 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Distributed Deep Learning in the Cloud
Aug 30, 2022We aim to resolve this problem by introducing a comprehensive distributed deep learning (DDL) profiler, which can determine the various execution "stalls" that DDL suffers from while running on a public cloud. We have implemented the profiler by extending prior work to additionally estimate two types of communication stalls - interconnect and network stalls. We train popular DNN models using the profiler to characterize various AWS GPU instances and list their advantages and shortcomings for users to make an informed decision. We observe that the more expensive GPU instances may not be the most performant for all DNN models and AWS may sub-optimally allocate hardware interconnect resources. Specifically, the intra-machine interconnect can introduce communication overheads up to 90% of DNN training time and network-connected instances can suffer from up to 5x slowdown compared to training on a single instance. Further, we model the impact of DNN macroscopic features such as the number of layers and the number of gradients on communication stalls. Finally, we propose a measurement-based recommendation model for users to lower their public cloud monetary costs for DDL, given a time budget.
Cocktail: Leveraging Ensemble Learning for Optimized Model Serving in Public Cloud
Jun 09, 2021
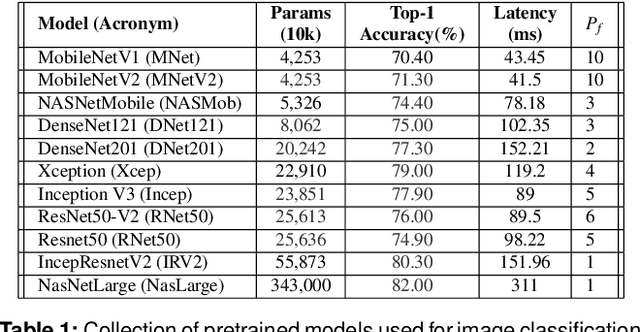
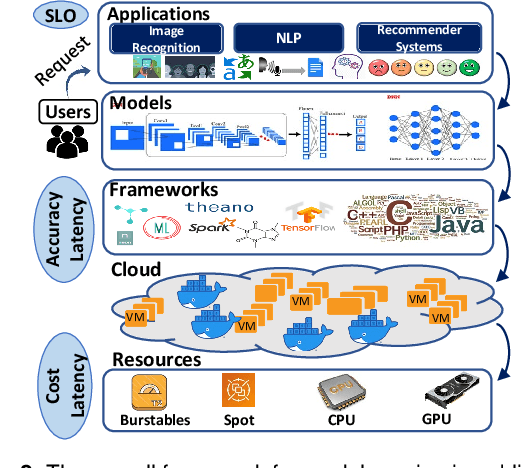
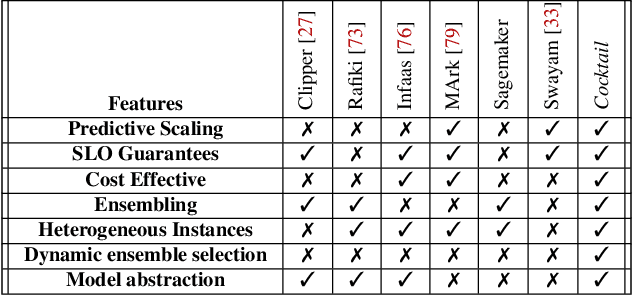
With a growing demand for adopting ML models for a varietyof application services, it is vital that the frameworks servingthese models are capable of delivering highly accurate predic-tions with minimal latency along with reduced deploymentcosts in a public cloud environment. Despite high latency,prior works in this domain are crucially limited by the accu-racy offered by individual models. Intuitively, model ensem-bling can address the accuracy gap by intelligently combiningdifferent models in parallel. However, selecting the appro-priate models dynamically at runtime to meet the desiredaccuracy with low latency at minimal deployment cost is anontrivial problem. Towards this, we proposeCocktail, a costeffective ensembling-based model serving framework.Cock-tailcomprises of two key components: (i) a dynamic modelselection framework, which reduces the number of modelsin the ensemble, while satisfying the accuracy and latencyrequirements; (ii) an adaptive resource management (RM)framework that employs a distributed proactive autoscalingpolicy combined with importance sampling, to efficiently allo-cate resources for the models. The RM framework leveragestransient virtual machine (VM) instances to reduce the de-ployment cost in a public cloud. A prototype implementationofCocktailon the AWS EC2 platform and exhaustive evalua-tions using a variety of workloads demonstrate thatCocktailcan reduce deployment cost by 1.45x, while providing 2xreduction in latency and satisfying the target accuracy for upto 96% of the requests, when compared to state-of-the-artmodel-serving frameworks.