 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Start Team Orienteering Problem for UAS Mission Re-Planning with Data-Efficient Deep Reinforcement Learning
Mar 02, 2023

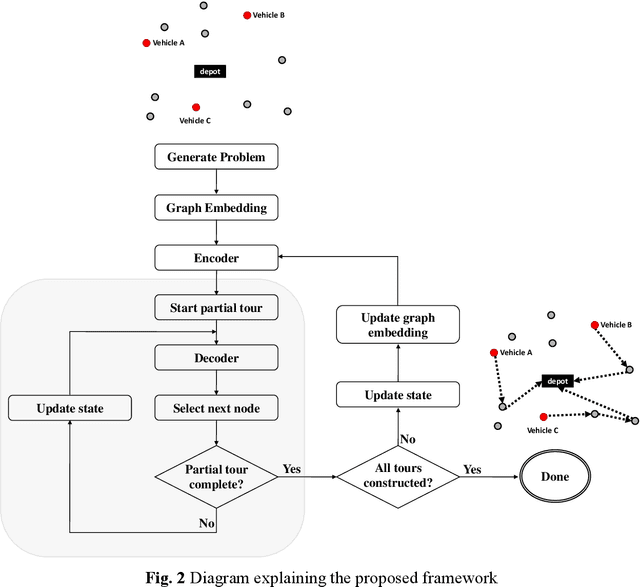

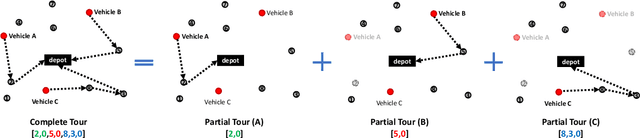
In this paper, we study the Multi-Start Team Orienteering Problem (MSTOP), a mission re-planning problem where vehicles are initially located away from the depot and have different amounts of fuel. We consider/assume the goal of multiple vehicles is to travel to maximize the sum of collected profits under resource (e.g., time, fuel) consumption constraints. Such re-planning problems occur in a wide range of intelligent UAS applications where changes in the mission environment force the operation of multiple vehicles to change from the original plan. To solve this problem with deep reinforcement learning (RL), we develop a policy network with self-attention on each partial tour and encoder-decoder attention between the partial tour and the remaining nodes. We propose a modified REINFORCE algorithm where the greedy rollout baseline is replaced by a local mini-batch baseline based on multiple, possibly non-duplicate sample rollouts. By drawing multiple samples per training instance, we can learn faster and obtain a stable policy gradient estimator with significantly fewer instances. The proposed training algorithm outperforms the conventional greedy rollout baseline, even when combined with the maximum entropy objective.
