 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time-aware topic identification in social media with pre-trained language models: A case study of electric vehicles
Oct 11, 2022
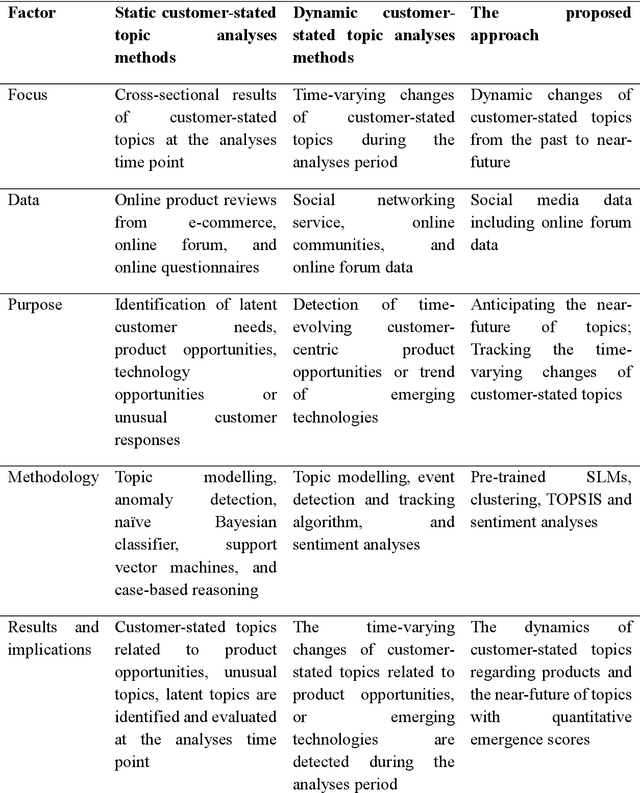
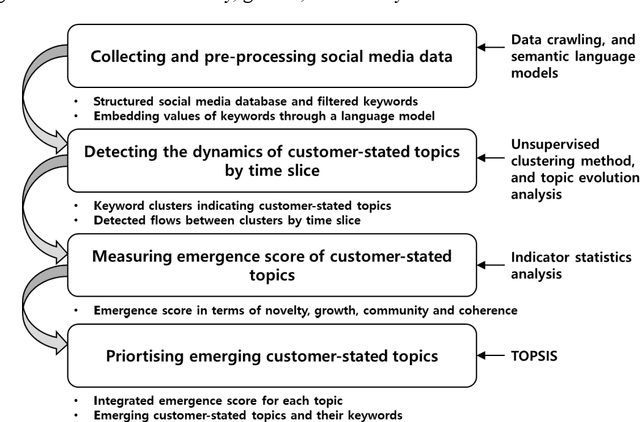
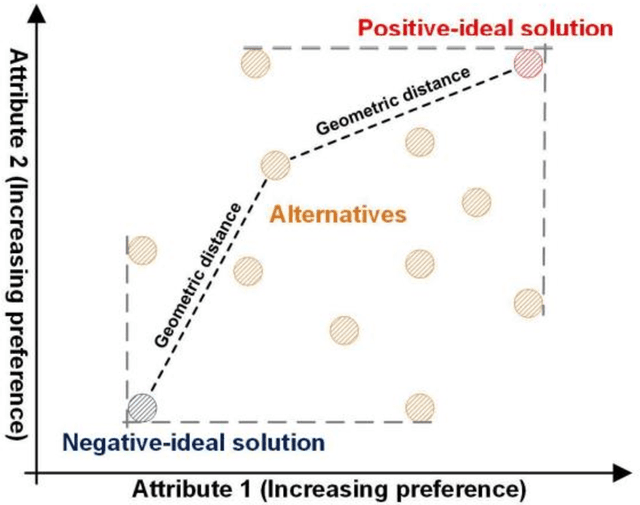
Recent extensively competitive business environment makes companies to keep their eyes on social media, as there is a growing recognition over customer languages (e.g., needs, interests, and complaints) as source of future opportunities. This research avenue analysing social media data has received much attention in academia, but their utilities are limited as most of methods provide retrospective results. Moreover, the increasing number of customer-generated contents and rapidly varying topics have made the necessity of time-aware topic evolution analyses. Recently, several researchers have showed the applicability of pre-trained semantic language models to social media as an input feature, but leaving limitations in understanding evolving topics. In this study, we propose a time-aware topic identification approach with pre-trained language models. The proposed approach consists of two stages: the dynamics-focused function for tracking time-varying topics with language models and the emergence-scoring function to examine future promising topics. Here we apply the proposed approach to reddit data on electric vehicles, and our findings highlight the feasibility of capturing emerging customer topics from voluminous social media in a time-aware manner.
