 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FasterX: Real-Time Object Detection Based on Edge GPUs for UAV Applications
Sep 07, 2022
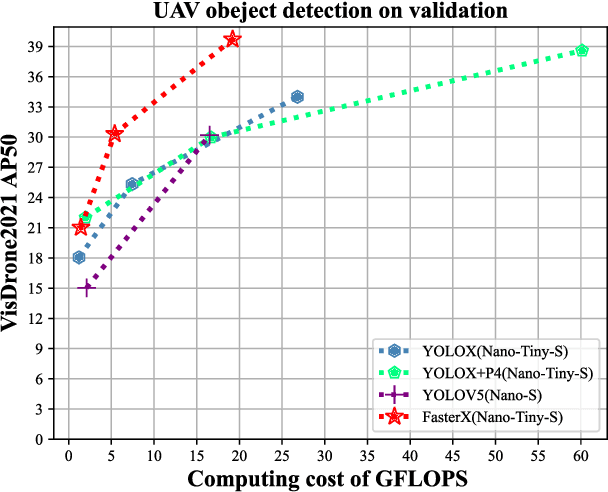

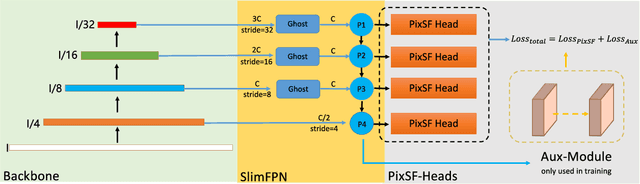
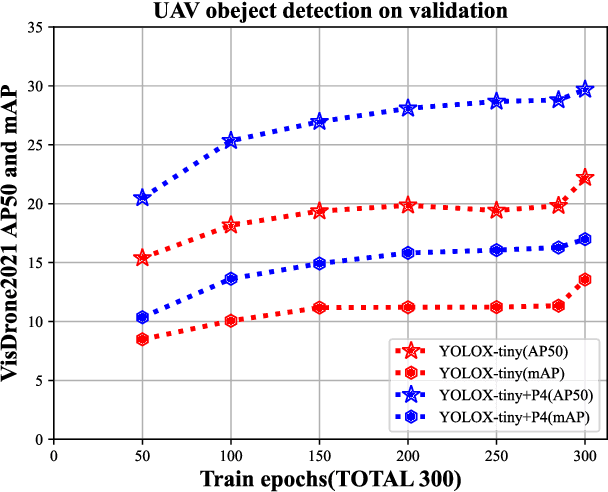
Real-time object detection on Unmanned Aerial Vehicles (UAVs) is a challenging issue due to the limited computing resources of edge GPU devices as Internet of Things (IoT) nodes. To solve this problem, in this paper, we propose a novel lightweight deep learning architectures named FasterX based on YOLOX model for real-time object detection on edge GPU. First, we design an effective and lightweight PixSF head to replace the original head of YOLOX to better detect small objects, which can be further embedded in the depthwise separable convolution (DS Conv) to achieve a lighter head. Then, a slimmer structure in the Neck layer termed as SlimFPN is developed to reduce parameters of the network, which is a trade-off between accuracy and speed. Furthermore, we embed attention module in the Head layer to improve the feature extraction effect of the prediction head. Meanwhile, we also improve the label assignment strategy and loss function to alleviate category imbalance and box optimization problems of the UAV dataset. Finally, auxiliary heads are presented for online distillation to improve the ability of position embedding and feature extraction in PixSF head. The performance of our lightweight models are validated experimentally on the NVIDIA Jetson NX and Jetson Nano GPU embedded platforms.Extensive experiments show that FasterX models achieve better trade-off between accuracy and latency on VisDrone2021 dataset compared to state-of-the-art models.
