 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Configurable EBEN: Extreme Bandwidth Extension Network to enhance body-conducted speech capture
Mar 17, 2023
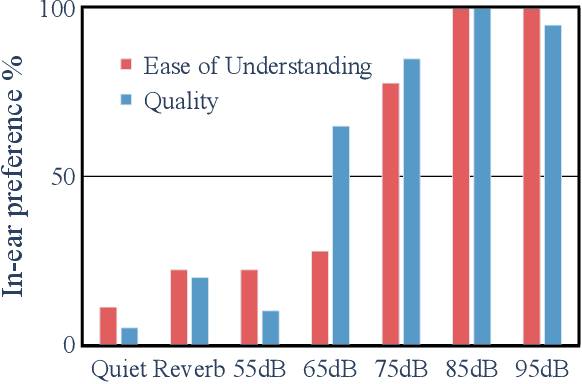
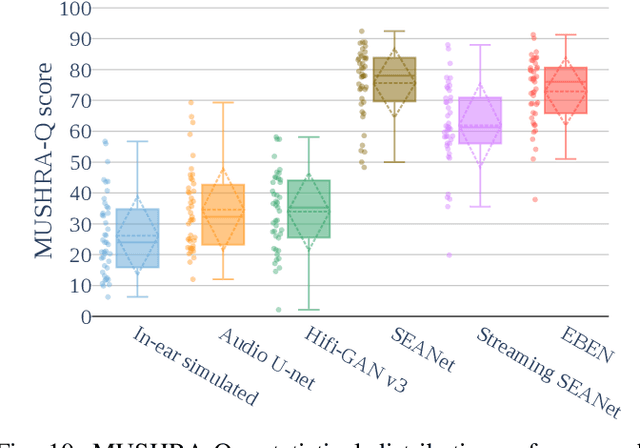
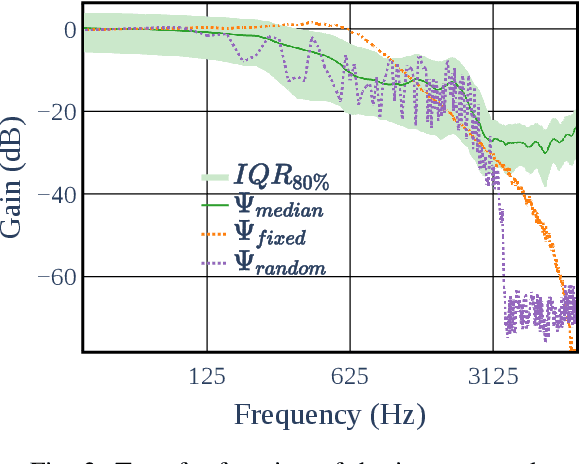
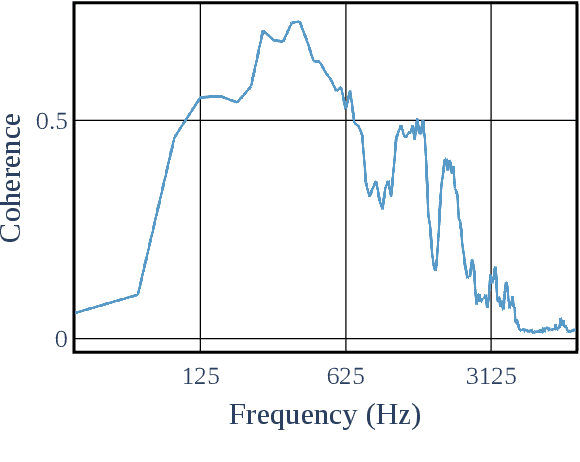
This paper presents a configurable version of Extreme Bandwidth Extension Network (EBEN), a Generative Adversarial Network (GAN) designed to improve audio captured with body-conduction microphones. We show that these microphones significantly reduce environmental noise. However, this insensitivity to ambient noise is at the expense of the bandwidth of the voice signal acquired from the wearer of the devices. The obtained captured signals therefore require the use of signal enhancement techniques to recover the full-bandwidth speech. EBEN leverages a configurable multiband decomposition of the raw captured signal. This decomposition allows the data time domain dimensions to be reduced and the full band signal to be better controlled. The multiband representation of the captured signal is processed through a U-Net-like model, which combines feature and adversarial losses to generate an enhanced speech signal. We also benefit from this original representation in the proposed configurable discriminator architecture. The configurable EBEN approach can achieve state-of-the-art enhancement results on synthetic data with a lightweight generator that allows real-time processing.
