 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Computational Spectral Imaging: A Contemporary Overview
Mar 08, 2023
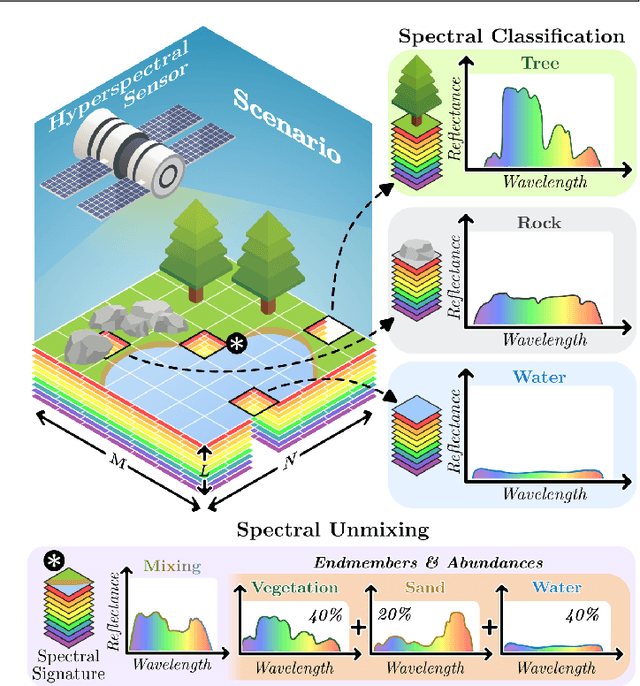
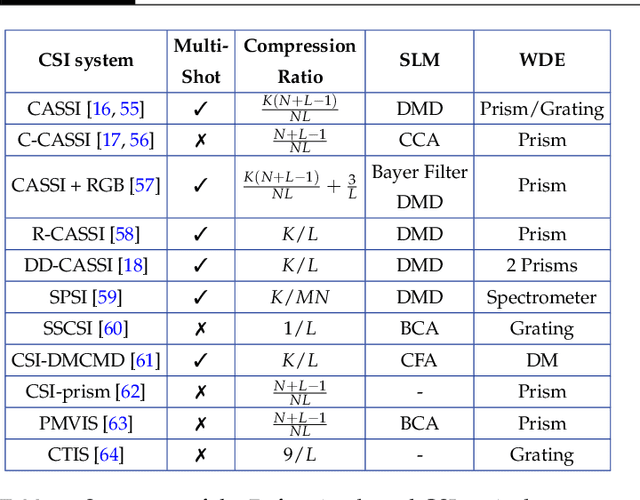
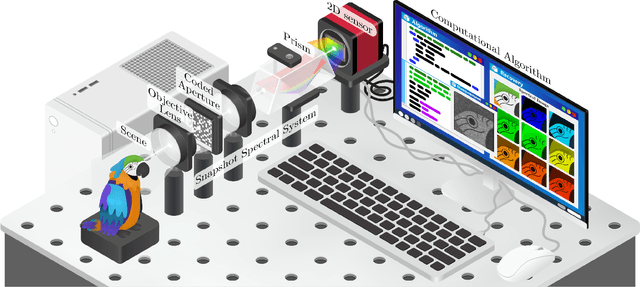
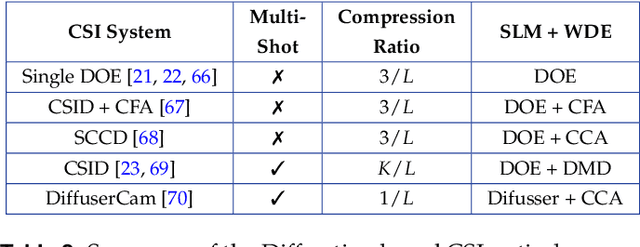
Spectral imaging collects and processes information along spatial and spectral coordinates quantified in discrete voxels, which can be treated as a 3D spectral data cube. The spectral images (SIs) allow identifying objects, crops, and materials in the scene through their spectral behavior. Since most spectral optical systems can only employ 1D or maximum 2D sensors, it is challenging to directly acquire the 3D information from available commercial sensors. As an alternative, computational spectral imaging (CSI) has emerged as a sensing tool where the 3D data can be obtained using 2D encoded projections. Then, a computational recovery process must be employed to retrieve the SI. CSI enables the development of snapshot optical systems that reduce acquisition time and provide low computational storage costs compared to conventional scanning systems. Recent advances in deep learning (DL) have allowed the design of data-driven CSI to improve the SI reconstruction or, even more, perform high-level tasks such as classification, unmixing, or anomaly detection directly from 2D encoded projections. This work summarises the advances in CSI, starting with SI and its relevance; continuing with the most relevant compressive spectral optical systems. Then, CSI with DL will be introduced, and the recent advances in combining the physical optical design with computational DL algorithms to solve high-level tasks.
