 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Physics Informed Deep Learning: Applications in Transportation
Feb 23, 2023
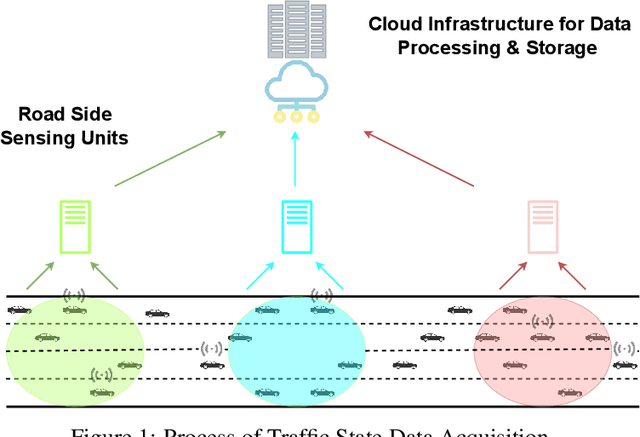

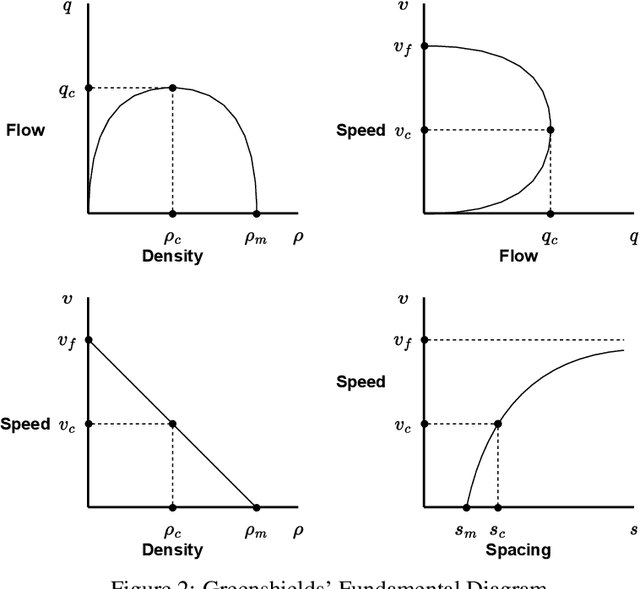
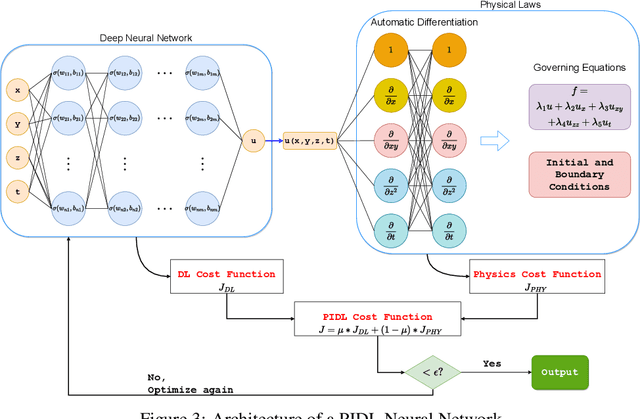
A recent development in machine learning - physics-informed deep learning (PIDL) - presents unique advantages in transportation applications such as traffic state estimation. Consolidating the benefits of deep learning (DL) and the governing physical equations, it shows the potential to complement traditional sensing methods in obtaining traffic states. In this paper, we first explain the conservation law from the traffic flow theory as ``physics'', then present the architecture of a PIDL neural network and demonstrate its effectiveness in learning traffic conditions of unobserved areas. In addition, we also exhibit the data collection scenario using fog computing infrastructure. A case study on estimating the vehicle velocity is presented and the result shows that PIDL surpasses the performance of a regular DL neural network with the same learning architecture, in terms of convergence time and reconstruction accuracy. The encouraging results showcase the broad potential of PIDL for real-time applications in transportation with a low amount of training data.
