 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Land Cover and Land Use Detection using Semi-Supervised Learning
Dec 21, 2022
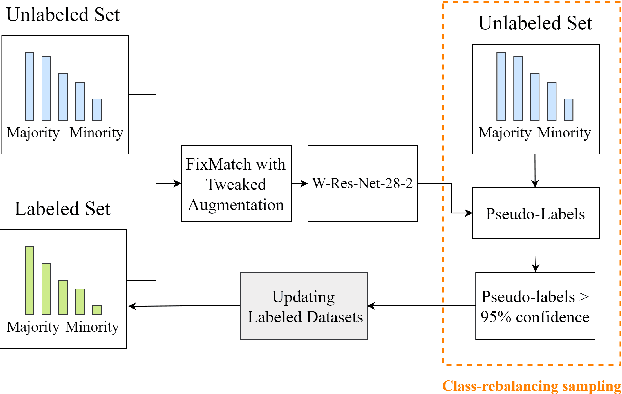
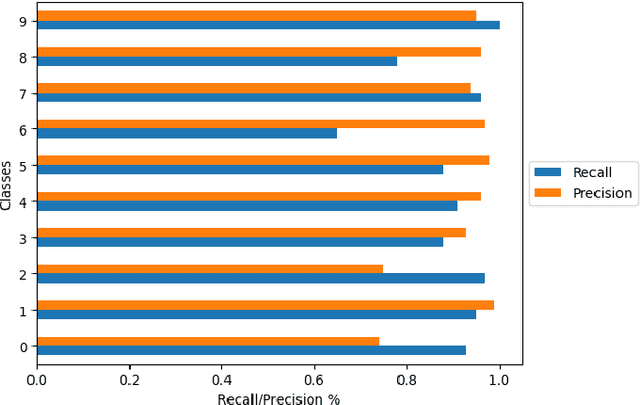
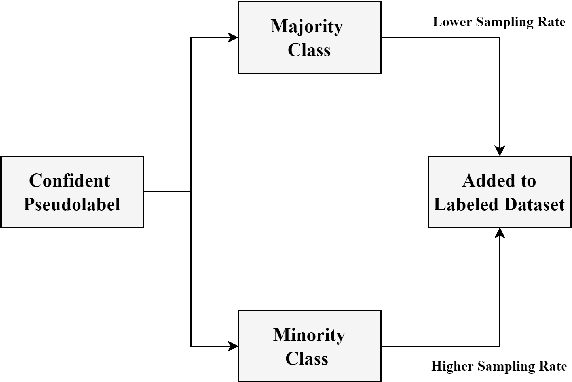
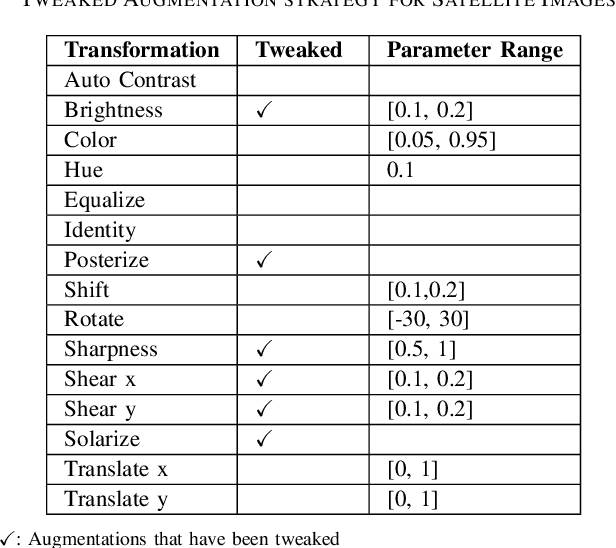
Semi-supervised learning (SSL) has made significant strides in the field of remote sensing. Finding a large number of labeled datasets for SSL methods is uncommon, and manually labeling datasets is expensive and time-consuming. Furthermore, accurately identifying remote sensing satellite images is more complicated than it is for conventional images. Class-imbalanced datasets are another prevalent phenomenon, and models trained on these become biased towards the majority classes. This becomes a critical issue with an SSL model's subpar performance. We aim to address the issue of labeling unlabeled data and also solve the model bias problem due to imbalanced datasets while achieving better accuracy. To accomplish this, we create "artificial" labels and train a model to have reasonable accuracy. We iteratively redistribute the classes through resampling using a distribution alignment technique. We use a variety of class imbalanced satellite image datasets: EuroSAT, UCM, and WHU-RS19. On UCM balanced dataset, our method outperforms previous methods MSMatch and FixMatch by 1.21% and 0.6%, respectively. For imbalanced EuroSAT, our method outperforms MSMatch and FixMatch by 1.08% and 1%, respectively. Our approach significantly lessens the requirement for labeled data, consistently outperforms alternative approaches, and resolves the issue of model bias caused by class imbalance in datasets.