AugNet: Dynamic Test-Time Augmentation via Differentiable Functions
Dec 09, 2022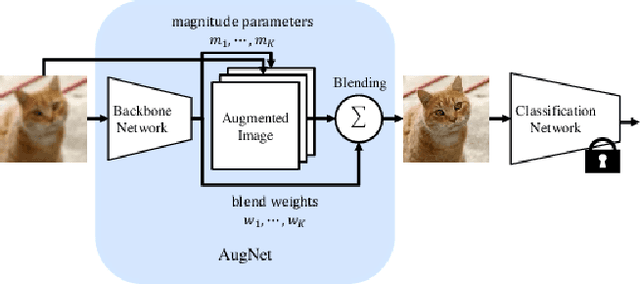
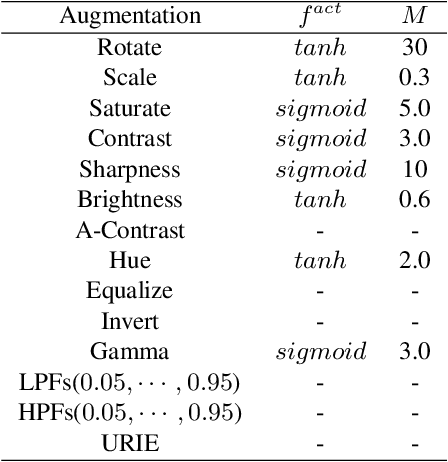
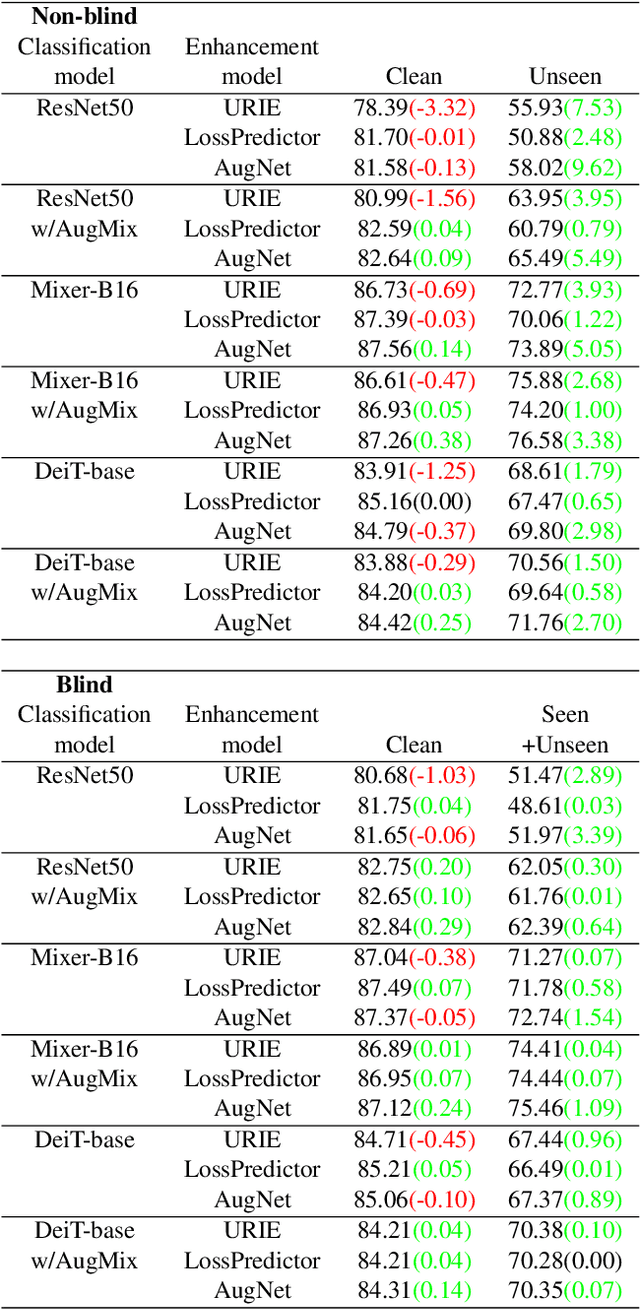
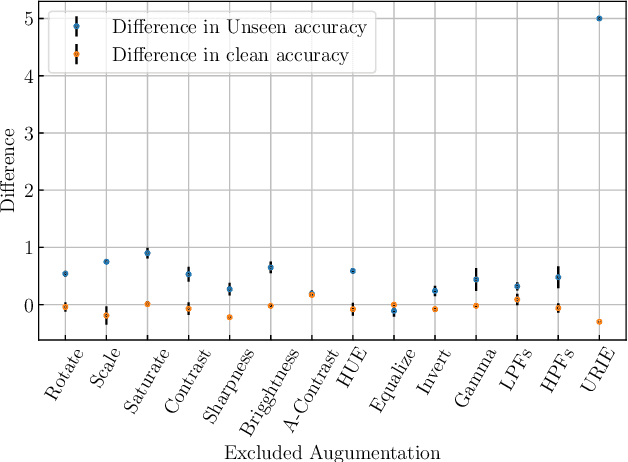
Distribution shifts, which often occur in the real world, degrade the accuracy of deep learning systems, and thus improving robustness is essential for practical applications. To improve robustness, we study an image enhancement method that generates recognition-friendly images without retraining the recognition model. We propose a novel image enhancement method, AugNet, which is based on differentiable data augmentation techniques and generates a blended image from many augmented images to improve the recognition accuracy under distribution shifts. In addition to standard data augmentations, AugNet can also incorporate deep neural network-based image transformation, which further improves the robustness. Because AugNet is composed of differentiable functions, AugNet can be directly trained with the classification loss of the recognition model. AugNet is evaluated on widely used image recognition datasets using various classification models, including Vision Transformer and MLP-Mixer. AugNet improves the robustness with almost no reduction in classification accuracy for clean images, which is a better result than the existing methods. Furthermore, we show that interpretation of distribution shifts using AugNet and retraining based on that interpretation can greatly improve robustness.