MVMTnet: A Multi-variate Multi-modal Transformer for Multi-class Classification of Cardiac Irregularities Using ECG Waveforms and Clinical Notes
Feb 21, 2023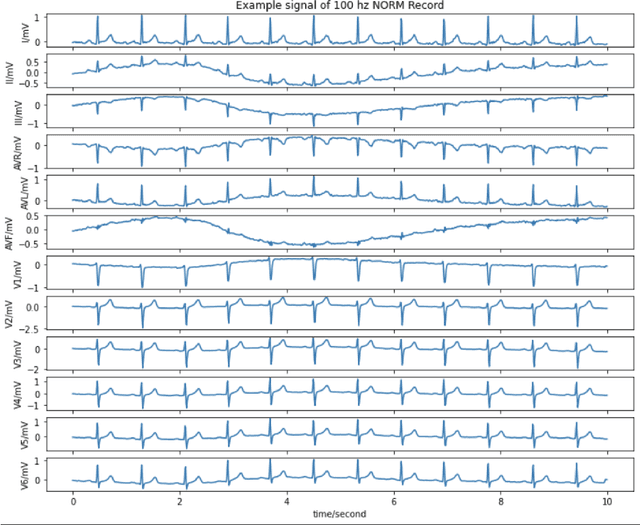

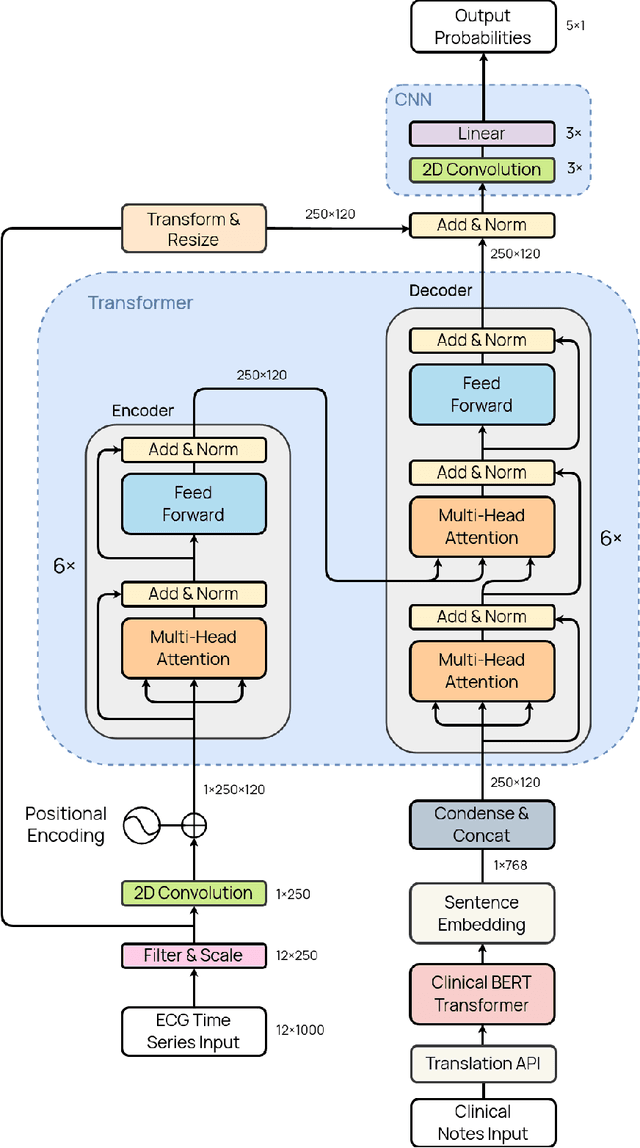

Deep learning provides an excellent avenue for optimizing diagnosis and patient monitoring for clinical-based applications, which can critically enhance the response time to the onset of various conditions. For cardiovascular disease, one such condition where the rising number of patients increasingly outweighs the availability of medical resources in different parts of the world, a core challenge is the automated classification of various cardiac abnormalities. Existing deep learning approaches have largely been limited to detecting the existence of an irregularity, as in binary classification, which has been achieved using networks such as CNNs and RNN/LSTMs. The next step is to accurately perform multi-class classification and determine the specific condition(s) from the inherently noisy multi-variate waveform, which is a difficult task that could benefit from (1) a more powerful sequential network, and (2) the integration of clinical notes, which provide valuable semantic and clinical context from human doctors. Recently, Transformers have emerged as the state-of-the-art architecture for forecasting and prediction using time-series data, with their multi-headed attention mechanism, and ability to process whole sequences and learn both long and short-range dependencies. The proposed novel multi-modal Transformer architecture would be able to accurately perform this task while demonstrating the cross-domain effectiveness of Transformers, establishing a method for incorporating multiple data modalities within a Transformer for classification tasks, and laying the groundwork for automating real-time patient condition monitoring in clinical and ER settings.