Text classification in shipping industry using unsupervised models and Transformer based supervised models
Dec 21, 2022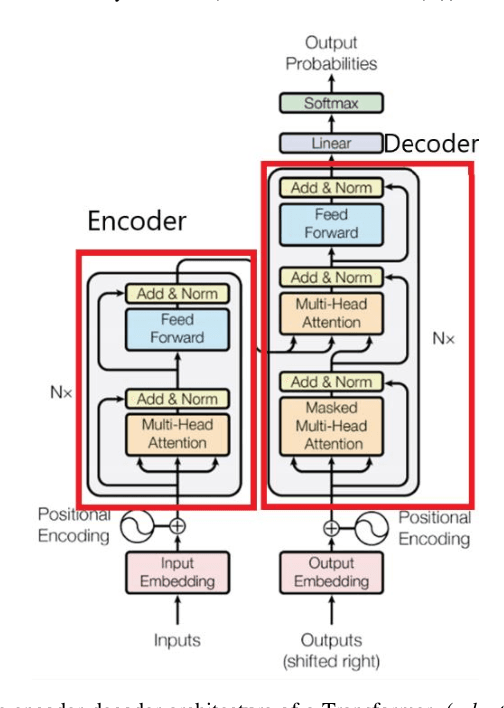
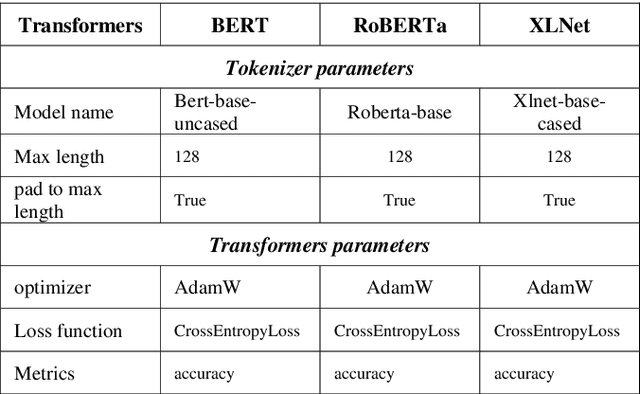
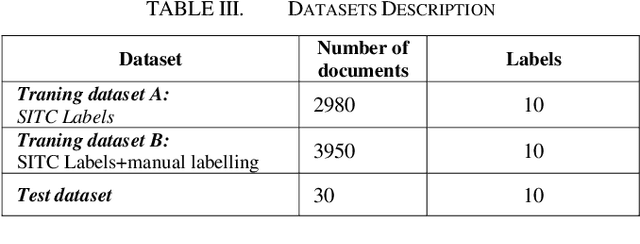
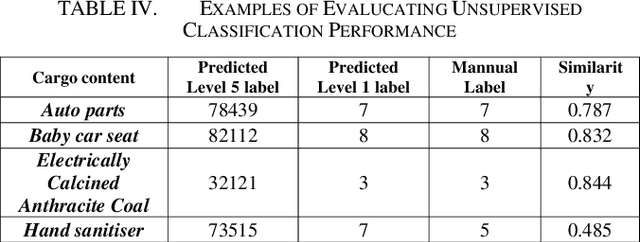
Obtaining labelled data in a particular context could be expensive and time consuming. Although different algorithms, including unsupervised learning, semi-supervised learning, self-learning have been adopted, the performance of text classification varies with context. Given the lack of labelled dataset, we proposed a novel and simple unsupervised text classification model to classify cargo content in international shipping industry using the Standard International Trade Classification (SITC) codes. Our method stems from representing words using pretrained Glove Word Embeddings and finding the most likely label using Cosine Similarity. To compare unsupervised text classification model with supervised classification, we also applied several Transformer models to classify cargo content. Due to lack of training data, the SITC numerical codes and the corresponding textual descriptions were used as training data. A small number of manually labelled cargo content data was used to evaluate the classification performances of the unsupervised classification and the Transformer based supervised classification. The comparison reveals that unsupervised classification significantly outperforms Transformer based supervised classification even after increasing the size of the training dataset by 30%. Lacking training data is a key bottleneck that prohibits deep learning models (such as Transformers) from successful practical applications. Unsupervised classification can provide an alternative efficient and effective method to classify text when there is scarce training data.
