 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PopSparse: Accelerated block sparse matrix multiplication on IPU
Mar 29, 2023
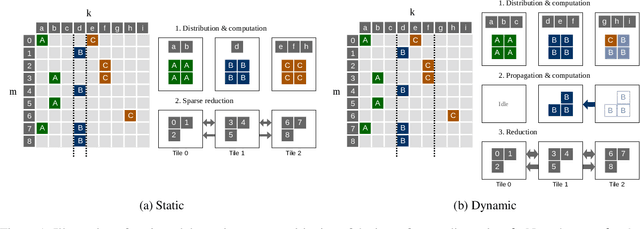
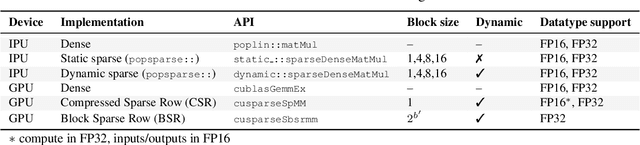
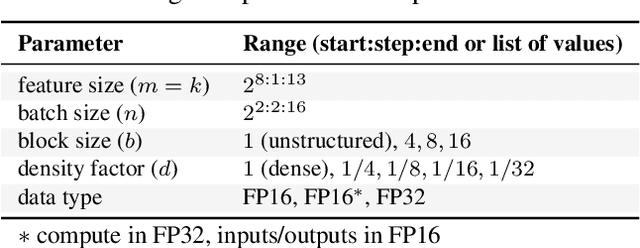
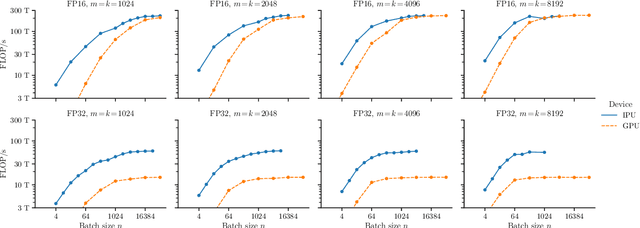
Reducing the computational cost of running large scale neural networks using sparsity has attracted great attention in the deep learning community. While much success has been achieved in reducing FLOP and parameter counts while maintaining acceptable task performance, achieving actual speed improvements has typically been much more difficult, particularly on general purpose accelerators (GPAs) such as NVIDIA GPUs using low precision number formats. In this work we introduce PopSparse, a library that enables fast sparse operations on Graphcore IPUs by leveraging both the unique hardware characteristics of IPUs as well as any block structure defined in the data. We target two different types of sparsity: static, where the sparsity pattern is fixed at compile-time; and dynamic, where it can change each time the model is run. We present benchmark results for matrix multiplication for both of these modes on IPU with a range of block sizes, matrix sizes and densities. Results indicate that the PopSparse implementations are faster than dense matrix multiplications on IPU at a range of sparsity levels with large matrix size and block size. Furthermore, static sparsity in general outperforms dynamic sparsity. While previous work on GPAs has shown speedups only for very high sparsity (typically 99\% and above), the present work demonstrates that our static sparse implementation outperforms equivalent dense calculations in FP16 at lower sparsity (around 90%).
