstrate its usefulness on a standard time series classification benchmark. We provide a demonstration application in C++.
Self-move and Other-move: Quantum Categorical Foundations of Japanese
Oct 10, 2022

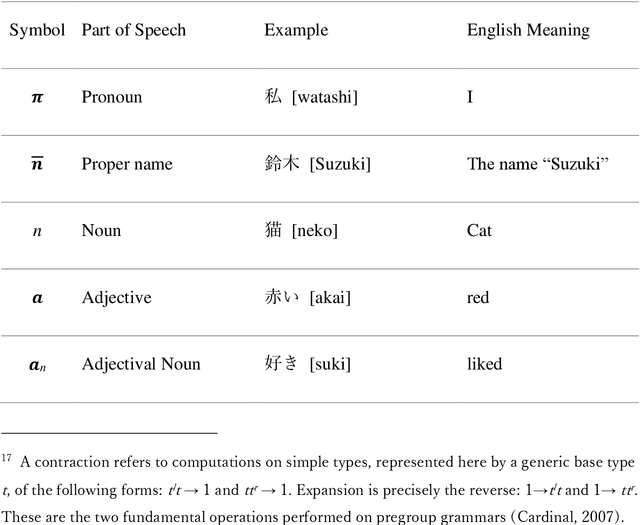

The purpose of this work is to contribute toward the larger goal of creating a Quantum Natural Language Processing (QNLP) translator program. This work contributes original diagrammatic representations of the Japanese language based on prior work that accomplished on the English language based on category theory. The germane differences between the English and Japanese languages are emphasized to help address English language bias in the current body of research. Additionally, topological principles of these diagrams and many potential avenues for further research are proposed. Why is this endeavor important? Hundreds of languages have developed over the course of millennia coinciding with the evolution of human interaction across time and geographic location. These languages are foundational to human survival, experience, flourishing, and living the good life. They are also, however, the strongest barrier between people groups. Over the last several decades, advancements in Natural Language Processing (NLP) have made it easier to bridge the gap between individuals who do not share a common language or culture. Tools like Google Translate and DeepL make it easier than ever before to share our experiences with people globally. Nevertheless, these tools are still inadequate as they fail to convey our ideas across the language barrier fluently, leaving people feeling anxious and embarrassed. This is particularly true of languages born out of substantially different cultures, such as English and Japanese. Quantum computers offer the best chance to achieve translation fluency in that they are better suited to simulating the natural world and natural phenomenon such as natural speech. Keywords: category theory, DisCoCat, DisCoCirc, Japanese grammar, English grammar, translation, topology, Quantum Natural Language Processing, Natural Language Processing
Lung2Lung: Volumetric Style Transfer with Self-Ensembling for High-Resolution Cross-Volume Computed Tomography
Oct 06, 2022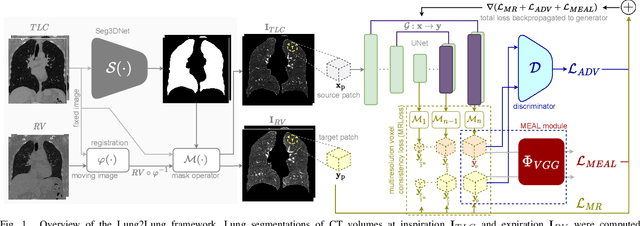
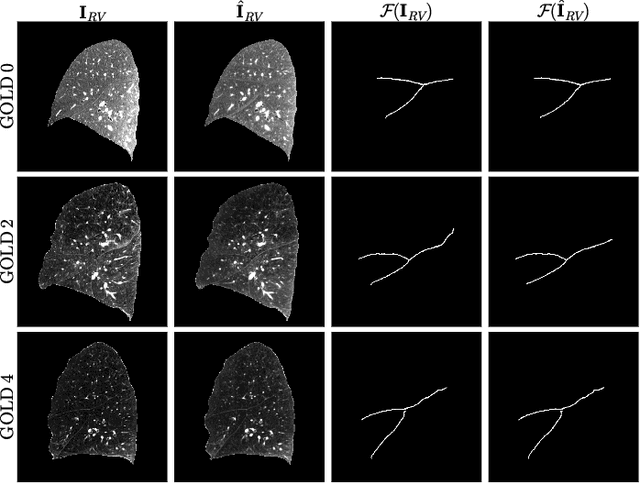
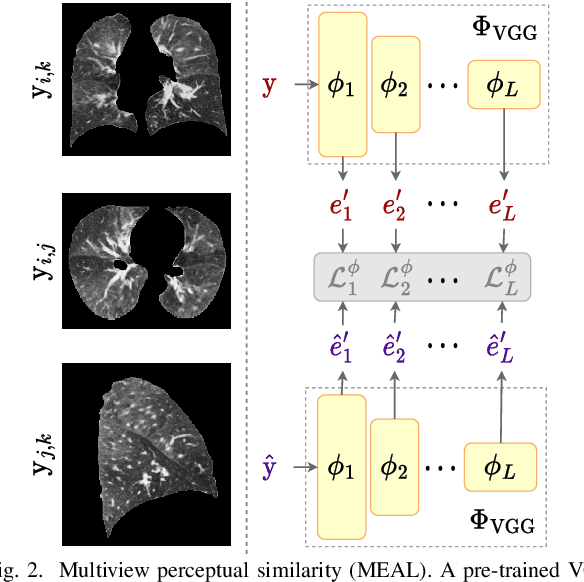