Winning the Lottery Ahead of Time: Efficient Early Network Pruning
Jun 21, 2022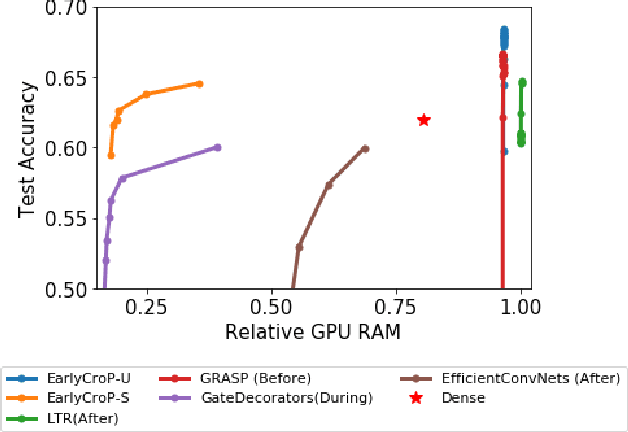
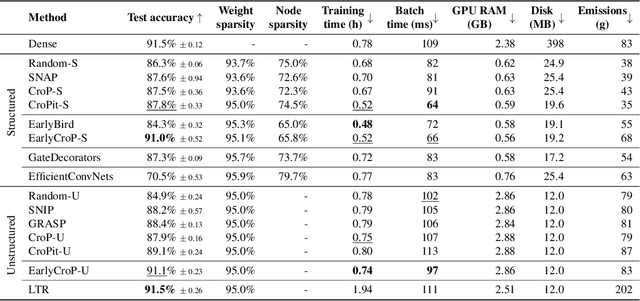
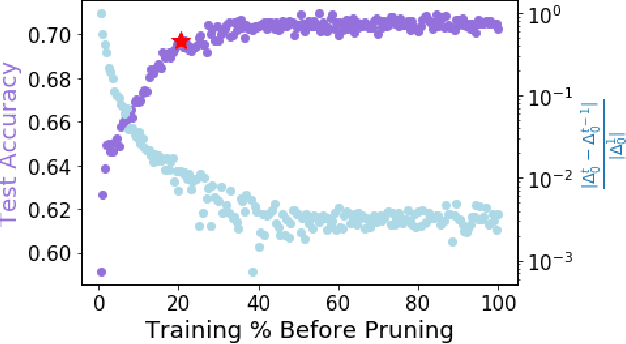
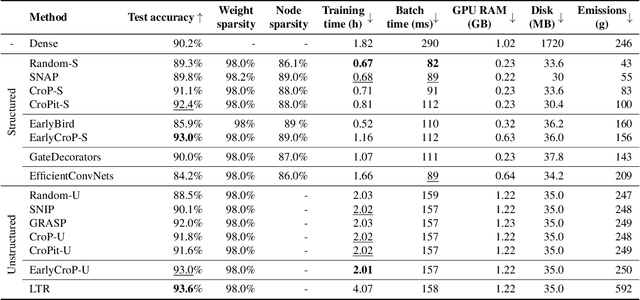
Pruning, the task of sparsifying deep neural networks, received increasing attention recently. Although state-of-the-art pruning methods extract highly sparse models, they neglect two main challenges: (1) the process of finding these sparse models is often very expensive; (2) unstructured pruning does not provide benefits in terms of GPU memory, training time, or carbon emissions. We propose Early Compression via Gradient Flow Preservation (EarlyCroP), which efficiently extracts state-of-the-art sparse models before or early in training addressing challenge (1), and can be applied in a structured manner addressing challenge (2). This enables us to train sparse networks on commodity GPUs whose dense versions would be too large, thereby saving costs and reducing hardware requirements. We empirically show that EarlyCroP outperforms a rich set of baselines for many tasks (incl. classification, regression) and domains (incl. computer vision, natural language processing, and reinforcment learning). EarlyCroP leads to accuracy comparable to dense training while outperforming pruning baselines.