Learning the Delay Using Neural Delay Differential Equations
Apr 03, 2023
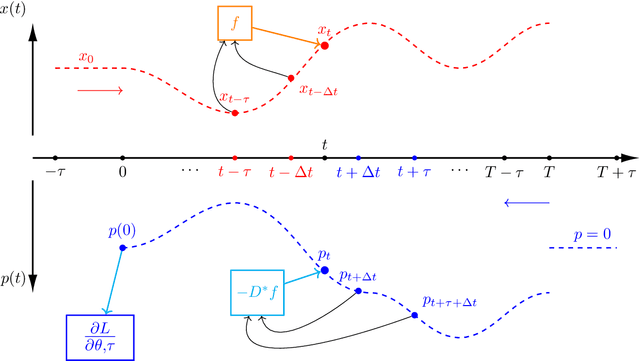
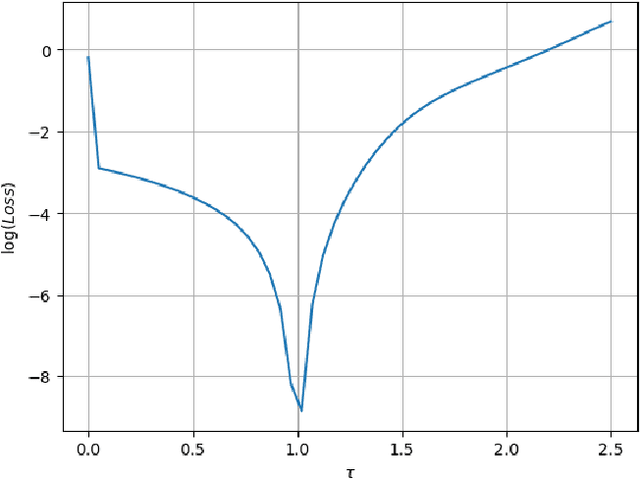
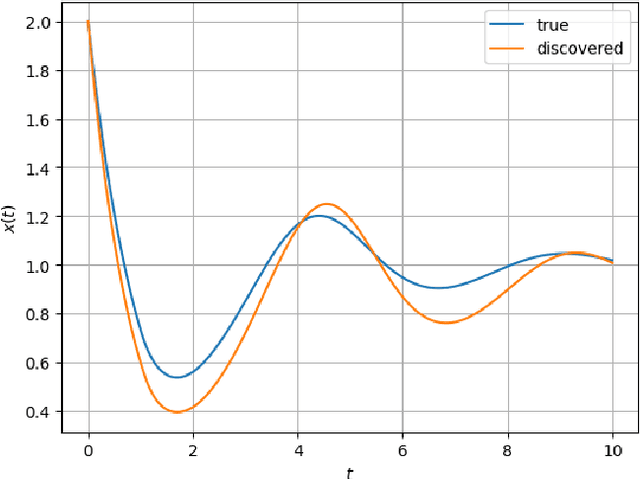
The intersection of machine learning and dynamical systems has generated considerable interest recently. Neural Ordinary Differential Equations (NODEs) represent a rich overlap between these fields. In this paper, we develop a continuous time neural network approach based on Delay Differential Equations (DDEs). Our model uses the adjoint sensitivity method to learn the model parameters and delay directly from data. Our approach is inspired by that of NODEs and extends earlier neural DDE models, which have assumed that the value of the delay is known a priori. We perform a sensitivity analysis on our proposed approach and demonstrate its ability to learn DDE parameters from benchmark systems. We conclude our discussion with potential future directions and applications.
UX-NET: Filter-and-Process-based Improved U-Net for Real-time Time-domain Audio Separation
Oct 28, 2022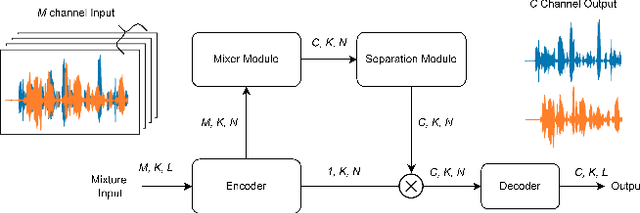
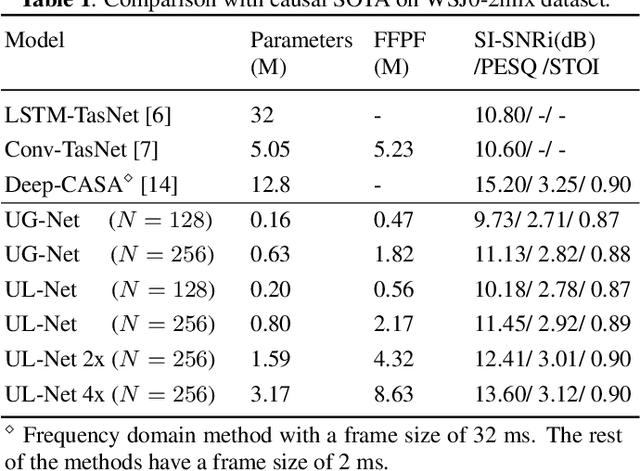
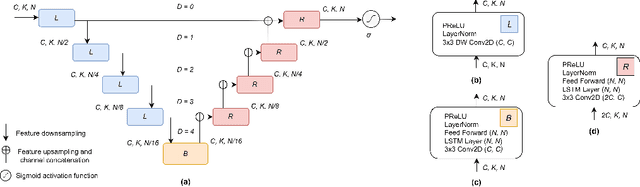
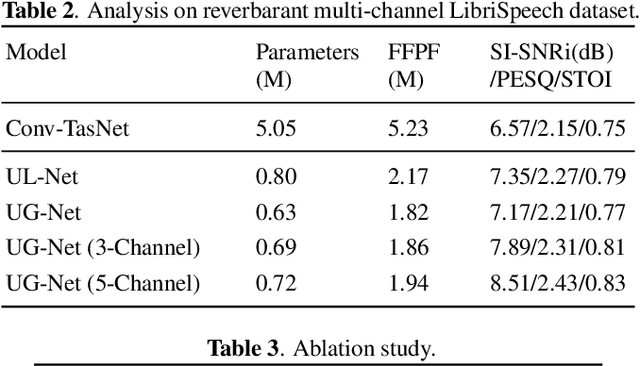
