 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Visual Analytics for Early Detection of Retinal Diseases
Dec 13, 2022
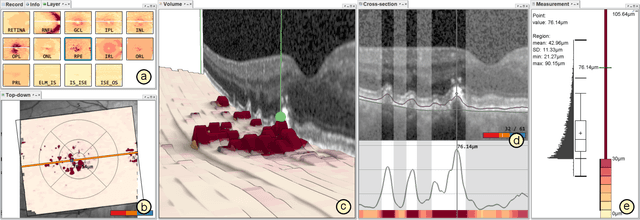
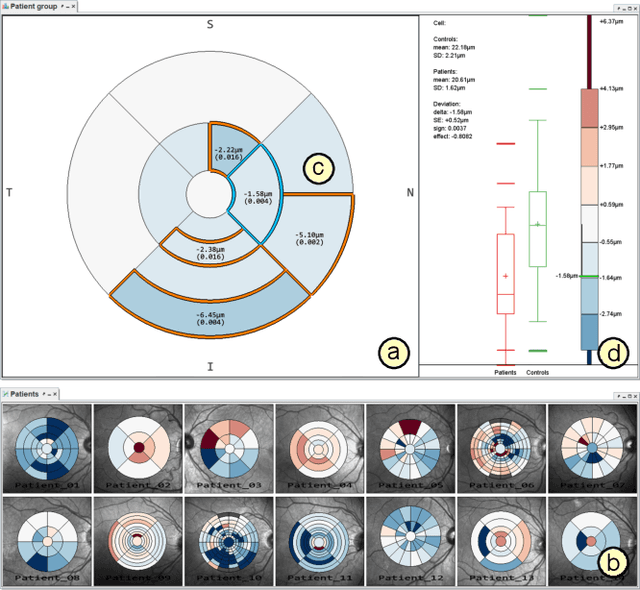
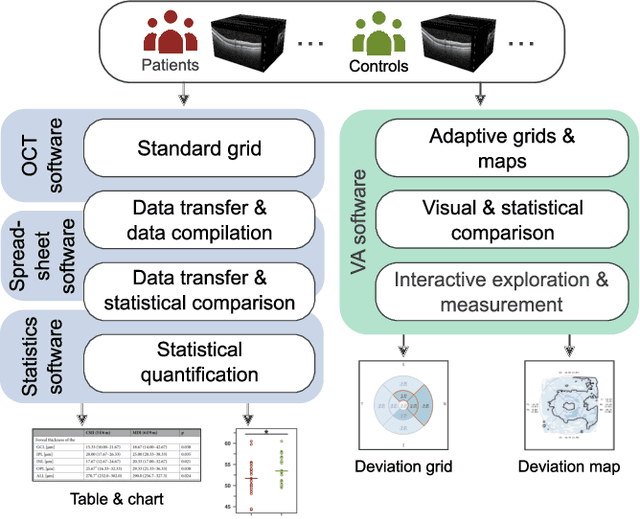
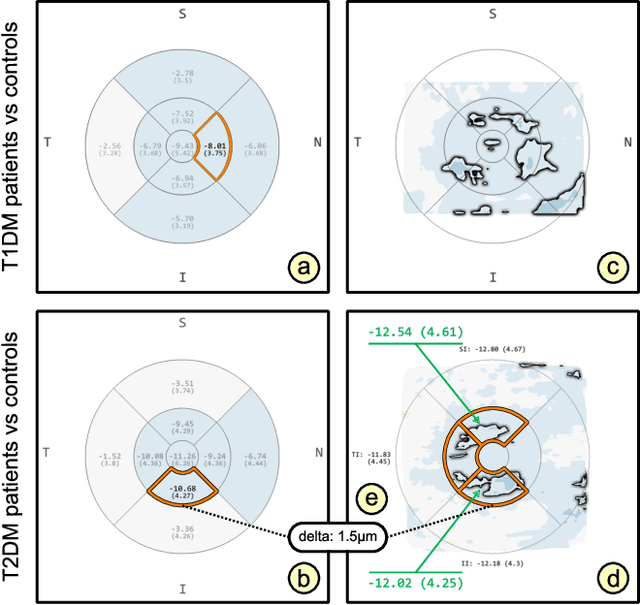
Advances in optical coherence tomography (OCT) have enabled noninvasive imaging of substructures of the human retina with high spatial resolution. OCT examinations are now a standard procedure in clinics and an integral part of ophthalmic research. The interpretation of the OCT helps ophthalmologists understand the impact of various retinal and systemic diseases on the structure of the retina in a way not previously possible. In the early stages of retinal diseases, however, the identification and analysis of small and localized substructural changes in the retina remains a challenge. We present an overview of novel visual analytics approaches for the interactive exploration of early retinal changes in single and multiple patients, the comparison of the changes with normative data, and automated quantification and measurement of diagnosis-relevant information. We developed these approaches in close collaboration with ophthalmology researchers and industry experts from a leading OCT device manufacturer. As a result, they not only significantly reduced the time and effort required for OCT data analysis, especially in the context of cross-sectional studies, but have also led to several new discoveries published in biomedical journals.