Continuous Methods : Adaptively intrusive reduced order model closure
Nov 30, 2022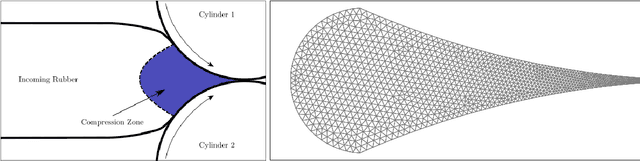

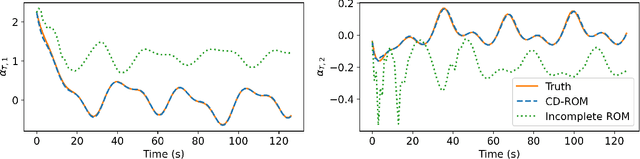
Reduced order modeling methods are often used as a mean to reduce simulation costs in industrial applications. Despite their computational advantages, reduced order models (ROMs) often fail to accurately reproduce complex dynamics encountered in real life applications. To address this challenge, we leverage NeuralODEs to propose a novel ROM correction approach based on a time-continuous memory formulation. Finally, experimental results show that our proposed method provides a high level of accuracy while retaining the low computational costs inherent to reduced models.
Iterative execution of discrete and inverse discrete Fourier transforms with applications for signal denoising via sparsification
Nov 17, 2022
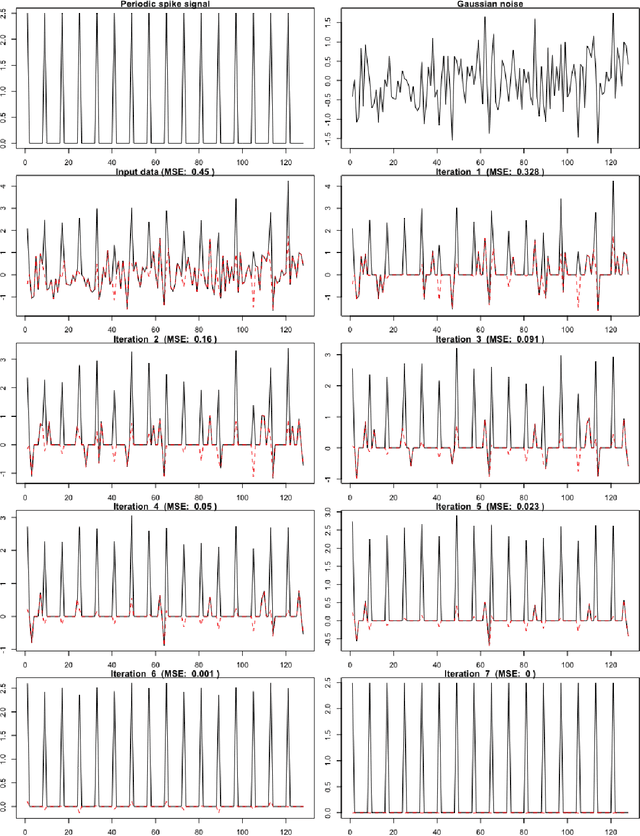
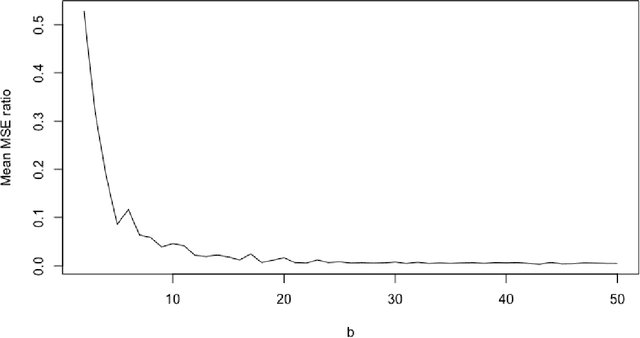
We describe a family of iterative algorithms that involve the repeated execution of discrete and inverse discrete Fourier transforms. One interesting member of this family is motivated by the discrete Fourier transform uncertainty principle and involves the application of a sparsification operation to both the time domain and frequency domain data with convergence obtained when time domain sparsity hits a stable pattern. This sparsification variant has practical utility for signal denoising, in particular the recovery of a periodic spike signal in the presence of Gaussian noise. General convergence properties and denoising performance are demonstrated using simulation studies. We are not aware of prior work on such iterative Fourier transformation algorithms and are posting this short paper in part to solicit feedback from others in the field who may be familiar with similar techniques.