ResDiff: Combining CNN and Diffusion Model for Image Super-Resolution
Mar 16, 2023
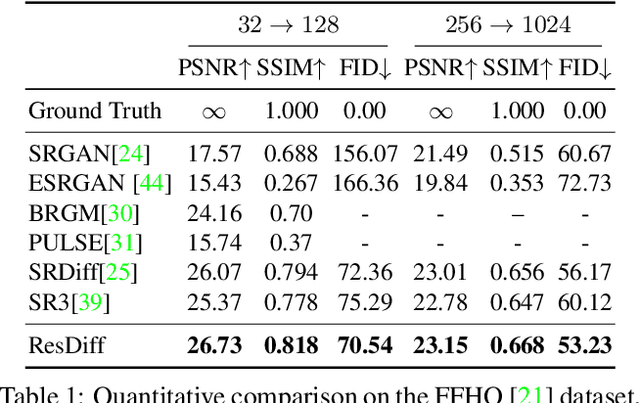
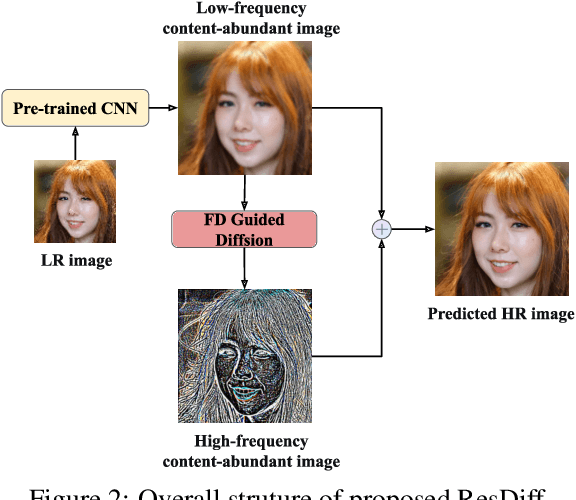
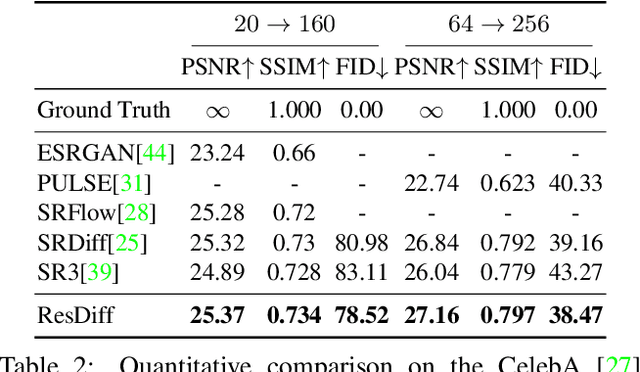
Adapting the Diffusion Probabilistic Model (DPM) for direct image super-resolution is wasteful, given that a simple Convolutional Neural Network (CNN) can recover the main low-frequency content. Therefore, we present ResDiff, a novel Diffusion Probabilistic Model based on Residual structure for Single Image Super-Resolution (SISR). ResDiff utilizes a combination of a CNN, which restores primary low-frequency components, and a DPM, which predicts the residual between the ground-truth image and the CNN-predicted image. In contrast to the common diffusion-based methods that directly use LR images to guide the noise towards HR space, ResDiff utilizes the CNN's initial prediction to direct the noise towards the residual space between HR space and CNN-predicted space, which not only accelerates the generation process but also acquires superior sample quality. Additionally, a frequency-domain-based loss function for CNN is introduced to facilitate its restoration, and a frequency-domain guided diffusion is designed for DPM on behalf of predicting high-frequency details. The extensive experiments on multiple benchmark datasets demonstrate that ResDiff outperforms previous diffusion-based methods in terms of shorter model convergence time, superior generation quality, and more diverse samples.
