 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Gradient Descent and the Power Method: Exploiting their connection to find the leftmost eigen-pair and escape saddle points
Nov 02, 2022
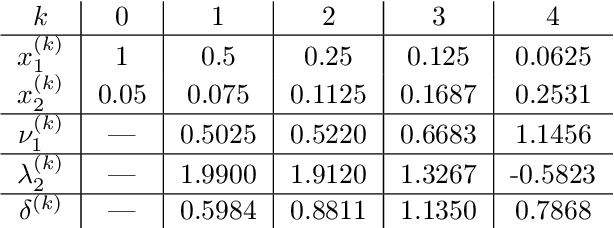
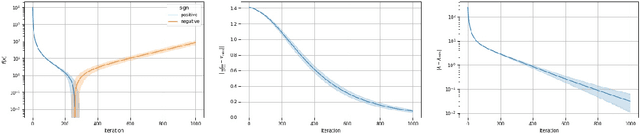
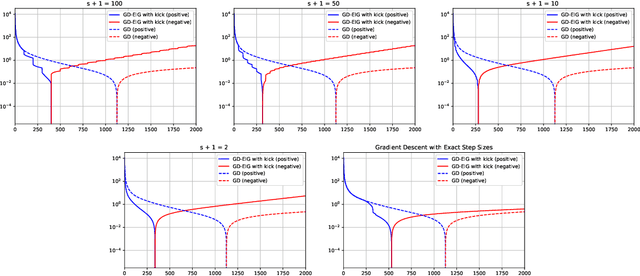
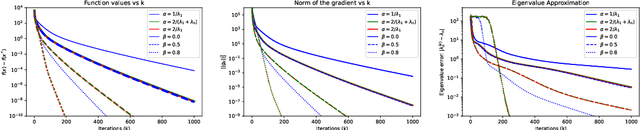
This work shows that applying Gradient Descent (GD) with a fixed step size to minimize a (possibly nonconvex) quadratic function is equivalent to running the Power Method (PM) on the gradients. The connection between GD with a fixed step size and the PM, both with and without fixed momentum, is thus established. Consequently, valuable eigen-information is available via GD. Recent examples show that GD with a fixed step size, applied to locally quadratic nonconvex functions, can take exponential time to escape saddle points (Simon S. Du, Chi Jin, Jason D. Lee, Michael I. Jordan, Aarti Singh, and Barnabas Poczos: "Gradient descent can take exponential time to escape saddle points"; S. Paternain, A. Mokhtari, and A. Ribeiro: "A newton-based method for nonconvex optimization with fast evasion of saddle points"). Here, those examples are revisited and it is shown that eigenvalue information was missing, so that the examples may not provide a complete picture of the potential practical behaviour of GD. Thus, ongoing investigation of the behaviour of GD on nonconvex functions, possibly with an \emph{adaptive} or \emph{variable} step size, is warranted. It is shown that, in the special case of a quadratic in $R^2$, if an eigenvalue is known, then GD with a fixed step size will converge in two iterations, and a complete eigen-decomposition is available. By considering the dynamics of the gradients and iterates, new step size strategies are proposed to improve the practical performance of GD. Several numerical examples are presented, which demonstrate the advantages of exploiting the GD--PM connection.