This study presents UX-Net, a time-domain audio separation network (TasNet) based on a modified U-Net architecture. The proposed UX-Net works in real-time and handles either single or multi-microphone input. Inspired by the filter-and-process-based human auditory behavior, the proposed system introduces novel mixer and separation modules, which result in cost and memory efficient modeling of speech sources. The mixer module combines encoded input in a latent feature space and outputs a desired number of output streams. Then, in the separation module, a modified U-Net (UX) block is applied. The UX block first filters the encoded input at various resolutions followed by aggregating the filtered information and applying recurrent processing to estimate masks of separated sources. The letter 'X' in UX-Net is a name placeholder for the type of recurrent layer employed in the UX block. Empirical findings on the WSJ0-2mix benchmark dataset show that one of the UX-Net configurations outperforms the state-of-the-art Conv-TasNet system by 0.85 dB SI-SNR while using only 16% of the model parameters, 58% fewer computations, and maintaining low latency.
Locality-constrained autoregressive cum conditional normalizing flow for lattice field theory simulations
Apr 04, 2023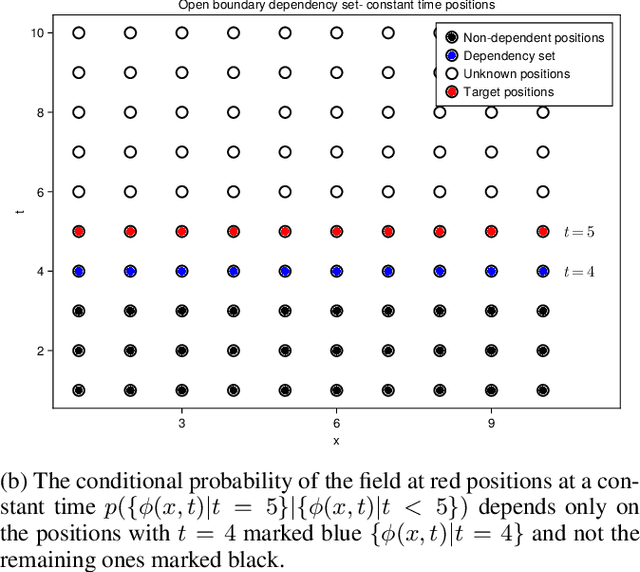
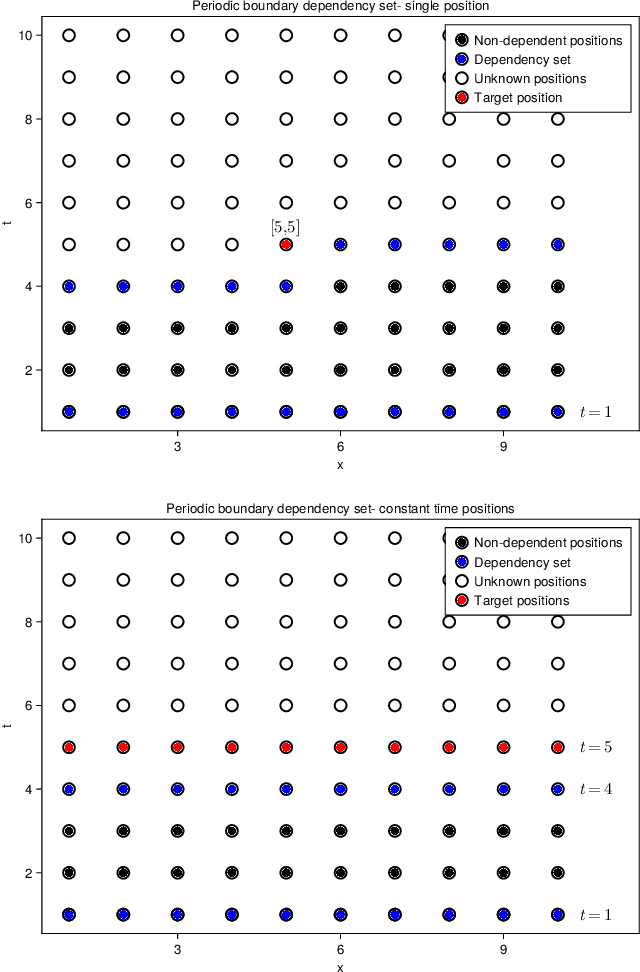
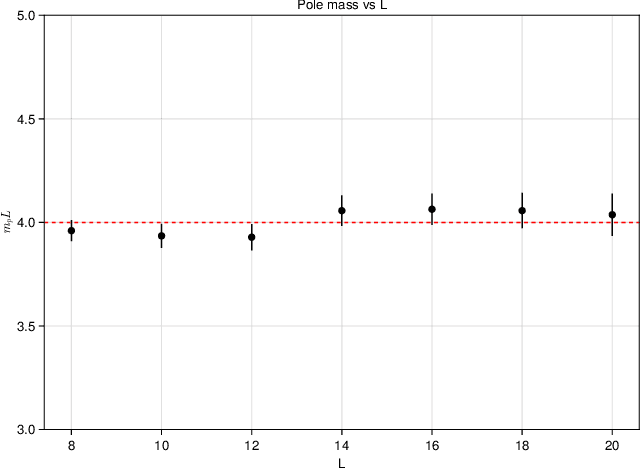
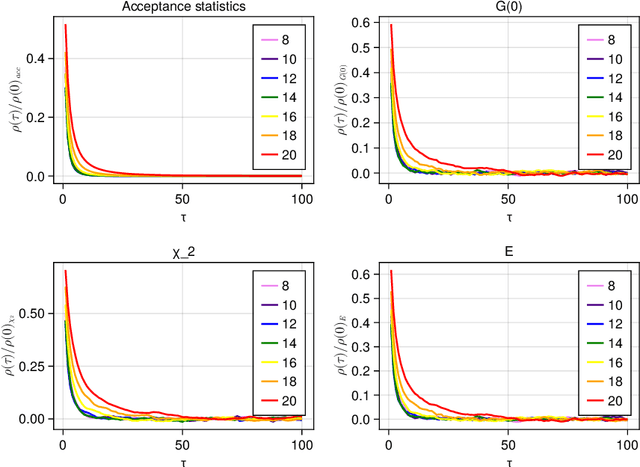
Normalizing flow-based sampling methods have been successful in tackling computational challenges traditionally associated with simulating lattice quantum field theories. Further works have incorporated gauge and translational