Transformer-based Planning for Symbolic Regression
Mar 16, 2023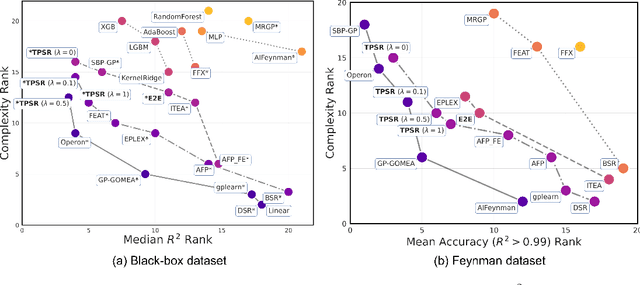
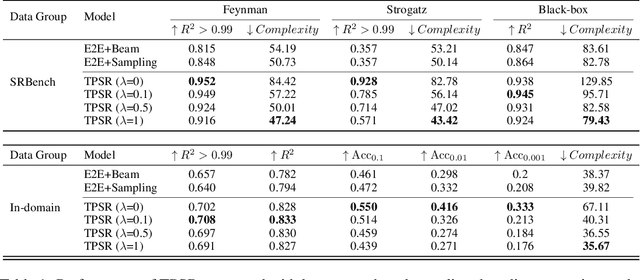
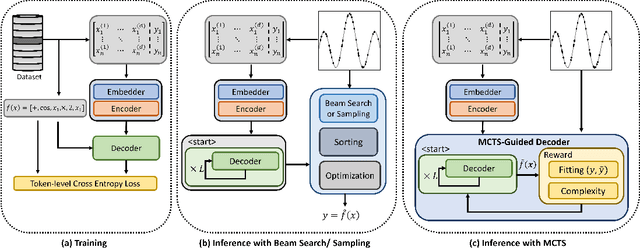
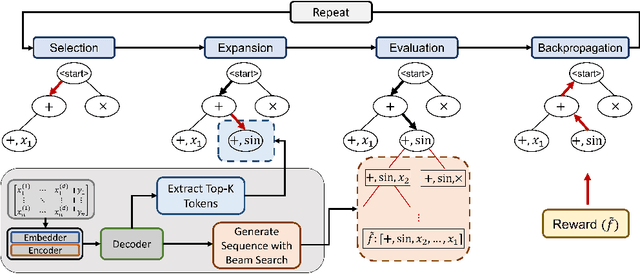
Symbolic regression (SR) is a challenging task in machine learning that involves finding a mathematical expression for a function based on its values. Recent advancements in SR have demonstrated the efficacy of pretrained transformer-based models for generating equations as sequences, which benefit from large-scale pretraining on synthetic datasets and offer considerable advantages over GP-based methods in terms of inference time. However, these models focus on supervised pretraining goals borrowed from text generation and ignore equation-specific objectives like accuracy and complexity. To address this, we propose TPSR, a Transformer-based Planning strategy for Symbolic Regression that incorporates Monte Carlo Tree Search into the transformer decoding process. TPSR, as opposed to conventional decoding strategies, allows for the integration of non-differentiable feedback, such as fitting accuracy and complexity, as external sources of knowledge into the equation generation process. Extensive experiments on various datasets show that our approach outperforms state-of-the-art methods, enhancing the model's fitting-complexity trade-off, extrapolation abilities, and robustness to noise. We also demonstrate that the utilization of various caching mechanisms can further enhance the efficiency of TPSR.
MixCycle: Mixup Assisted Semi-Supervised 3D Single Object Tracking with Cycle Consistency
Mar 16, 2023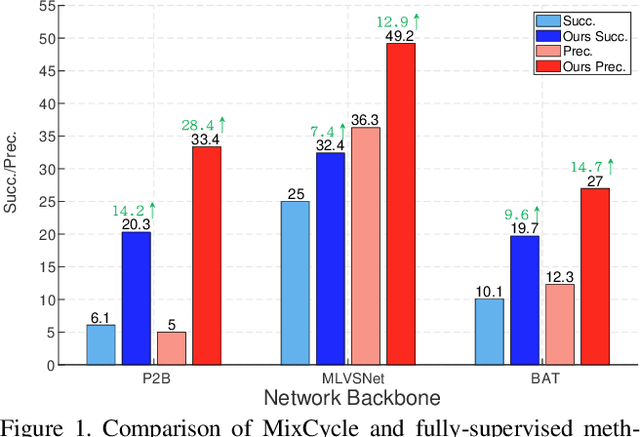
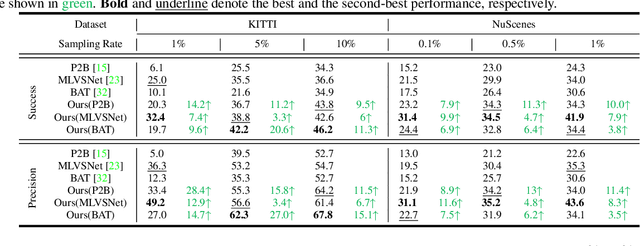
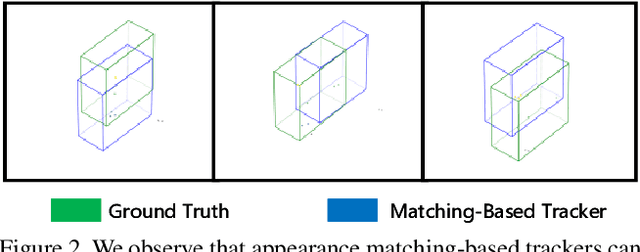
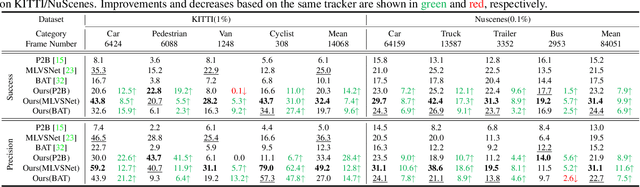
3D single object tracking (SOT) is an indispensable part of automated driving. Existing approaches rely heavily on large, densely labeled datasets. However, annotating point clouds is both costly and time-consuming. Inspired by the great success of cycle tracking in unsupervised 2D SOT, we introduce the first semi-supervised approach to 3D SOT. Specifically, we introduce two cycle-consistency strategies for supervision: 1) Self tracking cycles, which