Wheel Impact Test by Deep Learning: Prediction of Location and Magnitude of Maximum Stress
Oct 03, 2022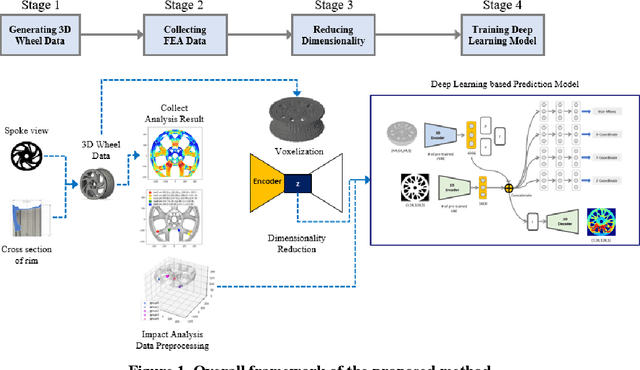
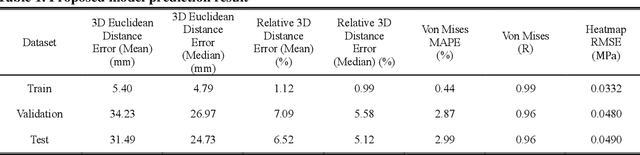
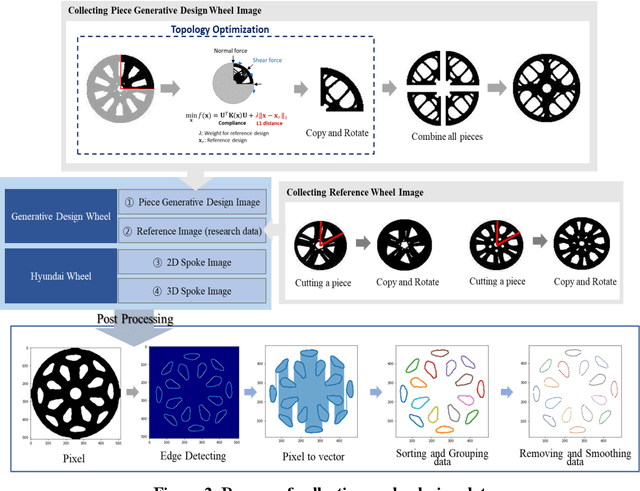
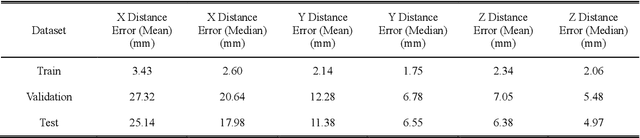
The impact performance of the wheel during wheel development must be ensured through a wheel impact test for vehicle safety. However, manufacturing and testing a real wheel take a significant amount of time and money because developing an optimal wheel design requires numerous iterative processes of modifying the wheel design and verifying the safety performance. Accordingly, the actual wheel impact test has been replaced by computer simulations, such as Finite Element Analysis (FEA), but it still requires high computational costs for modeling and analysis. Moreover, FEA experts are needed. This study presents an aluminum road wheel impact performance prediction model based on deep learning that replaces the computationally expensive and time-consuming 3D FEA. For this purpose, 2D disk-view wheel image data, 3D wheel voxel data, and barrier mass value used for wheel impact test are utilized as the inputs to predict the magnitude of maximum von Mises stress, corresponding location, and the stress distribution of 2D disk-view. The wheel impact performance prediction model can replace the impact test in the early wheel development stage by predicting the impact performance in real time and can be used without domain knowledge. The time required for the wheel development process can be shortened through this mechanism.