Chronological Self-Training for Real-Time Speaker Diarization
Aug 05, 2022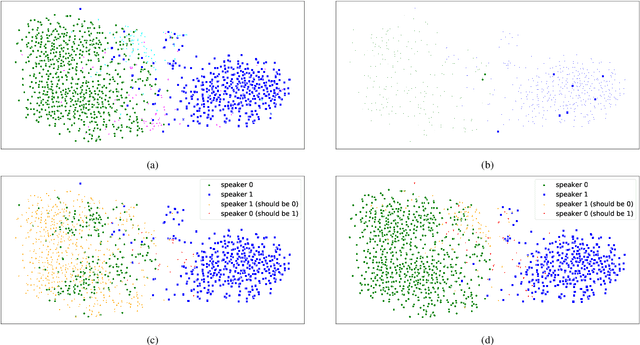
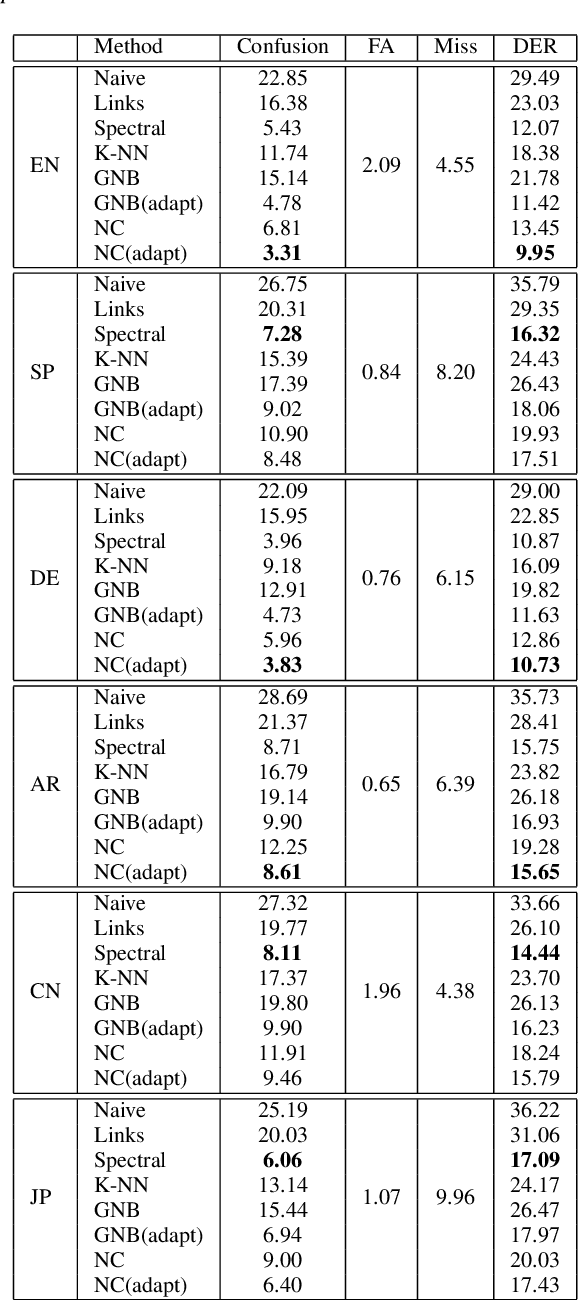
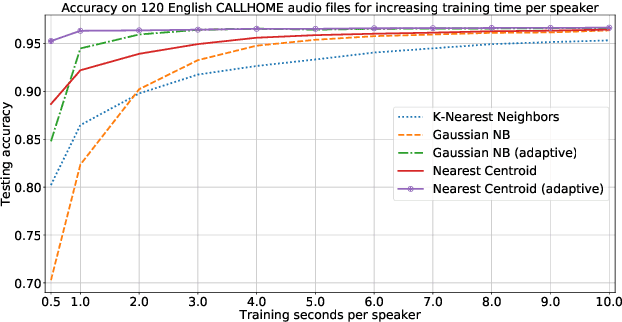
Diarization partitions an audio stream into segments based on the voices of the speakers. Real-time diarization systems that include an enrollment step should limit enrollment training samples to reduce user interaction time. Although training on a small number of samples yields poor performance, we show that the accuracy can be improved dramatically using a chronological self-training approach. We studied the tradeoff between training time and classification performance and found that 1 second is sufficient to reach over 95% accuracy. We evaluated on 700 audio conversation files of about 10 minutes each from 6 different languages and demonstrated average diarization error rates as low as 10%.
* 5 pages, 5 figures, ICASSP 2021
Attention Mechanism for Contrastive Learning in GAN-based Image-to-Image Translation
Feb 23, 2023

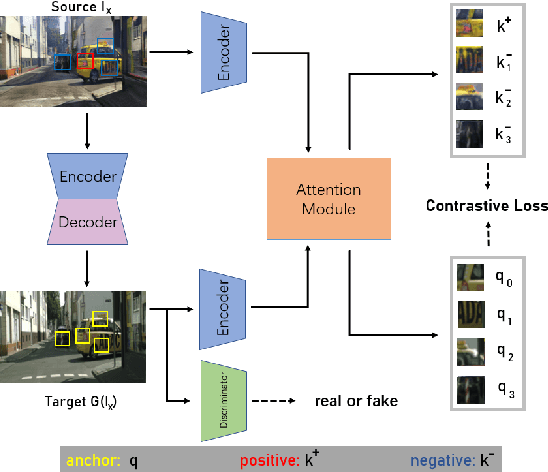
Using real road testing to optimize autonomous driving algorithms is time-consuming and capital-intensive. To solve this problem, we propose a GAN-based model that is capable of generating high-quality images across different domains. We further leverage Contrastive Learning to train the model in a self-supervised way using image data acquired in the real world using real sensors and simulated images from 3D games. In this paper, we also apply an Attention Mechanism module to emphasize features that contain more information about the source domain according to their measurement of significance. Finally, the generated images are used as datasets to train neural networks to perform a variety of downstream tasks to verify that the approach can fill in the gaps between the virtual and real worlds.