IterativePFN: True Iterative Point Cloud Filtering
Apr 04, 2023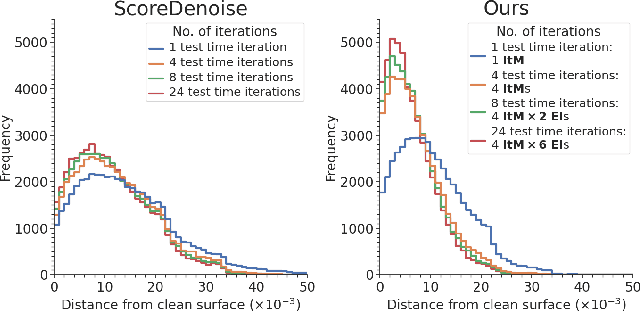
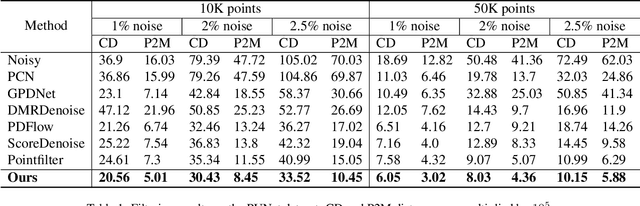
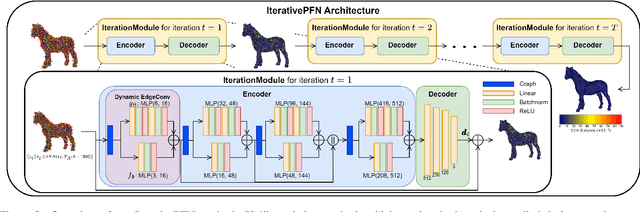
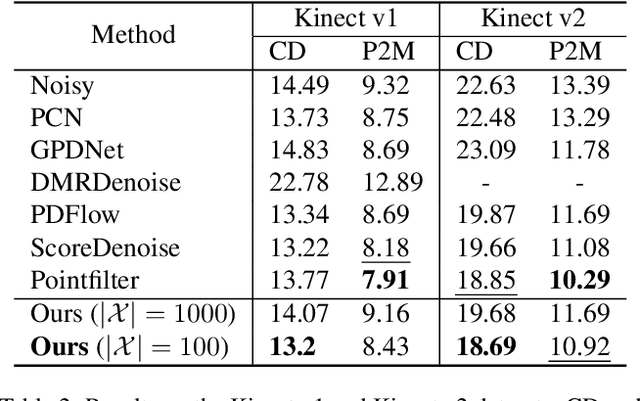
The quality of point clouds is often limited by noise introduced during their capture process. Consequently, a fundamental 3D vision task is the removal of noise, known as point cloud filtering or denoising. State-of-the-art learning based methods focus on training neural networks to infer filtered displacements and directly shift noisy points onto the underlying clean surfaces. In high noise conditions, they iterate the filtering process. However, this iterative filtering is only done at test time and is less effective at ensuring points converge quickly onto the clean surfaces. We propose IterativePFN (iterative point cloud filtering network), which consists of multiple IterationModules that model the true iterative filtering process internally, within a single network. We train our IterativePFN network using a novel loss function that utilizes an adaptive ground truth target at each iteration to capture the relationship between intermediate filtering results during training. This ensures that the filtered results converge faster to the clean surfaces. Our method is able to obtain better performance compared to state-of-the-art methods. The source code can be found at: https://github.com/ddsediri/IterativePFN.