Estimation of the qualification and behavior of a contributor and aggregation of his answers in a crowdsourcing context
Mar 08, 2023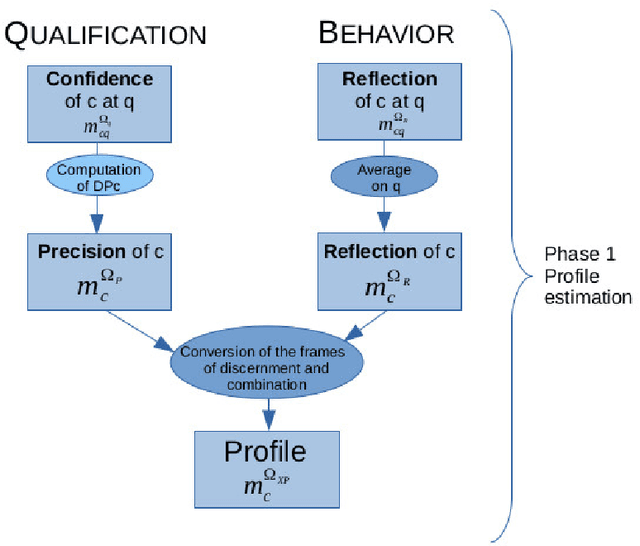
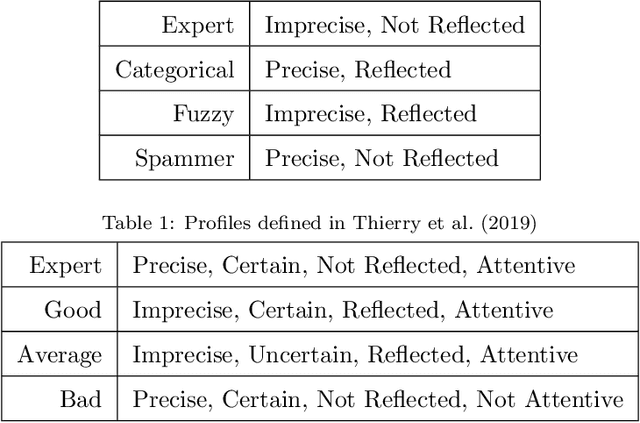
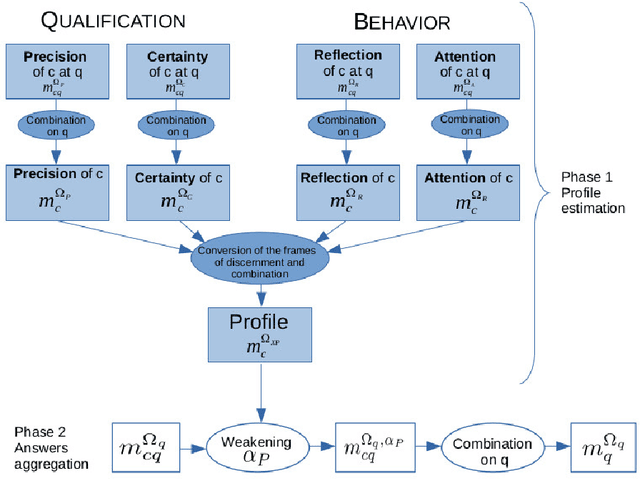
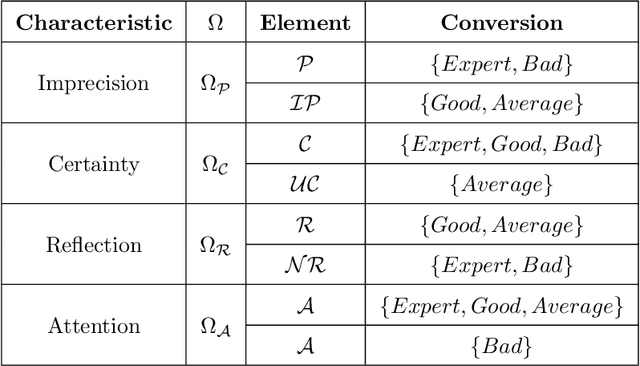
Crowdsourcing is the outsourcing of tasks to a crowd of contributors on a dedicated platform. The crowd on these platforms is very diversified and includes various profiles of contributors which generates data of uneven quality. However, majority voting, which is the aggregating method commonly used in platforms, gives equal weight to each contribution. To overcome this problem, we propose a method, MONITOR, which estimates the contributor's profile and aggregates the collected data by taking into account their possible imperfections thanks to the theory of belief functions. To do so, MONITOR starts by estimating the profile of the contributor through his qualification for the task and his behavior.Crowdsourcing campaigns have been carried out to collect the necessary data to test MONITOR on real data in order to compare it to existing approaches. The results of the experiments show that thanks to the use of the MONITOR method, we obtain a better rate of correct answer after aggregation of the contributions compared to the majority voting. Our contributions in this article are for the first time the proposal of a model that takes into account both the qualification of the contributor and his behavior in the estimation of his profile. For the second one, the weakening and the aggregation of the answers according to the estimated profiles.