Bayesian Structure Scores for Probabilistic Circuits
Feb 23, 2023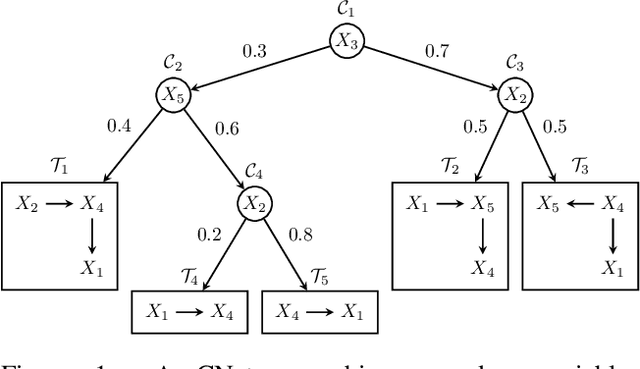
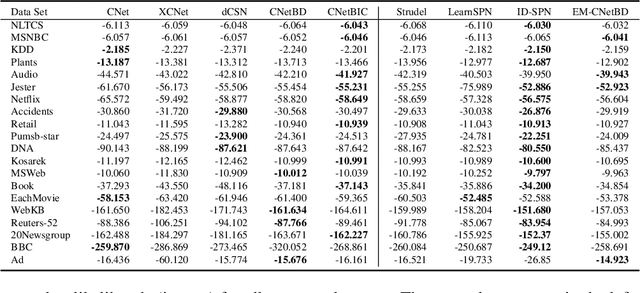
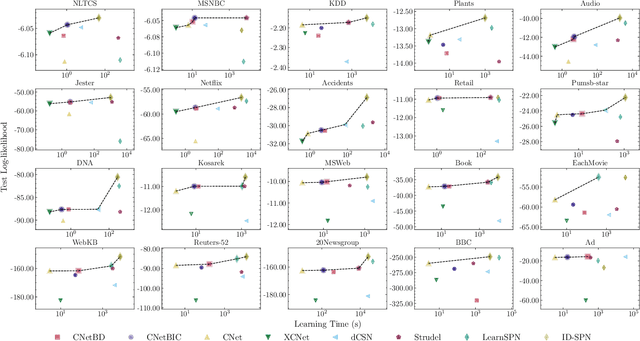
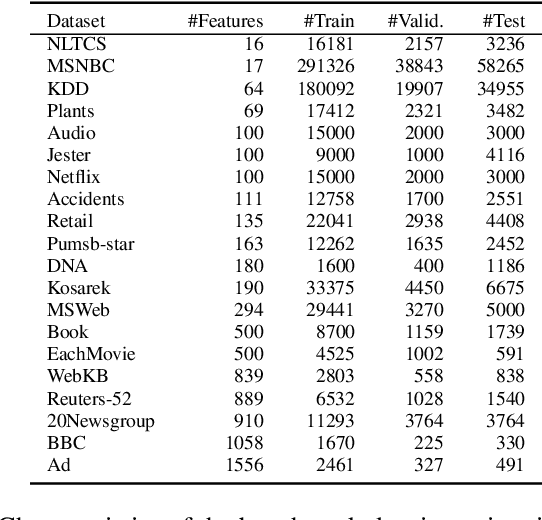
Probabilistic circuits (PCs) are a prominent representation of probability distributions with tractable inference. While parameter learning in PCs is rigorously studied, structure learning is often more based on heuristics than on principled objectives. In this paper, we develop Bayesian structure scores for deterministic PCs, i.e., the structure likelihood with parameters marginalized out, which are well known as rigorous objectives for structure learning in probabilistic graphical models. When used within a greedy cutset algorithm, our scores effectively protect against overfitting and yield a fast and almost hyper-parameter-free structure learner, distinguishing it from previous approaches. In experiments, we achieve good trade-offs between training time and model fit in terms of log-likelihood. Moreover, the principled nature of Bayesian scores unlocks PCs for accommodating frameworks such as structural expectation-maximization.