Energy Efficient Computation Offloading in Aerial Edge Networks With Multi-Agent Cooperation
Feb 14, 2023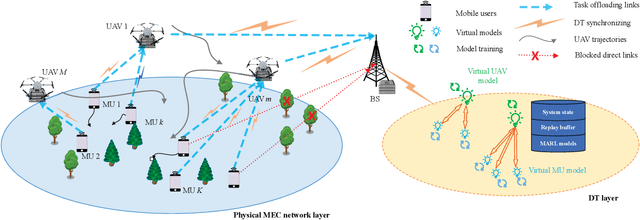
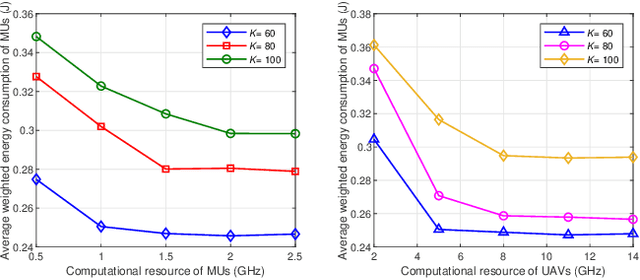
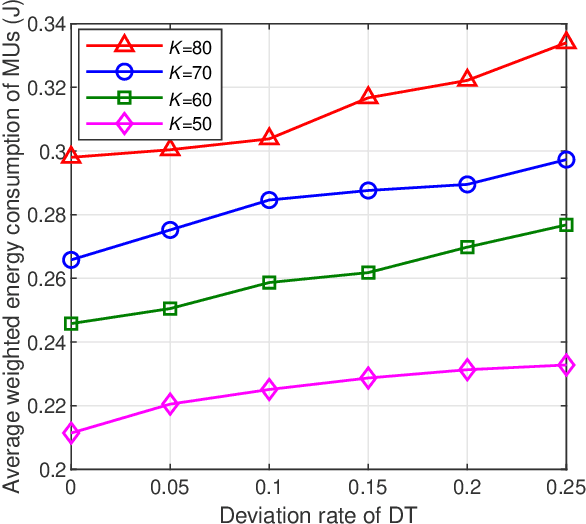
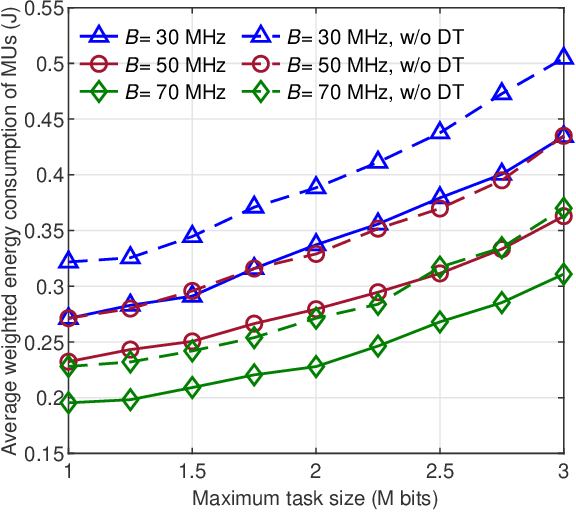
With the high flexibility of supporting resource-intensive and time-sensitive applications, unmanned aerial vehicle (UAV)-assisted mobile edge computing (MEC) is proposed as an innovational paradigm to support the mobile users (MUs). As a promising technology, digital twin (DT) is capable of timely mapping the physical entities to virtual models, and reflecting the MEC network state in real-time. In this paper, we first propose an MEC network with multiple movable UAVs and one DT-empowered ground base station to enhance the MEC service for MUs. Considering the limited energy resource of both MUs and UAVs, we formulate an online problem of resource scheduling to minimize the weighted energy consumption of them. To tackle the difficulty of the combinational problem, we formulate it as a Markov decision process (MDP) with multiple types of agents. Since the proposed MDP has huge state space and action space, we propose a deep reinforcement learning approach based on multi-agent proximal policy optimization (MAPPO) with Beta distribution and attention mechanism to pursue the optimal computation offloading policy. Numerical results show that our proposed scheme is able to efficiently reduce the energy consumption and outperforms the benchmarks in performance, convergence speed and utilization of resources.