Label-guided Attention Distillation for Lane Segmentation
Apr 04, 2023
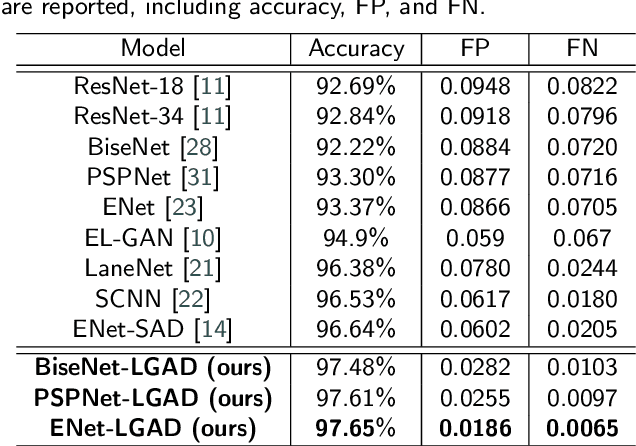

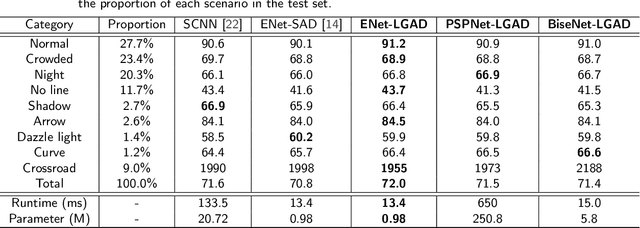
Contemporary segmentation methods are usually based on deep fully convolutional networks (FCNs). However, the layer-by-layer convolutions with a growing receptive field is not good at capturing long-range contexts such as lane markers in the scene. In this paper, we address this issue by designing a distillation method that exploits label structure when training segmentation network. The intuition is that the ground-truth lane annotations themselves exhibit internal structure. We broadcast the structure hints throughout a teacher network, i.e., we train a teacher network that consumes a lane label map as input and attempts to replicate it as output. Then, the attention maps of the teacher network are adopted as supervisors of the student segmentation network. The teacher network, with label structure information embedded, knows distinctly where the convolution layers should pay visual attention into. The proposed method is named as Label-guided Attention Distillation (LGAD). It turns out that the student network learns significantly better with LGAD than when learning alone. As the teacher network is deprecated after training, our method do not increase the inference time. Note that LGAD can be easily incorporated in any lane segmentation network.
* Accepted to Neurocomputing 2021
Dialogue-Contextualized Re-ranking for Medical History-Taking
Apr 04, 2023
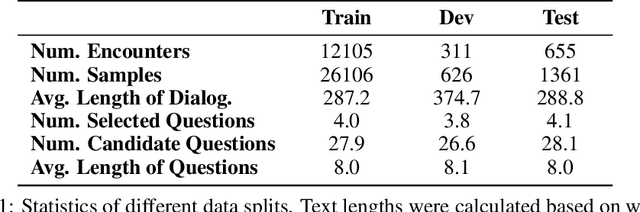
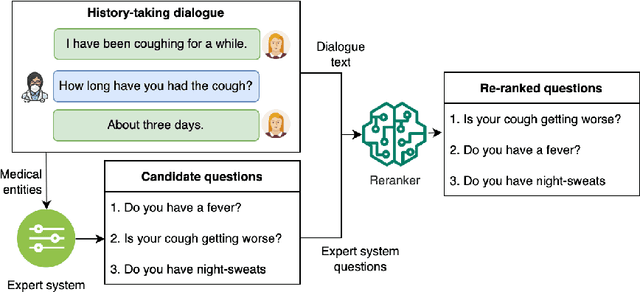
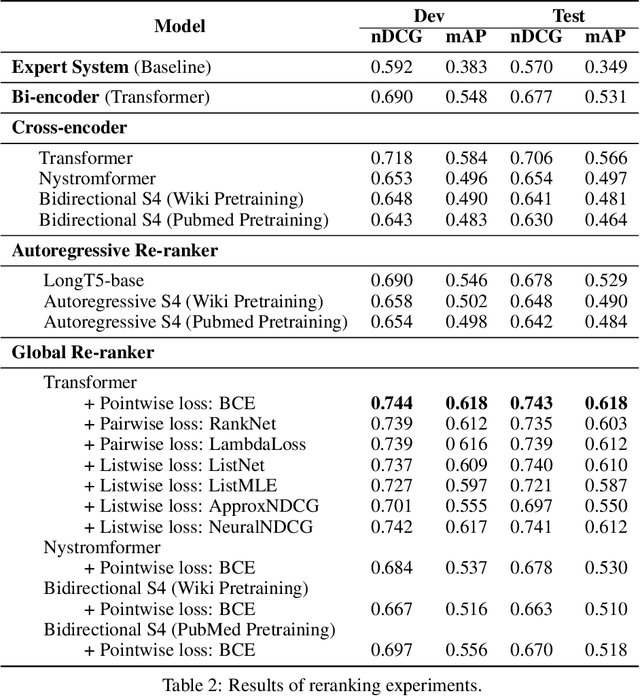
AI-driven medical history-taking is an important component in symptom checking, automated patient intake, triage, and other AI virtual care applications. As history-taking is extremely varied, machine learning models require a significant amount of data to train. To overcome this challenge, existing systems are developed using indirect data or expert knowledge. This leads to a training-inference gap as models are trained on different kinds of data than what they observe at inference