Violation-Aware Contextual Bayesian Optimization for Controller Performance Optimization with Unmodeled Constraints
Jan 28, 2023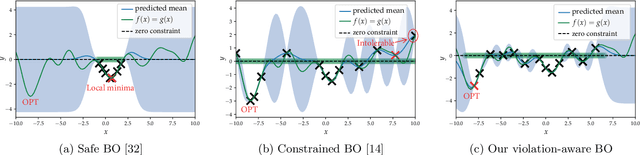
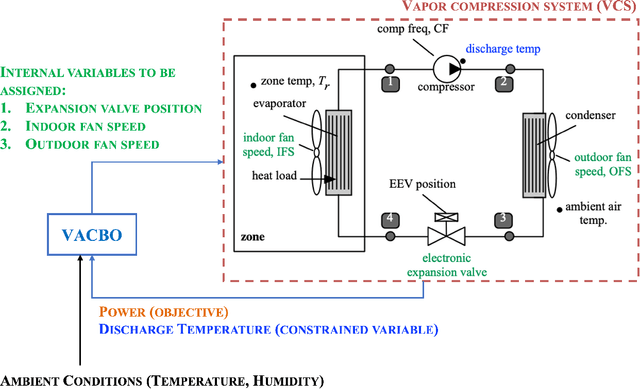
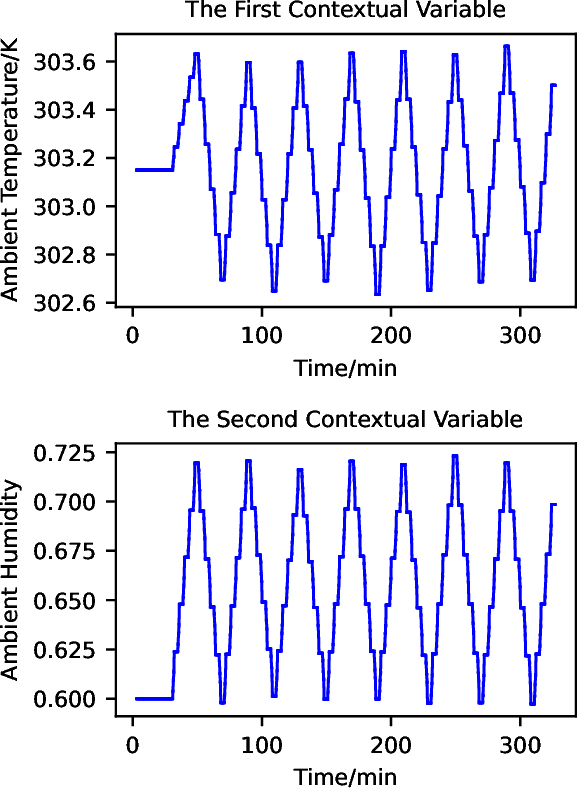
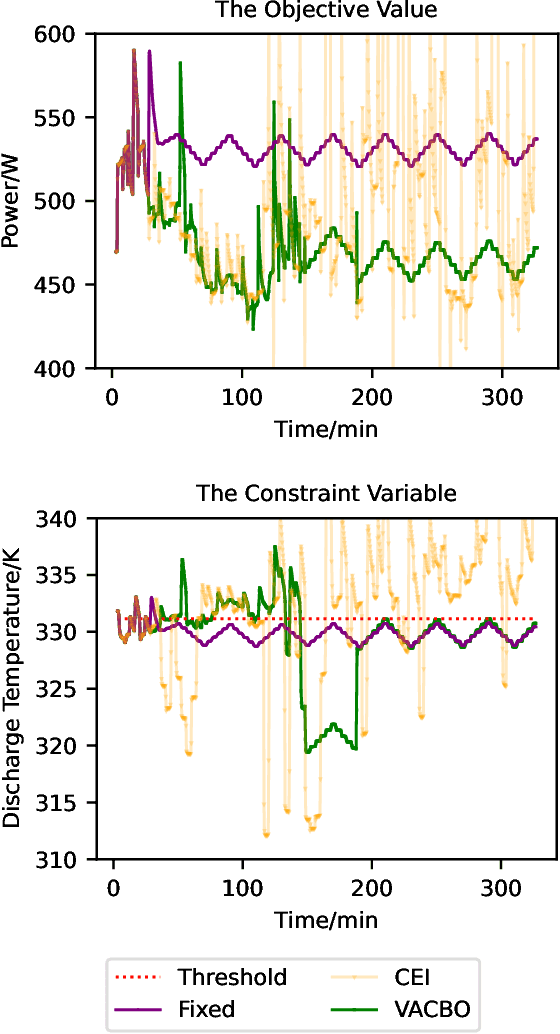
We study the problem of performance optimization of closed-loop control systems with unmodeled dynamics. Bayesian optimization (BO) has been demonstrated to be effective for improving closed-loop performance by automatically tuning controller gains or reference setpoints in a model-free manner. However, BO methods have rarely been tested on dynamical systems with unmodeled constraints and time-varying ambient conditions. In this paper, we propose a violation-aware contextual BO algorithm (VACBO) that optimizes closed-loop performance while simultaneously learning constraint-feasible solutions under time-varying ambient conditions. Unlike classical constrained BO methods which allow unlimited constraint violations, or 'safe' BO algorithms that are conservative and try to operate with near-zero violations, we allow budgeted constraint violations to improve constraint learning and accelerate optimization. We demonstrate the effectiveness of our proposed VACBO method for energy minimization of industrial vapor compression systems under time-varying ambient temperature and humidity.