invariance of the action integral in the underlying neural networks, which have led to efficient training and inference in those models. In this paper, we incorporate locality of the action integral which leads to simplifications to the input domain of conditional normalizing flows that sample constant time sub-lattices in an autoregressive process, dubbed local-Autoregressive Conditional Normalizing Flow (l-ACNF). We find that the autocorrelation times of l-ACNF models outperform an equivalent normalizing flow model on the full lattice by orders of magnitude when sampling $\phi^{4}$ theory on a 2 dimensional lattice.
Fast QTMT Partition for VVC Intra Coding Using U-Net Framework
Apr 06, 2023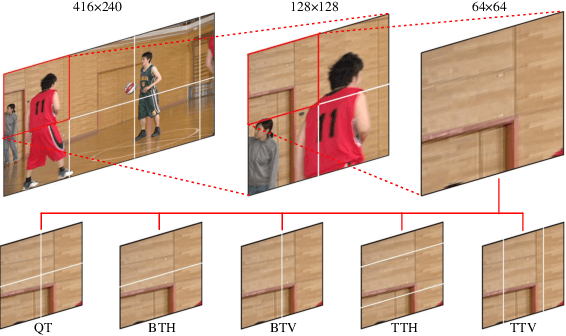
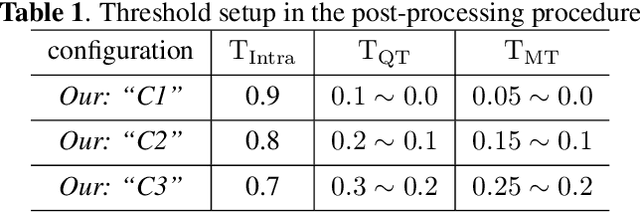
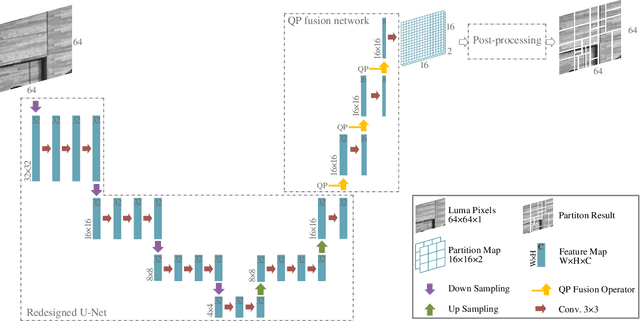
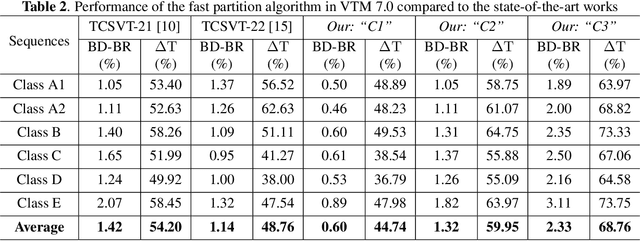
Versatile Video Coding (VVC) has significantly increased encoding efficiency at the expense of numerous complex coding tools, particularly the flexible Quad-Tree plus Multi-type Tree (QTMT) block partition. This paper proposes a deep learning-based algorithm applied in fast QTMT partition for VVC intra coding. Our solution greatly reduces encoding time by early termination of less-likely intra prediction and partitions with negligible BD-BR increase. Firstly, a redesigned U-Net is recommended as the network's fundamental framework. Next, we design a Quality Parameter (QP) fusion network to