time. In this work, we present a two-stage re-ranking approach that helps close the training-inference gap by re-ranking the first-stage question candidates using a dialogue-contextualized model. For this, we propose a new model, global re-ranker, which cross-encodes the dialogue with all questions simultaneously, and compare it with several existing neural baselines. We test both transformer and S4-based language model backbones. We find that relative to the expert system, the best performance is achieved by our proposed global re-ranker with a transformer backbone, resulting in a 30% higher normalized discount cumulative gain (nDCG) and a 77% higher mean average precision (mAP).
Model-corrected learned primal-dual models for fast limited-view photoacoustic tomography
Apr 04, 2023Learned iterative reconstructions hold great promise to accelerate tomographic imaging with empirical robustness to model perturbations. Nevertheless, an adoption for photoacoustic tomography is hindered by the need to repeatedly evaluate the computational expensive forward model. Computational feasibility can be obtained by the use of fast approximate models, but a need to compensate model errors arises. In this work we advance the methodological and theoretical basis for model corrections in learned image reconstructions by embedding the model correction in a learned primal-dual framework. Here, the model correction is jointly learned in data space coupled with a learned updating operator in image space within an unrolled end-to-end learned iterative reconstruction approach. The proposed formulation allows an extension to a primal-dual deep equilibrium model providing fixed-point convergence as well as reduced memory requirements for training. We provide theoretical and empirical insights into the proposed models with numerical validation in a realistic 2D limited-view setting. The model-corrected learned primal-dual methods show excellent reconstruction quality with fast inference times and thus providing a methodological basis for real-time capable and scalable iterative reconstructions in photoacoustic tomography.