Intent-based Deep Reinforcement Learning for Multi-agent Informative Path Planning
Mar 09, 2023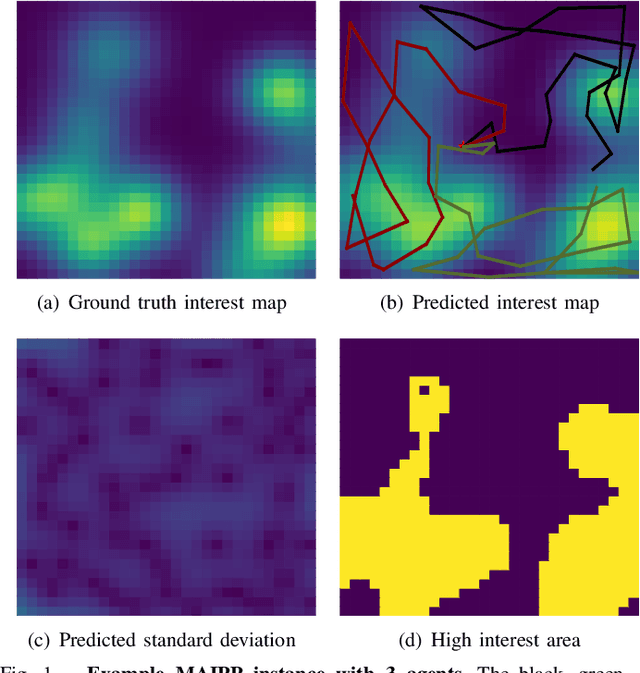
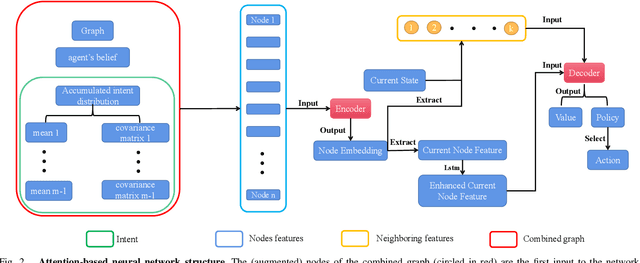
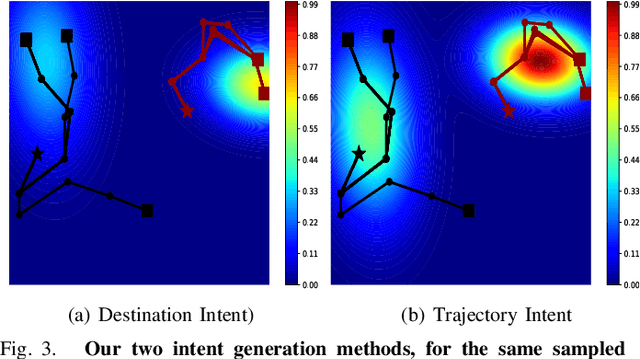
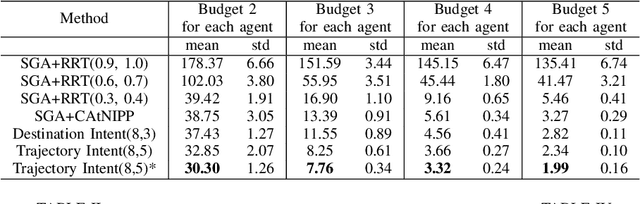
In multi-agent informative path planning (MAIPP), agents must collectively construct a global belief map of an underlying distribution of interest (e.g., gas concentration, light intensity, or pollution levels) over a given domain, based on measurements taken along their trajectory. They must frequently replan their path to balance the distributed exploration of new areas and the collective, meticulous exploitation of known high-interest areas, to maximize the information gained within a predefined budget (e.g., path length or working time). A common approach to achieving such cooperation relies on planning the agents' paths reactively, conditioned on other agents' future actions. However, as the agent's belief is updated continuously, these predicted future actions may not end up being the ones executed by agents, introducing a form of noise/inaccuracy in the system and often decreasing performance. In this work, we propose a decentralized deep reinforcement learning (DRL) approach to MAIPP, which relies on an attention-based neural network, where agents optimize long-term individual and cooperative objectives by explicitly sharing their intent (i.e., medium-/long-term future positions distribution, obtained from their individual policy) in a reactive, asynchronous manner. That is, in our work, intent sharing allows agents to learn to claim/avoid broader areas of the world. Moreover, since our approach relies on learned attention over these shared intents, agents are able to learn to recognize the useful portion(s) of these (imperfect) predictions to maximize cooperation even in the presence of imperfect information. Our comparison experiments demonstrate the performance of our approach compared to its variants and high-quality baselines over a large set of MAIPP simulations.