Improving Deep Localized Level Analysis: How Game Logs Can Help
Dec 07, 2022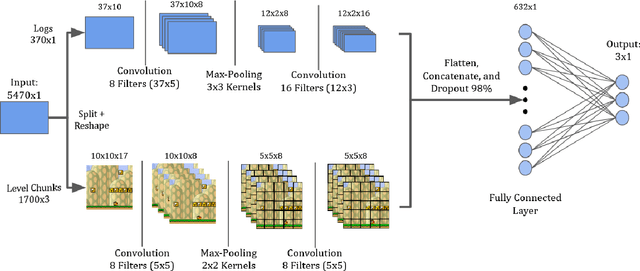

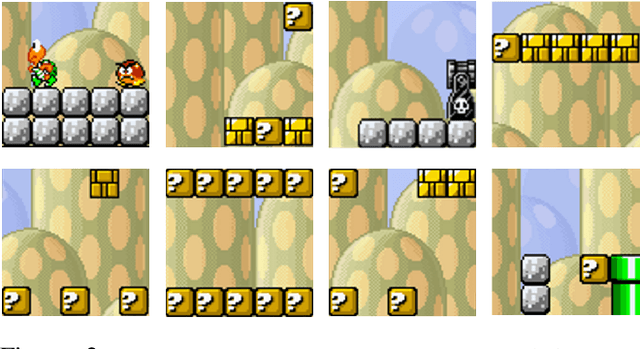
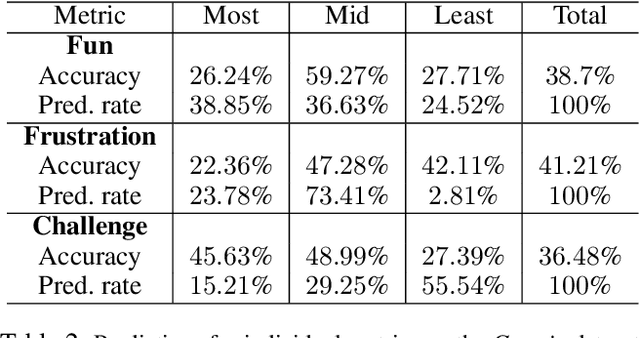
Player modelling is the field of study associated with understanding players. One pursuit in this field is affect prediction: the ability to predict how a game will make a player feel. We present novel improvements to affect prediction by using a deep convolutional neural network (CNN) to predict player experience trained on game event logs in tandem with localized level structure information. We test our approach on levels based on Super Mario Bros. (Infinite Mario Bros.) and Super Mario Bros.: The Lost Levels (Gwario), as well as original Super Mario Bros. levels. We outperform prior work, and demonstrate the utility of training on player logs, even when lacking them at test time for cross-domain player modelling.