DAMS-LIO: A Degeneration-Aware and Modular Sensor-Fusion LiDAR-inertial Odometry
Feb 03, 2023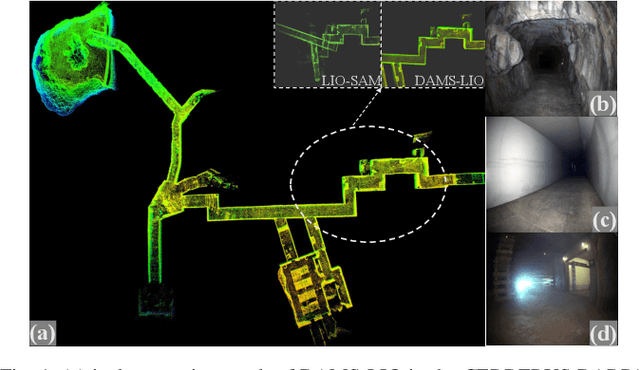
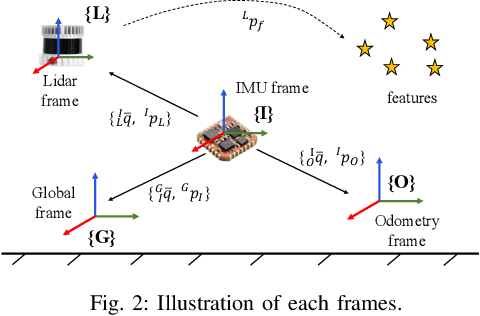
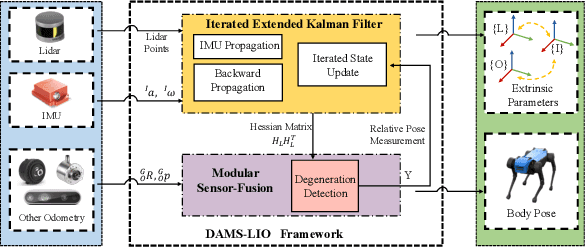
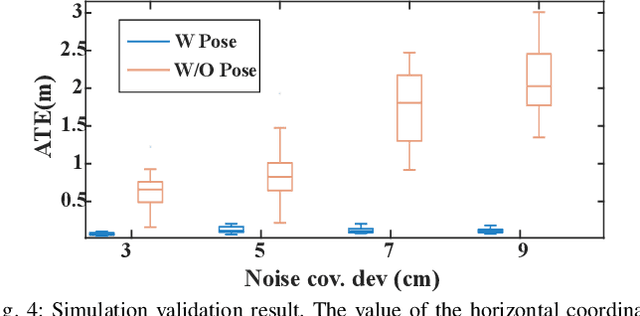
The fusion scheme is crucial to the multi-sensor fusion method that is the promising solution to the state estimation in complex and extreme environments like underground mines and planetary surfaces. In this work, a light-weight iEKF-based LiDAR-inertial odometry system is presented, which utilizes a degeneration-aware and modular sensor-fusion pipeline that takes both LiDAR points and relative pose from another odometry as the measurement in the update process only when degeneration is detected. Both the CRLB theory and simulation test are used to demonstrate the higher accuracy of our method compared to methods using a single observation. Furthermore, the proposed system is evaluated in perceptually challenging datasets against various state-of-the-art sensor-fusion methods. The results show that the proposed system achieves real-time and high estimation accuracy performance despite the challenging environment and poor observations.