SEAM: An Integrated Activation-Coupled Model of Sentence Processing and Eye Movements in Reading
Mar 09, 2023
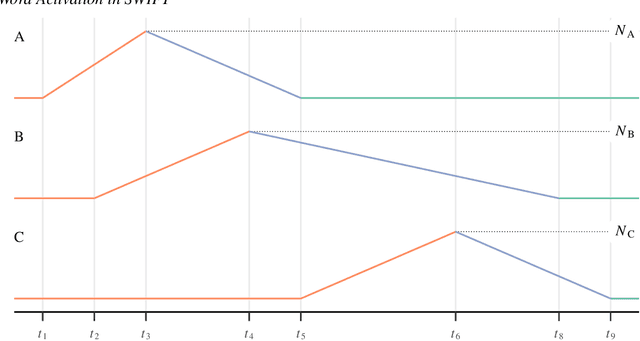
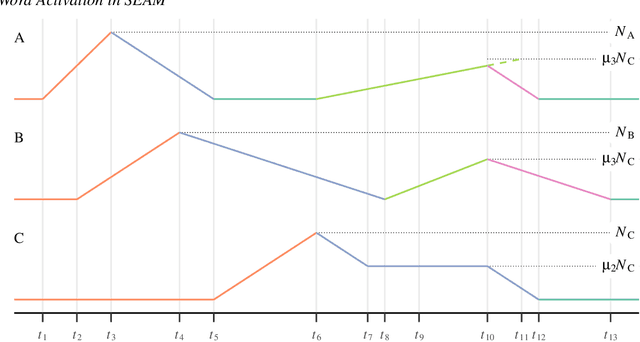

Models of eye-movement control during reading, developed largely within psychology, usually focus on visual, attentional, and motor processes but neglect post-lexical language processing; by contrast, models of sentence comprehension processes, developed largely within psycholinguistics, generally focus only on post-lexical language processes. We present a model that combines these two research threads, by integrating eye-movement control and sentence processing. Developing such an integrated model is extremely challenging and computationally demanding, but such an integration is an important step toward complete mathematical models of natural language comprehension in reading. We combine the SWIFT model of eye-movement control (Engbert et al., Psychological Review, 112, 2005, pp. 777-813) with key components of the Lewis and Vasishth sentence processing model (Lewis and Vasishth, Cognitive Science, 29, 2005, pp. 375-419). This integration becomes possible, for the first time, due in part to recent advances in successful parameter identification in dynamical models, which allows us to investigate profile log-likelihoods for individual model parameters. We present a fully implemented proof-of-concept model demonstrating how such an integrated model can be achieved; our approach includes Bayesian model inference with Markov Chain Monte Carlo (MCMC) sampling as a key computational tool. The integrated model, SEAM, can successfully reproduce eye movement patterns that arise due to similarity-based interference in reading. To our knowledge, this is the first-ever integration of a complete process model of eye-movement control with linguistic dependency completion processes in sentence comprehension. In future work, this proof of concept model will need to be evaluated using a comprehensive set of benchmark data.
Towards Generalized Robot Assembly through Compliance-Enabled Contact Formations
Mar 09, 2023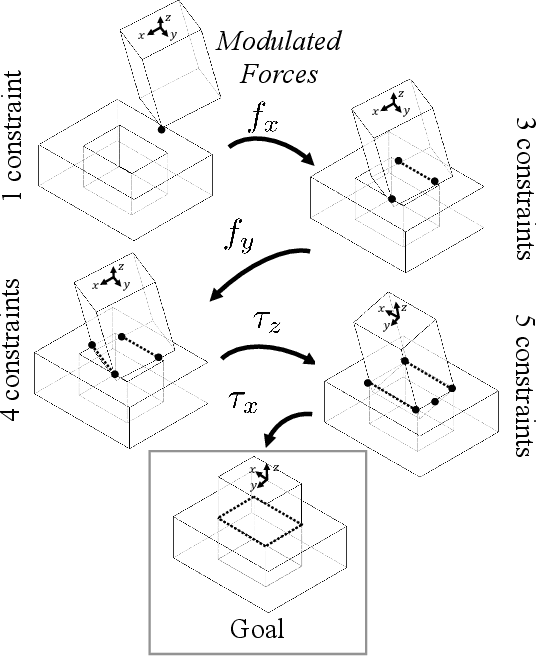
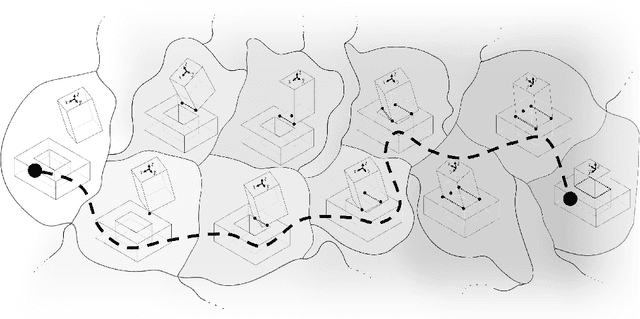
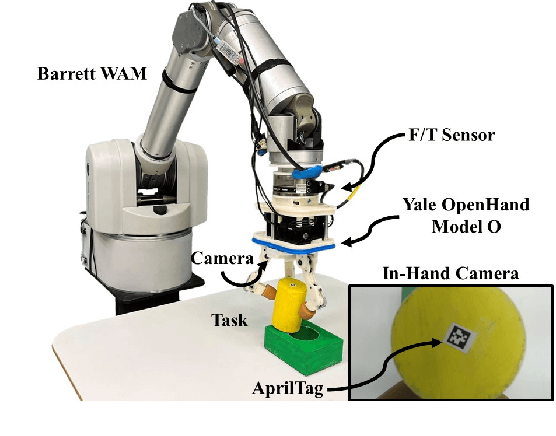
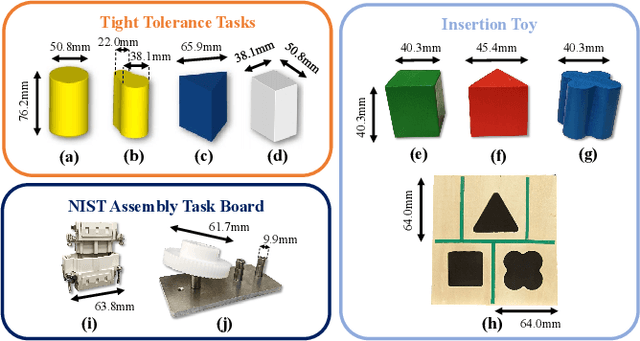
Contact can be conceptualized as a set of constraints imposed on two bodies that are interacting with one another in some way. The nature of a contact, whether a point, line, or surface, dictates how these bodies are able to move with respect to one another given a force, and a set of contacts can provide either partial or full constraint on a body's motion. Decades of work have explored how to explicitly estimate the location of a contact and its dynamics, e.g., frictional properties, but investigated methods have been computationally expensive and there often exists significant uncertainty in the final calculation. This has affected further advancements in contact-rich tasks that are seemingly simple to humans, such as