Deep Neural Network Based Accelerated Failure Time Models using Rank Loss
Jun 13, 2022
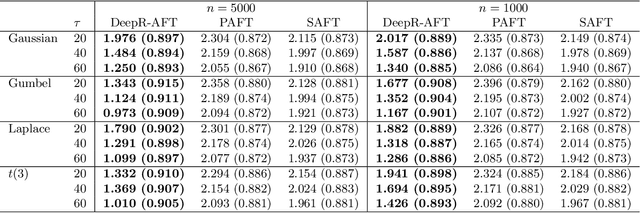
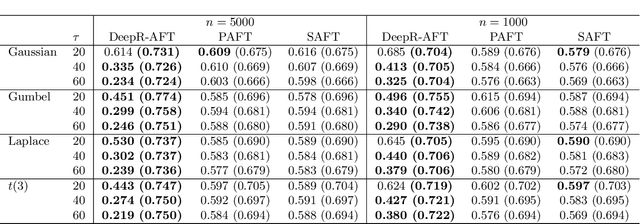
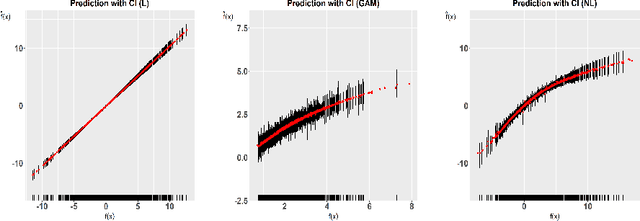
An accelerated failure time (AFT) model assumes a log-linear relationship between failure times and a set of covariates. In contrast to other popular survival models that work on hazard functions, the effects of covariates are directly on failure times, whose interpretation is intuitive. The semiparametric AFT model that does not specify the error distribution is flexible and robust to departures from the distributional assumption. Owing to the desirable features, this class of models has been considered as a promising alternative to the popular Cox model in the analysis of censored failure time data. However, in these AFT models, a linear predictor for the mean is typically assumed. Little research has addressed the nonlinearity of predictors when modeling the mean. Deep neural networks (DNNs) have received a focal attention over the past decades and have achieved remarkable success in a variety of fields. DNNs have a number of notable advantages and have been shown to be particularly useful in addressing the nonlinearity. By taking advantage of this, we propose to apply DNNs in fitting AFT models using a Gehan-type loss, combined with a sub-sampling technique. Finite sample properties of the proposed DNN and rank based AFT model (DeepR-AFT) are investigated via an extensive stimulation study. DeepR-AFT shows a superior performance over its parametric or semiparametric counterparts when the predictor is nonlinear. For linear predictors, DeepR-AFT performs better when the dimensions of covariates are large. The proposed DeepR-AFT is illustrated using two real datasets, which demonstrates its superiority.
Domain Generalization Strategy to Train Classifiers Robust to Spatial-Temporal Shift
Dec 10, 2022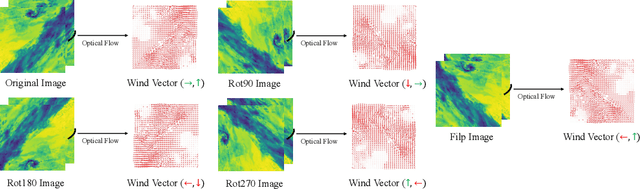
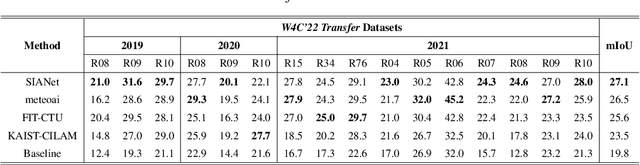
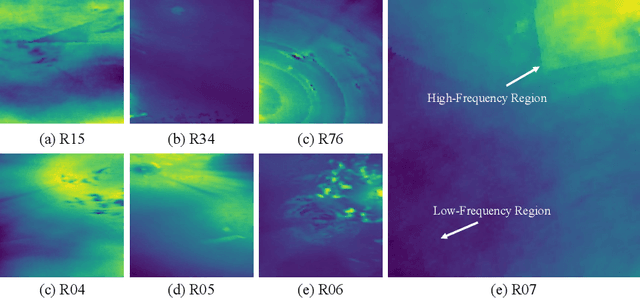
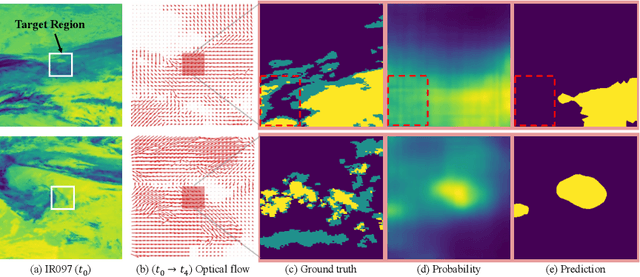