Scalable Lossless Coding of Dynamic Medical CT Data Using Motion Compensated Wavelet Lifting with Denoised Prediction and Update
Feb 03, 2023
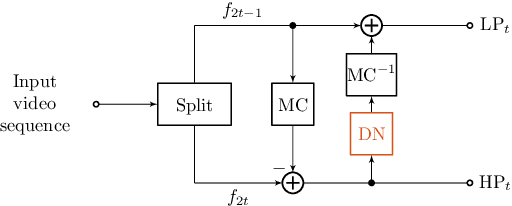
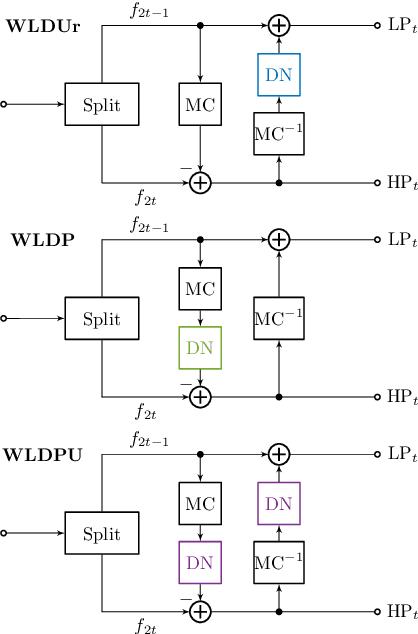
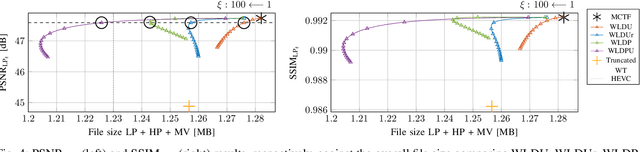
Professional applications like telemedicine often require scalable lossless coding of sensitive data. 3-D subband coding has turned out to offer good compression results for dynamic CT data and additionally provides a scalable representation in terms of low- and highpass subbands. To improve the visual quality of the lowpass subband, motion compensation can be incorporated into the lifting structure, but leads to inferior compression results at the same time. Prior work has shown that a denoising filter in the update step can improve the compression ratio. In this paper, we present a new processing order of motion compensation and denoising in the update step and additionally introduce a second denoising filter in the prediction step. This allows for reducing the overall file size by up to 4.4%, while the visual quality of the lowpass subband is kept nearly constant.
Mind the Gap -- Modelling Difference Between Censored and Uncensored Electric Vehicle Charging Demand
Jan 24, 2023
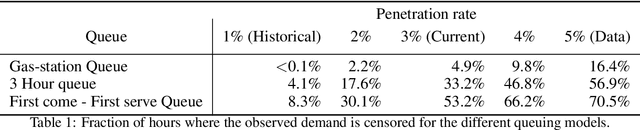
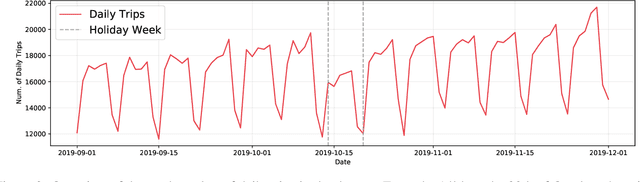

Electric vehicle charging demand models, with charging records as input, will inherently be biased toward the supply of available chargers, as the data do not include demand lost from occupied stations and competitors. This lost demand implies that the records only observe a fraction of the total demand, i.e. the observations are censored, and actual demand is likely higher than what the data reflect. Machine learning models often neglect to account for this censored demand when forecasting the charging demand, which limits models' applications for future expansions and supply management. We address this gap by modelling the charging demand with probabilistic censorship-aware graph neural networks, which learn the latent demand distribution in both the spatial and temporal dimensions. We use GPS trajectories from cars in Copenhagen, Denmark, to study how censoring occurs and much demand is lost due to occupied charging and competing services. We find that censorship varies throughout the city and over time, encouraging spatial and temporal modelling. We find that in some regions of Copenhagen, censorship occurs 61% of the time. Our results show censorship-aware models provide better prediction and uncertainty estimation in actual future demand than censorship-unaware models. Our results suggest that future models based on charging records should account for the censoring to expand the application areas of machine learning models in this supply management and infrastructure expansion.