Word-Level Representation From Bytes For Language Modeling
Nov 23, 2022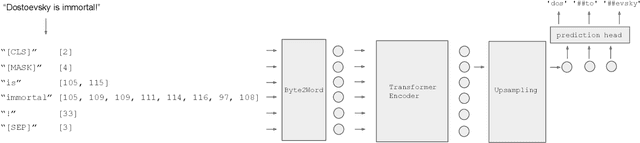
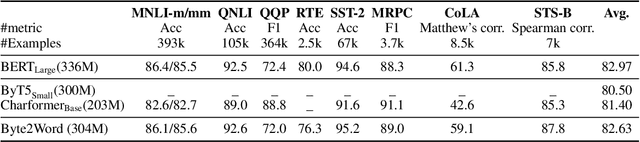

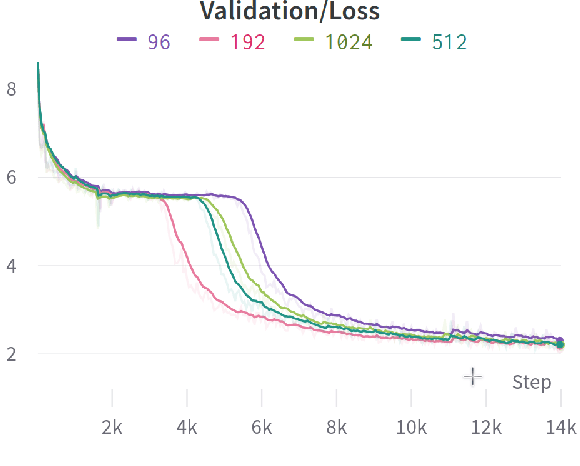
Modern language models mostly take sub-words as input, a design that balances the trade-off between vocabulary size, number of parameters, and performance. However, sub-word tokenization still has disadvantages like not being robust to noise and difficult to generalize to new languages. Also, the current trend of scaling up models reveals that larger models require larger embeddings but that makes parallelization hard. Previous work on image classification proves splitting raw input into a sequence of chucks is a strong, model-agnostic inductive bias. Based on this observation, we rethink the existing character-aware method that takes character-level inputs but makes word-level sequence modeling and prediction. We overhaul this method by introducing a cross-attention network that builds word-level representation directly from bytes, and a sub-word level prediction based on word-level hidden states to avoid the time and space requirement of word-level prediction. With these two improvements combined, we have a token free model with slim input embeddings for downstream tasks. We name our method Byte2Word and perform evaluations on language modeling and text classification. Experiments show that Byte2Word is on par with the strong sub-word baseline BERT but only takes up 10\% of embedding size. We further test our method on synthetic noise and cross-lingual transfer and find it competitive to baseline methods on both settings.
Safety of Sampled-Data Systems with Control Barrier Functions via Approximate Discrete Time Models
Mar 22, 2022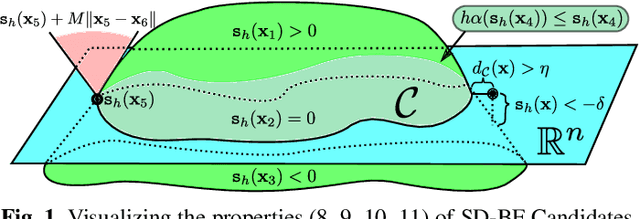
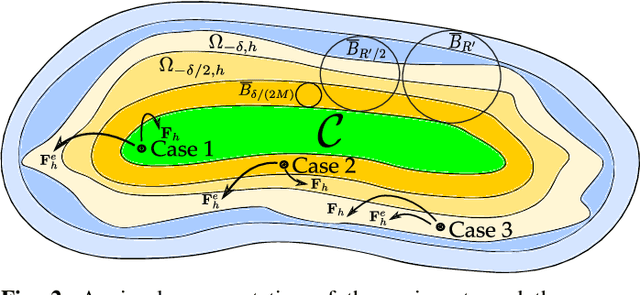
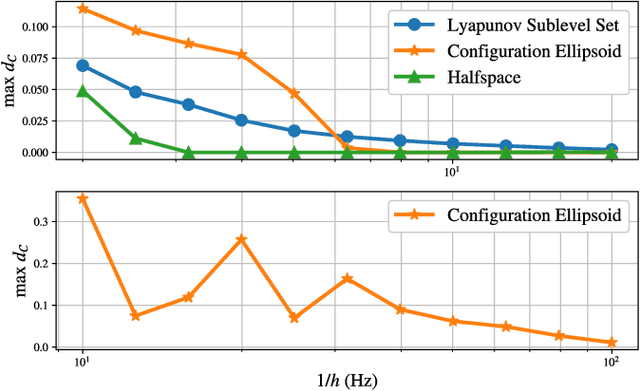

Control Barrier Functions (CBFs) have been demonstrated to be a powerful tool for safety-critical controller design for nonlinear systems. Existing design paradigms do not address the gap between theory (controller design with continuous time models) and practice (the discrete time sampled implementation of the resulting controllers); this can lead to poor performance and violations of safety for hardware instantiations. We propose an approach to close this gap by synthesizing sampled-data counterparts to these CBF-based controllers using approximate discrete time models and Sampled-Data Control Barrier Functions (SD-CBFs). Using properties of a system's continuous time model, we establish a relationship between SD-CBFs and a notion of practical safety for sampled-data systems. Furthermore, we construct convex optimization-based controllers that formally endow nonlinear systems with safety guarantees in practice. We demonstrate the efficacy of these controllers in simulation.