leverage labels to help the model converge better in the early stages of training; 2) forward-backward cycles, which strengthen the tracker's robustness to motion variations and the template noise caused by the template update strategy. Furthermore, we propose a data augmentation strategy named SOTMixup to improve the tracker's robustness to point cloud diversity. SOTMixup generates training samples by sampling points in two point clouds with a mixing rate and assigns a reasonable loss weight for training according to the mixing rate. The resulting MixCycle approach generalizes to appearance matching-based trackers. On the KITTI benchmark, based on the P2B tracker, MixCycle trained with $\textbf{10%}$ labels outperforms P2B trained with $\textbf{100%}$ labels, and achieves a $\textbf{28.4%}$ precision improvement when using $\textbf{1%}$ labels. Our code will be publicly released.
Knowledge Transfer for Pseudo-code Generation from Low Resource Programming Language
Mar 16, 2023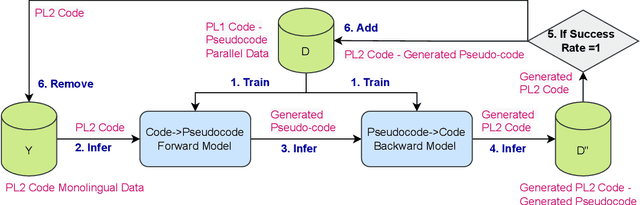
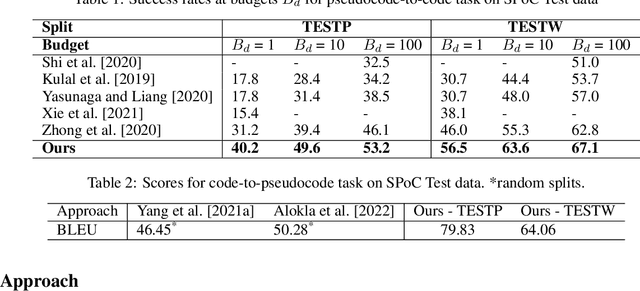


Generation of pseudo-code descriptions of legacy source code for software maintenance is a manually intensive task. Recent encoder-decoder language models have shown promise for automating pseudo-code generation for high resource programming languages such as C++, but are heavily reliant on the availability of a large code-pseudocode corpus. Soliciting such pseudocode annotations for codes written in legacy programming languages (PL) is a time consuming and costly affair requiring a thorough understanding of the source PL. In this paper, we focus on transferring the knowledge acquired by the code-to-pseudocode neural model trained on a high resource PL (C++) using parallel code-pseudocode data. We aim to transfer this knowledge to a legacy PL (C) with no PL-pseudocode parallel data for training. To achieve this, we utilize an Iterative Back Translation (IBT) approach with a novel test-cases based filtration strategy, to adapt the trained C++-to-pseudocode model to C-to-pseudocode model. We observe an improvement of 23.27% in the success rate of the generated C codes through back translation, over the successive IBT iteration, illustrating the efficacy of our approach.