Read the Signs: Towards Invariance to Gradient Descent's Hyperparameter Initialization
Jan 24, 2023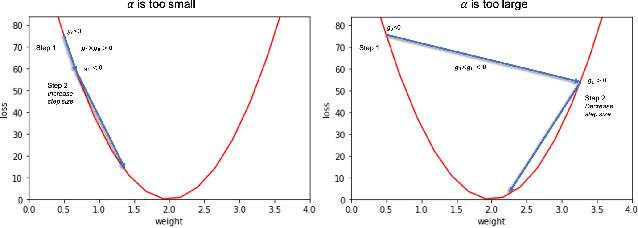
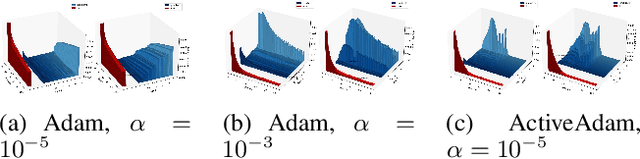

We propose ActiveLR, an optimization meta algorithm that localizes the learning rate, $\alpha$, and adapts them at each epoch according to whether the gradient at each epoch changes sign or not. This sign-conscious algorithm is aware of whether from the previous step to the current one the update of each parameter has been too large or too small and adjusts the $\alpha$ accordingly. We implement the Active version (ours) of widely used and recently published gradient descent optimizers, namely SGD with momentum, AdamW, RAdam, and AdaBelief. Our experiments on ImageNet, CIFAR-10, WikiText-103, WikiText-2, and PASCAL VOC using different model architectures, such as ResNet and Transformers, show an increase in generalizability and training set fit, and decrease in training time for the Active variants of the tested optimizers. The results also show robustness of the Active variant of these optimizers to different values of the initial learning rate. Furthermore, the detrimental effects of using large mini-batch sizes are mitigated. ActiveLR, thus, alleviates the need for hyper-parameter search for two of the most commonly tuned hyper-parameters that require heavy time and computational costs to pick. We encourage AI researchers and practitioners to use the Active variant of their optimizer of choice for faster training, better generalizability, and reducing carbon footprint of training deep neural networks.
Comparing Ordering Strategies For Process Discovery Using Synthesis Rules
Jan 04, 2023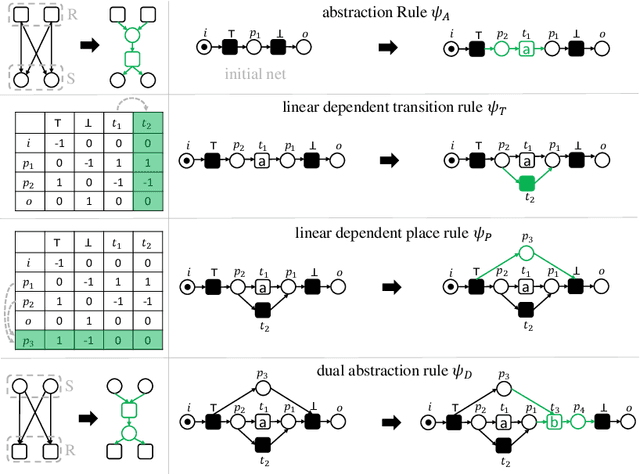
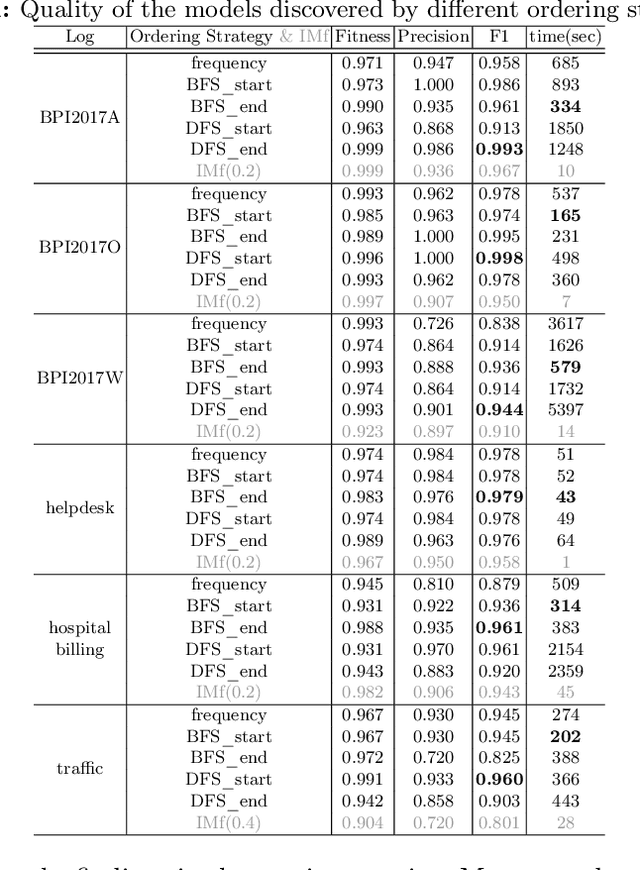

Process discovery aims to learn process models from observed behaviors, i.e., event logs, in the information systems.The discovered models serve as the starting point for process mining techniques that are used to address performance and compliance problems. Compared to the state-of-the-art Inductive Miner, the algorithm applying synthesis rules from the free-choice net theory discovers process models with more flexible (non-block) structures while ensuring the same desirable soundness and free-choiceness properties. Moreover, recent development in this line of work shows that the discovered models have compatible quality. Following the synthesis rules, the algorithm incrementally modifies an existing process model by adding the activities in the event log one at a time. As the applications of rules are highly dependent on the existing model