Ship trajectory planning method for reproducing human operation at ports
Mar 08, 2023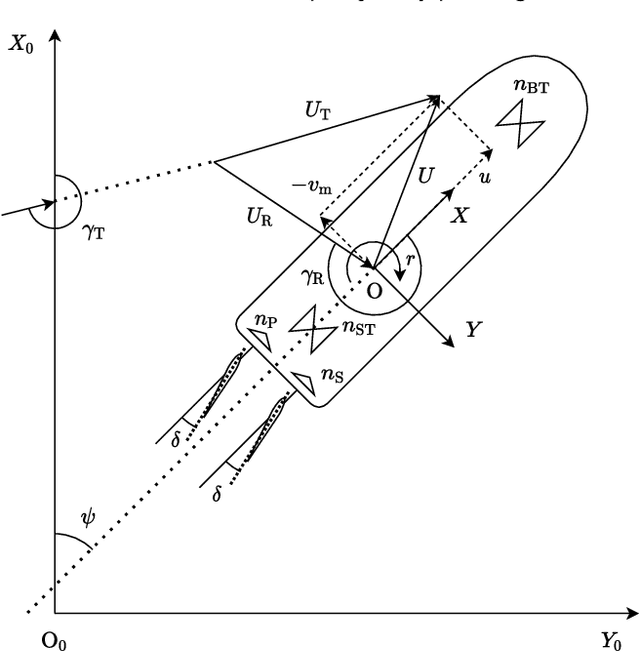


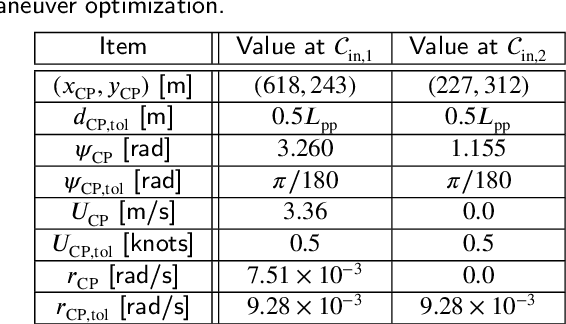
Among ship maneuvers, berthing/unberthing maneuvers are one of the most challenging and stressful phases for captains. Concerning burden reduction on ship operators and preventing accidents, several researches have been conducted on trajectory planning to automate berthing/unberthing. However, few studies have aimed at assisting captains in berthing/unberthing. The trajectory to be presented to the captain should be a maneuver that reproduces human captain's control characteristics. The previously proposed methods cannot explicitly reflect the motion and navigation, which human captains pay particular attention to reduce the mental burden in the trajectory planning. Herein, mild constraints to the trajectory planning method are introduced. The constraints impose certain states (position, bow heading angle, ship speed, and yaw angular velocity), to be taken approximately at any given time. The introduction of this new constraint allows imposing careful trajectory planning (e.g., in-situ turns at zero speed or a pause for safety before going astern), as if performed by a human during berthing/unberthing. The algorithm proposed herein was used to optimize the berthing/unberthing trajectories for a large car ferry. The results show that this method can generate the quantitatively equivalent trajectory recorded in the actual berthing/unberthing maneuver performed by a human captain.