Arbitrary Order Meta-Learning with Simple Population-Based Evolution
Mar 16, 2023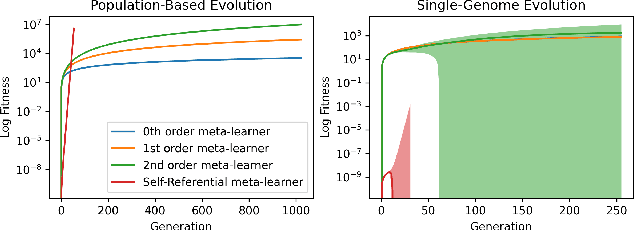
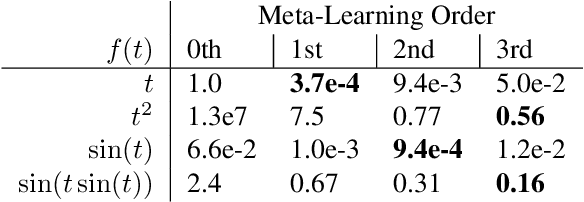
Meta-learning, the notion of learning to learn, enables learning systems to quickly and flexibly solve new tasks. This usually involves defining a set of outer-loop meta-parameters that are then used to update a set of inner-loop parameters. Most meta-learning approaches use complicated and computationally expensive bi-level optimisation schemes to update these meta-parameters. Ideally, systems should perform multiple orders of meta-learning, i.e. to learn to learn to learn and so on, to accelerate their own learning. Unfortunately, standard meta-learning techniques are often inappropriate for these higher-order meta-parameters because the meta-optimisation procedure becomes too complicated or unstable. Inspired by the higher-order meta-learning we observe in real-world evolution, we show that using simple population-based evolution implicitly optimises for arbitrarily-high order meta-parameters. First, we theoretically prove and empirically show that population-based evolution implicitly optimises meta-parameters of arbitrarily-high order in a simple setting. We then introduce a minimal self-referential parameterisation, which in principle enables arbitrary-order meta-learning. Finally, we show that higher-order meta-learning improves performance on time series forecasting tasks.
Maximum Correntropy Criterion Kalman Filter For Indoor Quadrotor Navigation Under Intermittent Measurements
Mar 16, 2023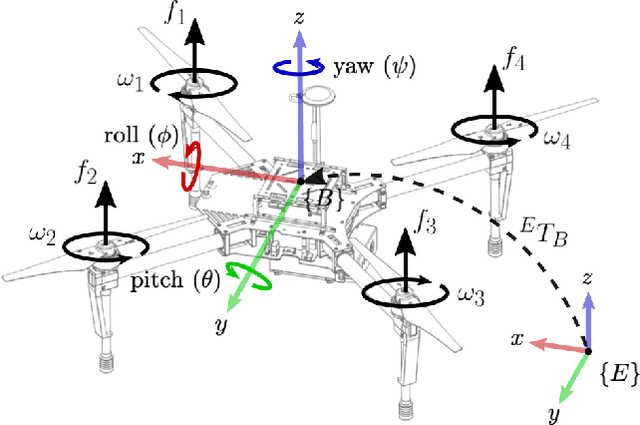
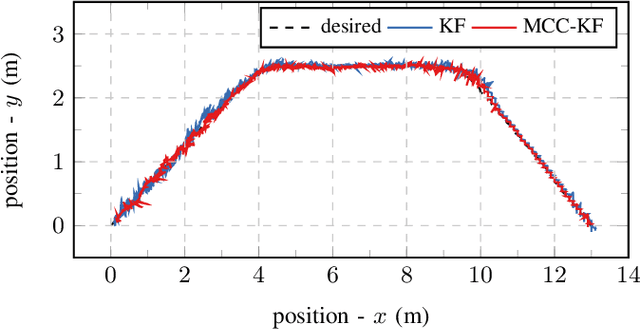
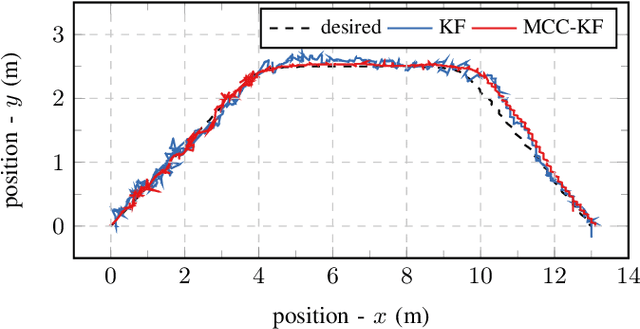
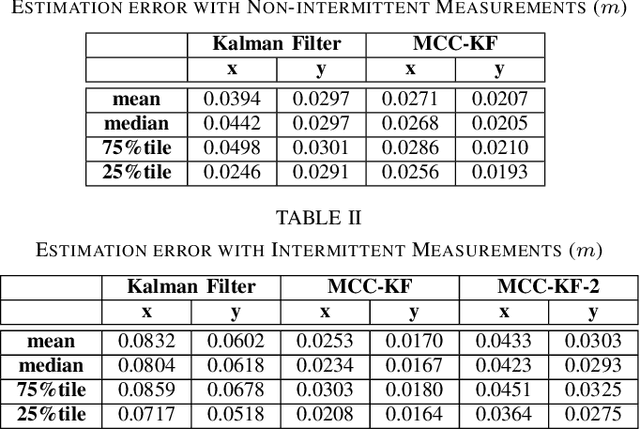
We present a multisensor fusion framework for the onboard real-time navigation of a quadrotor in an indoor environment. The framework integrates sensor readings from an Inertial Measurement Unit (IMU), a camera-based object detection algorithm, and an Ultra-WideBand (UWB) localisation system. Often the sensor readings are not always readily available, leading to inaccurate pose estimation and hence poor navigation performance. To effectively handle and fuse sensor readings, and accurately estimate the pose of the quadrotor for tracking a predefined trajectory, we design a Maximum Correntropy Criterion Kalman Filter (MCC-KF) that can manage intermittent observations. The MCC-KF is designed to improve the performance of the