regulate the effect of QPs on the partition results. Finally, we adopt a refined post-processing strategy to better balance encoding performance and complexity. Experimental results demonstrate that our solution outperforms the state-of-the-art works with a complexity reduction of 44.74% to 68.76% and a BD-BR increase of 0.60% to 2.33%.
Dual-Attention Neural Transducers for Efficient Wake Word Spotting in Speech Recognition
Apr 05, 2023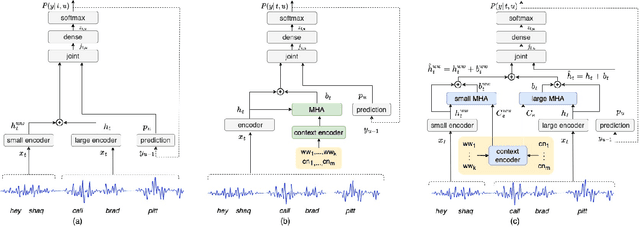
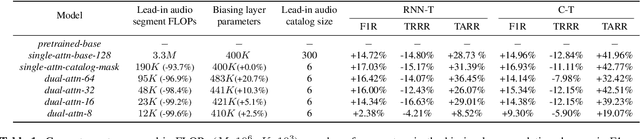
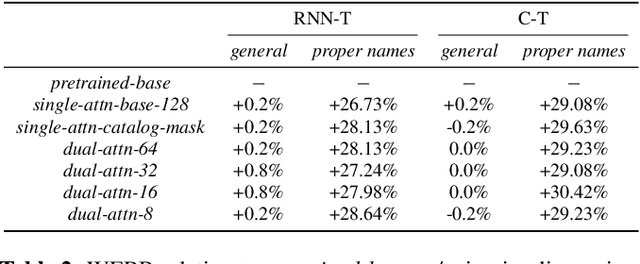
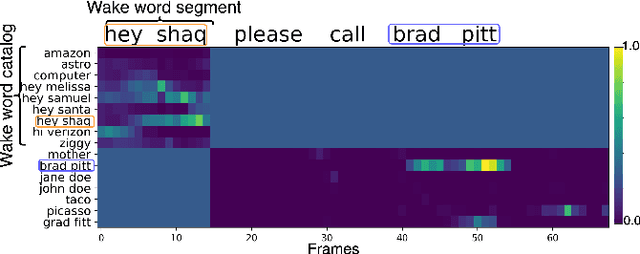
We present dual-attention neural biasing, an architecture designed to boost Wake Words (WW) recognition and improve inference time latency on speech recognition tasks. This architecture enables a dynamic switch for its runtime compute paths by exploiting WW spotting to select which branch of its attention networks to execute for an input audio frame. With this approach, we effectively improve WW spotting accuracy while saving runtime compute cost as defined by floating point operations (FLOPs). Using an in-house de-identified dataset, we demonstrate that the proposed dual-attention network can reduce the compute cost by $90\%$ for WW audio frames, with only $1\%$ increase in the number of parameters. This architecture improves WW F1 score by $16\%$ relative and improves generic rare word error rate by $3\%$ relative compared to the baselines.