* 16 pages, 12 figures, an accepted manuscript of a published paper on Ocean Engineering
Robust Multimodal Fusion for Human Activity Recognition
Mar 08, 2023


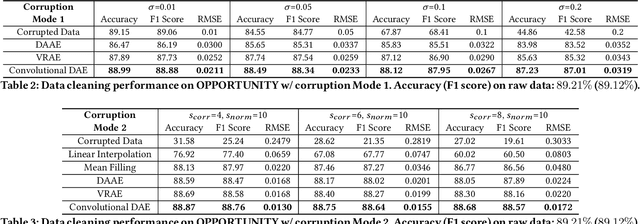
The proliferation of IoT and mobile devices equipped with heterogeneous sensors has enabled new applications that rely on the fusion of time-series data generated by multiple sensors with different modalities. While there are promising deep neural network architectures for multimodal fusion, their performance falls apart quickly in the presence of consecutive missing data and noise across multiple modalities/sensors, the issues that are prevalent in real-world settings. We propose Centaur, a multimodal fusion model for human activity recognition (HAR) that is robust to these data quality issues. Centaur combines a data cleaning module, which is a denoising autoencoder with convolutional layers, and a multimodal fusion module, which is a deep convolutional neural network with the self-attention mechanism to capture cross-sensor correlation. We train Centaur using a stochastic data corruption scheme and evaluate it on three datasets that contain data generated by multiple inertial measurement units. Centaur's data cleaning module outperforms 2 state-of-the-art autoencoder-based models and its multimodal fusion module outperforms 4 strong baselines. Compared to 2 related robust fusion architectures, Centaur is more robust, achieving 11.59-17.52% higher accuracy in HAR, especially in the presence of consecutive missing data in multiple sensor channels.
VOLTA: an Environment-Aware Contrastive Cell Representation Learning for Histopathology
Mar 08, 2023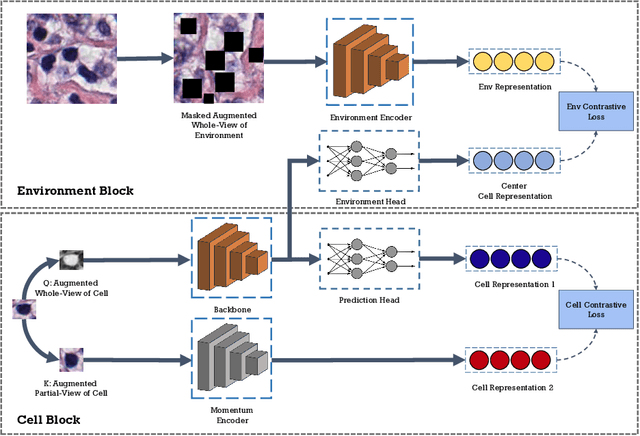
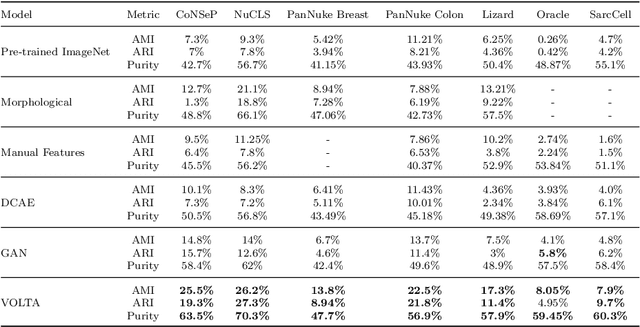

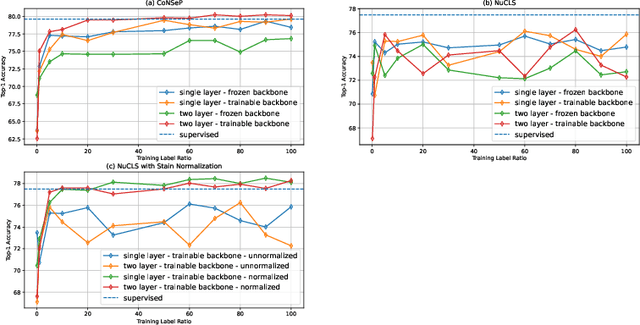
In clinical practice, many diagnosis tasks rely on the identification of cells in histopathology images. While supervised machine learning techniques require labels, providing manual cell annotations is time-consuming due to the large number of cells. In this paper, we propose a self-supervised framework (VOLTA) for cell representation learning in histopathology images using a novel technique that accounts for the cell's mutual relationship with its environment for improved cell representations. We subjected our model to extensive experiments on the data collected from multiple institutions around the world comprising of over 700,000 cells, four cancer types, and cell types ranging from three to six categories for each dataset. The results show that our model outperforms the state-of-the-art models in cell representation learning. To showcase the potential power of our proposed framework, we applied VOLTA to ovarian and endometrial cancers with very small sample sizes (10-20 samples) and demonstrated that our cell representations can be utilized to identify the known histotypes of ovarian cancer and provide novel insights that link histopathology and molecular subtypes of endometrial cancer. Unlike supervised deep learning models that require large sample sizes for training, we provide a framework that can empower new discoveries without any annotation data in situations where sample sizes are limited.