Neural representation of a time optimal, constant acceleration rendezvous
Mar 29, 2022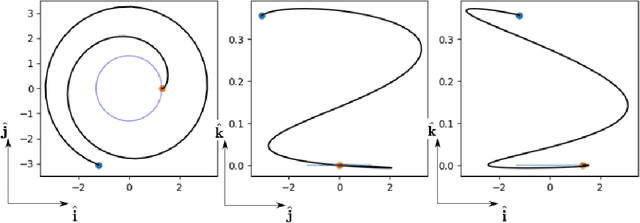
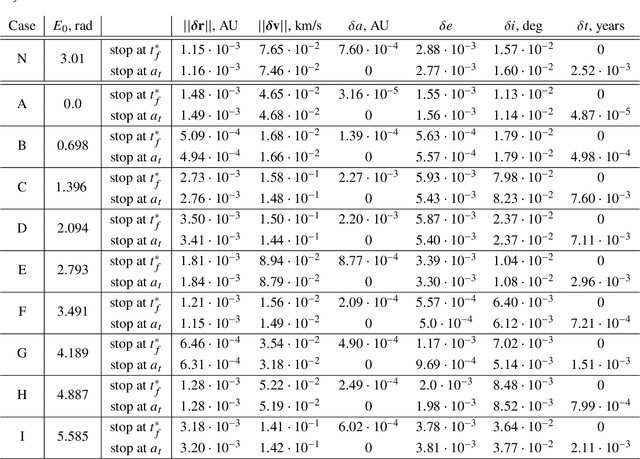
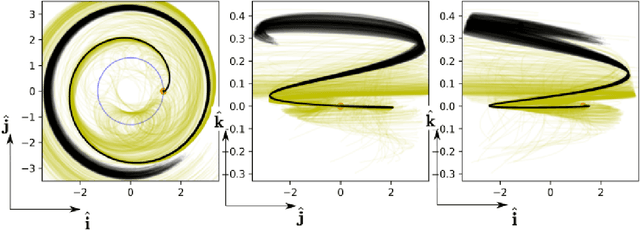
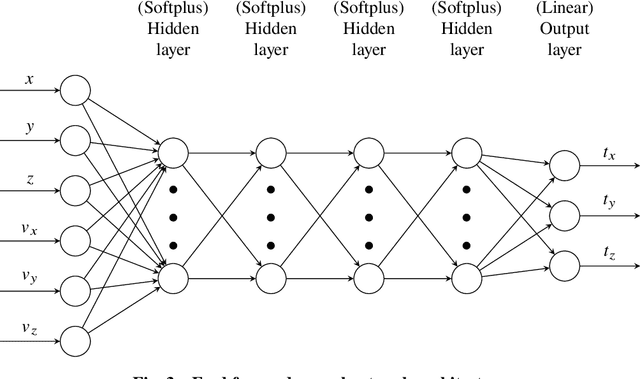
We train neural models to represent both the optimal policy (i.e. the optimal thrust direction) and the value function (i.e. the time of flight) for a time optimal, constant acceleration low-thrust rendezvous. In both cases we develop and make use of the data augmentation technique we call backward generation of optimal examples. We are thus able to produce and work with large dataset and to fully exploit the benefit of employing a deep learning framework. We achieve, in all cases, accuracies resulting in successful rendezvous (simulated following the learned policy) and time of flight predictions (using the learned value function). We find that residuals as small as a few m/s, thus well within the possibility of a spacecraft navigation $\Delta V$ budget, are achievable for the velocity at rendezvous. We also find that, on average, the absolute error to predict the optimal time of flight to rendezvous from any orbit in the asteroid belt to an Earth-like orbit is small (less than 4\%) and thus also of interest for practical uses, for example, during preliminary mission design phases.