Efficient Optimization-based Cable Force Allocation for Geometric Control of Multiple Quadrotors Transporting a Payload
Apr 05, 2023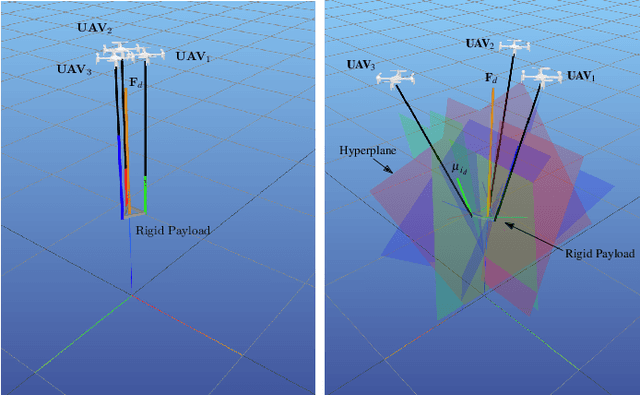

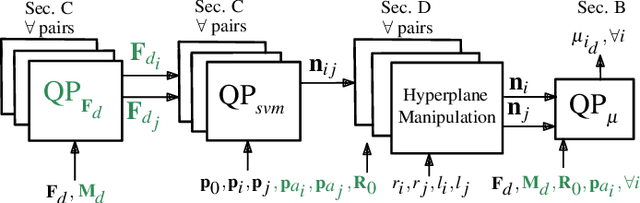
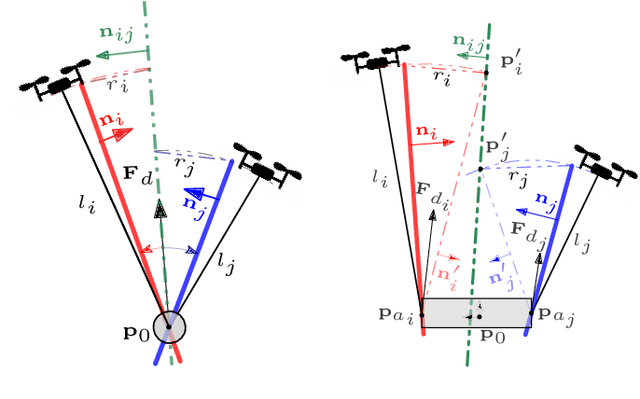
We consider transporting a heavy payload that is attached to multiple quadrotors. The current state-of-the-art controllers either do not avoid inter-robot collision at all, leading to crashes when tasked with carrying payloads that are small in size compared to the cable lengths, or use computational demanding nonlinear optimization. We propose an extension to an existing efficient geometric payload transport controller to effectively avoid such collisions by designing an optimized cable force allocation method, and thus retaining the original stability properties. Our approach introduces a cascade of carefully designed quadratic programs that can be solved efficiently on highly constrained embedded flight controllers. We demonstrate our method on challenging scenarios with up to three small quadrotors with various payloads and cable lengths, with our controller running in real-time directly on the robots.