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Mar 08, 2023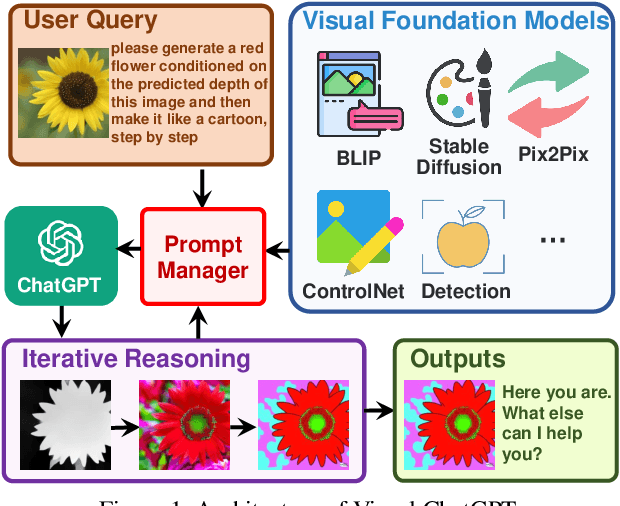
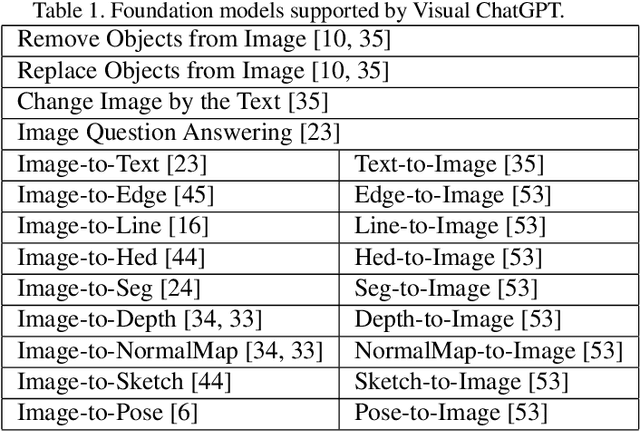
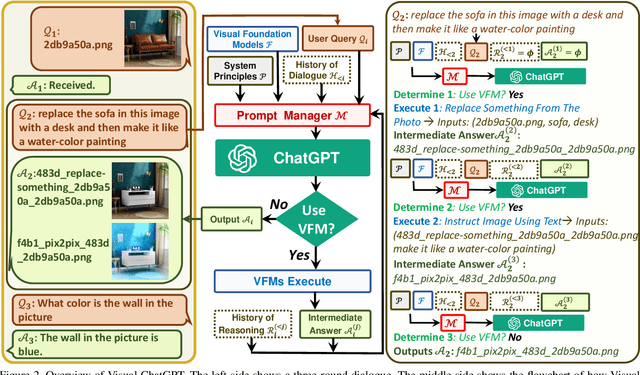
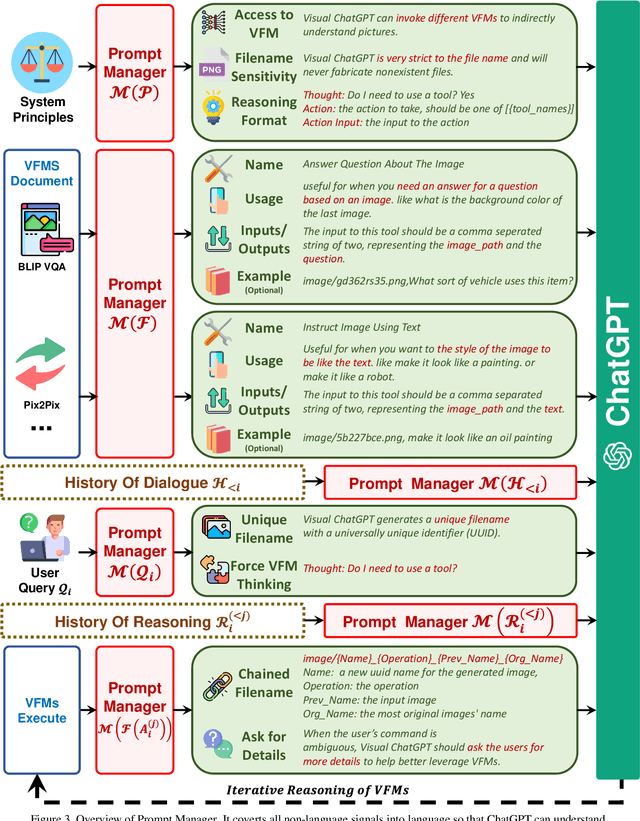
ChatGPT is attracting a cross-field interest as it provides a language interface with remarkable conversational competency and reasoning capabilities across many domains. However, since ChatGPT is trained with languages, it is currently not capable of processing or generating images from the visual world. At the same time, Visual Foundation Models, such as Visual Transformers or Stable Diffusion, although showing great visual understanding and generation capabilities, they are only experts on specific tasks with one-round fixed inputs and outputs. To this end, We build a system called \textbf{Visual ChatGPT}, incorporating different Visual Foundation Models, to enable the user to interact with ChatGPT by 1) sending and receiving not only languages but also images 2) providing complex visual questions or visual editing instructions that require the collaboration of multiple AI models with multi-steps. 