 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Remember, Learn, and Forget in Attention-Based Models
Feb 11, 2026In-Context Learning (ICL) in transformers acts as an online associative memory and is believed to underpin their high performance on complex sequence processing tasks. However, in gated linear attention models, this memory has a fixed capacity and is prone to interference, especially for long sequences. We propose Palimpsa, a self-attention model that views ICL as a continual learning problem that must address a stability-plasticity dilemma. Palimpsa uses Bayesian metaplasticity, where the plasticity of each attention state is tied to an importance state grounded by a prior distribution that captures accumulated knowledge. We demonstrate that various gated linear attention models emerge as specific architecture choices and posterior approximations, and that Mamba2 is a special case of Palimpsa where forgetting dominates. This theoretical link enables the transformation of any non-metaplastic model into a metaplastic one, significantly expanding its memory capacity. Our experiments show that Palimpsa consistently outperforms baselines on the Multi-Query Associative Recall (MQAR) benchmark and on Commonsense Reasoning tasks.
Optimal Gradient Checkpointing for Sparse and Recurrent Architectures using Off-Chip Memory
Dec 16, 2024



Recurrent neural networks (RNNs) are valued for their computational efficiency and reduced memory requirements on tasks involving long sequence lengths but require high memory-processor bandwidth to train. Checkpointing techniques can reduce the memory requirements by only storing a subset of intermediate states, the checkpoints, but are still rarely used due to the computational overhead of the additional recomputation phase. This work addresses these challenges by introducing memory-efficient gradient checkpointing strategies tailored for the general class of sparse RNNs and Spiking Neural Networks (SNNs). SNNs are energy efficient alternatives to RNNs thanks to their local, event-driven operation and potential neuromorphic implementation. We use the Intelligence Processing Unit (IPU) as an exemplary platform for architectures with distributed local memory. We exploit its suitability for sparse and irregular workloads to scale SNN training on long sequence lengths. We find that Double Checkpointing emerges as the most effective method, optimizing the use of local memory resources while minimizing recomputation overhead. This approach reduces dependency on slower large-scale memory access, enabling training on sequences over 10 times longer or 4 times larger networks than previously feasible, with only marginal time overhead. The presented techniques demonstrate significant potential to enhance scalability and efficiency in training sparse and recurrent networks across diverse hardware platforms, and highlights the benefits of sparse activations for scalable recurrent neural network training.
On-Chip Learning via Transformer In-Context Learning
Oct 11, 2024



Autoregressive decoder-only transformers have become key components for scalable sequence processing and generation models. However, the transformer's self-attention mechanism requires transferring prior token projections from the main memory at each time step (token), thus severely limiting their performance on conventional processors. Self-attention can be viewed as a dynamic feed-forward layer, whose matrix is input sequence-dependent similarly to the result of local synaptic plasticity. Using this insight, we present a neuromorphic decoder-only transformer model that utilizes an on-chip plasticity processor to compute self-attention. Interestingly, the training of transformers enables them to ``learn'' the input context during inference. We demonstrate this in-context learning ability of transformers on the Loihi 2 processor by solving a few-shot classification problem. With this we emphasize the importance of pretrained models especially their ability to find simple, local, backpropagation free, learning rules enabling on-chip learning and adaptation in a hardware friendly manner.
Analog In-Memory Computing Attention Mechanism for Fast and Energy-Efficient Large Language Models
Sep 28, 2024



Transformer neural networks, driven by self-attention mechanisms, are core components of foundational and Large Language Models. In generative transformers, self-attention uses cache memory to store token projections, avoiding recomputation at each time step. However, GPU-stored projections must be loaded into SRAM for each new generation step, causing latency and energy bottlenecks for long sequences. In this work, we propose a fast and energy-efficient hardware implementation of self-attention using analog in-memory computing based on gain cell memories. Volatile gain cell memories can be efficiently written to store new tokens during sequence generation, while performing analog signed weight multiplications to compute the dot-products required for self-attention. We implement Sliding Window Attention, which keeps memory of a finite set of past steps. A charge-to-pulse converter for array readout eliminates the need for analog-to-digital conversion between self-attention stages. Using a co-designed initialization algorithm to adapt pre-trained weights to gain cell non-idealities, we achieve NLP performance comparable to ChatGPT-2 with minimal training iterations, despite hardware constraints. Our end-to-end hardware design includes digital controls, estimating area, latency, and energy. The system reduces attention latency by up to two orders of magnitude and energy consumption by up to five orders compared to GPUs, marking a significant step toward ultra-fast, low-power sequence generation in Large Language Models.
SNNAX -- Spiking Neural Networks in JAX
Sep 04, 2024