One Node at a Time: Node-Level Network Classification
Aug 03, 2022
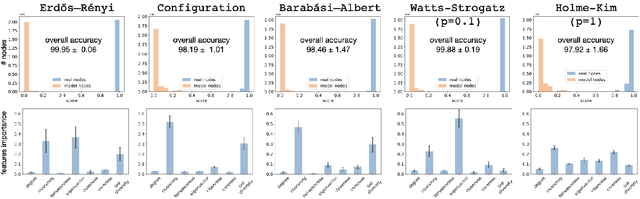

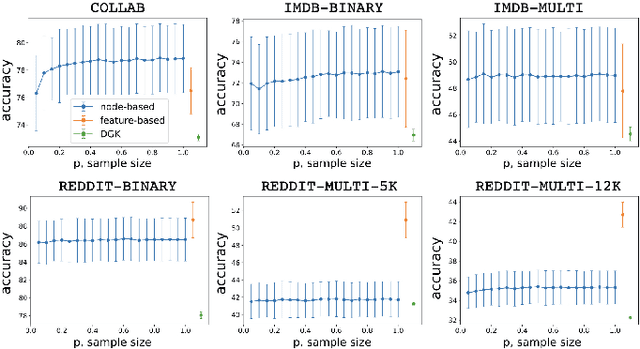
Network classification aims to group networks (or graphs) into distinct categories based on their structure. We study the connection between classification of a network and of its constituent nodes, and whether nodes from networks in different groups are distinguishable based on structural node characteristics such as centrality and clustering coefficient. We demonstrate, using various network datasets and random network models, that a classifier can be trained to accurately predict the network category of a given node (without seeing the whole network), implying that complex networks display distinct structural patterns even at the node level. Finally, we discuss two applications of node-level network classification: (i) whole-network classification from small samples of nodes, and (ii) network bootstrapping.
* 8 pages, 5 figures
Development and validation of deep learning based embryo selection across multiple days of transfer
Oct 05, 2022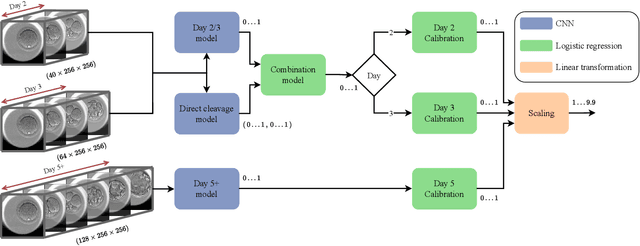


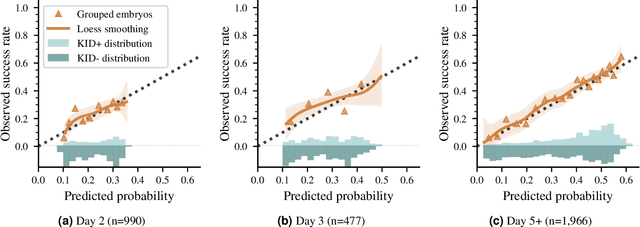
This work describes the development and validation of a fully automated deep learning model, iDAScore v2.0, for the evaluation of embryos incubated for 2, 3, and 5 or more days. The model is trained and evaluated on an extensive and diverse dataset including 181,428 embryos from 22 IVF clinics across the world. For discriminating transferred embryos with known outcome (KID), we show AUCs ranging from 0.621 to 0.708 depending on the day of transfer. Predictive performance increased over time and showed a strong correlation with morphokinetic parameters. The model has equivalent performance to KIDScore D3 on day 3 embryos while significantly surpassing the performance of KIDScore D5 v3 on day 5+ embryos. This model provides an analysis of time-lapse sequences without the need for user input, and provides a reliable method for ranking embryos for likelihood to implant, at both cleavage and blastocyst stages. This greatly improves embryo grading consistency and saves time compared to traditional embryo evaluation methods.