Efficient LQR-CBF-RRT*: Safe and Optimal Motion Planning
Apr 04, 2023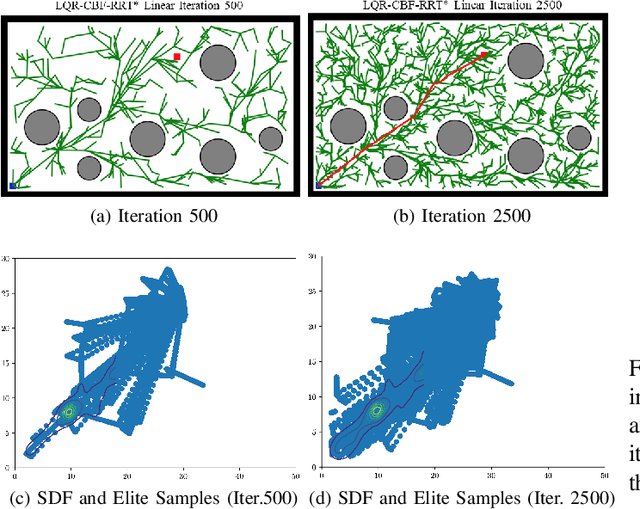
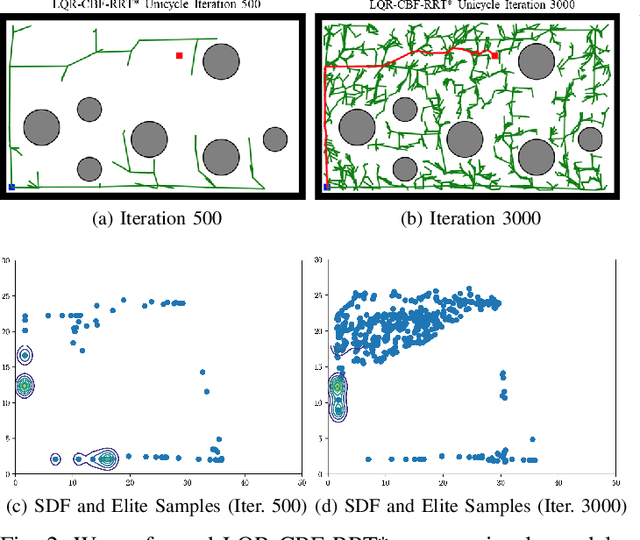
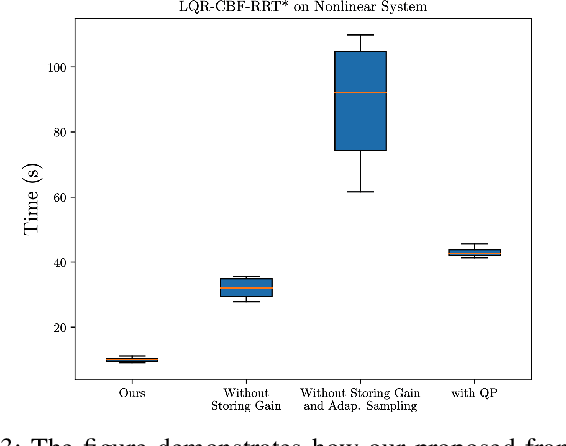
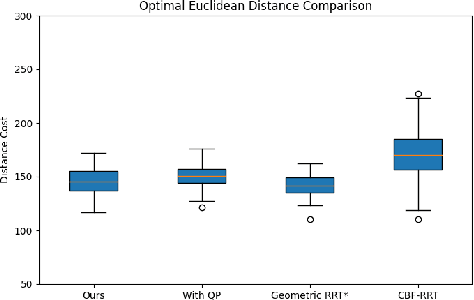
Control Barrier Functions (CBF) are a powerful tool for designing safety-critical controllers and motion planners. The safety requirements are encoded as a continuously differentiable function that maps from state variables to a real value, in which the sign of its output determines whether safety is violated. In practice, the CBFs can be used to enforce safety by imposing itself as a constraint in a Quadratic Program (QP) solved point-wise in time. However, this approach costs computational resources and could lead to infeasibility in solving the QP. In this paper, we propose a novel motion planning framework that combines sampling-based methods with Linear Quadratic Regulator (LQR) and CBFs. Our approach does not require solving the QPs for control synthesis and avoids explicit collision checking during samplings. Instead, it uses LQR to generate optimal controls and CBF to reject unsafe trajectories. To improve sampling efficiency, we employ the Cross-Entropy Method (CEM) for importance sampling (IS) to sample configurations that will enhance the path with higher probability and store computed optimal gain matrices in a hash table to avoid re-computation during rewiring procedure. We demonstrate the effectiveness of our method on nonlinear control affine systems in simulation.