Spiking Neural Networks (SNNs) simulators are essential tools to prototype biologically inspired models and neuromorphic hardware architectures and predict their performance. For such a tool, ease of use and flexibility are critical, but so is simulation speed especially given the complexity inherent to simulating SNN. Here, we present SNNAX, a JAX-based framework for simulating and training such models with PyTorch-like intuitiveness and JAX-like execution speed. SNNAX models are easily extended and customized to fit the desired model specifications and target neuromorphic hardware. Additionally, SNNAX offers key features for optimizing the training and deployment of SNNs such as flexible automatic differentiation and just-in-time compilation. We evaluate and compare SNNAX to other commonly used machine learning (ML) frameworks used for programming SNNs. We provide key performance metrics, best practices, documented examples for simulating SNNs in SNNAX, and implement several benchmarks used in the literature.
A Hybrid SNN-ANN Network for Event-based Object Detection with Spatial and Temporal Attention
Mar 15, 2024



Event cameras offer high temporal resolution and dynamic range with minimal motion blur, making them promising for object detection tasks. While Spiking Neural Networks (SNNs) are a natural match for event-based sensory data and enable ultra-energy efficient and low latency inference on neuromorphic hardware, Artificial Neural Networks (ANNs) tend to display more stable training dynamics and faster convergence resulting in greater task performance. Hybrid SNN-ANN approaches are a promising alternative, enabling to leverage the strengths of both SNN and ANN architectures. In this work, we introduce the first Hybrid Attention-based SNN-ANN backbone for object detection using event cameras. We propose a novel Attention-based SNN-ANN bridge module to capture sparse spatial and temporal relations from the SNN layer and convert them into dense feature maps for the ANN part of the backbone. Experimental results demonstrate that our proposed method surpasses baseline hybrid and SNN-based approaches by significant margins, with results comparable to existing ANN-based methods. Extensive ablation studies confirm the effectiveness of our proposed modules and architectural choices. These results pave the way toward a hybrid SNN-ANN architecture that achieves ANN like performance at a drastically reduced parameter budget. We implemented the SNN blocks on digital neuromorphic hardware to investigate latency and power consumption and demonstrate the feasibility of our approach.
Harnessing Manycore Processors with Distributed Memory for Accelerated Training of Sparse and Recurrent Models
Nov 07, 2023



Current AI training infrastructure is dominated by single instruction multiple data (SIMD) and systolic array architectures, such as Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs), that excel at accelerating parallel workloads and dense vector matrix multiplications. Potentially more efficient neural network models utilizing sparsity and recurrence cannot leverage the full power of SIMD processor and are thus at a severe disadvantage compared to today's prominent parallel architectures like Transformers and CNNs, thereby hindering the path towards more sustainable AI. To overcome this limitation, we explore sparse and recurrent model training on a massively parallel multiple instruction multiple data (MIMD) architecture with distributed local memory. We implement a training routine based on backpropagation through time (BPTT) for the brain-inspired class of Spiking Neural Networks (SNNs) that feature binary sparse activations. We observe a massive advantage in using sparse activation tensors with a MIMD processor, the Intelligence Processing Unit (IPU) compared to GPUs. On training workloads, our results demonstrate 5-10x throughput gains compared to A100 GPUs and up to 38x gains for higher levels of activation sparsity, without a significant slowdown in training convergence or reduction in final model performance. Furthermore, our results show highly promising trends for both single and multi IPU configurations as we scale up to larger model sizes. Our work paves the way towards more efficient, non-standard models via AI training hardware beyond GPUs, and competitive large scale SNN models.
Online Transformers with Spiking Neurons for Fast Prosthetic Hand Control
Mar 21, 2023