Online Transformers with Spiking Neurons for Fast Prosthetic Hand Control
Mar 21, 2023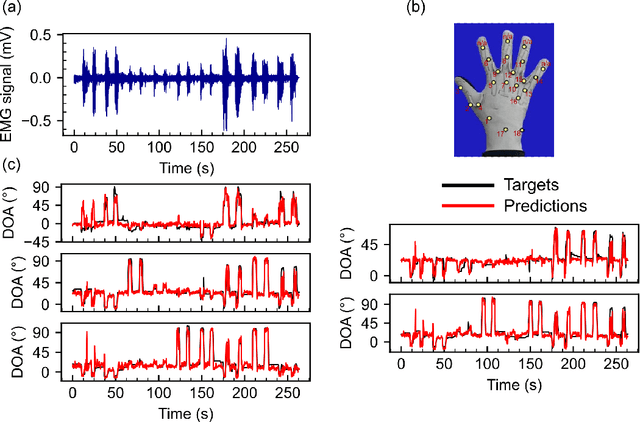
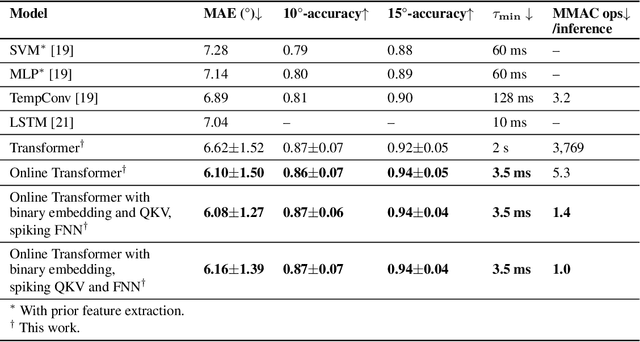
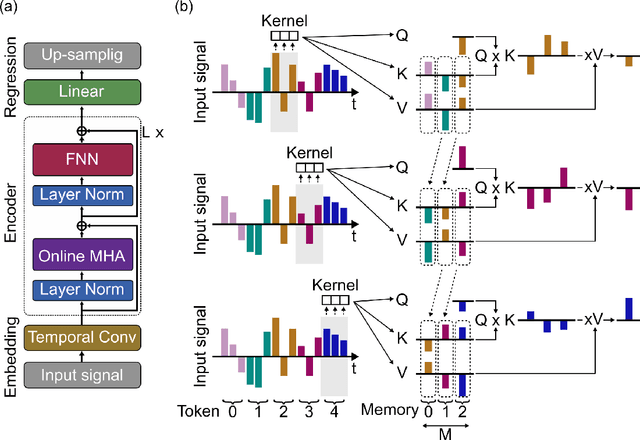
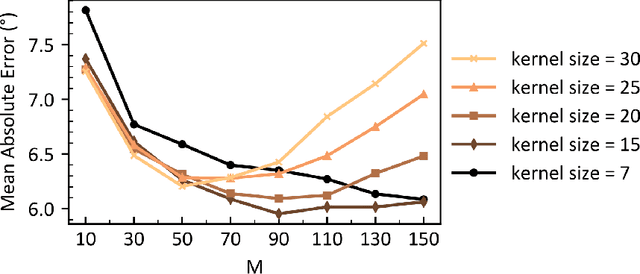
Transformers are state-of-the-art networks for most sequence processing tasks. However, the self-attention mechanism often used in Transformers requires large time windows for each computation step and thus makes them less suitable for online signal processing compared to Recurrent Neural Networks (RNNs). In this paper, instead of the self-attention mechanism, we use a sliding window attention mechanism. We show that this mechanism is more efficient for continuous signals with finite-range dependencies between input and target, and that we can use it to process sequences element-by-element, this making it compatible with online processing. We test our model on a finger position regression dataset (NinaproDB8) with Surface Electromyographic (sEMG) signals measured on the forearm skin to estimate muscle activities. Our approach sets the new state-of-the-art in terms of accuracy on this dataset while requiring only very short time windows of 3.5 ms at each inference step. Moreover, we increase the sparsity of the network using Leaky-Integrate and Fire (LIF) units, a bio-inspired neuron model that activates sparsely in time solely when crossing a threshold. We thus reduce the number of synaptic operations up to a factor of $\times5.3$ without loss of accuracy. Our results hold great promises for accurate and fast online processing of sEMG signals for smooth prosthetic hand control and is a step towards Transformers and Spiking Neural Networks (SNNs) co-integration for energy efficient temporal signal processing.