structure, the model quality and computation time are significantly influenced by the order of adding activities. In this paper, we investigate the effect of different ordering strategies on the discovered models (w.r.t. fitness and precision) and the computation time using real-life event data. The results show that the proposed ordering strategy can improve the quality of the resulting process models while requiring less time compared to the ordering strategy solely based on the frequency of activities.
Convolutional Neural Network-Based Automatic Classification of Colorectal and Prostate Tumor Biopsies Using Multispectral Imagery: System Development Study
Jan 30, 2023
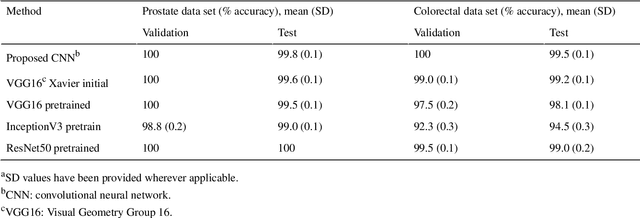

Colorectal and prostate cancers are the most common types of cancer in men worldwide. To diagnose colorectal and prostate cancer, a pathologist performs a histological analysis on needle biopsy samples. This manual process is time-consuming and error-prone, resulting in high intra and interobserver variability, which affects diagnosis reliability. This study aims to develop an automatic computerized system for diagnosing colorectal and prostate tumors by using images of biopsy samples to reduce time and diagnosis error rates associated with human analysis. We propose a CNN model for classifying colorectal and prostate tumors from multispectral images of biopsy samples. The key idea was to remove the last block of the convolutional layers and halve the number of filters per layer. Our results showed excellent performance, with an average test accuracy of 99.8% and 99.5% for the prostate and colorectal data sets, respectively. The system showed excellent performance when compared with pretrained CNNs and other classification methods, as it avoids the preprocessing phase while using a single CNN model for classification. Overall, the proposed CNN architecture was globally the best-performing system for classifying colorectal and prostate tumor images. The proposed CNN was detailed and compared with previously trained network models used as feature extractors. These CNNs were also compared with other classification techniques. As opposed to pretrained CNNs and other classification approaches, the proposed CNN yielded excellent results. The computational complexity of the CNNs was also investigated, it was shown that the proposed CNN is better at classifying images than pretrained networks because it does not require preprocessing. Thus, the overall analysis was that the proposed CNN architecture was globally the best-performing system for classifying colorectal and prostate tumor images.