Transformers are state-of-the-art networks for most sequence processing tasks. However, the self-attention mechanism often used in Transformers requires large time windows for each computation step and thus makes them less suitable for online signal processing compared to Recurrent Neural Networks (RNNs). In this paper, instead of the self-attention mechanism, we use a sliding window attention mechanism. We show that this mechanism is more efficient for continuous signals with finite-range dependencies between input and target, and that we can use it to process sequences element-by-element, this making it compatible with online processing. We test our model on a finger position regression dataset (NinaproDB8) with Surface Electromyographic (sEMG) signals measured on the forearm skin to estimate muscle activities. Our approach sets the new state-of-the-art in terms of accuracy on this dataset while requiring only very short time windows of 3.5 ms at each inference step. Moreover, we increase the sparsity of the network using Leaky-Integrate and Fire (LIF) units, a bio-inspired neuron model that activates sparsely in time solely when crossing a threshold. We thus reduce the number of synaptic operations up to a factor of $\times5.3$ without loss of accuracy. Our results hold great promises for accurate and fast online processing of sEMG signals for smooth prosthetic hand control and is a step towards Transformers and Spiking Neural Networks (SNNs) co-integration for energy efficient temporal signal processing.
Single-Shot 3D Detection of Vehicles from Monocular RGB Images via Geometry Constrained Keypoints in Real-Time
Jun 23, 2020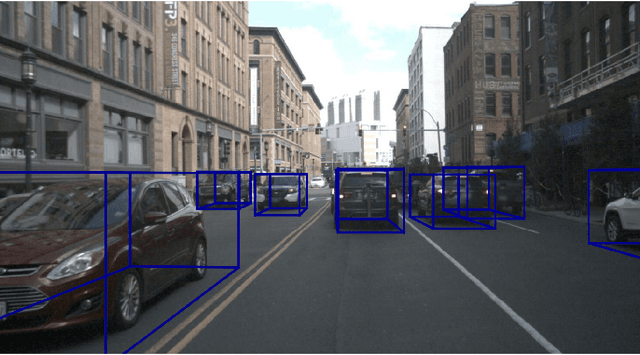
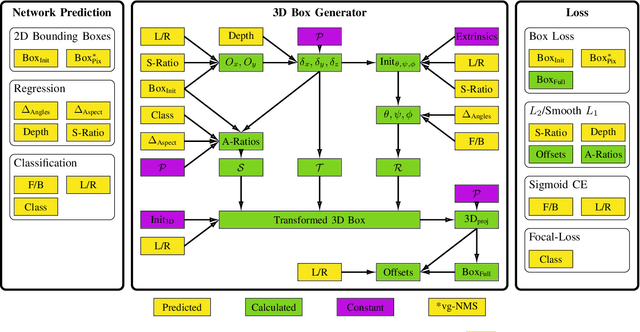
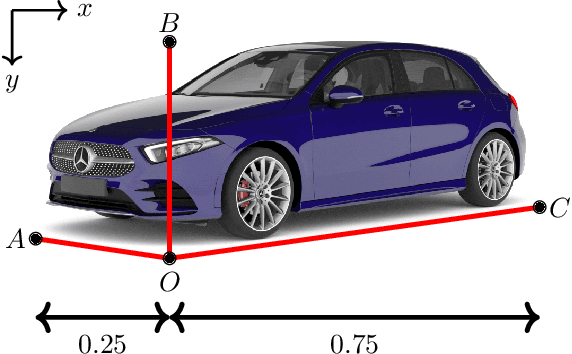

In this paper we propose a novel 3D single-shot object detection method for detecting vehicles in monocular RGB images. Our approach lifts 2D detections to 3D space by predicting additional regression and classification parameters and hence keeping the runtime close to pure 2D object detection. The additional parameters are transformed to 3D bounding box keypoints within the network under geometric constraints. Our proposed method features a full 3D description including all three angles of rotation without supervision by any labeled ground truth data for the object's orientation, as it focuses on certain keypoints within the image plane. While our approach can be combined with any modern object detection framework with only little computational overhead, we exemplify the extension of SSD for the prediction of 3D bounding boxes. We test our approach on different datasets for autonomous driving and evaluate it using the challenging KITTI 3D Object Detection as well as the novel nuScenes Object Detection benchmarks. While we achieve competitive results on both benchmarks we outperform current state-of-the-art methods in terms of speed with more than 20 FPS for all tested datasets and image resolutions.