Non-stationary Contextual Bandits and Universal Learning
Feb 14, 2023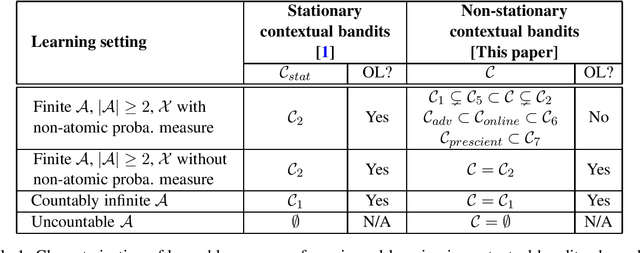
We study the fundamental limits of learning in contextual bandits, where a learner's rewards depend on their actions and a known context, which extends the canonical multi-armed bandit to the case where side-information is available. We are interested in universally consistent algorithms, which achieve sublinear regret compared to any measurable fixed policy, without any function class restriction. For stationary contextual bandits, when the underlying reward mechanism is time-invariant, [Blanchard et al.] characterized learnable context processes for which universal consistency is achievable; and further gave algorithms ensuring universal consistency whenever this is achievable, a property known as optimistic universal consistency. It is well understood, however, that reward mechanisms can evolve over time, possibly depending on the learner's actions. We show that optimistic universal learning for non-stationary contextual bandits is impossible in general, contrary to all previously studied settings in online learning -- including standard supervised learning. We also give necessary and sufficient conditions for universal learning under various non-stationarity models, including online and adversarial reward mechanisms. In particular, the set of learnable processes for non-stationary rewards is still extremely general -- larger than i.i.d., stationary or ergodic -- but in general strictly smaller than that for supervised learning or stationary contextual bandits, shedding light on new non-stationary phenomena.
How Does Data Freshness Affect Real-time Supervised Learning?
Aug 15, 2022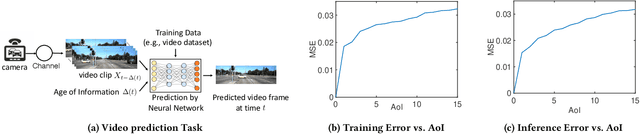
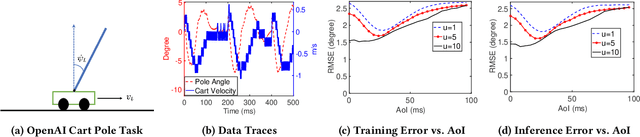
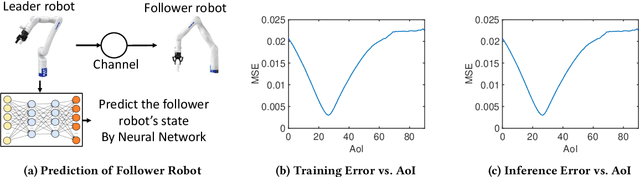
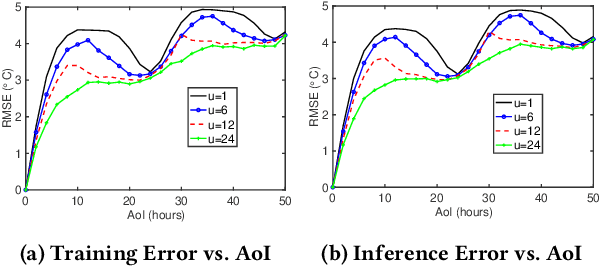
In this paper, we analyze the impact of data freshness on real-time supervised learning, where a neural network is trained to infer a time-varying target (e.g., the position of the vehicle in front) based on features (e.g., video frames) observed at a sensing node (e.g., camera or lidar). One might expect that the performance of real-time supervised learning degrades monotonically as the feature becomes stale. Using an information-theoretic analysis, we show that this is true if the feature and target data sequence can be closely approximated as a Markov chain; it is not true if the data sequence is far from Markovian. Hence, the prediction error of real-time supervised learning is a function of the Age of Information (AoI), where the function could be non-monotonic. Several experiments are conducted to illustrate the monotonic and non-monotonic behaviors of the prediction error. To minimize the inference error in real-time, we propose a new "selection-from-buffer" model for sending the features, which is more general than the "generate-at-will" model used in earlier studies. By using Gittins and Whittle indices, low-complexity scheduling strategies are developed to minimize the inference error, where a new connection between the Gittins index theory and Age of Information (AoI) minimization is discovered. These scheduling results hold (i) for minimizing general AoI functions (monotonic or non-monotonic) and (ii) for general feature transmission time distributions. Data-driven evaluations are presented to illustrate the benefits of the proposed scheduling algorithms.