generalized peg-in-hole insertions. In this work, instead of explicitly estimating the individual contact dynamics between an object and its hole, we approach this problem by investigating compliance-enabled contact formations. More formally, contact formations are defined according to the constraints imposed on an object's available degrees-of-freedom. Rather than estimating individual contact positions, we abstract out this calculation to an implicit representation, allowing the robot to either acquire, maintain, or release constraints on the object during the insertion process, by monitoring forces enacted on the end effector through time. Using a compliant robot, our method is desirable in that we are able to complete industry-relevant insertion tasks of tolerances <0.25mm without prior knowledge of the exact hole location or its orientation. We showcase our method on more generalized insertion tasks, such as commercially available non-cylindrical objects and open world plug tasks.
Classification in Histopathology: A unique deep embeddings extractor for multiple classification tasks
Mar 09, 2023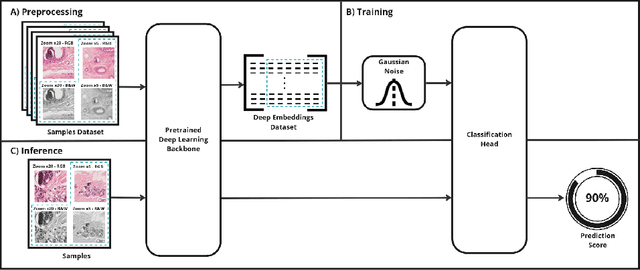
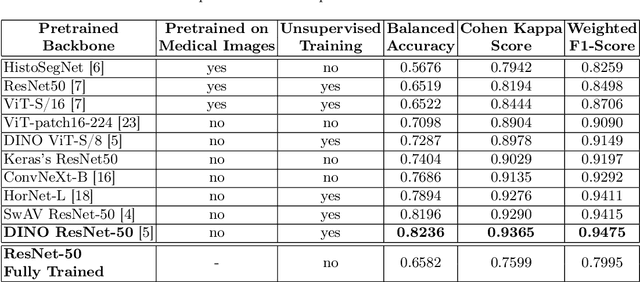
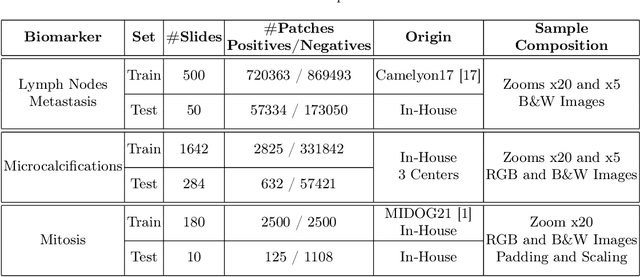

In biomedical imaging, deep learning-based methods are state-of-the-art for every modality (virtual slides, MRI, etc.) In histopathology, these methods can be used to detect certain biomarkers or classify lesions. However, such techniques require large amounts of data to train high-performing models which can be intrinsically difficult to acquire, especially when it comes to scarce biomarkers. To address this challenge, we use a single, pre-trained, deep embeddings extractor to convert images into deep features and train small, dedicated classification head on these embeddings for each classification task. This approach offers several benefits such as the ability to reuse a single pre-trained deep network for various tasks; reducing the amount of labeled data needed as classification heads have fewer parameters; and accelerating training time by up to 1000 times, which allows for much more tuning of the classification head. In this work, we perform an extensive comparison of various open-source backbones and assess their fit to the target histological image domain. This is achieved using a novel method based on a proxy classification task. We demonstrate that thanks to this selection method, an optimal feature extractor can be selected for different tasks on the target domain. We also introduce a feature space augmentation strategy which proves to substantially improve the final metrics computed for the different tasks considered. To demonstrate the benefit of such backbone selection and feature-space augmentation, our experiments are carried out on three separate classification tasks and show a clear improvement on each of them: microcalcifications (29.1% F1-score increase), lymph nodes metastasis (12.5% F1-score increase), mitosis (15.0% F1-score increase).