3) providing feedback and asking for corrected results. We design a series of prompts to inject the visual model information into ChatGPT, considering models of multiple inputs/outputs and models that require visual feedback. Experiments show that Visual ChatGPT opens the door to investigating the visual roles of ChatGPT with the help of Visual Foundation Models. Our system is publicly available at \url{https://github.com/microsoft/visual-chatgpt}.
Controlling mean exit time of stochastic dynamical systems based on quasipotential and machine learning
Sep 27, 2022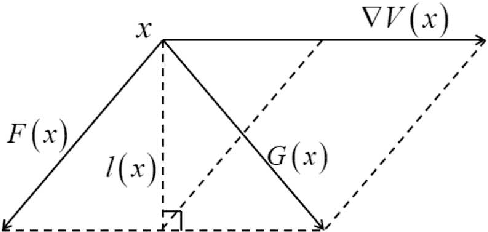
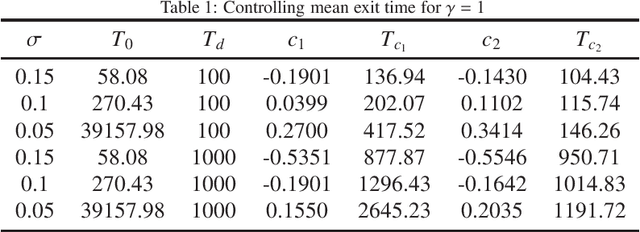
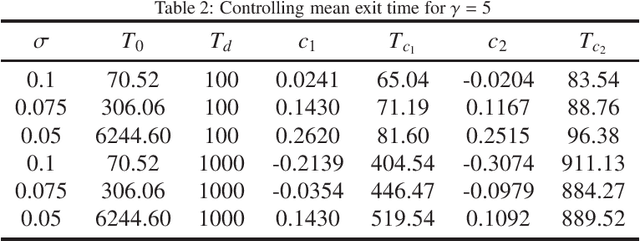
The mean exit time escaping basin of attraction in the presence of white noise is of practical importance in various scientific fields. In this work, we propose a strategy to control mean exit time of general stochastic dynamical systems to achieve a desired value based on the quasipotential concept and machine learning. Specifically, we develop a neural network architecture to compute the global quasipotential function. Then we design a systematic iterated numerical algorithm to calculate the controller for a given mean exit time. Moreover, we identify the most probable path between metastable attractors with help of the effective Hamilton-Jacobi scheme and the trained neural network. Numerical experiments demonstrate that our control strategy is effective and sufficiently accurate.