Weighted First Order Model Counting with Directed Acyclic Graph Axioms
Feb 20, 2023Weighted First Order Model Counting (WFOMC) is the task of computing the weighted sum of the models of a first-order logic sentence. Probabilistic inference problems in many statistical relational learning frameworks can be cast as a WFOMC problem. However, in general, WFOMC is known to be intractable (#P_1- complete). Hence, logical fragments that admit polynomial time WFOMC are of significant interest. Such fragments are called domain liftable. Recent works have identified the two-variable fragment of first-order logic, extended with counting quantifiers, to be domain liftable. In this paper, we extend this fragment with a Directed Acyclic Graph axiom, i.e., a relation is interpreted as a Directed Acyclic Graph.
Toward Asymptotic Optimality: Sequential Unsupervised Regression of Density Ratio for Early Classification
Feb 20, 2023
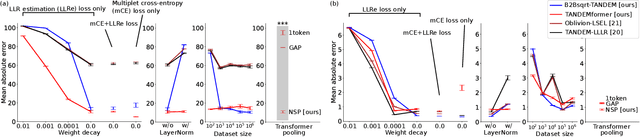
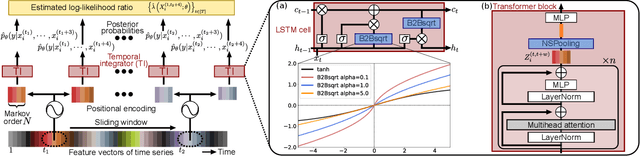
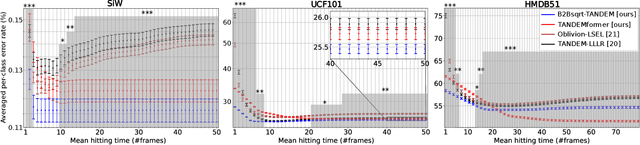
Theoretically-inspired sequential density ratio estimation (SDRE) algorithms are proposed for the early classification of time series. Conventional SDRE algorithms can fail to estimate DRs precisely due to the internal overnormalization problem, which prevents the DR-based sequential algorithm, Sequential Probability Ratio Test (SPRT), from reaching its asymptotic Bayes optimality. Two novel SPRT-based algorithms, B2Bsqrt-TANDEM and TANDEMformer, are designed to avoid the overnormalization problem for precise unsupervised regression of SDRs. The two algorithms statistically significantly reduce DR estimation errors and classification errors on an artificial sequential Gaussian dataset and real datasets (SiW, UCF101, and HMDB51), respectively. The code is available at: https://github.com/Akinori-F-Ebihara/LLR_saturation_problem.