Remote Medication Status Prediction for Individuals with Parkinson's Disease using Time-series Data from Smartphones
Jul 26, 2022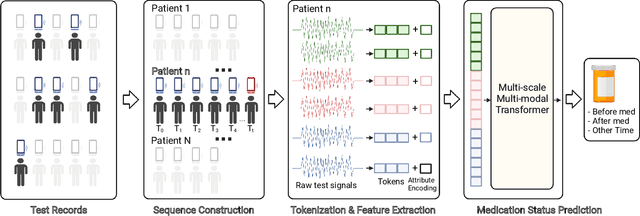
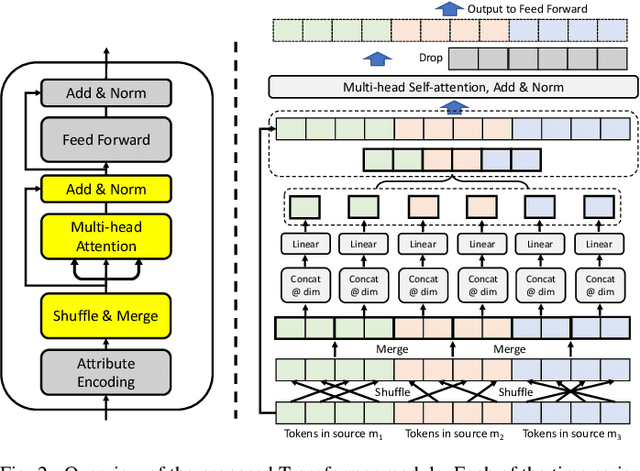
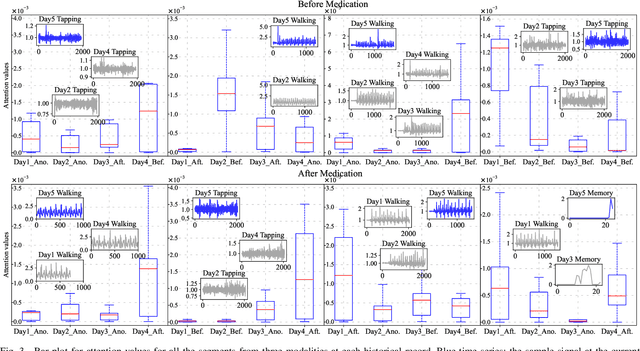
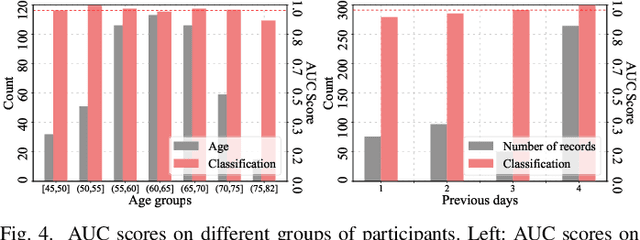
Medication for neurological diseases such as the Parkinson's disease usually happens remotely at home, away from hospitals. Such out-of-lab environments pose challenges in collecting timely and accurate health status data using the limited professional care devices for health condition analysis, medication adherence measurement and future dose or treatment planning. Individual differences in behavioral signals collected from wearable sensors also lead to difficulties in adopting current general machine learning analysis pipelines. To address these challenges, we present a method for predicting medication status of Parkinson's disease patients using the public mPower dataset, which contains 62,182 remote multi-modal test records collected on smartphones from 487 patients. The proposed method shows promising results in predicting three medication status objectively: Before Medication (AUC=0.95), After Medication (AUC=0.958), and Another Time (AUC=0.976) by examining patient-wise historical records with the attention weights learned through a Transformer model. We believe our method provides an innovative way for personalized remote health sensing in a timely and objective fashion which could benefit a broad range of similar applications.