Deep learning-based weather prediction models have advanced significantly in recent years. However, data-driven models based on deep learning are difficult to apply to real-world applications because they are vulnerable to spatial-temporal shifts. A weather prediction task is especially susceptible to spatial-temporal shifts when the model is overfitted to locality and seasonality. In this paper, we propose a training strategy to make the weather prediction model robust to spatial-temporal shifts. We first analyze the effect of hyperparameters and augmentations of the existing training strategy on the spatial-temporal shift robustness of the model. Next, we propose an optimal combination of hyperparameters and augmentation based on the analysis results and a test-time augmentation. We performed all experiments on the W4C22 Transfer dataset and achieved the 1st performance.
Estimating counterfactual treatment outcomes over time in complex multi-agent scenarios
Jun 04, 2022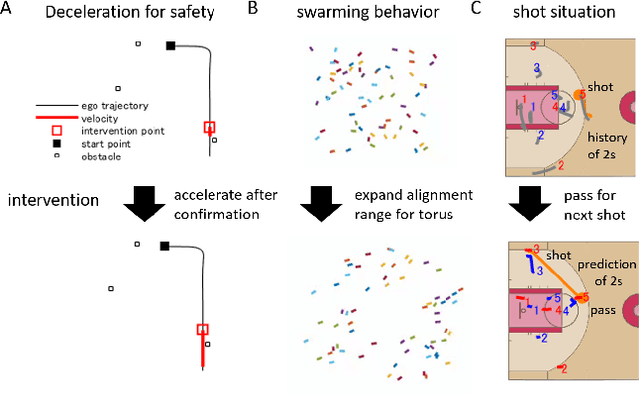
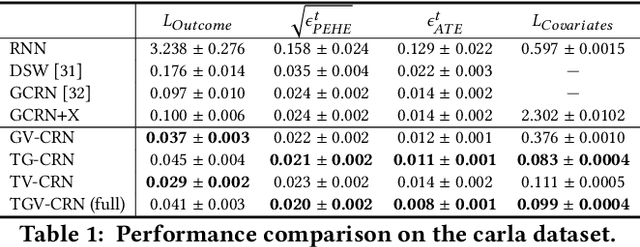
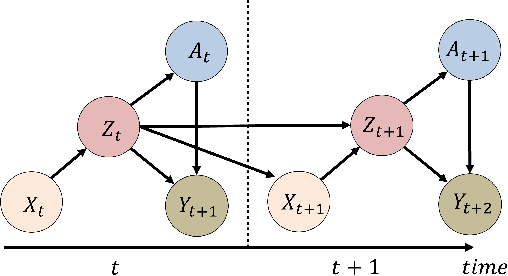
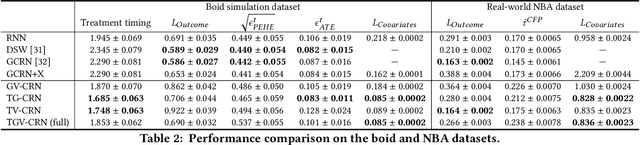
Evaluation of intervention in a multi-agent system, e.g., when humans should intervene in autonomous driving systems and when a player should pass to teammates for a good shot, is challenging in various engineering and scientific fields. Estimating the individual treatment effect (ITE) using counterfactual long-term prediction is practical to evaluate such interventions. However, most of the conventional frameworks did not consider the time-varying complex structure of multi-agent relationships and covariate counterfactual prediction. This may sometimes lead to erroneous assessments of ITE and interpretation problems. Here we propose an interpretable, counterfactual recurrent network in multi-agent systems to estimate the effect of the intervention. Our model leverages graph variational recurrent neural networks and theory-based computation with domain knowledge for the ITE estimation framework based on long-term prediction of multi-agent covariates and outcomes, which can confirm under the circumstances under which the intervention is effective. On simulated models of an automated vehicle and biological agents with time-varying confounders, we show that our methods achieved lower estimation errors in counterfactual covariates and the most effective treatment timing than the baselines. Furthermore, using real basketball data, our methods performed realistic counterfactual predictions and evaluated the counterfactual passes in shot scenarios.