Interruptions detection in video conferences
Feb 25, 2023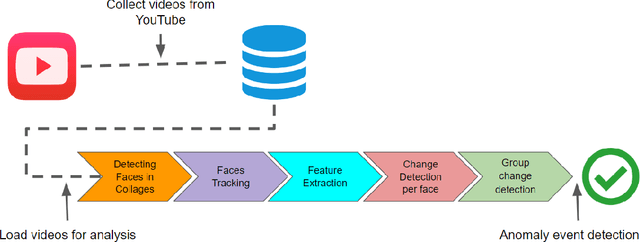
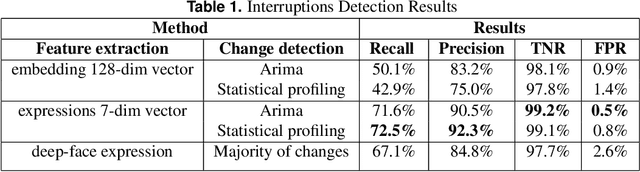
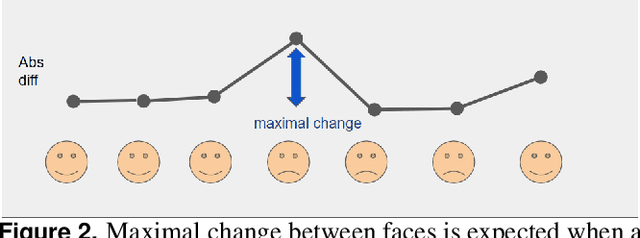
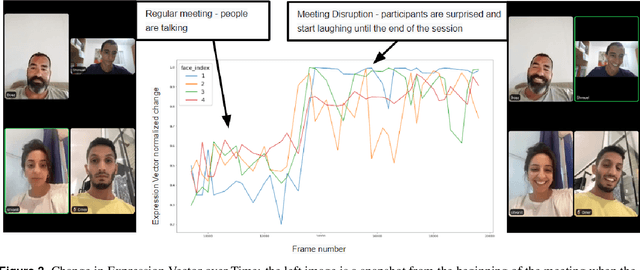
In recent years, video conferencing (VC) popularity has skyrocketed for a wide range of activities. As a result, the number of VC users surged sharply. The sharp increase in VC usage has been accompanied by various newly emerging privacy and security challenges. VC meetings became a target for various security attacks, such as Zoombombing. Other VC-related challenges also emerged. For example, during COVID lockdowns, educators had to teach in online environments struggling with keeping students engaged for extended periods. In parallel, the amount of available VC videos has grown exponentially. Thus, users and companies are limited in finding abnormal segments in VC meetings within the converging volumes of data. Such abnormal events that affect most meeting participants may be indicators of interesting points in time, including security attacks or other changes in meeting climate, like someone joining a meeting or sharing a dramatic content. Here, we present a novel algorithm for detecting abnormal events in VC data. We curated VC publicly available recordings, including meetings with interruptions. We analyzed the videos using our algorithm, extracting time windows where abnormal occurrences were detected. Our algorithm is a pipeline that combines multiple methods in several steps to detect users' faces in each video frame, track face locations during the meeting and generate vector representations of a facial expression for each face in each frame. Vector representations are used to monitor changes in facial expressions throughout the meeting for each participant. The overall change in meeting climate is quantified using those parameters across all participants, and translating them into event anomaly detection. This is the first open pipeline for automatically detecting anomaly events in VC meetings. Our model detects abnormal events with 92.3% precision over the collected dataset.
Time-distance vision transformers in lung cancer diagnosis from longitudinal computed tomography
Sep 04, 2022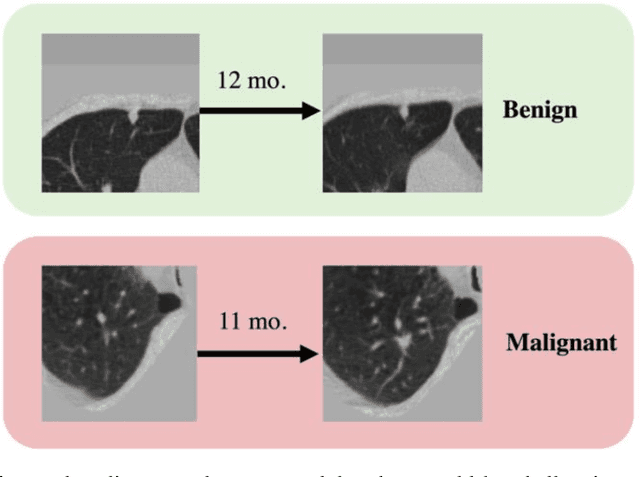

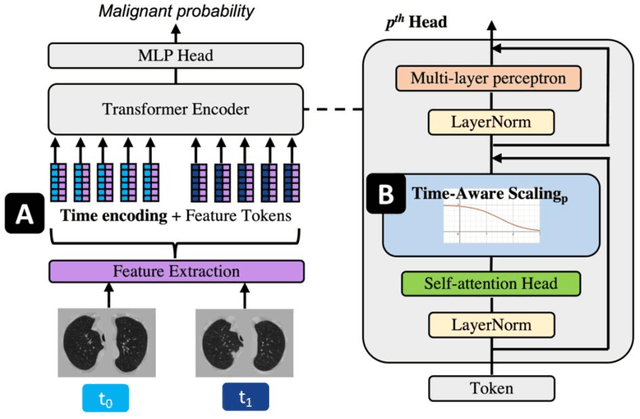

Features learned from single radiologic images are unable to provide information about whether and how much a lesion may be changing over time. Time-dependent features computed from repeated images can capture those changes and help identify malignant lesions by their temporal behavior. However, longitudinal medical imaging presents the unique challenge of sparse, irregular time intervals in data acquisition. While self-attention has been shown to be a versatile and efficient learning mechanism for time series and natural images, its potential for interpreting temporal distance between sparse, irregularly sampled spatial