Extending Temporal Data Augmentation for Video Action Recognition
Nov 09, 2022
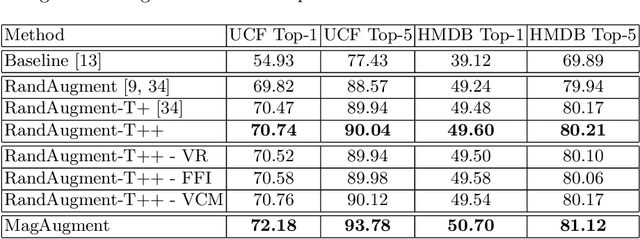
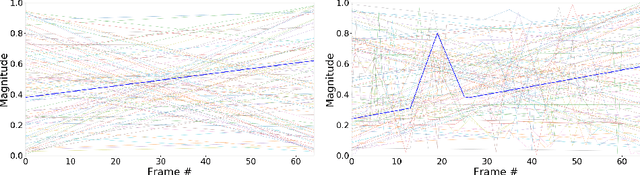
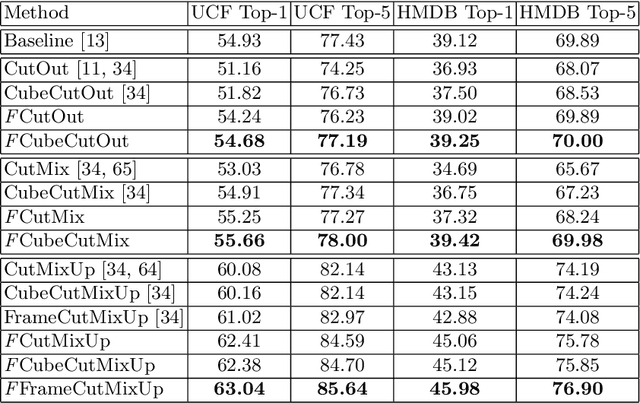
Pixel space augmentation has grown in popularity in many Deep Learning areas, due to its effectiveness, simplicity, and low computational cost. Data augmentation for videos, however, still remains an under-explored research topic, as most works have been treating inputs as stacks of static images rather than temporally linked series of data. Recently, it has been shown that involving the time dimension when designing augmentations can be superior to its spatial-only variants for video action recognition. In this paper, we propose several novel enhancements to these techniques to strengthen the relationship between the spatial and temporal domains and achieve a deeper level of perturbations. The video action recognition results of our techniques outperform their respective variants in Top-1 and Top-5 settings on the UCF-101 and the HMDB-51 datasets.