DANLIP: Deep Autoregressive Networks for Locally Interpretable Probabilistic Forecasting
Jan 05, 2023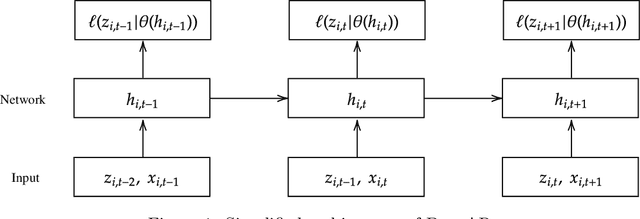
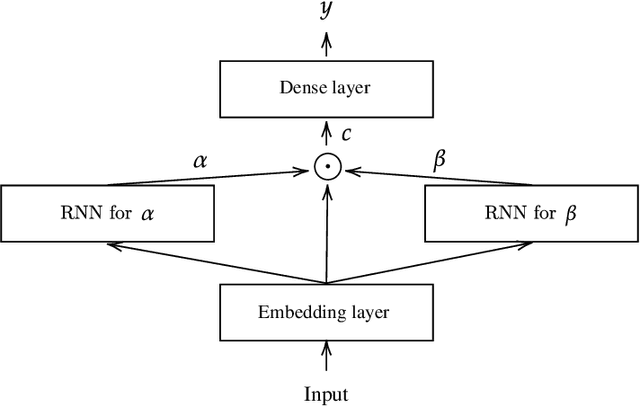
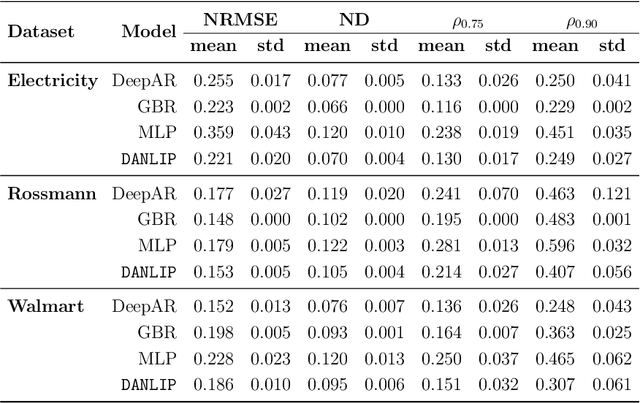
Despite the high performance of neural network-based time series forecasting methods, the inherent challenge in explaining their predictions has limited their applicability in certain application areas. Due to the difficulty in identifying causal relationships between the input and output of such black-box methods, they rarely have been adopted in domains such as legal and medical fields in which the reliability and interpretability of the results can be essential. In this paper, we propose \model, a novel deep learning-based probabilistic time series forecasting architecture that is intrinsically interpretable. We conduct experiments with multiple datasets and performance metrics and empirically show that our model is not only interpretable but also provides comparable performance to state-of-the-art probabilistic time series forecasting methods. Furthermore, we demonstrate that interpreting the parameters of the stochastic processes of interest can provide useful insights into several application areas.