Exploring Kinodynamic Fabrics for Reactive Whole-Body Control of Underactuated Humanoid Robots
Mar 09, 2023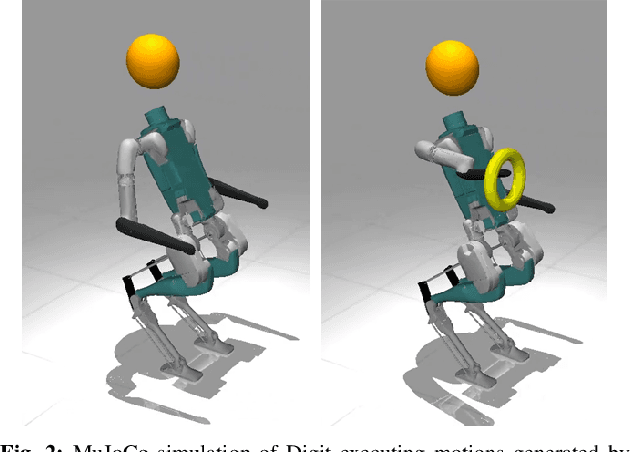
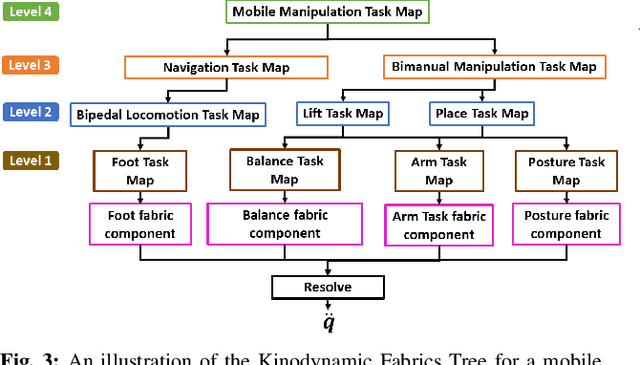
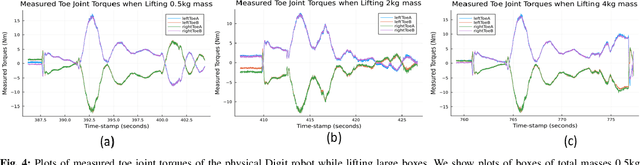
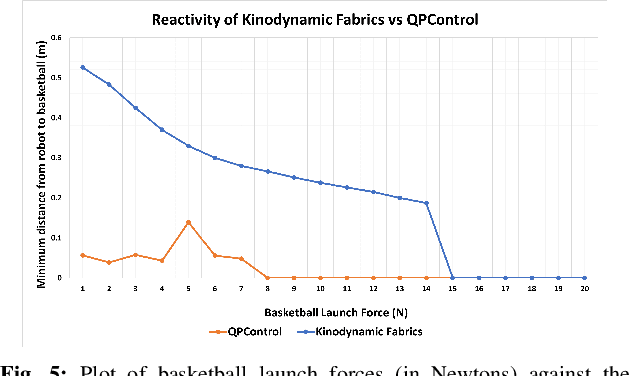
For bipedal humanoid robots to successfully operate in the real world, they must be competent at simultaneously executing multiple motion tasks while reacting to unforeseen external disturbances in real-time. We propose Kinodynamic Fabrics as an approach for the specification, solution and simultaneous execution of multiple motion tasks in real-time while being reactive to dynamism in the environment. Kinodynamic Fabrics allows for the specification of prioritized motion tasks as forced spectral semi-sprays and solves for desired robot joint accelerations at real-time frequencies. We evaluate the capabilities of Kinodynamic fabrics on diverse physically challenging whole-body control tasks with a bipedal humanoid robot both in simulation and in the real-world. Kinodynamic Fabrics outperforms the state-of-the-art Quadratic Program based whole-body controller on a variety of whole-body control tasks on run-time and reactivity metrics in our experiments. Our open-source implementation of Kinodynamic Fabrics as well as robot demonstration videos can be found at this url: https://adubredu.github.io/kinofabs.
Zoom is what you need: An empirical study of the power of zoom and spatial biases in image classification
Apr 11, 2023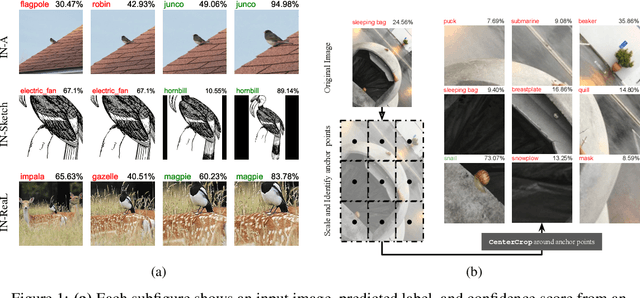



Image classifiers are information-discarding machines, by design. Yet, how these models discard information remains mysterious. We hypothesize that one way for image classifiers to reach high accuracy is to first zoom to the most discriminative region in the image and then extract features from there to predict image labels. We study six popular networks ranging from AlexNet to CLIP and find that proper framing of the input image can lead to the correct classification of 98.91% of ImageNet images. Furthermore, we explore the potential and limits of zoom transforms in image classification and uncover positional biases in various datasets, especially a strong center bias in two popular datasets: ImageNet-A and ObjectNet. Finally, leveraging our insights into the potential of zoom, we propose a state-of-the-art test-time augmentation (TTA) technique that improves classification accuracy by forcing models to explicitly perform zoom-in operations before making predictions. Our method is more interpretable, accurate, and faster than MEMO, a state-of-the-art TTA method. Additionally, we propose ImageNet-Hard, a new benchmark where zooming in alone often does not help state-of-the-art models better label images.