estimation process when is done with a Kalman Filter (KF), since KFs are likely to degrade dramatically in practical scenarios in which noise is non-Gaussian (especially when the noise is heavy-tailed). To evaluate the performance of the MCC-KF, we compare it with a previously designed Kalman filter by the authors. Through this comparison, we aim to demonstrate the effectiveness of the MCC-KF in handling indoor navigation missions. The simulation results show that our presented framework offers low positioning errors, while effectively handling intermittent sensor measurements.
Revisiting Wright: Improving supervised classification of rat ultrasonic vocalisations using synthetic training data
Mar 03, 2023
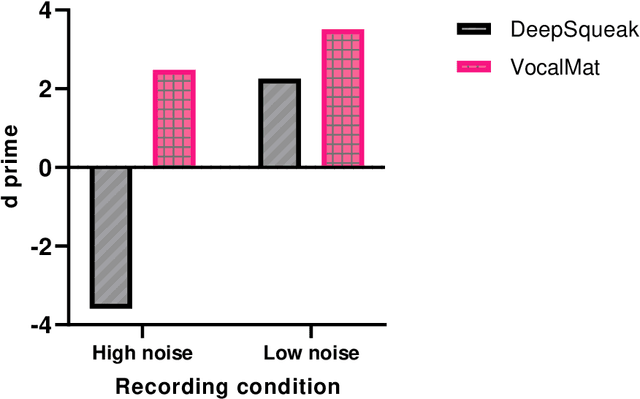
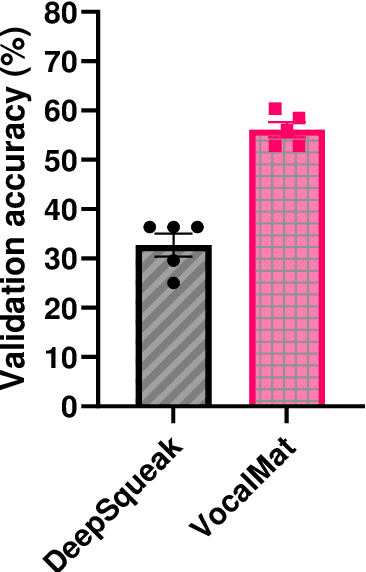
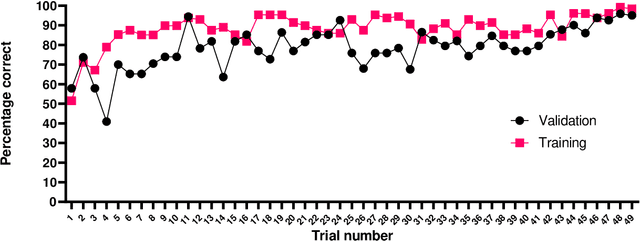
Rodents communicate through ultrasonic vocalizations (USVs). These calls are of interest because they provide insight into the development and function of vocal communication, and may prove to be useful as a biomarker for dysfunction in models of neurodevelopmental disorders. Rodent USVs can be categorised into different components and while manual classification is time consuming, advances in neural computing have allowed for fast and accurate identification and classification. Here, we adapt a convolutional neural network (CNN), VocalMat, created for analysing mice USVs, for use with rats. We codify a modified schema, adapted from that previously proposed by Wright et al. (2010), for classification, and compare the performance of our adaptation of VocalMat with a benchmark CNN, DeepSqueak. Additionally, we test the effect of inserting synthetic USVs into the training data of our classification network in order to reduce the workload involved in generating a training set. Our results show that the modified VocalMat outperformed the benchmark software on measures of both call identification, and classification. Additionally, we found that the augmentation of training data with synthetic images resulted in a marked improvement in the accuracy of VocalMat when it was subsequently used to analyse novel data. The resulting accuracy on the modified Wright categorizations was sufficiently high to allow for the application of this software in rat USV classification in laboratory conditions. Our findings also show that inserting synthetic USV calls into the training set leads to improvements in accuracy with little extra time-cost.