Annotated History of Modern AI and Deep Learning
Dec 21, 2022Machine learning is the science of credit assignment: finding patterns in observations that predict consequences of actions and help to improve future performance. Credit assignment is also required for human understanding of how the world works, not only for individuals navigating daily life, but also for academic professionals like historians who interpret the present in light of past events. Here I focus on the history of modern artificial intelligence (AI) which is dominated by artificial neural networks (NNs) and deep learning, both conceptually closer to the old field of cybernetics than to what's been called AI since 1956 (e.g., expert systems and logic programming). A modern history of AI will emphasize breakthroughs outside of the focus of traditional AI text books, in particular, mathematical foundations of today's NNs such as the chain rule (1676), the first NNs (linear regression, circa 1800), and the first working deep learners (1965-). From the perspective of 2022, I provide a timeline of the -- in hindsight -- most important relevant events in the history of NNs, deep learning, AI, computer science, and mathematics in general, crediting those who laid foundations of the field. The text contains numerous hyperlinks to relevant overview sites from my AI Blog. It supplements my previous deep learning survey (2015) which provides hundreds of additional references. Finally, to round it off, I'll put things in a broader historic context spanning the time since the Big Bang until when the universe will be many times older than it is now.
Time and Cost-Efficient Bathymetric Mapping System using Sparse Point Cloud Generation and Automatic Object Detection
Oct 19, 2022
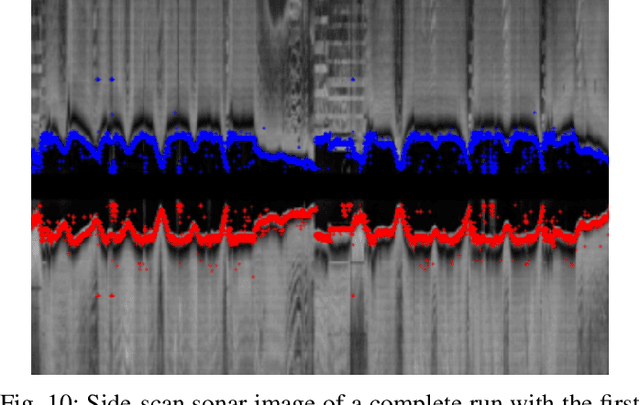
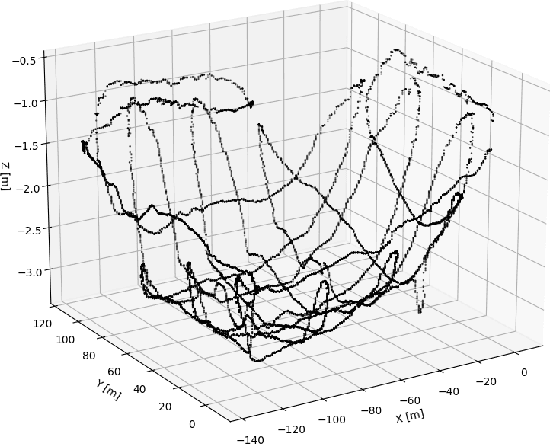
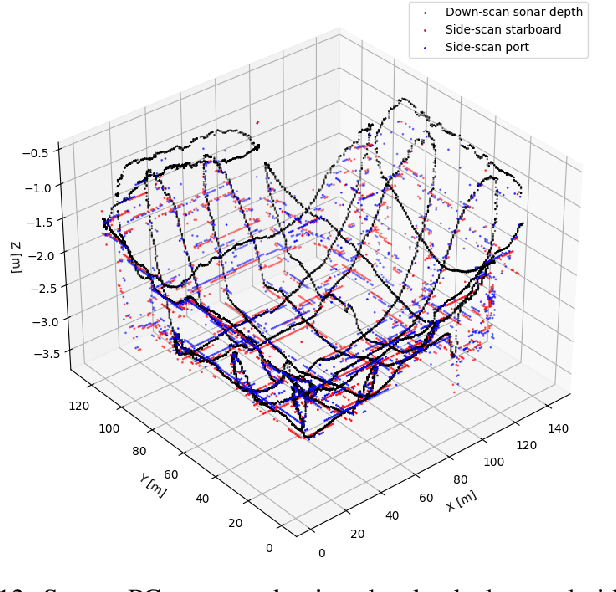
Generating 3D point cloud (PC) data from noisy sonar measurements is a problem that has potential applications for bathymetry mapping, artificial object inspection, mapping of aquatic plants and fauna as well as underwater navigation and localization of vehicles such as submarines. Side-scan sonar sensors are available in inexpensive cost ranges, especially in fish-finders, where the transducers are usually mounted to the bottom of a boat and can approach shallower depths than the ones attached to an Uncrewed Underwater Vehicle (UUV) can. However, extracting 3D information from side-scan sonar imagery is a difficult task because of its low signal-to-noise ratio and missing angle and depth information in the imagery. Since most algorithms that generate a 3D point cloud from side-scan sonar imagery use Shape from Shading (SFS) techniques, extracting 3D information is especially difficult when the seafloor is smooth, is slowly changing in depth, or does not have identifiable objects that make acoustic shadows. This paper introduces an efficient algorithm that generates a sparse 3D point cloud from side-scan sonar images. This computation is done in a computationally efficient manner by leveraging the geometry of the first sonar return combined with known positions provided by GPS and down-scan sonar depth measurement at each data point. Additionally, this paper implements another algorithm that uses a Convolutional Neural Network (CNN) using transfer learning to perform object detection on side-scan sonar images collected in real life and generated with a simulation. The algorithm was tested on both real and synthetic images to show reasonably accurate anomaly detection and classification.