Safe Networked Robotics via Formal Verification
Feb 17, 2023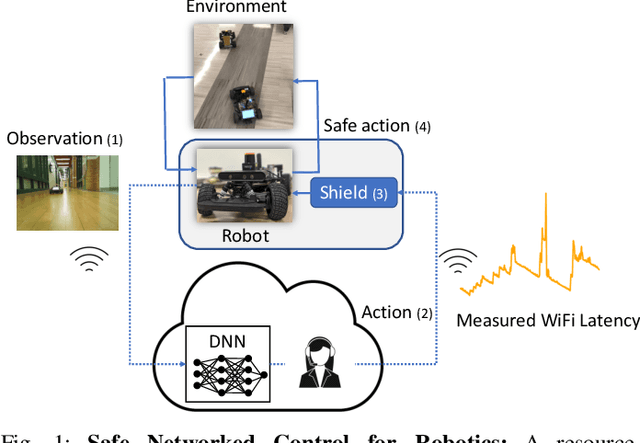
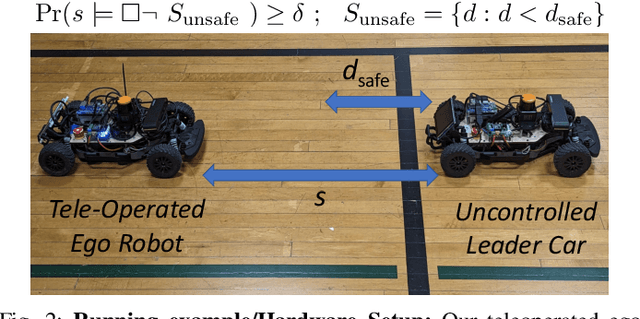
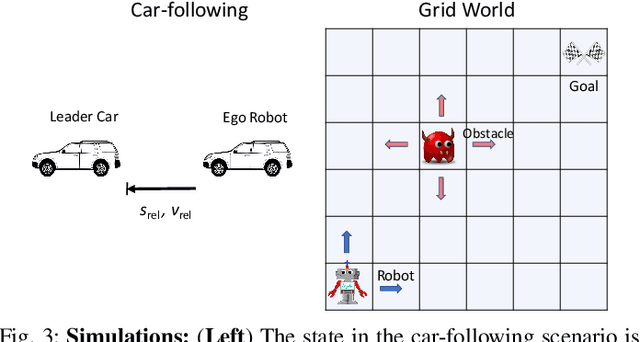
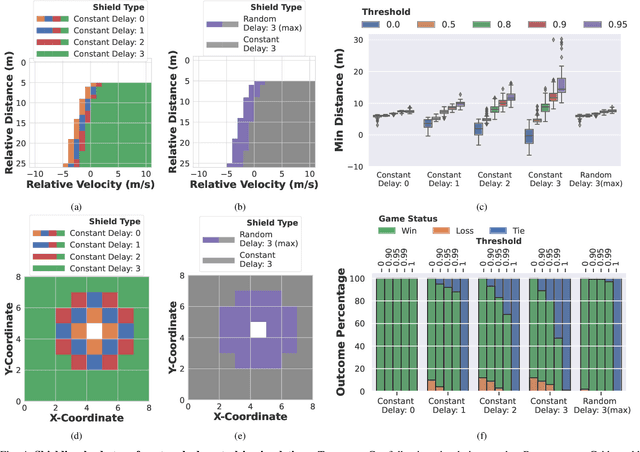
Autonomous robots must utilize rich sensory data to make safe control decisions. Often, compute-constrained robots require assistance from remote computation (''the cloud'') if they need to invoke compute-intensive Deep Neural Network perception or control models. Likewise, a robot can be remotely teleoperated by a human during risky scenarios. However, this assistance comes at the cost of a time delay due to network latency, resulting in stale/delayed observations being used in the cloud to compute the control commands for the present robot state. Such communication delays could potentially lead to the violation of essential safety properties, such as collision avoidance. This paper develops methods to ensure the safety of teleoperated robots with stochastic latency. To do so, we use tools from formal verification to construct a shield (i.e., run-time monitor) that provides a list of safe actions for any delayed sensory observation, given the expected and worst-case network latency. Our shield is minimally intrusive and enables networked robots to satisfy key safety constraints, expressed as temporal logic specifications, with high probability. Our approach gracefully improves a teleoperated robot's safety vs. efficiency trade-off as a function of network latency, allowing us to quantify performance gains for WiFi or even future 5G networks. We demonstrate our approach on a real F1/10th autonomous vehicle that navigates in crowded indoor environments and transmits rich LiDAR sensory data over congested WiFi links.