MixVPR: Feature Mixing for Visual Place Recognition
Mar 03, 2023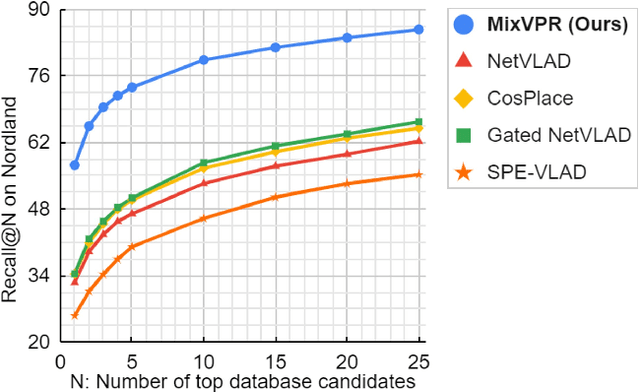
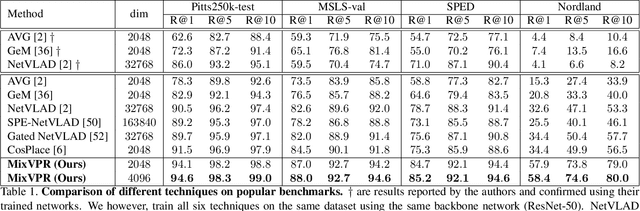
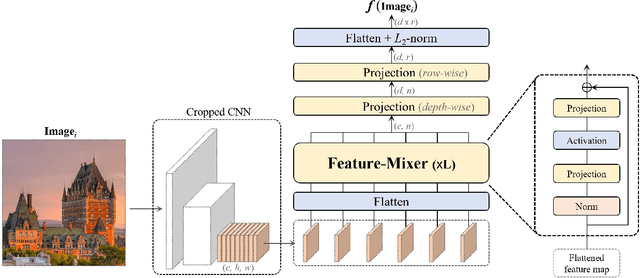
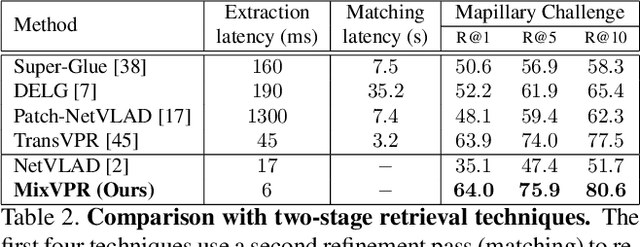
Visual Place Recognition (VPR) is a crucial part of mobile robotics and autonomous driving as well as other computer vision tasks. It refers to the process of identifying a place depicted in a query image using only computer vision. At large scale, repetitive structures, weather and illumination changes pose a real challenge, as appearances can drastically change over time. Along with tackling these challenges, an efficient VPR technique must also be practical in real-world scenarios where latency matters. To address this, we introduce MixVPR, a new holistic feature aggregation technique that takes feature maps from pre-trained backbones as a set of global features. Then, it incorporates a global relationship between elements in each feature map in a cascade of feature mixing, eliminating the need for local or pyramidal aggregation as done in NetVLAD or TransVPR. We demonstrate the effectiveness of our technique through extensive experiments on multiple large-scale benchmarks. Our method outperforms all existing techniques by a large margin while having less than half the number of parameters compared to CosPlace and NetVLAD. We achieve a new all-time high recall@1 score of 94.6% on Pitts250k-test, 88.0% on MapillarySLS, and more importantly, 58.4% on Nordland. Finally, our method outperforms two-stage retrieval techniques such as Patch-NetVLAD, TransVPR and SuperGLUE all while being orders of magnitude faster. Our code and trained models are available at https://github.com/amaralibey/MixVPR.