Time Series Forecasting Models Copy the Past: How to Mitigate
Jul 27, 2022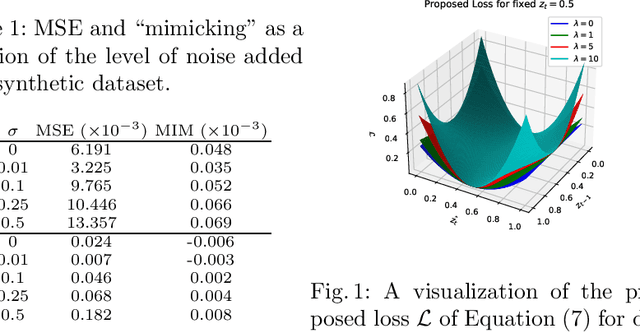
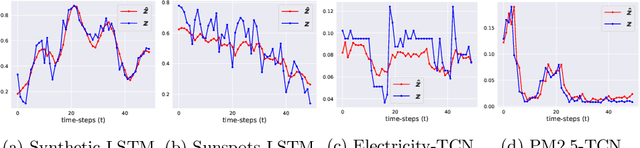
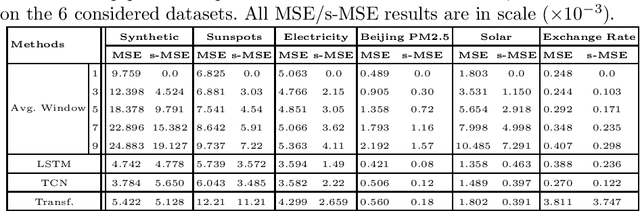
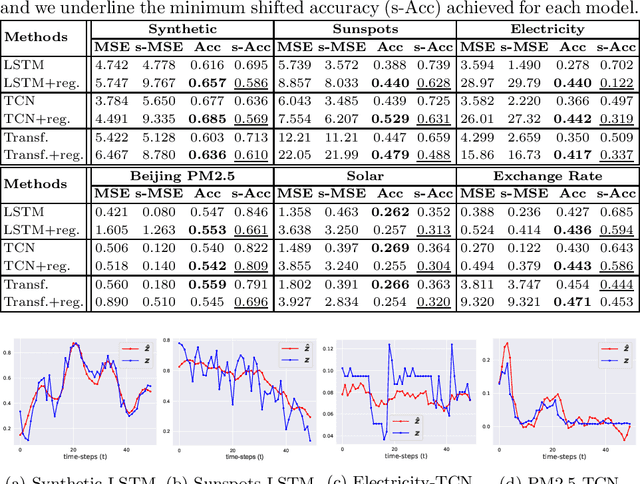
Time series forecasting is at the core of important application domains posing significant challenges to machine learning algorithms. Recently neural network architectures have been widely applied to the problem of time series forecasting. Most of these models are trained by minimizing a loss function that measures predictions' deviation from the real values. Typical loss functions include mean squared error (MSE) and mean absolute error (MAE). In the presence of noise and uncertainty, neural network models tend to replicate the last observed value of the time series, thus limiting their applicability to real-world data. In this paper, we provide a formal definition of the above problem and we also give some examples of forecasts where the problem is observed. We also propose a regularization term penalizing the replication of previously seen values. We evaluate the proposed regularization term both on synthetic and real-world datasets. Our results indicate that the regularization term mitigates to some extent the aforementioned problem and gives rise to more robust models.
Event-guided Multi-patch Network with Self-supervision for Non-uniform Motion Deblurring
Feb 14, 2023Contemporary deep learning multi-scale deblurring models suffer from many issues: 1) They perform poorly on non-uniformly blurred images/videos; 2) Simply increasing the model depth with finer-scale levels cannot improve deblurring; 3) Individual RGB frames contain a limited motion information for deblurring; 4) Previous models have a limited robustness to spatial transformations and noise. Below, we extend the DMPHN model by several mechanisms to address the above issues: I) We present a novel self-supervised event-guided deep hierarchical Multi-patch Network (MPN) to deal with blurry images and videos via fine-to-coarse hierarchical localized representations; II) We propose a novel stacked pipeline, StackMPN, to improve the deblurring performance under the increased network depth; III) We propose an event-guided architecture to exploit motion cues contained in videos to tackle complex blur in videos; IV) We propose a novel self-supervised step to expose the model to random transformations (rotations, scale changes), and make it robust to Gaussian noises. Our MPN achieves the state of the art on the GoPro and VideoDeblur datasets with a 40x faster runtime compared to current multi-scale methods. With 30ms to process an image at 1280x720 resolution, it is the first real-time deep motion deblurring model for 720p images at 30fps. For StackMPN, we obtain significant improvements over 1.2dB on the GoPro dataset by increasing the network depth. Utilizing the event information and self-supervision further boost results to 33.83dB.