Interactive Concept Bottleneck Models
Dec 14, 2022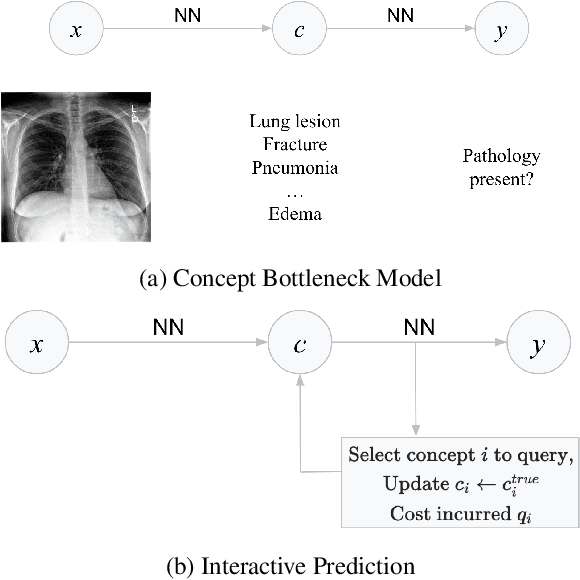
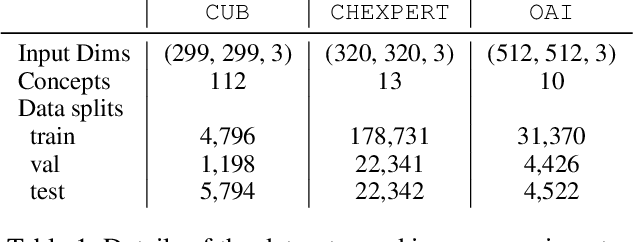
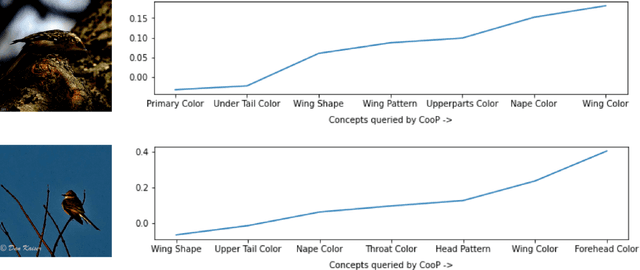
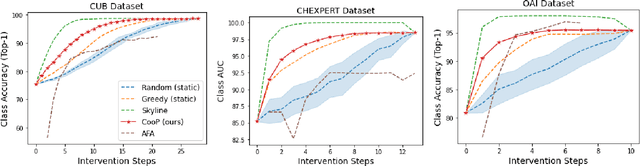
Concept bottleneck models (CBMs) (Koh et al. 2020) are interpretable neural networks that first predict labels for human-interpretable concepts relevant to the prediction task, and then predict the final label based on the concept label predictions.We extend CBMs to interactive prediction settings where the model can query a human collaborator for the label to some concepts. We develop an interaction policy that, at prediction time, chooses which concepts to request a label for so as to maximally improve the final prediction. We demonstrate thata simple policy combining concept prediction uncertainty and influence of the concept on the final prediction achieves strong performance and outperforms a static approach proposed in Koh et al. (2020) as well as active feature acquisition methods proposed in the literature. We show that the interactiveCBM can achieve accuracy gains of 5-10% with only 5 interactions over competitive baselines on the Caltech-UCSDBirds, CheXpert and OAI datasets.