Lifted Inference with Linear Order Axiom
Nov 02, 2022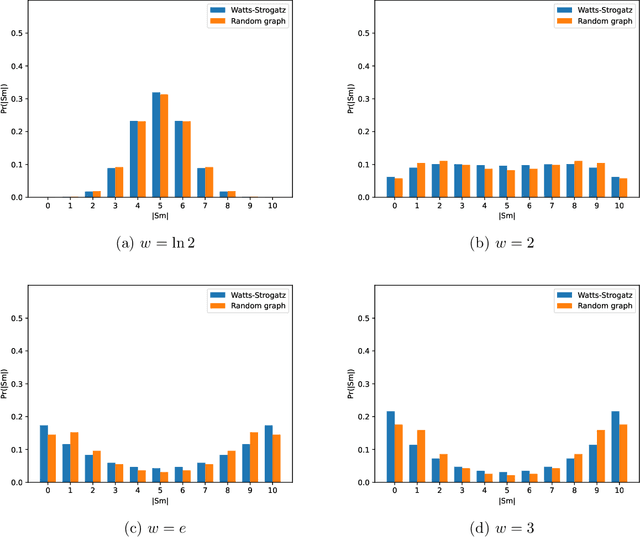
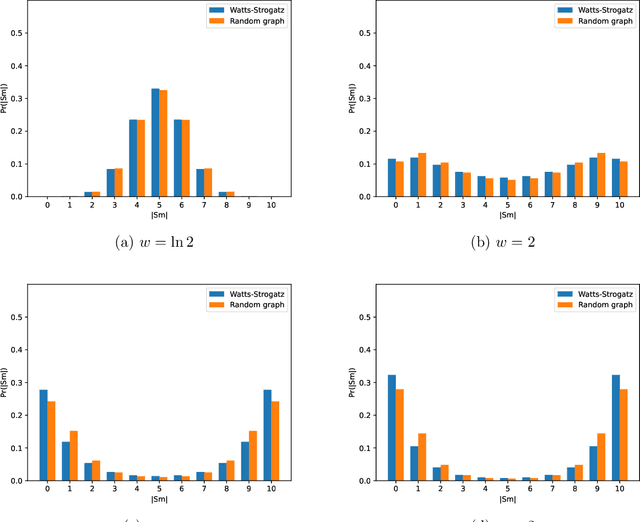
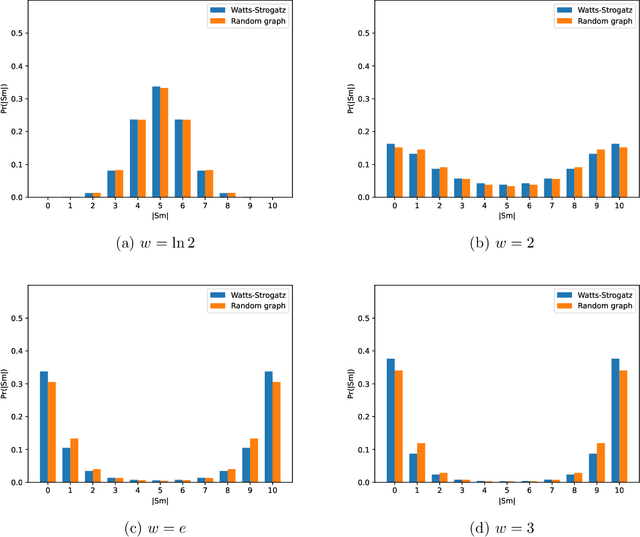
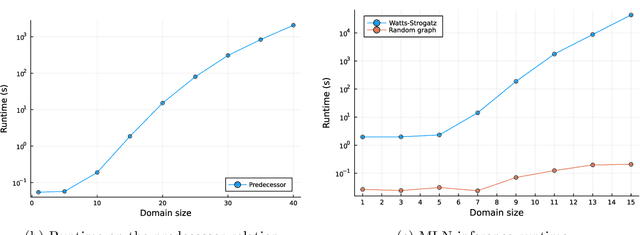
We consider the task of weighted first-order model counting (WFOMC) used for probabilistic inference in the area of statistical relational learning. Given a formula $\phi$, domain size $n$ and a pair of weight functions, what is the weighted sum of all models of $\phi$ over a domain of size $n$? It was shown that computing WFOMC of any logical sentence with at most two logical variables can be done in time polynomial in $n$. However, it was also shown that the task is $\texttt{#}P_1$-complete once we add the third variable, which inspired the search for extensions of the two-variable fragment that would still permit a running time polynomial in $n$. One of such extension is the two-variable fragment with counting quantifiers. In this paper, we prove that adding a linear order axiom (which forces one of the predicates in $\phi$ to introduce a linear ordering of the domain elements in each model of $\phi$) on top of the counting quantifiers still permits a computation time polynomial in the domain size. We present a new dynamic programming-based algorithm which can compute WFOMC with linear order in time polynomial in $n$, thus proving our primary claim.
Hierarchical Control Strategy for Moving A Robot Manipulator Between Small Containers
Nov 28, 2022
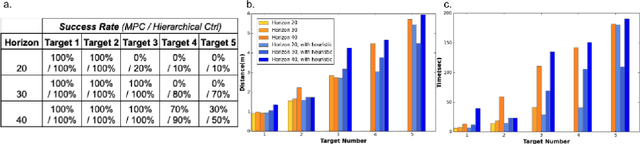