FedBot: Enhancing Privacy in Chatbots with Federated Learning
Apr 04, 2023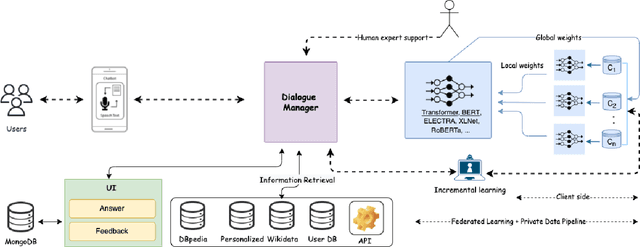

Chatbots are mainly data-driven and usually based on utterances that might be sensitive. However, training deep learning models on shared data can violate user privacy. Such issues have commonly existed in chatbots since their inception. In the literature, there have been many approaches to deal with privacy, such as differential privacy and secure multi-party computation, but most of them need to have access to users' data. In this context, Federated Learning (FL) aims to protect data privacy through distributed learning methods that keep the data in its location. This paper presents Fedbot, a proof-of-concept (POC) privacy-preserving chatbot that leverages large-scale customer support data. The POC combines Deep Bidirectional Transformer models and federated learning algorithms to protect customer data privacy during collaborative model training. The results of the proof-of-concept showcase the potential for privacy-preserving chatbots to transform the customer support industry by delivering personalized and efficient customer service that meets data privacy regulations and legal requirements. Furthermore, the system is specifically designed to improve its performance and accuracy over time by leveraging its ability to learn from previous interactions.
Cross-modulated Few-shot Image Generation for Colorectal Tissue Classification
Apr 04, 2023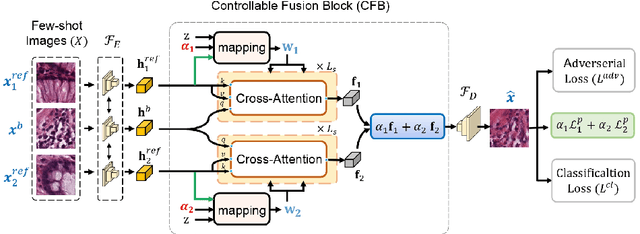
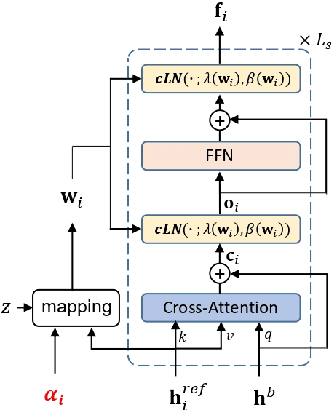
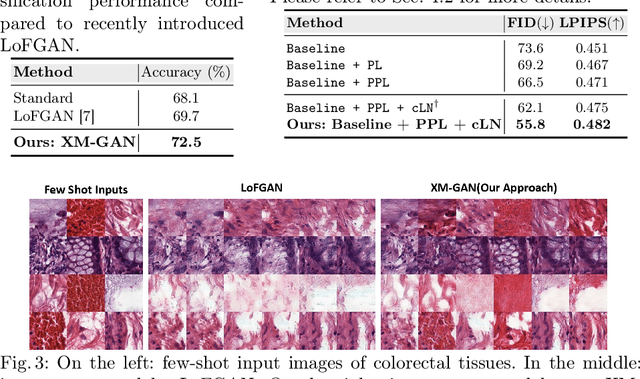
In this work, we propose a few-shot colorectal tissue image generation method for addressing the scarcity of histopathological training data for rare cancer tissues. Our few-shot generation method, named XM-GAN, takes one base and a pair of reference tissue images as input and generates high-quality yet diverse images. Within our XM-GAN, a novel controllable fusion block densely aggregates local regions of reference images based on their similarity to those in the base image, resulting in locally consistent features. To the best of our knowledge, we are the first to investigate few-shot generation in colorectal tissue images. We evaluate our few-shot colorectral tissue image generation by performing extensive qualitative, quantitative and subject specialist (pathologist) based evaluations. Specifically, in specialist-based evaluation, pathologists could differentiate between our XM-GAN generated tissue images and real images only 55% time. Moreover, we utilize these generated images as data augmentation to address the few-shot tissue image classification task, achieving a gain of 4.4% in terms of mean accuracy over the vanilla few-shot classifier. Code: \url{https://github.com/VIROBO-15/XM-GAN}