Chest computed tomography (CT) at inspiration is often complemented by an expiratory CT for identifying peripheral airways disease in the form of air trapping. Additionally, co-registered inspiratory-expiratory volumes are used to derive several clinically relevant measures of local lung function. Acquiring CT at different volumes, however, increases radiation dosage, acquisition time, and may not be achievable due to various complications, limiting the utility of registration-based measures, To address this, we propose Lung2Lung - a style-based generative adversarial approach for translating CT images from end-inspiratory to end-expiratory volume. Lung2Lung addresses several limitations of the traditional generative models including slicewise discontinuities, limited size of generated volumes, and their inability to model neural style at a volumetric level. We introduce multiview perceptual similarity (MEAL) to capture neural styles in 3D. To incorporate global information into the training process and refine the output of our model, we also propose self-ensembling (SE). Lung2Lung, with MEAL and SE, is able to generate large 3D volumes of size 320 x 320 x 320 that are validated using a diverse cohort of 1500 subjects with varying disease severity. The model shows superior performance against several state-of-the-art 2D and 3D generative models with a peak-signal-to-noise ratio of 24.53 dB and structural similarity of 0.904. Clinical validation shows that the synthetic volumes can be used to reliably extract several clinical endpoints of chronic obstructive pulmonary disease.
Cross-Modality Domain Adaptation for Freespace Detection: A Simple yet Effective Baseline
Oct 06, 2022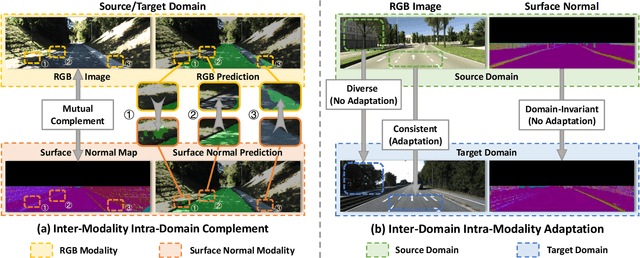
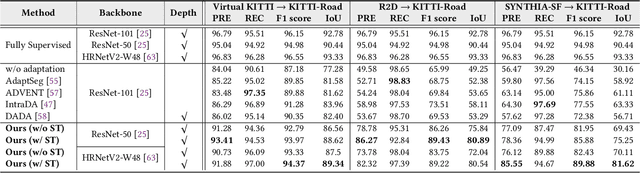
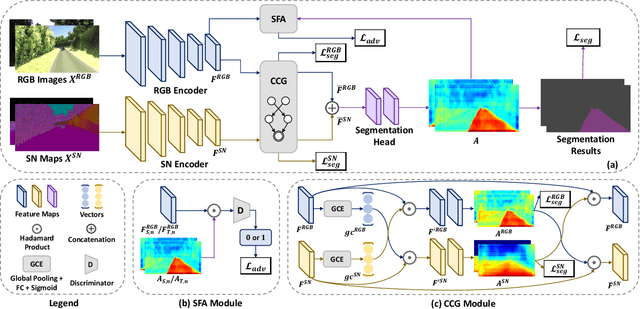
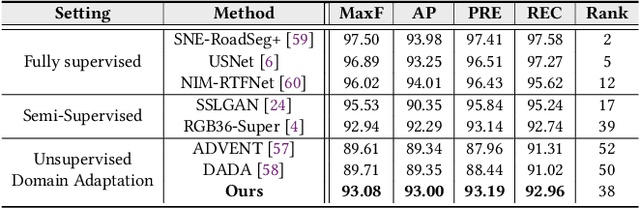
As one of the fundamental functions of autonomous driving system, freespace detection aims at classifying each pixel of the image captured by the camera as drivable or non-drivable. Current works of freespace detection heavily rely on large amount of densely labeled training data for accuracy and robustness, which is time-consuming and laborious to collect and annotate. To the best of our knowledge, we are the first work to explore unsupervised domain adaptation for freespace detection to alleviate the data limitation problem with synthetic data. We develop a cross-modality domain adaptation framework which exploits both RGB