In this paper, we study the implementation of a model predictive controller (MPC) for the task of object manipulation in a highly uncertain environment (e.g., picking objects from a semi-flexible array of densely packed bins). As a real-time perception-driven feedback controller, MPC is robust to the uncertainties in this environment. However, our experiment shows MPC cannot control a robot to complete a sequence of motions in a heavily occluded environment due to its myopic nature. It will benefit from adding a high-level policy that adaptively adjusts the optimization problem for MPC.
Longest Common Substring in Longest Common Subsequence's Solution Service: A Novel Hyper-Heuristic
Dec 03, 2022
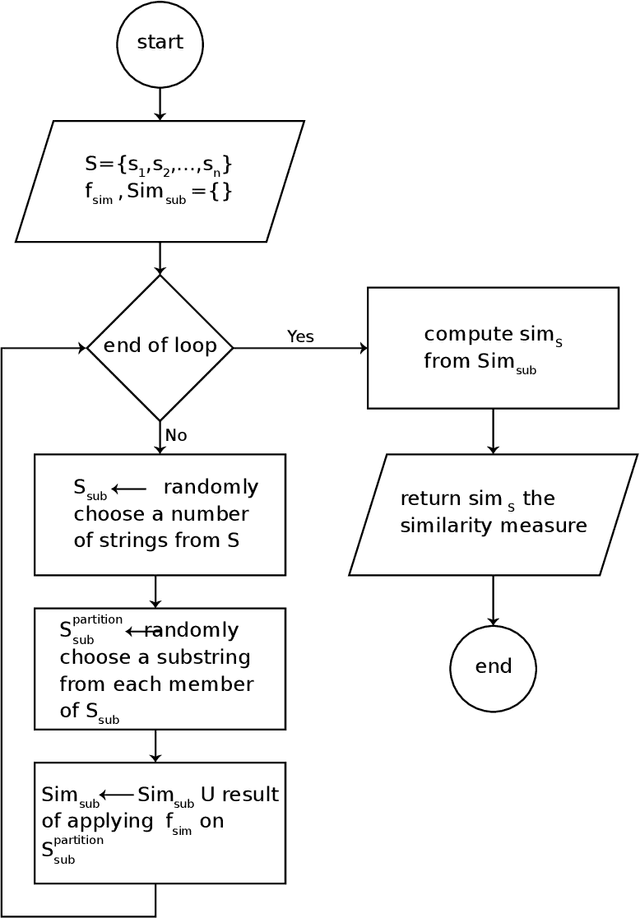
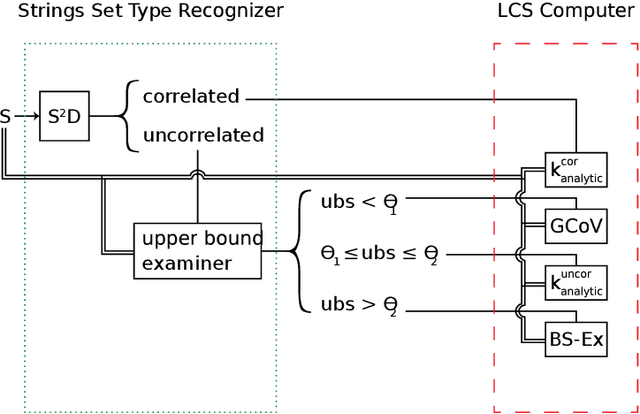

The Longest Common Subsequence (LCS) is the problem of finding a subsequence among a set of strings that has two properties of being common to all and is the longest. The LCS has applications in computational biology and text editing, among many others. Due to the NP-hardness of the general longest common subsequence, numerous heuristic algorithms and solvers have been proposed to give the best possible solution for different sets of strings. None of them has the best performance for all types of sets. In addition, there is no method to specify the type of a given set of strings. Besides that, the available hyper-heuristic is not efficient and fast enough to solve this problem in real-world applications. This paper proposes a novel hyper-heuristic to solve the longest common subsequence problem using a novel criterion to classify a set of strings based on their similarity. To do this, we offer a general stochastic framework