features has not been explored. In this work, we propose two interpretations of a time-distance vision transformer (ViT) by using (1) vector embeddings of continuous time and (2) a temporal emphasis model to scale self-attention weights. The two algorithms are evaluated based on benign versus malignant lung cancer discrimination of synthetic pulmonary nodules and lung screening computed tomography studies from the National Lung Screening Trial (NLST). Experiments evaluating the time-distance ViTs on synthetic nodules show a fundamental improvement in classifying irregularly sampled longitudinal images when compared to standard ViTs. In cross-validation on screening chest CTs from the NLST, our methods (0.785 and 0.786 AUC respectively) significantly outperform a cross-sectional approach (0.734 AUC) and match the discriminative performance of the leading longitudinal medical imaging algorithm (0.779 AUC) on benign versus malignant classification. This work represents the first self-attention-based framework for classifying longitudinal medical images. Our code is available at https://github.com/tom1193/time-distance-transformer.
Increasing the usefulness of already existing annotations through WSI registration
Mar 12, 2023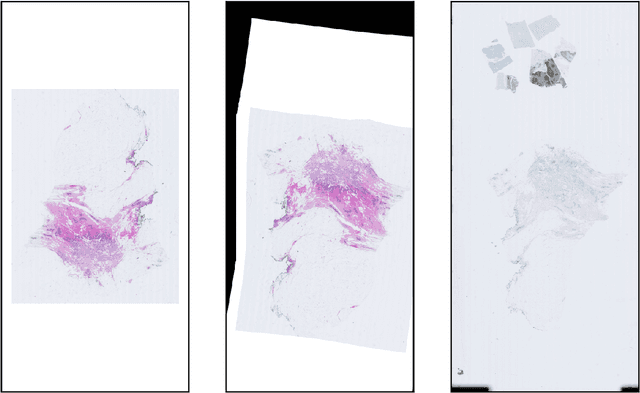
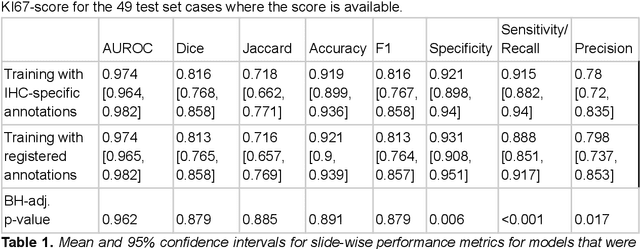

Computational pathology methods have the potential to improve access to precision medicine, as well as the reproducibility and accuracy of pathological diagnoses. Particularly the analysis of whole-slide-images (WSIs) of immunohistochemically (IHC) stained tissue sections could benefit from computational pathology methods. However, scoring biomarkers such as KI67 in IHC WSIs often necessitates the detection of areas of invasive cancer. Training cancer detection models often requires annotations, which is time-consuming and therefore costly. Currently, cancer regions are typically annotated in WSIs of haematoxylin and eosin (H&E) stained tissue sections. In this study, we investigate the possibility to register annotations that were made in H&E WSIs to their IHC counterparts. Two pathologists annotated regions of invasive cancer in WSIs of 272 breast cancer cases. For each case, a matched H&E and KI67 WSI are available, resulting in 544 WSIs with invasive cancer annotations. We find that cancer detection CNNs that were trained with annotations registered from the H&E to the KI67 WSIs only differ slightly in calibration but not in performance compared to cancer detection models trained on annotations made directly in the KI67 WSIs in a test set consisting of 54 cases. The mean slide-level AUROC is 0.974 [0.964, 0.982] for models trained with the KI67 annotations and 0.974 [0.965, 0.982] for models trained using registered annotations. This indicates that WSI registration has the potential to reduce the need for IHC-specific annotations. This could significantly increase the usefulness of already existing annotations.