images and surface normal maps generated from depth images. A Collaborative Cross Guidance (CCG) module is proposed to leverage the context information of one modality to guide the other modality in a cross manner, thus realizing inter-modality intra-domain complement. To better bridge the domain gap between source domain (synthetic data) and target domain (real-world data), we also propose a Selective Feature Alignment (SFA) module which only aligns the features of consistent foreground area between the two domains, thus realizing inter-domain intra-modality adaptation. Extensive experiments are conducted by adapting three different synthetic datasets to one real-world dataset for freespace detection respectively. Our method performs closely to fully supervised freespace detection methods (93.08 v.s. 97.50 F1 score) and outperforms other general unsupervised domain adaptation methods for semantic segmentation with large margins, which shows the promising potential of domain adaptation for freespace detection.
Semantic Segmentation of Vegetation in Remote Sensing Imagery Using Deep Learning
Sep 28, 2022
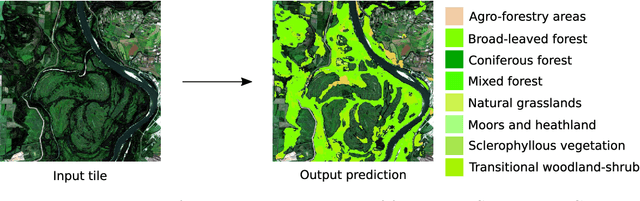
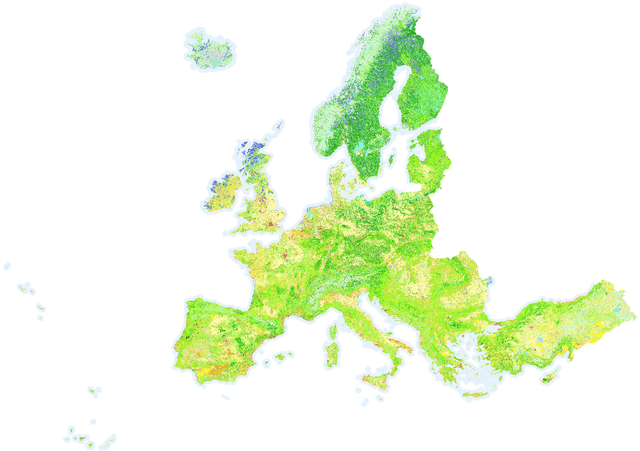
In recent years, the geospatial industry has been developing at a steady pace. This growth implies the addition of satellite constellations that produce a copious supply of satellite imagery and other Remote Sensing data on a daily basis. Sometimes, this information, even if in some cases we are referring to publicly available data, it sits unaccounted for due to the sheer size of it. Processing such large amounts of data with the help of human labour or by using traditional automation methods is not always a viable solution from the standpoint of both time and other resources. Within the present work, we propose an approach for creating a multi-modal and spatio-temporal dataset comprised of publicly available Remote Sensing data and testing for feasibility using state of the art Machine Learning (ML) techniques. Precisely, the usage of Convolutional Neural Networks (CNN) models that are capable of separating different classes of vegetation that are present in the proposed dataset. Popularity and success of similar methods in the context of Geographical Information Systems (GIS) and Computer Vision (CV) more generally indicate that methods alike should be taken in consideration and further analysed and developed.