to identify the type of a given set of strings. Following that, we introduce the set similarity dichotomizer ($S^2D$) algorithm based on the framework that divides the type of sets into two. This algorithm is introduced for the first time in this paper and opens a new way to go beyond the current LCS solvers. Then, we present a novel hyper-heuristic that exploits the $S^2D$ and one of the internal properties of the set to choose the best matching heuristic among a set of heuristics. We compare the results on benchmark datasets with the best heuristics and hyper-heuristics. The results show a higher performance of our proposed hyper-heuristic in both quality of solutions and run time factors.
Domain Generalization via Selective Consistency Regularization for Time Series Classification
Jun 16, 2022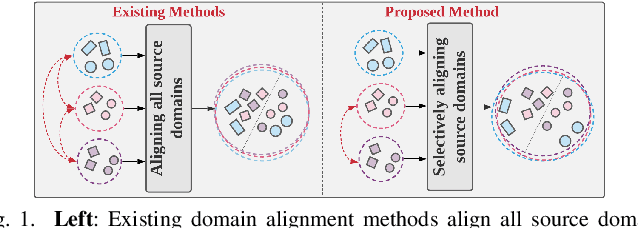
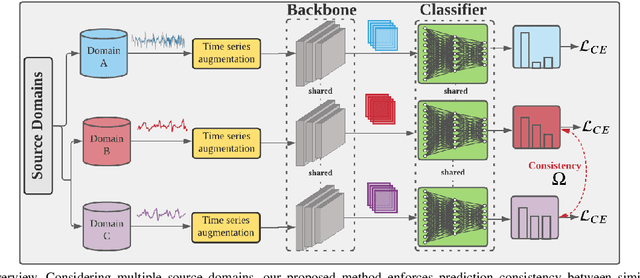
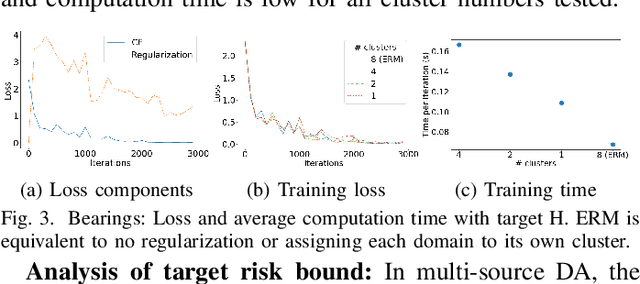
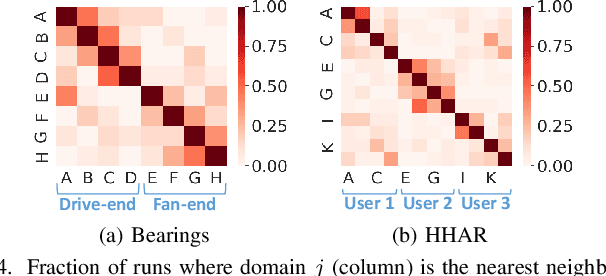
Domain generalization methods aim to learn models robust to domain shift with data from a limited number of source domains and without access to target domain samples during training. Popular domain alignment methods for domain generalization seek to extract domain-invariant features by minimizing the discrepancy between feature distributions across all domains, disregarding inter-domain relationships. In this paper, we instead propose a novel representation learning methodology that selectively enforces prediction consistency between source domains estimated to be closely-related. Specifically, we hypothesize that domains share different