NLPeer: A Unified Resource for the Computational Study of Peer Review
Nov 12, 2022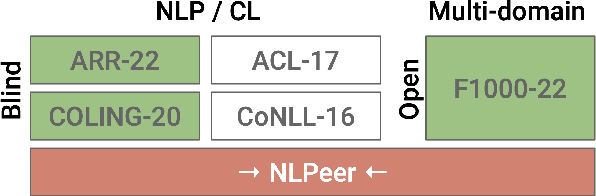
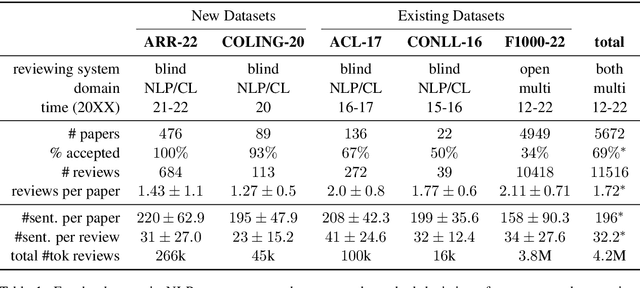
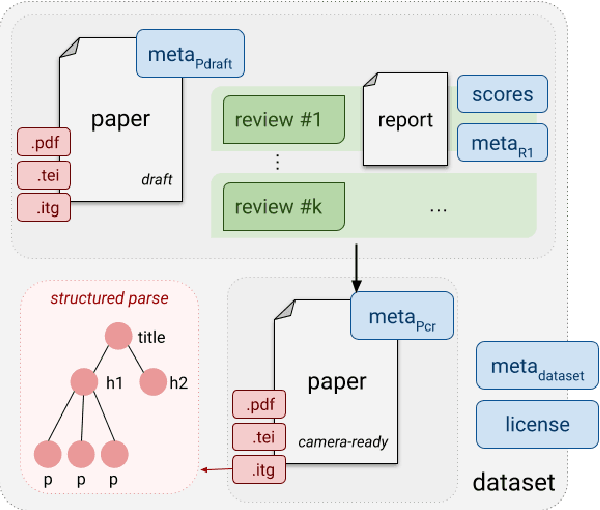
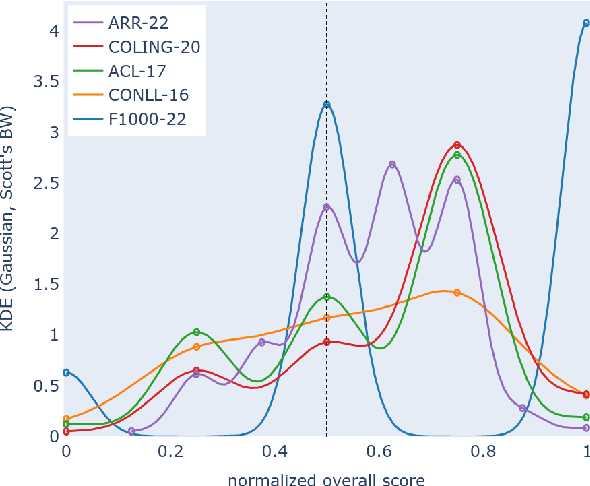
Peer review is a core component of scholarly publishing, yet it is time-consuming, requires considerable expertise, and is prone to error. The applications of NLP for peer reviewing assistance aim to mitigate those issues, but the lack of clearly licensed datasets and multi-domain corpora prevent the systematic study of NLP for peer review. To remedy this, we introduce NLPeer -- the first ethically sourced multidomain corpus of more than 5k papers and 11k review reports from five different venues. In addition to the new datasets of paper drafts, camera-ready versions and peer reviews from the NLP community, we establish a unified data representation, and augment previous peer review datasets to include parsed, structured paper representations, rich metadata and versioning information. Our work paves the path towards systematic, multi-faceted, evidence-based study of peer review in NLP and beyond. We make NLPeer publicly available.
Few-shot Multimodal Sentiment Analysis based on Multimodal Probabilistic Fusion Prompts
Nov 12, 2022
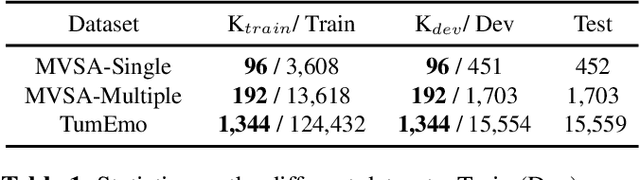
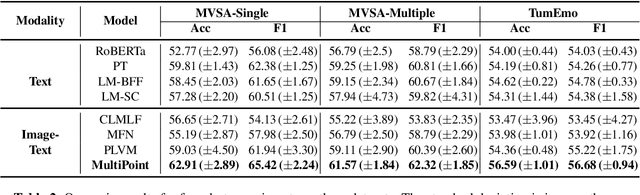
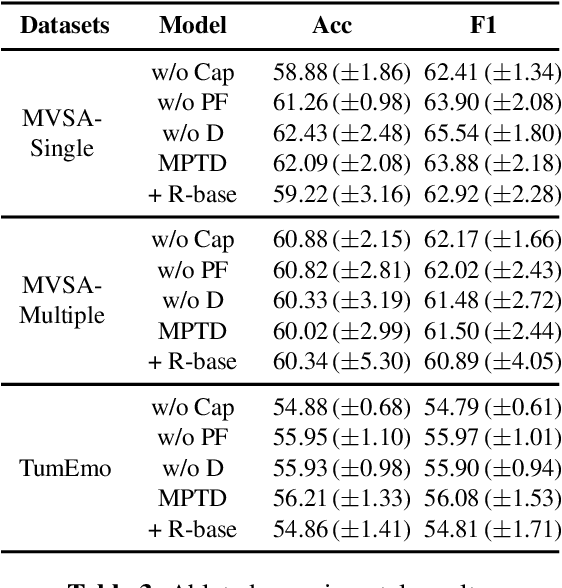
Multimodal sentiment analysis is a trending topic with the explosion of multimodal content on the web. Present studies in multimodal sentiment analysis rely on large-scale supervised data. Collating supervised data is time-consuming and labor-intensive. As such, it is essential to investigate the problem of few-shot multimodal sentiment