Rethinking Warm-Starts with Predictions: Learning Predictions Close to Sets of Optimal Solutions for Faster $\text{L}$-/$\text{L}^\natural$-Convex Function Minimization
Feb 02, 2023
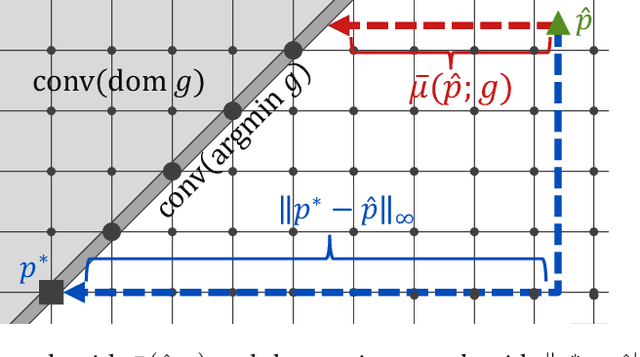
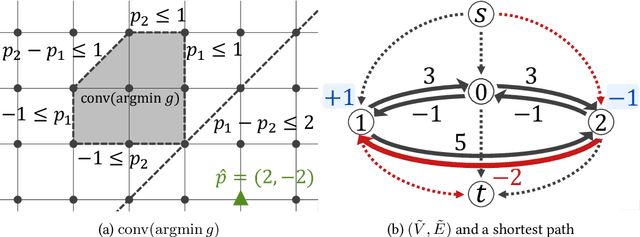
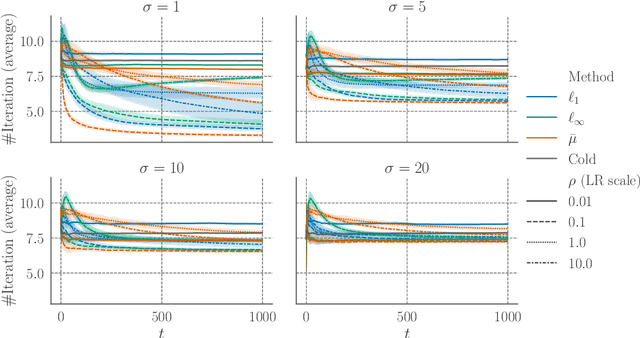
An emerging line of work has shown that machine-learned predictions are useful to warm-start algorithms for discrete optimization problems, such as bipartite matching. Previous studies have shown time complexity bounds proportional to some distance between a prediction and an optimal solution, which we can approximately minimize by learning predictions from past optimal solutions. However, such guarantees may not be meaningful when multiple optimal solutions exist. Indeed, the dual problem of bipartite matching and, more generally, $\text{L}$-/$\text{L}^\natural$-convex function minimization have arbitrarily many optimal solutions, making such prediction-dependent bounds arbitrarily large. To resolve this theoretically critical issue, we present a new warm-start-with-prediction framework for $\text{L}$-/$\text{L}^\natural$-convex function minimization. Our framework offers time complexity bounds proportional to the distance between a prediction and the set of all optimal solutions. The main technical difficulty lies in learning predictions that are provably close to sets of all optimal solutions, for which we present an online-gradient-descent-based method. We thus give the first polynomial-time learnability of predictions that can provably warm-start algorithms regardless of multiple optimal solutions.
Nonlinear Random Matrices and Applications to the Sum of Squares Hierarchy
Feb 09, 2023We develop new tools in the theory of nonlinear random matrices and apply them to study the performance of the Sum of Squares (SoS) hierarchy on average-case problems. The SoS hierarchy is a powerful optimization technique that has achieved tremendous success for various problems in combinatorial optimization, robust statistics and machine learning. It's a family of convex relaxations that lets us smoothly trade off running time for approximation guarantees. In recent works, it's been shown to be extremely useful for recovering structure in high dimensional noisy data. It also remains our best approach towards refuting the notorious Unique Games Conjecture. In this work, we analyze the performance of the SoS hierarchy on fundamental problems stemming from statistics, theoretical computer science and statistical physics. In particular, we show subexponential-time SoS lower bounds for the problems of the Sherrington-Kirkpatrick Hamiltonian, Planted Slightly Denser Subgraph, Tensor Principal Components Analysis and Sparse Principal Components Analysis. These SoS lower bounds involve analyzing large random matrices, wherein lie our main contributions. These results offer strong evidence for the truth of and insight into the low-degree likelihood ratio hypothesis, an important conjecture that predicts the power of bounded-time algorithms for hypothesis testing. We also develop general-purpose tools for analyzing the behavior of random matrices which are functions of independent random variables. Towards this, we build on and generalize the matrix variant of the Efron-Stein inequalities. In particular, our general theorem on matrix concentration recovers various results that have appeared in the literature. We expect these random matrix theory ideas to have other significant applications.