class-informative representations, so instead of aligning all domains which can cause negative transfer, we only regularize the discrepancy between closely-related domains. We apply our method to time-series classification tasks and conduct comprehensive experiments on three public real-world datasets. Our method significantly improves over the baseline and achieves better or competitive performance in comparison with state-of-the-art methods in terms of both accuracy and model calibration.
Visuotactile Affordances for Cloth Manipulation with Local Control
Dec 09, 2022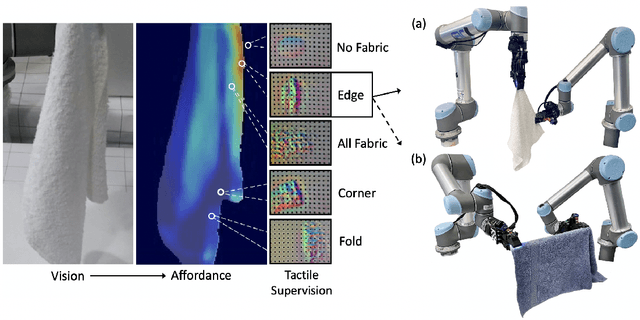

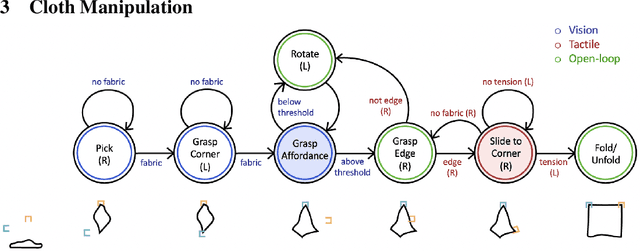
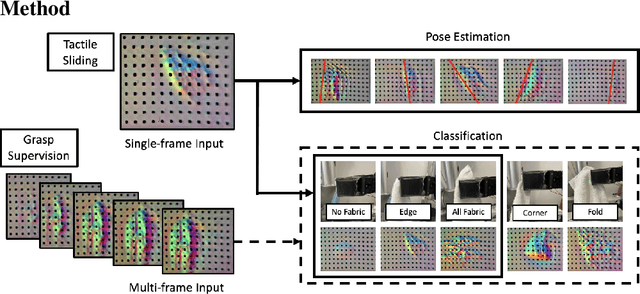
Cloth in the real world is often crumpled, self-occluded, or folded in on itself such that key regions, such as corners, are not directly graspable, making manipulation difficult. We propose a system that leverages visual and tactile perception to unfold the cloth via grasping and sliding on edges. By doing so, the robot is able to grasp two adjacent corners, enabling subsequent manipulation tasks like folding or hanging. As components of this system, we develop tactile perception networks that classify whether an edge is grasped and estimate the pose of the edge. We use the edge classification network to supervise a visuotactile edge grasp affordance network that can grasp edges with a 90% success rate. Once an edge is grasped, we demonstrate that the robot can slide along the cloth to the adjacent corner using tactile pose estimation/control in real time. See http://nehasunil.com/visuotactile/visuotactile.html for videos.