Automatic Measures for Evaluating Generative Design Methods for Architects
Mar 20, 2023


The recent explosion of high-quality image-to-image methods has prompted interest in applying image-to-image methods towards artistic and design tasks. Of interest for architects is to use these methods to generate design proposals from conceptual sketches, usually hand-drawn sketches that are quickly developed and can embody a design intent. More specifically, instantiating a sketch into a visual that can be used to elicit client feedback is typically a time consuming task, and being able to speed up this iteration time is important. While the body of work in generative methods has been impressive, there has been a mismatch between the quality measures used to evaluate the outputs of these systems and the actual expectations of architects. In particular, most recent image-based works place an emphasis on realism of generated images. While important, this is one of several criteria architects look for. In this work, we describe the expectations architects have for design proposals from conceptual sketches, and identify corresponding automated metrics from the literature. We then evaluate several image-to-image generative methods that may address these criteria and examine their performance across these metrics. From these results, we identify certain challenges with hand-drawn conceptual sketches and describe possible future avenues of investigation to address them.
DFSNet: A Steerable Neural Beamformer Invariant to Microphone Array Configuration for Real-Time, Low-Latency Speech Enhancement
Feb 26, 2023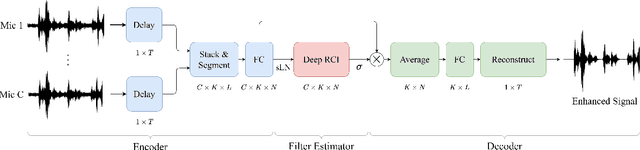
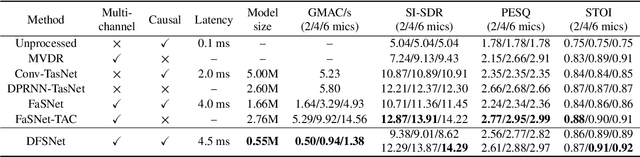
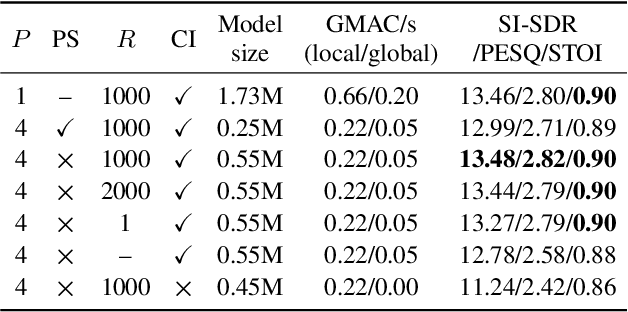
Invariance to microphone array configuration is a rare attribute in neural beamformers. Filter-and-sum (FS) methods in this class define the target signal with respect to a reference channel. However, this not only complicates formulation in reverberant conditions but also the network, which must have a mechanism to infer what the reference channel is. To address these issues, this study presents Delay Filter-and-Sum Network (DFSNet), a steerable neural beamformer invariant to microphone number and array geometry for causal speech enhancement. In DFSNet, acquired signals are first steered toward the speech source direction prior to the FS operation, which simplifies the task into the estimation of delay-and-summed reverberant clean speech. The proposed model is designed to incur low latency, distortion, and memory and computational burden, giving rise to high potential in hearing aid applications. Simulation results reveal comparable performance to noncausal state-of-the-art.