analysis. Previous works in few-shot models generally use language model prompts, which can improve performance in low-resource settings. However, the textual prompt ignores the information from other modalities. We propose Multimodal Probabilistic Fusion Prompts, which can provide diverse cues for multimodal sentiment detection. We first design a unified multimodal prompt to reduce the discrepancy in different modal prompts. To improve the robustness of our model, we then leverage multiple diverse prompts for each input and propose a probabilistic method to fuse the output predictions. Extensive experiments conducted on three datasets confirm the effectiveness of our approach.
Learning Robust Real-Time Cultural Transmission without Human Data
Mar 01, 2022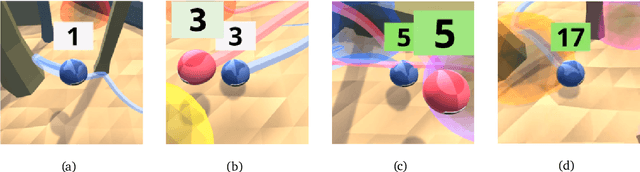
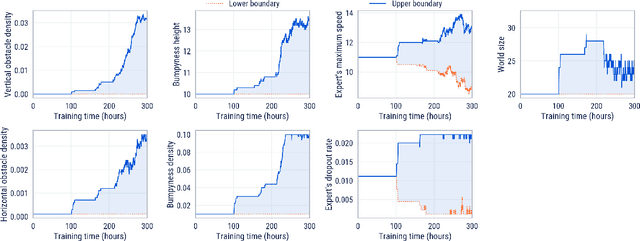
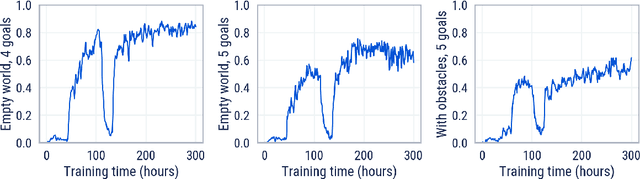
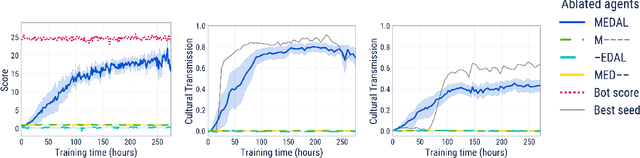
Cultural transmission is the domain-general social skill that allows agents to acquire and use information from each other in real-time with high fidelity and recall. In humans, it is the inheritance process that powers cumulative cultural evolution, expanding our skills, tools and knowledge across generations. We provide a method for generating zero-shot, high recall cultural transmission in artificially intelligent agents. Our agents succeed at real-time cultural transmission from humans in novel contexts without using any pre-collected human data. We identify a surprisingly simple set of ingredients sufficient for generating cultural transmission and develop an evaluation methodology for rigorously assessing it. This paves the way for cultural evolution as an algorithm for developing artificial general intelligence.