A Meta-Evaluation of Faithfulness Metrics for Long-Form Hospital-Course Summarization
Mar 07, 2023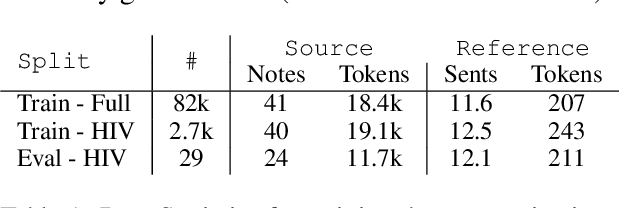
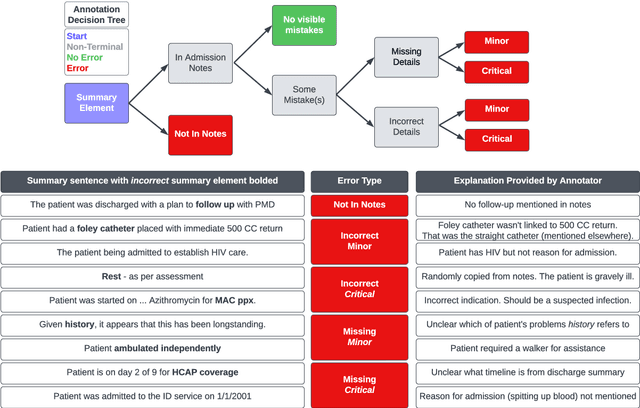
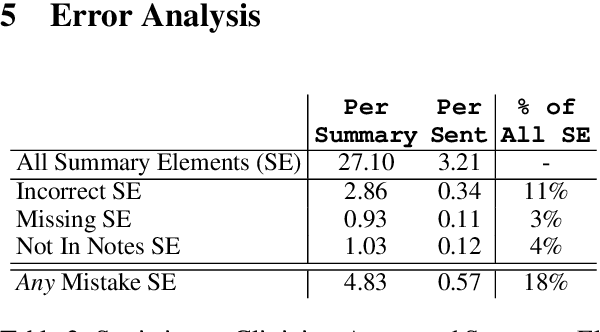
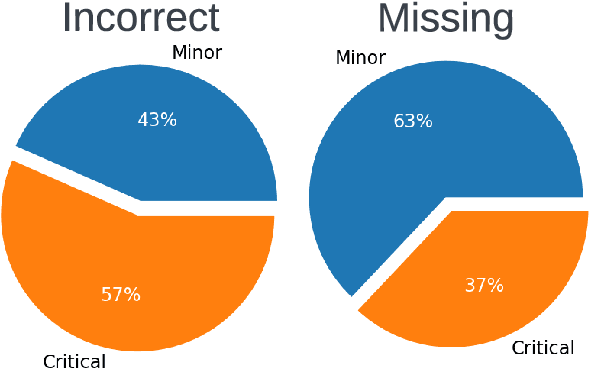
Long-form clinical summarization of hospital admissions has real-world significance because of its potential to help both clinicians and patients. The faithfulness of summaries is critical to their safe usage in clinical settings. To better understand the limitations of abstractive systems, as well as the suitability of existing evaluation metrics, we benchmark faithfulness metrics against fine-grained human annotations for model-generated summaries of a patient's Brief Hospital Course. We create a corpus of patient hospital admissions and summaries for a cohort of HIV patients, each with complex medical histories. Annotators are presented with summaries and source notes, and asked to categorize manually highlighted summary elements (clinical entities like conditions and medications as well as actions like "following up") into one of three categories: ``Incorrect,'' ``Missing,'' and ``Not in Notes.'' We meta-evaluate a broad set of proposed faithfulness metrics and, across metrics, explore the importance of domain adaptation (e.g. the impact of in-domain pre-training and metric fine-tuning), the use of source-summary alignments, and the effects of distilling a single metric from an ensemble of pre-existing metrics. Off-the-shelf metrics with no exposure to clinical text correlate well yet overly rely on summary extractiveness. As a practical guide to long-form clinical narrative summarization, we find that most metrics correlate best to human judgments when provided with one summary sentence at a time and a minimal set of relevant source context.